論文解讀(TAMEPT)《A Two-Stage Framework with Self-Supervised Distillation For Cross-Domain Text Classific
論文資訊
論文標題:A Two-Stage Framework with Self-Supervised Distillation For Cross-Domain Text Classification
論文作者:Yunlong Feng, Bohan Li, Libo Qin, Xiao Xu, Wanxiang Che
論文來源:2023 aRxiv
論文地址:download
論文程式碼:download
視屏講解:click
1 介紹
動機:以前的工作主要集中於提取 域不變特徵 或 任務不可知特徵,而忽略了存在於目標域中可能對下游任務有用的域感知特徵;
貢獻:
-
- 提出一個兩階段的學習框架,使現有的分類模型能夠有效地適應目標領域;
- 引入自監督蒸餾,可以幫助模型更好地從目標領域的未標記資料中捕獲域感知特徵;
- 在 Amazon 跨域分類基準上的實驗表明,取得了 SOTA ;
2 相關
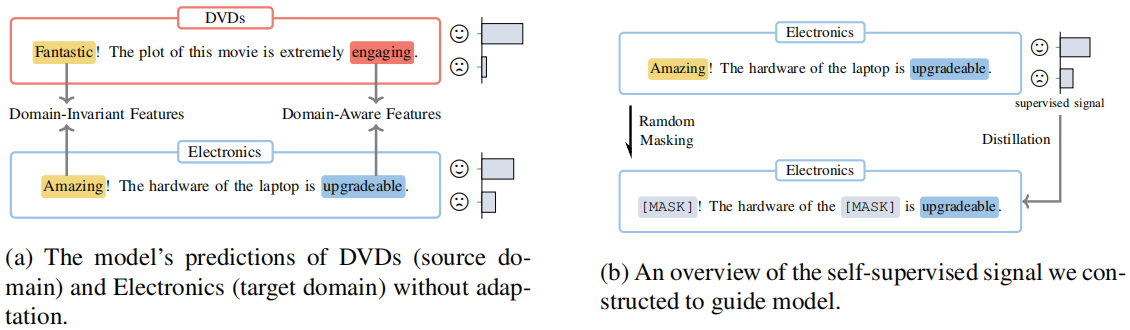
Figure 1(a):闡述域不變特徵和域感知特徵與任務的關係;
Figure 1(b):闡述遮蔽域不變特徵和域感知特徵與預測的關係:
-
- 通過掩蓋域不變特徵,模型建立預測和域感知特徵的相關性;
- 通過掩蓋域感知特徵,模型加強了預測和域不變特徵的關係;
一個文字提示組成如下:
$\boldsymbol{x}_{\mathrm{p}}=\text { "[CLS] } \boldsymbol{x} \text {. It is [MASK]. [SEP]"} \quad\quad(1)$
$\text{PLM}$ 將 $\boldsymbol{x}_{\mathrm{p}}$ 作為輸入,並利用上下文資訊用詞彙表中的一個單詞填充 $\text{[MASK]}$ 作為輸出,輸出單詞隨後被對映到一個標籤 $\mathcal{Y}$。
PT 的目標:
$\mathcal{L}_{p m t}\left(\mathcal{D}^{\mathcal{T}} ; \theta_{\mathcal{M}}\right)=-\sum_{\boldsymbol{x}, y \in \mathcal{D}} y \log p_{\theta_{\mathcal{M}}}\left(\hat{y} \mid \boldsymbol{x}_{\mathrm{p}}\right)$
使用 $\text{MLM }$ 來避免快捷學習($\text{shortcut learning}$),並適應目標域分佈。具體來說,構造了一個掩蔽文字提示符 $\boldsymbol{x}_{\mathrm{pm}}$:
$\boldsymbol{x}_{\mathrm{pm}}=\text { "[CLS] } \boldsymbol{x}_{\mathrm{m}} \text {. It is [MASK]. [SEP]"}$
其中,$m\left(y_{\mathrm{m}}\right)$ 和 $\operatorname{len}_{m\left(\boldsymbol{x}_{\mathrm{m}}\right)}$ 分別表示 $x_{\mathrm{m}}$ 中的掩碼詞和計數;
SSKD
核心:使模型能夠在預測和目標域的域感知特徵之間建立聯絡;
具體:模型迫使 $x_{\mathrm{p}}$ 的預測和 $\boldsymbol{x}_{\mathrm{pm}}$ 的未掩蔽詞之間聯絡起來,本文在 $p_{\theta}\left(y \mid \boldsymbol{x}_{\mathrm{pm}}\right)$ 和 $p_{\theta}\left(y \mid \boldsymbol{x}_{\mathrm{p}}\right)$ 的預測之間進行 $\text{KD}$:
$\mathcal{L}_{s s d}\left(\mathcal{D} ; \theta_{\mathcal{M}}\right)=\sum_{\boldsymbol{x} \in \mathcal{D}} K L\left(p_{\theta_{\mathcal{M}}}\left(y \mid \boldsymbol{x}_{\mathrm{pm}}\right)|| p_{\theta_{\mathcal{M}}}\left(y \mid \boldsymbol{x}_{\mathrm{p}}\right)\right)$
注意:$\boldsymbol{x}_{\mathrm{pm}}$ 可能包含域不變、域感知特徵,或兩者都包含;
3 方法
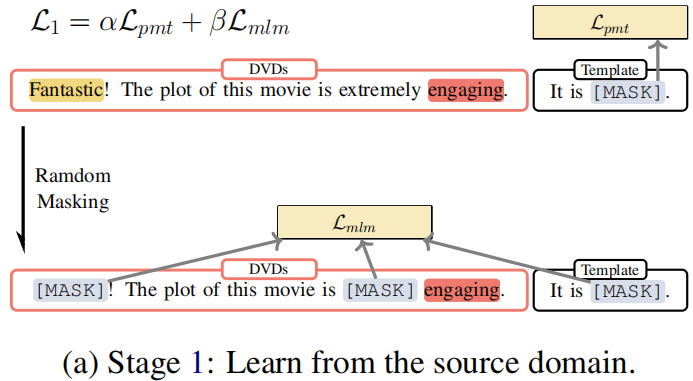
Procedure:
-
- Firstly, we calculate the classification loss of those sentences and update the parameters with the loss, as shown in line 5 of Algorithm 1.
- Then we mask the same sentence and calculate mask language modeling loss to update the parameters, as depicted in line 8 of Algorithm 1. The parameters of the model will be updated together by these two losses.
Objective:
$\begin{array}{l}\mathcal{L}_{1}^{\prime}\left(\mathcal{D}^{\mathcal{T}} ; \theta_{\mathcal{M}}\right)=\alpha \mathcal{L}_{p m t}\left(\mathcal{D}^{\mathcal{T}} ; \theta_{\mathcal{M}}\right) \\\mathcal{L}_{1}^{\prime \prime}\left(\mathcal{D}^{\mathcal{T}} ; \theta_{\mathcal{M}}\right)=\beta \mathcal{L}_{m l m}\left(\mathcal{D} ; \theta_{\mathcal{M}}\right)\end{array}$
Stage 2: Adapt to the target domain
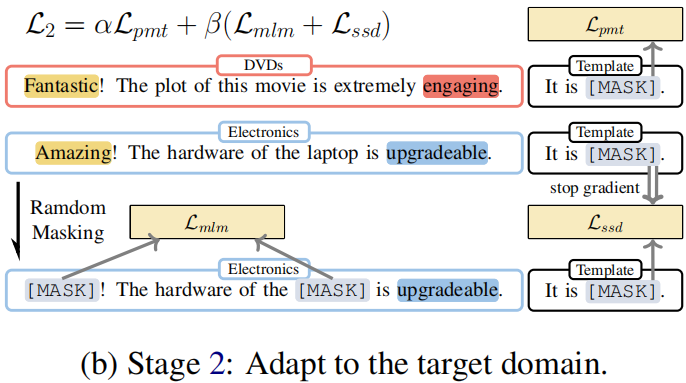
Procedure:
-
- Firstly, we sample labeled data from the source domain $\mathcal{D}_{S}^{\mathcal{T}} $ and calculate sentiment classification loss. The model parameters are updated using this loss in line 5 of Algorithm 2.
- Next, we sample unlabeled data from the target domain $\mathcal{D}_{T} $ and mask the unlabeled data to do a masking language model and selfsupervised distillation with the previous prediction.
Objective:
$\begin{aligned}\mathcal{L}_{2}^{\prime}\left(\mathcal{D}_{S}^{\mathcal{T}}, \mathcal{D}_{T} ; \theta_{\mathcal{M}}\right) & =\alpha \mathcal{L}_{p m t}\left(\mathcal{D}_{S}^{\mathcal{T}} ; \theta_{\mathcal{M}}\right) \\\mathcal{L}_{2}^{\prime \prime}\left(\mathcal{D}_{S}^{\mathcal{T}}, \mathcal{D}_{T} ; \theta_{\mathcal{M}}\right) & =\beta\left(\mathcal{L}_{m l m}\left(\mathcal{D}_{T} ; \theta_{\mathcal{M}}\right)\right. \left.+\mathcal{L}_{s s d}\left(\mathcal{D}_{T} ; \theta_{\mathcal{M}}\right)\right)\end{aligned}$
Algorithm

4 實驗
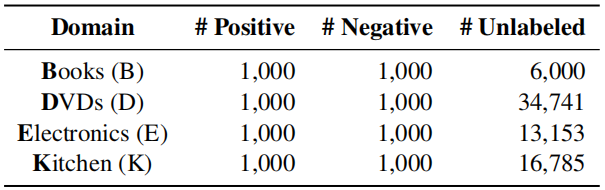
Dataset
Amazon reviews dataset
- $\text{R-PERL }$(2020): Use BERT for cross-domain text classification with pivot-based fine-tuning.
- $\text{DAAT}$ (2020): Use BERT post training for cross-domain text classification with adversarial training.
- $\text{p+CFd}$ (2020): Use XLM-R for cross-domain text classification with class-aware feature self-distillation (CFd).
- $\text{SENTIX}_{\text{Fix}}$ (2020): Pre-train a sentiment-aware language model by several pretraining tasks.
- $\text{UDALM}$ (2021): Fine-tuning with a mixed classification and MLM loss on domain-adapted PLMs.
- $\text{AdSPT}$ (2022): Soft Prompt tuning with an adversarial training object on vanilla PLMs.
- During Stage 1, we train 10 epochs with batch size 4 and early stopping (patience =3 ) on the accuracy metric. The optimizer is AdamW with learning rate 1 $\times 10^{-5}$ . And we halve the learning rate every 3 epochs. We set $\alpha=1.0$, $\beta=0.6$ for Eq.6 .
- During Stage 2, we train 10 epochs with batch size 4 and early stopping (patience =3 ) on the mixing loss of classification loss and mask language modeling loss. The optimizer is AdamW with a learning rate $1 \times 10^{-6}$ without learning rate decay. And we set $\alpha=0.5$, $\beta=0.5$ for Eq. 7 .
- In addition, for the mask language modeling objective and the self-supervised distillation objective, we randomly replace 30% of tokens to [MASK] and the maximum sequence length is set to 512 by truncation of inputs. Especially we randomly select the equal num unlabeled data from the target domain every epoch during Stage 2.
Single-source domain adaptation on Amazon reviews
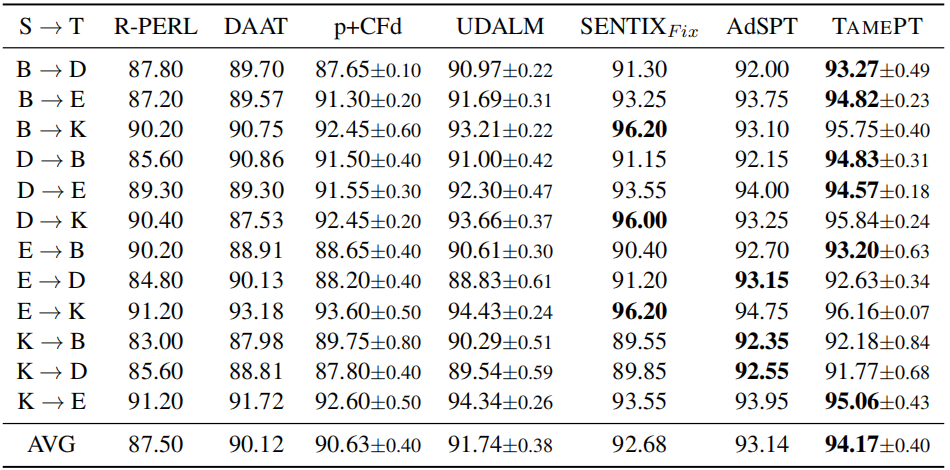
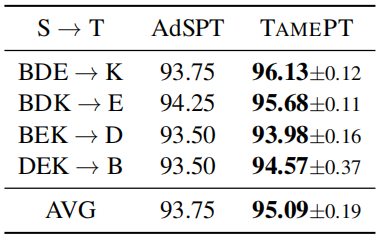
Multi-source domain adaptation on Amazon reviews
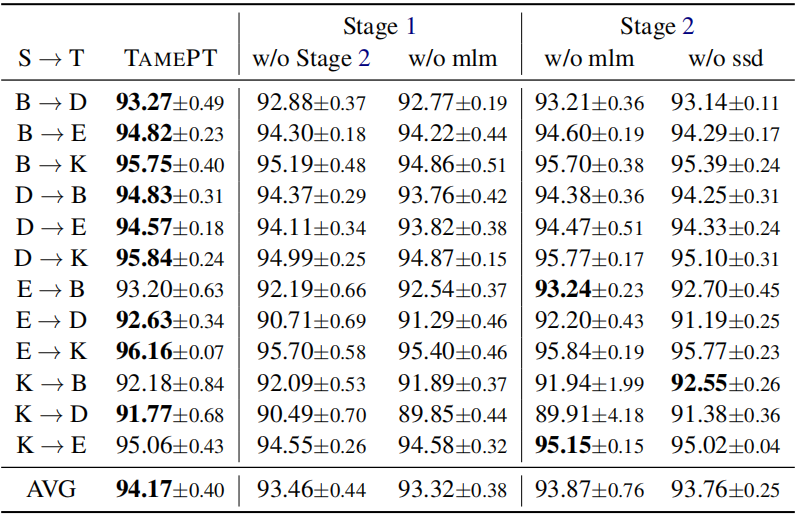
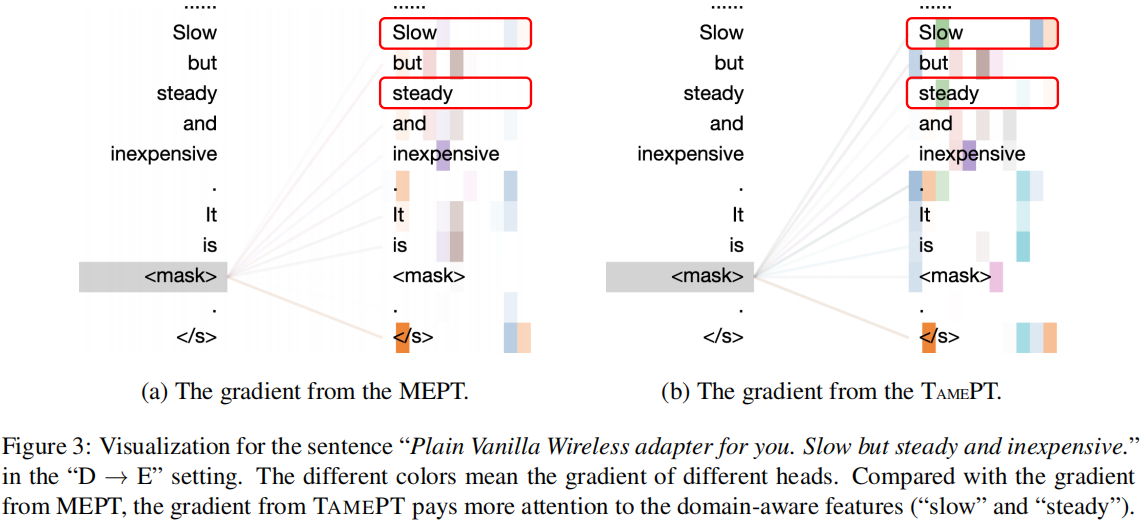

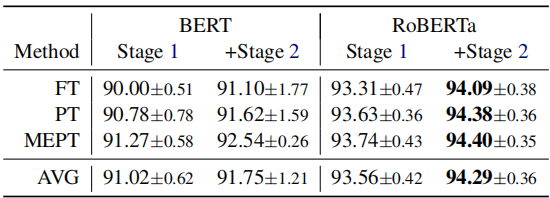
MEPT: The proposed model TAMEPT without Stage 2.
因上求緣,果上努力~~~~ 作者:Wechat~Y466551,轉載請註明原文連結:https://www.cnblogs.com/BlairGrowing/p/17654194.html