聯邦學習中的推理攻擊
Inference Attacks in FL
在人工智慧領域,推理攻擊是提取沒有公開的但攻擊者感興趣的資訊。在聯邦學習中,如果雲聚合器是攻擊者,那麼其獲知的資訊可能包含模型引數、梯度、訓練集的邊界分佈等等;其未知的資訊可能包括使用者端的訓練集資訊(影象內容、某特定成員資訊、屬性等)
推理攻擊的分類
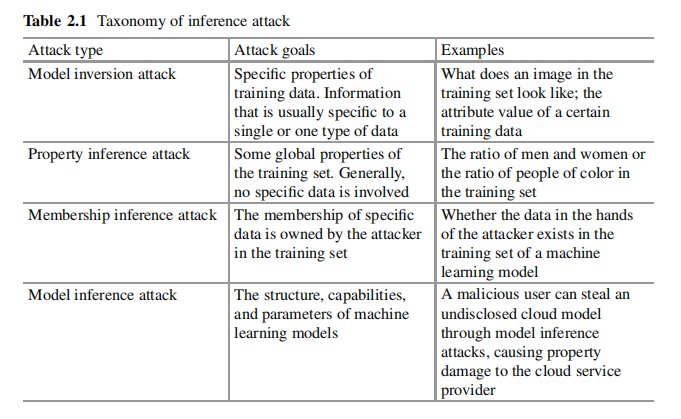
根據攻擊者的目的分為:模型逆向攻擊、屬性推理攻擊、成員推理攻擊和模型推理攻擊。
-
模型逆向攻擊(Model inversion attacks)
模型逆向攻擊又叫模型重構攻擊(Model reconstruction attack, RA)。攻擊者企圖從模型中獲取訓練資料集的原始資料資訊。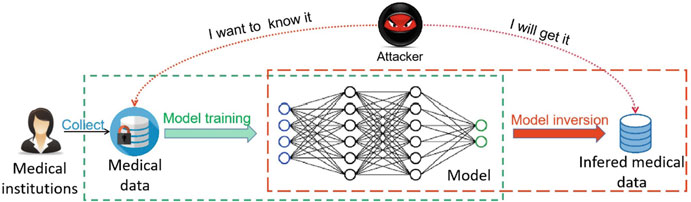
-
屬性推理攻擊(Property inference attacks, PIA)
攻擊者企圖獲取訓練資料集的統計資訊,如某些屬性人群的比例等。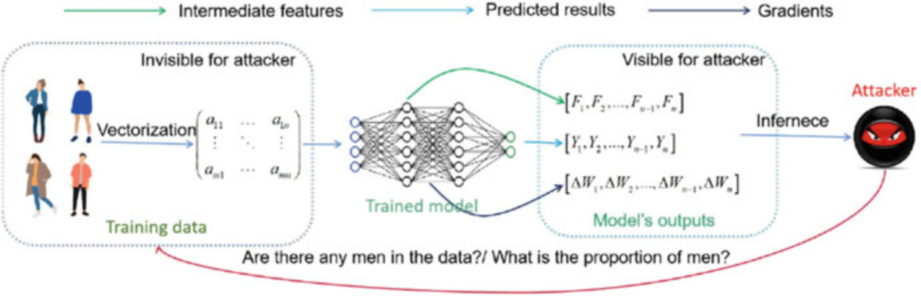
-
成員推理攻擊(Membership inference attacks, MIA)
攻擊者企圖獲知某一條給定資料是否在目標模型的訓練集中(利用目標模型的輸出推斷)。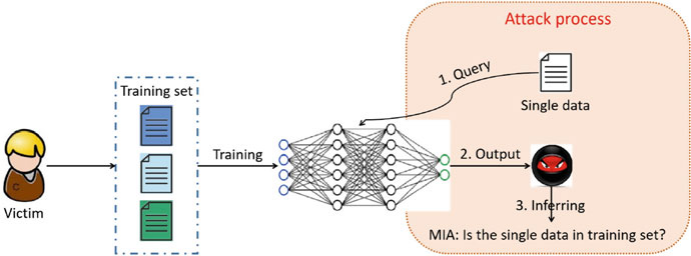
-
模型推理攻擊(Model inference attacks)
模型推理攻擊又叫模型提取攻擊(Model extraction attack, MEA).目標是生成一個與目標模型相似的替代模型。模型推理攻擊更常見於傳統機器學習中,而不是聯邦學習中。
聯邦學習中的推理攻擊
模型逆向攻擊(重構攻擊RA, Res)
在聯邦學習中,重構攻擊中的私有資料指使用者端本地資料,公開資料指全域性模型(中央伺服器和使用者端能夠獲取的)和梯度(中央伺服器能夠獲取的)。因此可以進一步將聯邦學習中的MIA分成兩類:針對聚合梯度的攻擊和針對全域性模型的攻擊。
針對聚合梯度的攻擊
均方誤差損失函數的定義:
反向傳播演演算法中\(W\)和\(b\)如下計算:
可以通過以下兩種方式重構使用者端的輸入\(x\):
- 可以發現\(\frac{\nabla W_{i}}{\nabla b}=x_{i}\)。因此使用者端的隱私可能會在使用者端上傳梯度給中央伺服器時洩露。
- \(\nabla W_{i}\) 和\(x_i\) 是成比例的,因此當中央伺服器沒有接收到\(\nabla b\) 時,原始資料可以通過調整比例值獲取,尤其是當資料\(x_i\) 是影象時,通過視覺化方式可以直觀判斷比例是否正確。
上述相同的攻擊策略可以被應該用到有多個隱藏層的神經網路(即深度神經網路)中。深度神經網路的\(W\) 和\(b\) 梯度如下:
就有:
其中\(W_{i,k}^{1}\)和\(b_{i}^{1}\)代表第一個隱藏層的梯度和偏置;\(\lambda\)是正則化係數。
當\(\lambda=0\)時,\(\frac{\nabla W_{i,k}^{1}}{\nabla b_{i}^{1}}\)就是資料\(x\),而當\(\lambda>0\)時,\(\frac{\nabla W_{i,k}^{1}}{\nabla b_{i}^{1}}\)是資料\(x\)的近似值。
然而,這種方法並不適用於複雜神經網路,如折積神經網路。為此,Zhu等人提出了一個梯度擬合方法——Deep Leakage from Gradients(DLG),該方法通過最小化噪聲和全域性模型下獲得的原始資料之間的梯度差異來優化噪聲,從而逐漸洩露原始資料。通過對噪聲的優化,噪聲將逐漸轉化為與原始梯度對應的資料,即私有資料。
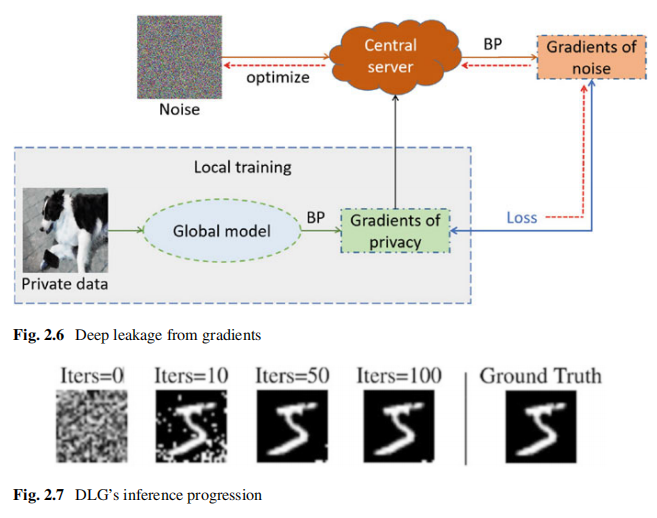
其中,\(\nabla_\theta\mathcal{L}_\theta(x,y)\)和\(\nabla_\theta\mathcal{L}_\theta\left(x^*,y\right)\)分別代表私有資料和噪聲產生的梯度,\(d\)是一個距離度量函數。
值得注意的是,優化的推導需要一個二階可推導的全域性模型。因此,當全域性模型的啟用函數是一個二階不可推導的函數時,如ReLU、leaky_ReLU等,則不能使用該方法。

其中,BP代表back-propagation algorithm,即反向傳播演演算法。
作者還證明了重構攻擊在聚合梯度上也可能存在。例如當攻擊者獲得聚合梯度\(\Delta W=\frac{1}{n}(\Delta w_{1}+\Delta w_{2}+\Delta w_{3}+\ldots+\Delta w_{n})
\)時,攻擊者只需要知道\(n\)的值就可以推斷出\(W_1\)到\(W_n\)對應的所有資料。此外,DLG除了能推理原始資料\(x\)之外,還可以推理原始資料的標籤\(y\),但錯誤率很高。Zhao等人提出的Improved Deep Leakage from Gradients (iDLG)方法可以提高標籤推理準確率。
使用獨熱編碼的神經網路其交叉熵損失函數定義如下:其中\(x\)是輸入,\(c\)是標籤
根據反向傳播演演算法,每個\(y\)對應的梯度定義如下:
通常來說,聯邦學習中基於梯度的推理攻擊只能在中央伺服器實現。因此在這些方法中中央伺服器被認為是惡意的。
針對全域性模型的攻擊
機器學習模型會在訓練過程中會以某種方式「記住」訓練資料,因此全域性模型是否會洩露隱私值得關注。在聯邦學習中,中央伺服器和使用者端共用全域性模型和所有的細節。因此,不同於基於梯度的攻擊,使用者端和中央伺服器都有可能被攻擊者腐化來達到他們的惡意目標。
但聯邦學習中大多數基於模型的攻擊是依賴生成對抗網路方法或與基於梯度的攻擊聯合。Hitaj等人證明惡意使用者端可以使用生成對抗網路執行重構攻擊來獲取使用者端的隱私資訊,把他們這種方法記作DMU-GAN。DMU-GAN獲取的更像是一個平均樣本,也就是說不是一個特定的樣本點,而是對應於某一個特定標籤的平均樣本。然而在臉部辨識中,其與基於梯度的攻擊效果沒什麼不同,因為每個標籤對應一個特定的人。另外DMU-GAN顯著阻礙聯邦學習的訓練過程,這是的這種攻擊非常容易被檢測到。
屬性推理攻擊(PIA, Property Inference Attacks)
不同於重構攻擊專注於推理資料集的資料表示,屬性推理攻擊更注意資料集的整體統計特徵。
通常大多數屬性推理攻擊假設攻擊者擁有和受害者資料集分佈相同的輔助資料集,這在聯邦學習設定中是合理的。屬性推理攻擊的核心思想是攻擊者將輔助資料集分成幾部分,為便於理解,假設分成兩部分\(P\)和\(\bar{P}\),分別代表擁有屬性\(p\)和不擁有屬性\(p\)。攻擊者分別利用這兩個資料集訓練連個影子模型。理論上其中一個影子模型會捕捉到屬性\(p\),而其餘影子模型則沒有,這使得他們的輸出有區別。接著攻擊者利用這些擁有屬性P的輸出形成一個後設資料集。使用後設資料集可以訓練判別模型,通過輸出資料判斷目標資料集是否含有屬性P。
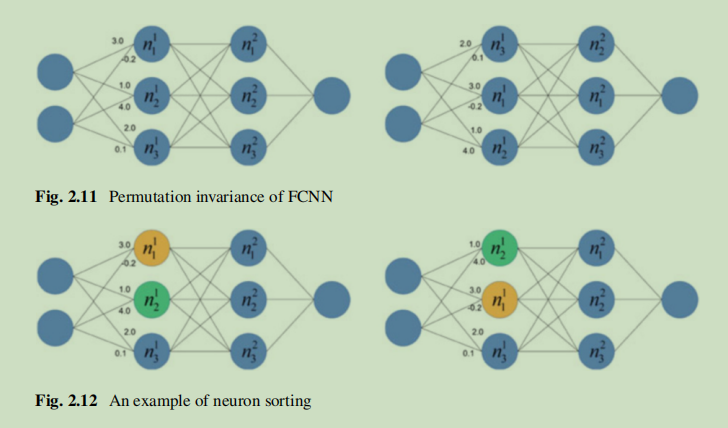
這種方法很直接,但只適用於傳統機器學習模型,例如隱式馬爾科夫鏈和支援向量機,而對於大多數主流深度神經網路失效。主要原因是全連線神經網路的排列不變性。而解決這個問題Ganju提出兩種方法:1.神經元排序(根據對應權重總和對影子模型中每一層節點排序),這種方法通過輸入預定模式消除了排序不變性的影響,然而這種方法沒有考慮等效網路的影響,因為大量引數將給訓練元分類器和影子模型帶來巨大挑戰 2.基於深度集的表示法,深度集允許輸入具有排列不變性,而基於深度集的網路可以實現具有不變性的函數,如圖集合\(A\)有三種不同的表示,但它們與順序的不同在本質上是相同的。對於一個普通的神經網路\(F(·)\),元素的順序會產生不同的輸出。\(F'(·)\)滿足排列不變性可以解決這個問題,並且輸入結果是它應該的那樣無論集合的元素順序怎樣。
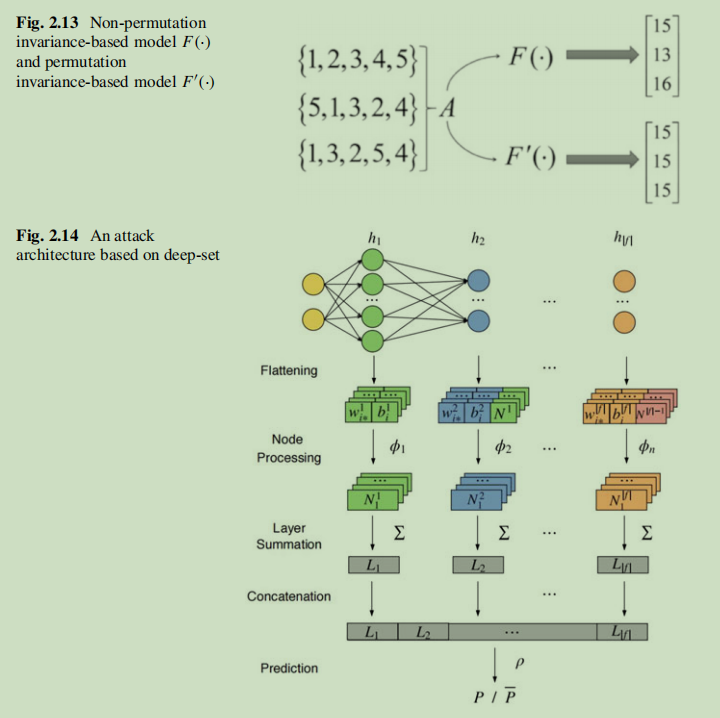
此外,Melis等人進一步將屬性推理攻擊融入聯邦學習設定中。他們沒有使用目標模型的輸入作為元分類器的輸入,而是使用聯邦學習過程中的梯度作為輸入,實驗結果證明這種方法在推理與目標模型任務不相關的屬性時更有效,並且可以應用在更復雜的資料集中。
成員推理攻擊(MIA, Membership Inference Attacks)
在MIA中,攻擊者對特定的資料點(例如,人、影象等)是否在受害者模型的訓練集中感興趣,這是聯邦學習系統中一個嚴重的威脅。
基本思路:使用影子訓練集建立一個影子模型來模擬目標模型的表現,之後通過影子模型獲得影子訓練集和影子測試集的相應輸出,使用「在訓練集中」和「不在訓練集中」來分別標記這些輸出。最後攻擊者使用新構建的資料集來訓練元分類器(也就是攻擊模型)。該元分類器根據該範例對應的輸出可以判斷一個範例是否在目標模型的訓練集中。
在成員推理攻擊中,知識可以被粗略分為四個類別:資料知識、訓練知識、模型知識和輸出知識。
- 資料知識:資料知識決定了對手如何構建有效的影子訓練集。
當敵手不能獲得目標資料分散式,可以採用以下兩種方法:- 統計合成:對手可能有一些統計資訊,如某些特徵的邊緣分佈。他們可以從這些邊際分佈中取樣。
- 模型合成:如果攻擊者既沒有資料分佈,也沒有統計知識,他們可以利用目標模型獲得陰影訓練集。直覺是,由目標模型分類的具有高置信度的樣本更有可能在統計上與目標訓練集中的資料相似。
- 訓練知識:訓練知識是指訓練過程中的一些超引數,如訓練時代、優化器、學習速率等。
- 模型知識:模型知識主要是指模型結構,其中包括每個神經網路層所使用的結構和啟用函數。
- 輸出知識:輸出知識決定了攻擊者將從目標模型中獲得什麼樣的反饋。
有三種主要的輸出知識型別:- 敵手獲得了完全輸出的知識,這意味著他們知道每個類別的置信度。
- 敵手擁有部分輸出知識,這意味著攻擊者只能獲得具有最高置信度的前k個。
- 敵手只能獲得與輸入對應的硬標籤(沒有置信度資訊)。
在協同訓練設定下,如果攻擊者通過影響訓練的中間結果來實現成員推理攻擊,那麼我們將這種攻擊稱為主動攻擊(如模型逆向攻擊、屬性推理攻擊),否則稱為被動攻擊。
Shokri等人的論文中提出了三個強假設:
- 需要訓練多個影子模型,這大大增加了攻擊的成本。
- 攻擊者需要了解目標模型的結構,並將其作為影子模型的結構。
- 攻擊者必須知道目標分佈,才能實現有效的攻擊。
這些假設雖然在某些場景能實現,但這嚴重阻礙了成員推理攻擊的廣泛使用。

Li等人首先使用一個影子模型來擬合目標模型的行為,使影子模型輸出的概率分佈與目標模型輸出的概率分佈相等。其次,他們利用影子模型上目標資料的損失來確定目標資料是否在目標訓練集中。 此外,他們還結合了對抗性攻擊的思想,並通過對抗性擾動的大小來判斷目標樣本的隸屬度。直覺是,目標模型在訓練集上的判斷模型通常是非常魯棒的;因此,它需要比其他樣本更多的擾動來改變標籤。
模型推理攻擊
模型推理攻擊的目的是獲取公眾認為不知道的資訊,如目標模型的結構和引數。
防禦推理攻擊
-
基於機器學習優化的防禦
-
學習機制
模型過擬合的主要原因之一是模型容量的規模較大。因此,一般來說,在相同的條件下,一個規模更大的網路更有能力進行訓練,更容易記住相關資訊,從而導致過擬合,這使得過擬合的網路很容易受到推理攻擊。 -
正則化
正則化的目的是優化模型的效能。 正則化並不改變模型的結構。它將使一定的模型引數接近於0,以減少其對模型的影響。 此外,這些引數所捕獲的特徵的權重將顯著減少,但不會完全丟失。因此,它比過擬合更柔和一些,但它也使模型容易受到推理攻擊。 -
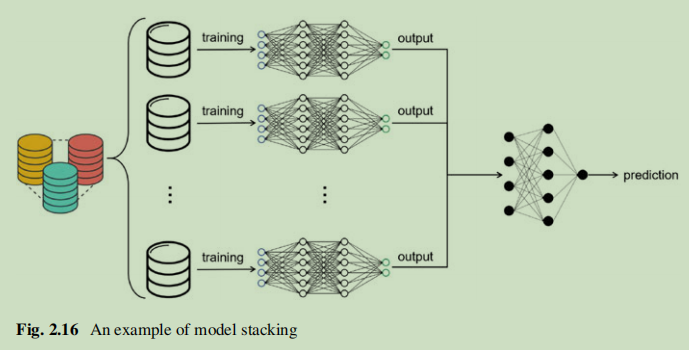
模型堆疊
模型疊加本質上是一種整合學習。它通過將訓練集分成成對的不相交的集合,使用訓練集訓練多個模型,然後將它們組合成一個聚合的模型來進行預測。該方法可以有效地提高模型的推廣性。此外,與前兩種方法相比,它可以更好地減輕推理攻擊。
-
-
基於擾動的防禦
推理攻擊使用現有知識\(K\)來推斷未知資料U。人們很難不去思考\(K\)和\(U\)之間的特定關係是否支援推理攻擊的可能性。破壞這種關係最簡單的方法之一是向\(K\)新增噪聲。差分隱私(DP)是目前廣泛研究的擾動方法之一,例如在基於梯度的重構攻擊中對梯度新增擾動;在屬性推理攻擊中對模型輸出新增擾動以及在對模型引數新增擾動。一般來說,防禦者可以干擾優化演演算法、模型引數、中間模型結果(如梯度)、模型輸出等。 -
知識蒸餾
Hinton等人提出了一種基於模型壓縮的知識蒸餾技術。 Shejwalkar等人應用了知識蒸餾來對抗推理攻擊。他們最小化了學生模型和教師模型輸出之間的KL散度(資訊理論中流行的距離度量),避免了直接使用特定的資料集來訓練學生模型(用於部署),從而在一定程度上減輕了推理攻擊。Kaya等人比較了知識蒸餾和各種正則化技術,實驗表明知識蒸餾是一種有效的防禦方法。然而,它們中沒有一個在最先進的攻擊設定下被實驗驗證,而且大多數的防禦只能用一個公共訓練集來構建。 -
對抗機器學習
對抗性機器學習的主要思想是,當訓練或部署模型時,防禦者從他的角度優化模型。目前的對抗性機器學習主要可分為兩大類:- 在訓練階段,防禦者將現有的攻擊策略作為模型訓練過程的正則化項新增到模型訓練過程中。例如,在MIA中,最大限度化攻擊模型的損失,最小化模型效用的損失,形成最小-最大博弈。顯然,這將不可避免地降低目標模型的效用。
- 在預測階段,由於攻擊模型以目標模型的輸出作為輸入,並且攻擊模型容易受到對抗性樣本的影響,因此,防禦者可以對目標模型的輸出新增複雜的擾動,將其變成一個對抗性的樣本,從而減輕攻擊。這種防禦策略可以緩解由於隱私保護和模型效用的權衡所造成的問題
-
基於加密的方法
同態加密是目前最有前途的隱私保護方法。例如,敵手可以在聯邦學習中基於梯度執行模型逆向攻擊。但是,如果梯度採用同態加密進行加密,它不僅可以完成梯度的聚合操作,還可以防止MIAs。然而,加密方法經常帶來很高的通訊和計算成本。因此,它很難在大規模的應用程式中實現。此外,對於基於目標模型輸出的攻擊(如機器學習即服務場景中的攻擊),加密並不是一種有效的防禦方法。