ENVI+ERDAS實現Hyperion葉綠素含量反演:經驗比值法、一階微分法
本文介紹基於ENVI與ERDAS軟體,依據Hyperion高光譜遙感影像,採用經驗比值法、一階微分法等,對葉綠素含量等地表引數加以反演的具體操作。
1 前期準備與本文理論部分
1.1 幾句閒談
前面幾篇部落格介紹了基於Landsat這一多光譜遙感影象資料的多種地表溫度(LST)反演方法,大家可以參考文章ENVI實現QUAC、簡化黑暗像元、FLAASH方法的遙感影像大氣校正,以及文章ENVI大氣校正方法反演Landsat 7地表溫度,還有文章ENVI、ERDAS計算Landsat 7地表溫度:單窗演演算法實現等;那麼接下來,我們就將基於比多光譜資料可以說是更進一步的高光譜衛星資料——大名鼎鼎的Hyperion資料,進行多種其他地表引數的反演。其中,在此之前有必要先了解一下國內外主流的星載高光譜感測器及其平臺的相關資訊,大家可以參考文章全球都有哪些高光譜遙感衛星?。
瞭解相關背景之後,話不多說,我們開始本次的內容。
1.2 背景知識
1.2.1 Hyperion資料介紹
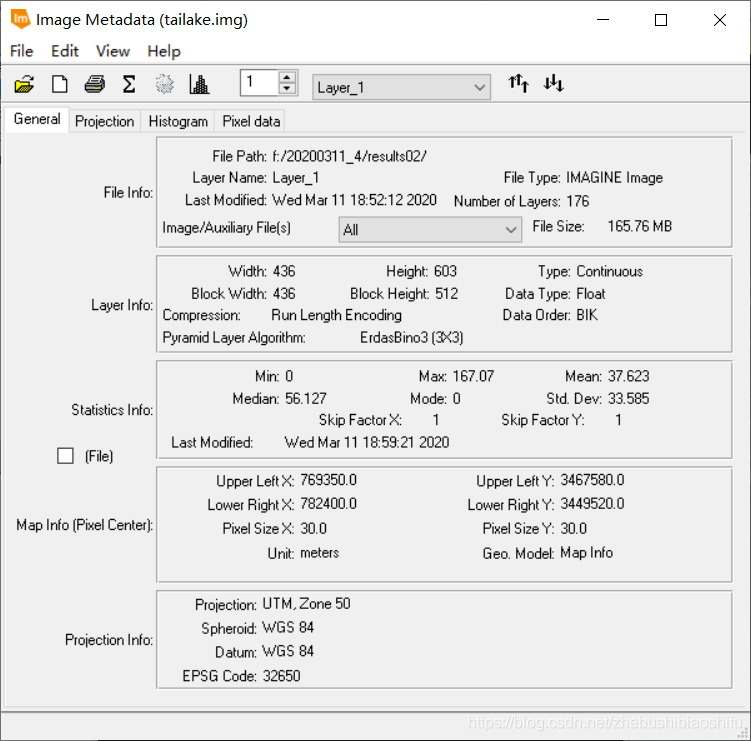
本文所使用的遙感影像資料不同於上述三篇部落格所用的Landsat-7 ETM+影像資料,其來自地球觀測衛星-1(Earth Observing-1,EO-1)。EO-1是美國國家航空航天局(National Aeronautics and Space Administration,NASA)新千年計劃(New Millennium Program,NMP)地球探測部分中第一顆對地觀測衛星,其目的即為在21世紀接替Landsat-7衛星,於2000年11月發射升空。除此之外,NMP目前還包括深空探測(Deep Space,DS)、空間技術(Space Technology,ST)兩個部分。
EO-1衛星軌道引數與Landsat-7較為近似,以期實現兩顆衛星影象每天具有1至4景的重疊,從而進行二者的對比。此外,EO-1已於2017年2月停止服役。
EO-1搭載了三種感測器,分別為高光譜成像光譜儀(Hyperion)、高階陸地成像儀(Advanced Land Imager,ALI)與線性標準成像光譜儀陣列大氣校正器(the Linear Etalon Imaging Spectrometer Array Atmospheric Corrector,LAC)。一般地,傳統的陸地資源衛星只能提供為數不多的多光譜波段,並不能很好滿足日常實際研究、運用的需要;而藉助具有242個波段、光譜範圍為356至2578納米的EO-1 Hyperion感測器,可獲得更具價值的高光譜資料。
EO-1遙感影像命名格式如下:
EO1SPPPRRRYYYYDDDXXXML_GGG_VV
其中,EO1為EO-1衛星代號,S為所用感測器代號(H為Hyperion感測器,A為ALI感測器),PPP為成像時目標所處全球參考系統(Worldwide Reference System,WRS)的軌道(Path),RRR為成像時目標所處WRS的行(Row),YYYY為成像年份,DDD為成像當日在該年份的天數,XXX分別為Hyperion、ALI與AC三種感測器的開關狀態(1為開啟,0為關閉),M為指向模式【(N為天底模式(Nadir),P為點在軌道模式(Pointed Within Path/Row),K為點不在軌道模式(Pointed Outside Path/Row)】,L為影象長度【F為全景(Full Scene),P為區域性景(Partial Scene),Q為次級區域性景(Second Partial Scene),S為樣例(Swatch)】,GGG為影像地面接收站,VV為影像版本編號。
一般地,遙感衛星感測器主要有兩大型別:擺掃式(Whisk Broom Scanners)與推掃式(Push Broom Scanners);Hyperion屬於後者。其242個波段分為可見光近紅外波段(V-NIR)與短波紅外波段(SWIR);其中,1至70波段屬於V-NIR通道,71至242波段屬於SWIR通道。兩個波段之間具有20個波段的波長數值相互重疊,其分別用兩套不同的敏感元件收集各自訊號。
Hyperion產品波段資訊如下所示。
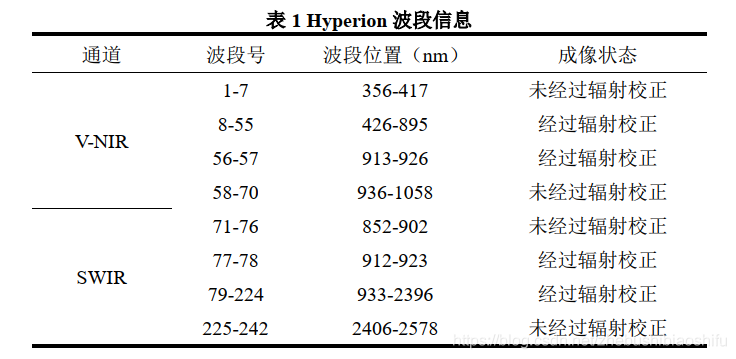
一般地,輻射校正包括輻射定標、大氣校正和太陽及地形校正,用來消除輻射誤差;而上述「輻射校正」包括正射校正,即使用地形資料的幾何校正,不包括大氣校正。
Hyperion產品分為兩級,Level 0與Level 1。前者為原始資料,其僅用來生產Level 1產品。Level 1產品則可以繼續分為L1A、L1B、L1R、L1Gs與L1Gst等。其中,L1B產品與L1R產品分別由美國TRW與USGS處理生成。上述兩種產品與L1A產品的最大不同在於,前二者糾正了V-NIR波段與SWIR波段的空間錯位問題。
而通過影象原始資料中「README.txt」檔案可知,本文所使用的資料為L1Gst級別(大家自己操作時,也依據自己檔案的實際情況判斷即可);如以上內容所述,其已經過部分預處理過程,如正射校正、座標轉換等。
Hyperion產品影象資料的空間解析度為30米。
如上述內容所提到的,Hyperion產品共有242個波段,波長覆蓋範圍為356至2578納米。而在這其中,由於紫色光與短波紅外兩端有些通道的響應度較低,資料利用價值不大,因此係統並未對這些波段加以輻射校正——即對於正式分發的Hyperion產品Level 1資料,上述242個波段中,1至7波段、58至76波段、225至242波段亦稱之壞波段(Bad Bands),其數值均為0值。除此之外,121至126(或127)波段、167至178(或180)波段、224(或222至224)波段由於受到水汽吸收影響較為嚴重,亦需要作為壞波段處理。最後,通過上述篩選後剩餘的波段中,還包括波長重疊的56至57波段和77至78波段;考慮到77至78波段噪聲相對前者較大,訊雜比較低,因此將其同樣剔除。
上述波段篩選結果如下所示。
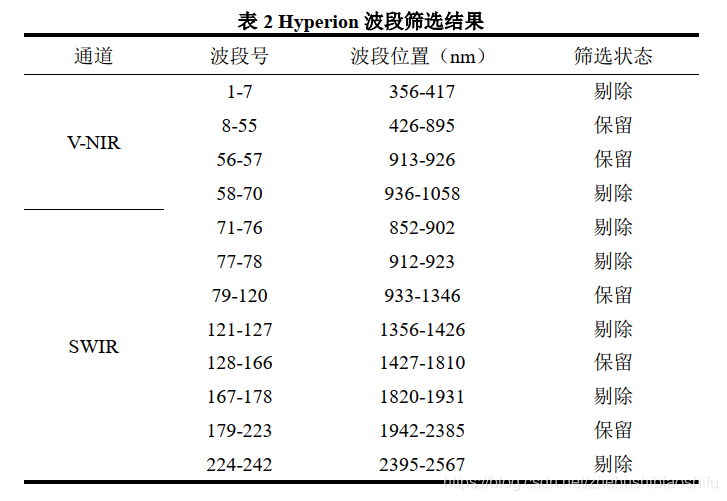
此外,除上述因未定標和水汽吸收影響被剔除的波段外,還包括壞線、條紋與「Smile」效應等非正常像元。其中,壞線是指一行或一列DN值為零或非常小的像元;條紋是指像元DN值不為零但較小,與周圍有明顯差異的帶狀現象;「Smile」效應是指由於前期光譜定標而產生的光譜差異。若對定量遙感結果精度要求較高,上述這些非正常像元或現象均需要在預處理階段加以解決。
目前,針對Hyperion產品影象的壞線處理主要通過均值鄰域法,即用壞線周圍的像元畫素值求平均後替換壞線中的畫素——這依賴於壞線像元與周圍像元的高度相關關係;若當壞線出現在地形比較複雜的區域,採用這種方法則會導致處理結果精度較低。
對此,有國內學者提出了一種基於地物型別的壞線修復方法。該方法假設各波段影象成像在一瞬間完成,或成像過程中天氣未發生變化,則不同波段影象中同一類地物的DN值應當相同。當某一波段的影象A的地物M出現部分壞線時,搜尋另一對應位置無壞線的波段對應的影象B,確定B中M位置對應的DN值α;隨後繼續在B中搜尋,找到所有DN值為α的像元N。隨後返回A,求取A中N像元對應位置的DN值,將其求平均後作為M位置處的DN值。這一壞線修復方法大大縮小了修復結果與真實值之間的均方根誤差,效果較好。
條紋尤多出現於SWIR波段,其嚴重影響影象質量;因此,條紋去除同樣十分重要。針對這一問題,有學者提出了一種全域性去除條紋的方法。其原理公式如下:
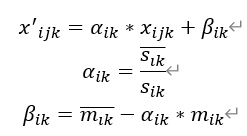
其中,〖x^'〗_ijk為第k波段對應影象第i行,第j列畫素校正後的數值,x_ijk為其原值;s_ik為第k波段對應影象第i列標準差,m_ik為第k波段對應影象第i列平均值,(s_ik ) ̅與(m_ik ) ̅分別為第k波段對應影象第i列標準差與平均值的對應平均值。實際計算時,用整幅影象的平均值與標準差代替每一列的平均值與標準差。
針對條紋去除結果的檢驗,可以利用最低噪聲分離旋轉(Minimum Noise Fraction Rotation,MNF)轉換加以實現。
「Smile」效應是指在垂直飛行方向上,像元的波長隨著影象中心位置向兩旁移動,產生的偏移。其中,V-NIR波段的「Smile」效應較為明顯,約在2.6至3.6納米範圍內;SWIR波段的這一效應表現則不如前者明顯,其約在0.40至0.97納米範圍內。「Smile」效應同樣可以藉助光譜資訊的MNF轉換加以檢測。「Smile」效應往往會對植被遙感產生影響;可以通過大氣糾正來降低「Smile」效應的影響。
Hyperion產品Level 1資料以有符號的整型資料格式記錄其資訊,數值範圍為-32768至32767;而實際地物輻射數值都比較小,如V-NIR波段最大輻射約為750 W/m2/sr/Lm,而SWIR波段最大輻射僅有350 W/m2/sr/Lm。因此,在產品生成時,系統採用了擴大因子,即分別將V-NIR與SWIR所對應波段的數值擴大為40和80倍。出於這個原因,在應用Hyperion產品Level 1資料時,需要將像元值轉換為絕對輻射值。其中,兩通道對應波段的計算公式有所不同:

其中,L_ℷVNIR為V-NIR波段定標後的絕對輻射值,L_ℷSWIR為SWIR波段定標後的絕對輻射值。
此外,在計算時需要注意,由於經過波段篩選後的影象波段不再完全連續,會出現一些間段區域。因此需要首先將同一通道內波段編號相連的波段合併,再將同一通道內全部波段合成;第二次合成後,將兩個通道對應的波段分別帶入上述兩個公式,計算結束後再將兩個通道的176個波段最終合成為一幅影象。
編輯標頭檔案時,除需注意中心波長的修正外,還要注意半高寬(又稱半峰全寬,Full Width at Half Maxima,FWHM)的輸入。若不進行大氣校正或進行大氣校正但不採取FLAASH大氣校正方法,則無需匯入FWHM這一引數。
需要注意的是,本文重點在於Hyperion的反演操作,因此上述Hyperion影象的壞線修復、條紋去除等處理暫未寫入本文。具體操作我將在後期的部落格中展現。
1.2.2 遙感影象分類方法
本文使用監督分類(又稱訓練分類,Supervised Classification)方法提取影像中各個不同地物部分,尤其是太湖湖面水體區域。而和前期部落格一致,本文的監督分類部分依然藉助ERDAS軟體,選擇採取平行六面體規則(Parallelepied)這一非引數規則(Non-parametric Rule)與最大似然規則(Maximum Likelihood)這一引數規則(Parametric Rule)加以實現;並且嘗試了特徵空間規則(Feature Space)的效果。
監督分類是指在已掌握有足夠先驗知識(亦即訓練場地)的情況下,根據已有訓練場地提供的已知屬性樣本選擇特徵引數,並訓練、建立得到對應判別函數;隨後進而將影象未知類別部分的畫素的值代入建立得到的判別函數,依據所選擇的不同判別準則,對該樣本所屬的地物類別進行自動分類處理;即監督分類是一種利用已知地物屬性、資訊,進而對未知屬性地物進行分類的方法。
正如上述內容所提到的,常用的監督分類判別規則包括非引數規則與引數規則兩個部分。其中,非引數規則包括特徵空間規則與平行六面體規則;引數規則則包括最小距離規則(Minimum Distance)、馬氏距離規則(Mahalanobis Distance)、最大似然規則以及波普角規則(Spectral Angle Mapper)等多種。
ERDAS IMAGINE 2015軟體中「Supervised Classification」模組可以選擇的規則十分齊全。本次我們依然運用這一模組,並選擇採取平行六面體規則與最大似然規則加以實現。平行六面體規則是指:根據訓練樣本的影象亮度值,形成一個N維的平行六面體資料空間;其餘像元的光譜數值如果落在平行六面體任何一個訓練樣本所對應的區域,其就被劃分至這一對應的類別中。其中,平行六面體的尺度是由標準差閾值所確定的,而該標準差閾值則是根據所選類的均值求出。最大似然規則是指:假設每一個波段的每一類統計都呈正態分佈,並計算給定像元屬於某一訓練樣本的似然度;隨後,像元將最終被歸併到似然度最大的一類樣本當中。
另一方面,遙感影像處理也可使用非監督分類(又稱聚類分析或點群分類,Unsupervised Classification)加以完成。非監督分類方法是在多光譜影象中搜尋、定義其自然相似光譜叢集的過程,其不必針對影像地物獲取先驗知識,僅依靠影像中不同類地物的光譜(或紋理)資訊進行特徵提取,再統計特徵的差別,從而達到分類的目的;最後對已分出各個類別的實際屬性進行確認。
1.2.3 大氣校正
本次實驗可以不進行大氣校正;但不經過大氣校正,由於未消除大氣影響,會使得得到的結果會有一定誤差。本實驗中,我們首先不進行大氣校正,對葉綠素加以反演;隨後再先後嘗試FLAASH大氣校正與QUAC快速大氣校正兩種方法,對得到的高光譜遙感影像加以處理,從而對葉綠素反演精度加以提升。
大氣層是介於衛星感測器與地球表層之間的一層由多種氣體及氣溶膠組成的媒介層,其由下至上可依次分為:對流層(0至8-18千米)、平流層(8-18至50-55千米)、中間層(50-55至80-85千米)、電離層(又稱熱層,80-85至800千米)、散逸層(800至3000千米)。在太陽輻射到達地表再到達衛星感測器這一過程中,輻射兩次經過大氣,故大氣對太陽輻射的作用影響較大。
大氣校正的目的即消除大氣和光照等因素對地物反射的影響,廣義上講是獲得地物反射率、輻射率或地表亮度溫度等真實物理模型引數,狹義上講是獲取地物真實反射率資料。大氣校正可以用來消除大氣中水蒸氣、氧氣、二氧化碳、甲烷和臭氧等物質對地物反射的影響,也可以消除大氣分子和氣溶膠散射的影響。在大多數情況下,大氣校正也是反演地物真實反射率的過程。
有時可完全忽略遙感資料的大氣影響。對某些地物分類和變化檢測過程(如用最大似然法對單時相遙感資料進行分類)而言,只要影像中用於分類的訓練資料具有相對一致的尺度(即均經過或未經過大氣校正),大氣校正並不是必需的;而當訓練資料需要進行時空拓展時,其影像分類和各種變化檢測則需進行大氣校正。
而對於涉及定量遙感的應用方面,如前期部落格所進行的地表真實溫度反演運算,大氣校正則多是必不可少的環節。有研究指出,是否進行大氣校正過程,對植被稀少或植被被破壞地區的NDVI計算誤差影響可達50%。
大氣校正方法整體上可以分為兩類:一是絕對大氣校正方法,即將遙感影象的DN值轉換為地表反射率、地表輻射率、地表溫度等數值的方法;二是相對大氣校正方法,即將原始的DN值校正為不考慮地物實際反射率情況下,相同DN值代表相同地表反射率的格式的結果。在此其中,常用的絕對大氣校正方法包括基於輻射傳輸模型方法(其中包括MOR/DTRAN模型、LOWTRAN模型、ATCOR模型、5S模型、6S模型等)、基於簡化輻射傳輸模型的黑暗像元方法、基於統計學模型的反射率反演方法等;常用的相對大氣校正方法包括基於統計的不變目標方法、直方圖匹配方法等。針對上述繁多方法的選擇,當進行精細的定量遙感研究時,需要採用基於輻射傳輸模型的大氣校正方法;當進行動態監測研究時,可採用相對大氣校正或簡單的絕對大氣校正方法;但所知引數較少時,則只能選擇相對簡單、對引數要求較少的方法。
本文采用FLAASH大氣校正與QUAC快速大氣校正兩種方法。
FLAASH大氣校正是一種絕對大氣校正方法,其適用於多光譜資料與高光譜衛星影像資料,能夠精確補償大氣對輻射的影響。這一方法採用 MODTRAN4+ 輻射傳輸模型,需要輸入地表反射率,通過影像畫素光譜中的特徵估計大氣屬性,可以有效去除水蒸氣、氣溶膠散射等效應帶來的干擾,精度較高。而另一方面,通過部落格1可知,FLAASH大氣校正方法同樣對待處理資料有著一定嚴格的要求,例如需要資料的儲存結構為「BIP」或「BIL」模式,像元值型別為經過定標後的輻射亮度(即輻射率)資料,資料單位為(μW)/(cm2nmsr)等。這需要我們針對原始資料加以一定處理。
QUAC快速大氣校正自動從影象中收集不同物質的波譜資訊,獲取經驗值,從而完成高光譜和多光譜的快速大氣校正。這一大氣校正方法只可以對多光譜、高光譜影象進行處理。
值得一提的是,FLAASH大氣校正與QUAC快速大氣校正兩種方法得到的結果均為擴大了10000倍的反射率資料。
1.2.4 反演演演算法
獲得太湖水體區域多個樣點的高光譜資料曲線後,分別對其加以一階微分處理與倒數對數處理。
本文中,針對太湖水體葉綠素a含量的估計,首先採用常見文獻中已給出的模型與引數:
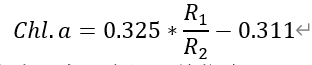
其中,Chl.a為水體葉綠素a含量,單位為(mg/L);R_1與R_2為兩個特徵波段,R_1為近紅外波段的反射峰,R_2為紅光波段的吸收谷,二者需要通過光譜曲線加以求取;0.325與0.311為兩個經驗模型引數。一般地,特徵光譜曲線其可以依據實測水體葉綠素a含量與光譜數值,通過計算二者相關係數隨著對應波長變化而變化的關係,從而加以確定;而經驗引數則是依據選擇出的特徵波段,通過迴歸分析等擬合手段求出。這一建立模型的正演過程本次我們不做討論。
另一方面,由於所獲取的高光譜資料可能會受到背景噪聲影像,且相似光譜之間因存在明顯共線性而導致資訊冗餘,我們還可以對光譜資料加以一定預處理,從而消除上述噪聲,突出光譜特徵。往往使用光譜一階微分、光譜倒數對數與光譜包絡線去除等方式加以處理。其中,光譜包絡線去除可以方便地在ENVI軟體中實現。我們本次採取光譜一階微分、光譜倒數對數方法。
光譜一階微分可以去除部分線性或接近線性的背景,以及噪聲光譜對目標光譜的影響。光譜一階微分計算公式如下:
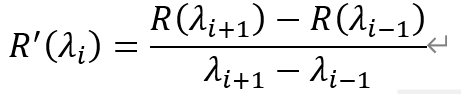
其中,R^' (λ_i )為波段λ_i對應的一階微分數值,R(λ_i )為波段λ_i原本數值,λ_(i+1)為對應波段中心波長。
在光譜定量分析中,光譜倒數對數可以十分有效地增強相似光譜之間的差別;計算如下:
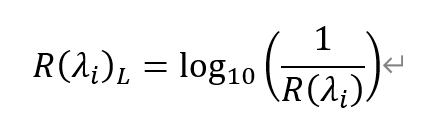
其中,〖R(λ_i )〗_L為波段λ_i對應的倒數對數數值,R(λ_i )為波段λ_i原本數值,λ_i為對應波段中心波長。
此外,包絡線去除法亦是一種常用的光譜分析方法,其可以有效地突出光譜曲線的吸收和反射特徵。但我們在此不做討論,後期我會專門寫一篇部落格討論這一內容。
除水體葉綠素a含量反演外,利用高光譜資料反演地表沉積物顆粒度引數同樣被學者們加以廣泛研究。有學者藉助Hyperion遙感影像,分別建立一個單波段因子與四個多波段組合因子;利用光譜包絡線去除方法,挑選出與顆粒度引數相關性較高的幾個特徵波長,並選用穩定性更高、整體更簡單的線性迴歸模型作為最終的引數反演模型。以平均粒徑這一引數為例,具體反演計算模型如下:
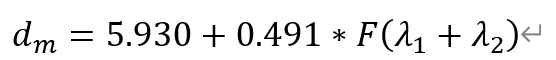
其中,d_m為平均粒徑,F為特徵波段的運算函數,λ_1與λ_2分別為所選擇的兩個特徵波段。其中,
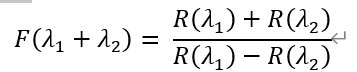
同時,本次土壤有機質含量反演模型採用如下公式:
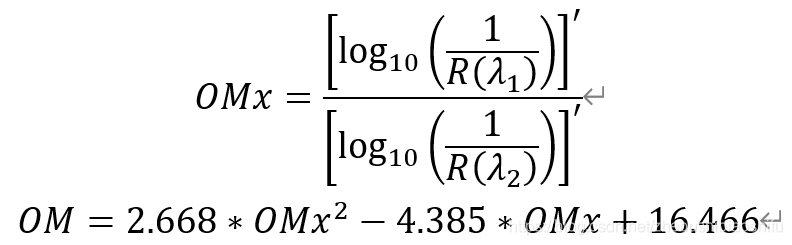
其中,OM為土壤有機質含量。
2 基於經驗比值法、一階微分法的葉綠素a含量反演
首先,在未進行大氣校正的情況下,我們基於經驗比值法、一階微分法,對葉綠素a含量加以反演。
2.1 資料匯入與波段合成
(1) 將資料中「EO1H1190382004095110KZ.tgz」影象壓縮包檔案解壓縮;開啟ENVI Classic 5.3(64-bit)軟體,選擇「File」→「Open Image File」,在彈出的檔案選擇視窗中分別選中壓縮包中字尾名包括8至57的50個「.tif」格式檔案;點選「開啟」。
(2) 選擇→「Layer Stacking」,在彈出的檔案選擇視窗中選擇開啟的50個波段影象。

(3) 選擇後,需要觀察六幅影象在待合成檔案列表中的排列順序。由於後期我們需要對合成後的影象各個波段的資訊進行折線圖形式的分析操作,因此需要將待合成檔案按照「中心波長值」由小至大的順序排列。點選「Reorder Files」即可實現這一功能。
(4) 結合本文開頭提到的三篇部落格可知,由於匯入「Layer Stacking」模組的波段往往是倒序排列,這使得幾十個波段的合成排序操作變得較為複雜——需要進行排序操作百餘次。因此本次嘗試再將檔案匯入ENVI軟體時就採取倒序匯入的方式。但隨後發現即使這樣操作,也會使得順序列表中的波段倒序排列。


(5) 順序排列完畢後,檢查投影資訊等無誤後,點選「OK」即可開始合成操作。
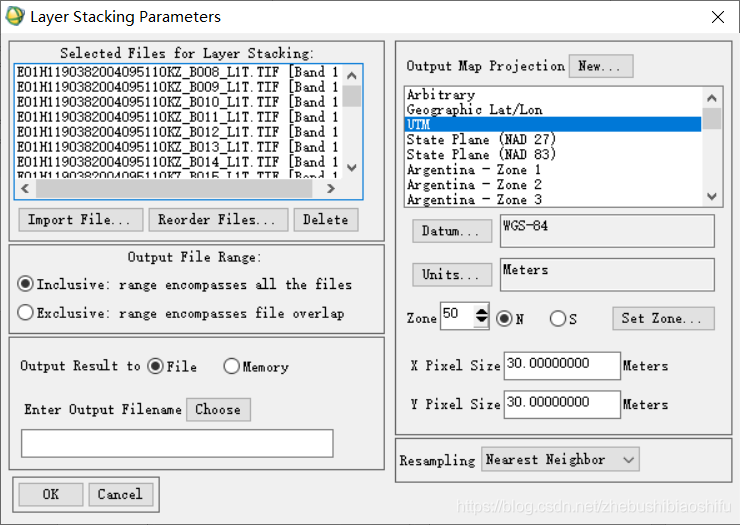
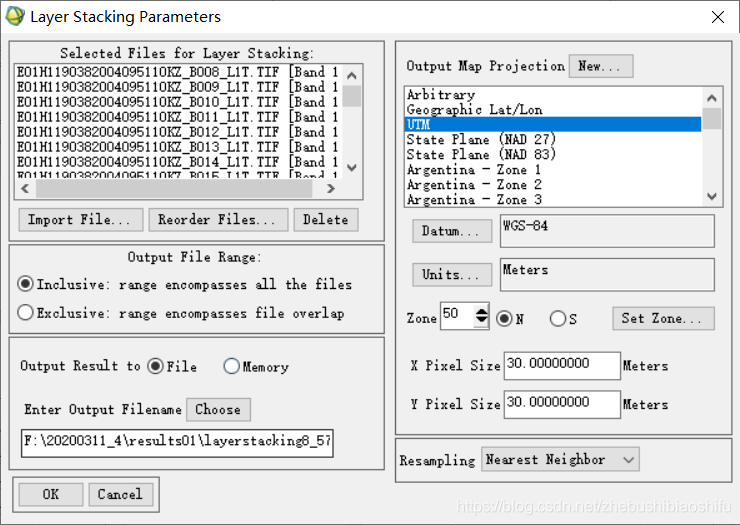

(6) 多次重複這一過程,直至將同一通道內全部波長編號相連的影象各自拼接。
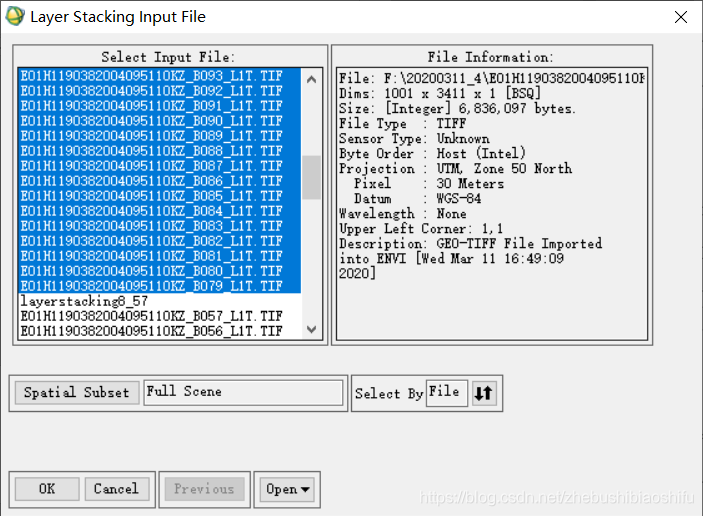

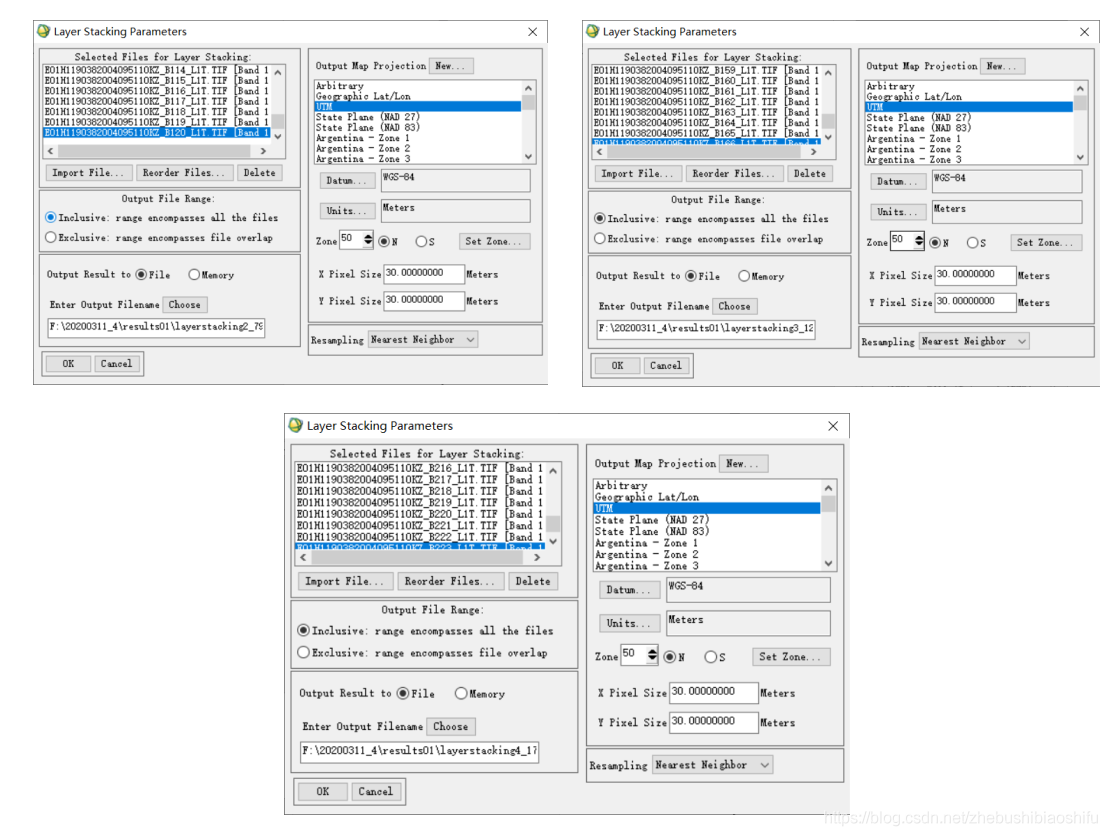
(7) 四個波合成後,將SWIR通道對應的三個一次合成後的影象再一次合成。
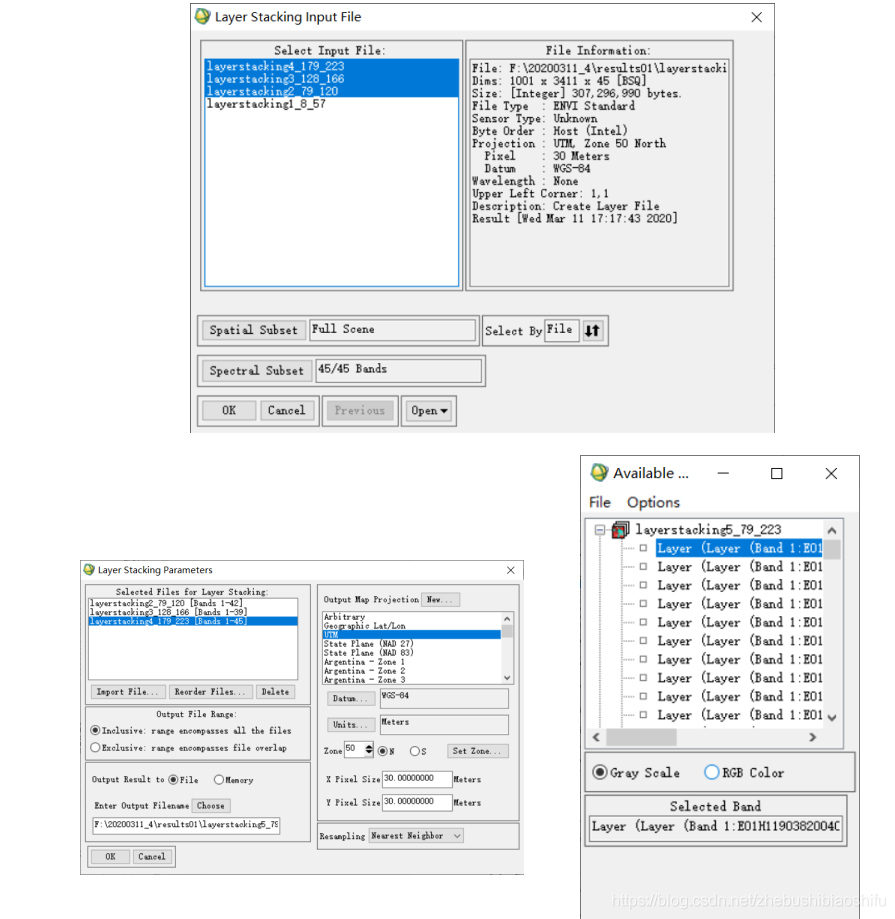
2.2 輻射定標與波段合成
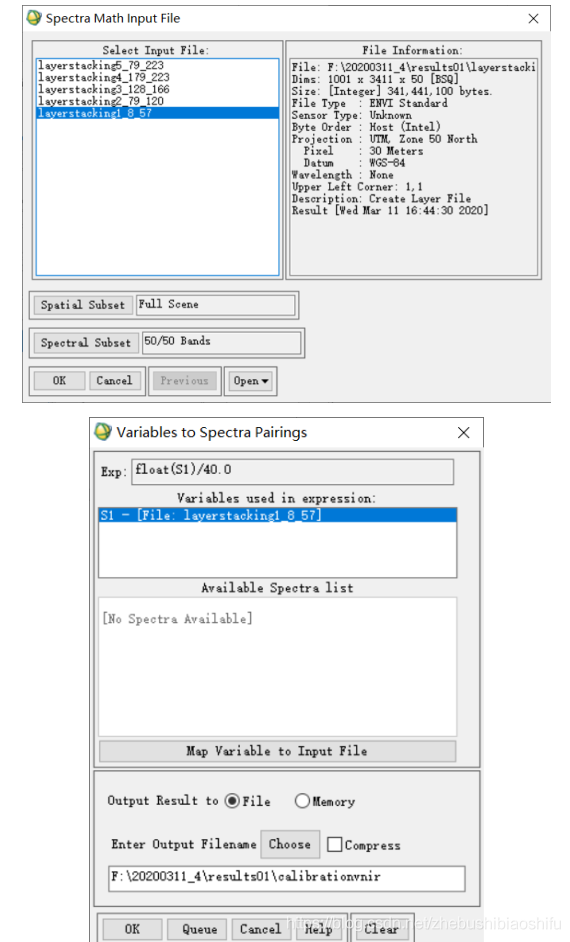
(1) 選擇「Basic Tools」→「Spectral Math」,在彈出的公式建立視窗中輸入本次實驗的兩個輻射定標公式;輸入單個公式完成後,點選下方「Add to List」按鈕,即可將鍵入的公式存入待選擇區內。為了減少後期不必要的工作量,可以在編輯完成每一公式後點選「Save」按鈕,並將最近一次儲存的同一公式檔案覆蓋,以將待選擇區內的兩條公式統一儲存。若直接選擇「Band Math」(如下圖)會導致無法對各波段實現簡單的批次操作。

(2) 儲存公式完成後,點選左下角「OK」按鈕,即可開始公式的計算。在彈出的公式變數檔案選擇視窗中,將這一公式的變數「S1」選擇為我們通過上述操作生成、新增的影象檔案「layerstacking1_8_57」,並將第二個公式的變數「S1」選擇為同樣通過上述步驟獲得、新增的影象檔案「layerstacking5_79_223」。隨後,設定對應兩個定標輸出檔案地址等資訊。
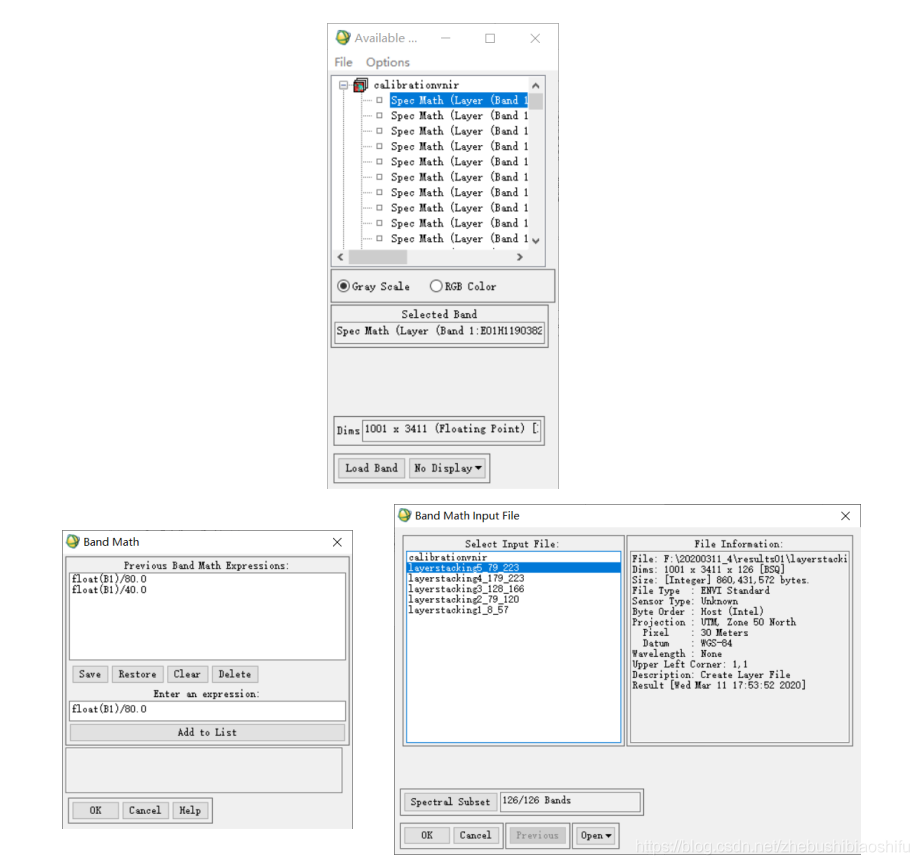
(3) 設定完成後,點選左下角「OK」按鈕,即可開始公式的執行。執行結束,將所得到的研究區兩幅輻射定標結果影象匯入ENVI軟體中,顯示如下。

(4) 由兩幅圖各自的光譜曲線可以看出,V-NIR波段數約為50個,SWIR波段數約為120個。這與我們通過上述波段合成得到的波段數分別為50個、126個的兩幅影象相符合。
(5) 再次執行上述波段合成操作,將V-NIR波段影象與SWIR波段影象合成。
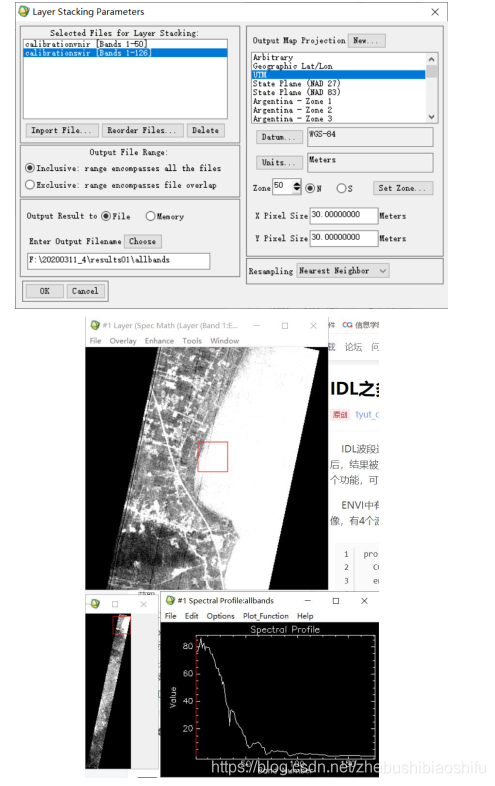
(6) 通過本次波段合成,可以看到得到的結果影象包含了V-NIR波段數50個,SWIR波段數126個。
2.3 編輯標頭檔案
(1) 由於在選擇波段合成範圍時,我們去除了一些「壞波段」,因此合成後的影象中心波長、FWHM等資訊均丟失,需要重新將其匯入。考慮到176個波段數量較大,我們可以採取Excel資料匯出的方式將其填入ENVI影像中。
(2) 首先在Microsoft Office Excel軟體中開啟原始遙感影像資料資料夾中的「Hyperion_Spectral_Coverage.xls」檔案。這一表格檔案為我們列出了Hyperion產品Level 1資料242個波段的相關資訊,包括波段編號(Hyperion Band)、平均中心波長(Average Wavelength)、FWHM等屬性資料。
(3) 將我們最終定標、合成後的176個波段對應的上述三種屬性資料匯入到一張新的表格中,並匯出為TXT檔案。其中需要注意,將V-NIR波段與SWIR波段重疊部分的資料剔除。

(4) 其次在「Available Bands List」檔案列表中右鍵選擇波段合成後的結果檔案,選擇「Edit Header」功能。
(5) 選擇「Edit Attributes」→「Wavelengths」,將TXT檔案匯入,並注意將資料單位修改為「Micrometers」。
(6) 此時再次開啟上述操作編輯標頭檔案完畢的176個波段的影象,可以看到光譜曲線中橫座標已經由原先的1至176轉變為對應波段的中心波長數值範圍。

2.4 影象格式轉換
經過ENVI處理後,得到的結果影象並不能直接被ERDAS軟體所識別,我們需要將其轉換為「.img」等格式檔案。
(1) 選擇「File」→「Save File As」→「ERDAS IMAGINE」,在彈出的檔案轉換選擇視窗中選擇經過波段合成與標頭檔案編輯後的結果影象,點選左下角「OK」。

(2) 在彈出的轉換檔案屬性設定視窗中設定,設定好結果影象檔案儲存路徑、儲存檔名等。
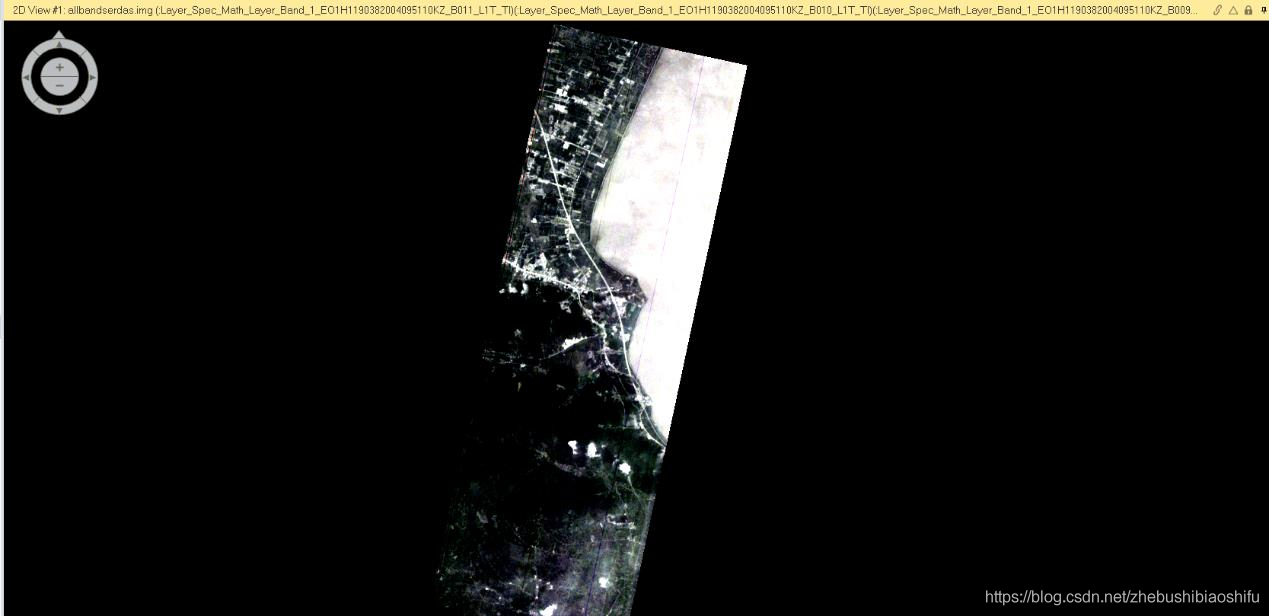
(3) 檔案格式轉換完畢後,即可將結果檔案在ERDAS軟體中開啟,並在其中進行後續操作。
2.5 EDRDAS檔案匯入與裁剪
通過上述步驟得到的「.img」格式檔案範圍為太湖區域加之其西南部大面積陸地區域,水體佔比並不多;而遙感影象整體區域面積較大,檔案資料量多;另一方面,我們的主要反演目標區域為太湖水體。因此,我們需要藉助自行劃定的AOI(Area of Interest)檔案,將原本的整體面積地區裁剪為太湖佔比較多的地區。
(1) 開啟ERDAS IMAGINE 2015軟體,在黑色圖層視窗區域右鍵,並選擇「Open Raster Layer」,在彈出的檔案開啟選擇視窗中選擇經過上述全部預處理後的「.img」結果影象,點選右上角「OK」。ERDAS軟體選擇檔案時,可以藉助「Recent」和「Goto」功能,選擇最近操作的資料夾路徑或檔案。
(2) 在影象中劃定一個合適的太湖AOI區域,使得全部太湖水體都包含在內。
(3) 選擇「Raster」→「Subset & Chip」→「Create Subset Image」,在彈出的檔案裁剪設定視窗中選擇上述「.img」結果影象,設定輸出檔案路徑和檔名,並選擇輸出影象檔案格式為「Float Single」,在下方「AOI」選項中選擇「Viewer」,點選左下角「OK」選項。這樣即可以剛剛劃定的AOI區域為裁剪範圍。

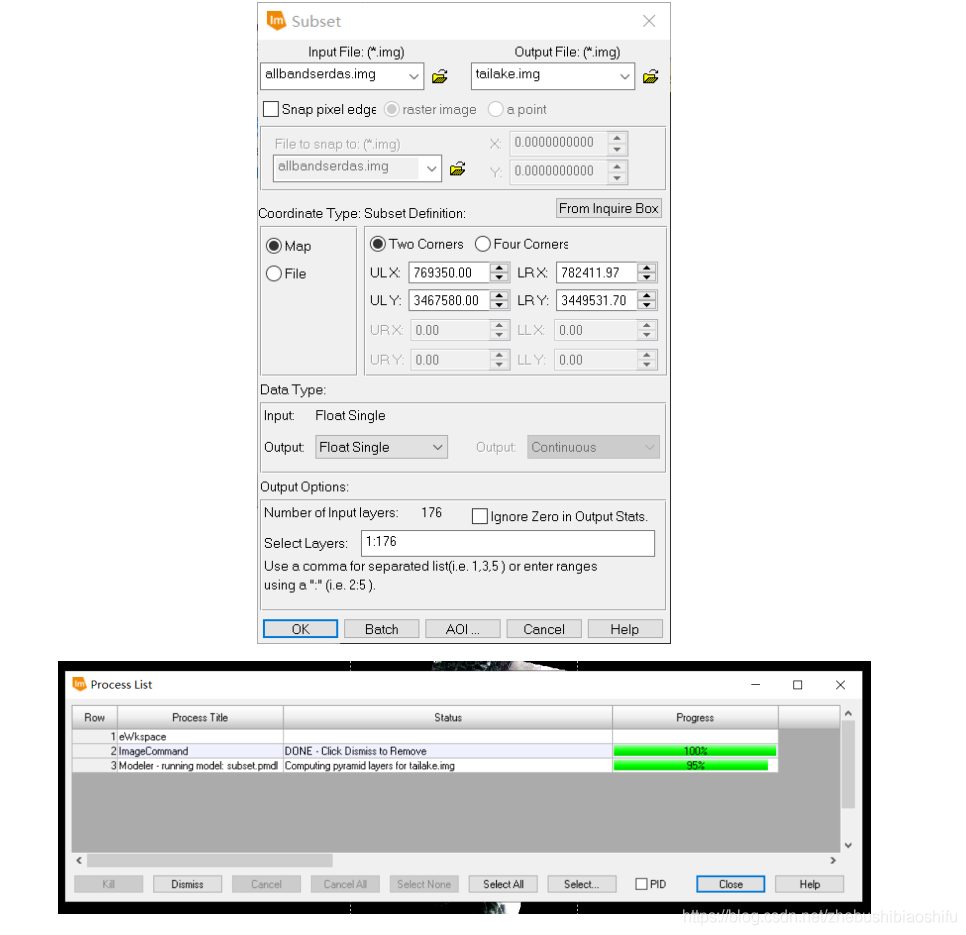
(4) 觀察得到的結果影象,若對其直方圖加以分析可發現,影象中存在大量數值為零的像元。其實這樣並不是影象出現錯誤,而是在傾斜長方形影象周圍區域實際上仍為影象所包括的區域,這些大量黑色的畫素數值為0,使得直方圖出現零值。
2.6 監督分類
如本文第一部分原理所述,本次實驗我們依然利用監督分類方式區分太湖水體、其他水體與其它土地,從而實現更加精確的太湖區域提取。監督分類依然在ERDAS中實現。
(1) 選擇「Raster」→「Supervised」→「Supervised Editor」,在彈出的AOI區域顯示錶中可以看到,此時還沒有新增進入任何AOI,表格中處於空白狀態。
(2) 分別依據太湖水體、其他水體與其它土地,在影象中劃定區域。每一種地表型別需要劃出儘可能多的AOI,以期提高最終監督分類的效果與精確度。
(3) 每劃定一個AOI,便新增進入「Supervised Editor」中;同一地物型別的AOI新增完畢後,對這一型別的全部AOI加以合併,並賦以一個易於辨認的Value值。
(4) 其中,可以藉助衛星地圖影像對具體地物類別加以具體區分。但應注意,我們所使用的遙感影像為2004年的資料,而衛星影像資料成像時間相對較為接近我們現在的時間。因此,利用衛星影像亦只可以作為一種參考。
(5) 另一方面,亦發現無論是採用灰度影象還是選擇三個波段分別作為R、G、B的值,在「Supervised Editor」中顯示的顏色都是一致的,即原有的灰度影象。這一特點與前幾次的多光譜部落格有所差距,或許為高光譜影像的特徵之一。

(6) AOI劃分完畢後,儲存。選擇「Raster」→「Supervised」→「Supervised Classification」,在彈出的監督分類設定視窗中設定輸入檔案、輸出檔案與用於指定區域地表型別的AOI檔案。

(7) 得到的監督分類結果如下。其中,選擇了採取平行六面體規則這一非引數規則。可以看到,由於三種地類分類顏色相近,具體的分類結果需要放大後才可以看清。
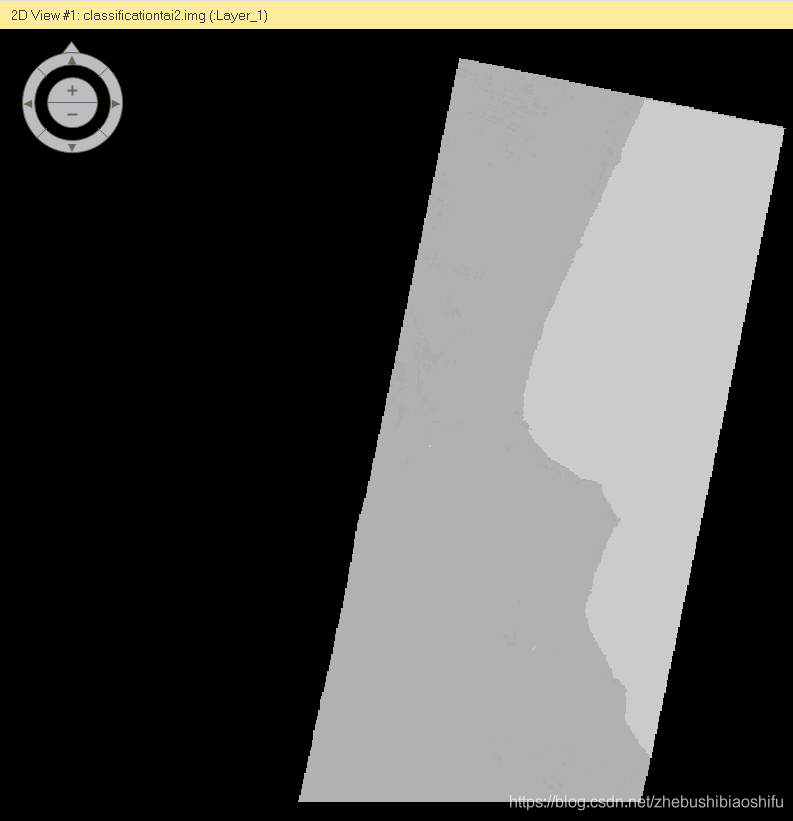

(8) 下圖中,左圖則是採用特徵空間規則這一非引數規則加以實現的監督分類結果。二者對比可以看出,右側的平行六面體規則分類效果明顯優於左側。

2.7 水體光譜曲線提取
(1) 利用「Inquire」模組,分別選取太湖水體中20處不同位置,並上述位置對應的各波段光譜數值匯入Excel表格中,作為我們觀察特徵波段的基礎。
(2) 在進行這一步驟時,需要注意在ERDAS軟體左下角有一個百分比顯示區域。由於176個波段數量較多,資料在複製過程中會有些卡頓;藉助百分比顯示狀態即可看出複製進度。



2.8 特徵波段選取與計算
(1) 將20個取樣點的光譜曲線匯入Excel軟體後,利用本文第一部分原理中的公式計算對應光譜數值的一階微分與倒數對數。並將得到的結果製圖。以下三幅圖分別為光譜原始數值、一階微分與倒數對數對應影象。
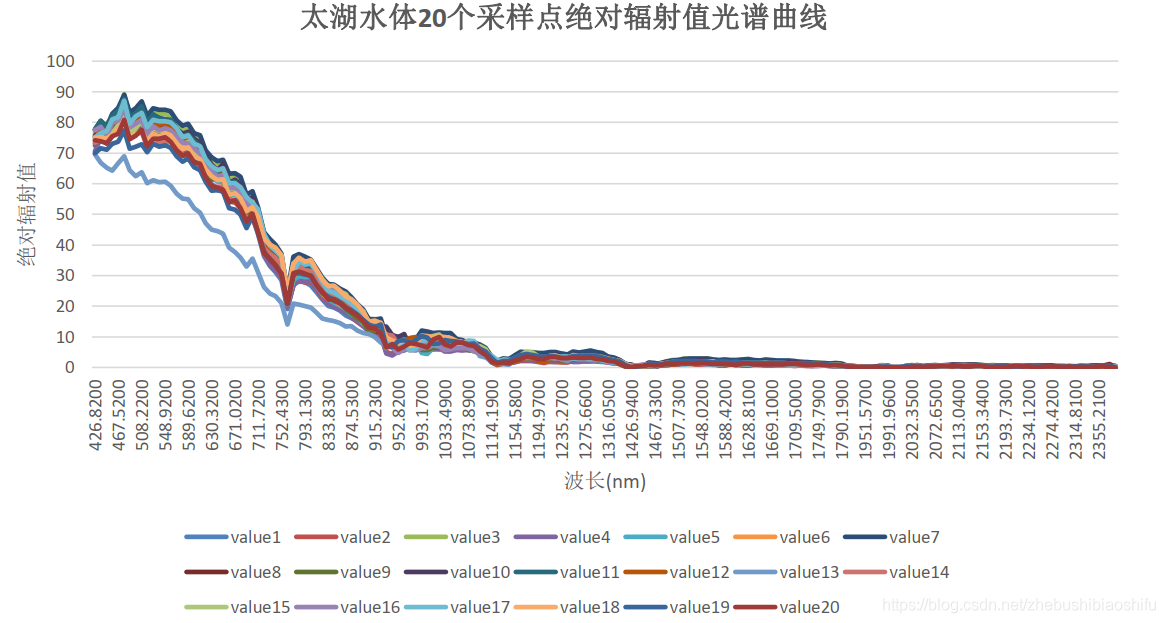
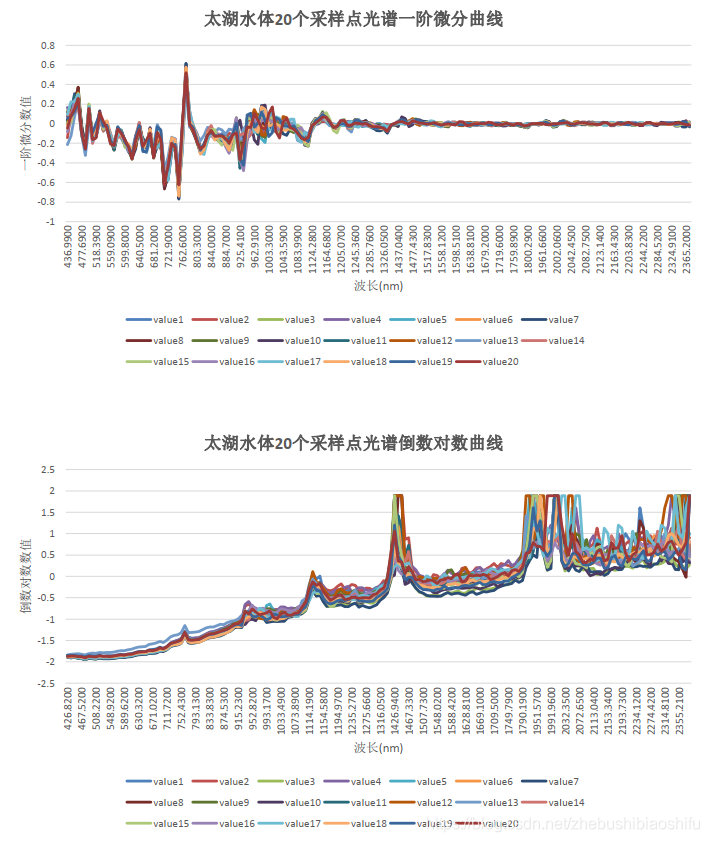
(2) 依據以上三幅光譜曲線,我們可以從中選取特徵波峰或波谷,並將其帶入經驗公式中。
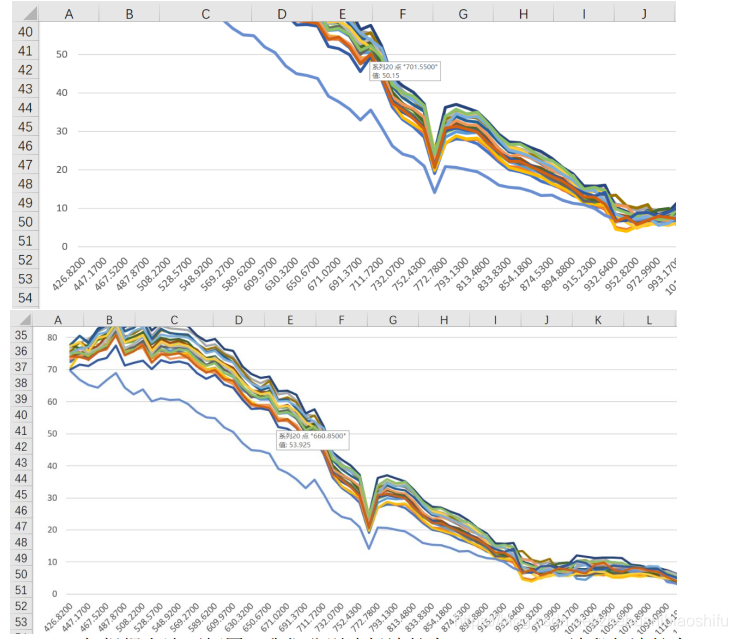
(3) 如根據上述兩幅圖,我們分別選擇波長為701.5500nm波段與波長為660.8500nm波段。如本文第一部分所示,將其帶入文獻中所展示的經驗比值模型。
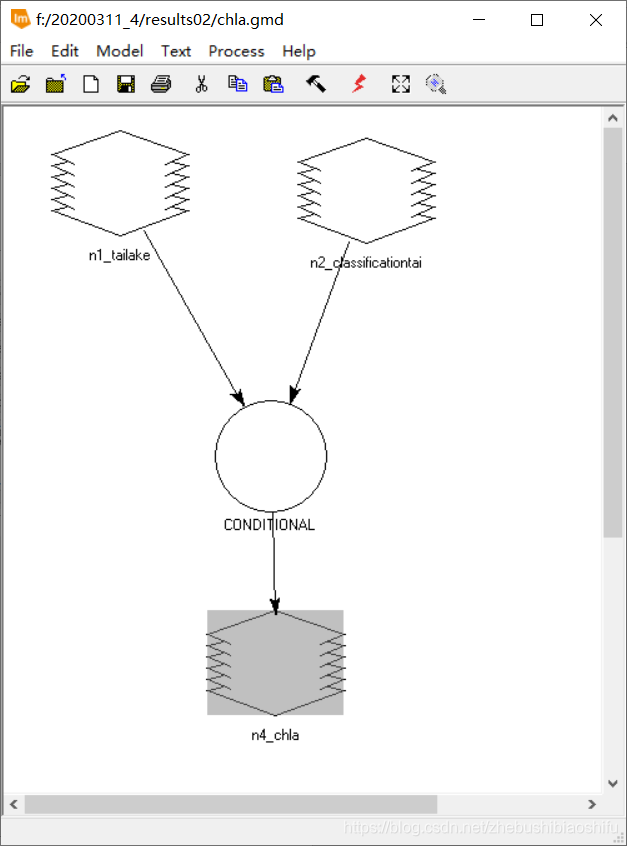
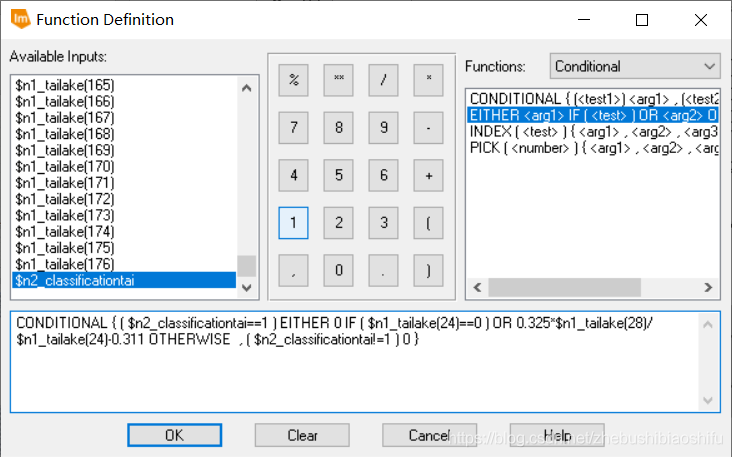
(4) 選擇「Toolbox」→「Model Maker」→「Model Maker」,在彈出的New_Model視窗中設定模型。
(5) 經過上述ERDAS建模過程,我們得到依據經驗比值方法計算的太湖水體葉綠素a含量反演結果影象。可以看到,影象中出現大量負值。這是由於我們直接選用了文獻中的引數,且原始影象未經過大氣校正造成的。

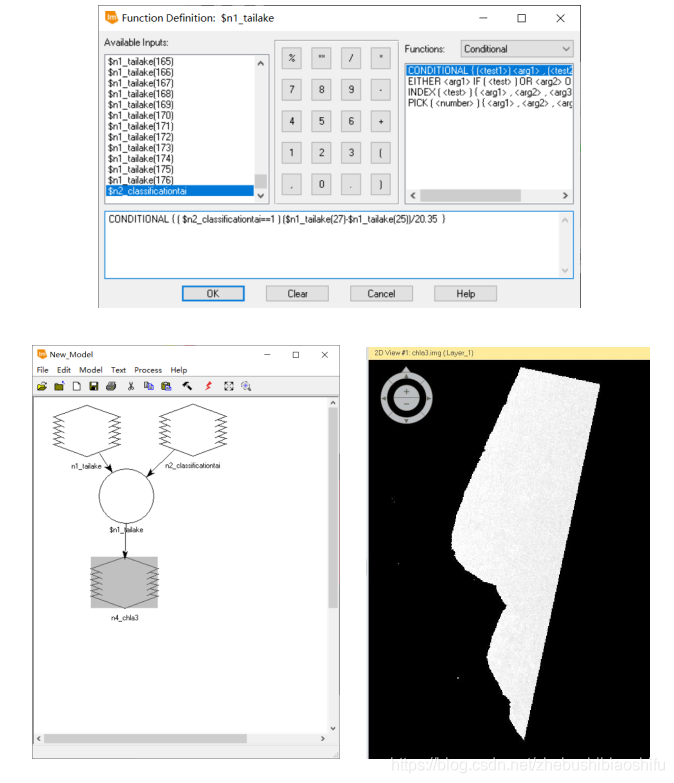
(6) 此外,依據上述近似的思路,利用光譜的一階微分數值計算太湖水體葉綠素a含量。其中,本次所選擇的一階微分處理特徵波段分別為波長為691.3700nm與671.0200nm的兩個波段。
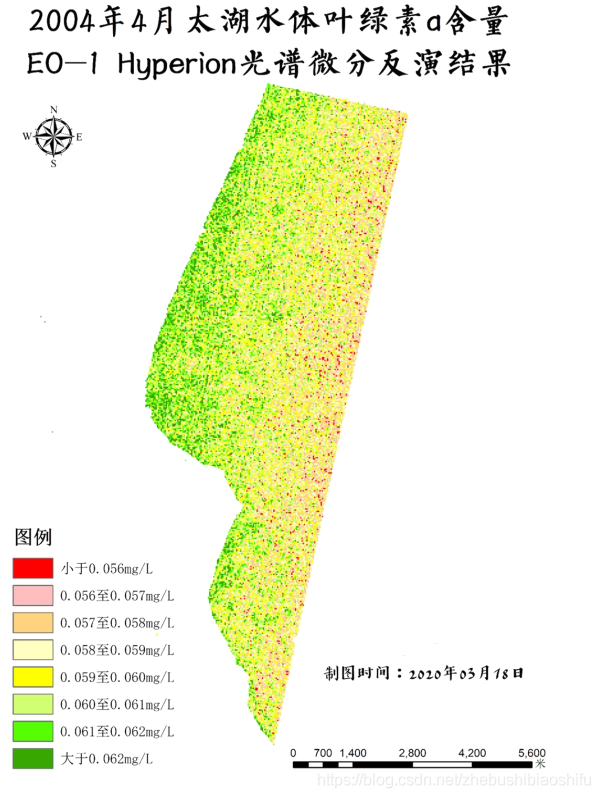
(7) 分別將以上兩幅經驗比值法、一階微分法計算得出的葉綠素a含量結果製作為專題地圖。上述經驗比值法計算得到結果存在較多負值,故此處暫不展示其專題地圖——大家繼續往後看即可。
3 大氣校正及經驗比值法波段調整
由以上結果可知,不進行大氣校正,所得葉綠素a含量反演結果精度較低,甚至經驗比值法計算得到結果存在較多負值,肯定是不對的。因此,這一部分我們基於以下兩個方面,對葉綠素a含量反演精度加以提升:
-
進行大氣校正;
-
對出了問題的經驗比值法所選用的波段加以調整。
3.1 轉換檔案資料格式
(1) 選擇「Basic Tools」→「Convert Data (BSQ,BIL,BIP)」,在彈出的檔案選擇視窗中選擇經過波段合成、編輯標頭檔案操作後的結果影象,點選「OK」。

(2) 調整為「BIL」資料儲存格式後,即可使用該影象檔案進行FLAASH大氣校正。
3.2 FLAASH大氣校正
(1) 選擇「Basic Tools」→「Preprocessing」→「Calibration Utilities」→「FLAASH」,在彈出的轉換因子視窗中選擇第二項,即單一因子適用於所有波段的情況。由於我們本次所使用資料原有光譜數值為絕對輻射值的標準單位,即(μW)/(cm2nmsr),這一單位為FLAASH方法所能利用的單位,故我們需要將轉換因子設定為1.00。
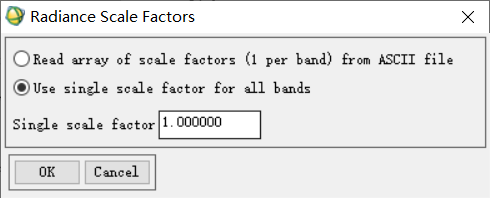
(2) 隨後彈出的設定對話方塊中,首先選擇輸入影象檔案、輸出影象檔案目錄及名稱,同時依據遙感影像的後設資料,設定其中心點經緯度、感測器型別(感測器型別一旦選定,系統將會自動匹配感測器高度與像元大小這兩個引數)、航行時間;同時依據實際研究區的情況,設定平均海拔高度這一選項;其次,選擇合適的地球大氣模型和氣溶膠模型。其中,地球大氣模型需要根據一張標準查詢表確定,氣溶膠模型則依據研究區域實際情況加以確定。設定FLAASH大氣校正引數如下。其中,Hyperion產品Level 1資料的航行時間、影象經緯度等後設資料可以通過解壓縮後的資料夾中「EO1H1190382004095110KZ_SGS_01.fgdc」檔案查閱。
(3) 接下來,選擇「Multispectral Settings」。當基本設定中設定了水汽反演模型和氣溶膠模型時,我們需要相應地將多光譜相關屬性加以設定,設定完畢後點選「OK」。
(4) 全部設定完畢後,可以點選右下角的「Save」按鈕,從而將本次對於FLAASH方法的全部屬性設定儲存;在後期若對同樣的遙感資料進行同樣的操作時,儲存屬性設定可以免去多次重複調整相關引數的工作,從而提高效率。
(5) 點選「Apply」,將會開始執行FLAASH大氣校正。但在開始前,將會彈出一個FWHM設定視窗。這是由於,FLAASH若針對高光譜影象加以執行,需要設定這一屬性。
(6) 通過與匯入中心波長相似的操作,我們將FWHM同樣通過Excel軟體與TXT檔案匯入。
(7) 隨後開始執行FLAASH大氣校正。但發現,FLAASH大氣校正執行一定時間後,總會出現未包含錯誤原因的報錯提示,並自動暫停執行過程。
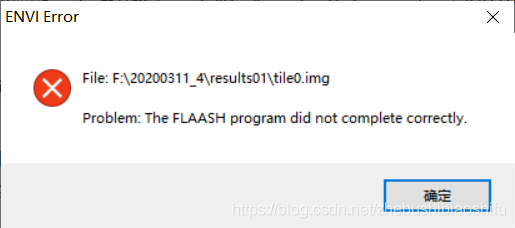
(8) 多次嘗試依據網路資源對FLAASH大氣校正引數加以調整,但這一問題依然存在。針對這一問題的分析附於下文3.4的(7)部分。
3.3 QUAC快速大氣校正
(1) FLAASH大氣校正無法執行後,嘗試使用QUAC快速大氣校正方法。選擇「Basic Tools」→「Preprocessing」→「Calibration Utilities」→「Quick Atmospheric Correction」,在彈出的檔案選擇視窗中選擇待處理影象檔案,點選「OK」。
(2) 得到結果影象檔案後,在其上任意位置處右鍵,選擇「Z Profile (Spectrum)」,檢視影象中任意位置對應波譜資訊。

(3) 將得到的QUAC快速大氣校正影象與校正前影象光譜曲線加以對比,可以看到針對地表植被,光譜曲線走勢更加符合植被特徵曲線,尤其是550nm附近的反射峰、670nm附近的吸收谷、700nm附近的吸收陡坡、900至1300nm附近的平緩趨勢等,QUAC大氣校正結果影象均有著較好的展現。
3.4 經驗比值法調整
(1) 通過ENVI軟體QUAC快速大氣校正後,嘗試將大氣校正後的結果影象重新帶入第一次未成功的經驗比值模型中,再一次計算這種方法得到的葉綠素a含量。

(2) 大氣校正後的結果影象為包括大部分非水體的原有範圍區域影象,因此需要對其加以重新裁剪、監督分類。
(3) 本次監督分類時,嘗試用不同R、G、B波段設定方式。隨後發現,若採用Hyperion產品的真彩色配色方式(29:23:16)得到的結果雖然更加符合實際情況,但其影象畫素之間變得較為難以識別,不利於監督分類。

(4) 另一方面,在重新進行監督分類時,發現總是會報出如下錯誤。多次嘗試,均無法避免。

(5) 因此,對輸入的QUAC大氣校正結果影象加以光譜曲線加以複製,並匯出到Excel軟體中驗證。

(6) 可以看到,上述光譜曲線在波長前一部分並無問題,而在930nm左右之後,其數值均不再發生變化。經過多次重複、嘗試,找到問題所在——由於波段合成、編輯標頭檔案、大氣校正等過程均在ENVI軟體中執行,因此使得輸出的檔名越來越長(ENVI軟體每完成一步光譜處理均會在原波段名稱前增添一個操作名稱單詞);而過長的ENVI檔名超出了ERDAS軟體的檔名識別上限,因此軟體將B57波段後的所有波段均識別為同一波段,造成錯誤。錯誤的影象如上頁最後一幅圖;下圖則為一幅未經過ENVI大氣校正而沒有產生這一問題的正常高光譜影象的波段資訊。

(7) Excel軟體中,可以清晰地看出由B79波段開始,所有光譜數值不再發生變化。之所以在B79波段開始出現這一問題,一定是因其為SWIR波段的第一個波段,而SWIR波段相較之V-NIR波段多經過一次ENVI軟體的波段合成(因為其額外需要由三組波段合成為一組);多經過一次ENVI操作,其名稱會多出一個英文單詞,從而出現這一問題。且由此分析,FLAASH之所以無法正常完成,亦是因為我是用ENVI進行影象預處理,使得波段名稱過長;而FLAASH執行過程中會生成很多新的臨時檔案,這些新檔案的波段命名方式應亦為在各波段前新增單詞,從而導致部分波段名稱中相互之間唯一不同的字元被「擠出」軟體可識別的名稱範圍,出現重名,導致FLAASH在執行過程中報錯。

(8) 因此,為解決經驗比值演演算法出現的葉綠素a含量為負數的問題,決定只得由第二個角度——特徵波段入手。因為我們直接運用文獻中推導的經驗比值模型引數,且特徵波段的選擇具有一定主觀性;因此特徵波段亦會影響最終結果取值。

(9) 多次觀察反射率光譜曲線,同時適當結合一階微分、倒數對數光譜曲線 ,以確定出新的特徵波段。
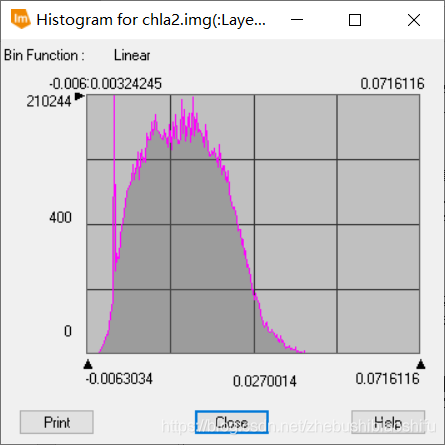
(10) 同樣利用ERDAS軟體,以期建立模型求出採用新特徵波段的葉綠素a含量。最終,確定出701.5500nm與691.3700nm這兩個特徵波段作為選定的波段。上述特徵波段確定的葉綠素a含量數值雖仍有小於0的部分,但已有很大改觀。
(11) 修正後的經驗比值模型求得的太湖水體葉綠素a含量專題地圖如圖所示(經過指正,以下這幅我的專題地圖有誤,大家所得結果可能與我的不太一樣,依據實際情況判斷即可)。同上述第一幅專題地圖一致,在製作時需要將影象中太湖周圍(即陸地部分)的0值轉為NoData。
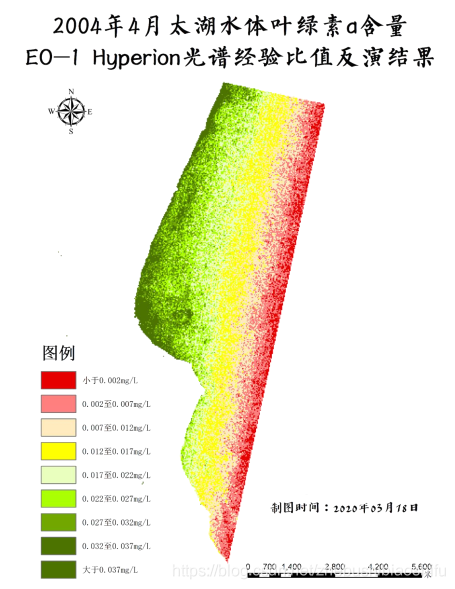
4 經驗比值法、一階微分法的葉綠素a含量反演結果對比
(1) 針對上述兩種水體葉綠素a反演演演算法得到的兩幅專題地圖,對比、分析如下。

(2) 其中,左側影象為經驗比值模型反演結果,右側影象為一階微分模型反演結果。
(3) 在取值範圍上,經驗比值結果取值分佈於0至0.040mg/L左右,一階微分結果取值分佈於0.020至0.065mg/L左右。依據文獻及實際情況,可以看到上述兩種方法得到的結果整體均偏小,尤其是缺少含量較高的數值(我國東部亞熱帶、溫帶內陸湖泊水體葉綠素a含量最大值往往可達0.110至0.120mg/L以上);其中,經驗比值得到的結果明顯小於一階微分結果,前者最大值甚至僅僅達到後者最小值左右的水平;且經驗比值結果中包含極少量負值畫素。由此可知,在數值方面,一階微分模型精度更高一些。當然,我們本次模型中常數引數均直接利用文獻給出的數值,而實際中這些引數的數值是需要依據地表水體實測葉綠素含量、各波段與葉綠素含量的相關係數等加以推導、驗證得出的,即上述取值範圍有很大一部分是由於引數選取並不是很準確導致的。
(4) 在分佈趨勢上,可以看到兩種方法得出的結果均符合「岸邊含量達到最高,水體中心含量相對最低,由岸邊至水體中心含量逐漸降低」這一情況。而不同的是,經驗比值得到的結果隨離岸距離的變化極其明顯,呈現由東北至西南方向的條帶狀分佈;甚至在太湖這一區域的西南部分,由於河岸向水體中心方向明顯延申,導致其隨亦是近岸區域,但反演得到的葉綠素a含量並沒有隨之升高——這樣的條帶狀分佈過於明顯,可能是由於未經處理的光譜曲線含有的噪聲或共線性過多,光譜的大氣影響等未很好消除而導致的。而一階微分得到的結果影象相對前者而言,其葉綠素a含量隨水體向內延伸而變化的幅度較小,並不是特別明顯。而兩幅圖中,葉綠素a含量最高和最低的區域則較為一致,均為西南圓弧狀岸邊處含量整體較高,東北部水域含量整體較低。
(5) 綜上所述,可以看出無論是在具體數值取值範圍上,還是在數值的空間分佈上,一階微分得到的結果相對較為真實。
5 其他探究內容
5.1 基於ENVI實現微分計算
(1) 在ENVI 5.3 (64-bit) 軟體中,可以藉助「deriv」函數實現光譜曲線的微分計算。
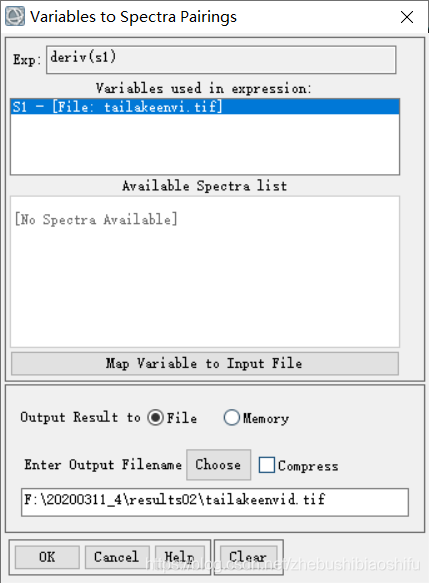
(2) 與經典版不同的是,ENVI 5.3 (64-bit) 軟體在編輯標頭檔案時有所變化,但整體步驟流程一致。此外,太湖區域的提取亦可以在ENVI軟體中通過剪裁實現。

5.2 水體表層沉積物平均粒徑反演
(1) 依據本文第一部分原理,反演計算太湖區域水體表層沉積物平均粒徑。
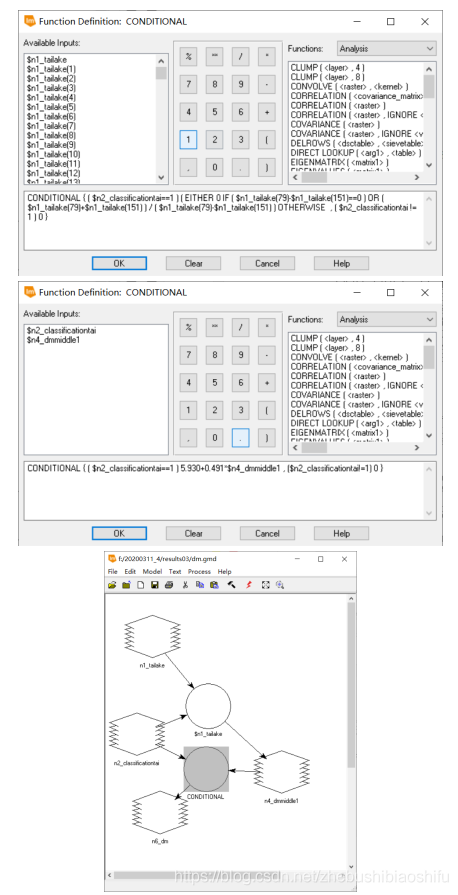
(2) 求出專題地圖。

(3) 由專題地圖可以看出,所求得的水體表層沉積物平均粒徑取值主要集中於6.0Ф以上;其結果影象中高值分佈區域與前期在做監督分類時採用的假彩色影象中太湖水體渾濁(即泛白色)位置(如下圖所示)十分一致,可見原本遙感影象中渾濁其實為水體中表層沉積物;沉積物平均粒徑越大,水體越渾濁。而上述結果中的條紋狀現象可能為特徵波段選取並不是很恰當,其間具有部分共線性導致的。

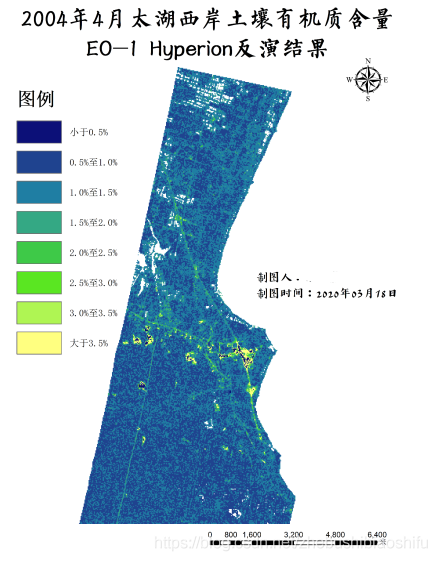
5.3 土壤有機質反演
(1) 依據文獻,利用兩個特徵波段各自倒數對數的一階微分的比值與土壤有機質含量的二次迴歸方程,經過同樣的建模、製圖過程,得出太湖周邊地區土壤有機質反演專題地圖。
(2) 從中可以看出,土壤有機質含量較高的區域主要集中於城鎮中心、道路兩旁,這可能是由於人為、交通等導致的碳積累;大部分地區有機質含量處於0.5%至1.0%左右,這個值或許有些小於常見水平。影象中的小面積空白區域多為非太湖湖泊、水田、魚塘等水體。

本文公式、反演演演算法等可以參考的文獻
