Pandas 使用教學 Series、DataFrame
Pandas 一個強大的分析結構化資料的工具集,基礎是 Numpy(提供高效能的矩陣運算)
Pandas 可以從各種檔案格式比如 CSV、JSON、SQL、Microsoft Excel 匯入資料。
Pandas 可以對各種資料進行運算操作,比如歸併、再成形、選擇,還有資料淨化和資料加工特徵。
Pandas 廣泛應用在學術、金融、統計學等各個資料分析領域。
Pandas 的主要資料結構是 Series (一維資料)與 DataFrame(二維資料)
- Series 是一種類似於一維陣列的物件,它由一組資料(各種Numpy資料型別)以及一組與之相關的資料標籤(即索引)組成
- DataFrame 是一個表格型的資料結構,它含有一組有序的列,每列可以是不同的值型別(數值、字串、布林型值)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 組成的字典(共同用一個索引)。
pip install pandas -i https://pypi.tuna.tsinghua.edu.cn/simple
Series (一維資料)
Pandas Series 類似表格中的一個列(column),類似於一維陣列,可以儲存任何資料型別。
Series 由索引(index)和列組成,函數如下:
pandas.Series( data, index, dtype, name, copy)
引數說明:
- data:一組資料(ndarray 型別)。
- index:資料索引標籤,如果不指定,預設從 0 開始。
- dtype:資料型別,預設會自己判斷。
- name:設定名稱。
- copy:拷貝資料,預設為 False。
import pandas as pd
a = [1, 2, 3]
myvar = pd.Series(a)
print(myvar)
print(myvar[1]) # 2
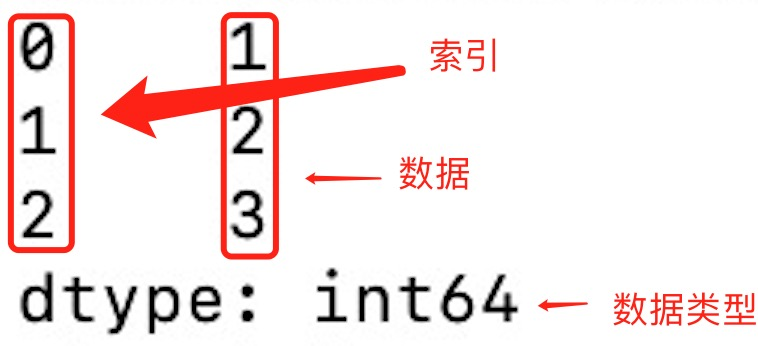
如果沒有指定索引,索引值就從 0 開始,
指定索引值
如下範例:
import pandas as pd
a = ["Google", "Runoob", "Wiki"]
myvar = pd.Series(a, index = ["x", "y", "z"])
print(myvar)
print(myvar["y"]) # Runoob

使用 key/value 物件,建立物件
import pandas as pd
sites = {1: "Google", 2: "Runoob", 3: "Wiki"}
myvar = pd.Series(sites)
print(myvar)

設定 Series 名稱引數
import pandas as pd
sites = {1: "Google", 2: "Runoob", 3: "Wiki"}
myvar = pd.Series(sites, index = [1, 2], name="RUNOOB-Series-TEST" )
print(myvar)

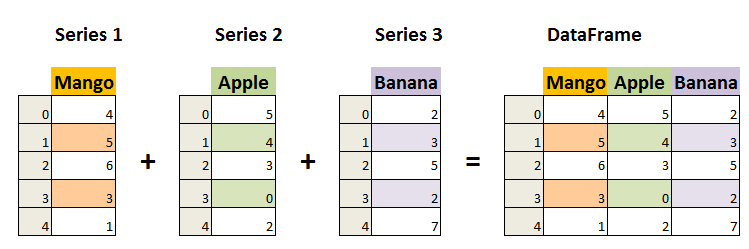
DataFrame(二維資料)
DataFrame 是一個表格型的資料結構,它含有一組有序的列,每列可以是不同的值型別(數值、字串、布林型值)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 組成的字典(共同用一個索引)。

DataFrame 構造方法如下:
pandas.DataFrame( data, index, columns, dtype, copy)
引數說明:
- data:一組資料(ndarray、series, map, lists, dict 等型別)。
- index:索引值,或者可以稱為行標籤。
- columns:列標籤,預設為 RangeIndex (0, 1, 2, …, n) 。
- dtype:資料型別。
- copy:拷貝資料,預設為 False。
Pandas DataFrame 是一個二維的陣列結構,類似二維陣列。
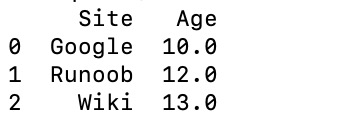
import pandas as pd
data = [['Google',10],['Runoob',12],['Wiki',13]]
# data = {'Site':['Google', 'Runoob', 'Wiki'], 'Age':[10, 12, 13]} # 也可以這樣寫
df = pd.DataFrame(data,columns=['Site','Age'],dtype=float)
print(df)
DataFrame 資料型別一個表格,包含 rows(行) 和 columns(列):
使用字典(key/value)建立
import pandas as pd
data = [{'a': 1, 'b': 2},{'a': 5, 'b': 10, 'c': 20}]
df = pd.DataFrame(data)
print (df)
輸出
a b c
0 1 2 NaN
1 5 10 20.0
loc 屬性返回指定行的資料
import pandas as pd
data = {
"calories": [420, 380, 390],
"duration": [50, 40, 45]
}
# 資料載入到 DataFrame 物件
df = pd.DataFrame(data)
# 返回第一行
# calories 420
# duration 50
print(df.loc[0])
# 返回第二行
# calories 380
# duration 40
print(df.loc[1])
# 返回第一行和第三行
# calories duration
#0 420 50
#2 390 45
print(df.loc[[0, 2]])
本文來自部落格園,作者:VipSoft 轉載請註明原文連結:https://www.cnblogs.com/vipsoft/p/17656714.html