聯邦學習:對「資料隱私保護」和「資料孤島」困境的破局
作者:vivo 網際網路安全團隊- Tu Daxi
隨著計算力、演演算法和資料量的巨大發展,人工智慧迎來第3次發展高潮,開始了各行業的落地探索。然而,在「巨量資料」興起的同時,更多行業應用領域中是「小資料」或者質量很差的資料。「資料孤島」現象廣泛存在,例如在資訊保安領域的應用中,雖然多家企業推出了基於人工智慧技術的內容安全稽核、入侵檢測等安全服務,但出於使用者隱私和商業機密的考慮,企業之間很難進行原始資料的交換,各個企業之間服務是獨立的,整體共同作業和技術水平很難在短時間內實現突破式發展。如何在保護各機構資料隱私的前提下促成更大範圍的合作,能否通過技術手段破解資料隱私保護難題,聯邦學習是解決這一問題、實現跨企業協同治理的有效方式。
一、引言
最近的ChatGPT(全稱:Chat Generative Pre-trained Transformer )在各類社交媒體上風頭無二,其是由OpenAI開發的一個人工智慧聊天機器人程式,於2022年11月推出。該程式使用基於GPT-3.5架構的大型語言模型並通過強化學習進行訓練,釋出至今,OpenAI估值已漲至290億美元,上線兩個月後,使用者數量達到1億。再往前看2016年,人工智慧已經初現走向成熟的端倪,這一年隨著AlphaGo 擊敗人類頂尖圍棋選手李世石、柯潔,我們真正見證了人工智慧(AI)的巨大潛力,並開始期望在許多應用中使用更復雜,最先進的AI技術,包括無人駕駛汽車,醫療保健。如今,人工智慧技術正在幾乎每個行業中展示其優勢。
但是,當我們回顧AI的發展時,不可迴避的是AI的發展經歷了幾次起伏。人工智慧會不會再下滑呢?什麼時候出現?由於什麼因素?當前公眾對AI的興趣部分是由巨量資料的可用性驅動的:2016年AlphaGo總共使用了30萬場遊戲作為訓練資料,以取得出色的成績。隨著AlphaGo的成功,人們自然希望像AlphaGo這樣的巨量資料驅動的AI將成為在我們生活的各個方面。但是,人們都很快意識到現實世界中的情況有些令人失望:
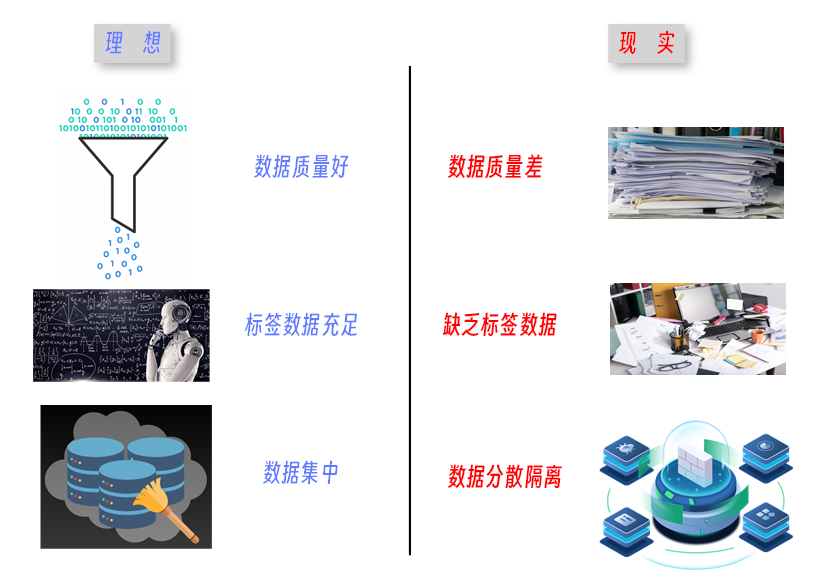
圖 1:人工智慧發展挑戰
-
現實中,我們的資料質量是非常有限甚至是差的,比如聊天資料中有很多噪音。
-
資料標籤的收集是比較困難的,很多場景中的資料是沒有標籤的。
-
資料是孤島的,這也是最重要一點,每家應用的資料不一樣,比如主營社交軟體的公司用的是社交屬性資料,主營電商的公司用的是電商交易資料,銀行用的是信用資料,都是分散來應用的。現實中,如何進行跨組織間的資料合作,會有很大的挑戰。
-
同時隱私保護政策變嚴格,這是重要的第二點,這些條例使得很多機構不能夠把使用者的資料收集起來、集中起來做分析,資料被條例保護在使用者本地了。
資料是人工智慧時代的石油,但是由於監管法規和商業機密等因素限制,「資料孤島」現象越來越明顯。同時隨著政策法規的逐漸完善和公眾隱私保護意識加強,如何在保護資料隱私的前提下實現行業共同作業和協同治理,如何破解「資料孤島」和「資料隱私保護」的兩難困境,成為了當下人工智慧技術行業應用中亟待解決的問題。
二、聯邦學習概述
2.1 「資料隱私保護」與「資料孤島」困境
資料孤島和資料隱私保護的兩難困境:一是來自於人工智慧技術本身的特點,需要海量資料作為基礎;二是來自於世界範圍內對資料隱私和安全的日益重視。
人工智慧技術尤其是深度學習依賴於模型、 演演算法,更依輟於通過海量資料進行模型訓練。從而不斷改進,僅依靠某一機構所掌握的資料,無法實現技術的快速突破。理想狀態是在資料之間建立廣 泛連線,形成合力,創造更大價值。而現實情況是:有效資料往往難以獲取或以「資料孤島」的形式呈現。公司之間的資料共用需要使用者的授權,而許多使用者傾向於拒絕資料共用;即便一個公司內部,資料壁壘也不易打通;網際網路巨頭的存在,使得少數公司襲斷大量資料。這些因素都會導致資料孤島,難以創造出「1+1>2」的資料價值。
全球範圍內對資料隱私和安全的重視帶來了更大挑戰,這個挑戰導致大部分企業只擁用小資料,加劇了資料孤島現象的產生。歐盟出臺了首個關於資料隱私保護的法案《通用資料保護條例》 (General Data Protection Regulation, GDPR),明確了對資料隱私保護的若干規定。和以往的行業規範不同,這是一個真正可以執行的法律,並且條款非常清晰嚴格。例如,經營者要允許使用者來表達資料「被遺忘」的願望,即「我不希望你記住我過去的資料,並希望從現在起你不要利用我的資料來建模」。與此同時,違背GDPR的後果也非常嚴重,罰款可以高達被罰機構的全球營收的4%。Facebook 和Google已經成為基於這個法案的第1批被告。而中國在2017年起實施的《中華人民共和國網路安全法》和《中華人民共和國民法總則》中也指出:「網路運營者不得洩露、篡改、毀壞其收集的個人資訊,並且與第三方進行資料交易時需確保擬定的合同明確約定擬交易資料的範圍和資料保護義務」。這意味著對於使用者資料的收集必須公開、透明,企業、機構之間在沒有使用者授權的情況下不能交換資料。
雖然有明確的法律法規並且在全球範圍內達成了廣泛共識,但由於技術等因素的限制,實際應用中,資料隱私保護仍然是難題。收集資料的一方往往不是使用資料的一方,例如A方收集資料,轉移到B方清洗,再轉移到C方建模,最後將模型賣給D方使用。這種資料在實體間轉移、交換和交易的形式違反了相關法律法規,並可能受到嚴厲的懲罰。如何在保護資料隱私的前提下,從技術上解決資料孤島的問題,在隱私安全和監管要求下,如何讓AI系統更加高效、準確地共同使用各自的資料,能夠在小資料(很少的樣本和特徵)和弱監督(有很少的標註)的條件下做更好的模型,人們提出聯邦學習的解決方案,並且不斷探索其在具休行業場景下的應用。
2.2 聯邦學習定義
數學定義:
定義N個資料持有者{F1, F2, F3..., Fn},他們都希望通過整合各自的資料 {D1, D2, D3..., Dn}來訓練機器學習模型。傳統的方法是將所有資料放在一起使用 D=D1 U D2 U...U Dn 來訓練出一個模型 MSUM,而聯邦系統是一個學習過程,在此過程中,所有資料持有者共同作業訓練模型 MFED,並且對任意一個資料持有者 Fi 不會將其獨享的資料 Di 暴露給其他人。除此之外,模型 MFED 的準確性定義為 VFED 其應該是非常接近於將資料集中放一起訓練的模型 MSUM 的準確度 VSUM. 用公式定義,讓 δ 為非負實數,如果
| VFED - VSUM |< δ
則稱該聯邦學習演演算法有 δ 的精度損失。
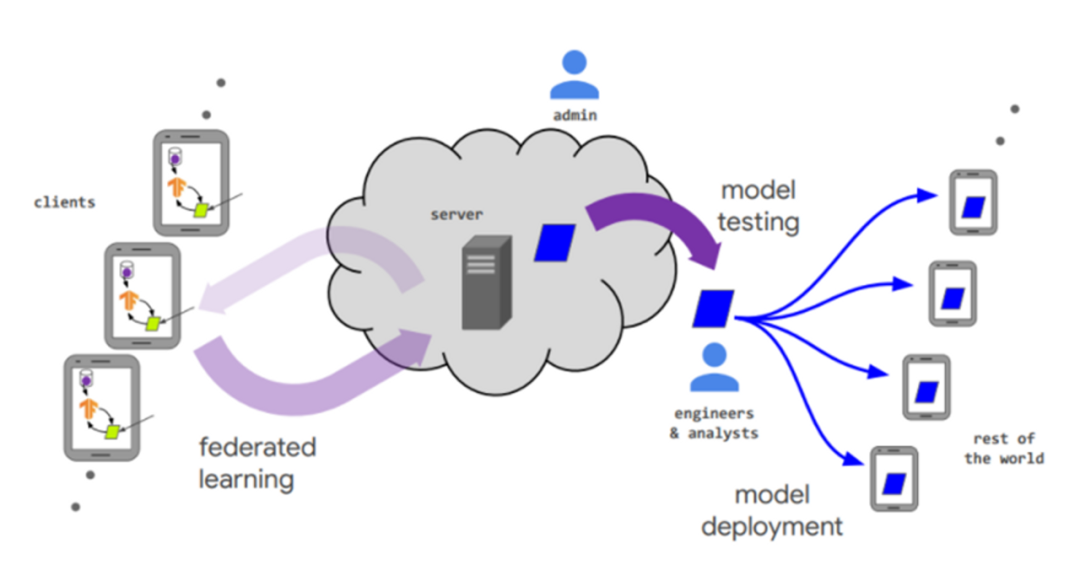
圖 2.1:聯邦學習模型組成
在Peter等在綜述【1】中給出的上圖定義中可以清晰看出,聯邦學習指的是在滿足隱私保護和資料安全的前提下設計一個機器學習框架,使得其中許多使用者端(例如移動裝置或整個組織)在中央伺服器(例如服務提供商)的協調下共同訓練模型,同時保持訓練資料的去中心化及分散性,實現在不暴露資料的情況下分析和學習多個資料擁有者的資料。同時從定義中可以為其總結四大特徵:
-
資料隔離:聯邦學習的整套機制在合作過程中,資料不會傳遞到外部,資料保留在本地,避免資料洩露,滿足使用者隱私保護和資料安全的需求。
-
無失真:通過聯邦學習分散建模的效果和把資料合集中在一起建模的效果對比,幾乎是無失真的。
-
共同獲益:能夠保證參與各方在保持獨立性的情況下,進行資訊與模型引數的加密交換,並同時獲得成長。
-
對等:在聯邦學習的框架下,各參與者地位對等,能夠實現公平合作,不存在一方主導另一方的情況。
2.3 聯邦學習隱私性
隱私是聯邦學習的基本屬性之一,這需要安全模型和分析以提供有意義的隱私保證。在本節中,將簡要介紹和比較聯邦學習的不同隱私技術,並確定方法和潛力防止間接洩漏的挑戰。
多方安全計算(Secure Multi-party Computation, SMC):
SMC安全模型自然涉及多方參與,並在定義良好的模擬框架中提供安全證明,保證完全零知識,即每一方除了自己的輸入和輸出外一無所知。零知識是非常可取的,但是這種所需的屬性通常需要複雜的計算協定並且可能無法有效地實現。在某些情況下,如果提供安全保證,部分知識披露可能被認為是可以接受的。可以在較低的安全要求下用 SMC 構建安全模型以換取效率。
差分隱私計算(Differential Privacy):
使用差分隱私或 k-匿名演演算法來保護資料隱私 。差分隱私計算、k-匿名計算和演化計算的方法包括在資料中加入噪聲,或者使用泛化方法來掩蓋某些敏感屬性,直到第三方無法區分個體,從而使資料無法被敵手恢復,進而起到保護使用者隱私的作用。
同態加密計算(Homomorphic Encryption):
在機器學習過程中,還採用同態加密通過加密機制下的引數交換來保護使用者資料隱私。與差分隱私保護不同,資料和模型本身不傳輸,也無法通過對方的資料進行猜測。因此,原始資料層面洩露的可能性很小。最近的工作採用同態加密來集中和訓練雲上的資料。在實踐中,加法同態加密被廣泛使用,並且需要進行多項式逼近來評估機器學習演演算法中的非線性函數,從而導致準確性和隱私之間的權衡。
2.4 聯邦學習分類
在實際應用中,因為孤島資料具有不同的分佈特點,所以聯邦學習也可分為:橫向聯邦學習、縱向聯邦學習、聯邦遷移學習3大類:
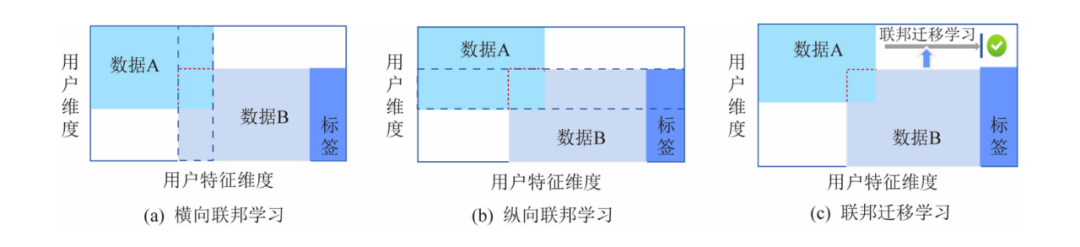
圖 2.2:聯邦學習分類
如果要對使用者行為建立預測模型,需要有一部分的特徵,即原始特徵,叫作 X ,例如使用者特徵, 也必須要有標籤資料,即期望獲得的答案,叫作 Y。比如,在金融領域,標籤 Y 是需要被預測的使用者信用;在行銷領域,標籤 Y 是使用者的購買願望;在教育領域,則是學生掌握知識的程度等.使用者特徵 X 加標籤 Y 構成了完整的訓練資料 (X,Y)。但是,在現實中,往往會遇到這種情況:各個資料集的使用者不完全相同,或使用者特徵不完全相同。具體而言,以包含2個資料擁有方的聯邦學習為例,資料分佈可以分為3種情況:
-
2個資料集的使用者特徵重疊部分較大,而使用者重疊部分較小,如圖2.2中(a)所示;
-
2個資料集的使用者重疊部分較大,而使用者特徵重疊部分較小,如圖2.2中(b)所示;
-
2個資料集的使用者與使用者特徵重疊部分都比較小,如圖2.2中(c)所示。
為了應對以上3種資料分佈情況,我們把聯邦學習分為橫向聯邦學習、縱向聯邦學習與聯邦遷移學習。
2.5 聯邦學習步驟
一般一個聯邦學習模型主要有聯邦學習系統架構和加密模型訓練兩大部分組成[2]。假設現有兩個資料擁有方(組織A和組織B)希望聯合訓練一個機器學習模型,它們的業務系統分別擁有各自使用者的相關資料。此外,組織B還擁有模型需要預測的標籤資料。出於資料隱私和安全考慮,組織A和組織B無法直接進行資料交換。此時,可使用聯邦學習系統建立模型,系統架構由2部分構成,如圖2.3所示:
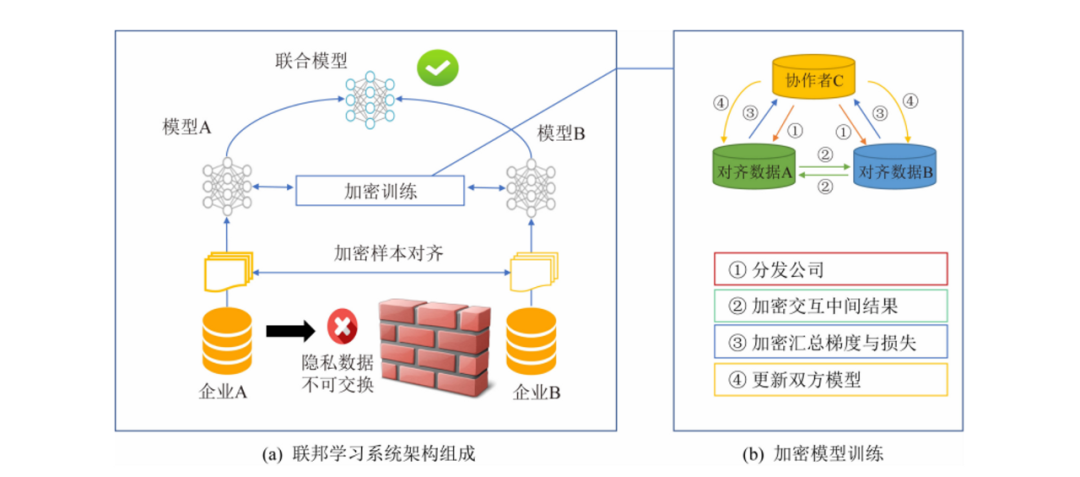
圖 2.3:聯邦學習系統架構
整個進行的步驟可以分為:
(1)加密樣本對齊:由於2家組織的使用者群體並非完全重合,系統利用基於加密的使用者樣本對齊技術,在組織A和組織B不公開各自資料的前提下確認雙方的共有使用者,並且不暴露不互相重疊的使用者,以便聯合這些使用者的特徵進行建模。
(2)加密模型訓練:在確定共有使用者群體後,就可以利用這些資料訓練機器學習模型。為了保證訓 練過程中資料的保密性,需要藉助第三方共同作業者C進行加密訓練。以線性迴歸模型為例,訓練過程可分為以下4步(如圖(b)所示):
-
共同作業者C把公鑰分發給模型A和模型B,用以對訓練過程中需要交換的資料進行加密。
-
對齊資料A和對齊資料B之間以加密形式互動用於計算梯度的中間結果。
-
對齊資料A和對齊資料B分別基於加密的梯度值進行計算,同時對齊資料B根據其標籤資料計算損失,並把這些結果彙總給共同作業者C。共同作業者C通過彙總結果計算總梯度並將其解密。
-
共同作業者C將解密後的梯度分別回傳給模型A和模型B;模型A和模型B根據梯度更新各自模型的引數。迭代上述步驟直至損失函數收斂,這樣就完成整個訓練過程。在樣本對齊及模型訓練過程中,組織A和組織B各自的資料均保留在本地,且訓練中的資料互動也不會導致資料隱私洩露。因此,雙方在聯邦學習的幫助下得以實現合作訓練模型。
(3)效果激勵:聯邦學習的一大特點就是它解決了為什麼不同機構要加入聯邦共同建模的問題,即建立模型以後模型的效果會在實際應用中表現出來,並記錄在永久資料記錄機制(如區塊鏈)上。提供資料多的機構會看到模型的效果也更好[3],這體現在對自己機構的貢獻和對他人的貢獻。這些模型會向各個機構反饋其在聯邦機制上的效果,並繼續激勵更多機構加入這一資料聯邦。
以上3個步驟的實施,既考慮了在多個機構間共同建模的隱私保護和效果,又考慮瞭如何獎勵貢獻資料多的機構,以一個共識機制來實現,所以,聯邦學習是一個「閉環」的學習機制。
三、 總結展望
3.1 總結
聯邦學習作為隱私增強計算與人工智慧相結合的新型技術正規化,成為了解決資料安全與開放共用矛盾的一個重要技術路徑。聯邦學習中,使用者可以在自己的終端使用本地資料對模型進行訓練,並將模型的加密引數進行上傳彙總,將不同的模型更新進行融合,優化預測模型。
2022年是聯邦學習的技術分水嶺——從聯邦學習到可信聯邦學習。針對近兩年來隱私計算和聯邦學習發展和應用中面臨的安全、效率等挑戰,「可信聯邦學習」被提出,這一正規化將隱私保護、模型效能、演演算法效率作為核心,共同構成了更加安全可信的聯邦學習。
3.2 落地展望
目前,聯邦學習已經開始了在行業領域的落地探索,在不同的行業有多樣化的應用場景和落地形態,未來在一些領域可能有以下廣闊前景[4-10]:
在手機領域,近年來,移動裝置配備了越來越先進的感測和計算能力。再加上深度學習 (Deep Learning,DL) 的進步,這為有意義的應用開闢了無數可能性,例如,用於智慧車載和輔助駕駛。傳統的基於雲的機器學習 (Machine Learning,ML) 方法需要將資料集中在雲伺服器或資料中心。然而,這會導致與不可接受的延遲和通訊效率低下相關的關鍵問題。為此,有人提出了移動邊緣計算 (Mobile Edge Computing,MEC),以使產生資料的邊緣裝置變得更加智慧。然而,傳統的移動邊緣網路 ML 支援技術仍然需要與外部各方共用個人資料,例如邊緣伺服器。最近,鑑於越來越嚴格的資料隱私立法和日益增長的隱私問題,聯邦學習(FL)的概念被引入。在 FL 中,終端裝置使用其本地資料來訓練伺服器所需的 ML 模型。然後終端裝置將模型更新而不是原始資料傳送到伺服器進行聚合,這將進一步加速產生資料的終端裝置變得更加智慧;
在風控領域,多家金融機構聯合建模的風控模型能更準確地識別信貸風險,聯合反欺詐。多家銀行建立的聯邦反洗錢模型,能解決該領域樣本少、資料質量低的問題。
在智慧零售領域,聯邦學習能有效提升資訊和資源匹配的效率。例如,銀行擁有使用者購買能力的特徵,社交平臺擁有使用者個人偏好特徵,電商平臺則擁有產品特點的特徵,傳統的機器學習模型無法直接在異構資料上進行學習,聯邦學習卻能在保護三方資料隱私的基礎上進行聯合建模,為使用者提供更精準的產品推薦等服務,從而打破資料壁壘,構建跨領域合作。
在醫療健康領域,聯邦學習對於提升醫療行業共同作業水平更具有突出意義。在推進智慧醫療的過程中,病症、病理報告、檢測結果等病人隱私資料常常分散在多家醫院、診所等跨區域、不同型別的醫療機構,聯邦學習使機構間可以跨地域共同作業而資料不出本地,多方合作建立的預測模型能夠更準確地預測痛症、基因疾病等疑難病。如果所有的醫療機構能建立一個聯邦學習聯盟,或許可以使人類的醫療衛生事業邁上一個全新的臺階。
參考文獻:
-
[1] Kairouz P, McMahan H B, Avent B, et al. Advances and open problems in federated learning[J]. Foundations and Trends® in Machine Learning, 2021, 14(1–2): 1-210.
-
[2] Li T, Sahu A K, Talwalkar A, et al. Federated learning: Challenges, methods, and future directions[J]. IEEE signal processing magazine, 2020, 37(3): 50-60.
-
[4] 楊強. GDPR對AI的挑戰和基於聯邦遷移學習的對策[J]. 中國人工智慧學會通訊,2018,8:1-8
-
[5] Zhang C, Xie Y, Bai H, et al. A survey on federated learning[J]. Knowledge-Based Systems, 2021, 216: 106775.
-
[6] Kairouz P, McMahan H B, Avent B, et al. Advances and open problems in federated learning[J]. Foundations and Trends® in Machine Learning, 2021, 14(1–2): 1-210.
-
[10] Yang Q, Liu Y, Chen T, et al. Federated machine learning: Concept and applications[J]. ACM Transactions on Intelligent Systems and Technology (TIST), 2019, 10(2): 1-19.MLA