解放雙手!ChatGPT助力編寫JAVA框架
親愛的Javaer們,在平時編碼的過程中,你是否曾想過編寫一個Java框架去為開發提效?但是要麼編寫框架時感覺無從下手,不知道從哪開始。要麼有思路了後對某個功能實現的技術細節不瞭解,空有想法而無法實現。如果你遇到了這些問題,看完這篇文章你也能用ChatGPT編寫一個簡單的JAVA框架。
構思清晰
首先,你需要明確你的框架要解決什麼問題,具有什麼特性。這將有助於ChatGPT更好的理解你的需求。
例如:我在一個前後端分離的需求中發現有太多的列舉類的描述需要給前端返回。傳統的方式是後端根據列舉類的對映,每個列舉值編寫程式碼對映成描述給前端返回。但這次需求需要給前端返回的列舉描述太多了。這讓我和我的小夥伴們感覺無從下手。所以我就思考能否編寫一個註解自動幫我們掃描這些列舉類,然後生成key和描述的map,最終放到容器中去呢?
解決問題:解決前後端分離過程中需要手動編寫程式碼將列舉key的描述對映給前端。
特性:框架有一個註解,註解有三個欄位name,key,和desc,修飾在列舉類上。框架需提供外部獲取列舉map的介面。
與 ChatGPT 交流
啟動 ChatGPT,向它講述你的構想和需求。它可以為你生成初始程式碼、提供結構建議,甚至幫你處理一些邏輯。
想好了框架要解決的問題和框架的特性之後,接下來就要將框架要解決的問題和特性給總結成一段文字發給ChatGPT
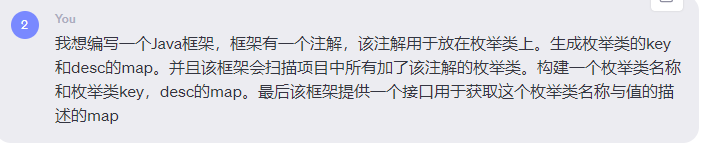
chatgpt根據我的需求大概生成了下框架的demo版本。可以看到和我設想的還是有些區別的,我想是將列舉放在類上。然後列舉的屬性有name,key,和desc。
name:代表列舉map在最外層map中的key。
key:代表列舉的key或值欄位。
desc:代表列舉的描述欄位。
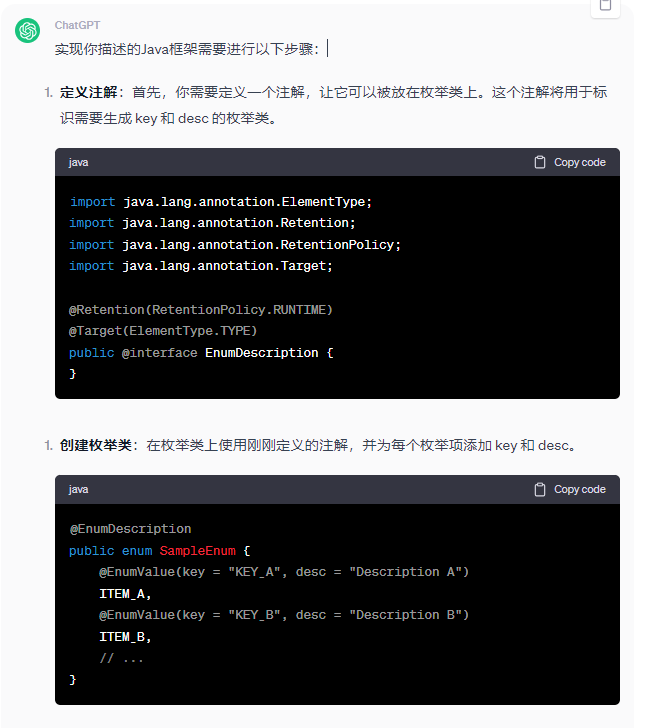

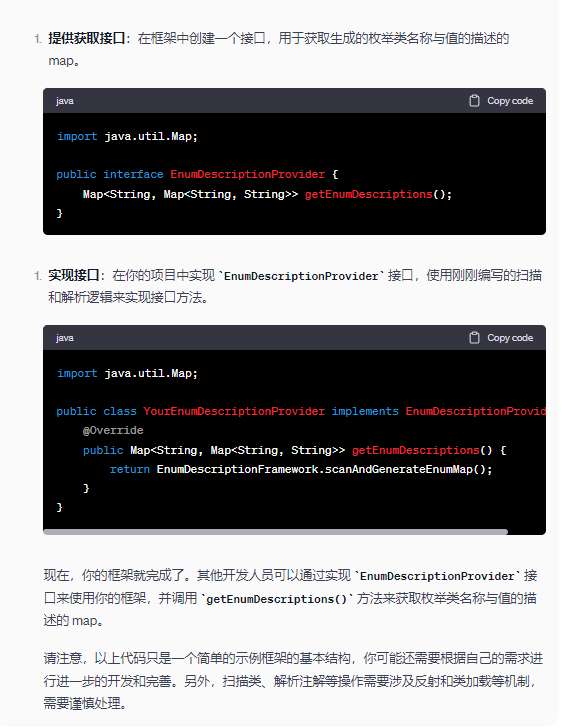
深入互動
與 ChatGPT 進行更深入的交流,詢問它關於程式碼優化、例外處理等方面的建議。它可以幫你找到更好的解決方案。
接下來需要與ChatGPT進一步交流,讓ChatGPT將之前生成的程式碼進行優化。
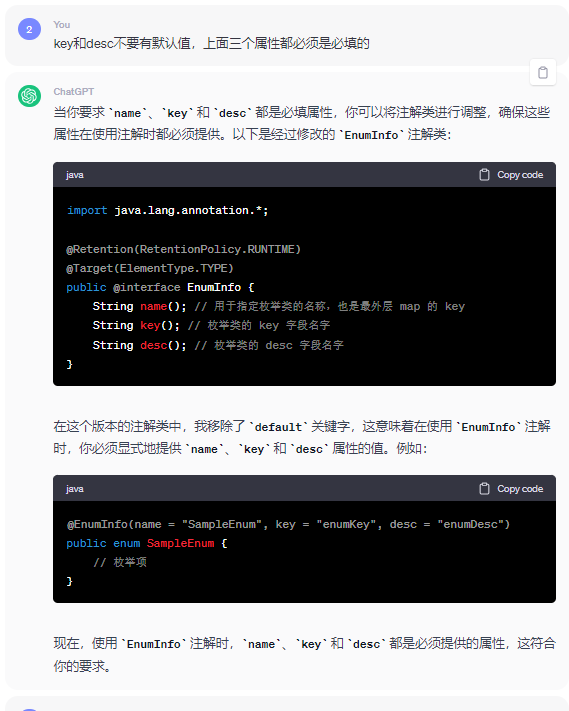
EnumInfo註解優化前:
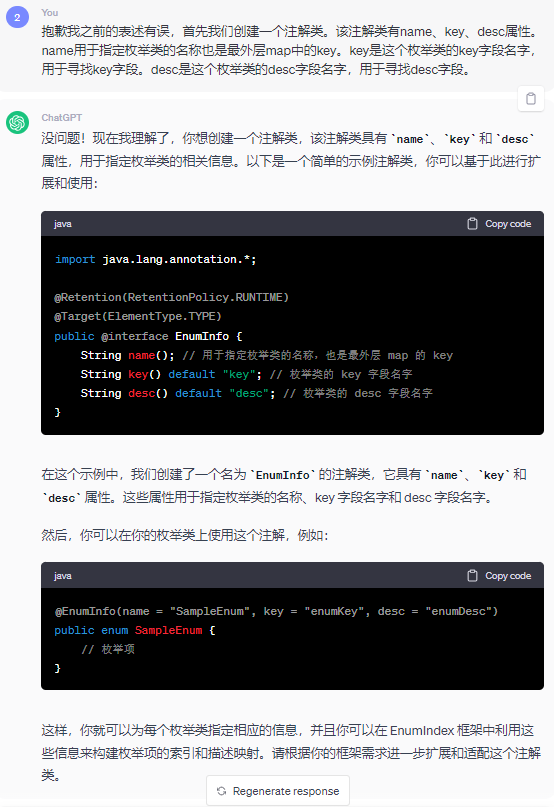
優化後:
逐步完善
逐步引導chatgpt完善框架
在 ChatGPT 的幫助下,逐步完善你的框架。親自動手編寫程式碼,與 ChatGPT 一起探討每個細節。
最後可以和ChatGPT一步步交流,讓它幫你構建一個完整的框架。
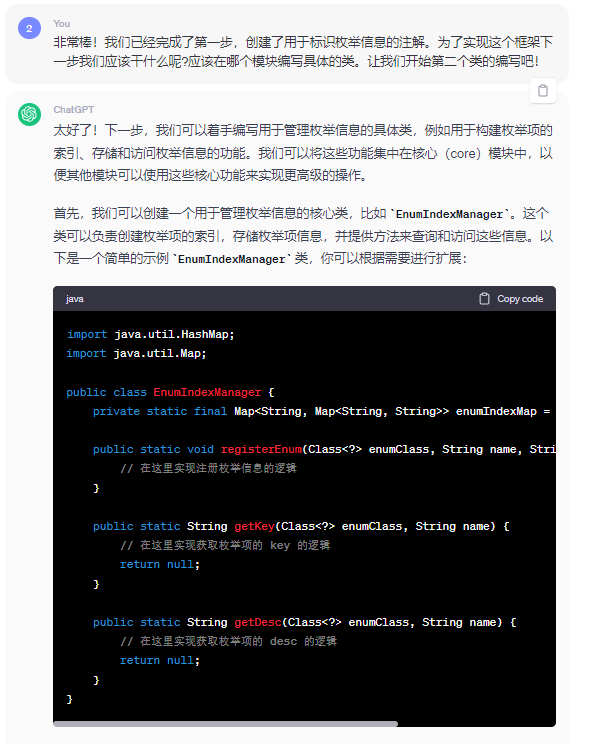
最終慢慢與ChatGPT不斷對話迭代之後將框架的核心類生成,迭代過程由於太長故省略。
框架核心類說明
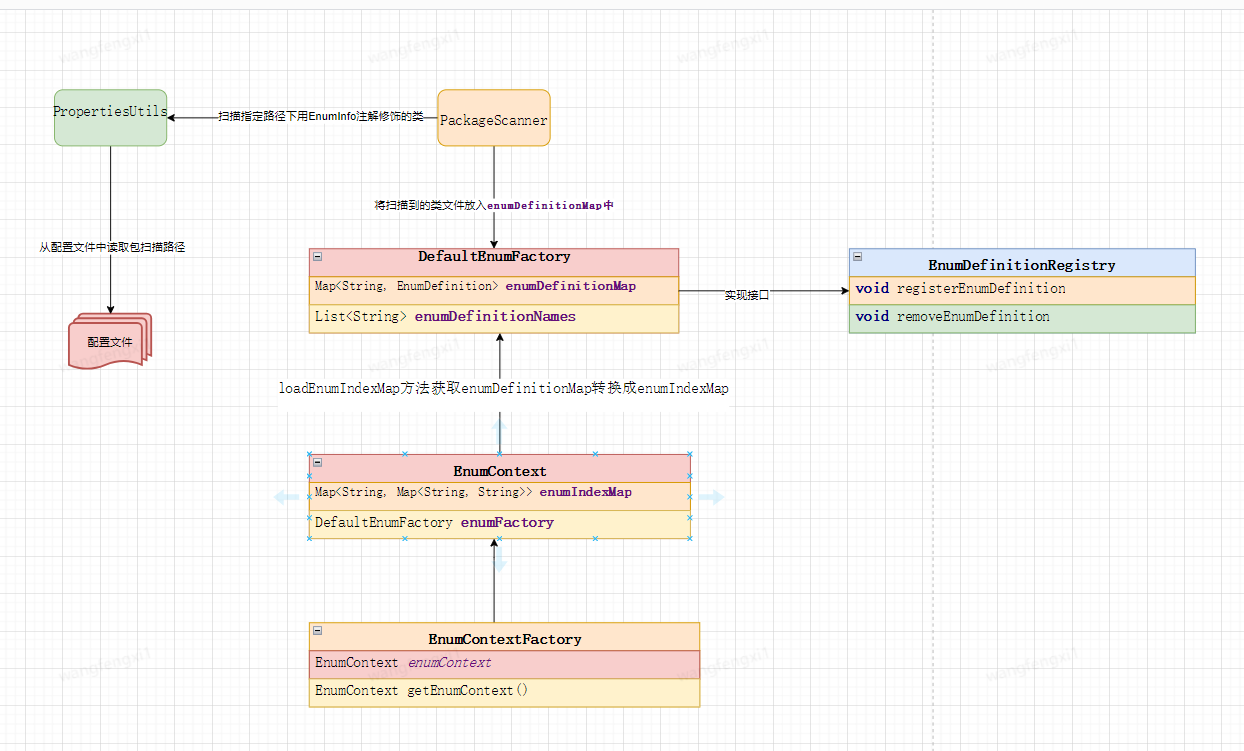
在ChatGPT給出核心程式碼之後,我參考Spring模組設計最終初版框架類如下:
PackageScanner:用於掃描給定包中帶有指定註解的類的實用工具類。
PropertiesUtils:提供操作屬性檔案的實用方法的工具類。
EnumInfo:用於標註列舉類的註解,指定列舉項的名稱、key 欄位和 desc 欄位資訊。 通過在列舉類上新增該註解,可以為列舉項建立索引對映,並指定用於查詢 key 和 desc 的欄位名稱。
EnumContext:列舉上下文類,用於管理列舉定義資訊並提供獲取列舉資訊的方法。
EnumContextFactory:列舉上下文工廠類,用於建立和獲取單例的列舉上下文物件。
EnumDefinition:表示列舉定義的類,用於儲存列舉類的資訊。
EnumDefinitionRegistry:列舉定義註冊介面,用於註冊、查詢和管理列舉定義。
DefaultEnumFactory:預設的列舉定義工廠類,實現了 EnumDefinitionRegistry 介面。
看到這使用ChatGPT編寫框架部分已經完成了。大件可以使用chatgpt開發自己的JAVA框架。但要想把框架實際應用到生產還需要做一些收尾流程。
框架使用測試
在於ChatGPT交流,完成框架編寫之後需要將框架應用到實際專案中。
筆者業務系統管理端在進行前後端分離的過程中,研發們發現有許多列舉類對應的列舉描述需要給前端返回。
1)一開始設想的是每個列舉類都寫程式碼給前端封裝返回文字。但是由於筆者業務系統設定項過多,每個設定項都寫程式碼太過麻煩。
2)於是研發們想能否使用一個統一的介面給前端返回列舉類對應的描述,前端只需要輸入列舉類名稱就可以獲得對應的列舉key和描述的對映關係。
於是我們建立了一個介面,定義了一個Map物件給前端返回列舉類的key和描述的對應關係。但是由於筆者業務系統的渠道設定還是太多了。使用這種方式我們需要初始化這個Map。初始化Map程式碼如下:
public HashMap<String, Map<Integer, String>> initEnumMap() {
enumMap = new HashMap<>();
enumMap.put("前端獲取列舉map的key", XXXEnum.getEnumMap());
enumMap.put("前端獲取列舉map的key", XXXEnum.getEnumMap());
enumMap.put("前端獲取列舉map的key", XXXEnum.getEnumMap());
...
return enumMap;
}
可見,每新增一個列舉類。我們都需要在靜態程式碼塊中將對映關係放入map中。並且列舉類需要新增一個獲取key和描述的對映關係方法。這樣還是太麻煩了。並且後續新增對映關係還得更改這個類的程式碼。
能否將map初始化的步驟和列舉類建立map的步驟省略呢?
3)於是我們設想定義一個註解。使用這個註解標記的類,框架掃描這些類。並生成獲取列舉key和描述的對映關係的方法。最終完成初始化Map的過程。對外只提供獲取總列舉Map的方法即可。使用者無需關心Map如何構建。使用這個框架之後,筆者業務系統這個介面的程式碼如下:
/**
* 獲取列舉
*
* @param enumKey 列舉key
* @return 返回值 Map<Integer,String>;code,描述
*/
@RequestMapping("/getEnum")
public Result<Map<String, Map<String, String>>> getEnum(String enumKey) {
try {
// 獲取列舉上下文物件
EnumContext enumContext = EnumContextFactory.getEnumContext();
// 獲取列舉map
newEnumMap = enumContext.getEnumIndexMap();
// buid對映從ducc中獲取,所以需要手動設定
newEnumMap.put(BUID.getKey(), getBuIdMap());
} catch (Exception e) {
log.error("獲取列舉map出錯!enumKey:{}", enumKey, e);
return Result.createFail(e.getMessage());
}
// 如果列舉key為空則返回全部
if (StringUtils.isBlank(enumKey)) {
return Result.createWithSuc(newEnumMap);
}
// 如果列舉key不為空則返回指定值
Map<String, Map<String, String>> resultMap = new HashMap<>();
resultMap.put(enumKey, newEnumMap.get(enumKey));
return Result.createWithSuc(resultMap);
}
4)註解類程式碼如下:
在這舉個測試列舉類的例子
@EnumInfo(name = "StatusEnum", key = "code", desc = "description")
public enum StatusEnum {
SUCCESS(200, "Success"),
ERROR(500, "Error");
private final int code;
private final String description;
StatusEnum(int code, String description) {
this.code = code;
this.description = description;
}
public int getCode() {
return code;
}
public String getDescription() {
return description;
}
}
以後新增一個列舉類只需要標記@EnumInfo(name = "StatusEnum", key = "code", desc = "description")。將列舉類的name ,key欄位名稱和描述欄位名稱指定即可。無需修改介面的程式碼即可給前端返回該列舉的key和描述的對映關係。極大的減少了研發聯調時間及測試迴歸時間。
框架效能壓測
框架應用到實際生產專案中,需要對ChatGPT輔助編寫的框架進行充分的測試驗證。同時也要對框架的效能進行測試,知道框架的瓶頸。常見的介面壓測工具有LoadRunner和Apache JMeter等。任選一種壓測工具進行壓測即可。
筆者將框架應用到專案中對外暴露了一個介面,該介面在4C4G機器設定下,單機最高可支援1000QPS,在1000QPS下,單機CPU使用率達到30%,系統負載接近0.9,記憶體使用率與壓測前無明顯變化。
作者:京東零售 王鳳璽
來源:京東雲開發者社群 轉載請註明來源