問題排查:nginx的反向代理感覺失效了一樣
背景
最近,負責基礎設施的同事,要對一批測試環境機器進行回收,回收就涉及到應用遷移,問題是整個過程一團亂。比如伺服器A上一堆應用要呼叫伺服器B上一堆服務,結果伺服器B被回收了,然後伺服器A上一堆應用報錯。
今天就是負責查一個問題,app上一個頭像上傳的介面,之前都好好的,不知道怎麼就不能存取了,報錯現象是在請求後等待n秒超時,然後伺服器端報錯502。
這個服務也不知道誰維護的,可能維護的人早已離職了也說不定,這也是這邊的常態吧,人走了,負責的服務還在伺服器上跑,也沒有交接檔案。
問題現象
鏈路梳理
先上個圖,再解釋整個鏈路:

現象就是,app端呼叫外網ip(記作A): xxxx埠的某個介面,超時後報502錯誤,因為是http協定,能從響應中看出來是Apache。
然後,就是去找網路同事,問外網ip:xxx埠對應的內網ip和埠,得到了內網ip(記作B):80埠。接下來,又是找負責伺服器的同事,要伺服器B的密碼,一開始以為是linux機器,沒想到還是windows的。vnc登入進去後,根據埠號找到對應的程序,發現是Apache HTTP Server,這個東西我也不熟悉,知道它類似於nginx,功能類似,但是幾乎一直沒用過,所幸,在程式的根目錄下,找到了一個組態檔,組態檔中設定了反向代理,將請求反向代理到了伺服器C:8088埠。
這個伺服器C,基本就是今天的主角了。
於是,又去找同事要伺服器C的密碼,這次還好,是個linux機器,查詢8088埠對應的服務,是個nginx程序,然後檢視該程序的組態檔,發現請求被反向代理到了本機的9901埠。
問題現象
梳理完整個鏈路後,我決定去看看最後的java服務的紀錄檔,因為是第一次看到這個服務,也不知道紀錄檔檔案在哪裡。cd到/proc/服務pid/fd目錄下,看到了其開啟的檔案,裡面有個紀錄檔檔案,但是,開啟紀錄檔檔案,發現裡面空空如也。
我又去調了調紀錄檔級別,然後app發起請求,發現還是沒啥紀錄檔。
然後開始懷疑請求沒到服務這裡,行吧,那還是跟著鏈路排查下,看看怎麼回事。
於是在linux機器上開啟java服務的9901埠的抓包,然後重試,發現還是空空如也,什麼包都沒有。
tcpdump -i any tcp port 9901 -Ann
這就奇怪了,沒到java服務,那到了nginx沒有呢?然後開始抓nginx這塊:
tcpdump -i any tcp port 8808 -Ann
這次發現包還挺多的,於是根據介面名(url包括Upload關鍵字)加了個過濾條件:
tcpdump -i any tcp port 8808 -Ann |grep Upload
這次發現,能抓到包。這,意思是,看起來nginx是收到包了,但是,沒往java服務發啊。這倒是奇了怪了,看起來,反正是nginx的問題,於是,去看nginx的access紀錄檔和error紀錄檔,發現access紀錄檔裡並沒有該介面的記錄,error紀錄檔裡也啥都沒有。
於是我調整了nginx error紀錄檔級別為info,如下(從上而下,越來越詳細):
alert - 系統級別緊急資訊
critical - 關鍵錯誤資訊
error - 一般性錯誤資訊
warn - 警告資訊
notice - 一些特殊資訊
info - 一般資訊
debug - 偵錯資訊
error_log /var/log/nginx/error.log info;
結果,發現error紀錄檔還是啥都沒有。
然後,我想著是不是我組態檔沒看對,我以為會走某個location,該不會沒匹配上,走到別的location了,然後轉發到其他後端去了?
後面仔細觀察了請求介面的url,感覺還是沒問題。
當時,基於兩個原因,決定採用strace去看看nginx的系統呼叫:
- 看看是不是我把location看錯了,nginx把請求發到其他機器去了,所以在9901的java服務才看不到紀錄檔
- 看看是不是nginx內部報啥錯了,error紀錄檔沒體現出來
然後找到nginx的pid後,使用如下命令檢視網路呼叫:
strace -p nginx-pid -q -f -s 10000 -e trace=network
命令我也是查了自己當年的文章,不然誰記得住:
https://www.cnblogs.com/grey-wolf/articles/13139308.html
結果,發現系統感覺有問題,執行命令後,啥結果都沒有。
換了nginx的worker程序的pid,還是沒效果。後邊再換了個pid,直接卡死了,ctrl c也沒用。
我他麼就是感覺這機器有點怪,之前執行lsof也卡住不動,現在strace又這樣,真的服了。
一看時間,到午飯時間了,吃飯吧。
來了一點靈感
吃完飯,我又去把之前抓的windows apache和nginx之間的網路包開啟分析了一會。
包的前面幾個報文如下:

前三個報文是三次握手,8088是我們的nginx伺服器端。因為我的包就是伺服器端抓的,看起來,一切正常,伺服器端是正常完成了三次握手了。
包4,使用者端發了個報文過來,包長1516位元組,這個包,其實也就是包含了http請求(見下圖);理論上,下一個包應該是我們回覆ack,表示包4收到了。
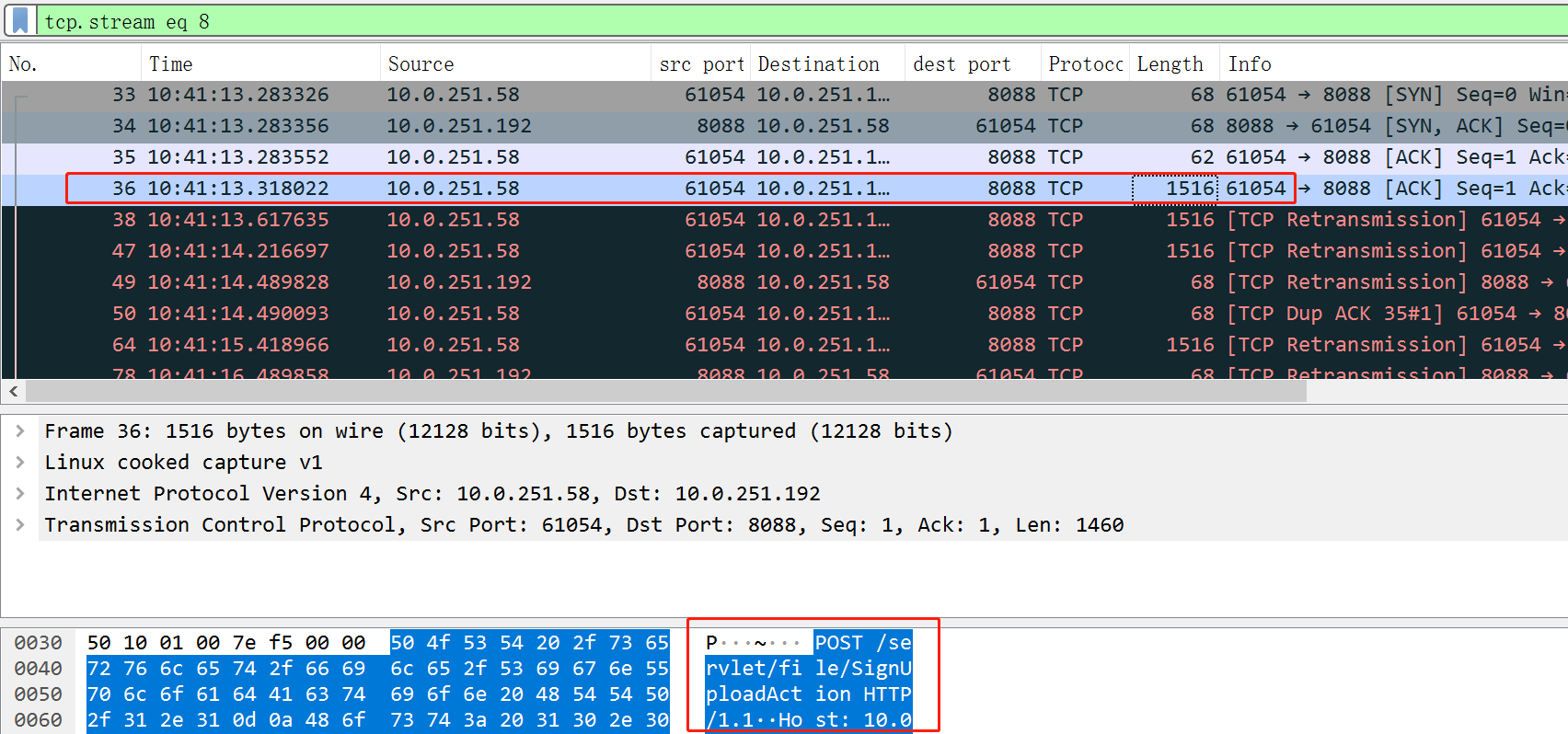
但是,下面的包5、包6,看起來是使用者端發生了重傳,為啥要重傳呢?不知道,接著看下面。
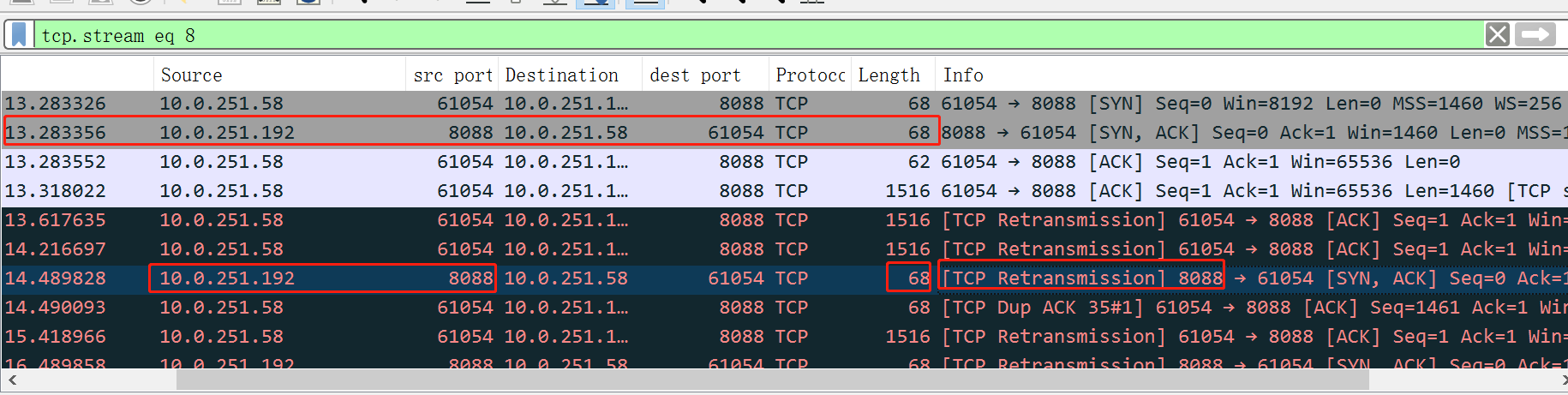
看我上圖示紅的下面那一行,是我們伺服器端nginx往使用者端發的,68個位元組,也有個重傳字樣,看起來,意思是我們也發生了重傳,重傳了哪個包呢,就是包2,也就是握手時候的我方回覆的syn+ack那個包。
再加個過濾,看看我方到底給對方發了些啥包:

結果,我方貌似一直在給對方重傳第二次握手的訊息。
我想了半天,終於想差不多了,看來是使用者端的第三次握手的ack,被我們忽略了,所以,我們這邊,連線一直不是established狀態,而是syn received狀態。而使用者端呢,發完第三次的ack後,就進入了established狀態,所以就開始發http請求過來了,我方由於狀態不是established,所以一直給對方重發syn + ack。
為啥會忽略第三次的ack呢,我突然想起來,如果接收了ack,連線就會正式建立,連線就會放入accept佇列(全連線佇列),等待應用去accept了。現在反過來想,既然沒往accept佇列放,會不是佇列滿了,所以乾脆就不添堵了,所以不放了,直接丟棄ack呢?
然後我開始搜尋全連線佇列滿相關的文章,看了幾篇,基本感覺有戲。
解決問題
午休結束後,去到測試機(沒法在本地直接ssh)上根據文章查驗。
參考文章:
https://blog.51cto.com/u_15181572/6172585
https://blog.csdn.net/Octopus21/article/details/132124481
其實全連線佇列這個,幾年前學習過這個,但是久了沒碰到這個場景,早已淡忘,這次還真遇上了。
每一個listen狀態的socket,都有個全連線佇列,佇列大小受到兩個引數控制,一個是linux的核心引數net.core.somaxconn,可通過sysctl -a |grep somaxconn檢視,我看了我們機器,值為128;另一個引數是應用執行listen時,可以指定一個叫做backlog的int型別引數,nginx中預設為512.
全連線佇列大小呢,就是取min(net.core.somaxconn, 應用listen時的backlog值),我這裡,兩者取小,就是128.
這個值怎麼檢視呢,可以通過:
[root@168assi logs]# ss -lnt |egrep "State|8088"
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 129 128 *:8088
這裡可以看到Send-Q的值,就表示佇列的最大值為128. 而Recv-Q呢,就是當前全連線佇列的長度,129,可以看到,已經大於128了,說明佇列滿了。
這裡的Recv-Q和Send-Q的值,僅當socket處於listen時表示該意思,非listen時,表示其他意思。這裡給個官方解釋:
Recv-Q
Established: The count of bytes not copied by the user program connected to this socket.
Listening: Since Kernel 2.6.18 this column
contains the current syn backlog.
Send-Q
Established: The count of bytes not acknowledged by the remote host.
Listening: Since Kernel 2.6.18 this column contains the maximum
size of the syn backlog.
另外,再根據文章提到的命令:
netstat -s | grep overflow
果然看到數位一直在增長,見下面網圖:

基本認定這個問題後,就是修改了,我是直接將核心引數改成了65535:
[root@168assi 12556]# vim /etc/sysctl.conf
net.core.somaxconn = 65535
然後如下命令生效:
sysctl -p
接下來,重啟nginx,檢視佇列長度,已經是511了(nginx 預設的listen的backlog值):
[root@168assi 12556]# ss -lnt|grep 8088
LISTEN 0 511 *:8088 *:*
另外,補充一點,再遇到該佇列滿時,我們的linxu機器是直接忽略了ack,也可以設定如下引數(值為1,預設為0,表示忽略報文),讓其給使用者端回覆rst報文:
[root@168assi logs]# sysctl -a |grep tcp_abort_on_overflow
net.ipv4.tcp_abort_on_overflow = 0
官方解釋如下(man tcp,如提示沒安裝,yum install man-pages):
tcp_abort_on_overflow (Boolean; default: disabled; since Linux 2.4)
Enable resetting connections if the listening service is too slow and unable to keep up and accept them. It means that if overflow occurred due to a burst, the connection will recover. Enable this option only if you are really sure that the listening daemon cannot be tuned to accept connections faster. Enabling this option can harm the clients of your server.
改完再測試,抓包檢視,報文很清爽,再沒有一堆重傳了:
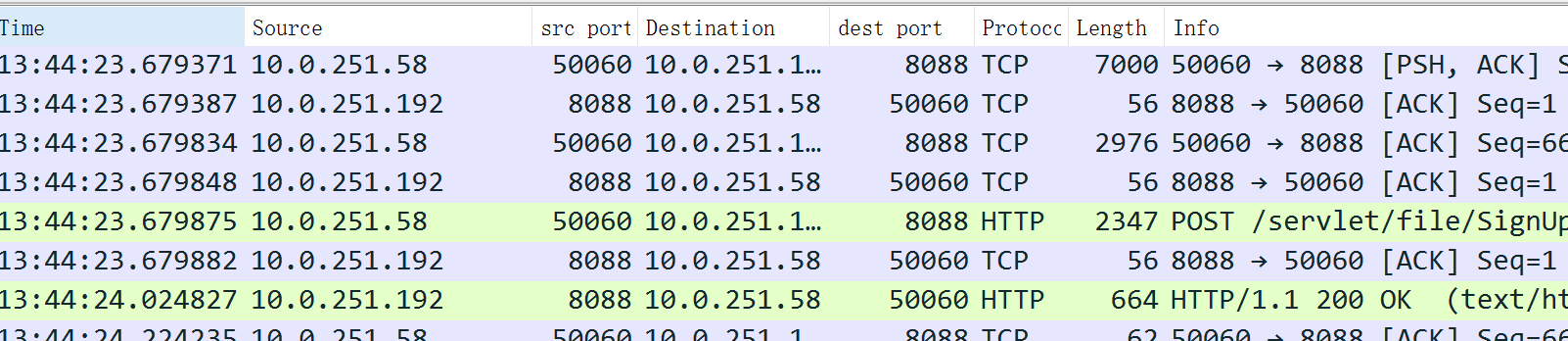
補充
如需檢視nginx在location眾多時,到底發給了哪個後端upstream,不用像我上面那樣用strace,太複雜了,我查了下,可以這樣:
http://nginx.org/en/docs/http/ngx_http_log_module.html
官方檔案的access_log中,預設包含了一個紀錄檔format為combined,內容:
The configuration always includes the predefined 「combined」 format: log_format combined '$remote_addr - $remote_user [$time_local] ' '"$request" $status $body_bytes_sent ' '"$http_referer" "$http_user_agent"';
我們可以增加一個屬性$upstream_addr,即可展示轉發到哪個upstream了:
http://nginx.org/en/docs/http/ngx_http_upstream_module.html
log_format combined1 '$remote_addr - $remote_user [$time_local] '
'"$request" $status $body_bytes_sent '
'"$http_referer" "$http_user_agent" $upstream_addr' ;
access_log logs/access.log combined1;
效果如下:

參考檔案
https://mp.weixin.qq.com/s/2qN0ulyBtO2I67NB_RnJbg
http://04007.cn/article/323.html nginx設定listen的backlog