開始之前
本篇文章僅僅是針對SQL Server 2022新推出功能的概覽,以及我個人作為使用者視角對於每個功能的理解,有些功能會結合一些我的經驗進行描述,實際上,SQL Server 2022在引擎層面的增強的確算是里程碑級別,涉及到的每一個功能點展開都可以單獨開出一篇文章。但本篇文章只是一個概覽性文章,並不會深入解釋每個功能。
本篇文章側重於討論SQL Server 2022引擎本身,與Azure的整合以及對S3 Blob的整合、On Linux與K8S的部署層面增強不在本文的討論範圍內。
測試環境
本篇文章會對一些新功能進行測試,但不會進行深入測試,僅做初步的驗證,因此環境以簡單為主,用完即釋放。
阿里雲RDS for SQL Server 2022企業叢集版
mssql.x4.medium.e2(2c8g)
範例資料庫:https://github.com/microsoft/sql-server-samples/tree/master/samples/databases/wide-world-importers
Built-In Query Intelligence
SQL Server 2022引入的部分功能是能夠立竿見影地提升效能的,也是帶來最大提升的部分。對於大多數產品來說,要想提升產品效果就需要改變使用行為,這通常會帶來較高的成本。相比之下,單純提升產品本身的能力而不改變使用方式是增益最大的。
舉個例子,在手機電池電量不變的情況下,改變使用習慣,例如手動經常關閉不使用的功能節省電量,與作業系統定期根據特定規則自動關閉功能節省電量相比,前者的成本會遠遠大於後者。
對於資料庫也是類似的情況。很多新功能可能需要應用程式程式碼的變更,這會帶來較高的使用成本。相比之下,如果在核心層面進行增強,僅需設定部分功能的開關,這部分的使用成本就會比較低。
Build-In Query Intelligence的整個一個大圖如下,可以看到Query Store是實現這一些基礎的核心,那什麼是Query Store?
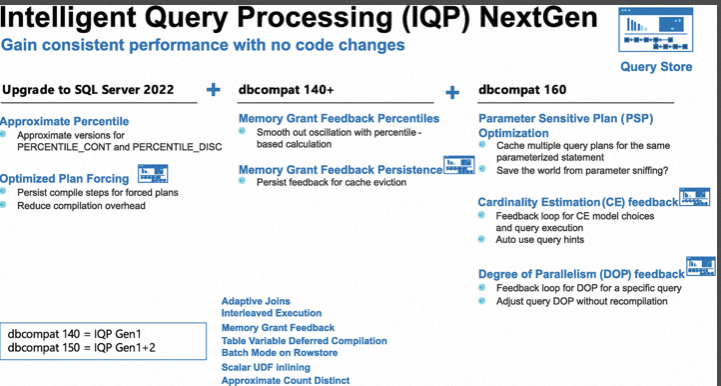
Query Store
過去DBA有一部分比較重要的工作就是效能調優,而效能調優中有一部分比較重要的工作就是「建立Baseline」,打個比方,建立Baseline能夠就好比一個人定期去體檢,健康狀態下的指標就類似於Baseline,也就是一個人正常狀態下的指標,當人感覺不舒服時,使用檢查的資料比對Baseline可以快速縮小病因範圍,類似的,當系統出現瓶頸時,通過當前指標與Baseline比較能夠幫助快速縮小排查範圍。
另一部分效能調優的工作是捕捉「慢SQL」,通過定期捕捉高資源消耗的語句,人為針對這些語句進行調優。
SQL Server雖然內建了不少DMV記錄統計資訊,但這部分資訊基於記憶體,重啟後就消失, 同時只有聚合資料,沒有細分資料。
上述兩部分都需要進行資料收集,這個動作通常需要有一定SQL Server基礎,同時也需要額外部署監控收集-資料處理-展示 等多個元件。
傳統的方式是通過外掛收集器進行,例如我之前提到的阿里雲RDS for SQL Server效能洞察體系。
而SQL Server自從2016以來引入了Query Store,能夠將已執行SQL效能的各類後設資料隨資料庫持久化到磁碟,啟用方式僅為一個選項。這些後設資料包括:
-
執行計劃多版本資訊
-
執行計劃統計資訊(IO、CPU使用等)
-
等待型別資訊
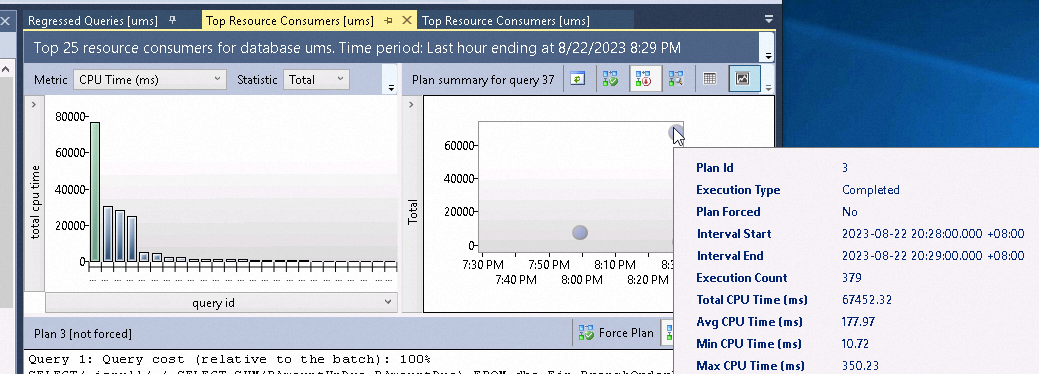
例如,我們通過Query Store可以按照CPU 對Query進行排序,每分鐘做一次彙總,比如下圖中該SQL只對應1條執行計劃,1分鐘執行379次,CPU時間等相關資訊。
那麼有了Query Store,過去DBA的調優方式簡化版本:
-
發現慢
-
人為介入,找到慢SQL
-
調優慢SQL
-
上線,觀察效能,如果不達預計重複調優步驟
Query Store演進了好幾個版本,到了SQL Server 2022作為預設啟用的選項,預設啟用意味著微軟需要為該功能引起的副作用負責,因此在我看來該功能已經進入到非常成熟的階段。
因此Query Store作為下面談到的幾個優化器功能提供決策資料。
Cardinality Estimation Feedback
一個SQL從語法解析到最終生成的執行計劃會在優化器經歷一系列過程,一個SQL解析出的執行計劃質量高低通常和SQL效能有直接關係,而解析的過程需要參考各類資料,這些資料的準確性對執行計劃的至關重要,就好比你希望去逛商場,那麼從家到商場如何最快取決於路上是否堵車,如果堵車則地鐵會比駕駛汽車更快,反之則地鐵更快,「路上的交通狀況」這個後設資料對做出更好的「執行路徑」就非常重要。
一個SQL解析為執行計劃也要參考很多後設資料,例如統計資訊、是否有索引、過濾後的預估行數等等。而Cardinality Estimation指的是SQL在存取表活物件根據過濾或Join等操作後,預估的行數,該行數的準確性直接影響執行計劃的質量。
SQL Server從7.0 到2014之前(相容級別低於2014)評估是基於這樣一個假設,資料之間沒有關聯,例如where a =1 and b=2 的預估行數= a的選擇性*b的選擇性*總行數。
SQL Server 2014以上(相容級別>=2014)的預設的場景是資料有較多關聯,而同一個表多個條件之間預估行數應該更多,具體演演算法見連結。
這兩者之間適應不同負載型別,舊模型更適合關聯度低簡單的負載型別,新模型適合更復雜的查詢(微軟稱之為「modern workload」),之前可以通過相容級別全域性控制也可以通過hint單獨控制,無論哪種方式都不完美。
2022提供的機制是通過歷史查詢提供反饋,查詢優化器和Query Store之間聯動,編譯SQL找出不同CE成本差異比較大的語句,並嘗試附加CE Hint,並根據Query Store的結果糾正這一機制(附加Hint提升不明顯甚至效能下降,類似下圖,摘自Bob ward)。
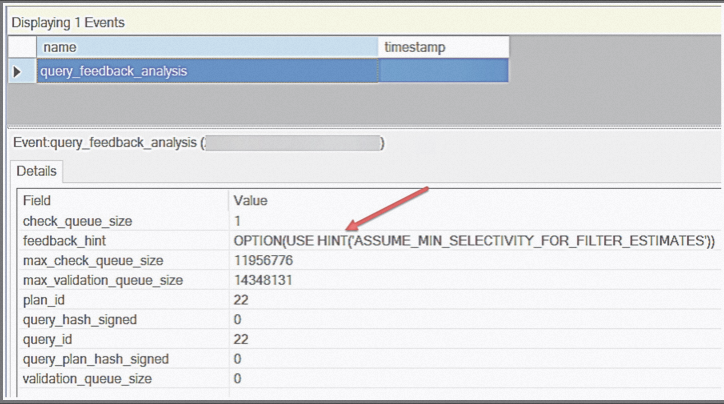
這意味著CE模型可以針對不同Query進行Per Query級別的適配,這部分工作已經是一個高階DBA的工作了,也就是根據多次歷史記錄做出優化決策,啟用該功能無需應用程式適配,只需要滿足下述條件:
-
啟用Query Store
-
相容級別160
Memory Grant Feedback
SQL Server在執行Query中,一些操作會明顯依賴記憶體,比如Sort或Hash Join,執行計劃中會預設對記憶體的使用量提前申請,這裡就會遇到兩個問題:
-
記憶體申請過多:浪費記憶體是一部分副作用,分配記憶體的等待也會導致Query需要更長的時間(尤其是高並行Query)。
-
記憶體申請過少:那麼查詢所需的記憶體不夠,就需要TempDB補齊,TempDB位於IO子系統,記憶體速度和IO速度通常不在同一個量級,導致查詢會變慢非常多,SQL Server中稱之為「spill to tempdb」。
記憶體授予的多少取決於執行計劃,比如Sort 1萬資料和10萬資料所需的記憶體肯定不同,但執行計劃很多時候估計並不精準,導致記憶體的不準確
SQL Server 2022提供了基於Query Store的記憶體歷史記錄,根據一個Query歷史執行所需的實際記憶體,決定最新的查詢的記憶體授予,但這也是基於閾值,只有記憶體授予差異極大的場景下才會進行記憶體授予的調整。
啟用條件:
-
相容級別140(2017)以上
Parameter-Sensitive Plan (PSP) optimization
前面提到,SQL Server中Query->執行計劃的過程需要依賴的後設資料依賴於成本預估,成本預估的一個先決條件就是引數本身。例如where a =1 返回1萬行 和where a=2 返回1行,執行計劃通常不一樣。比如下圖引數1對應的就是1次Seek,引數2對應就是一次Scan:
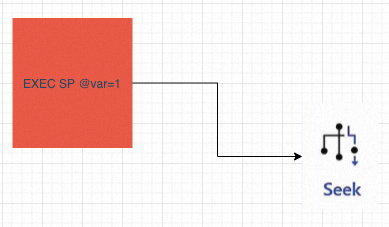
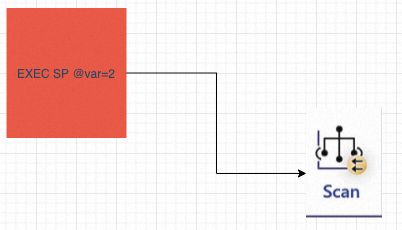
另外,SQL Server與Oracle這類商業資料庫牛逼的點是處理複雜SQL的能力(某種程度上是優點也是缺點,強大的SQL引擎導致濫用,相比mysql pg來說,一般使用的SQL會簡單很多,更適應今天DDD的設計理念和微服務的部署方式,當然這是另外的話題),我見過最大的執行計劃是一個1萬多行的儲存過程生成,執行計劃本身80MB。
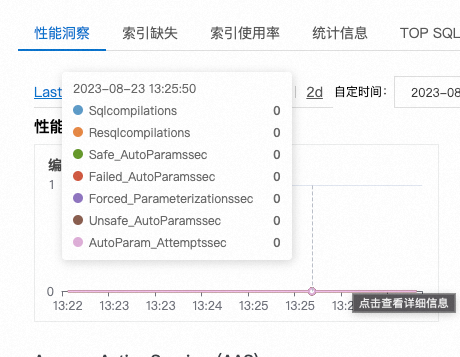
這類執行計劃編譯本身的成本就很高,不僅消耗CPU還會增加語句執行時間,當類似的語句並行出現,還可能導致系統層面的編譯瓶頸,一般有等待型別和效能計數器展示這一點,比如在阿里雲控制檯擷取的幾個相關效能計數器:
因此將已經編譯的執行計劃快取起來就是一個更好的選擇。此時又會面臨另外一個問題,已經快取的執行計劃不準怎麼辦?使用快取的執行計劃成本遠高於重新編譯怎麼辦?在此之前這個問題一直是給DBA同仁們留了一口飯吃,瞭解這個概念和不瞭解這個概念也是是否入門的分水嶺:-)
傳統的手段也是各顯神通,從SQL上就是對引數寫法的優化、定期更新統計資訊,針對語句加recompile hint,調整索引,拆分SQL,高階一點的主動監測高消耗語句定點對單個快取進行清理,當然還有更low的,直接重啟(重啟後所有執行計劃快取不存在,因此全部重編譯)。
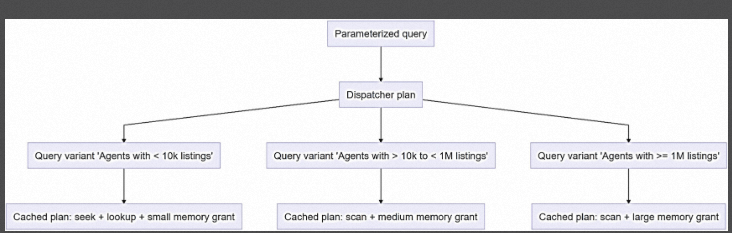
SQL Server 2022開始引入的PSP,用來解決這個問題,由於Query Store有能力對一個SQL快取多個執行計劃,因此根據引數選擇更適合的執行計劃就是很牛逼,大概原理就是:
在Query Hash -> plan cache hash中間增加dispather,根據dispather決定使用什麼快取的執行計劃。該功能對於較多複雜查詢的略巨量資料庫絕對是大殺器級別,雖然目前我還沒有機會看到一些案例,但根據經驗這個功能會極大減少運維門檻。
啟用條件:
相容級別160(SQL Server 2022)
Degree of Parallelism (DOP) Feedback
SQL Server的一個指標是「最大並行度」,另外是「並行開銷閾值」,前者指的是是一個Query最大可以使用多少的Core並行執行,後者是執行成本達到某個值就會走並行。
這兩個值是90年代的產物,預設值分別為0和5,0指的是SQL Server自行控制使用多少Core並行執行,基本等於當前機器所擁有的物理核數,在現代機器上,由於多個Socket和Numa的存在,這種設定極為不合理,對於典型的OLTP系統我們都預設調整為2或4,當然部分OLAP類語句也會單獨做一些設定。
「並行開銷閾值」預設為5也是極低的值,今天的硬體能力已經完全不一致,過去多核CPU完成的任務,今天CPU單核甚至更快,因為並行存在較高Core的協同成本,如果太低會導致協同成本甚至高於Query執行成本。
這兩個值是範例級別,雖然後續引入到了庫級別,但Scope還是過大,可能類AP語句需要DOP更大,而TP類甚至設定為1更合理。
DOP Feedback和上面提到的其他Feedback類似,都是基於Query Store,根據歷史收集的反饋經驗,Query Store後臺任務會根據一系列因素判斷查詢是否適合使用DOP反饋,包括查詢執行次數、持續時間、並行效率等,根據內建的規則針對語句動態調整DOP:
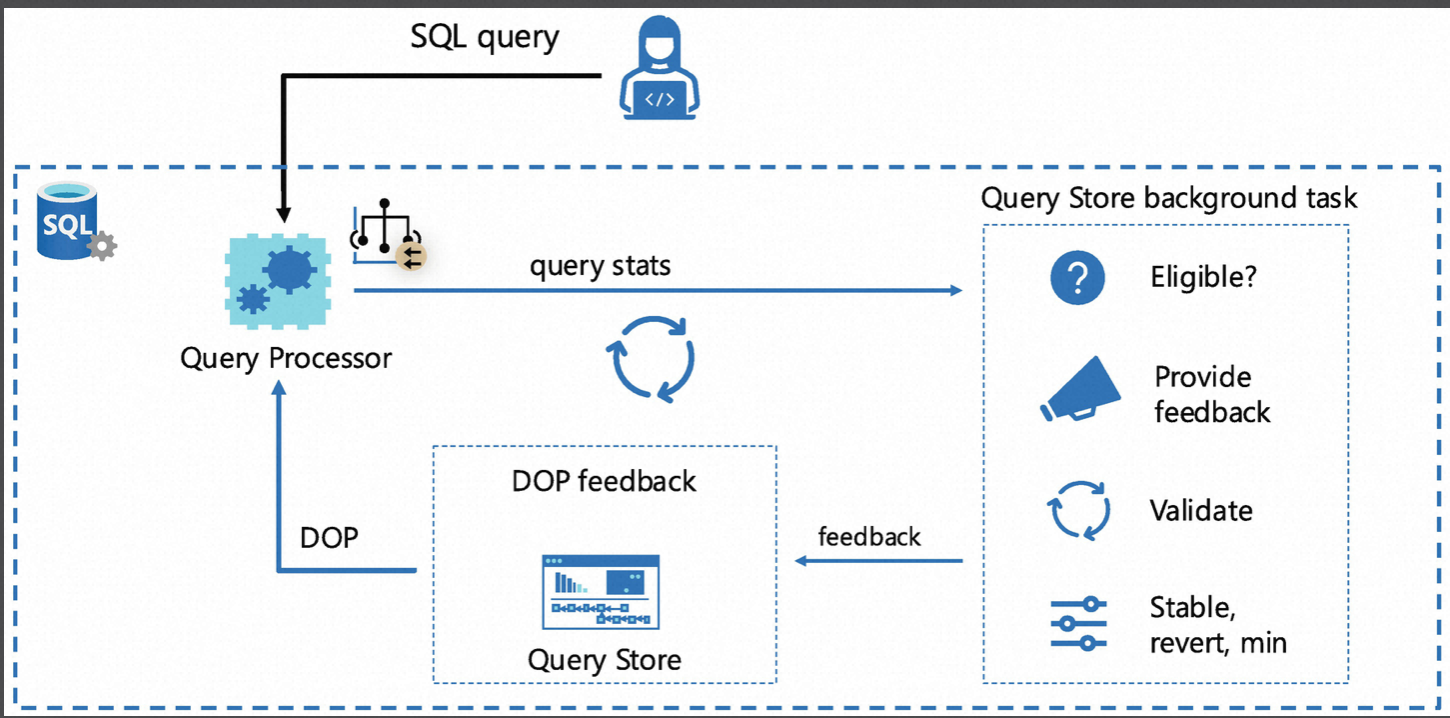
啟用條件:
ALTER DATABASE SCOPED CONFIGURATION SET DOP_FEEDBACK = ON
小結
Build-In Query Intelligence讓SQL Server在優化器做決策時,能夠根據歷史資料做出更好的調整,這在自適應能力上已經到達新的高度。在我看來,未來資料庫也應該向這個方向走,資料庫作為底層平臺系統,絕大多數場景更應該讓使用者更關注業務,而不是底層資料使用的複雜性。
上面提供到的所有功能都能讓系統在不做任何程式碼變更的情況下,大幅提升效能和穩定性,因此如果有條件,建議去升級2022,並啟用Query Store。
如果對自適應資料庫的一些概念感興趣,可以讀一下Andy Pavlo 大神的一篇舊聞What is a Self-Driving Database Management System?。
資料庫引擎層面
Ledger for SQL Server
賬本資料庫是SQL Server 2019引入的,在2022做了部分增強,利用區塊鏈做防篡改和0信任相關的分散式賬本資料庫。這類功能和SSL和TDE一樣,在國內都屬於弱需求,對於業務方來說都屬於「我不需要,但監管等第三方讓我必須要」,這裡就不多贅述了。
System page latch concurrency
該功能又是一勞永逸的解決TempDB後設資料的問題。
每次做DDL時,例如建立表、刪除表等需要修改資料庫標記內部分配使用的後設資料,SQL Server內叫PFS頁,通常情況這個點不應該成為瓶頸,但是臨時表和表變數就是特殊的DDL語句,如果高頻高並行建立臨時表和表變數,就是需要高頻修改PFS頁,PFS頁修改本身通過「悲觀並行控制」,也就是通過資料庫內一種保護記憶體結構特殊的鎖,學名Latch Lock,這本身會成為資料庫的一種瓶頸。
多年來作為SQL Server DBA一個常識就是建立範例根據機器核數多少,TempDB至少4個檔案起步,多個檔案意味著多個PFS頁,減少鎖阻塞發生的概率。
SQL Server 2022通過「樂觀並行控制」更新PFS頁,基本就能解決爭搶問題,而僅對少數系統頁做樂觀並行成本也可控。這個提升還是為了減少運維
該選項需要手動啟動:
ALTER SERVER CONFIGURATION SET MEMORY_OPTIMIZED TEMPDB_METADATA = ON
Buffer Pool Parallel Scan
Buffer Pool是基於記憶體結構,記憶體的隨機查詢成本很低,更適用於Hash結構,因此隨機查詢通常不是問題,但對於大規格範例的掃描通常成本高昂,值得大規格通常是256GB以及以上記憶體。當記憶體>64GB時,過去單執行緒的Buffer Pool掃描變為多執行緒,會提升掃描效能。
受影響的操作包括:
-
資料庫啟動
-
資料庫關閉或重啟
-
AG 故障轉移
-
刪除資料庫 (刪除)
-
從資料庫中刪除檔案
-
完整或差異資料庫備份
-
資料庫還原
-
事務紀錄檔還原
-
聯機還原
這個功能從我的體驗,針對256G以上記憶體的範例有提升,尤其是AlwaysOn發生故障轉移時會快很多,其他場景並沒有太明顯的感覺,所以適用面有限。
HA/DR
AlwaysOn
Contained Availability Groups
這個功能主要是允許AlwaysOn 叢集包含Contained Database,也就是過去範例級的物件比如作業、Login、連結伺服器物件能夠隨著資料庫遷移,或隨著HA切換保證一致性。
這個功能我想是更進一步降低運維成本,畢竟發生HA之後,如果作業或者Login丟了,基本等同於故障,而Contained到資料庫中由核心保證一致性會穩定很多。
AlwaysOn 恢復執行緒擁有更高死鎖優先順序
原文描述:The database recovery task is now run with a higher deadlock priority to avoid being chosen as a deadlock victim with user transactions.
也就是說用於recovery的系統執行緒Session死鎖優先順序為「高」。
這個事情雖然概率低,但我不幸遇到過,微軟早就應該這麼設計了,我曾經遇到過AlwaysOn切換之後,使用者新連線將Recovery執行緒作為死鎖kill掉,導致資料庫一直沉迷在Recovery狀態,重啟後才解決,直接導致了不可用時間。
AlwaysOn其他增強
原文描述:
We fixed a problem where a replica database would get stuck in a recovery pending state.
Ensured data movement is not paused to replicas due to internal log block errors.
Eliminated schema lock contention problems on secondary replicas
想起那個句話,懂得都懂,上面3條我更不幸全遇到過,最壞的結果就是重搭AlwaysOn,一次幾T資料,簡直比吃了老譚酸菜面還酸爽。當前提升還沒有機會驗證,有機會驗證後補充一下實際效果。
DR
Accelerated Database Recovery
關聯式資料庫一個很重要特點就是「ACID」其中,D指的是永續性,保證永續性一個很重要的點是「崩潰一致性」的恢復。比如資料庫在斷電、程序崩潰的情況下,資料庫中資料一致性不應該受到影響。
而實現這一點就是在下次資料庫啟動時,進行Recovery動作,也就是事務未提交,但已落盤的資料進行rollback,事務已提交,但在記憶體中未落盤的髒頁進行redo,整個過程也就是所謂的「undo/redo recovery」。
但recovery過程的長短取決於程序崩潰、重啟、關機時最早的活動事務,我見過recovery 8個小時的過程,使用者在半夜做了大量的ETL操作,存在幾百G的活動紀錄檔(Active transaction log),後重啟範例,需要完整掃描幾百G的紀錄檔並做Recovery。直接導致8個小時的不可用時間(哎,差點背鍋,不堪回首:-( )。
微軟在之前版本為了解決慢的問題,做過並行Recovery,但根據我的經驗效果比較一般,與此同時,還出現過並行Recovery程序之間死鎖(這個真背過鍋,越想越氣-.-)。
ADR是2019引入,2022做了很多機制上的增強,的基本原理是通過多版本並行控制,因此弊端類似事務快照隔離,需要更多的儲存空間和額外的CPU和記憶體使用。
因 此帶來的收益:
-
大事務不會導致紀錄檔增長失控
-
降低大事務回滾導致的資料庫不可用
-
解決非常久的Recovery時間問題
https://cloudblogs.microsoft.com/sqlserver/2023/03/28/accelerated-database-recovery-enhancements-in-sql-server-2022/ 微軟官方部落格的驗證資料是49秒和4秒的Recovery時間區別,提升還是很巨大的。
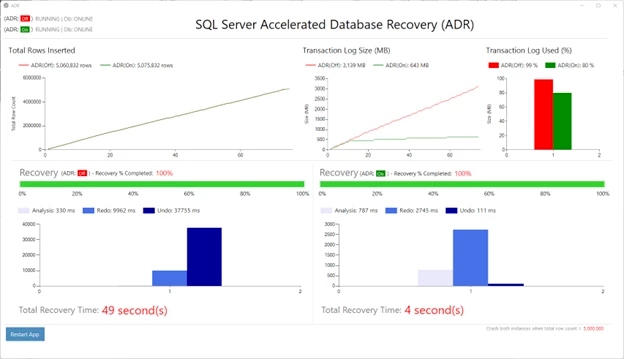
總結一下,Recovery時間可以從過去最早的事務紀錄檔,到現在最近一個Checkpoint(一般60S),將會極大降低恢復時間,與此同時由於資料快照存在,紀錄檔可以更激進的truncate,還避免了磁碟空間問題,因此,建議對於幾百G以上,負載較高,同時經常有長事務的資料庫,啟用該功能能夠提升可用性。
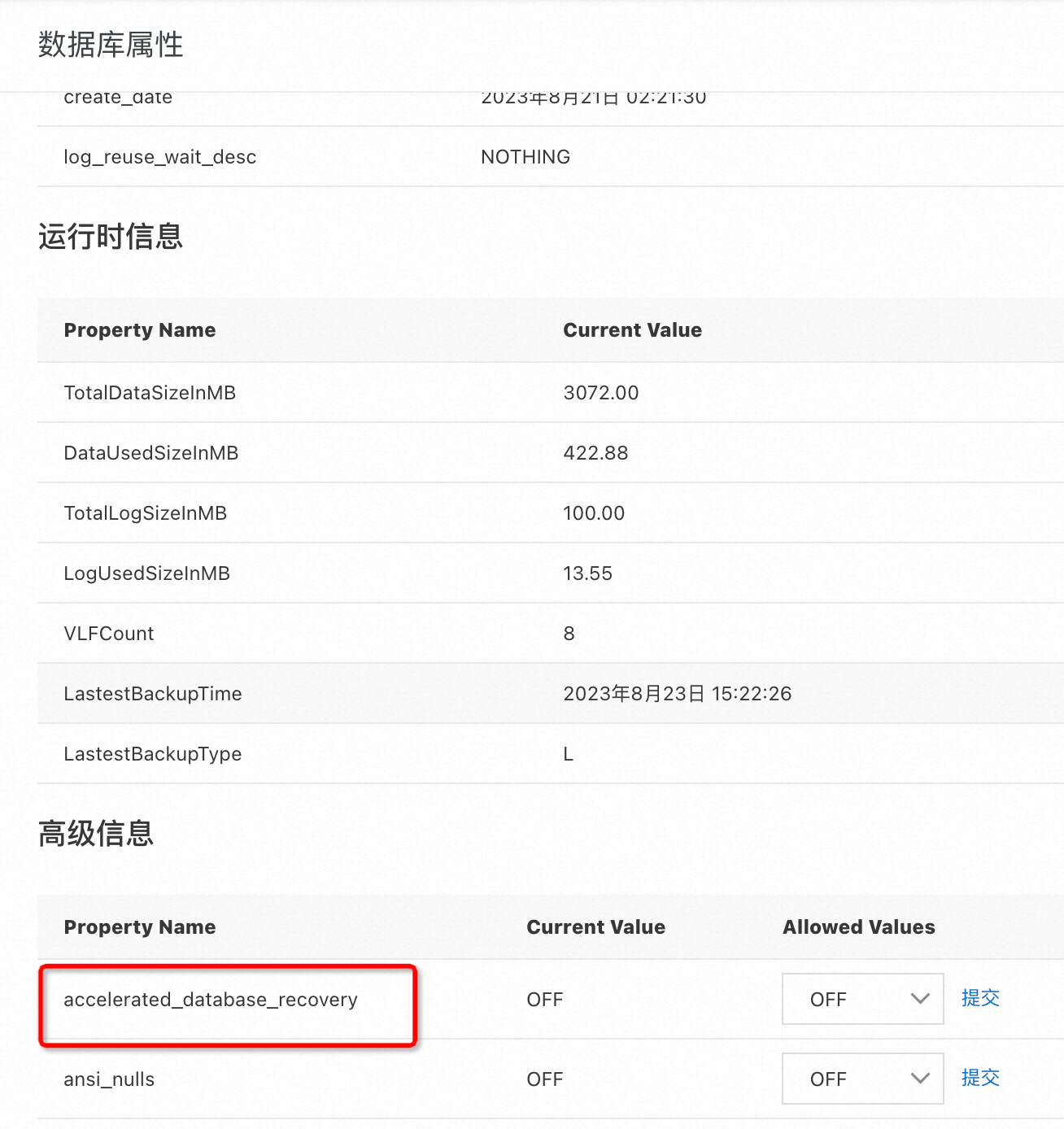
在阿里雲RDS控制檯直接修改該資料庫的屬性。
Parallel Redo Enhancements
Parallel Redo主要是AlwaysOn使用,但效果有限,有時候我們甚至需要關掉,2022的優化是將Worker限制100挪掉,對於資料庫數量較多的範例會有幫助,但不知道之前並行Redo的一些問題是否得到修復。
T-SQL 增強
JSON
JSON基本已經是當今絕大多數資料交換的事實標準了,SQL Server 2016開始在T-SQL支援JSON,2022新增了JSON_ARRAY和IS_JSON函數,看名稱基本知道做什麼的,細節可以看微軟檔案。
一般來講,今天的應用程式在JSON的處理已經非常成熟,擁有成熟的類庫和方案,在資料庫側做JSON的解析通常得不償失,所以這裡不再贅述
時序資料函數
-
DATE_BUCKET
-
GENERATE_SERIES
-
FIRST_VALUE 和 LAST_VALUE
都是一些和時間相關的函數,具體看微軟官網
雜項
-
DATETRUNC
-
STRING_SPLIT
-
IS [NOT] DISTINCT FROM
小結
針對資料庫內建提供SQL方言的額外能力,我一直持保守態度,資料庫因為自身的特點,Scale-Out成本是非常高的,而應用因為無狀態更容易Scale-Out,同時應用語言做邏輯處理能力更加強大,因此個人通常更傾向於在資料庫外側完成工作,把資料存取以外的計算能力外移到應用。
安全性
Always Encrypted提升
這個功能本身用於端到端加密,應用程式側掌握加密Key,整個鏈路資料都是加密的。SQL Server中無法檢視加密後的資料,我個人覺得可能是用於解決客戶和雲廠商的信任問題,雲PaaS側即使負責運維資料庫,也無法檢視資料庫的內容。
2022中做了一些提升,將應用的Key放到SQL Server的安全區域,以便一些字串操作生效,例如Like操作,這裡不再贅述。
加密提升
主要是支援TLS1.3支援鏈路加密,這類功能主要滿足合規需求,不再贅述。
新增部分系統預設角色
例如##MS_DefinitionReader##、##MS_ServerStateReader##、##MS_ServerPerformanceStateReader##,主打一個能看系統的各類效能資料,不能看業務資料,或許是方便一些第三方的運維人員使用,又擔心洩漏資料,在我看來這類功能在國內比較雞肋。
總結
SQL Server 2022整體來看還是比較值得投入升級,尤其是「自適應查詢」部分雖然還沒有到「自動駕駛」這麼強,也算是進入L2.5輔助駕駛級別了。
其他HA/DR 方面的提升也讓人期待,尤其是DR恢復時間的極大縮短,帶來的提升對於企業級應用至關重要。
如果你的資料庫的可用性和效能問題是當前的痛點,對SQL Server 2022的升級的投入會帶來驚喜。
注:本篇文章沒有涉及到和Azure/AWS聯動部分,也沒有涉及到K8S、On Linux部分,另外快照備份由於場景小眾也沒涉及。
參考資料:
SQL Server 2022 Revealed: A Hybrid Data Platform Powered by Security, Performance, and Availability
Bob Ward
SQL Server 2022官方部落格:https://cloudblogs.microsoft.com/sqlserver/tag/sql-server-2022-blogging-series/