MIT6.s081/6.828 lectrue07:Page faults 以及 Lab5 心得
本篇部落格主要是複習 MIT6.s081/6.828 lectrue07:Page faults 以及記錄 Lab5 :COW fork 的心得
值得一提的是,2020 年之前的版本第 5 個 lab 是 lazy alloction,但是到了 2020 年之後就換成了難度稍高一點的 COW fork,有興趣的小夥伴可以把 lazy alloction也一起做一做~畢竟這些 lab 都是精心設計的,不做蠻可惜的。
前面 6 節課程,Frans 教授的授課風格都是一邊講解,一邊實際操作 xv6 來演示,但這節課有所不同,以理論講解為主,主要是因為對應的程式碼在 xv6 中都沒有實現,而是作為 lab 要求學生來實現,所以教授無法演示,但今天的理論也很好理解,而且十分「漲見識」,我在沒學之前完全沒有意識到 Page faults 竟然有如此多的作用。(以下有時對 Page faults 簡稱 pf)
借用權遊中的著名臺詞:混亂是階梯。
這句臺詞完美描述了 Page fault 的設計哲學!
Page fault 概述
Page fault(頁錯誤)是 OS 中的一種異常情況,當程式存取一個虛擬記憶體中的 page 時,發現該地址無效(可能是在頁表中找不到,或者是找到之後 PTE_V 標誌位為 0)。
xv6 對於 Page fault 的處理十分簡單粗暴,就是直接殺死程序,但實際上沒有任何真實世界的 OS 會這麼幹,因為 「Page fault 是階梯」,可以利用它做很多有益的事情。
page fault 提供的資訊
當程式發生 page fault 時,OS 應該考慮如何處理,而不是簡單粗暴的殺死程序,正如我們遇到問題,要先了解問題才能解決之一樣,OS 要處理 page fault,需要了解 page fault 的以下資訊:
- 出錯的虛擬地址,當出現 page fault 的時候,是由於頁表中找不到這個地址對應的 PTE 或者 PTE 無效,這裡的出錯的虛擬地址值得就是這條"找不到的地址",XV6 核心會列印出錯的虛擬地址,並且這個地址會被儲存在 STVAL 暫存器中。
- 出錯的原因,檢視 RISC-V 檔案可知有三種引起 page fault 的原因:load 引起的 page fault;store 引起的 page fault;指令執行引起的 page fault。這個資訊存在 SCAUSE 暫存器中,總共有3個型別的原因與page fault 相關,分別是讀、寫和指令
- 觸發 page fault 的指令的地址,即 page fault 在使用者空間發生的位置。從上節課可以知道,作為trap處理程式碼的一部分,這個地址存放在 SEPC 暫存器中,並同時會儲存在trapframe->epc 中。
處理 page fault
有了以上三條資訊,OS 就有能力處理 page fault 了,xv6 對於 pf 採取了非常保守的處理方式,即直接殺死程序,但是在稍微正式一點的作業系統中都不會這麼簡單粗暴,因為藉助 pf 可以實現很多功能,比如:
- lazy page allocation
- copy-on-write fork(會作為 lab 出現)
- demand paging
- memory mapped files(會作為 lab 出現)
比如Linux就實現了所有的這些功能。
為什麼藉助 pf 可以實現這些功能,歸根到底還是 pf 會導致 trap 到 kernel mode,在 kernel mode 中,就可以做很多「魔法」。下面會依次介紹這些 pf 的處理方式。
Page fault 作用
page fault 是階梯,觸發 page fault 後,我們可以在 page fault handler 中做很多事情,其中最重要的就是「懶載入」,下面的 lazy allocation、Zero Fill On Demand、COW fork 、Demand paging 、Memory mapped 的核心思想都是「懶載入」。
Lazy allocation
XV6提供了一個系統呼叫叫 sbrk,這個系統呼叫的核心實現如下:
uint64
uvmalloc(pagetable_t pagetable, uint64 oldsz, uint64 newsz, int xperm)
{
char *mem;
uint64 a;
if(newsz < oldsz)
return oldsz;
oldsz = PGROUNDUP(oldsz);
for(a = oldsz; a < newsz; a += PGSIZE){
mem = kalloc();
if(mem == 0){
uvmdealloc(pagetable, a, oldsz);
return 0;
}
memset(mem, 0, PGSIZE);
if(mappages(pagetable, a, PGSIZE, (uint64)mem, PTE_R|PTE_U|xperm) != 0){
kfree(mem);
uvmdealloc(pagetable, a, oldsz);
return 0;
}
}
return newsz;
}
很容易就看明白其中使用 kalloc() 和 mappages() 函數分配實體記憶體並且在頁表中新增新的 PTE(如果看不明白說明 lectrue04:page table 沒有學好哦,快來這裡複習),所以 sbrk 的作用就是應用程式用來申請新的記憶體空間
在XV6中,sbrk的實現預設是 eager allocation。即一旦呼叫了sbrk,核心會立即分配應用程式所需要的實體記憶體。但是實際上,對於應用程式來說很難預測自己需要多少記憶體,所以通常來說,應用程式傾向於申請多於自己所需要的記憶體。以矩陣計算程式為例,程式設計師需要為最壞的情況做準備,比如說為最大可能的矩陣分配記憶體,但是應用程式可能永遠也用不上這些記憶體。所以,程式設計師過多的申請記憶體但是過少的使用記憶體,這種情況還挺常見的。
所以就引出了lazy allocation 的概念。核心思想非常簡單,摒棄 eager allocation,sbrk 被呼叫時不會立即分配記憶體,只是記錄一下"假如真的分配了記憶體,那麼現在應用程式可用的記憶體是多少"(在實際的 xv6 中,這個值是由 p->sz 記錄的,他表示堆頂指標)
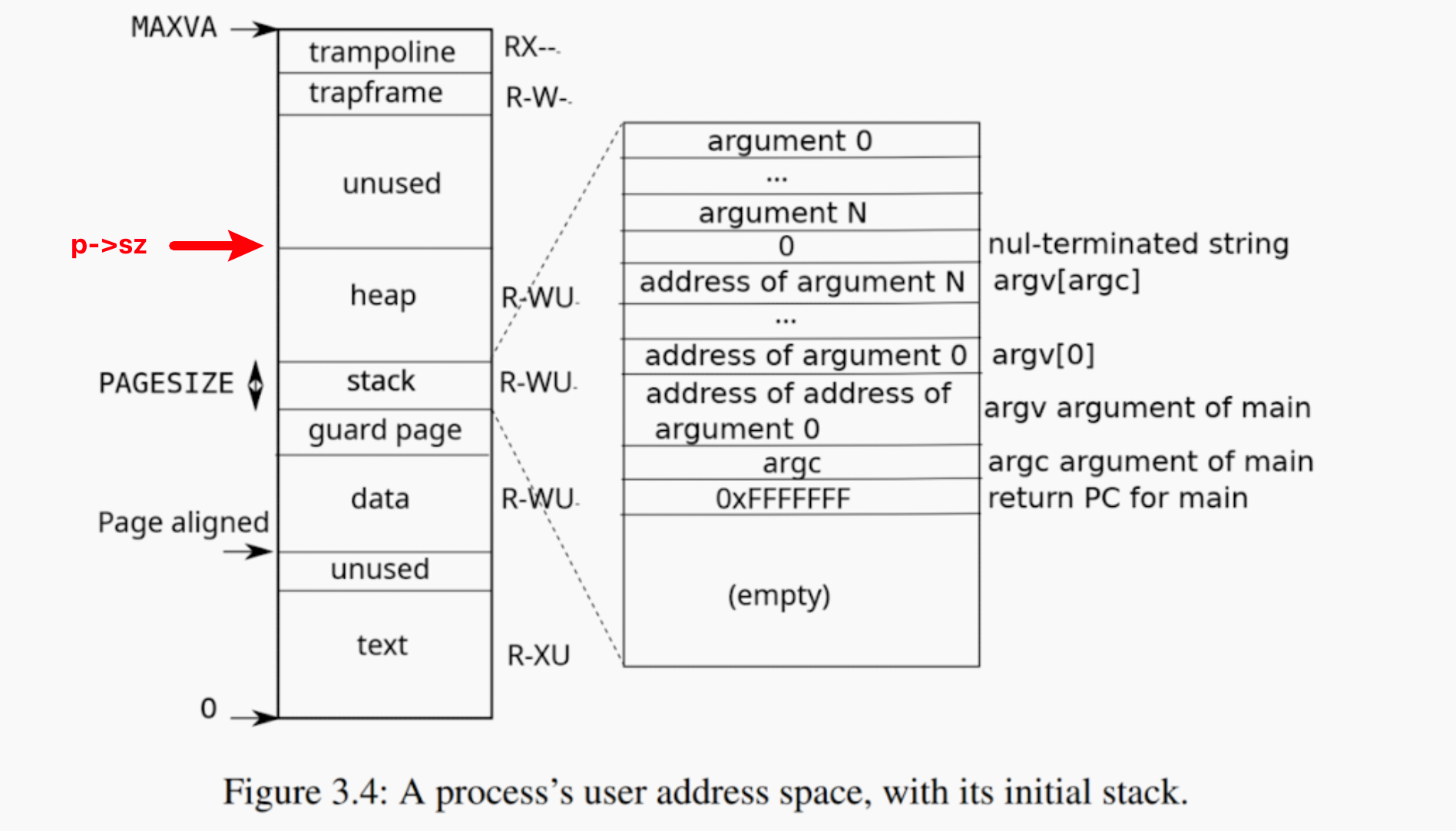
當應用程式真的用到了新申請的這部分記憶體,由於沒有分配、頁表中沒有對映,自然找不到相應PTE,這時會觸發page fault,但是 kernel 會識別到:要存取 va 小於新的 p->sz,並且大於舊的 p->sz,就知道這是一個當初假裝分配的地址,所以這時才會真正分配實體地址並且在使用者程式的頁表中新增 PTE,所以在 page fault handler 中就會:
- 在page fault handler中,通過kalloc函數分配一個記憶體page;並初始化這個 page 內容為0;
- 將這個記憶體 page 對映到 user page table 中;
- 最後重新執行指令(SEPC 暫存器記錄了發生 pf 時的地址,所以可以回到「事發地」重新執行指令)
總之,lazy allocation 的核心概念就是「將分配實體記憶體 page 推遲到了真正存取這個記憶體 page 時做」。
Zero Fill On Demand
再次搬出這張圖:一個使用者程式的記憶體分佈圖
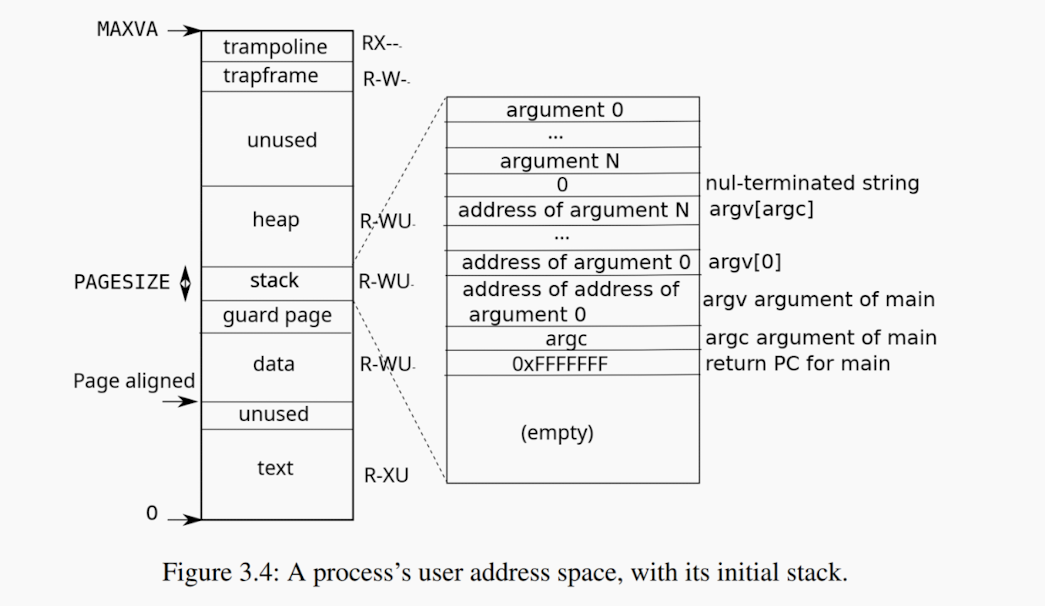
但是這張圖省略了一點佈局,就是除了 text 區域,data 區域,同時還有一個BSS區域,BSS 區域位於 data 區域之後。text 區域存放是程式的指令,data 區域存放的是初始化了的全域性變數,BSS 包含了未被初始化或者初始化為0的全域性變數。
之所以要建立這個 BSS 區域,是因為作為全域性變數,元素初始值都是 0 的情況還是蠻多的,比如在 C 語言中定義了一個大的矩陣作為全域性變數,那麼它的元素初始值都是 0。由於 BSS 裡面儲存了未被初始化的全域性變數,這裡可能有很多 page,但是所有的page內容都為0。每個 page 都需要分配實際的實體記憶體空間:
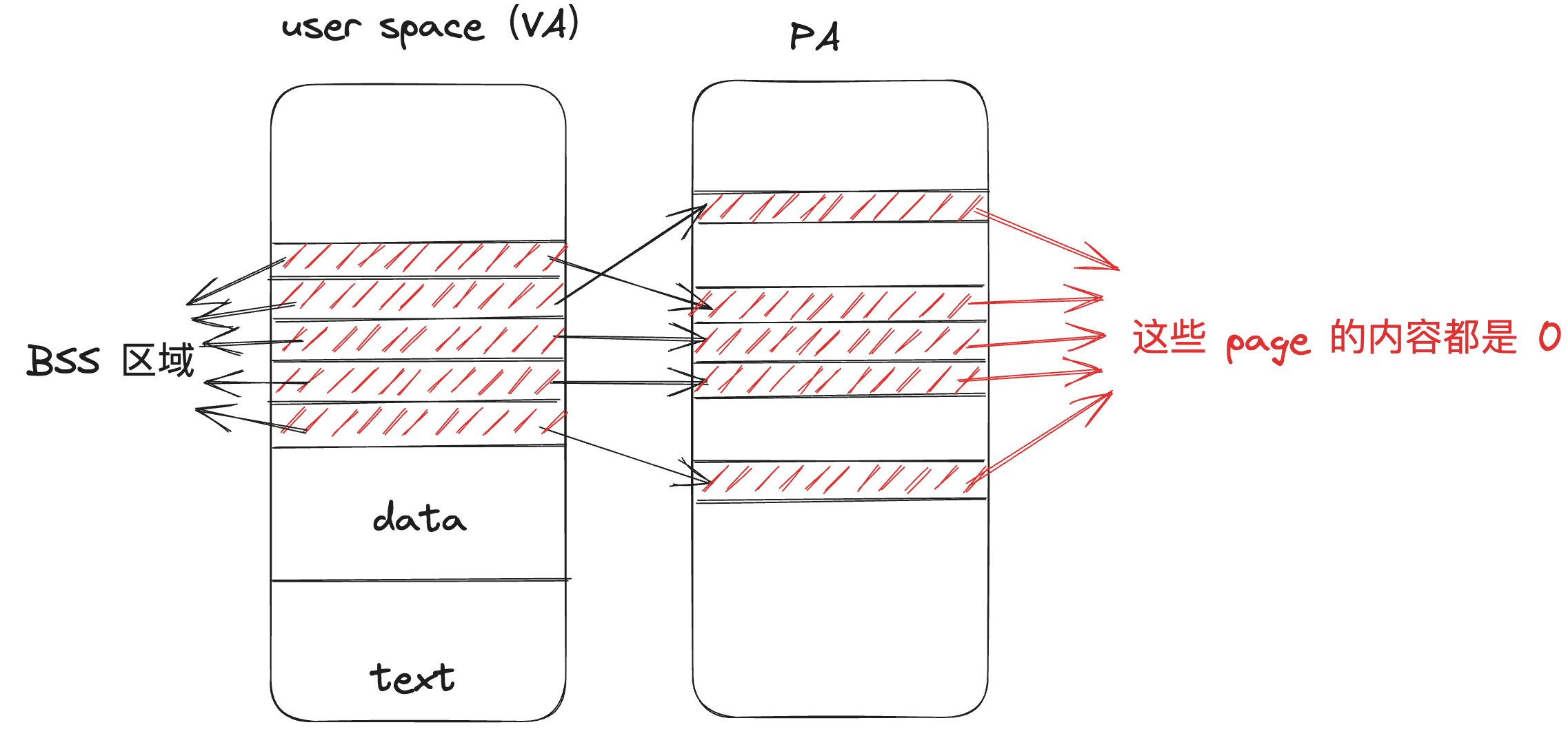
但如果採用 Zero Fill On Demand ,那麼 BSS 區域的 page 就不需要全部到不同的實體記憶體上,而是都對映到同一個物理 page 上,之所以能這麼做,是因為所有的 page 內容都是 0,所以就可以用一個 page 代替其他 page,但是由於共用了 page,便不能隨意寫這個 page 了,所以這個 page 的 flag 標誌位設定為唯讀:

如果需要寫這個BSS 區域的某個 page(va),由於設定了唯讀,所以會觸發 page fault,這時在 page fault handler 中就會:
- 分配一個新的物理 page,將 va 對映到新的 page 上
- 在新的 page 上執行寫指令,而 BSS 區域其他page 依舊對映到原 page 上
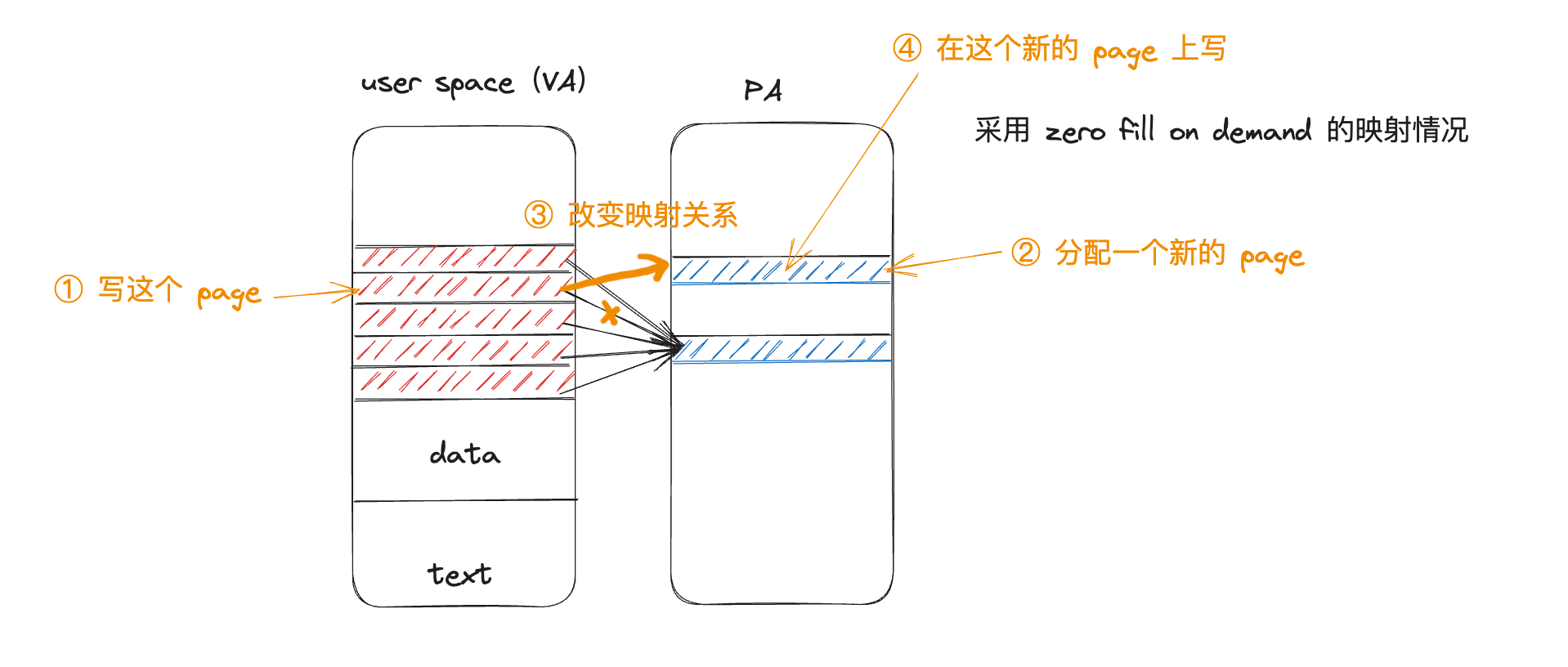
Copy On Write Fork
fork 機制在第一節已經講過了,fork會拷貝當前程序的記憶體,並建立一個新的程序,這裡的記憶體包含了程序的指令和資料。之後,我們就有了兩個擁有完全一樣記憶體的程序。
fork 最典型的用法就是和 exec 系統呼叫一起使用,先呼叫fork,再在子程序中呼叫 exec,通過這種方式來執行程式,最典型的就是 shell,我們在 shell 中執行的任何命令,都是 shell 這個程序 fork 出一個子程序,然後在子程序中呼叫 exec 來執行這個命令。
再來重複一遍這個浪費的過程:fork 建立了 Shell 地址空間的一個完整的拷貝,而 exec 做的第一件事情就是丟棄這個地址空間,取而代之的是一個包含了 echo 的地址空間。
由於fork首先拷貝了整個父程序的記憶體,但是之後exec整個將這個拷貝丟棄了,所以這裡的拷貝,顯得有些浪費(雙押23333):
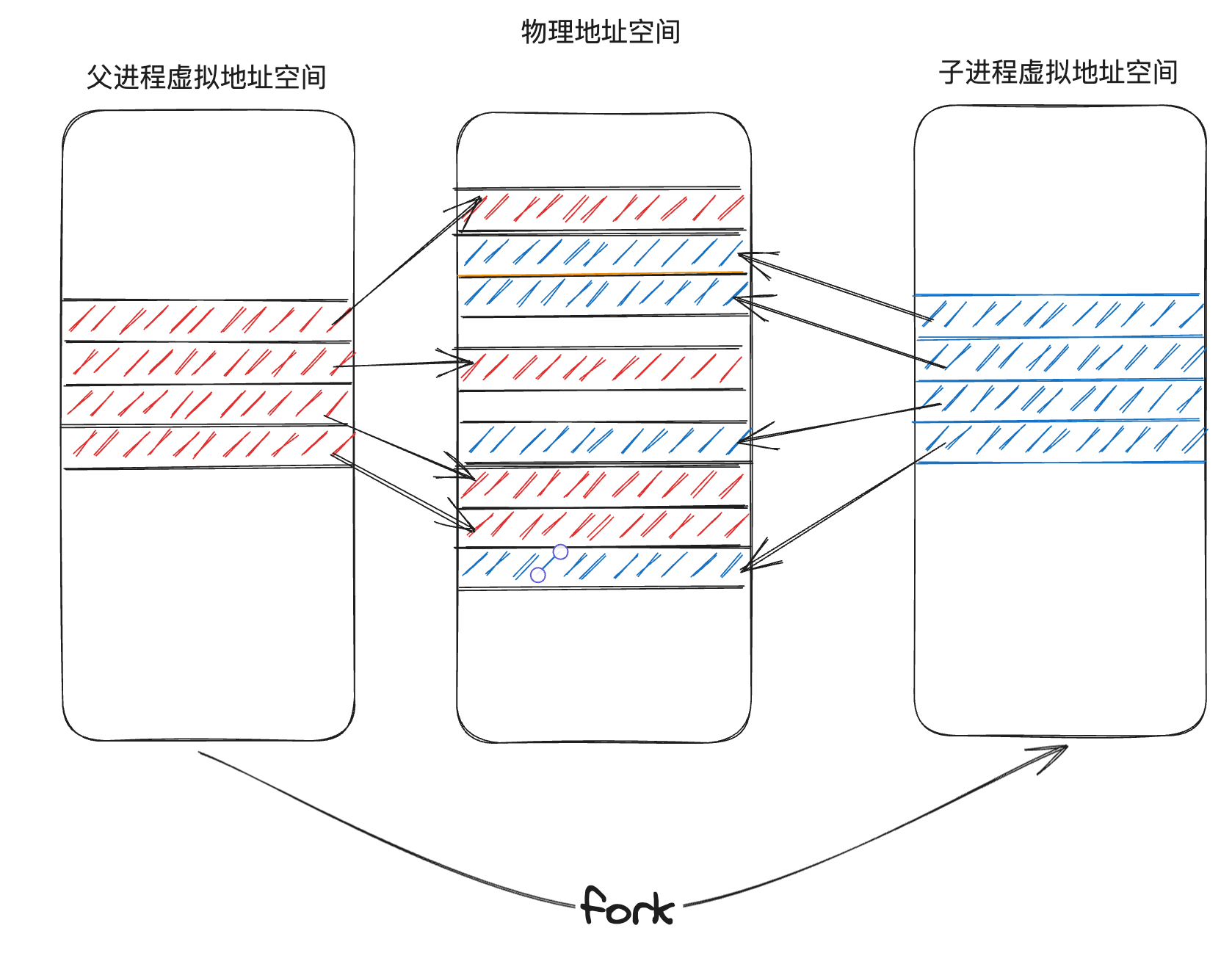
而 Copy On Write Fork 就是解決這個浪費問題的,他的核心思想依舊很簡單:當我們建立子程序時,直接共用父程序的實體記憶體page,而不是分配新的記憶體 page。即直接設定子程序的 PTE 指向父程序對應的實體記憶體 page,和 zero fill on demand 一樣,由於共用了物理 page,父程序和子程序的 PTE 的標誌位都應該設定成唯讀的,這樣寫這個 page 時才會觸發 page fault
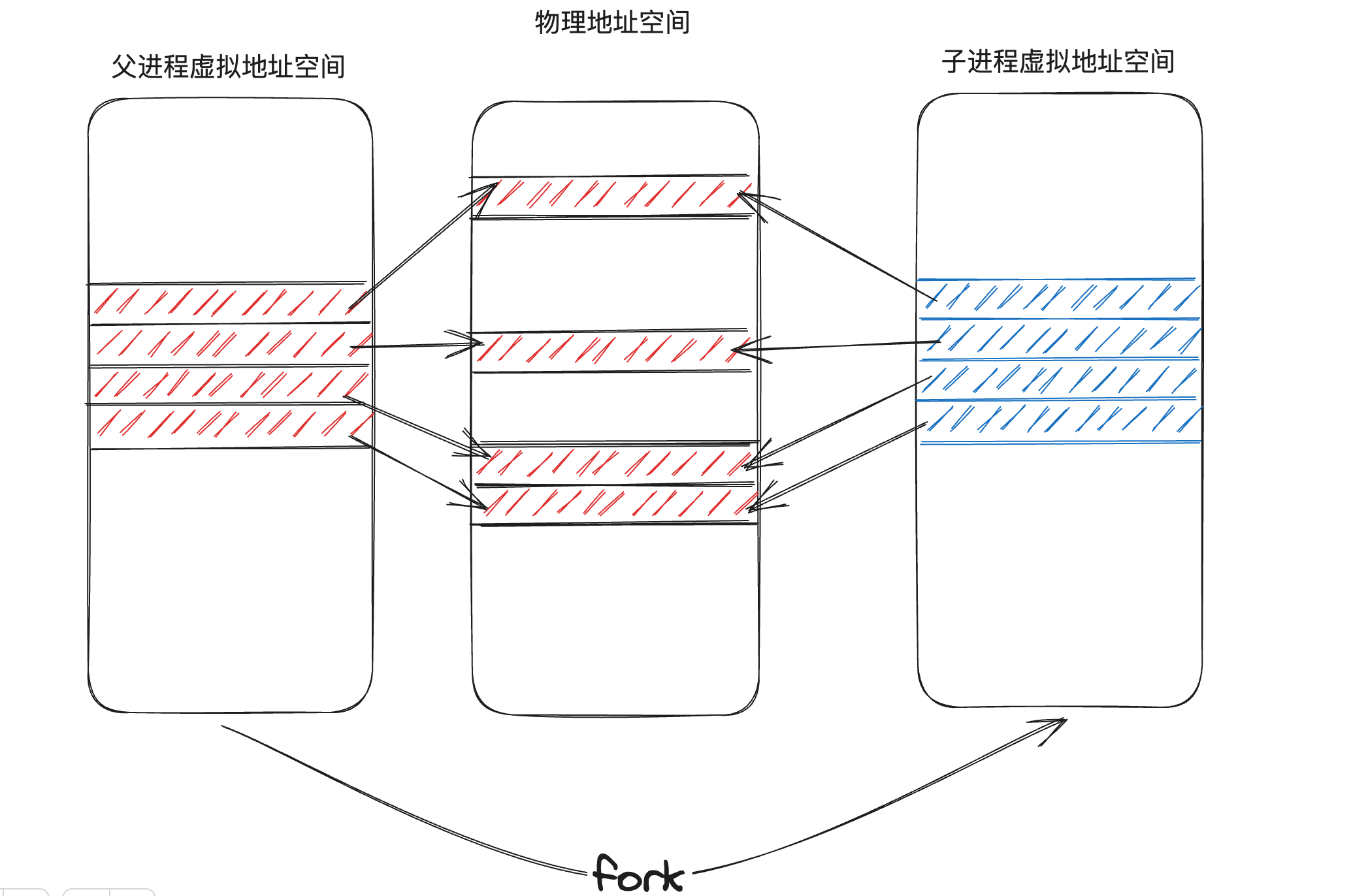
當父程序或者子程序寫這些共用的地址時,就會觸發 page fault,page fault handler 就會
-
複製出錯的 page 並重新對映
-
在新 page 上寫
-
將複製的 page 和原 page 的標誌位修改為可寫(原來是唯讀)
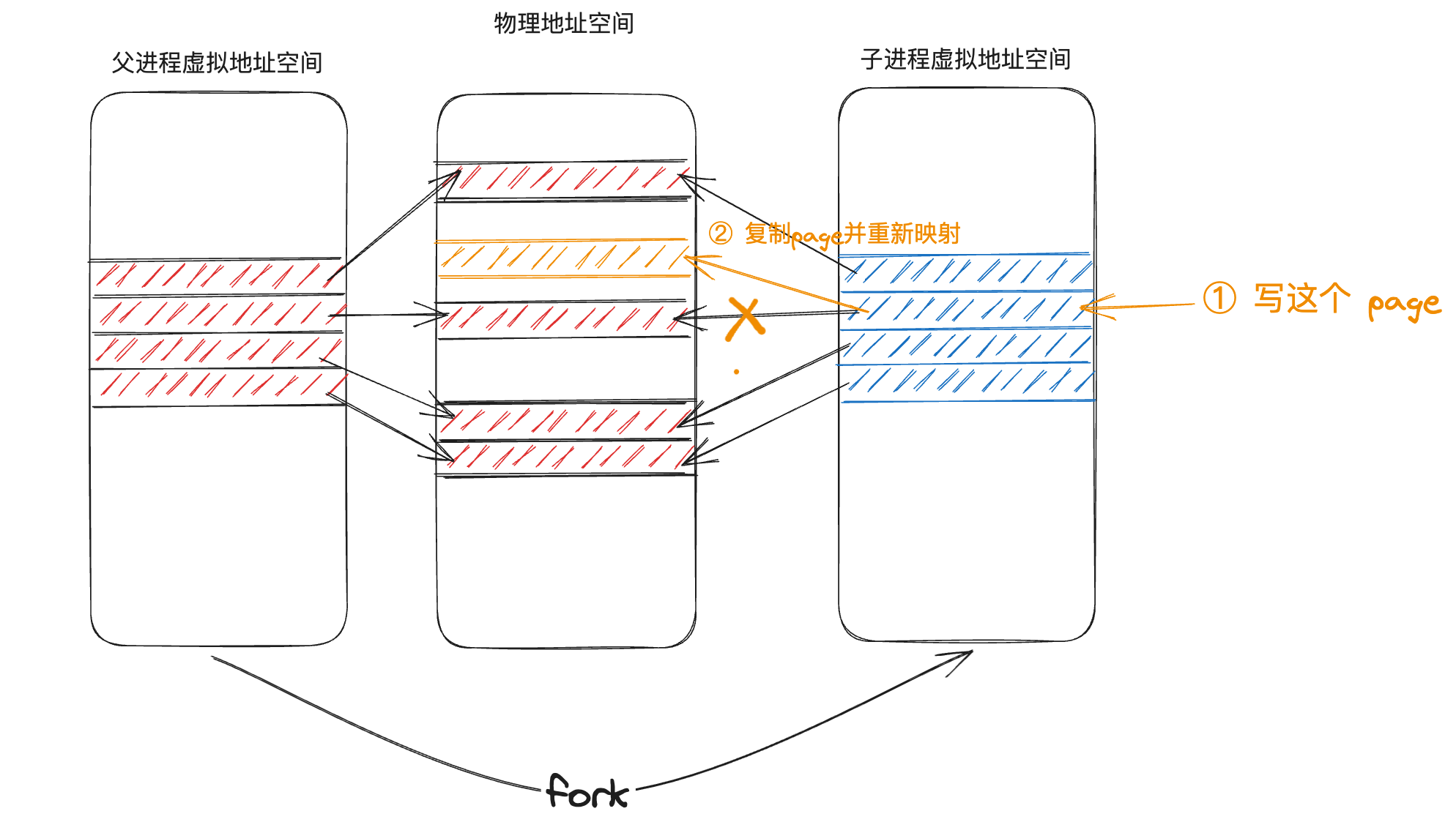
關於 COW fork 還有兩個重要的細節:
-
當發生page fault時,我們其實是在向一個唯讀的地址執行寫操作。核心如何能分辨現在是一個 copy-on-write fork 的場景,而不是應用程式在向一個正常的唯讀地址寫資料?
這其實是個共性的問題
在 lazy allocation 中,我們如何知道是向 PTE 找不到是因為本該分配的 lazy 了,還是確實沒找到?答案是根據存取地址判斷:如果要存取的 va < 新的 p->sz 且 > 舊的 p->sz,說明是 lazy 的情況。
在 zero fill on demand 中,如何能分辨現在是一個 zero fill on demand 的場景,而不是應用程式在向一個正常的唯讀地址寫資料?答案也是根據 va 判斷,va 是否是 BSS 段的 page,如果是則說明是一個 zero fill on demand 的場景
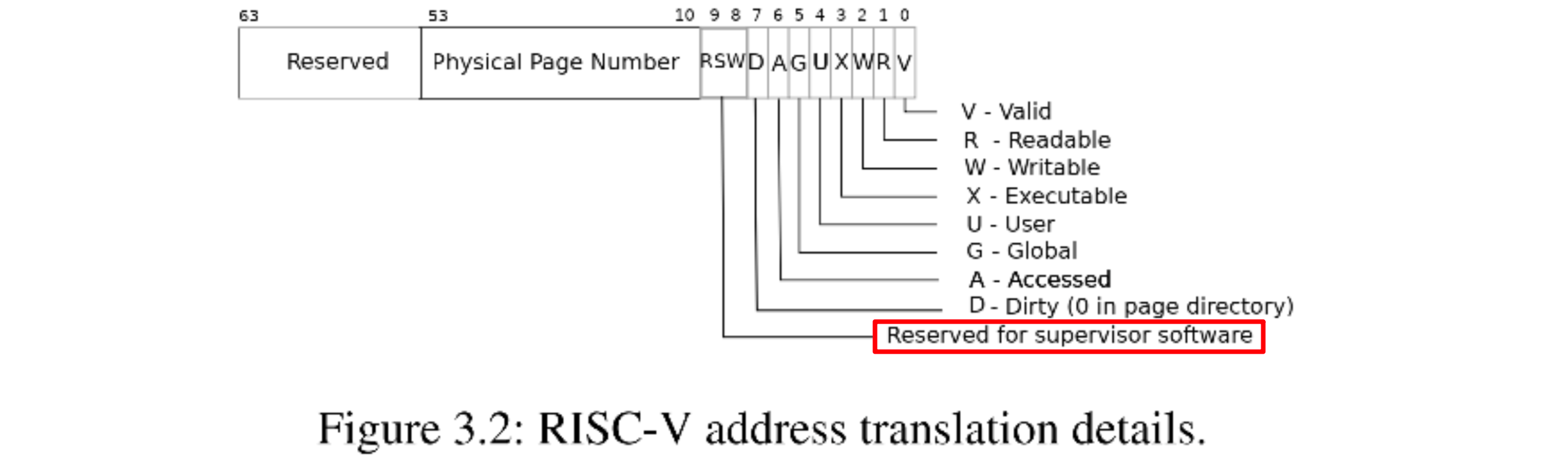
那麼在 COW fork 中也一樣,還記得 RISC-V 中一條 PTE 有10 bit 的輔助位把,其中 8、9bit 是保留位,我們可以使用其中的任意一個 bit 作為「這是 COW page 」的標記:
-
第二個細節是 page 釋放時要小心翼翼,因為共用物理 page 的存在,每次釋放 page 時都要確保沒有程序參照這些 page,所以需要有一個參照計數器來統計當前有多少個程序在使用這個 page,只有參照計數器為 0,才可以釋放 page
Demand paging
這裡老師講的十分模糊,核心依舊是 lazy 的思想,我認為關鍵在於細節,但教授沒有給出更多細節,這裡推薦一篇部落格:
Memory Mapped Files
這個後面會有 mmap lab (也是本課程最後一個 lab)來實現相應的功能,所以我打算乾脆放在那裡一起復習。
Lab5 :COW fork 心得
這個 lab 要求實現 COW fork,xv6 已經實現了一個 eager allocation 的 fork,而本次要求將這種實現修改為 COW fork,推遲實際的實體記憶體的分配,直到真正使用要使用的時候,才會複製實體記憶體頁。
以下是一些需要注意的細節:
-
每個 page 的參照計數存在哪裡?我第一反應是 map,key 是 page 的地址,value 是參照計數,但 lab 提示可以使用一個陣列來儲存,每個 page 的參照計數索引可以使用
頁的實體地址/4096來索引陣列。 -
COW fork 要求實際使用 page 時,複製原 page,而且要將原來的 page 和新 page 的標誌位改為可寫,但是值得注意的是,對於那些本來就使唯讀的(例如程式碼段),不論在舊頁還是新頁中,應該依舊保持它的唯讀性,那些試圖對這樣一個唯讀頁進行寫入的程序應該被殺死。
實際這裡的處理更加巧妙,讓我們仔細梳理一下這個正常的流程:
-
裝模作樣 fork 的時候(只建立頁表,並且在頁表中新增 pte),pte 需要打 cow 標誌位,並且清除 W 標誌位,使其唯讀
-
這樣寫這個 page 時會觸發 pf(寫入了唯讀 page ),並且由 cow bit 得知這是 cow 頁,不能直接殺死程序,需要懶複製
-
但有一種情況就是,這個 cow page 本身就是唯讀的,而不是清除了 W 標誌位之後才唯讀,所以這時即使是 cow page 也需要殺死程序
正常的想法是利用 PTE 中一個保留 bit 記錄一下這個 page 本身就是唯讀的,這樣在 pf 之後,如果是 cow page,只需要再判斷一下這個保留位,本身唯讀就直接殺死,否則正常進行 cow 的實際複製過程
但實際寫程式碼時並不需要這個保留位來記錄,採用另一種更巧妙的寫法:在 fork 時,如果判斷這個 page 是唯讀的,乾脆就不給他打 cow 標誌(這樣就能保證所有的 cow page 原來都是可寫的),所以觸發 pf 後就可以直接殺死程序,這樣和觸發 pf 後、判斷 cow、判斷原來就是唯讀的效果是一樣的,都是直接殺死。
-
-
cow page 的處理一定要小心翼翼,lab 提示要在 copyout() 函數中,如遇到 cow page,也要採取相應的策略,這裡的關鍵問題就是想清楚為什麼會影響到 copyout() 函數,因為 copyout 函數是用來將核心地址空間的 page 複製到使用者地址空間,如果目的地的使用者地址是一個 cow page,說明這個 page 不能被寫入,但是這時沒有任何 page fault 發生來觸發 cow_handler,所以就需要我們在copyout() 函數中主動檢查這一點
1.子程序只新增 PTE,不分配 page
檢視 fork 函數的原始碼,會發現複製記憶體的核心函數是:uvmcopy(p->pagetable, np->pagetable, p->sz),所以我們知道要修改這個函數,讓這個函數不再真正分配 page,而是隻在子程序的頁表中對映父程序的 page。
int uvmcopy(pagetable_t old, pagetable_t new, uint64 sz)
{
pte_t *pte;
uint64 pa, i;
uint flags;
// char *mem;
// 從這裡也能看出來 fork 時父程序是從地址 0 開始一直到 p-sz,複製到子程序
for(i = 0; i < sz; i += PGSIZE){
if((pte = walk(old, i, 0)) == 0)
panic("uvmcopy: pte should exist");
if((*pte & PTE_V) == 0)
panic("uvmcopy: page not present");
pa = PTE2PA(*pte);
flags = PTE_FLAGS(*pte);
// if((mem = kalloc()) == 0)
// goto err;
// memmove(mem, (char*)pa, PGSIZE);
// if(mappages(new, i, PGSIZE, (uint64)mem, flags) != 0){
// kfree(mem);
// goto err;
// }
// 父程序 page 可寫, 絕妙之處!
if((*pte) & PTE_W) {
// 新增 COW 標誌位、清除可寫標誌位
flags = (flags | PTE_COW) & (~PTE_W);
*pte = (*pte & ~PTE_W) | PTE_COW;
}
// 子程序頁表新增對映
if(mappages(new, i, PGSIZE, pa, flags) != 0){
//kfree((void *)pa);
goto err;
}
krefincr((void *)pa);
}
return 0;
err:
uvmunmap(new, 0, i / PGSIZE, 1);
return -1;
}
以上連續註釋掉的程式碼就是原始碼,即真正分配物理 page 的程式碼,而緊接著下面的程式碼就是實現只新增 PTE 、而不分配 page 的程式碼
2.觸發 pf 後的處理
由於我們在父程序和子程序的頁表中都設定了唯讀標誌位,所以觸發 pf 需要有程序對這個 page 進行寫。出錯的原因資訊存在 SCAUSE 暫存器中,在 [trap 的流程](MIT6.s081/6.828 lectrue5/6:System call entry/exit 以及 Lab4 心得 - byFMH - 部落格園 (cnblogs.com))中我們已經知道,一旦 trap,就會進入 trampoline.S 程式碼,trampoline.S 又會跳到 usertrap(),所以我們需要在 usertrap()程式碼中判斷 SCAUSE 暫存器 的值:

可以看出當寫 page 時觸發 pf 時,scause 暫存器的值是 15:
if(r_scause() == 15) {
uint64 va = r_stval();
// ** If virtual address is over maximum va size or within guard page, kill the process
if (va >= MAXVA || (va < p->trapframe->sp && va >= (p->trapframe->sp - PGSIZE)))
p->killed = 1;
if (cow_handler(p->pagetable, PGROUNDDOWN(va)) == -1)
p->killed = 1;
}
在cow_handler就要進行實際的 page 分配,但這裡也要注意判斷 page 的參照,如果參照只有 1,那麼也無需複製了,直接將 page 修改為可寫即可
int cow_handler(pagetable_t pagetable, uint64 va) {
pte_t *pte;
void *new_pa;
uint flags;
// ** va must be PGSIZE aligned
if ((va % PGSIZE) != 0) return -1;
// ** safety check
if (va >= MAXVA) return -1;
pte = walk(pagetable, va, 0);
if (pte == 0) return -1;
uint64 pa = PTE2PA(*pte);
if (pa == 0) return -1;
if(*pte & PTE_COW) {// cow page,uvmcopy 已經初始化,有 cow bit 一定沒有 w bit
int cnt = krefget((void *)pa);
if(cnt == 1) {// 唯一參照,直接修改標誌位讓其順利寫,我認為這裡是我多慮了,應該不會有這種情況,如果是 cow page ,參照至少為 2
*pte = (*pte | PTE_W) & (~PTE_COW);
} else if(cnt > 1) {// 多個參照,不能隨意寫,需要複製新頁,這裡的程式碼屬於原 uvmcopy
new_pa = kalloc();
memmove(new_pa, (char*)pa, PGSIZE);
flags = PTE_FLAGS(*pte);
flags = (flags | PTE_W) & (~PTE_COW);
uvmunmap(pagetable, PGROUNDDOWN(va), 1, 0);
mappages(pagetable, va, PGSIZE, (uint64)new_pa, flags);
krefdecr((void *)pa);// va 已經對映到 new_pa了,所以原 pa 參照計數減 1
} else {//
printf("cnt < 0\n");
return -1;
}
} else if(!(*pte & PTE_COW) && (*pte & PTE_W)){// 沒有 cow bit 、有 w bit,但依舊觸發 pf,不是此函數的職責
return 0;
} else if(!(*pte & PTE_COW) && !(*pte & PTE_W)){// 沒有 cow bit 且沒有 w bit,直接殺死
printf("cnt < 0\n");
return -1;
}
return 0;
}
最後在 copyout()函數中也要有相應的處理,至於為什麼已經在前面分析過了:
// in copyout
if(uvmcheckcowpage(va0)) {
cow_handler(pagetable, va0);
}
另外還有一些 參照計數 方面的修改細節,入 kallock 時 page 的計數初始化為 1,mappage 後參照計數++,kfree 後參照計數--等
OK,以上就是 MIT6.s081/6.828 lectrue07:Page faults 的所有內容了,這節課程的確很漲見識,page fault 是階梯,藉助它可以實現靈活的 page table 對映,或者說得掉書袋一些就是:實現虛擬記憶體的動態分配~
獲得更好的閱讀體驗,這裡是我的部落格,歡迎存取:byFMH - 部落格園
所有程式碼見:我的GitHub實現(記得切換到相應分支)