當小白遇到FullGC
起初沒有人在意這場GC,直到它影響到了每一天!
前言
本文記錄了一次排查FullGC導致的TP99過高過程,介紹了一些排查時思路,線索以及工具的使用,希望能夠幫助一些新手在排查問題沒有很好的思路時,提供一些思路,讓小白也能輕鬆解決FullGC問題,文中實際提到的引數設定不一定適合其他業務場景,在調優自己的專案時還是需要實際試驗過才能得出最佳引數設定
我也是小白,如有不合理的地方,歡迎大佬們進行指正
因為線上伺服器,我們大部分是沒有SSH許可權的,沒有辦法直接執行命令獲取容器資訊,所以排查過程中只能藉助平臺提供的工具,平臺提供的工具還是挺全的,本文主要用到的工具有: JDOS容器智慧監控,JDOS程序查詢,SGM容器監控資訊,SGM方法呼叫查詢
以下幾個工具簡單介紹:
http://sgm-server.jd.com/
http://jagile.jd.com/jdosCD/jdt/apps
JDOS容器智慧監控: 檢視容器的CPU,記憶體,磁碟,IO等資訊
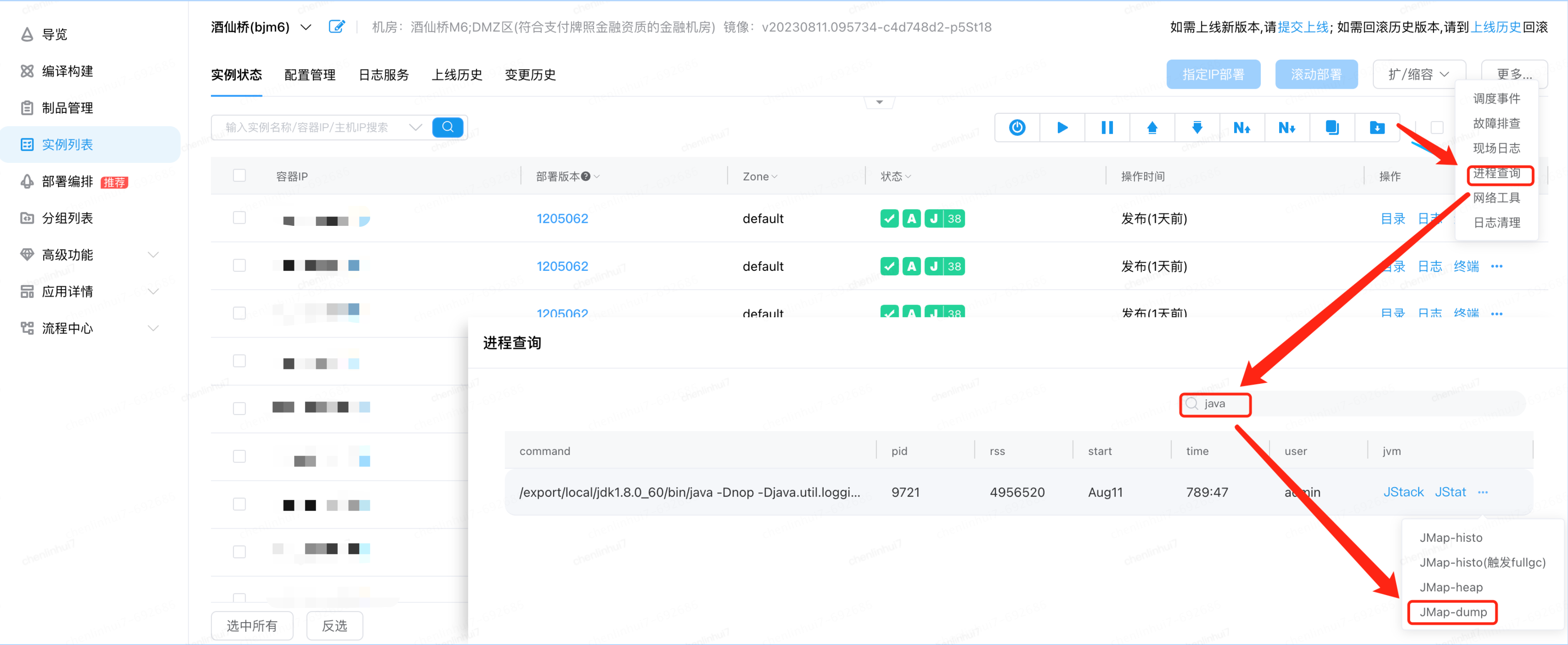
JDOS程序查詢: 檢視Java程序編號,執行常用的Java記憶體程序檢視命令
SGM容器監控資訊: 檢視JVM虛擬機器器記憶體變更歷史記錄
SGM方法呼叫查詢: 檢視某一次關鍵介面呼叫的上下依賴,時間分佈
起因 - 偶爾出現介面超時
一開始偶爾會收到報警郵件,顯示有些介面呼叫時間比較長,抽查了一些介面,發現大部分都是呼叫下游JSF時間比較長,導致響應比較慢,這時候就沒太在意,接下來繼續觀察了幾天,發現一個規律,大部分郵件都是每天10點
排查定位問題
-
首先確認了10點這個時間點有沒有定時任務之類的操作,經過詢問確定這個時間點是倉庫出庫高峰期,導致業務量出現峰值(呼叫量變大可能是激發FullGC問題,成為問題暴漏的導火線)
-
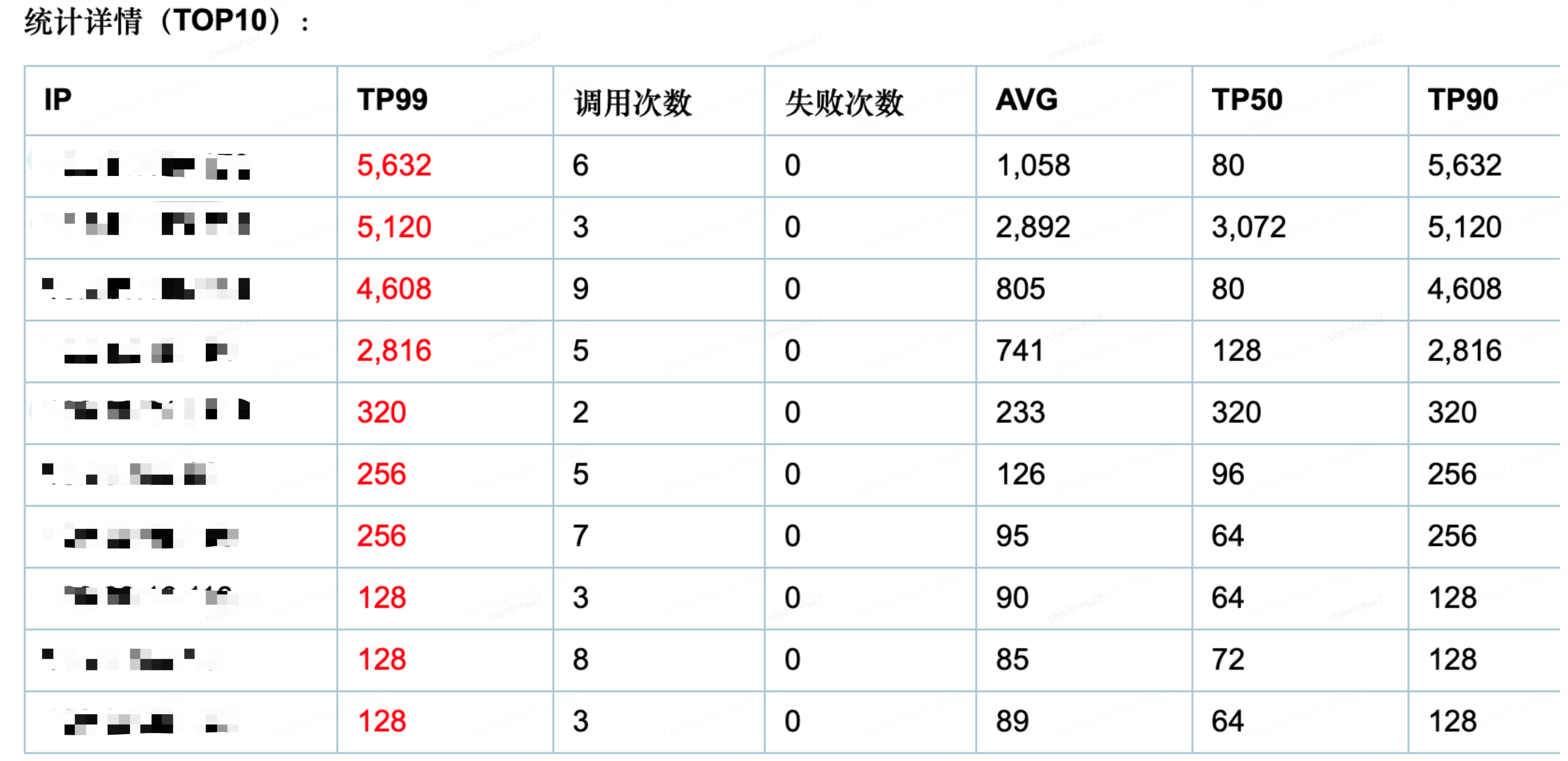
第二部就是確認是資料庫原因,還是業務程式碼,還是JSF下游介面達到極限原因,到這一步還是未知的,在這用到了SGM的介面呼叫查詢工具,下圖中我們看到,這次呼叫JSF也是挺高的(這個沒有太好辦法,除非讓下游優化,所以暫時忽略),但是還有一個是logic,這個就是邏輯處理,如果沒有那個FullGC提示,就需要去分析程式碼的處理是否有問題,這通過那行紅色字型的提示,很顯然我們確定了是FullGC導致的問題
-
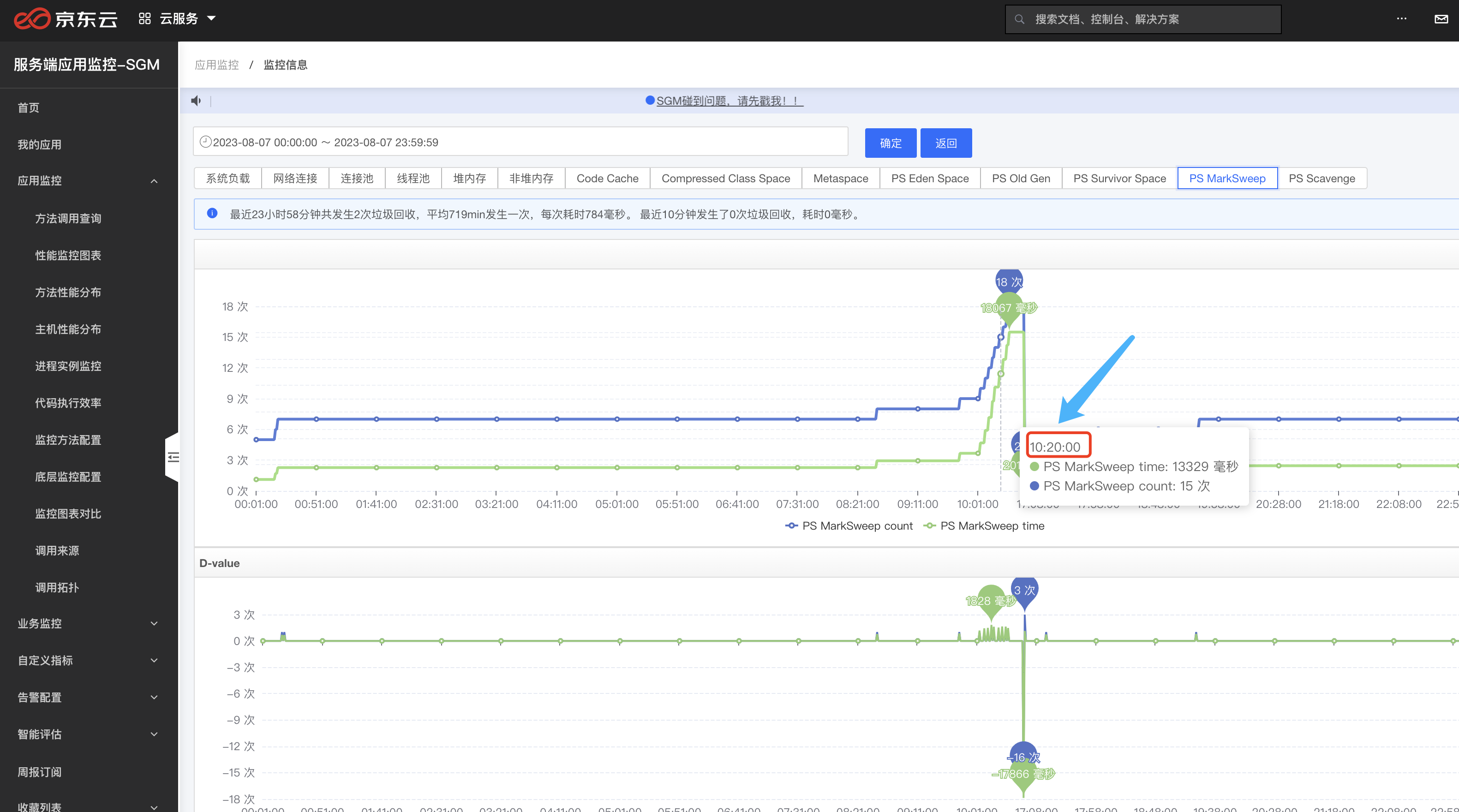
我們去檢視一下容器的FullGC情況,確實發現這個時間點的FullGC特別頻繁,到此已經把問題範圍定位到就是FullGC導致的

FullGC問題排查
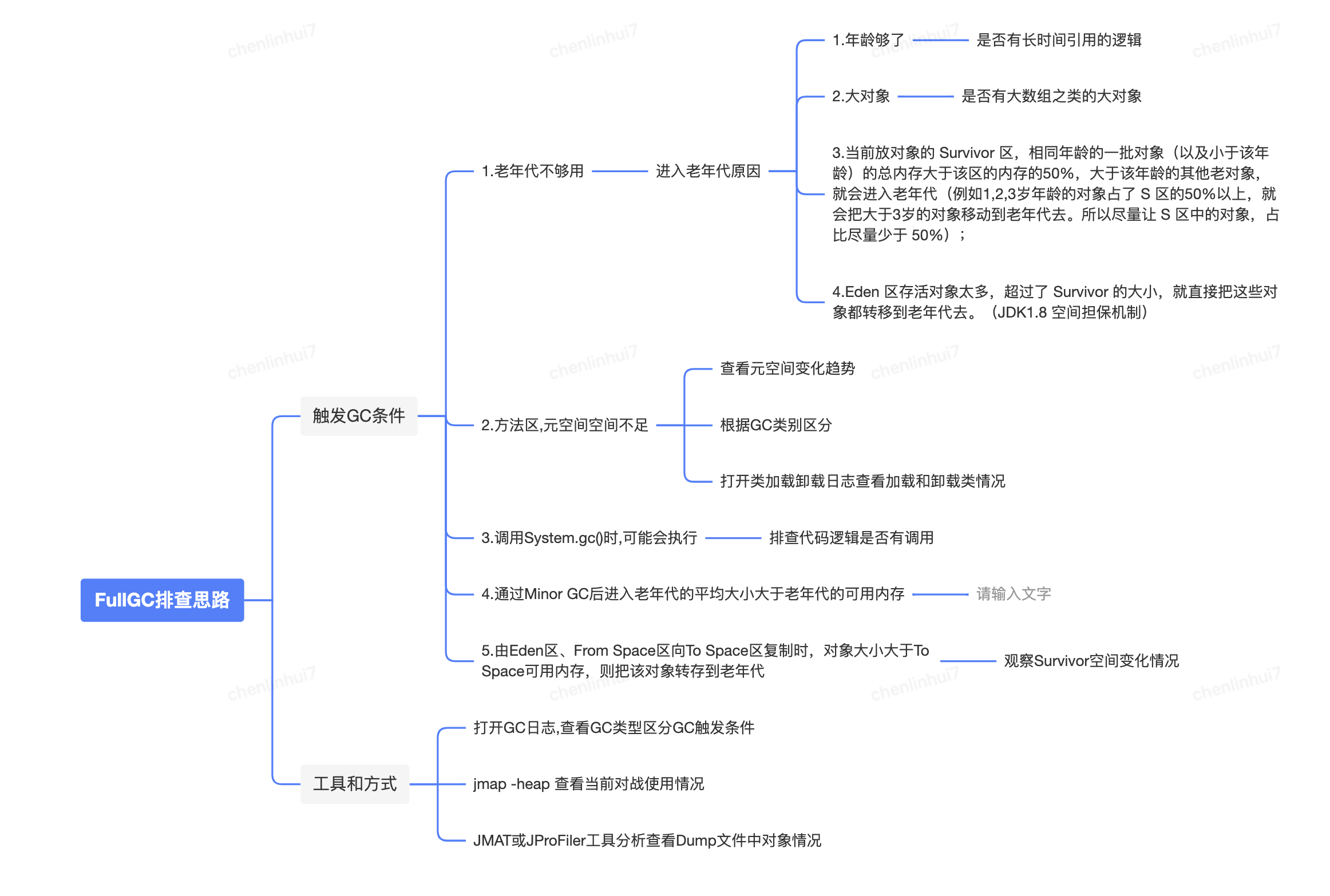
Full GC 觸發條件:
到這裡我們需要確定一個問題 : 「觸發FullGC的條件是什麼?」,新手可以去部落格搜尋,當然最好是能記住這個知識點。注意這不是確定「什麼原因導致的FullGC?」,因為這個問題原因太多了,我們要一步一步排查。 下面是我查到的資料,粘到這裡供參考.
-
Minor GC觸發條件:當Eden區滿時,觸發Minor GC。
-
Full GC觸發條件:
- (1)呼叫System.gc()時,系統建議執行Full GC,但是不必然執
- (2)老年代空間不足
- (3)方法區空間不足
- (4)通過Minor GC後進入老年代的平均大小大於老年代的可用記憶體
- (5)由Eden區、From Space區向To Space區複製時,物件大小大於To Space可用記憶體,則把該物件轉存到老年代
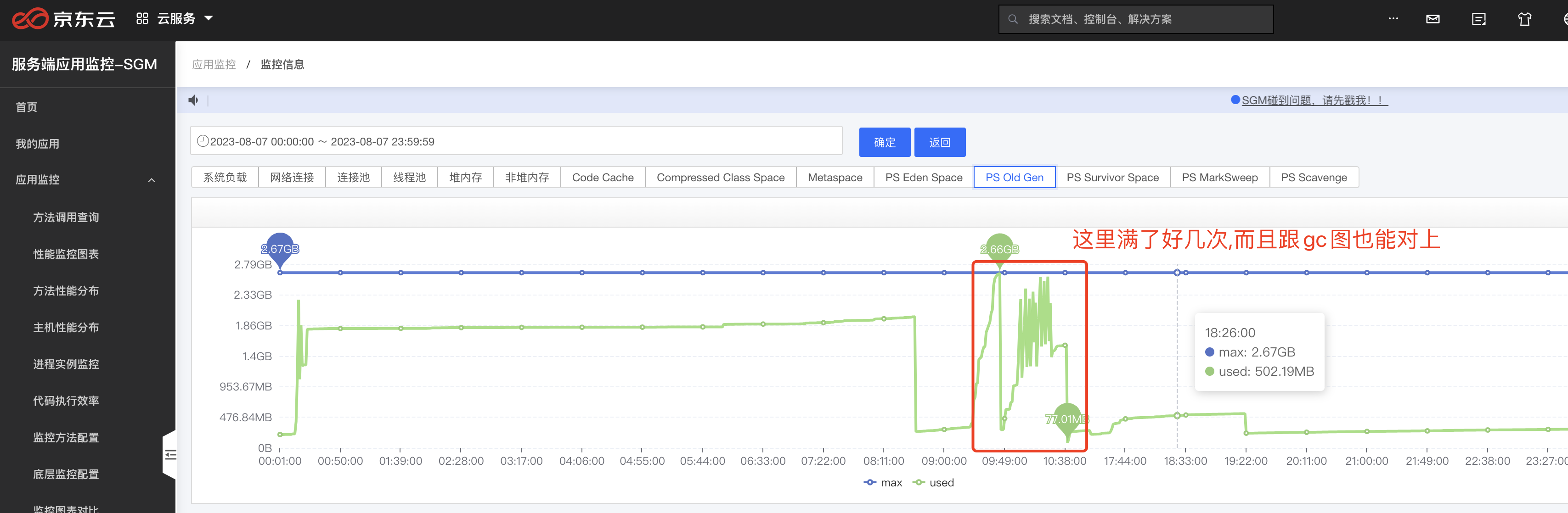
這裡在程式碼中並沒有找到System.gc()的顯示呼叫,一般我們也不會呼叫這個方法,所以我們直接看第二種情況,到SGM中檢視老年代變化,結果發現老年代頻繁達到90%,而這個時間正好可以跟上面GC時間對上.
物件進入老年代的幾種情況
我們都知道,老年代的物件應該是存活時間很長的物件,但是我們發現這些物件都在FullGC時被釋放掉了,他們為什麼到了老年代呢? 這時候我們需要確定的第二個問題是:「什麼情況下物件會進入老年代?」 查資料後有以下幾種情況
-
年齡夠了: 躲過15次(預設設定是15次) minorGC 之後從新生代進入老年代;
-
大物件: 大物件直接進入老年代。有一個 JVM 引數 '-XX:PretenureSizeThreshold' 設定值為位元組數,建立超過該大小的物件直接進入老年代,如果沒有設定這個引數,這個值好像預設是1M。
-
動態年齡判斷:當前放物件的 Survivor 區,相同年齡的一批物件(以及小於該年齡)的總記憶體大於該區的記憶體的50%,大於該年齡的其他老物件,就會進入老年代(例如1,2,3歲年齡的物件佔了 S 區的50%以上,就會把大於3歲的物件移動到老年代去。所以儘量讓 S 區中的物件,佔比儘量少於 50%);
-
剩的總量太多: Eden 區存活物件太多,超過了 Survivor 的大小,就直接把這些物件都轉移到老年代去。(JDK1.8 空間擔保機制)
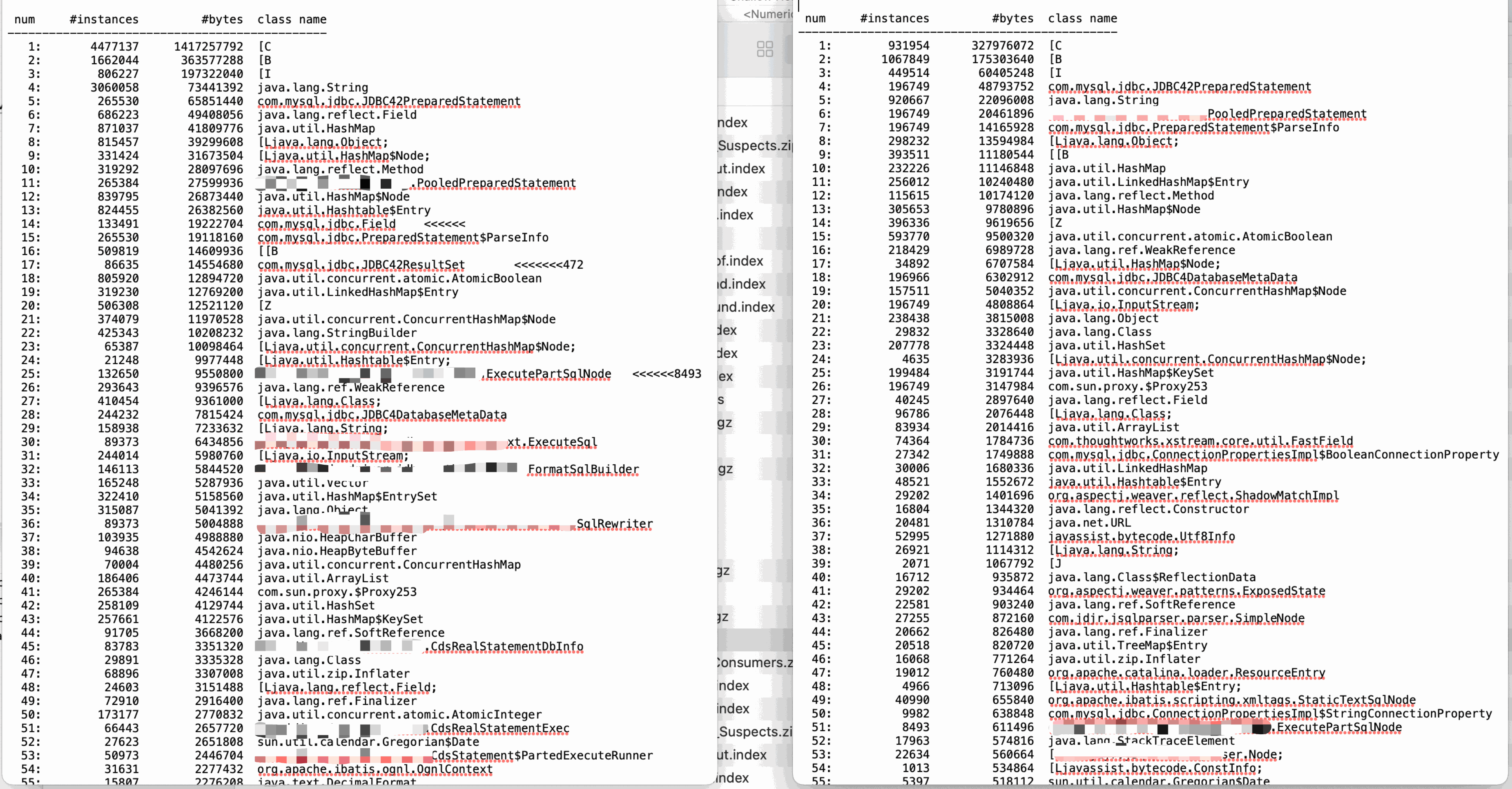
首先分析第一種情況,如果出現大批次這樣的物件,程式碼中出現了長時間參照(例如:靜態Map只加不刪),但是我們可以看到,這些物件在每次FullGC都被釋放掉了,說明這批物件存活的時間並不長, 而且程式碼排查也沒發現這種程式碼,暫時排除這種情況(這的程式碼因為是工具包的程式碼,所以沒有太深糾,這為續集留個伏筆). 第二種情況,大物件,我們到JDOS下載下來JMap-dump記憶體快照和JMap-Histo物件統計資訊,經過對FullGC錢dump分析,結合GC前GC後物件統計結果,並沒有發現大量的大物件,這個基本也排除
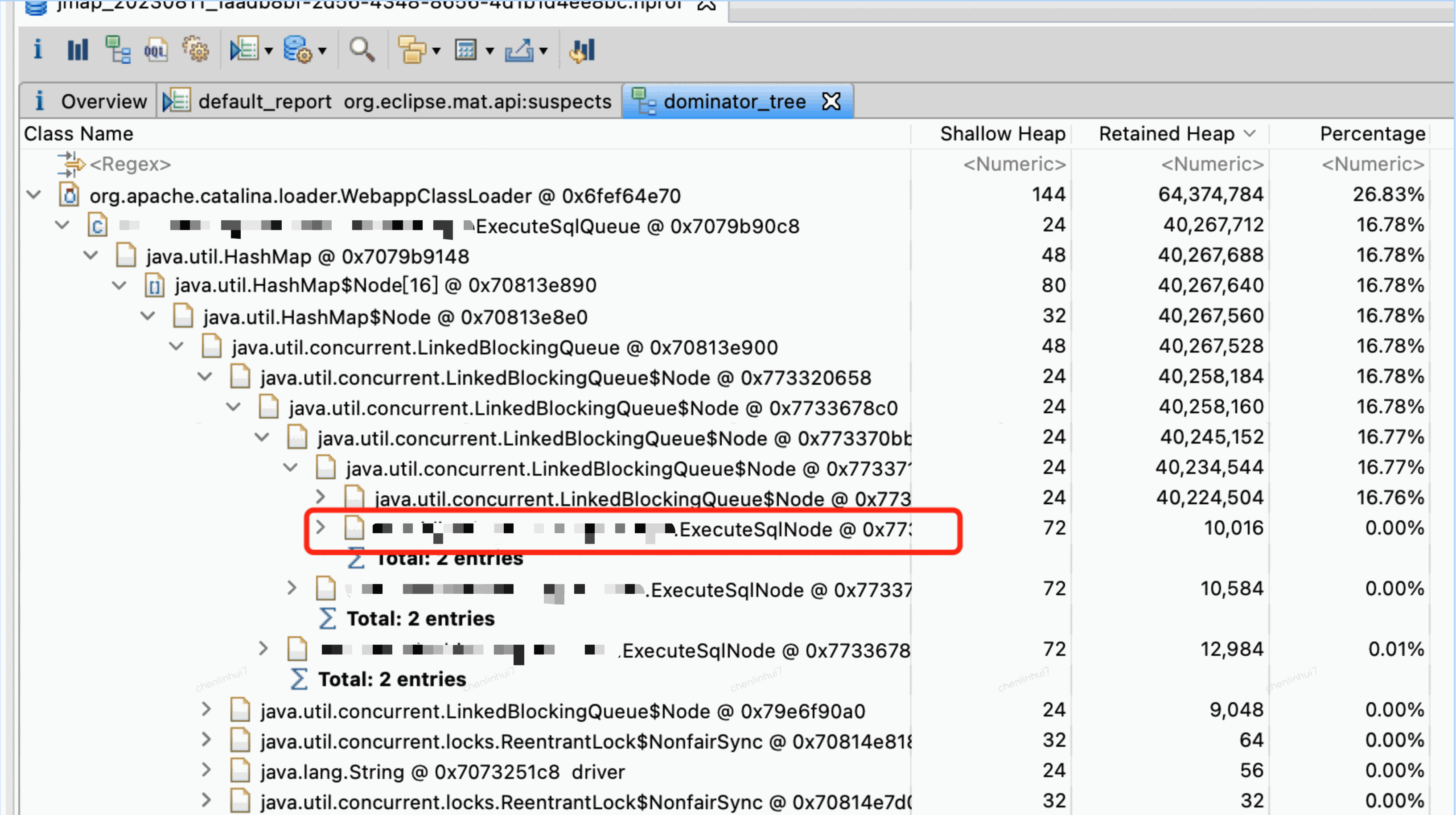
通過JMAT(Eclipse Memory Analysis Tools)匯入dump檔案進行分析,記憶體漏失問題一般我們直接選Leak Suspects即可,mat給出了記憶體漏失的建議。另外也可以選擇Top Consumers來檢視最大物件報告。和執行緒相關的問題可以選擇thread overview進行分析。除此之外就是選擇Histogram類概覽來自己慢慢分析,大家可以搜搜mat的相關教學。
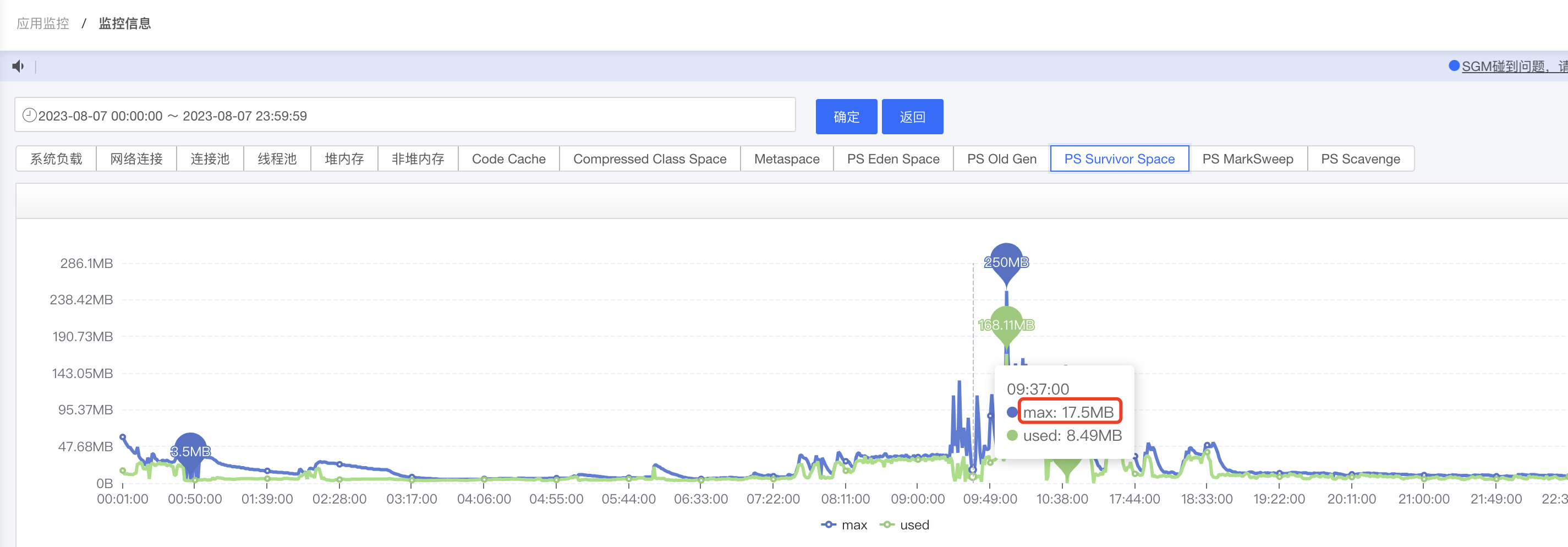
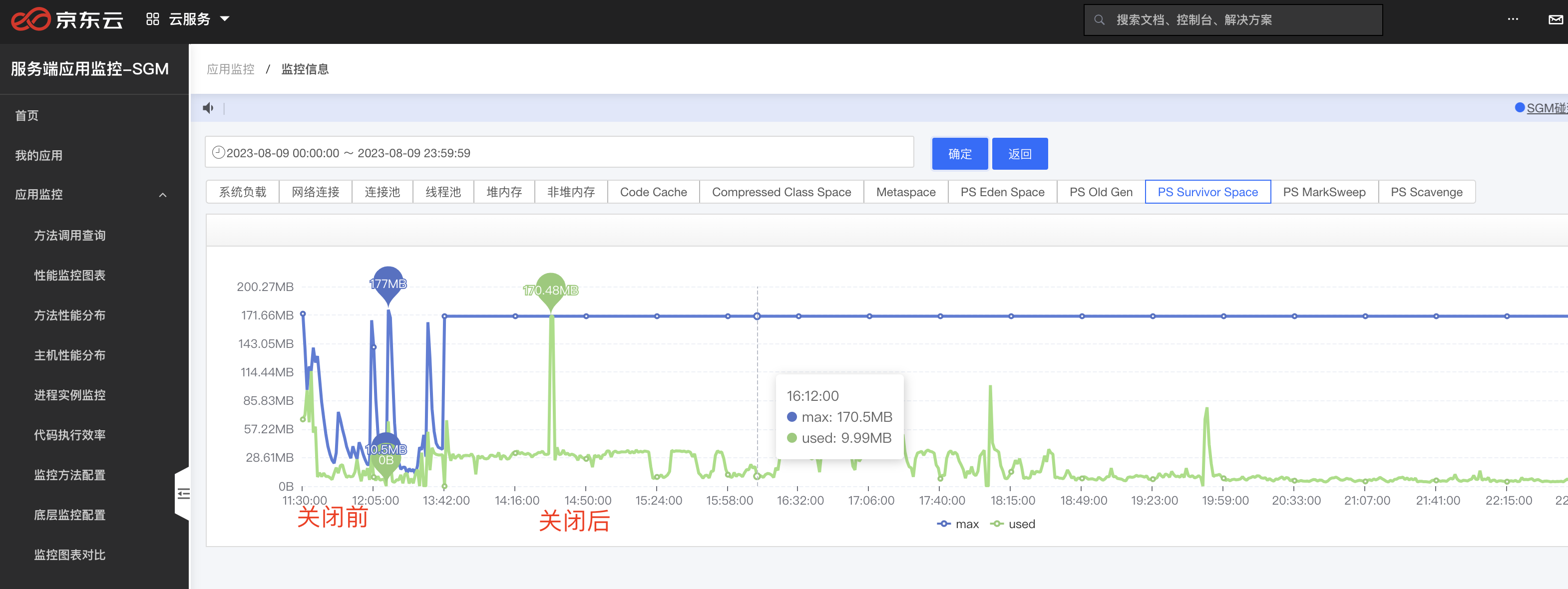
接下來就是第三種和第四種情況,這時候我們需要取檢視年輕代三塊區域的變化,尤其是Survivor區域,下圖是當時一個情況,S區大小一直在變化,而且基本一致保持在50%以上,這時候想到了一個JVM高版本特性,會自動開啟UseAdaptiveSizePolicy(動態調整),查資料後發現,好多人反應這個引數會導致物件跨過S區,直接跑到老年代的情況,我們看到在呼叫量持續很高的情況,盡然調整到了17M,這肯定會導致容納不下當時存活的物件
UseAdaptiveSizePolicy開關引數-XX:+UseAdaptiveSizePolicy是一個開關引數,當這個引數開啟之後,虛擬機器器會根據當前系統的執行情況收集效能監控資訊,動態調整這些引數以提供最合適的停頓時間或最大的吞吐量,這種調節方式稱為GC自適應的調節策略(GC Ergonomics)。
定位到UseAdaptiveSizePolicy問題
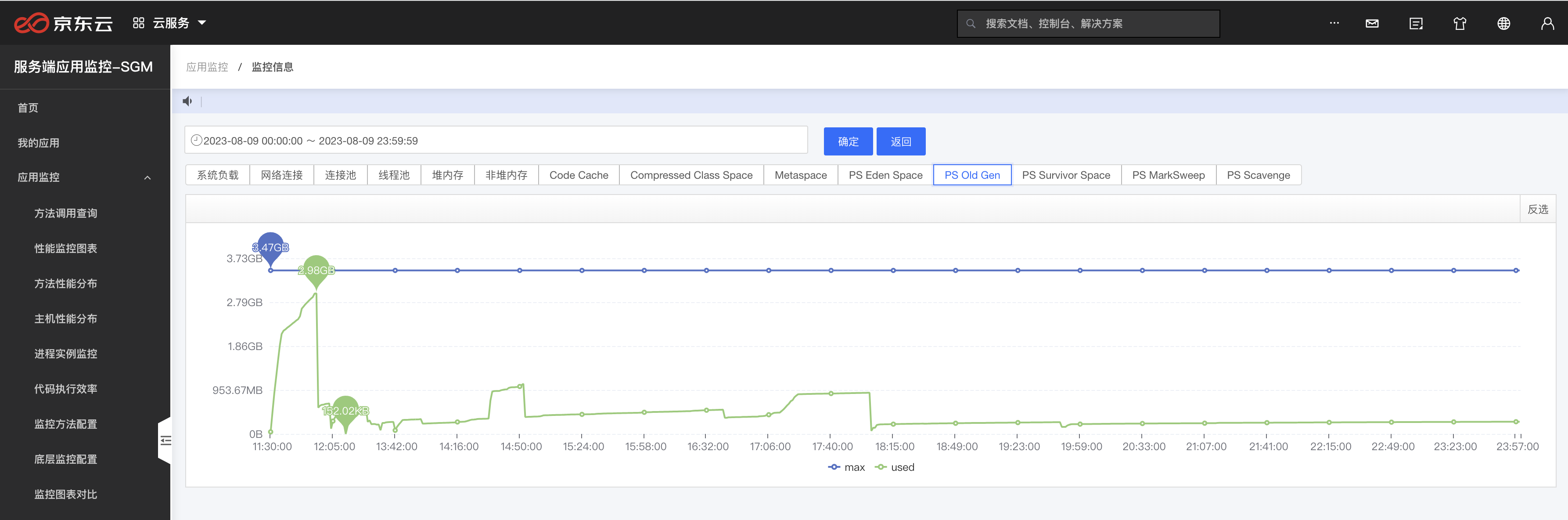
既然這有問題,我們嘗試關閉一下這個引數看下效果,下面是老年代,S區和FullGC,在關閉前和關閉後的效果,關閉之後S區大多數時間有充足的空間,而且,老年代和FullGC圖也安穩了很多 關閉AdaptiveSizePolicy的方式
開啟:-XX:+UseAdaptiveSizePolicy(JDK1.8 Parallel Scavenge收集器預設)
關閉:-XX:-UseAdaptiveSizePolicy
發現新的問題
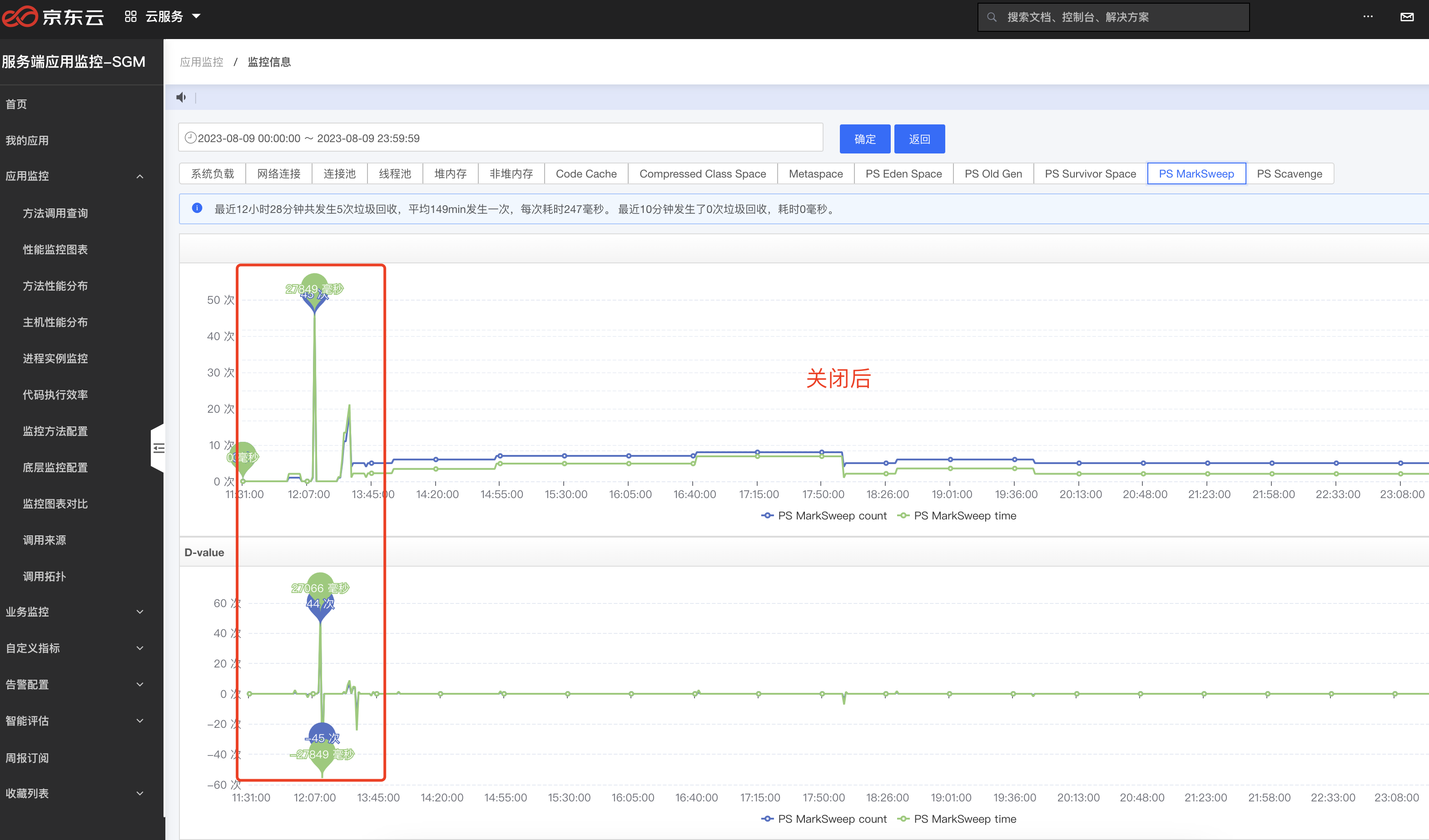
上圖中雖然已經安穩了很多,但是還是有一點小問題,頻繁FullGC雖然沒有了,但是一個小時還是會出現一次FullGC,而且這時候老年代還沒有滿,這種頻率的FullGC,理論上也是不允許的. 我們回到第一個問題,FullGC觸發條件,第三個,我們趕緊看了下永久代,也就是元空間,如下圖,這一看不得了,元空間也在頻繁變動,而且達到300M左右時會觸發一次FullGC釋放掉.
tips: 這裡是沒有設定元空間的大小的,也沒有設定元空間的理論上元空間無限大,不會滿,查詢資料後解釋是,元空間也會根據當前已使用進行動態調整,當達到上次調整值90%後就會FullGC,所以每次FullGC元空間大小在200M到500M不等
元空間記憶體排查
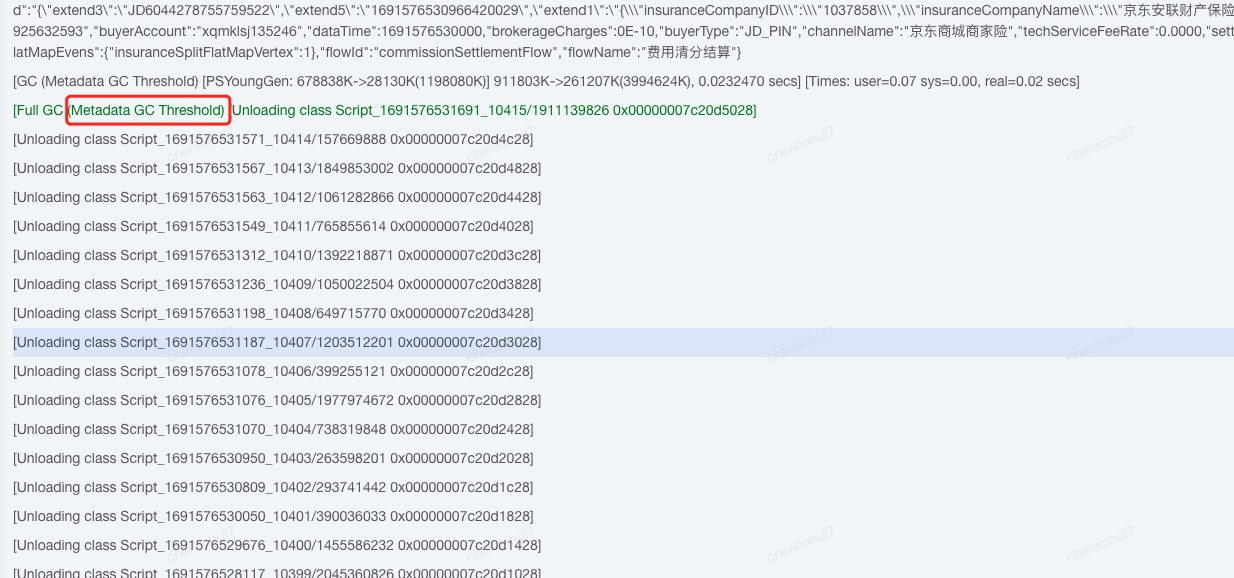
這時猜測可能是程式碼中出現了大量的動態類的宣告,想要定位哪些類需要jvm啟動引數加上列印類載入和解除安裝的引數,順帶把GC紀錄檔開關也開啟
-XX:+TraceClassUnloading -XX:+TraceClassLoading -XX:+PrintGCDetails
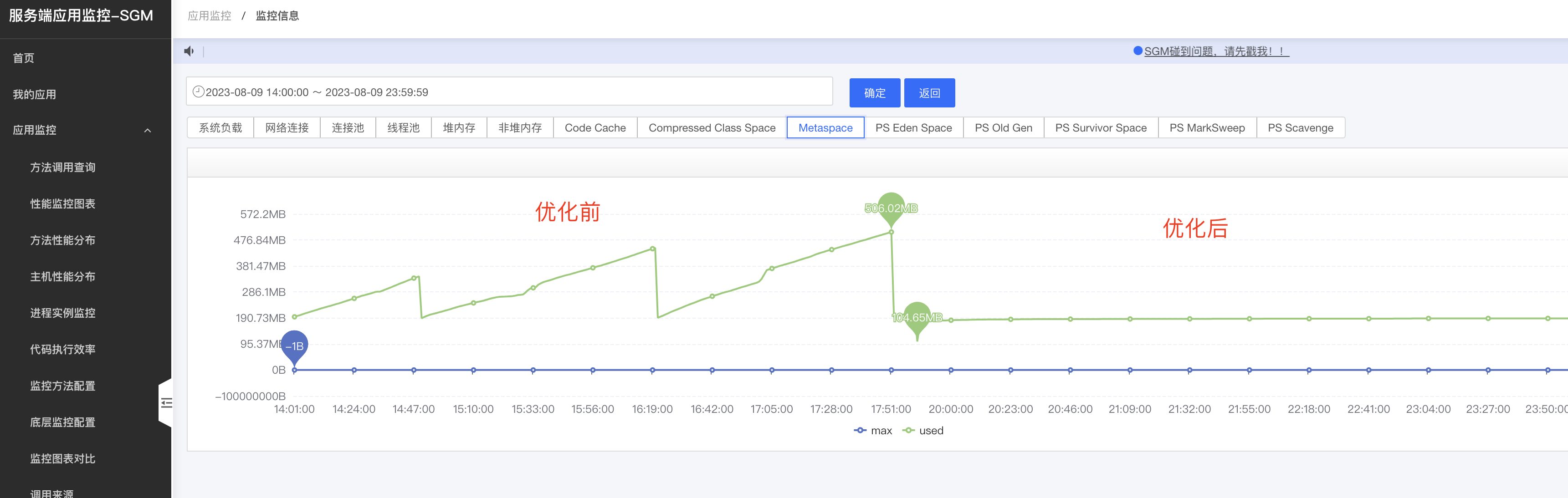
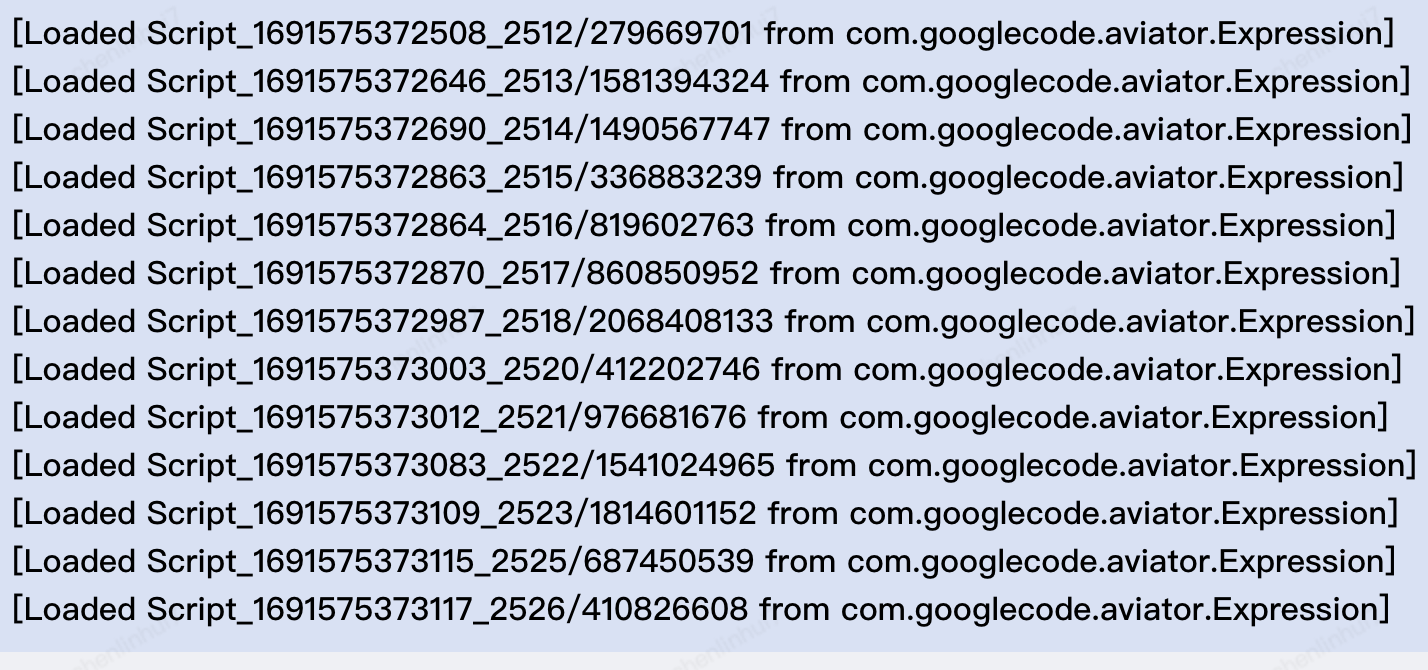
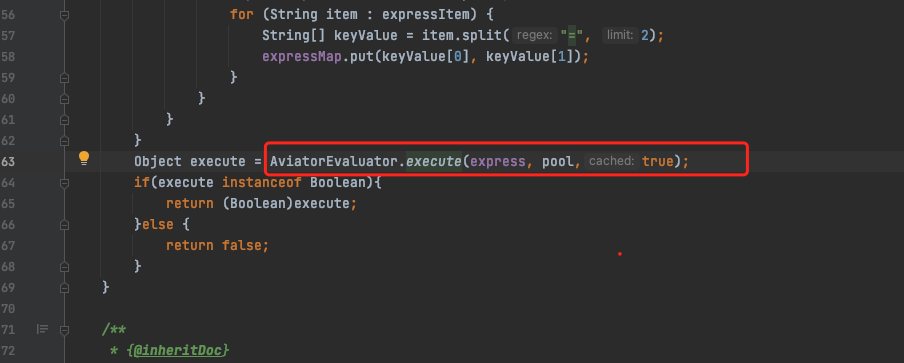
開啟後檢視紀錄檔發現一個頻繁載入和解除安裝的類[com.googlecode.aviator.Expression], 經查詢資料,這個是aviator 工具的一個規則引擎類,在載入規則時會動態載入一個類,預設不使用快取,可以開啟快取防止頻繁宣告新類
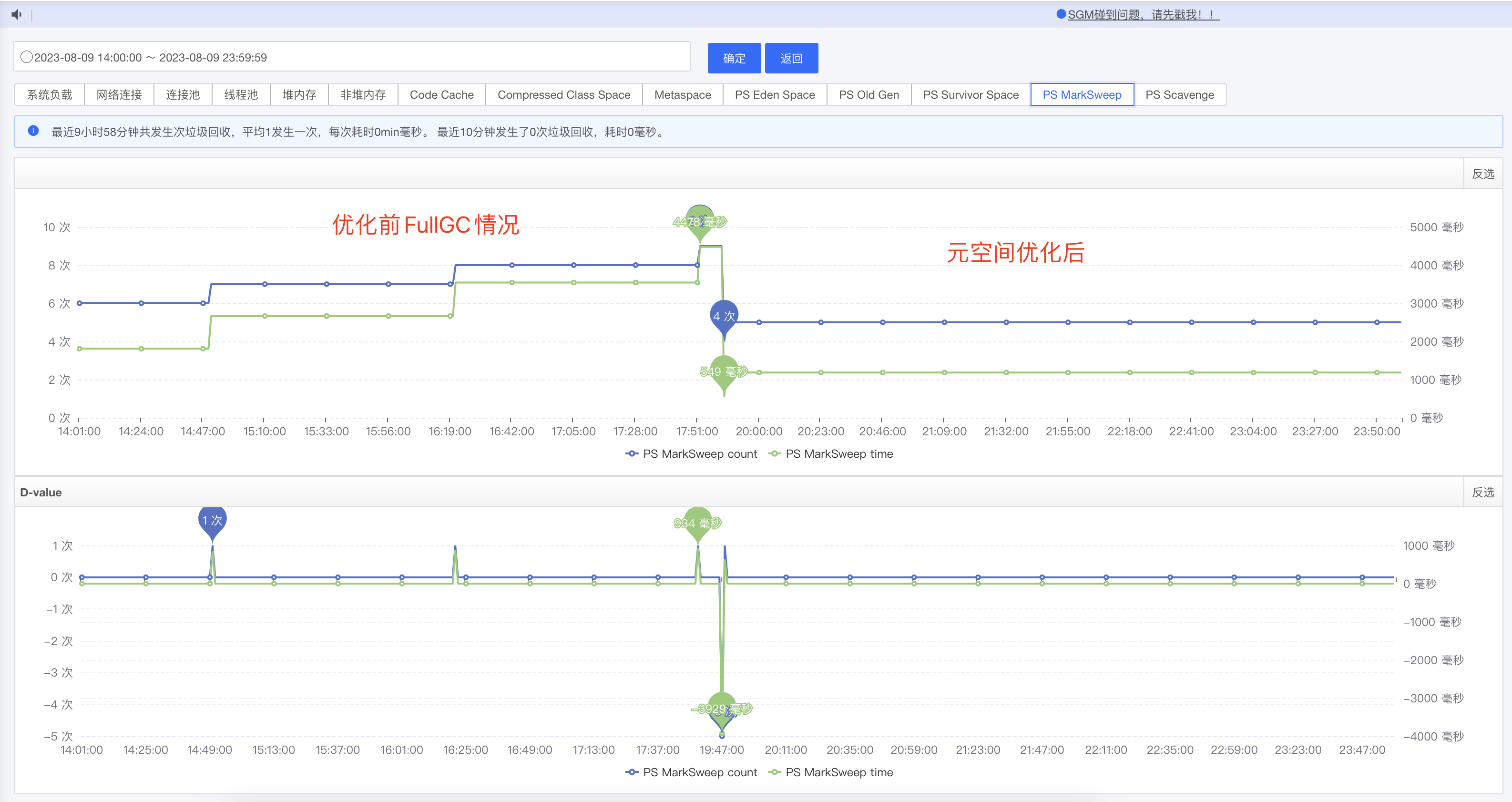
修改程式碼後重新部署,一小時一次的FullGC也沒了,如下圖
總結
發現的問題: 問題一: AdaptiveSizePolicy導致物件提前進入老年代,老年代增長速度快,導致頻繁FullGC 解決方式: 關閉:-XX:-UseAdaptiveSizePolicy
問題二: 元空間不斷增長,導致一小時一次FullGC 解決方式: 修改邏輯程式碼防止頻繁載入新類
在排查問題時儘可能先找直接原因,縮小排查跨度,不要一步就想知道根本原因,每個線索都要問個為什麼,不正常的現象肯定是有原因的.
下面是FullGC排查思路參考腦圖
作者:京東保險 陳林輝
來源:京東雲開發者社群 轉載請註明來源