在同事的程式碼中學習-責任鏈模式
前言
不知道大家有沒有發現,設計模式學習起來其實不容易,並不是說它難,主要是它表達的是思想層面或者說抽象層面的東西,如果你沒有實踐經歷過,感覺就是看了就懂,過了就忘。
所以本人現在也不多花費時間去專門學習設計模式,而是平時在看一些框架原始碼時,多留意,多學習別人的設計方法和實現思路,在平時工作中,遇到比較複雜的場景,不好看的程式碼,或者想要更優雅的寫法時,再反過來去翻設計模式,這樣學習起來印象更加深刻,出去面試時,有解決場景也比背書要更容易說服別人。
這不最近在review同學程式碼時就發現如下程式碼,學習的機會不就來了嗎~~~
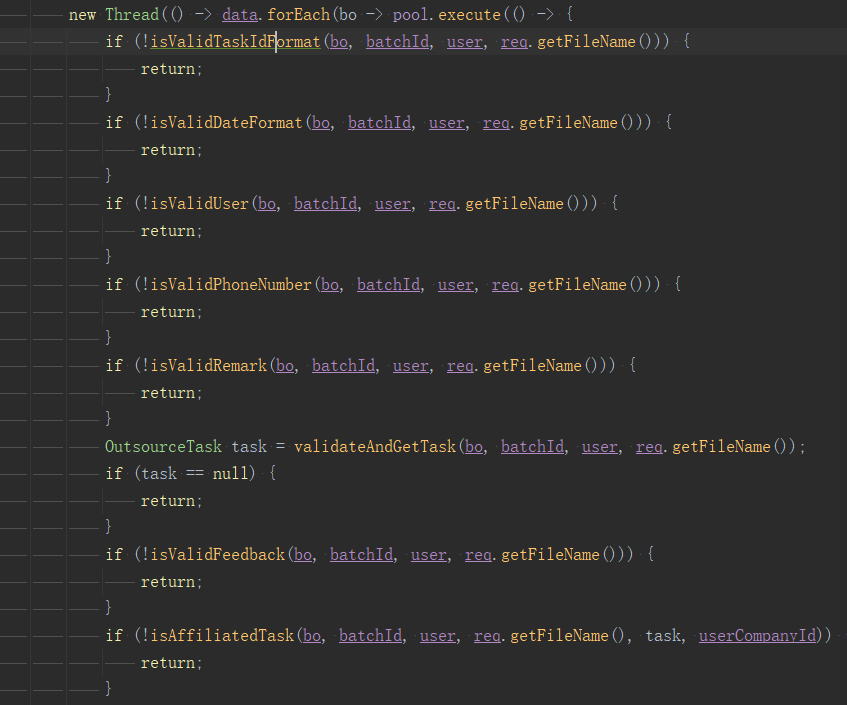
我簡單說一下這段程式碼的邏輯,非常簡單,就是要處理使用者端上傳的一批資料,處理前要校驗一下,失敗就記錄,退出。
從方法命名大概可以看出要校驗日期、使用者、號碼、備註等等,這些校驗規則可能會隨著業務變化而增減,且它們之前有順序要求,也就是圖中的if不能隨意顛倒順序。
這段程式碼的缺點很明顯,首先它不符合「開閉原則」,每次增減校驗都需要來修改主業務流程的程式碼,沒有做到動態擴充套件。
且在主業務流程裡看到如此長的if,真的非常影響閱讀體驗,if裡方法的程式碼也高度重複,如下:
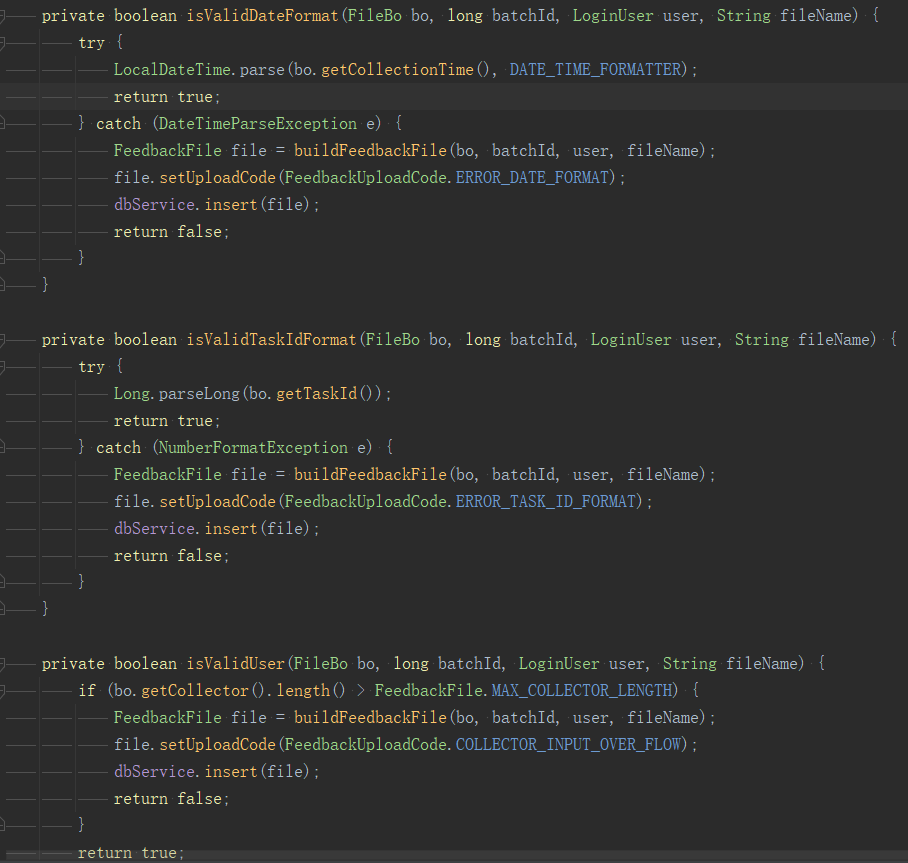
同時它還會形成「破窗效應」,你說它不好吧,一排if還挺有規則的,以後新加,大概率大家都是繼續加if,那這段程式碼就越來越難看了。
接下來我們就看如何用設計模式中的責任鏈模式來優化它。
責任鏈模式
來自百度百科的解釋:責任鏈模式是一種設計模式,在責任鏈模式裡,很多物件由每一個物件對其下家的參照而連線起來形成一條鏈。請求在這個鏈上傳遞,直到鏈上的某一個物件決定處理此請求。發出這個請求的使用者端並不知道鏈上的哪一個物件最終處理這個請求,這使得系統可以在不影響使用者端的情況下動態地重新組織和分配責任。
我們轉換成圖如下:
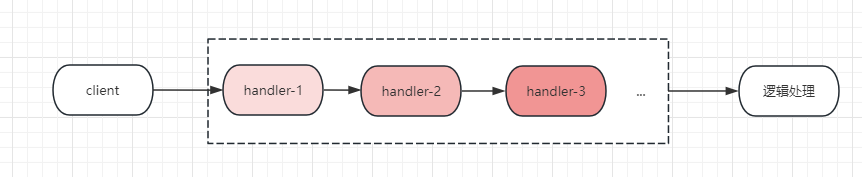
在使用者端請求與真實邏輯處理之前,請求需要經過一條請求處理鏈條,其中每個handler可以對請求進行加工、處理、過濾,這與我們上面的業務場景是完全一樣的。
網上的uml圖都把介面和實現物件定義為XXHandler,但這不是強制,你可以結合實際業務場景來,例如XXInterceotor,XXValidator都可以。
使用責任鏈模式的優點:(來自chatgpt的回答)
降低耦合度:請求傳送者不需要知道哪個物件會處理請求,處理器之間也不需要知道彼此的詳細資訊,從而降低了系統的耦合度。
動態新增/移除處理器:可以在執行時動態地新增、移除處理器,而不會影響其他部分的程式碼。
增強靈活性:可以根據具體情況客製化處理器的鏈條,以適應不同的請求處理流程。
遵循開閉原則:當需要新增一種處理方式時,只需建立一個新的具體處理器,並將其新增到鏈條中,而無需修改現有程式碼。
案例
本人在看到上面程式碼,開始想優化思路的時候,實際並不是馬上想到責任鏈模式,這也是開頭說的,死記硬背並不牢靠。
我先想到的是一些使用過的工具或元件也有類似的場景,如spring中的攔截器,sentinel中的插槽。
spring攔截器
spring攔截器要實現HandlerInterceptor,它的作用是可以在請求處理前後做一些處理邏輯,如下定義了兩個攔截器。
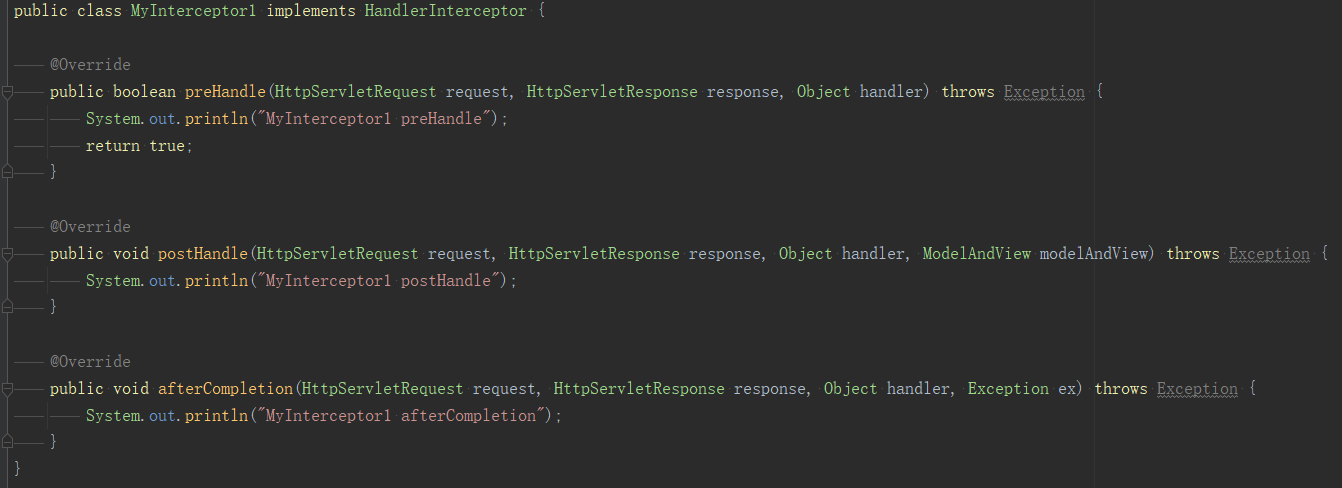

上面只是定義,還是註冊到spring中,如下
@Configuration
public class MyInterceptorConfig implements WebMvcConfigurer {
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(new MyInterceptor1());
registry.addInterceptor(new MyInterceptor2());
}
}
接著請求介面就會發現請求依次經過MyInterceptor1,MyInterceptor2,順序就是我們註冊時寫的順序。我們可以猜測spring肯定在請求過程會有一個迴圈,把所有的攔截器都拿出來依次執行,答案就是HandlerExecutionChain這個類中,從名字就可以看出它是一個Handler執行鏈,它內部有一個集合儲存了本次請求要經過的攔截器,可以看到我們的攔截器也在集合當中。
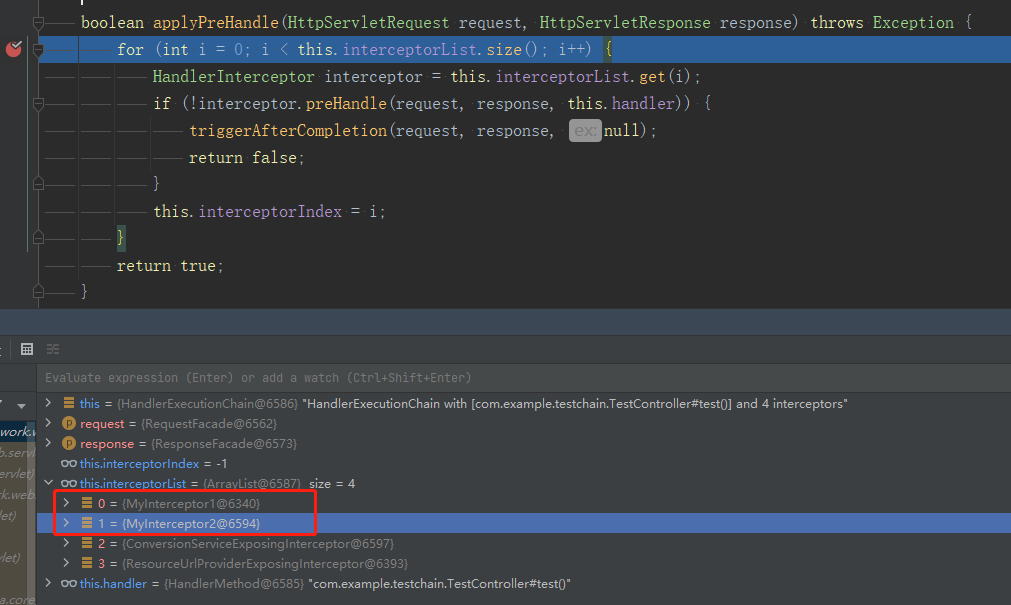
比較類似的servlet Filter也是類似原理,有興趣的可以對比一下。
sentinel solt
sentinel是阿里的一個流量管理中介軟體,它的架構圖如下:
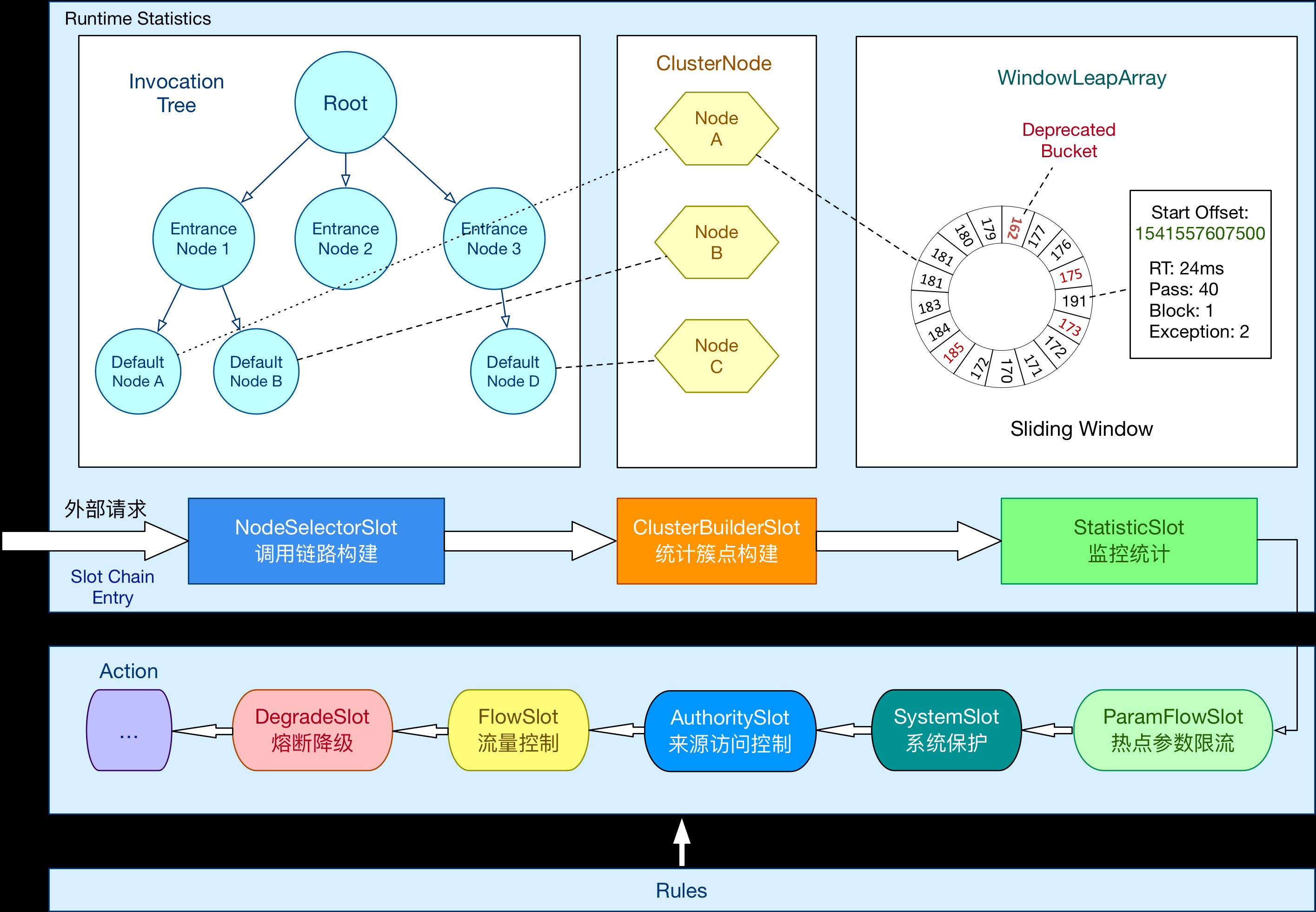
請求會經過一系列稱為「功能插槽」的物件,這些物件會對請求進行判斷,統計,限流,降級等。
這些物件在sentinel中是實現ProcessorSlot介面的物件,預設為我們提供了8種slot,使用SPI的機制載入,具體設定在sentinel包的META-INF目錄下。
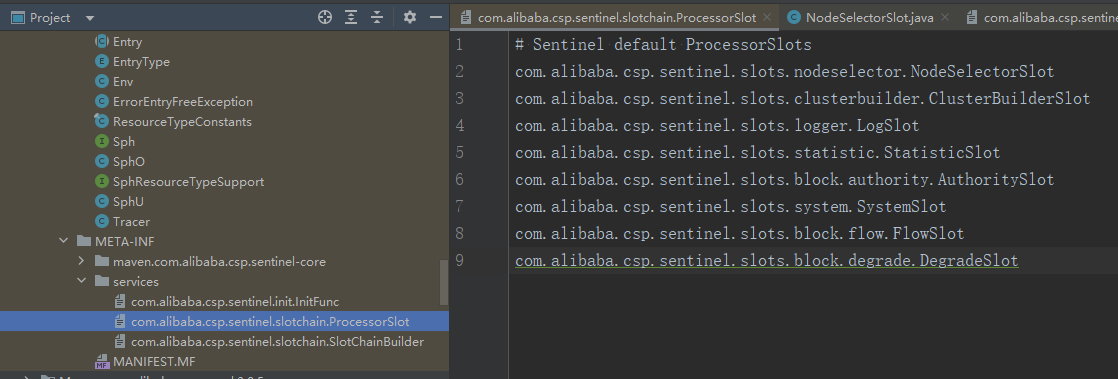
從上面架構圖可以看出,sentinel的solt會組成一個連結串列,在它們的基礎類別AbstractLinkedProcessorSlot中的next屬性就指向下一個節點,這些solt的順序就是設定的順序,也定義在Constants中,可以看到它是以1000為步長,以後想在中間新增一個就比較方便。
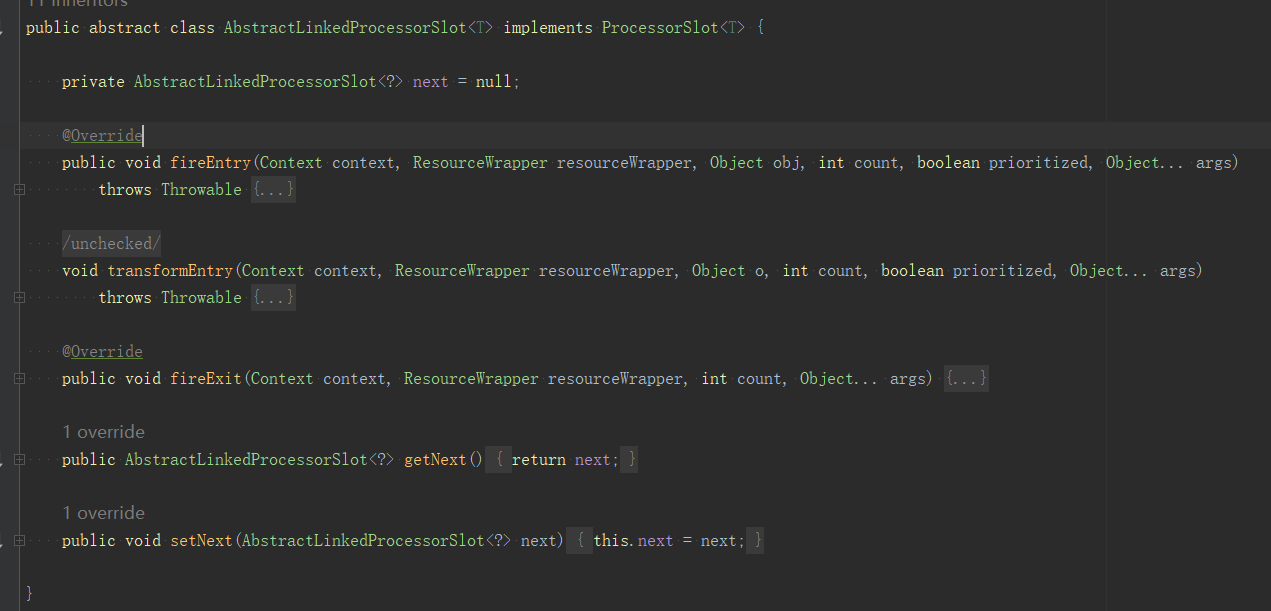
/**
* Order of default processor slots
*/
public static final int ORDER_NODE_SELECTOR_SLOT = -10000;
public static final int ORDER_CLUSTER_BUILDER_SLOT = -9000;
public static final int ORDER_LOG_SLOT = -8000;
public static final int ORDER_STATISTIC_SLOT = -7000;
public static final int ORDER_AUTHORITY_SLOT = -6000;
public static final int ORDER_SYSTEM_SLOT = -5000;
public static final int ORDER_FLOW_SLOT = -2000;
public static final int ORDER_DEGRADE_SLOT = -1000;
程式碼改造
從上面的案例可以看出,設計模式的實現並沒有固定的套路,只要設計思想一致就行了,實現方式可以有很多種,spring攔截器使用集合儲存,sentinel使用連結串列,適合才是最好的。
有了上面的知識儲備,現在我們可以開始改造程式碼了,以下程式碼都經過簡寫。
首先定義一個校驗介面,有一個校驗方法,由於原來程式碼的引數比較多,所以我們定義一個context來包裝。
public interface MyValidator {
/**
* 校驗
*
* @param context 上下文
* @return 校驗失敗時的錯誤碼,成功返回null
*/
FeedbackUploadCode valid(ValidateContext context);
}
接著我們定義一個抽象類作為基礎類別,來實現一些程式碼的複用,其中getNext用於指示下一個校驗器,也是我們構建順序的方式。
public abstract class AbstractMyValidator implements MyValidator {
public abstract AbstractMyValidator getNext();
}
由於校驗比較多,我們就拿前兩個校驗作為兩個例子,其中新增一個頭節點,作為起始節點,後面每一個校驗器只需要實現valid校驗邏輯,和說明它的下一個校驗器是誰即可,最後一個的next就是null。
class HeadValidator extends AbstractMyValidator {
@Override
public AbstractMyValidator getNext() {
return new TaskIdValidator();
}
@Override
public FeedbackUploadCode valid(ValidateContext context) {
return null;
}
}
class TaskIdValidator extends AbstractMyValidator {
@Override
public AbstractMyValidator getNext() {
return new DateFormatValidator();
}
@Override
public FeedbackUploadCode valid(ValidateContext context) {
try {
Long.parseLong(context.getFileBo().getTaskId());
return null;
} catch (NumberFormatException e) {
return FeedbackUploadCode.ERROR_TASK_ID_FORMAT;
}
}
}
class DateFormatValidator extends AbstractMyValidator {
private static final String DATE_TIME_PATTERN = "yyyy-MM-dd HH:mm:ss";
private static final DateTimeFormatter DATE_TIME_FORMATTER = DateTimeFormatter.ofPattern(DATE_TIME_PATTERN);
@Override
public AbstractMyValidator getNext() {
return null;
}
@Override
public FeedbackUploadCode valid(ValidateContext context) {
try {
LocalDateTime.parse(context.getFileBo().getCollectionTime(), DATE_TIME_FORMATTER);
return null;
} catch (DateTimeParseException e) {
return FeedbackUploadCode.ERROR_DATE_FORMAT;
}
}
}
新增一個Service,對外提供校驗方法,核心就是持有校驗器的頭節點,外部呼叫只需要組裝好上下文,校驗方法會通過頭節點遍歷所有的校驗器完成校驗。
@Service
public class ValidateService {
@Autowired
private FileDbService fileDbService;
private AbstractMyValidator feedbackValidator = new HeadValidator();
public Boolean valid(ValidateContext context) {
AbstractMyValidator currentValidator = feedbackValidator.getNext();
while (currentValidator != null) {
if (currentValidator.valid(context) != null) {
FeedbackFile file = buildOutsourceFeedbackFile(context.getFileBo(), context.getBatchId(), context.getUser(), context.getFileName());
fileDbService.insert(file);
return false;
}
currentValidator = currentValidator.getNext();
}
return true;
}
private FeedbackFile buildOutsourceFeedbackFile(FileBo fileBo, long batchId, LoginUser user, String fileName) {
FeedbackFile file = new FeedbackFile();
// set value
return file;
}
}
由於校驗的規則都比較簡單,我們可以把所有的校驗器都寫到同一個類中,並且程式碼順序就是校驗的順序,當然也可以像sentinel一樣維護一個順序值,或者像spring攔截器一樣把它們按照順序新增到集合中。
這樣以後新增一個校驗規則,就只需要新增一個校驗器,並且把它放到連結串列合適的位置即可,真正做到對擴充套件開放,對修改封閉。
更多分享,歡迎關注我的github:https://github.com/jmilktea/jtea