Spark RDD惰性計算的自主優化
原創/朱季謙
RDD(彈性分散式資料集)中的資料就如final定義一般,只可讀而無法修改,若要對RDD進行轉換或操作,那就需要建立一個新的RDD來儲存結果。故而就需要用到轉換和行動的運算元。
Spark執行是惰性的,在RDD轉換階段,只會記錄該轉換邏輯而不會執行,只有在遇到行動運算元時,才會觸發真正的運算,若整個生命週期都沒有行動運算元,那麼RDD的轉換程式碼便不會執行。
這樣的惰性計算,其實是有好處的,它在遇到行動運算元需要對整個DAG(有向無環圖)做優化,以下是一些優化說明——
本文的樣本部分內容如下,可以基於這些資料做驗證——
Amy Harris,39,男,18561,價效比,家居用品,天貓,微信支付,10,折扣優惠,品牌忠誠
Lori Willis,33,女,14071,功能性,家居用品,蘇寧易購,貨到付款,1,折扣優惠,日常使用
Jim Williams,61,男,14145,時尚潮流,汽車配件,淘寶,微信支付,3,免費贈品,禮物贈送
Anthony Perez,19,女,11587,時尚潮流,珠寶首飾,拼多多,支付寶,5,免費贈品,商品推薦
Allison Carroll,28,男,18292,環保可持續,美妝護膚,唯品會,信用卡,8,免費贈品,日常使用
Robert Rice,47,男,5347,時尚潮流,圖書音像,拼多多,微信支付,8,有優惠券,興趣愛好
Jason Bradley,25,男,9480,價效比,汽車配件,拼多多,信用卡,5,折扣優惠,促銷打折
Joel Small,18,女,15586,社交影響,食品飲料,亞馬遜,支付寶,5,無優惠券,日常使用
Stephanie Austin,33,男,7653,舒適度,汽車配件,亞馬遜,銀聯支付,3,無優惠券,跟風購買
Kathy Myers,33,男,18159,舒適度,美妝護膚,亞馬遜,貨到付款,4,無優惠券,商品推薦
Gabrielle Mccarty,57,男,19561,環保可持續,母嬰用品,網易考拉,支付寶,5,免費贈品,日常使用
Joan Smith,43,女,11896,品牌追求,圖書音像,亞馬遜,支付寶,4,免費贈品,商品推薦
Monica Garcia,19,男,16665,時尚潮流,電子產品,京東,貨到付款,7,免費贈品,商品推薦
Christopher Faulkner,55,男,3621,社交影響,美妝護膚,蘇寧易購,支付寶,7,無優惠券,日常使用
一、減少不必要的計算
RDD的惰性計算可以通過優化執行計劃去避免不必要的計算,同時可以將過濾操作下推到資料來源或者其他轉換操作之前,減少需要處理的資料量,進而達到計算的優化。
例如,執行以下這段spark程式碼時,
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("count")
val ss = SparkSession.builder().config(conf).getOrCreate()
val filePath: String = "transaction_data.csv"
val lineRDD = ss.sparkContext.textFile(filePath)
val value = lineRDD.map { x => {
println(s"列印 $x")
x.split(",")
} }
value.take(10).foreach(println)
ss.stop()
}
若Spark不是惰性計算的情況下,程式碼順序執行到這行 val lineRDD = ss.sparkContext.textFile(filePath)程式碼時,就會將transaction_data.csv檔案裡的幾萬條資料全部載入出來,然後再做計算。
而在惰性計算的情況下,直至執行這行程式碼 value.take(10).foreach(println)而遇到foreach這個行動運算元時,才會去執行前面的轉換,這時它會基於RDD的轉化自行做一個優化——在這個例子裡,它會基於lineRDD.take(5)這行程式碼只會從transaction_data.csv取出前5行,避免了將檔案裡的幾萬條資料全部取出。
列印結果如下,發現lineRDD.map確實只處理了前5條資料——
列印 Amy Harris,39,男,18561,價效比,家居用品,天貓,微信支付,10,折扣優惠,品牌忠誠
列印 Lori Willis,33,女,14071,功能性,家居用品,蘇寧易購,貨到付款,1,折扣優惠,日常使用
列印 Jim Williams,61,男,14145,時尚潮流,汽車配件,淘寶,微信支付,3,免費贈品,禮物贈送
列印 Anthony Perez,19,女,11587,時尚潮流,珠寶首飾,拼多多,支付寶,5,免費贈品,商品推薦
列印 Allison Carroll,28,男,18292,環保可持續,美妝護膚,唯品會,信用卡,8,免費贈品,日常使用
[Ljava.lang.String;@3c87e6b7
[Ljava.lang.String;@77bbadc
[Ljava.lang.String;@3c3a0032
[Ljava.lang.String;@7ceb4478
[Ljava.lang.String;@7fdab70c
二、操作合併和優化
Spark在執行行動運算元時,會自動將存在連續轉換的RDD操作合併到更為高效的執行計劃,這樣可以減少中間不是必要的RDD資料的生成和傳輸,可以整體提高計算的效率。這很像是,擺在你面前是一條彎彎曲曲的道路,但是因為你手裡有地圖,知道這條路是怎麼走的,因此,可以基於這樣的地圖,去嘗試發掘下是否有更好的直徑。
還是以一個程式碼案例說明,假如需要統計薪資在10000以上的人數。
執行的程式碼,是從transaction_data.csv讀取了幾萬條資料,然後將每行資料按","分割成陣列,再基於每個陣列去過濾出滿足薪資大於10000的資料,最後再做count統計出滿足條件的人數。
以下是最冗餘的程式碼,每個步驟都轉換生成一個新的RDD,彼此之間是連續的,這些RDD是會佔記憶體空間,同時增加了很多不必要的計算。
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("count")
val ss = SparkSession.builder().config(conf).getOrCreate()
val filePath: String = "transaction_data.csv"
val lineRDD = ss.sparkContext.textFile(filePath)
val array = lineRDD.map(_.split(","))
//過濾出薪資10000的資料
val valueRdd = array.filter(x => x.apply(3).toInt > 10000)
//統計薪資10000以上的人數
val count = valueRdd.count()
ss.stop()
}
Spark就可能會將這些存在連續的RDD進行優化,將其合併成一個單獨的轉換操作,直接就對原始RDD進行對映和過濾——
val value = ss.sparkContext.textFile(filePath).map(_.split(",")).filter(x =>{x.apply(3).toInt > 10000})
value.count()
這樣優化同時避免了多次迴圈遍歷,每個對映的陣列只需要遍歷一次即可。
可以通過coalesce(1)只設定一個分割區,使程式碼序列執行,然後增加列印驗證一下效果——
val value = ss.sparkContext.textFile(filePath).coalesce(1).map(x =>{
println(s"分割列印 $x")
x.split(",")
}).filter(x =>
{
println(s"過濾列印 ${x.apply(0)}")
x.apply(3).toInt > 10000
}
)
value.count()
列印部分結果,發現沒每遍歷一次,就把對映陣列和過濾都完成了,沒有像先前多個RDD那樣需要每次都得遍歷,這樣就能達到一定優化效果——
分割列印 Amy Harris,39,男,18561,價效比,家居用品,天貓,微信支付,10,折扣優惠,品牌忠誠
過濾列印 Amy Harris
分割列印 Lori Willis,33,女,14071,功能性,家居用品,蘇寧易購,貨到付款,1,折扣優惠,日常使用
過濾列印 Lori Willis
分割列印 Jim Williams,61,男,14145,時尚潮流,汽車配件,淘寶,微信支付,3,免費贈品,禮物贈送
過濾列印 Jim Williams
分割列印 Anthony Perez,19,女,11587,時尚潮流,珠寶首飾,拼多多,支付寶,5,免費贈品,商品推薦
過濾列印 Anthony Perez
分割列印 Allison Carroll,28,男,18292,環保可持續,美妝護膚,唯品會,信用卡,8,免費贈品,日常使用
過濾列印 Allison Carroll
分割列印 Robert Rice,47,男,5347,時尚潮流,圖書音像,拼多多,微信支付,8,有優惠券,興趣愛好
過濾列印 Robert Rice
這樣也提醒了我們,在遇到連續轉換的RDD時,其實可以自行做程式碼優化,避免產生中間可優化的RDD和遍歷操作。
三、窄依賴優化
RDD在執行惰性計算時,會盡可能進行窄依賴優化。
有窄依賴,便會有寬依賴,兩者有什麼區別呢?
窄依賴指的是父RDD的每個分割區只需要通過簡單的轉換操作就可以計算出對應的子RDD分割區,不涉及跨多個分割區的資料交換,即父子之間每個分割區都是一對一的。
前文提到的map、filter等轉換都屬於窄依賴的操作。
例如,array.filter(x => x.apply(3).toInt > 10000),父RDD有三個分割區,那麼三個分割區就會分別執行array.filter(x => x.apply(3).toInt > 10000)將過濾的資料傳給子RDD對應的分割區——
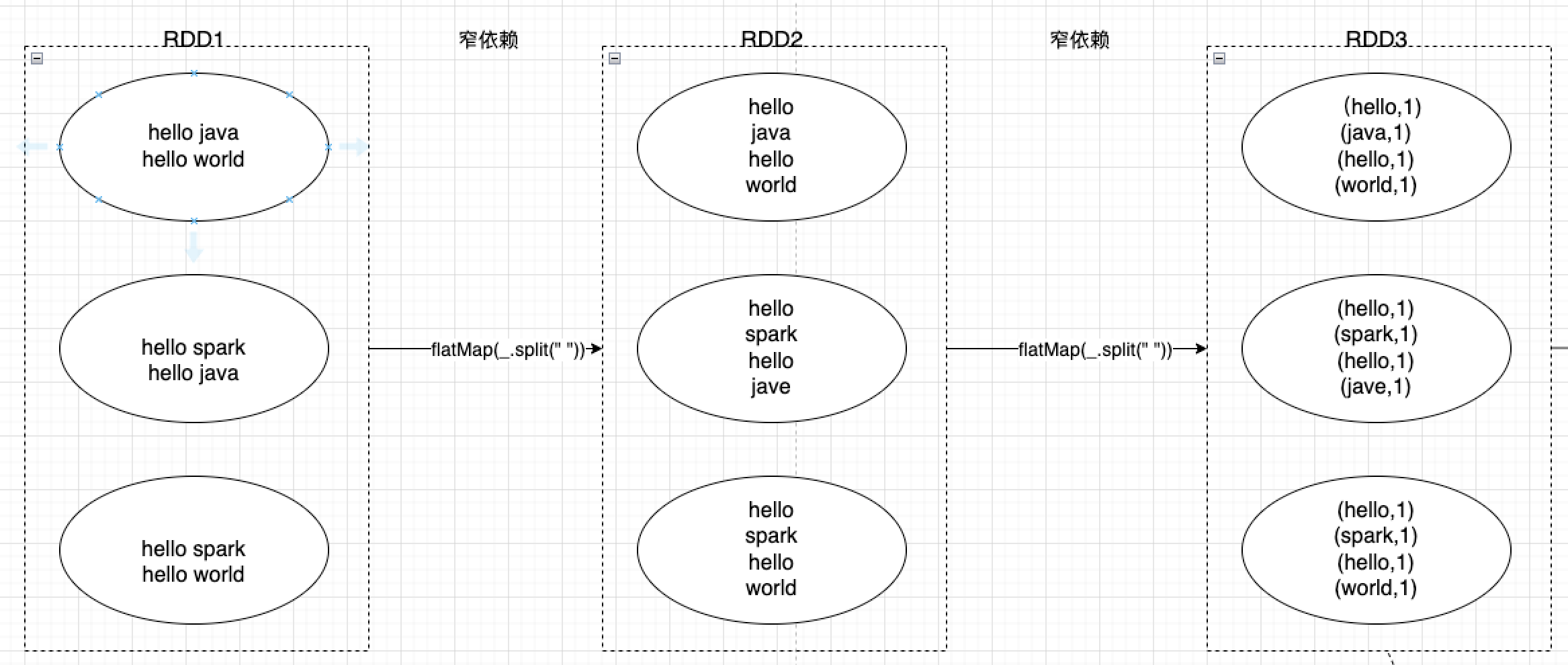
寬依賴指父RDD的每個分割區會通過跨區計算將原本同一個分割區資料分發到不同子分割區上,這中間涉及到shuffle重新洗牌操作,會存在較大的計算,父子之間分割區是一對多的。可以看到,父RDD同一個分割區的資料,在寬依賴情況下,會將相同的key傳輸到同一個分割區裡,這就意味著,同一個父RDD,如果存在多個不同的key,可能會分發到多個不同的子分割區上,進而出現shuffle重新洗牌操作。
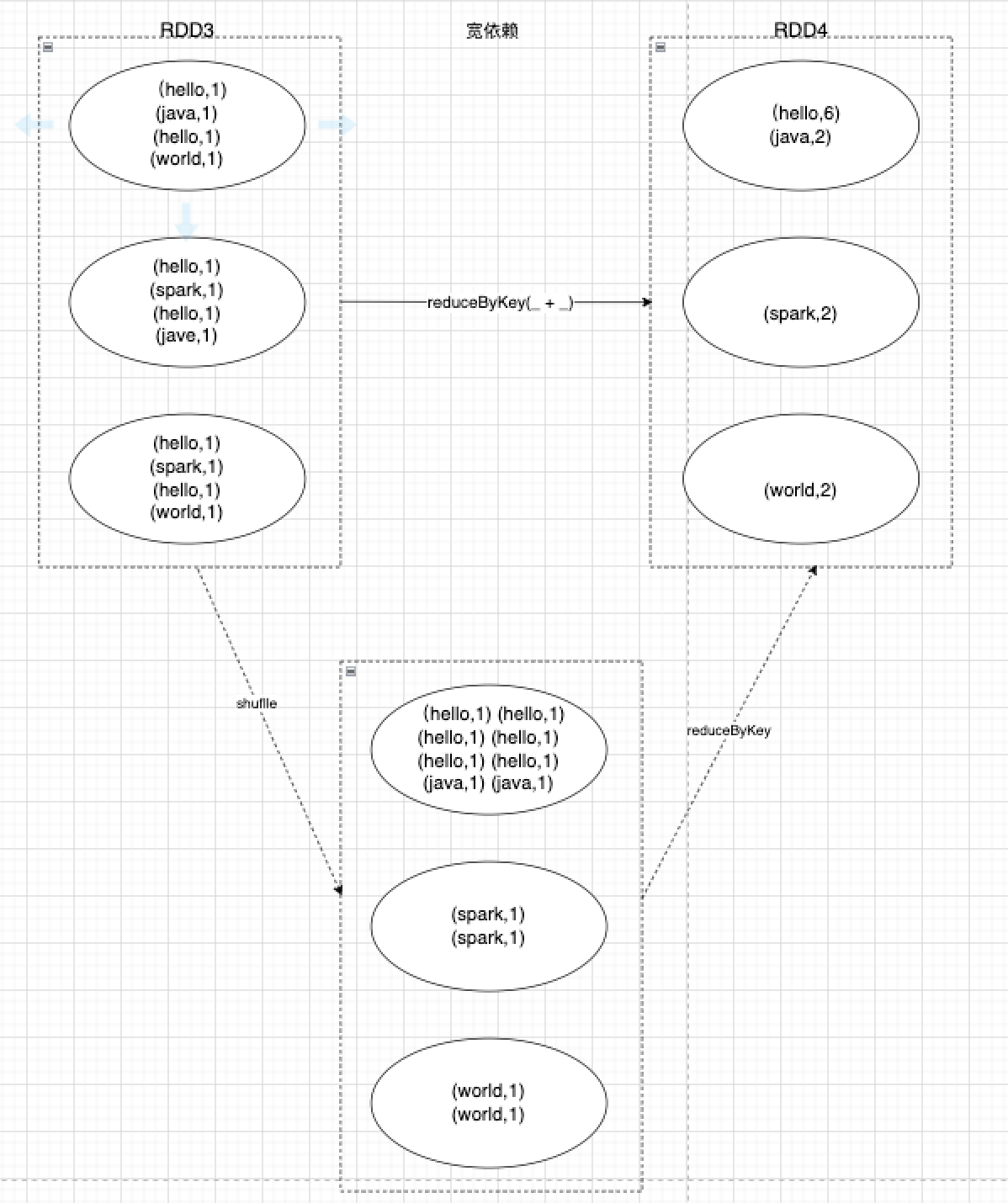
因此,RDD會盡可能的進行窄依賴優化,在無需跨區計算的情況下,就避免進行shuffle重新洗牌操作,將父分割區一對一地傳輸給子分割區。同時,窄依賴還有一個好處是,在子分割區出現丟失資料異常時,只需要重新計算對應的父分割區資料即可,無需將父分割區全部資料進行計算。