一張圖讀懂TuGraph Analytics開源技術架構
TuGraph Analytics(內部專案名GeaFlow)是螞蟻集團開源的分散式實時圖計算引擎,即流式圖計算。通過SQL+GQL融合分析語言對錶模型和圖模型進行統一處理,實現了流、批、圖一體化計算,並支援了Exactly Once語意、高可用以及一站式圖研發平臺等生產化能力。
開源專案程式碼目前託管在GitHub,歡迎業界同仁、巨量資料/圖計算技術愛好者關注我們的專案並參與共建。
專案地址:https://github.com/TuGraph-family/tugraph-analytics
GeaFlow論文【SIGMOD 2023】:GeaFlow: A Graph Extended and Accelerated Dataflow System
概覽
本文希望通過一張圖描述清楚TuGraph Analytics的整體架構脈絡和關鍵設計思路,以幫助大家快速對TuGraph Analytics專案的輪廓有個整體的認識。閒言少敘,直接上圖。
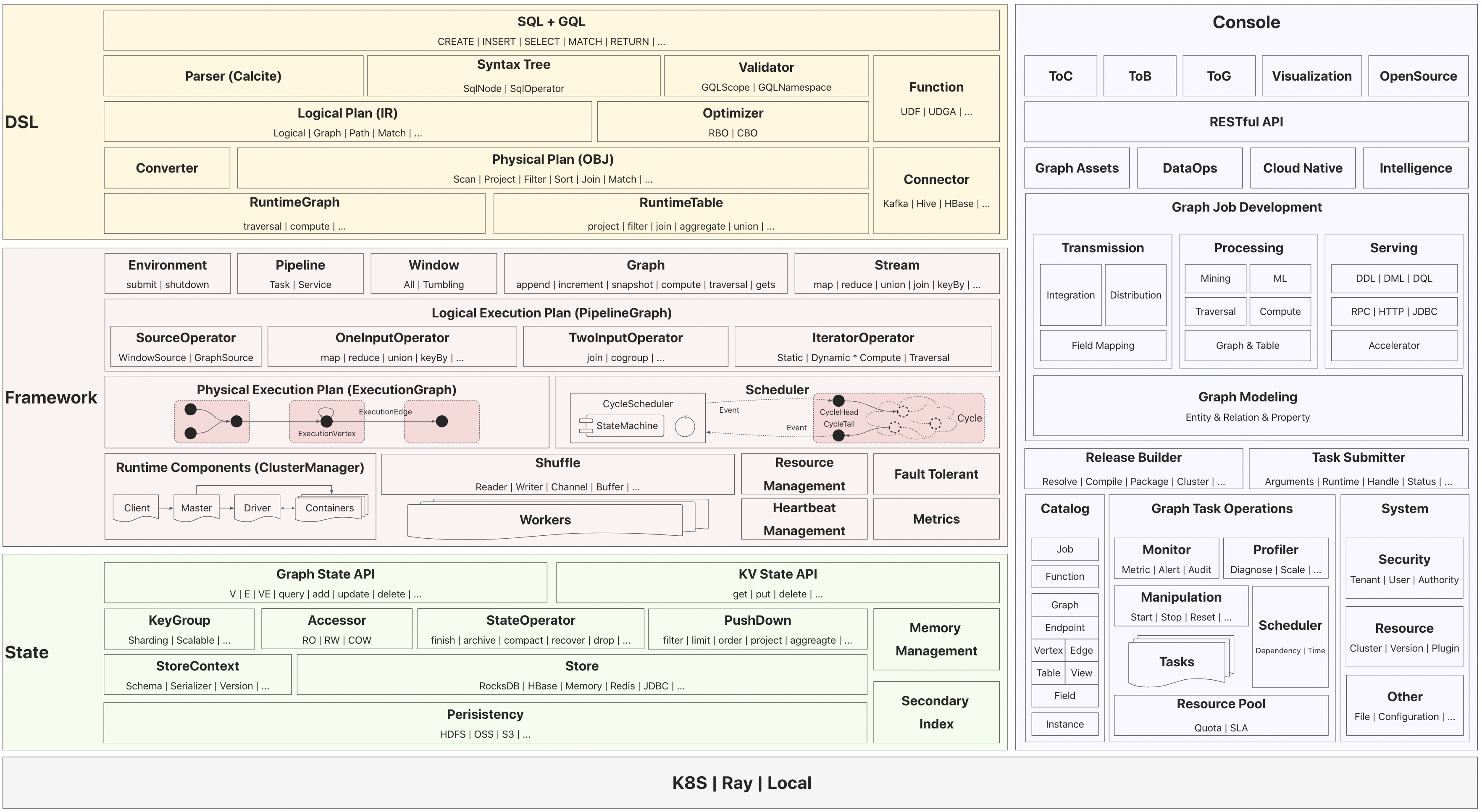
TuGraph Analytics開源技術架構一共分為五個部分:
- DSL層:即語言層。TuGraph Analytics設計了SQL+GQL的融合分析語言,支援對錶模型和圖模型統一處理。
- Framework層:即框架層。TuGraph Analytics設計了面向Graph和Stream的兩套API支援流、批、圖融合計算,並實現了基於Cycle的統一分散式排程模型。
- State層:即儲存層。TuGraph Analytics設計了面向Graph和KV的兩套API支援表資料和圖資料的混合儲存,整體採用了Sharing Nothing的設計,並支援將資料持久化到遠端儲存。
- Console平臺:TuGraph Analytics提供了一站式圖研發平臺,實現了圖資料的建模、加工、分析能力,並提供了圖作業的運維管控支援。
- 執行環境:TuGraph Analytics可以執行在多種異構執行環境,如K8S、Ray以及本地模式。
DSL層
DSL層是一個典型的編譯器技術架構,即語法分析、語意分析、中間程式碼生成(IR)、程式碼優化、目的碼生成(OBJ)的流程。
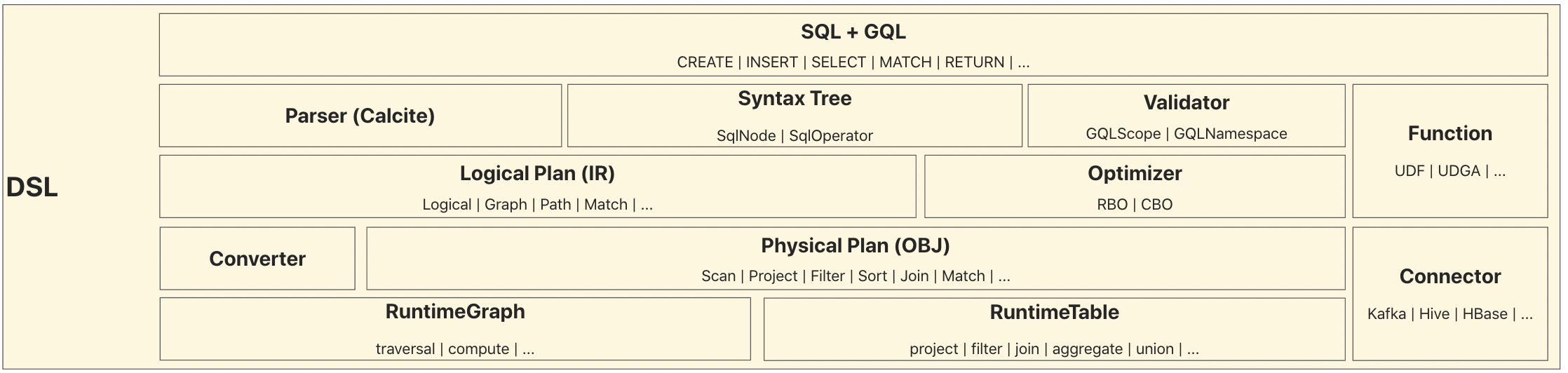
- 語言設計:TuGraph Analytics設計了SQL+GQL的融合語法,解決了圖+表一體化分析的訴求。具體語法設計可以參考文章:DSL語法檔案
- 語法分析:通過擴充套件Calcite的SqlNode和SqlOperator,實現SQL+GQL的語法解析器,生成統一的語法樹資訊。
- 語意分析:通過擴充套件Calcite的Scope和Namespace,實現自定義Validator,對語法樹進行約束語意檢查。
- 中間程式碼生成:通過擴充套件Calcite的RelNode,實現圖上的Logical RelNode,用於GQL語法的中間表示。
- 程式碼優化:優化器實現了大量的優化規則(RBO)用於提升執行效能,未來也會引入CBO。
- 目的碼生成:程式碼生成器Converter負責將Logical RelNode轉換為Physical RelNode,即目的碼。Physical RelNode可以直接翻譯為Graph/Table上的API呼叫。
- 自定義函數: TuGraph Analytics提供了大量的內建系統函數,使用者也可以根據需要註冊自定義函數。
- 自定義外掛: TuGraph Analytics允許使用者擴充套件自己的Connector型別,以支援不同的資料來源和資料格式。
Framework層
Framework層設計與Flink/Spark等同類巨量資料計算引擎有一定的相似性,即提供了類FlumeJava(FlumeJava: Easy, Efficient Data-Parallel Pipelines)的統一高階API(簡稱HLA),使用者呼叫高階API的過程會被轉換為邏輯執行計劃,邏輯執行計劃執行一定的優化(如ChainCombine、UnionPushUp等)後,被轉換為物理執行計劃,物理執行計劃會被排程器分發到分散式Worker上執行,最終Worker會回撥使用者傳遞的高階API函數邏輯,實現整個分散式計算鏈路的執行。

- 高階API:TuGraph Analytics通過Environment介面適配異構的分散式執行環境(K8S、Ray、Local),使用Pipeline封裝了使用者的資料處理流程,使用Window抽象統一了流處理(無界Window)和批次處理(有界Window)。Graph介面提供了靜態圖和動態圖(流圖)上的計算API,如append/snapshot/compute/traversal等,Stream介面提供了統一流批次處理API,如map/reduce/join/keyBy等。
- 邏輯執行計劃:邏輯執行計劃資訊統一封裝在PipelineGraph物件內,將高階API對應的運算元(Operator)組織在DAG中,運算元一共分為5大類:SourceOperator對應資料來源載入、OneInputOperator/TwoInputOperator對應傳統的資料處理、IteratorOperator對應靜態/動態圖計算。DAG中的點(PipelineVertex)記錄了運算元(Operator)的關鍵資訊,如型別、並行度、運算元函數等資訊,邊(PipelineEdge)則記錄了資料shuffle的關鍵資訊,如Partition規則(forward/broadcast/key等)、編解碼器等。
- 物理執行計劃:物理執行計劃資訊統一封裝在ExecutionGraph物件內,並支援二級巢狀結構,以儘可能將可以流水線執行的子圖(ExecutionVertexGroup)結構統一排程。圖中範例的物理執行計劃DAG被劃分為三部分子圖結構分別執行。
- 排程器:TuGraph Analytics設計了基於Cycle的排程器(CycleScheduler)實現對流、批、圖的統一排程,排程過程通過事件驅動模型觸發。物理執行計劃中的每部分子圖都會被轉換為一個ExecutionCycle物件,排程器會向Cycle的頭結點(Head)傳送Event,並接收Cycle尾結點(Tail)的發回的Event,形成一個完整的排程閉環。對於流處理,每一輪Cycle排程會完成一個Window的資料的處理,並會一直不停地執行下去。對於批次處理,整個Cycle排程僅執行一輪。對於圖處理,每一輪Cycle排程會完成一次圖計算迭代。
- 執行時元件:TuGraph Analytics執行時會拉起Client、Master、Driver、Container元件。當Client提交Pipeline給Driver後,會觸發執行計劃構建、分配Task(ResourceManagement提供資源)和排程。每個Container內可以執行多個Worker元件,不同Worker元件之間通過Shuffle模組交換資料,所有的Worker都需要定期向Master上報心跳(HeartbeatManagement),並向時序資料庫上報執行時指標資訊。另外TuGraph Analytics執行時也提供了故障容忍機制(FailOver),以便在異常/中斷後能繼續執行。
State層
State層設計相比於傳統的巨量資料計算引擎,除了提供面向表資料的KV儲存抽象,也支援了面向圖資料的Graph儲存抽象,以更好地支援面向圖模型的IO效能優化。

- State API:提供了面向KV儲存API,如get/put/delete等。以及面向圖儲存的API,如V/E/VE,以及點/邊的add/update/delete等。
- State執行層:通過KeyGroup的設計實現資料的Sharding和擴縮容能力,Accessor提供了面向不同讀寫策略和資料模型的IO抽象,StateOperator抽象了儲存層SPI,如finish(刷盤)、archive(Checkpoint)、compact(壓縮)、recover(恢復)等。另外,State提供了多種PushDown優化以加速IO存取效率。通過自定義記憶體管理和麵向屬性的二級索引也會提供大量的儲存存取優化手段。
- Store層:TuGraph Analytics支援了多種儲存系統型別,並通過StoreContext封裝了Schema、序列化器,以及資料版本資訊。
- 持久化層:State的資料支援持久化到遠端儲存系統,如HDFS、OSS、S3等。
Console平臺
Console平臺提供了一站式圖研發、運維的平臺能力,同時為引擎執行時提供後設資料(Catalog)服務。
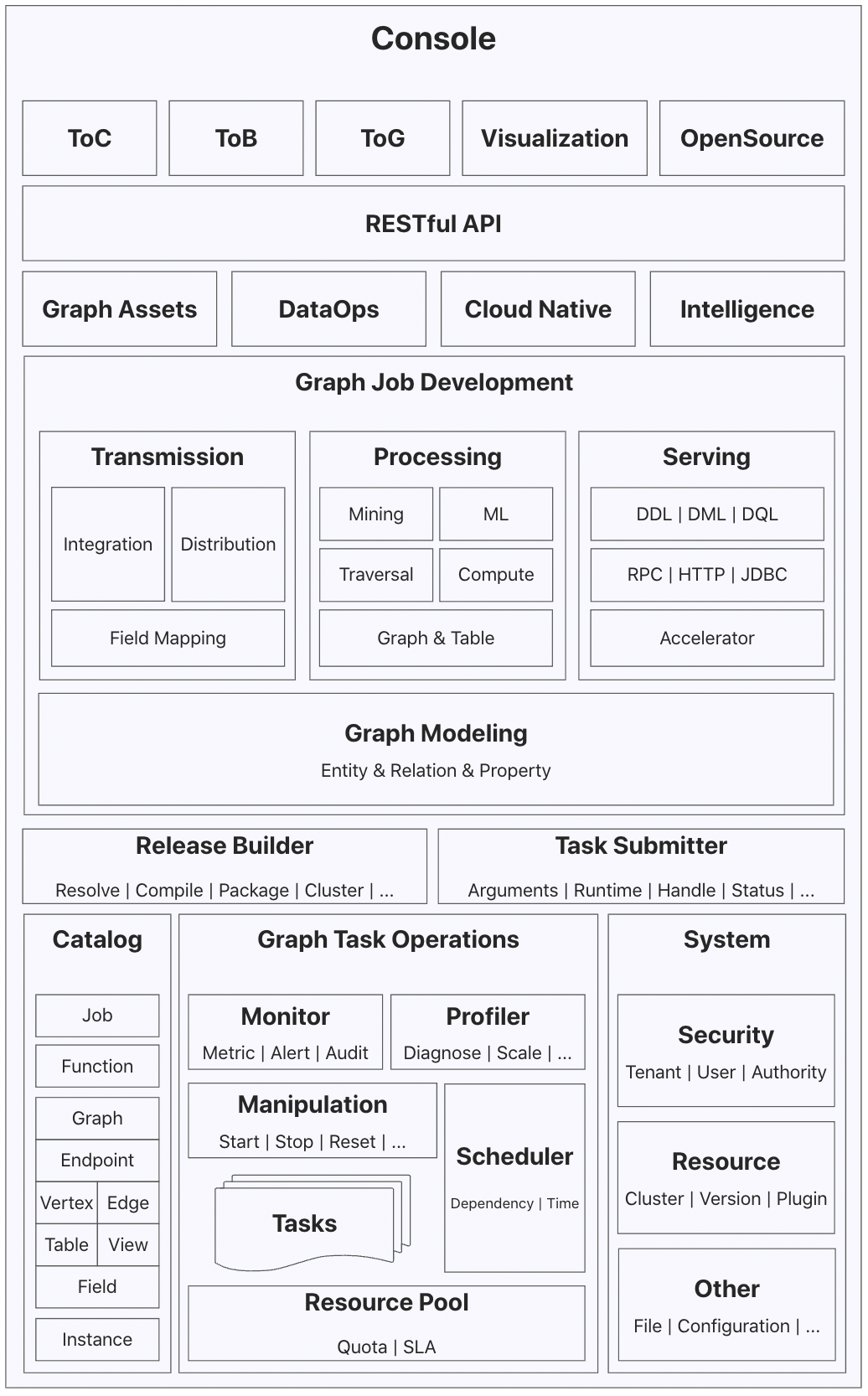
- 標準化API:平臺提供了標準化的RESTful API和認證機制,同時支援了頁面端和應用端的統一API服務能力。
- 任務研發:平臺支援「關係-實體-屬性」的圖資料建模。基於欄位對映設定,可以定義圖資料傳輸任務,包括資料整合(Import)和資料分發(Export)。基於圖表模型的圖資料加工任務支援多樣化的計算場景,如Traversal、Compute、Mining等。基於資料加速器的圖資料服務,提供了多協定的實時分析能力,支援BI、視覺化分析工具的接入整合。
- 構建提交:平臺通過任務和作業的獨立抽象,實現研發態與運維態的分離。任務開發完成後執行釋出動作,會自動觸發構建流水線(Release Builder),生成釋出版本。任務提交器(Task Submitter)負責將釋出版本的內容提交到執行環境,生成計算作業。
- 作業運維:作業屬於任務的執行態,平臺提供了作業的操縱(啟停、重置)、監控(指標、告警、審計)、調優(診斷、伸縮、調參)、排程等運維能力。作業的執行時資源會由資源池統一分配和管理。
- 後設資料服務:平臺同時承載了引擎執行時的後設資料服務能力,以實現研發與運維的自動化。後設資料以範例維度進行隔離,範例內的研發資源可以根據名字直接存取,如點、邊、圖、表、檢視、函數等。
- 系統管理:平臺提供了多租戶隔離機制、細粒度使用者許可權控制,以及系統資源的管理能力。
執行環境
TuGraph Analytics支援多種異構環境執行,以常見的K8S部署環境為例,其物理部署架構如下:

在TuGraph Analytics作業的全生命週期過程中,涉及的關鍵資料流程有:
- 研發階段:Console平臺提供了範例下所有的研發資源的管理,使用者可以在建立任務前,提前準備所需的研發資源資訊,並儲存在Catalog。
- 構建階段:任務建立完成後,通過釋出動作觸發構建流水線,使用者的JAR包、任務的ZIP包等會上傳到RemoteFileStore。
- 提交階段:作業提交時,Console會根據作業的引數設定、執行時環境資訊,以及遠端檔案地址等建立KubernetesJobClient,既而會拉起Client Pod,Client會拉起Master Pod,Master會拉起Container Pods和Driver Pod。所有的Pod拉起後,Client會把作業的Pipeline傳送給Driver執行,Driver最終通過Cycle排程的Events與Containers互動。所有的Pod啟動時都會從RemoteFileStore下載版本JAR包、使用者JAR包、作業ZIP包等資訊。Driver對DSL程式碼編譯時,也需要通過Console提供的Catalog API操作Schema資訊。
- 執行階段:作業執行時,各個元件會上報不同的資料和資訊。Master會上報作業的心跳彙總資訊,Driver會上報作業的Pipeline/Cycle指標以及錯誤資訊,Container會上報作業的Offset、指標定義以及錯誤資訊等。RuntimeMetaStore儲存作業的Pipeline/Cycle指標、Offset、心跳彙總、錯誤等資訊。HAMetaStore儲存各個執行元件的地址資訊。DataStore儲存State資料和作業FailOver時所需的後設資料資訊。MetricStore儲存執行時指標資訊。
- 監控階段:Console會主要查詢RuntimeMetaStore和MetricStore儲存的資訊用於作業的執行時監控。
- 清理階段:作業重置/刪除時,Console會對作業的RuntimeMeta、HAMeta以及部分Data做清理操作。
總結
希望通過以上的介紹,可以讓大家對TuGraph Analytics開源技術架構有個比較清晰的瞭解,我們非常歡迎開源社群的技術愛好者參與到專案的建設中來。
如果您對TuGraph Analytics專案比較感興趣,歡迎動動手指直達我們的GitHub倉庫github.com/TuGraph-family/tugraph-analytics,為我們的專案加一顆Star。【網路不暢可以嘗試使用VPN存取】
如果您對該專案的發展有好的建議和意見,歡迎大家提交Issue到開源社群,或者通過郵箱/釘釘群與我們直接聯絡。
釘釘群:TuGraph Analytics討論群
若本文對你有所幫助,您的 關注 和 推薦 是我分享知識的動力!