分庫分表之拆分鍵設計
眾所周知,在現實世界中,每一個資源都有其提供能力的最大上限,當單一資源達到最大上限後就得讓多個資源同時提供其能力來滿足使用方的需求。同理,在計算機世界中,單一資料庫資源不能滿足使用需求時,我們也會考慮使用多個資料庫同時提供服務來滿足需求。當使用了多個資料庫來提供服務時,最為關鍵的點是如何讓每一個資料庫比較均勻的承擔壓力,而不至於其中的某些資料庫壓力過大,某些資料庫沒什麼壓力。這其中的關鍵點之一就是拆分鍵的設計。
1 水平、垂直拆分
在關聯式資料庫中,當單個庫的負載、連線數、並行數等達到資料庫的最大上限時,就得考慮做資料庫和表的拆分。如一個簡單的電商資料庫,在業務初期,為了快速驗證業務模式,把使用者、商品、訂單都放到一個資料庫中,隨著業務的發展及使用者量的增長,單資料庫逐漸不能支撐業務(MySQL中單記錄容量超過1K時,單表資料量建議不超過一千萬條),這時就得考慮把資料庫和表做出拆分。
1.1 垂直拆分
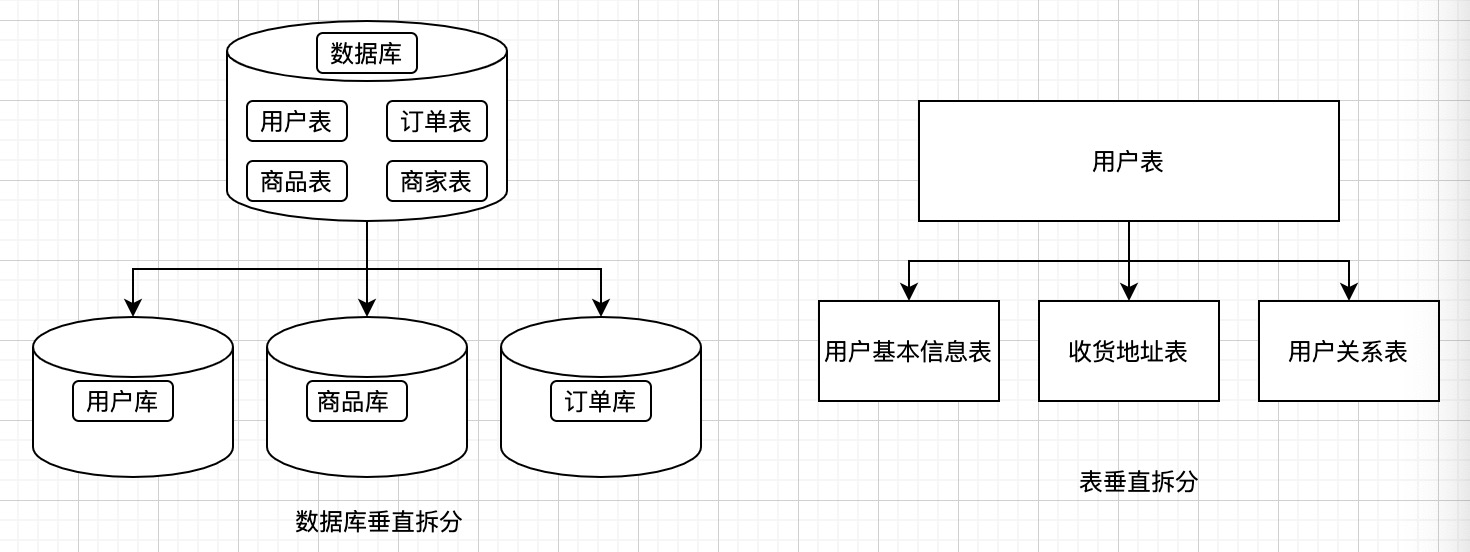
簡單的說就是將資料庫及表由一個拆分為多個,如我們這裡的電商資料庫,可以垂直拆分為使用者資料庫、商品資料庫和訂單資料庫,訂單表可以垂直拆分為訂單基本資訊表,訂單收貨地址表、訂單商品表等,每一個表裡儲存了一個訂單的一部分資料。
1.2 水平拆分
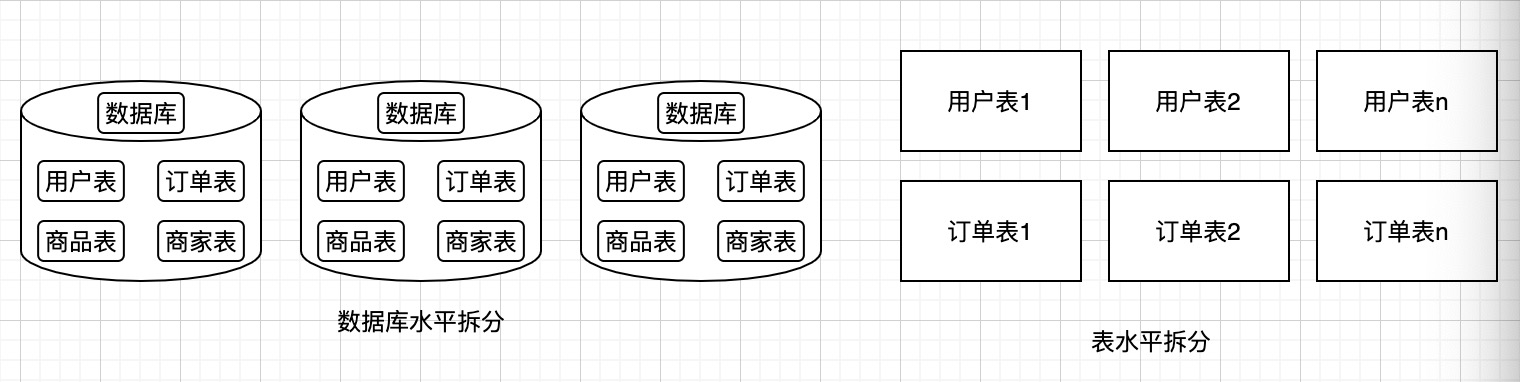
簡單的說就是將一個庫、一個表擴充套件為多個庫,多個表,每一個拆分後的表中儲存的依然是一個訂單的完整資訊。如電商資料庫,我們按水平拆分資料庫和表後,每一個拆分後的資料庫表與現有未拆分前的都保持一致。
1.3 常用拆分方法
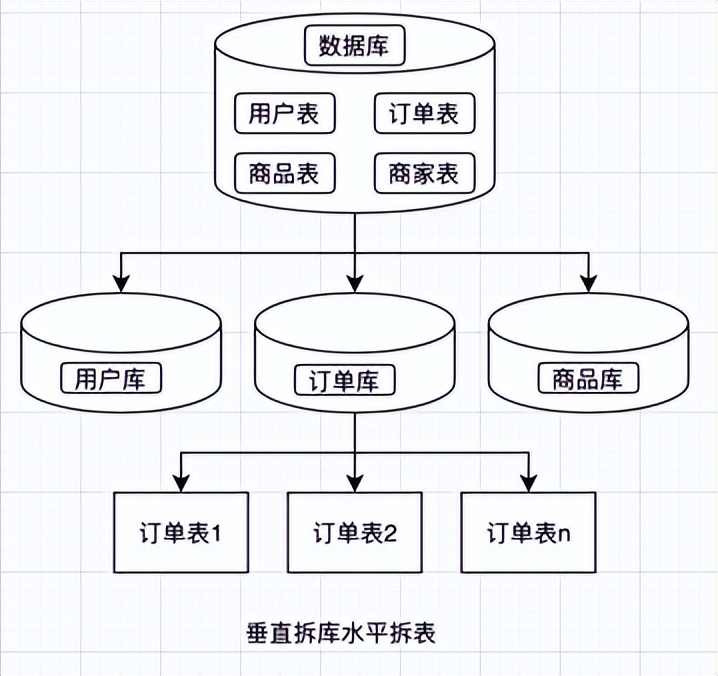
上述僅從理論上講解了可行的水平、垂直拆分方法,在實際的生產上,我們拆分一般是按照水平拆表、垂直拆庫這一原則進行,在業務比較複雜的場景下也會對錶進行垂直拆分。
2 拆分鍵的選取
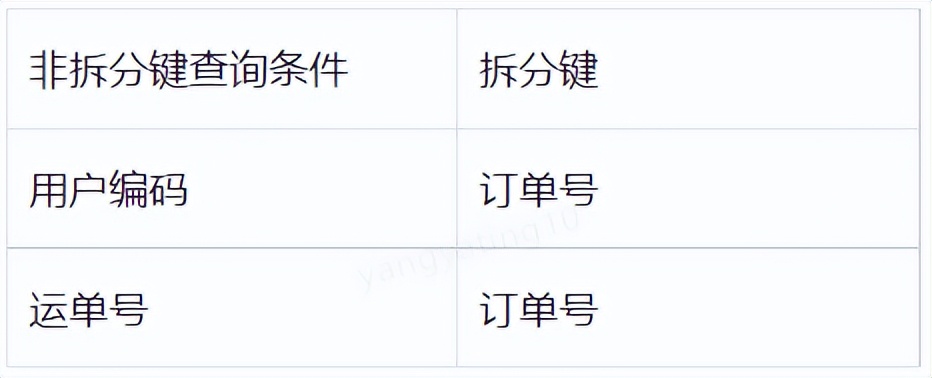
分庫分表的關鍵項之一是拆分鍵的選取,一般情況下,拆分鍵的選取遵循以什麼維度進行查詢就選取該維度為拆分鍵。如:訂單表就以訂單號作為拆分鍵,商品表就以商品編號作為拆分鍵。拆分鍵選取後,對於一些非拆分鍵的單條件查詢,我們需要怎麼支援呢?在這裡提供3種方法供參考。
2.1 等值法
對於非拆分鍵的單條件查詢,對這一個單條件的賦值,可以將其值與拆分鍵保持一致。比如在電商場景中,使用者下訂單後,需要通過物流給使用者把商品送到使用者手上。對於使用者來說僅能看到訂單資訊,訂單上展示的物流資訊使用者也是通過訂單號查詢而來;但對於物流系統來說,其系統裡的業務主鍵(拆分鍵)是運單號,此時,運單號如果和訂單號相同,即可完美解決這一問題。訂單表和運單表的基本資料模型如下:
1)訂單表

2)運單表

在訂單表中,拆分鍵order_id與運單表中的拆分鍵waybill_code值相同,當按訂單號查詢運單表裡的運單資訊時,可以直接查詢拆分鍵waybill_code獲取訂單對應的運單資訊。
2.2 索引法
對於常用的非拆分鍵,我們可以將其與拆分鍵之間建立一個索引關係,當按該條件進行查詢時,先查詢對應的拆分鍵,再通過拆分鍵查詢對應的資料資訊。訂單表的索引法查詢表模型如下:
1)索引表
例:使用者user001在商城上購買了一支筆下單的訂單號為10001,商家發貨後,物流公司給的運單號是Y0023
2)該使用者的訂單表、運單表模型如下:
訂單表:

運單表:

索引表:

當查詢使用者(user001)的下單記錄時,通過使用者編碼先查詢索引表,查詢出user001的所有下單的訂單號(10001),再通過訂單號查詢訂單表獲取使用者的訂單資訊;同理,根據運單號(Y00232)查詢訂單資訊時,在索引表裡先查詢到對應的訂單號,再根據訂單號查詢對應的訂單資訊。
2.3 基因法
拆分鍵與非拆分鍵的單號生成規則中,存在相同規則的部分且該部分被用作拆分鍵來進行庫表的定位。比如:訂單號生成時,生成一個Long型別的單號,由於Long是64位元的,我們可以用其低4位元取模來定位該訂單儲存的資料庫及表,其他表的拆分鍵也用Long型別的低4位元取模來定位對應的資料庫及表。還是用訂單表和運單表的模型做解釋如下:
1)訂單表

2)運單表
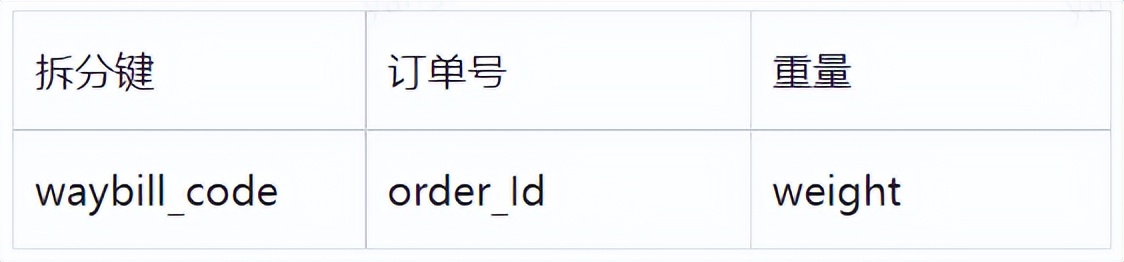
當通過訂單表裡的訂單號查運單表時,通過訂單號的低4位元定位到該訂單號在運單資料庫及表的位置,再直接通過指令碼查詢出訂單號對應的運單資訊。
3 拆分鍵的生成
拆分鍵選取後,接下來是拆分鍵的生成,拆分鍵的生成有多種方式,建議根據業務量及並行量的大小來確定拆分鍵生成的規則,在這裡介紹幾種常用的拆分鍵生成規則。
3.1 資料庫自增主鍵
在並行量不大的情況下,我們可以使用MySQL資料庫裡的自增主鍵來實現拆分鍵。
3.2 UUID
在Java裡,可以使用Java自帶的UUID工具類直接生成,UUID的組成:UUID=當前日期和時間+時鐘序列+全域性唯一的IEEE機器識別號組成。其中,全域性唯一的IEEE機器識別號一般是通過網路卡的MAC地址獲得,沒有網路卡時以其他的方式獲得。UUID生成的編號不會重複,但不利於閱讀和理解。
import java.util.UUID;
public class UUIDTest {
public static void main(String[] args) {
UUID uuid = UUID.randomUUID();
System.out.println(uuid.toString());
}
}
3.3 雪花演演算法
雪花演演算法生成的ID是一個64位元大小的整數,結構如下:
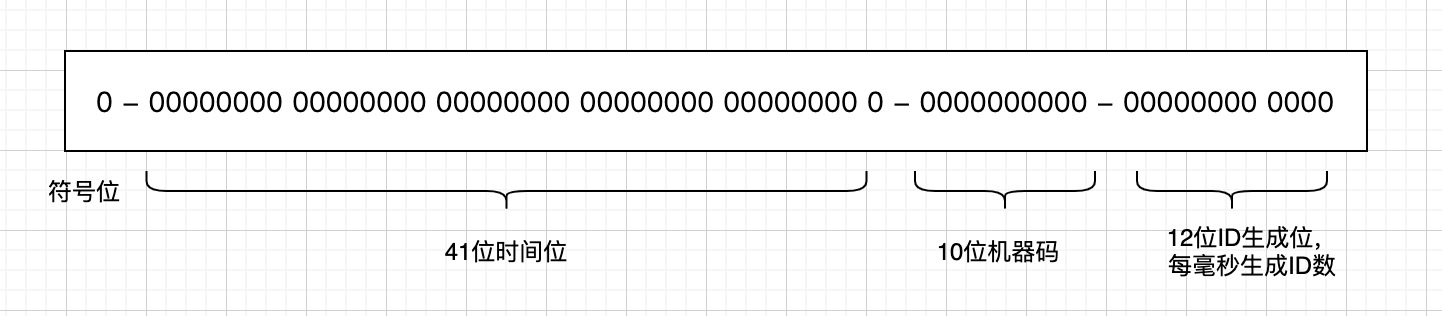
從其結構可以看出,第一位是符號位,在使用時一般不使用,後面的41位是時間位,是由時間戳來確定的,後面的10位是機器位,最後的12位元是生成的ID序列,是每豪秒生成的ID數,即每毫秒可以生成4096個ID。從該結構可以看出,10位機器位決定了使用機器的上限,在某些業務場景下,需要所有的機器使用同一個業務空間,這可能導致機器超限;同時,每一個機器分配後如果機器宕機需要更換時,對ID的回收也需要有相應的策略;最為關鍵的一點是機器的時間是動態調整的,有可能會出現時間回退幾毫秒的情況,如果這個時候獲取到這個時間,則會生成重複的ID,導致資料重複。
4 提升總結
單資料庫不能滿足業務場景的情況下,主要的思路還是要進行拆分,無論是NoSQL還是關聯式資料庫,隨著業務量的增長,都得需要把多個伺服器資源組合成一個整體共同來支撐業務。資料庫拆分後,如果業務上有多個複雜查詢條件的需求,一般就得把資料同步到NoSQL資料庫裡,由NoSQL來提供支援。無論什麼時候,資料庫提供的主要能力是儲存能力,對於複雜的計算需求,一般是需要在業務邏輯裡實現。
作者:京東物流 廖宗雄
來源:京東雲開發者社群 自猿其說Tech 轉載請註明來源