GAN!生成對抗網路GAN全維度介紹與實戰
本文為生成對抗網路GAN的研究者和實踐者提供全面、深入和實用的指導。通過本文的理論解釋和實際操作指南,讀者能夠掌握GAN的核心概念,理解其工作原理,學會設計和訓練自己的GAN模型,並能夠對結果進行有效的分析和評估。
作者 TechLead,擁有10+年網際網路服務架構、AI產品研發經驗、團隊管理經驗,同濟本復旦碩,復旦機器人智慧實驗室成員,阿里雲認證的資深架構師,專案管理專業人士,上億營收AI產品研發負責人
一、引言
1.1 生成對抗網路簡介

生成對抗網路(GAN)是深度學習的一種創新架構,由Ian Goodfellow等人於2014年首次提出。其基本思想是通過兩個神經網路,即生成器(Generator)和判別器(Discriminator),相互競爭來學習資料分佈。
- 生成器:負責從隨機噪聲中學習生成與真實資料相似的資料。
- 判別器:嘗試區分生成的資料和真實資料。
兩者之間的競爭推動了模型的不斷進化,使得生成的資料逐漸接近真實資料分佈。
1.2 應用領域概覽
GANs在許多領域都有廣泛的應用,從藝術和娛樂到更復雜的科學研究。以下是一些主要的應用領域:
- 影象生成:如風格遷移、人臉生成等。
- 資料增強:通過生成額外的樣本來增強訓練集。
- 醫學影象分析:例如通過GAN生成醫學影象以輔助診斷。
- 聲音合成:利用GAN生成或修改語音訊號。



1.3 GAN的重要性
GAN的提出不僅在學術界引起了廣泛關注,也在工業界取得了實際應用。其重要性主要體現在以下幾個方面:
- 資料分佈學習:GAN提供了一種有效的方法來學習複雜的資料分佈,無需任何明確的假設。
- 多學科交叉:通過與其他領域的結合,GAN開啟了許多新的研究方向和應用領域。
- 創新能力:GAN的生成能力使其在設計、藝術和創造性任務中具有潛在的用途。
二、理論基礎
2.1 生成對抗網路的工作原理
生成對抗網路(GAN)由兩個核心部分組成:生成器(Generator)和判別器(Discriminator),它們共同工作以達到特定的目標。
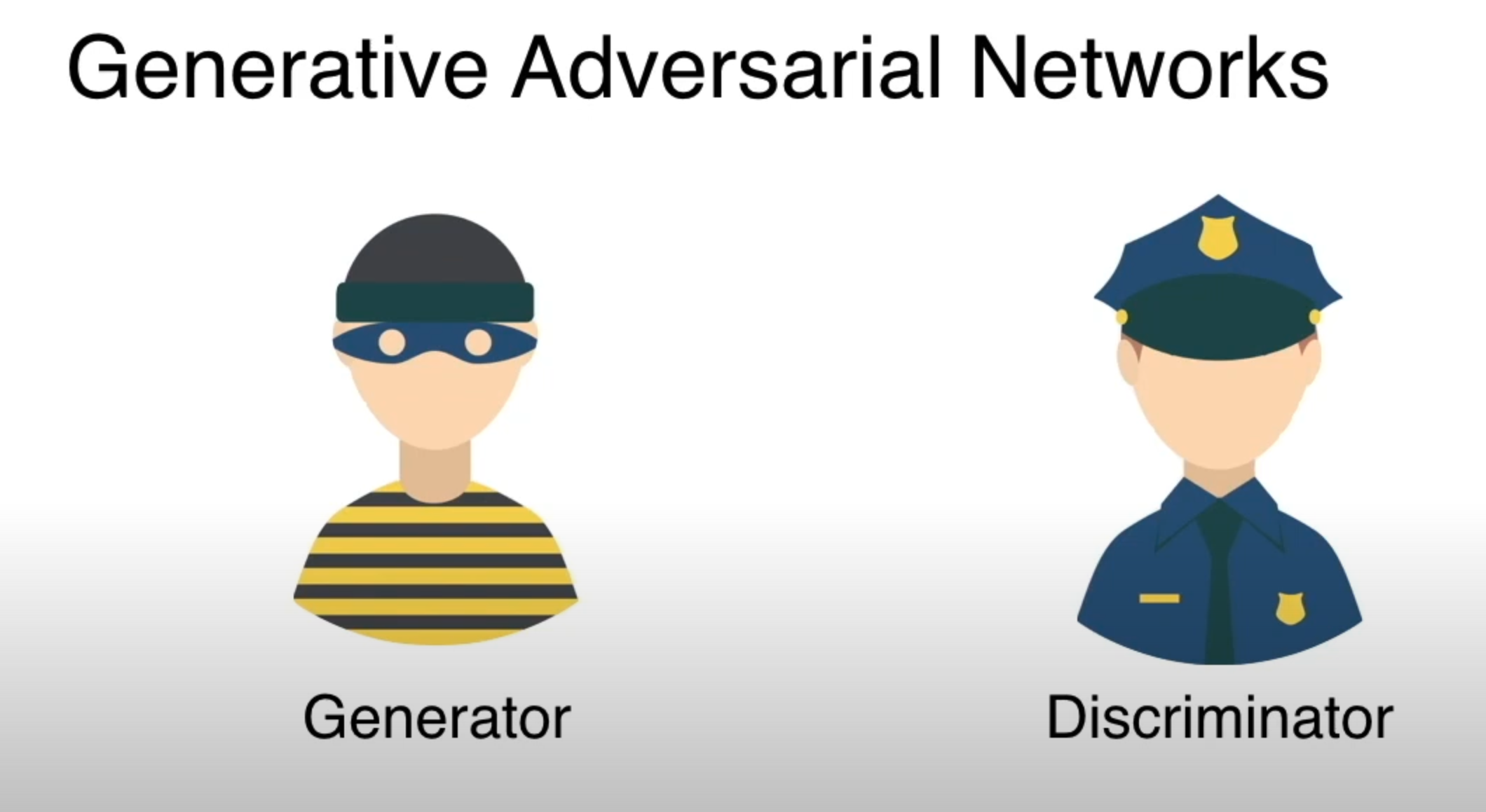
2.1.1 生成器
生成器負責從一定的隨機分佈(如正態分佈)中抽取隨機噪聲,並通過一系列的神經網路層將其對映到資料空間。其目標是生成與真實資料分佈非常相似的樣本,從而迷惑判別器。
生成過程
def generator(z):
# 輸入:隨機噪聲z
# 輸出:生成的樣本
# 使用多層神經網路結構生成樣本
# 範例程式碼,輸出生成的樣本
return generated_sample
2.1.2 判別器
判別器則嘗試區分由生成器生成的樣本和真實的樣本。判別器是一個二元分類器,其輸入可以是真實資料樣本或生成器生成的樣本,輸出是一個標量,表示樣本是真實的概率。
判別過程
def discriminator(x):
# 輸入:樣本x(可以是真實的或生成的)
# 輸出:樣本為真實樣本的概率
# 使用多層神經網路結構判斷樣本真偽
# 範例程式碼,輸出樣本為真實樣本的概率
return probability_real
2.1.3 訓練過程
生成對抗網路的訓練過程是一場兩個網路之間的博弈,具體分為以下幾個步驟:
- 訓練判別器:固定生成器,使用真實資料和生成器生成的資料訓練判別器。
- 訓練生成器:固定判別器,通過反向傳播調整生成器的引數,使得判別器更難區分真實和生成的樣本。
訓練程式碼範例
# 訓練判別器和生成器
# 範例程式碼,同時註釋後增加指令的輸出
2.1.4 平衡與收斂
GAN的訓練通常需要仔細平衡生成器和判別器的能力,以確保它們同時進步。此外,GAN的訓練收斂性也是一個複雜的問題,涉及許多技術和戰略。
2.2 數學背景
生成對抗網路的理解和實現需要涉及多個數學概念,其中主要包括概率論、最佳化理論、資訊理論等。
2.2.1 損失函數
損失函數是GAN訓練的核心,用於衡量生成器和判別器的表現。
生成器損失
生成器的目標是最大化判別器對其生成樣本的錯誤分類概率。損失函數通常表示為:
L_G = -\mathbb{E}[\log D(G(z))]
其中,(G(z)) 表示生成器從隨機噪聲 (z) 生成的樣本,(D(x)) 是判別器對樣本 (x) 為真實的概率估計。
判別器損失
判別器的目標是正確區分真實資料和生成資料。損失函數通常表示為:
L_D = -\mathbb{E}[\log D(x)] - \mathbb{E}[\log (1 - D(G(z)))]
其中,(x) 是真實樣本。
2.2.2 優化方法
GAN的訓練涉及複雜的非凸優化問題,常用的優化演演算法包括:
- 隨機梯度下降(SGD):基本的優化演演算法,適用於大規模資料集。
- Adam:自適應學習率優化演演算法,通常用於GAN的訓練。
優化程式碼範例
# 使用PyTorch的Adam優化器
from torch.optim import Adam
optimizer_G = Adam(generator.parameters(), lr=0.0002, betas=(0.5, 0.999))
optimizer_D = Adam(discriminator.parameters(), lr=0.0002, betas=(0.5, 0.999))
2.2.3 高階概念
- Wasserstein距離:在某些GAN變體中,用於衡量生成分佈與真實分佈之間的距離。
- 模式崩潰:訓練過程中生成器可能會陷入生成有限樣本的情況,導致訓練失敗。
這些數學背景為理解生成對抗網路的工作原理提供了堅實基礎,並揭示了訓練過程中的複雜性和挑戰性。通過深入探討這些概念,讀者可以更好地理解GAN的內部運作,從而進行更高效和有效的實現。
2.3 常見架構及變體
生成對抗網路自從提出以來,研究者們已經提出了許多不同的架構和變體,以解決原始GAN存在的一些問題,或者更好地適用於特定應用。
2.3.1 DCGAN(深度折積生成對抗網路)
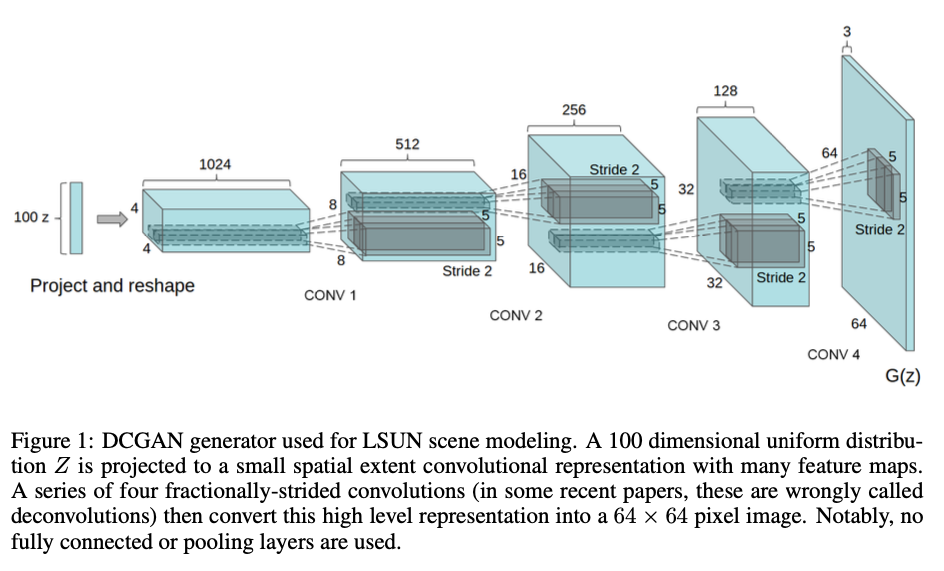
DCGAN是使用折積層的GAN變體,特別適用於影象生成任務。
- 特點:使用批次歸一化,LeakyReLU啟用函數,無全連線層等。
- 應用:影象生成,特徵學習等。
程式碼結構範例
# DCGAN生成器的PyTorch實現
import torch.nn as nn
class DCGAN_Generator(nn.Module):
def __init__(self):
super(DCGAN_Generator, self).__init__()
# 定義折積層等
2.3.2 WGAN(Wasserstein生成對抗網路)
WGAN通過使用Wasserstein距離來改進GAN的訓練穩定性。
- 特點:使用Wasserstein距離,剪裁權重等。
- 優勢:訓練更穩定,可解釋性強。
2.3.3 CycleGAN
CycleGAN用於進行影象到影象的轉換,例如將馬的影象轉換為斑馬的影象。
- 特點:使用迴圈一致損失確保轉換的可逆性。
- 應用:風格遷移,影象轉換等。
2.3.4 InfoGAN
InfoGAN通過最大化潛在程式碼和生成樣本之間的互資訊,使得潛在空間具有更好的解釋性。
- 特點:使用互資訊作為額外損失。
- 優勢:潛在空間具有解釋性,有助於理解生成過程。
2.3.5 其他變體
此外還有許多其他的GAN變體,例如:
- ProGAN:逐漸增加解析度的方法來生成高解析度影象。
- BigGAN:大型生成對抗網路,適用於大規模資料集上的影象生成。
生成對抗網路的這些常見架構和變體展示了GAN在不同場景下的靈活性和強大能力。理解這些不同的架構可以幫助讀者選擇適當的模型來解決具體問題,也揭示了生成對抗網路研究的多樣性和豐富性。
三、實戰演示
3.1 環境準備和資料集

在進入GAN的實際編碼和訓練之前,我們首先需要準備適當的開發環境和資料集。這裡的內容會涵蓋所需庫的安裝、硬體要求、以及如何選擇和處理適用於GAN訓練的資料集。
3.1.1 環境要求
構建和訓練GAN需要一些特定的軟體庫和硬體支援。
軟體依賴
- Python 3.x: 編寫和執行程式碼的語言環境。
- PyTorch: 用於構建和訓練深度學習模型的庫。
- CUDA: 如果使用GPU訓練,則需要安裝。
程式碼範例:安裝依賴
# 安裝PyTorch
pip install torch torchvision
硬體要求
- GPU: 推薦使用具有足夠記憶體的NVIDIA GPU,以加速計算。
3.1.2 資料集選擇與預處理
GAN可以用於多種型別的資料,例如影象、文字或聲音。以下是資料集選擇和預處理的一般指南:
資料集選擇
- 影象生成:常用的資料集包括CIFAR-10, MNIST, CelebA等。
- 文字生成:可以使用WikiText, PTB等。
資料預處理
- 規範化:將影象畫素值縮放到特定範圍,例如[-1, 1]。
- 資料增強:旋轉、裁剪等增強泛化能力。
程式碼範例:資料載入與預處理
# 使用PyTorch載入CIFAR-10資料集
from torchvision import datasets, transforms
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
train_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
小結
環境準備和資料集的選擇與預處理是實施GAN專案的關鍵初始步驟。選擇適當的軟體、硬體和資料集,並對其進行適當的預處理,將為整個專案的成功奠定基礎。讀者應充分考慮這些方面,以確保專案從一開始就在可行和有效的基礎上進行。
3.2 生成器構建
生成器是生成對抗網路中的核心部分,負責從潛在空間的隨機噪聲中生成與真實資料相似的樣本。以下是更深入的探討:
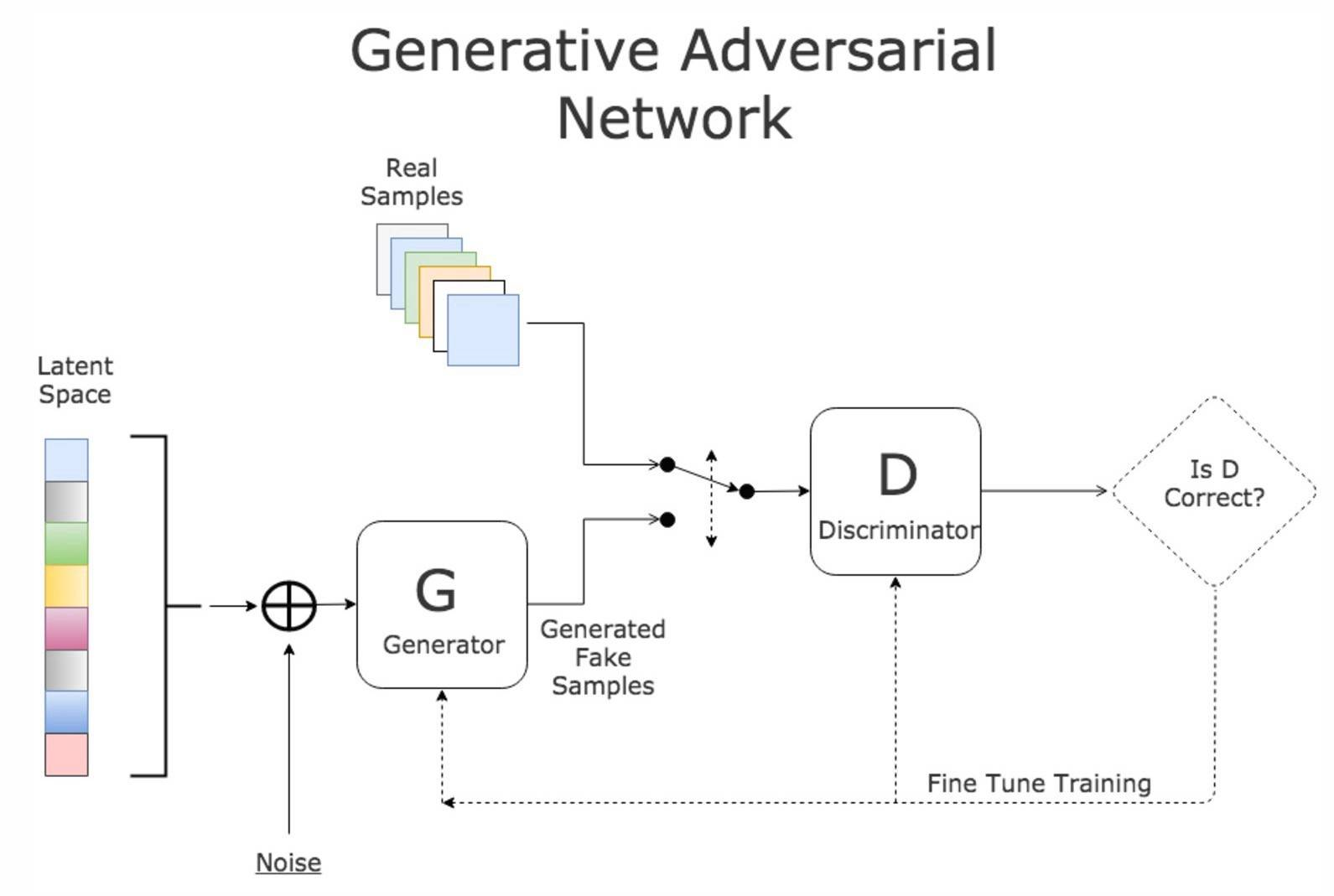
架構設計
生成器的設計需要深思熟慮,因為它決定了生成資料的質量和多樣性。
全連線層
適用於較簡單的資料集,如MNIST。
class SimpleGenerator(nn.Module):
def __init__(self):
super(SimpleGenerator, self).__init__()
self.main = nn.Sequential(
nn.Linear(100, 256),
nn.ReLU(),
nn.Linear(256, 512),
nn.ReLU(),
nn.Linear(512, 784),
nn.Tanh()
)
def forward(self, input):
return self.main(input)
折積層
適用於更復雜的影象資料生成,如DCGAN。
class ConvGenerator(nn.Module):
def __init__(self):
super(ConvGenerator, self).__init__()
self.main = nn.Sequential(
# 逆折積層
nn.ConvTranspose2d(100, 512, 4),
nn.BatchNorm2d(512),
nn.ReLU(),
# ...
)
def forward(self, input):
return self.main(input)
輸入潛在空間
- 維度選擇:潛在空間的維度選擇對於模型的生成能力有重要影響。
- 分佈選擇:通常使用高斯分佈或均勻分佈。
啟用函數和歸一化
- ReLU和LeakyReLU:常用在生成器的隱藏層。
- Tanh:通常用於輸出層,將畫素值縮放到[-1, 1]。
- 批歸一化:幫助提高訓練穩定性。
反折積技巧
- 逆折積:用於上取樣影象。
- PixelShuffle:更高效的上取樣方法。
與判別器的協調
- 設計匹配:生成器和判別器的設計應相互協調。
- 折積層引數共用:有助於增強生成能力。
小結
生成器構建是一個複雜和細緻的過程。通過深入瞭解生成器的各個組成部分和它們是如何協同工作的,我們可以設計出適應各種任務需求的高效生成器。不同型別的啟用函數、歸一化、潛在空間設計以及與判別器的協同工作等方面的選擇和優化是提高生成器效能的關鍵。
3.3 判別器構建
生成對抗網路(GAN)的判別器是一個二分類模型,用於區分生成的資料和真實資料。以下是判別器構建的詳細內容:
判別器的角色和挑戰
- 角色:區分真實資料和生成器生成的虛假資料。
- 挑戰:平衡生成器和判別器的能力。
架構設計
- 折積網路:常用於影象資料,效率較高。
- 全連線網路:對於非影象資料,例如時間序列。
程式碼範例:折積判別器
class ConvDiscriminator(nn.Module):
def __init__(self):
super(ConvDiscriminator, self).__init__()
self.main = nn.Sequential(
nn.Conv2d(3, 64, 4, stride=2, padding=1),
nn.LeakyReLU(0.2),
# ...
nn.Sigmoid() # 二分類輸出
)
def forward(self, input):
return self.main(input)
啟用函數和歸一化
- LeakyReLU:增加非線性,防止梯度消失。
- Layer Normalization:訓練穩定性。
損失函數設計
- 二分類交叉熵損失:常用損失函數。
- Wasserstein距離:WGAN中使用,理論基礎堅實。
正則化和穩定化
- 正則化:如L1、L2正則化防止過擬合。
- Gradient Penalty:例如WGAN-GP中,增加訓練穩定性。
特殊架構設計
- PatchGAN:區域性感受域的判別器。
- 條件GAN:結合額外資訊的判別器。
與生成器的協調
- 協同訓練:注意保持生成器和判別器訓練的平衡。
- 漸進增長:例如ProGAN中,逐步增加解析度。
小結
判別器的設計和實現是複雜的多步過程。通過深入瞭解判別器的各個元件以及它們是如何協同工作的,我們可以設計出適應各種任務需求的強大判別器。判別器的架構選擇、啟用函數、損失設計、正則化方法,以及如何與生成器協同工作等方面的選擇和優化,是提高判別器效能的關鍵因素。
3.4 損失函數和優化器
損失函數和優化器是訓練生成對抗網路(GAN)的關鍵元件,它們共同決定了GAN的訓練速度和穩定性。
損失函數
損失函數量化了GAN的生成器和判別器之間的競爭程度。
1. 原始GAN損失
- 生成器損失:欺騙判別器。
- 判別器損失:區分真實和虛假樣本。
# 判別器損失
real_loss = F.binary_cross_entropy(D_real, ones_labels)
fake_loss = F.binary_cross_entropy(D_fake, zeros_labels)
discriminator_loss = real_loss + fake_loss
# 生成器損失
generator_loss = F.binary_cross_entropy(D_fake, ones_labels)
2. Wasserstein GAN損失
- 理論優勢:更連續的梯度。
- 訓練穩定性:解決模式崩潰問題。
3. LSGAN(最小平方損失)
- 減小梯度消失:在訓練早期。
4. hinge損失
- 魯棒性:對噪聲和異常值具有魯棒性。
優化器
優化器負責根據損失函數的梯度更新模型的引數。
1. SGD
- 基本但強大。
- 學習率調整:如學習率衰減。
2. Adam
- 自適應學習率。
- 用於大多數情況:通常效果很好。
3. RMSProp
- 適用於非平穩目標。
- 自適應學習率。
# 範例
optimizer_G = optim.Adam(generator.parameters(), lr=0.0002, betas=(0.5, 0.999))
optimizer_D = optim.Adam(discriminator.parameters(), lr=0.0002, betas=(0.5, 0.999))
超引數選擇
- 學習率:重要的調整引數。
- 動量引數:例如Adam中的beta。
- 批大小:可能影響訓練穩定性。
小結
損失函數和優化器在GAN的訓練中起著核心作用。損失函數界定了生成器和判別器之間的競爭關係,而優化器則決定了如何根據損失函數的梯度來更新這些模型的引數。在設計損失函數和選擇優化器時需要考慮許多因素,包括訓練的穩定性、速度、魯棒性等。理解各種損失函數和優化器的工作原理,可以幫助我們為特定任務選擇合適的方法,更好地訓練GAN。
3.5 模型訓練
在生成對抗網路(GAN)的實現中,模型訓練是最關鍵的階段之一。本節詳細探討模型訓練的各個方面,包括訓練迴圈、收斂監控、偵錯技巧等。
訓練迴圈
訓練迴圈是GAN訓練的心臟,其中包括了前向傳播、損失計算、反向傳播和引數更新。
程式碼範例:訓練迴圈
for epoch in range(epochs):
for real_data, _ in dataloader:
# 更新判別器
optimizer_D.zero_grad()
real_loss = ...
fake_loss = ...
discriminator_loss = real_loss + fake_loss
discriminator_loss.backward()
optimizer_D.step()
# 更新生成器
optimizer_G.zero_grad()
generator_loss = ...
generator_loss.backward()
optimizer_G.step()
訓練穩定化
GAN訓練可能非常不穩定,下面是一些常用的穩定化技術:
- 梯度裁剪:防止梯度爆炸。
- 使用特殊的損失函數:例如Wasserstein損失。
- 漸進式訓練:逐步增加模型的複雜性。
模型評估
GAN沒有明確的損失函數來評估生成器的效能,因此通常需要使用一些啟發式的評估方法:
- 視覺檢查:人工檢查生成的樣本。
- 使用標準資料集:例如Inception Score。
- 自定義度量標準:與應用場景相關的度量。
超引數調優
- 網格搜尋:系統地探索超引數空間。
- 貝葉斯優化:更高效的搜尋策略。
偵錯和視覺化
- 視覺化損失曲線:瞭解訓練過程的動態。
- 檢查梯度:例如使用梯度直方圖。
- 生成樣本檢查:實時觀察生成樣本的質量。
分散式訓練
- 資料並行:在多個GPU上並行處理資料。
- 模型並行:將模型分佈在多個GPU上。
小結
GAN的訓練是一項複雜和微妙的任務,涉及許多不同的元件和階段。通過深入瞭解訓練迴圈的工作原理,學會使用各種穩定化技術,和掌握模型評估和超引數調優的方法,我們可以更有效地訓練GAN模型。
3.6 結果分析和視覺化
生成對抗網路(GAN)的訓練結果分析和視覺化是評估模型效能、解釋模型行為以及調整模型引數的關鍵環節。本節詳細討論如何分析和視覺化GAN模型的生成結果。
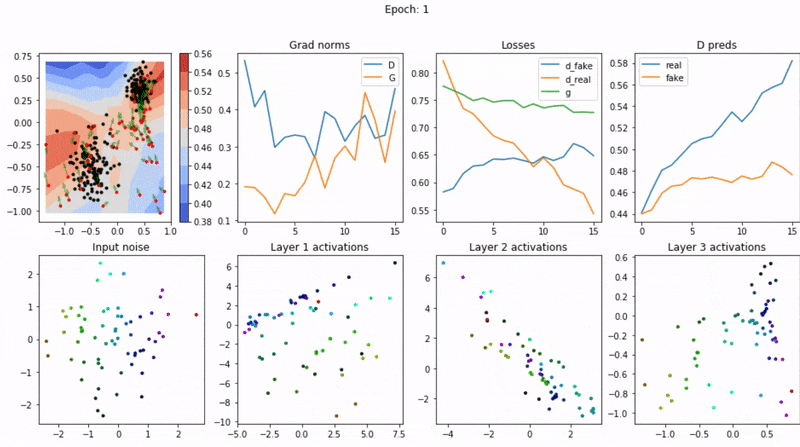
結果視覺化
視覺化是理解GAN的生成能力的直觀方法。常見的視覺化方法包括:
1. 生成樣本展示
- 隨機樣本:從隨機噪聲生成的樣本。
- 插值樣本:展示樣本之間的平滑過渡。
2. 特徵空間視覺化
- t-SNE和PCA:用於降維的技術,可以揭示高維特徵空間的結構。
3. 訓練過程動態
- 損失曲線:觀察訓練穩定性。
- 樣本質量隨時間變化:揭示生成器的學習過程。
量化評估
雖然視覺化直觀,但量化評估提供了更準確的效能度量。常用的量化方法包括:
1. Inception Score (IS)
- 多樣性和一致性的平衡。
- 在標準資料集上評估。
2. Fréchet Inception Distance (FID)
- 比較真實和生成分佈。
- 較低的FID表示更好的效能。
模型解釋
理解GAN如何工作以及每個部分的作用可以幫助改進模型:
- 敏感性分析:如何輸入噪聲的變化影響輸出。
- 特徵重要性:哪些特徵最影響判別器的決策。
應用場景分析
- 實際使用情況下的效能。
- 與現實世界任務的結合。
持續監測和改進
- 自動化測試:保持模型效能的持續監測。
- 迭代改進:基於結果反饋持續優化模型。
小結
結果分析和視覺化不僅是GAN工作流程的最後一步,還是一個持續的、反饋驅動的過程,有助於改善和優化整個系統。視覺化和量化分析工具提供了深入瞭解GAN效能的方法,從直觀的生成樣本檢查到複雜的量化度量。通過這些工具,我們可以評估模型的優點和缺點,並做出有針對性的調整。
四、總結
生成對抗網路(GAN)作為一種強大的生成模型,在許多領域都有廣泛的應用。本文全面深入地探討了GAN的不同方面,涵蓋了理論基礎、常見架構、實際實現和結果分析。以下是主要的總結點:

1. 理論基礎
- 工作原理:GAN通過一個生成器和一個判別器的博弈過程實現強大的生成能力。
- 數學背景:深入瞭解了損失函數、優化方法和穩定化策略。
- 架構與變體:討論了不同的GAN結構和它們的適用場景。
2. 實戰實現
- 環境準備:提供了準備訓練環境和資料集的指導。
- 模型構建:詳細解釋了生成器和判別器的設計以及損失函數和優化器的選擇。
- 訓練過程:深入討論了訓練穩定性、模型評估、超引數調優等關鍵問題。
- 結果分析:強調了視覺化、量化評估和持續改進的重要性。
3. 技術挑戰與前景
- 訓練穩定性:GAN訓練可能不穩定,需要深入理解和恰當選擇穩定化技術。
- 評估標準:缺乏統一的評估標準仍是一個挑戰。
- 多樣性與真實性的平衡:如何在保持生成樣本多樣性的同時確保其真實性。
- 實際應用:將GAN成功地應用於實際問題,仍需進一步研究和實踐。
展望
GAN的研究和應用仍然是一個快速發展的領域。隨著技術的不斷進步和更多的實際應用,我們期望未來能夠看到更多高質量的生成樣本,更穩定的訓練方法,以及更廣泛的跨領域應用。GAN的理論和實踐的深入融合將為人工智慧和機器學習領域開闢新的可能性。
作者 TechLead,擁有10+年網際網路服務架構、AI產品研發經驗、團隊管理經驗,同濟本復旦碩,復旦機器人智慧實驗室成員,阿里雲認證的資深架構師,專案管理專業人士,上億營收AI產品研發負責人
如有幫助,請多關注
個人微信公眾號:【TechLead】分享AI與雲服務研發的全維度知識,談談我作為TechLead對技術的獨特洞察。
TeahLead KrisChang,10+年的網際網路和人工智慧從業經驗,10年+技術和業務團隊管理經驗,同濟軟體工程本科,復旦工程管理碩士,阿里雲認證雲服務資深架構師,上億營收AI產品業務負責人。