TCP的可靠性之道:確認重傳和流量控制
TCP 全稱為 Transmission Control Protocol(傳輸控制協定),是一種面向連線的、可靠的、基於位元組流的傳輸層通訊協定,其中可靠性是相對於其他傳輸協定的優勢點。TCP 為了確保資料傳輸的可靠性主要做了以下幾點:
- 傳送確認機制
- 丟包重傳機制
- 滑動視窗
- 擁塞控制
TCP 的傳輸基於位元組流,記錄起始序列號、是否傳送、是否接收。本文從實戰出發,使用 Wireshark 抓包工具來分析具體的請求。
確認和重傳
- TCP 報文頭中有兩個欄位:
- Sequence number 序列號:表示要傳送資料的起始號
- Acknowledgment number 確認號:表示訊息已經接收,返回下次要傳送的起始號
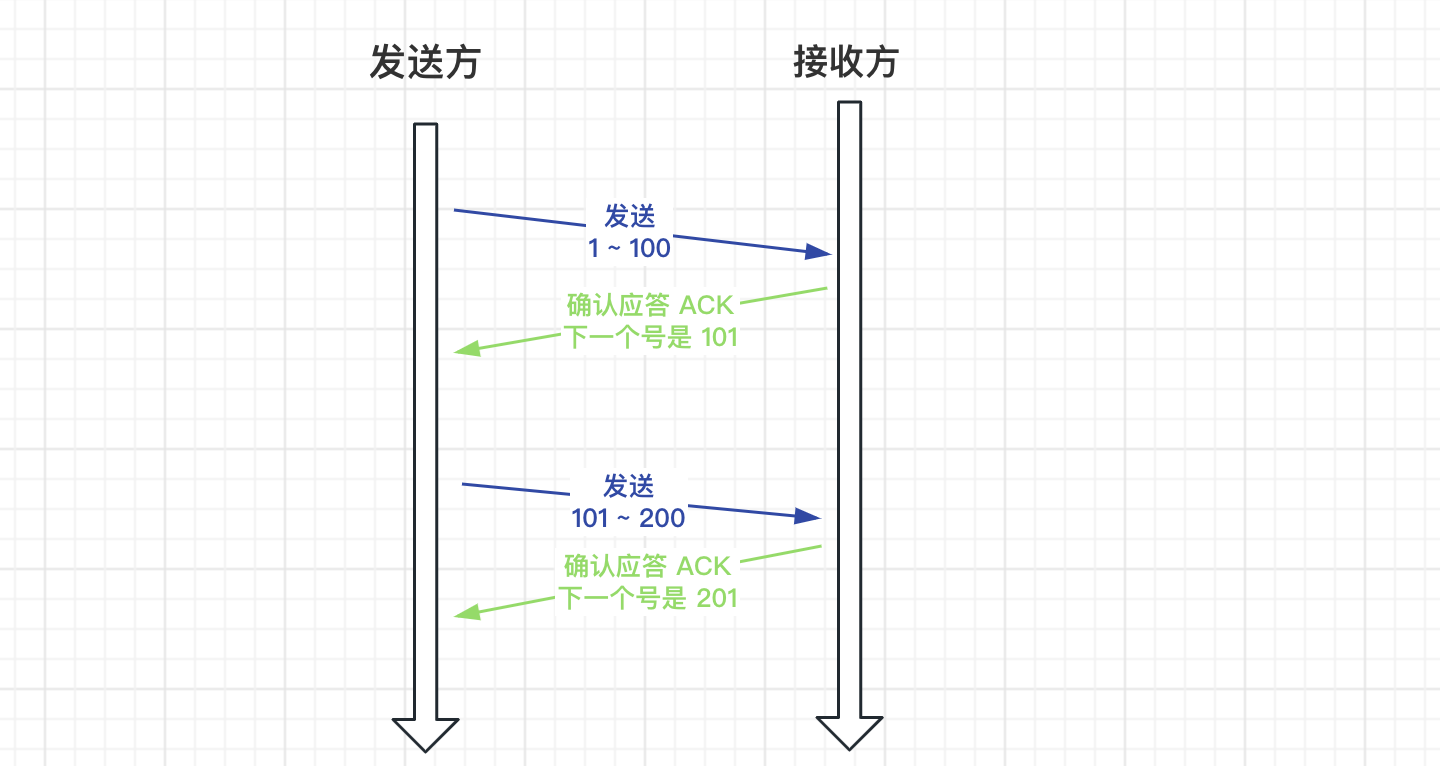
傳送確認
TCP 每次傳送資料,都有一個確認應答 ACK,表示已經收到了封包。確認號表示下一個傳送的起始號。
傳送一個 http 請求,使用 Wireshake 抓取封包,開啟 Statistics -> Flow Graph,在彈出的頁面上將 Flow type 修改成 TCP Flows,就能看到 TCP 的封包請求:

上圖中標記了三個地方,中間的的標記的傳送確認,就表示資料傳送和確認應答,len 表示位元組長度。傳送 1 ~ 218 的位元組,確認應答返回了確認號 219。第二個傳送確認也是類似原理,所不同的是,這個傳送確認時接收端的傳送確認。
重傳機制
傳送端的封包,一般都傳送到接收端。但是在網路不好,或者訊號比較差的情況,可能就無法正常傳送到資料。
先介紹兩個概念,RTT 和 RTO。
RTT Round-Trip Time 表示往返時間,表示網路一段到另一端所需要的時間,也就是封包的往返時間,以 TCP 握手為例:
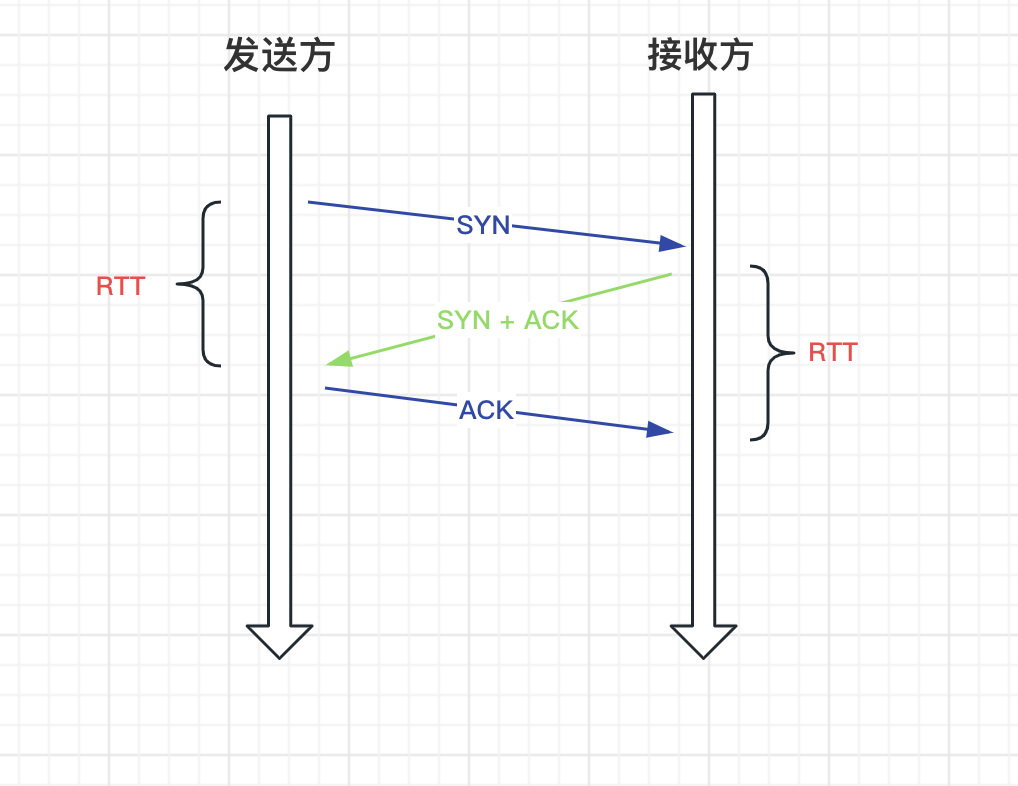
RTT 表示封包從傳送到收到確認應答的時間。
RTO Retransmission Timeout 表示超時重傳時間。超過這個時間沒有確認應答,就會重傳報文段,這個時間根據 RTT 來設定的。
重傳機制是 TCP 基本的錯誤恢復功能,常見的重傳機制有兩種:
- 超時重傳
- 快速重傳
1、超時重傳
超時重傳,字面意思是,超時規定的時間沒有收到確認訊息,就會再次傳送一個訊息請求。TCP 傳送方傳送報文時,會設定一個定時器,如果在時間範圍內沒有收到接收方發來的 ACK 確認報文,傳送方就會重傳已經傳送的報文段。
TCP 有兩種超時重傳的情況:
- 報文在傳送途中丟失
- 確認包在途中丟失
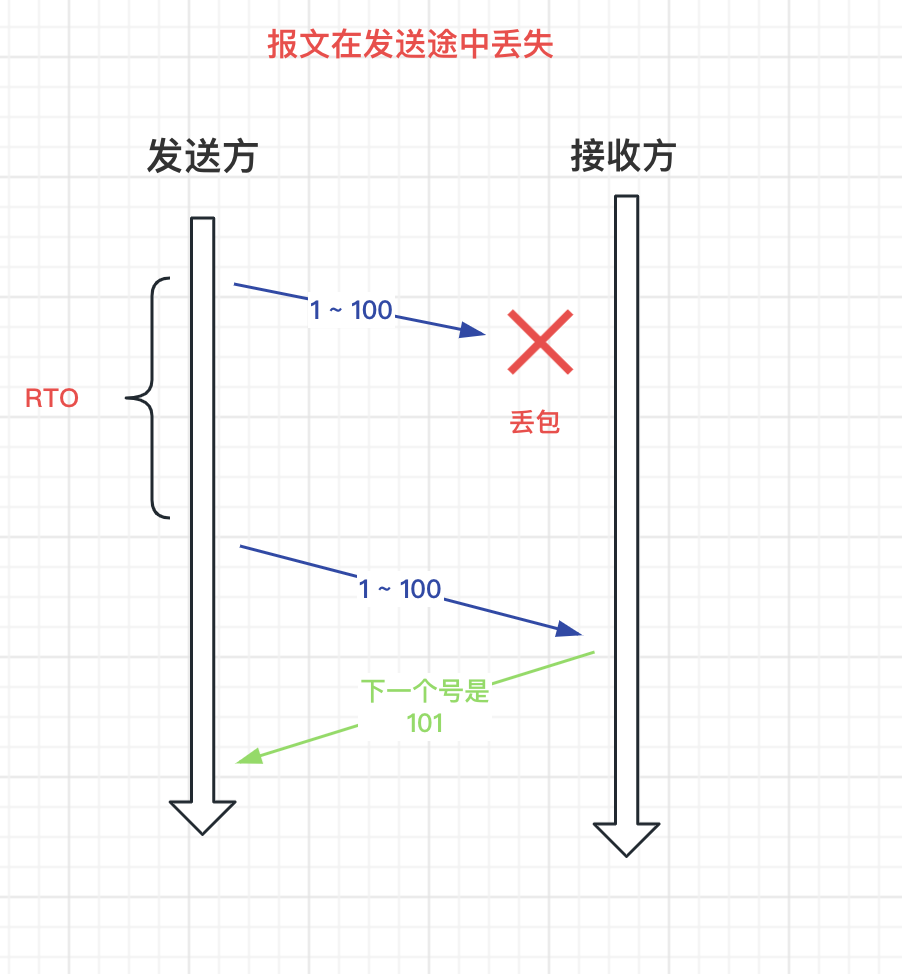
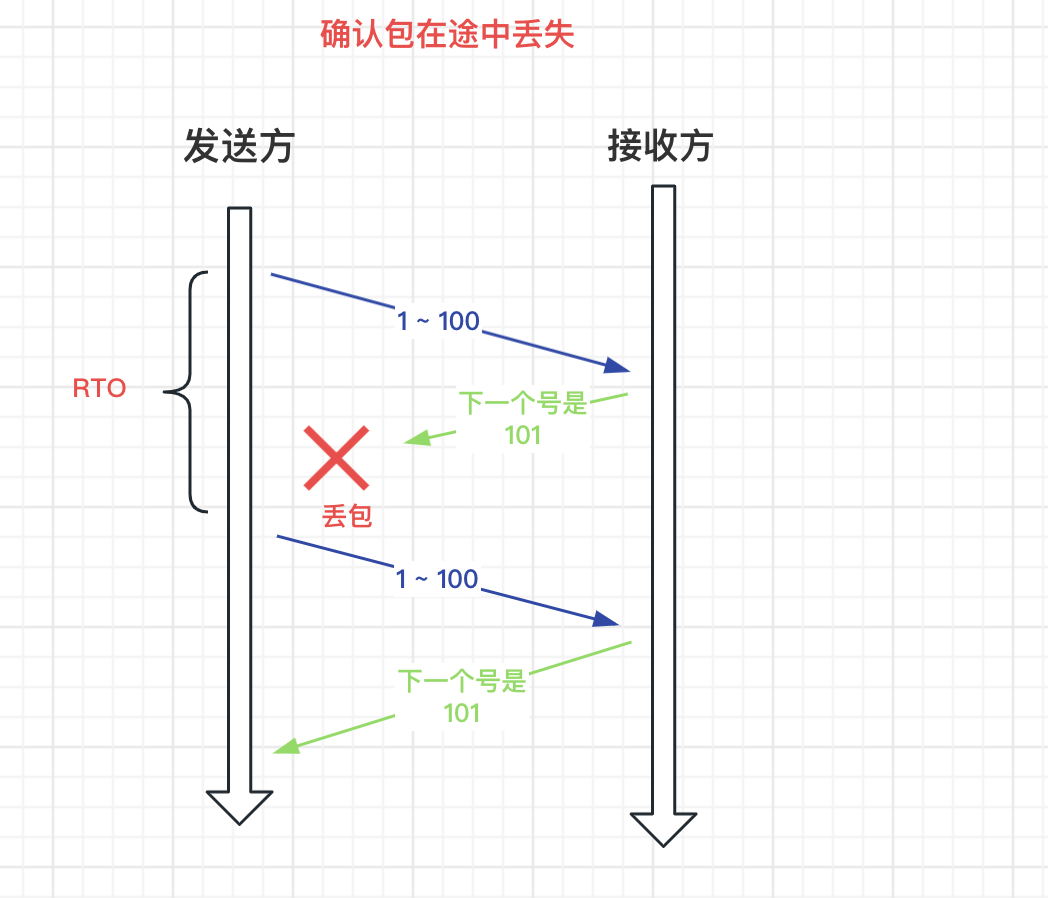
上面的 RTO 表示超時重傳時間,RTO 的設定不能過大的或者過小:
- 如果過大,請求等待的時間過長,請求的效率低。
- 如果過小,正常返回的確認還未來得及返回,就重傳。加大網路符合。
設定一個適當的 RTO 才會讓重傳機制更加高效。超時時間 RTT 應該略大於往返時間 RTT。
如果超時重傳的報文段又超時了該怎麼辦呢?,答案就是重傳的超時時間加倍,也就是再次超時重傳的超時時間會增加到之前的兩倍。
如果超時重傳的報文段又丟包呢?此時傳送方會以 RTO 時間的 2、4、8倍的倍數嘗試多次重傳。
超時重傳如果訊息多次沒有收到確認報文,超時的週期也比較長,有沒有更加高效的方法減少超時重傳的時間呢?就引出下面的要講的快速重傳。
快速重傳
快速重傳不會等待超時時間到了再重傳,傳送方收到 3 次重複確認報文端,就不會等超時時間重試,而是直接重傳報文。
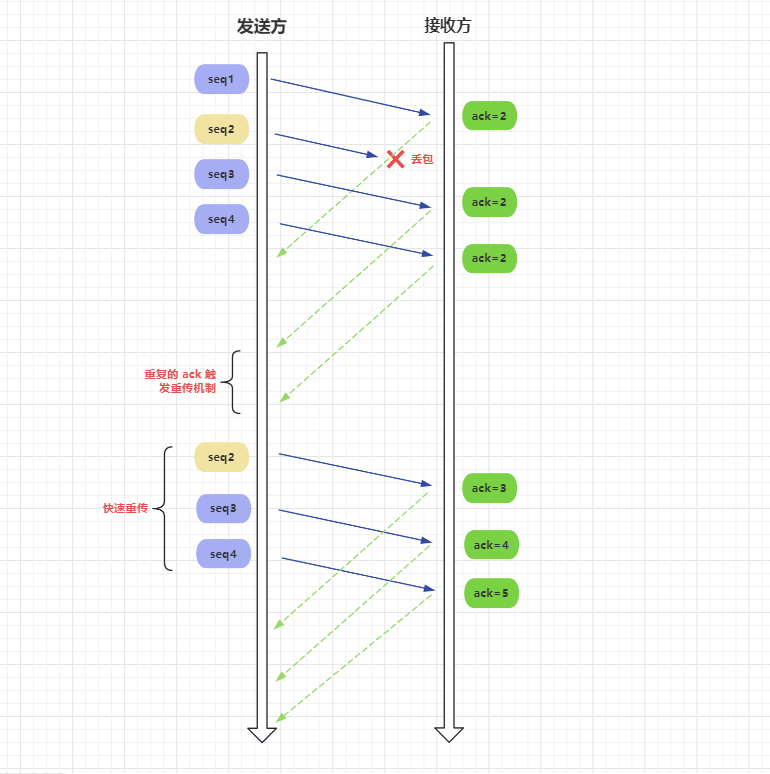
連續傳送的報文段,中間只要有一個丟失,後續返回的確認號都是相同,後面的報文段無論有沒有返回,都會重傳一遍,這種設定還是比較合理的。在一段時間內,如果網路狀況不好,導致丟包情況,後續的報文段一般也會丟包。
但是重傳丟包後面所有的包,也會造成網路傳輸的浪費。對於上面的例子,如果只想傳輸 seq2,其他有返回的確認包就不用重傳。
TCP 有一種重傳機制: SACK Selective Acknowledgment 選擇性重傳。
這種方式需要 TCP 報文段選項加一個 SACK 欄位,使用檢視 Wireshake SYN 包中 SACK Permitted:
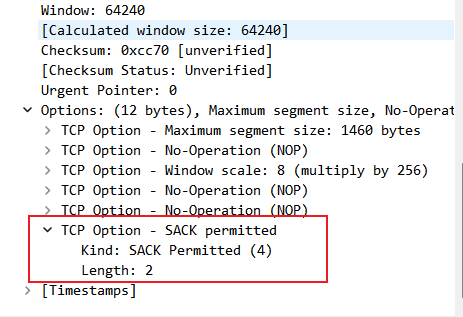
傳送包有返回確認應答,就會傳送給傳送方告知對應的資料被接收了,傳送方就能記錄哪些資料被接收了,哪些資料沒有被接收。後面只會重傳沒有被接收的封包,這就是選擇性重傳。
滑動視窗
TCP 傳送比較大的封包,TCP 會一次性傳送大的封包給接收方?答案是不會的,需要考慮網路頻寬,TCP 會將大的封包拆分成多個大小適中的封包,傳送一個 http 請求,新增較大的引數,使用 Wireshake 抓取封包:

封包被拆分成五個小的封包。
封包被拆分成多個小的封包之後,封包傳送都有返回一個確認序列號,每次傳送一個新的包,都等待上一個包的 ACK 回來之後才能傳送,這樣一來一回的效率是很低的:
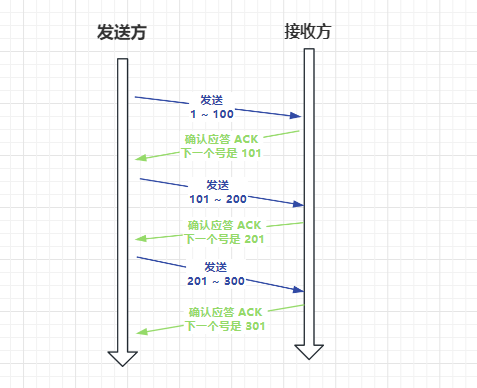
TCP 為了解決這個問題,引入視窗的概念,在視窗範圍內的封包,無需等待上一次 ACK 確認,可以直接傳送封包:
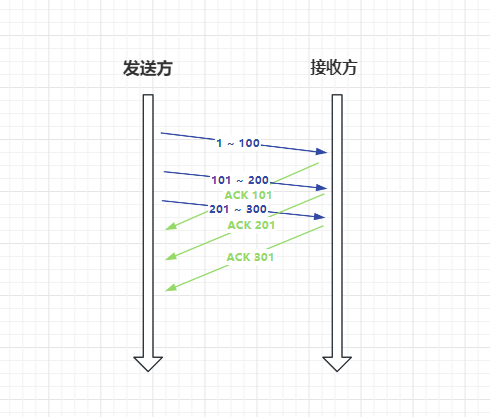
滑動視窗是 TCP 協定中的一種流量控制機制,用來控制傳送方和接收方資料傳輸的速率,避免資料過多造成資料無法及時處理。
視窗的大小也就是 TCP 報文段的 windos 欄位,表示的就是接收方目前能接收的緩衝區的剩餘大小,傳送端根據這個欄位處理傳送的資料。
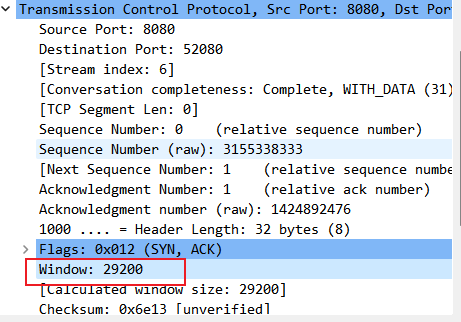
傳送端的視窗
傳送視窗根據三個標準來劃分:是否傳送、是否收到 ACK、是否在接收方處理範圍內,分成了四個部分:
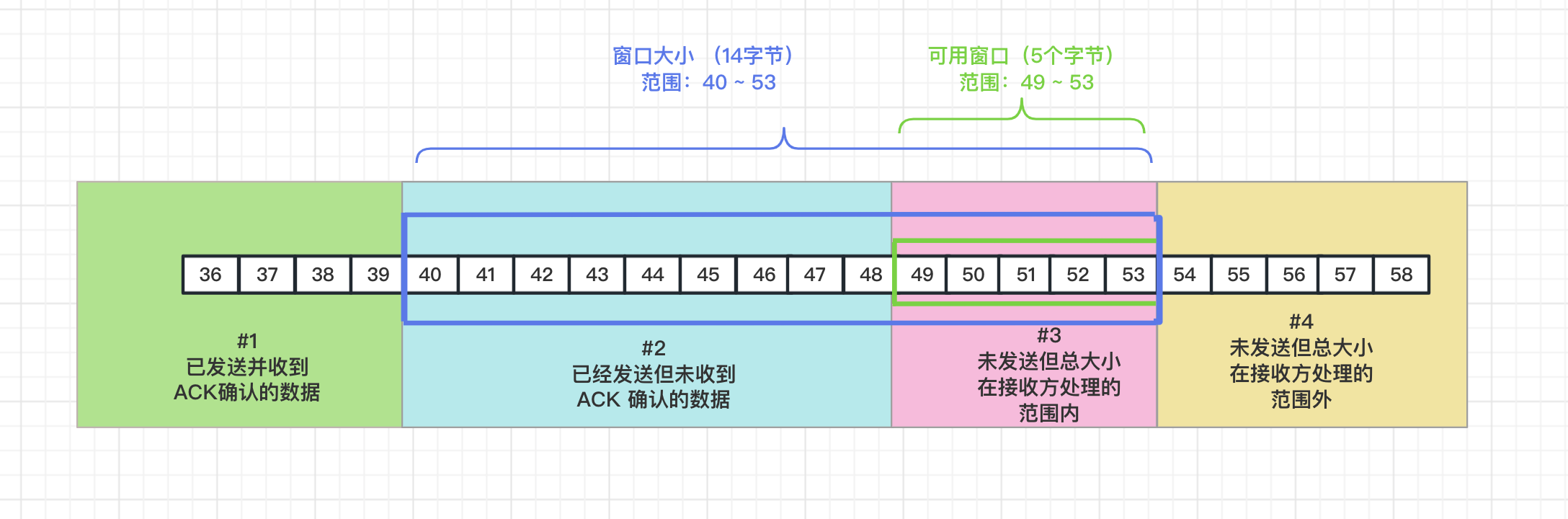
四個部分組成:
- 第一部分是已經傳送並收到 ACK 確認的資料,這部分資料已經傳送成功了,無需在快取中保留了。
- 第二部分資料是已經發生但是未收到 ACK 確認的資料。
- 第三部分資料是未傳送,但是在接收方處理範圍之內的資料。第二、第三部分共同組成傳送的視窗。
- 第四部分是需要傳送,但是未在接收方範圍之內的資料。這部分資料在沒有接收 ACK 確認之前,是不會傳送資料的。
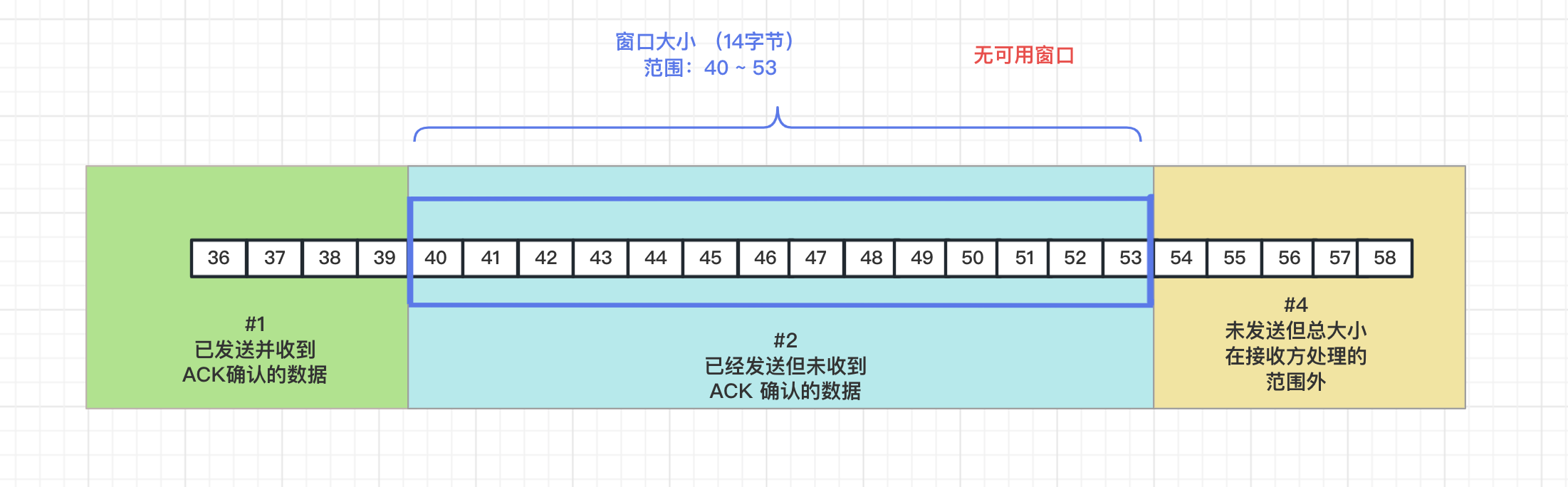
如果傳送方一直沒有收到 ACK,資料不斷的傳送,很快可用視窗也被耗盡,這時傳送方也不會繼續傳送資料了,這時傳送端可用視窗為零的情況我們成為「零視窗」。
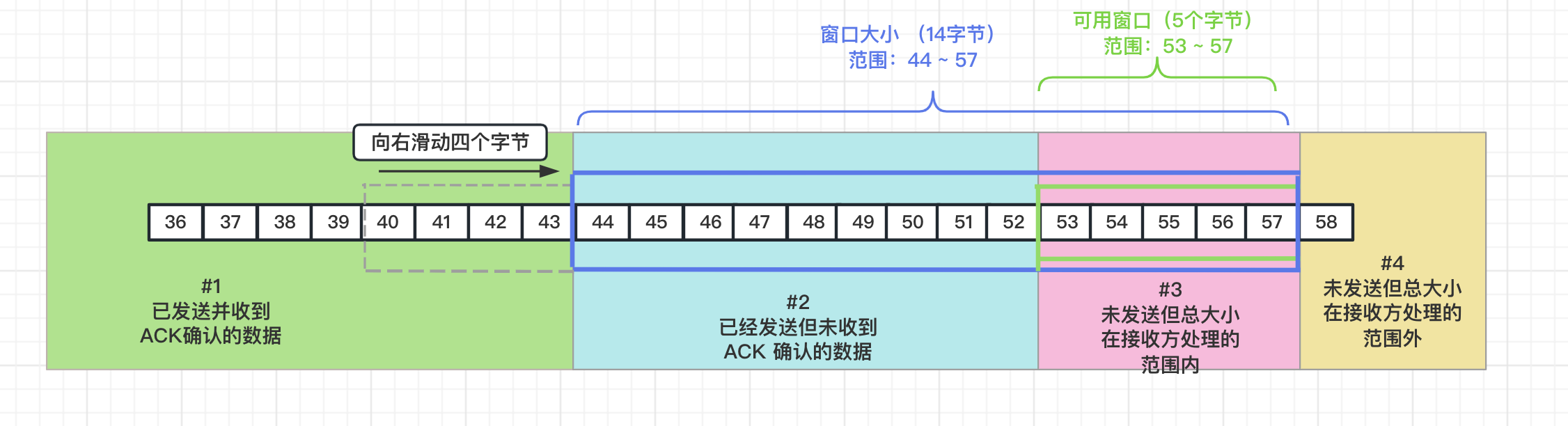
隨著 ACK 的確認,視窗也會依次向右滑動,比如傳送端的視窗中,比如 40 ~ 43 位元組都收到了 ACK 確認,那麼整個可用的視窗就會順次往右移動。此時 53 ~ 57的資料也都能傳送了。
接收端的視窗
接收端的滑動視窗相對傳送的視窗要簡單的多,主要分為三個部分:
- 已經接收並確認的資料
- 可以接收但是未接收的資料
- 在接收範圍之外(不夠快取的資料),也就是不可以接收的資料。
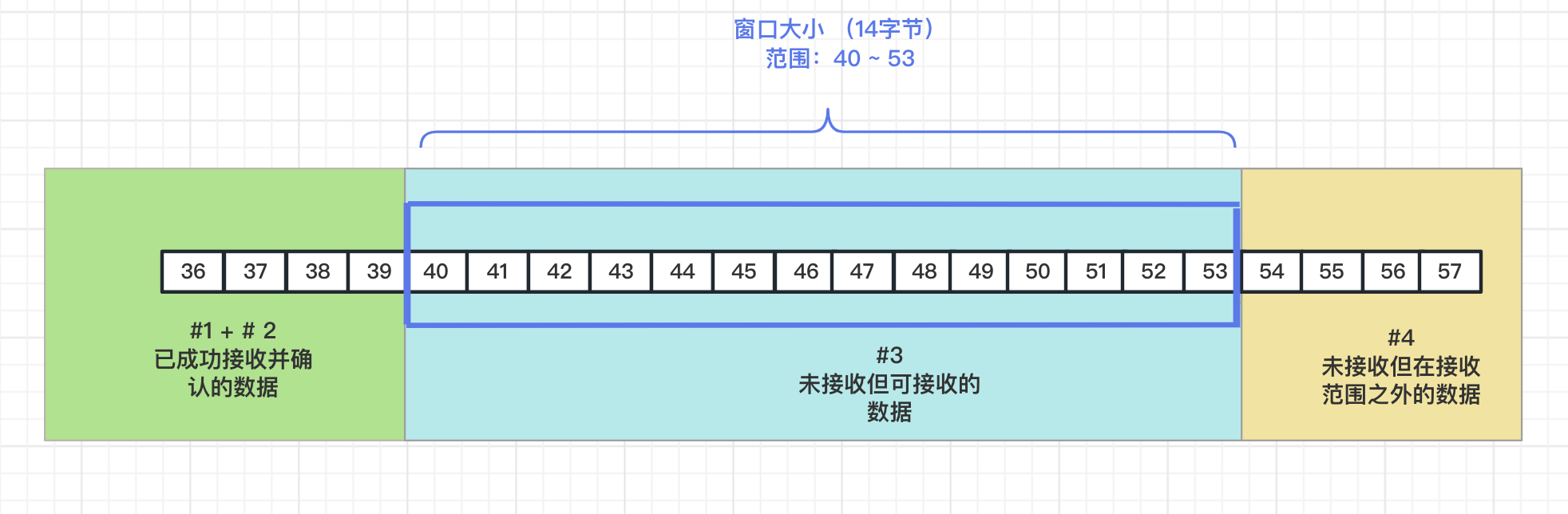
但資料接收後,視窗也向右邊滑動,給發生端的資料提供資料快取。如果讀取快取的資料速度有變化時,接收端可能也會改變接收視窗的大小,以此來控制傳送端的傳送速度。這就是滑動視窗進行流量控制的一種機制。
擁塞控制
網路中由於有大量的包傳輸,在固定頻寬下處理不過來封包的傳輸,可能會導致封包阻塞,網路傳輸的速度下降,甚至會下降到 0 的情況。這就有點類似排隊買東西,如果正常排隊,速度雖然不快但處理速度比較穩定。但是如果一下湧來很多人口,就會處理不過來,導致堵死情況。
而 TCP 被設定成一個無私的協定,當遇到網路擁塞時,TCP 會減少自己傳送封包,這樣網路擁塞會得到很大的緩解。
為了實現擁塞控制,首先在傳送端定義一個擁塞視窗 CWND (congestion window),限制傳送端傳送資料最多沒有收到 ACK 確認包的大小,超過擁塞視窗範圍後,就不會繼續傳送資料了。
擁塞視窗會隨著網路情況的變化動態的呼叫自身的大小,大體的變化規則是:如果沒有出現擁塞,就擴大視窗大小,否則就縮小視窗的大小。
擁塞控制演演算法主要包含四個部分:
- 慢啟動
- 擁塞避免
- 擁塞發生
- 快速恢復
慢啟動
當一個新的TCP連線開始時,無法確定是否用擁塞發生,一開始不會傳送大量的包,而是從最小的傳送視窗開始,後續會採用倍增的方式增加視窗的大小,視窗大小從 1 開始,後續慢慢增大到 2、4、8 等。
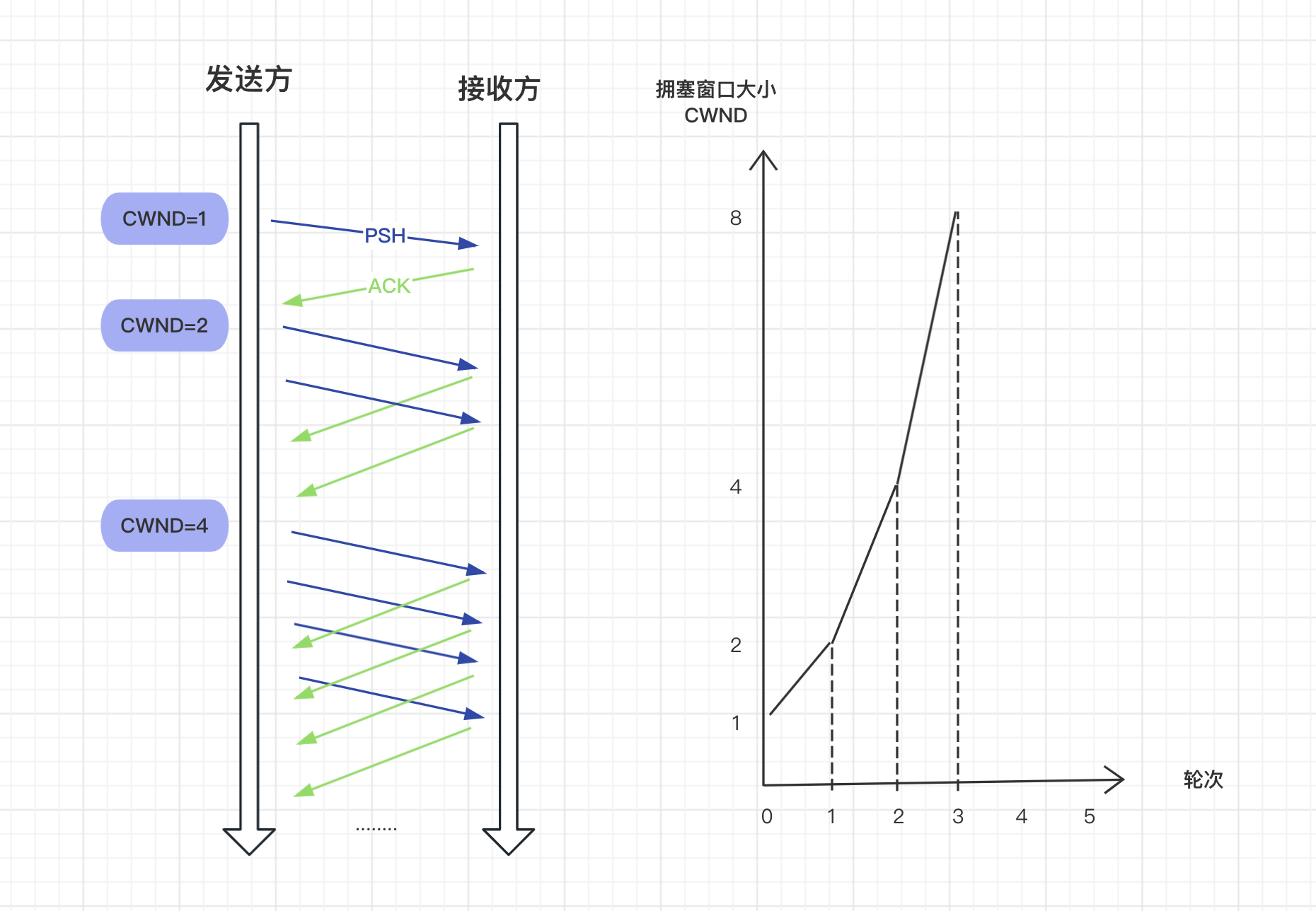
指數增加速度會越來越快,視窗擴大的一定的程度,就會減慢增加的速度,改成線性增加,這時候就進入擁塞避免階段。
擁塞避免
慢啟動和擁塞避免的臨界點叫做慢啟動門限 ssthresh (slow start threshold。
- cwnd < ssthresh 時,使用慢啟動演演算法。
- cwnd >= ssthresh 時,就會使用「擁塞避免演演算法」。
ssthresh 大小一般是 65535 位元組。擁塞避免的規則是:每當收到一個 ACK 時,cwnd 增加 1/cwnd。就變成線性增長了。
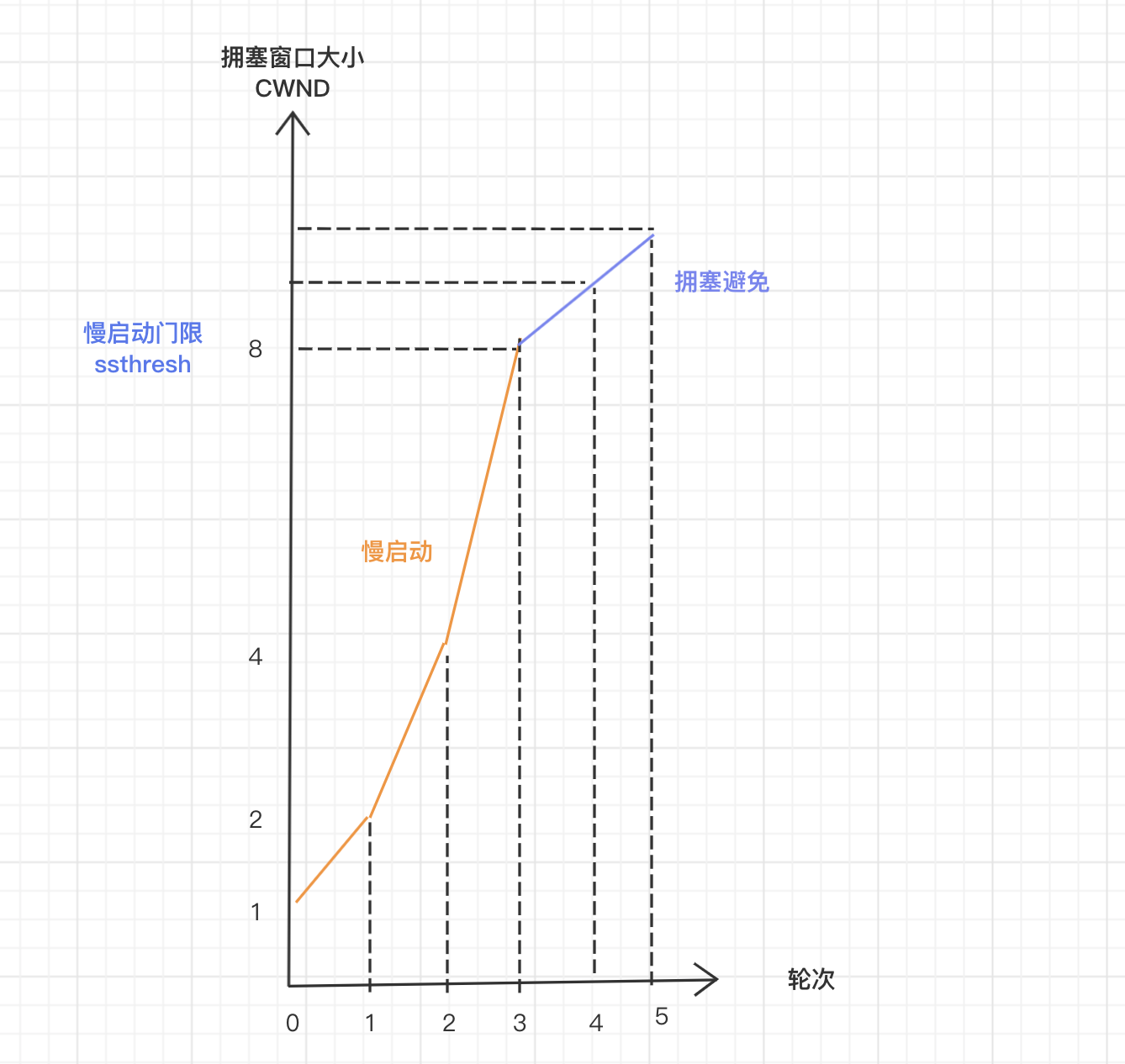
擁塞發生
擁塞避免將原來的指數增長改成了線性增長,雖然增長速度減慢,但 CWND 視窗還是在增長階段。隨著視窗進一步緩慢增加,網路還是會遇到阻塞的狀態,會出現丟包的情況。就需要對丟包進行重傳。
重傳機制有兩種:
- 超時重傳
- 快速重傳
當發生超時重傳時,sshresh 和 cwnd 的值會發生如下變化:
- sshresh 變成 cwnd 的一半
- cwnd 重置為 1
cwnd 重置為1,表示直接進入慢啟動狀態。
上面的超時重傳速度變化太快,而快速重傳是一個相對溫和的方案。如果我們連續 3 次收到同樣序號的 ACK,包還能回傳,說明這個時候可能只是碰到了部分丟包,網路阻塞還沒有很嚴重,無需重置 cwnd。
此時 ssthresh 和 cwnd 變化如下:
- cwnd = cwnd/2 ,也就是設定為原來的一半;
- ssthresh = cwnd
並進入到快速恢復階段。
快速恢復
快速恢復主要是將 cwnd 恢復到正常大小,上面說的 cwnd 設定成原來的一半,ssthresh 設定成 cwnd 的大小。
快速恢復演演算法如下:
- 重傳丟失的封包。
- 如果接收到重複 ACK 確認,cwnd 增加 1。
- 如果接收到新資料的 ACK 確認,就將 ssthresh 恢復到慢啟動時期的值,因為返回新資料的 ACK 確認,表示網路阻塞已經結束,可以恢復到之前的狀態,cwnd 也可以指數或者線性增加。
總結
TCP 提供基於位元組流、可靠的資料傳輸,為了確保資料的可靠性,做了很多工作:
- 報文段序號和確認號
- 每個報文都有序號和確認號,序號表示報文段第一個位元組號,確認號表示下一個接收位元組的序號。
- 傳送確認和重傳機制
- 每個報文段傳送後,都會確認應答 ACK,表示已經報文段已經成功傳送。
- 當網路異常封包無法達到時,就會觸發重傳機制。重傳主要有兩種方式:超時重傳和快速重傳。
- 超時重傳:設定一個定時器,超過時間未收到確認應答,就會重新傳數封包。這個重傳方式週期比較長。
- 快速重傳:快速重傳不會等待超時時間到了再重傳,是以資料為基點,傳送多次報文段,當接受到重複的確認應答號 ACK 時,直接重傳所有的報文段。可以使用 SACK 記錄哪些報文段已經成功接收了,只重傳沒有被成功接收的報文段。
- 滑動視窗
- 報文段拆分,TCP 將要傳送的資料拆分適當大小的封包。
- 引入視窗的概念,這個視窗大小是由接收方來決定,表示接收方可以接收的快取大小。在視窗範圍之內, TCP 可以連續傳送多個封包給接收方,當封包傳送並且有確認應答,整個視窗會往後移動,繼續傳送新的資料。
- 隨著資料傳輸的速度和網路情況,接受方可能會動態修改視窗的大小,以此來控制資料傳輸的速度。
- 滑動視窗能流量進行控制,控制資料傳送的速度和頻率,避免出現擁塞情況。
- 擁塞控制,在網路傳輸中可能會出現大量的資料請求,而固定的網路寬頻可能處理不過來這麼多資料傳輸,容易形成阻塞的情況。TCP 遇到網路擁塞時,會自動減少自己傳送包的數量,這樣網路擁塞情況就會緩解。TCP 傳送端定義擁塞視窗 CWND,表示沒有接收到 ACK 確認資料的最大傳送量。擁塞控制演演算法主要包含四個部分:
- 慢啟動:開始一個新的連線時,從較小的傳送視窗開始,然後指數增長增加 CWND 視窗大小,知道達到慢啟動門限。
- 擁塞避免:視窗達到慢啟動門限臨界點時候,慢啟動階段結束,這個階段,視窗大小線性增加,增長速度比較慢,避免發生網路擁塞。
- 擁塞發生:視窗進一步緩慢增加,網路還是會遇到阻塞的狀態,會出現丟包的情況。就需要對丟包進行重傳。此時有兩種重傳機制:超時重傳和快速重傳。超時重傳,是視窗大小重置為 1,資料傳輸又恢復成慢啟動時的速度。這種傳輸速度急劇下降,不利於系統穩定,由於視窗大小限制,網路傳輸次數更多,擁塞的情況也會更大。而快速重傳是相對溫和的方案,此時認為網路只是暫時有阻塞情況,將視窗大小 CWND 改成原來的一半,並進入快速恢復階段。
- 快速恢復:重傳丟失的封包,如果接收到重複 ACK 確認,cwnd 增加 1。如果接收到新資料的 ACK 確認,就將 ssthresh 恢復到慢啟動時期的值,因為返回新資料的 ACK 確認,表示網路阻塞已經結束,cwnd 也可以指數或者線性增加。