[語音識別] 基於Python構建簡易的音訊錄製與語音識別應用
語音識別技術的快速發展為實現更多智慧化應用提供了無限可能。本文旨在介紹一個基於Python實現的簡易音訊錄製與語音識別應用。文章簡要介紹相關技術的應用,重點放在音訊錄製方面,而語音識別則關注於呼叫相關的語音識別庫。本文將首先概述一些音訊基礎概念,然後詳細講解如何利用PyAudio庫和SpeechRecognition庫實現音訊錄製功能。最後,構建一個簡單的語音識別範例應用,該應用程式可以實時監聽音訊的開始和結束,並將錄製的音訊資料傳輸至Whisper語音識別庫進行語音識別,最終將識別結果輸出到基於PyQt5搭建的簡易頁面中。
本文所有程式碼見:Python-Study-Notes
0 音訊基礎概念
隨著深度學習技術的迅猛發展,端到端語音識別已廣泛應用。然而,音訊相關的最基礎概念如取樣頻率、取樣位數,我們仍需有一定了解。聲音是由物體振動引起的機械波,而音訊是聲音的電子表示。PCM (Pulse Code Modulation)編碼將一種常見將模擬音訊訊號轉換為數位形式的方法。在此過程,音訊取樣是指在一段時間內通過固定間隔採集聲音的振幅值以將連續的聲音模擬訊號轉換為離散的數位資料。取樣頻率表示每秒鐘採集的樣本數,而取樣位數則表示每個樣本的量化級別即聲音的精細度和動態範圍。關於音訊詳細概念介紹見:數位音訊基礎從PCM說起。
取樣頻率
音訊訊號通常是連續的模擬波形,為了儲存它們,需要將其離散化。這通過取樣來實現,即在固定時間間隔內測量聲音訊號的幅度。取樣的過程就是抽取模擬訊號各點的頻率值。取樣率越高即1秒內抽取的資料點越多,音訊音質就越好,但同時也增加了儲存和處理成本。奈奎斯特-夏農(Nyquist–Shannon)取樣定理強調取樣頻率必須高於訊號最大頻率的兩倍,以確保從取樣值中完全恢復原始模擬訊號。在音訊訊號取樣領域,常使用兩個主要的取樣頻率:16kHz和44.1kHz。
舉例來說,16kHz表示每秒取樣16000次,而人類言語聲音訊率範圍在200Hz到8kHz,16kHz的取樣頻率已足夠捕捉人類語音訊率特徵,同時減輕了音訊資料儲存和處理的負擔。因此常用語音取樣頻率為16kHz。人耳可感知20Hz到20kHz的聲音,為了呈現高質量音訊,通常選擇44.1kHz取樣頻率以覆蓋人耳可聽聲音的上限。
取樣位數和聲道
取樣後的訊號是連續的模擬值,為了將其轉換為數位形式,需要對訊號進行量化。量化是將連續的模擬值對映到離散的數位值,通常使用固定取樣位數(例如16位元或24位元)來表示樣本的幅度範圍。例如,使用16位元(16bit),也就是雙位元組的二進位制訊號表示音訊取樣,而16位元的取值範圍為-32768到32767,共有65536個可能的取值。因此,最終模擬的音訊訊號在幅度上被分成了65536個數值等級。較高的取樣位數能夠表示更大的聲音幅度範圍,並保留更多的細節資訊。常用的位深度包括8位元、16位元和24位元,其中8位元是最低要求,16位元可以滿足一般應用的需求,而24位元則適用於專業音訊工作。
聲道是指音訊訊號在播放系統或錄音系統中的傳輸通道。一個聲道通常對應於一個單獨的音訊訊號源或訊號流,並負責傳輸該訊號到揚聲器或錄音裝置。在立體聲系統中,通常有兩個聲道,分別是左聲道和右聲道,用來分別處理來自音訊源的左右聲音訊號,以實現空間立體聲效果。聲道的概念也可延伸到多聲道系統,如5.1聲道、7.1聲道等,它們可以支援更多的音訊源和更豐富的音效體驗,比如環繞音效。
常用音訊編碼格式
PCM編碼所獲得的音訊資料是最為原始的,為了進行儲存和網路傳輸需要對其進行二次編碼。這些二次音訊編碼格式都是在PCM編碼基礎上再次編碼和壓縮的,按照壓縮方式又分為無失真壓縮和有失真壓縮。無失真壓縮是指相對於PCM編碼完整地保留音訊資料的音質。然而,無失真壓縮的音訊檔通常比有失真壓縮的音訊檔稍大。有失真壓縮在編碼過程中,為了減小檔案大小,犧牲了部分音訊資料的資訊和音質。
無失真壓縮常見的音訊編碼格式有:WAV/WAEV(Waveform Audio File Format),FLAC(Free Lossless Audio Codec),AIFF(Audio Interchange File Format)等。有失真壓縮常見的音訊編碼格式有:MP3(MPEG Audio Layer III),AAC(Advanced Audio Coding),WMA(Windows Media Audio)等。
在獲得編碼後的音訊資料後,需要使用合適的檔案格式來儲存編碼資料。一種音訊編碼可能對應一種檔案格式,也可能對應多種檔案格式,一般情況下是一種。例如WAV編碼資料對應於.wav檔案格式,MP3編碼資料對應於.mp3檔案格式。PCM編碼資料對應於.raw或者.pcm檔案格式,AAC編碼資料對應於.acc或者.mp4檔案格式等。
音訊與視訊概念對比
| 概念 | 音訊 | 視訊 |
|---|---|---|
| 維度 | 通過聲波傳遞的聲音資訊,是一維的 | 通過影象序列傳遞的運動影象資訊,是二維的 |
| 核心特徵 | 包括音調、音量、節奏等,由頻率和振幅表現 | 包括畫面內容、顏色等,由畫素和色彩表現 |
| 訊號頻率 | 以取樣率表示,人類對聲音的感知更為敏銳,因而音訊取樣率遠遠大於視訊影格率 | 以影格率表示,視訊是通過多張靜止影象以一定的速度播放來模擬流暢的動畫 |
| 取樣精度 | 用於表示聲音的幅度值,常見16bit | 用於表示影象的顏色和亮度值,常見為8bit(256色) |
| 處理技術 | 均衡、壓縮、降噪等 | 剪輯、特效、編解碼等 |
| 通道 | 以聲道表示,如單聲道和雙聲道 | 以顏色通道表示,如GRAY、RGB、RGBA |
| 儲存 | 便於傳輸和儲存,佔用的空間較小 | 需要更大的儲存空間和頻寬來傳輸和儲存 |
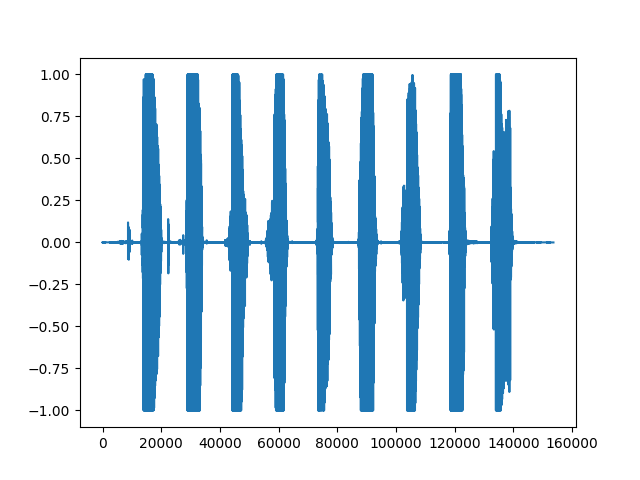
下面的程式碼展示了讀取音訊內容為123456789的wav檔案並繪製出音訊資料的波形圖。
# 匯入用於繪圖的matplotlib庫
from matplotlib import pyplot as plt
# 匯入用於讀取音訊檔的soundfile庫
# pip install soundfile
import soundfile as sf
# 從demo.wav檔案中讀取音訊資料和取樣率,data為numpy陣列
data, samplerate = sf.read('asr_example_hotword.wav', dtype='float32')
# 儲存音訊
sf.write("output.wav", data=data, samplerate=samplerate)
# 列印音訊資料的形狀和列印取樣率
# data為一個numpy陣列,samplerate為一個整數
print('data shape: {}'.format(data.shape))
print('sample rate: {}'.format(samplerate))
# 繪製音訊波形
plt.figure()
plt.plot(data)
plt.show()
程式碼執行結果如下,其中表示音訊資料的樣本點索引,即音訊的時間軸。每個樣本點都對應音訊資料的每一幀,從左到右依次遞增。縱軸表示音訊訊號在每個時間點的歸一化後的音訊強度。所讀取的資料以float32表示格式,數值取樣值範圍為-32678~32678,soundfile庫會除以32678(2^16/2),以歸一化到[-1, 1]區間內。
1 PyAudio
1.1 PyAudio介紹與安裝
PyAudio是一個用於處理音訊輸入和輸出的Python庫,其主要變數和介面的實現依賴於C語言版本的PortAudio。PyAudio提供從麥克風或其他輸入裝置錄製音訊、儲存音訊檔、實時處理音訊資料以及播放音訊檔或實時音訊流等功能。此外,PyAudio也允許通過設定取樣率、位深度、聲道數等引數以及支援回撥函數和事件驅動機制來滿足不同應用需求。PyAudio官方網站見:PyAudio。PyAudio的安裝需要Python3.7及以上環境。
Windows下PyAudio安裝命令如下:
python -m pip install pyaudio
Linux下PyAudio按照命令如下:
sudo apt-get install python3-pyaudio
python -m pip install pyaudio
本文所用PyAudio版本為0.2.13。
1.2 音訊錄製與播放
1.2.1 音訊播放
以下程式碼展示了基於PyAudio播放本地音訊檔。
# wave為python處理音訊標準庫
import wave
import pyaudio
# 定義每次從音訊檔中讀取的音訊取樣資料點的數量
CHUNK = 1024
filepath = "demo.wav"
# 以音訊二進位制流形式開啟音訊檔
with wave.open(filepath, 'rb') as wf:
# 範例化PyAudio並初始化PortAudio系統資源
p = pyaudio.PyAudio()
# 開啟音訊流
# format: 指定音訊流的取樣格式。其中wf.getsampwidth()用於獲取音訊檔的取樣位數(sample width)。
# 取樣位數指的是每個取樣點佔用的位元組數。通常情況下,取樣位數可以是1位元組(8位元)、2位元組(16位元)等。
# channels:指定音訊流的聲道數。聲道數可以是單聲道(1)或立體聲(2)
# rate:指定音訊流的取樣率。取樣率表示每秒鐘音訊取樣的次數,常見的取樣率有44100Hz或16000Hz
# output:是否播放音訊
stream = p.open(format=p.get_format_from_width(wf.getsampwidth()),
channels=wf.getnchannels(),
rate=wf.getframerate(),
output=True)
# 從音訊檔播放樣本資料
while True:
# data為二進位制資料
data = wf.readframes(CHUNK)
# len(data)表示讀取資料的長度
# 在此len(data)應該等於取樣點佔用的位元組數wf.getsampwidth()乘以CHUNK
if len(data):
stream.write(data)
else:
break
# 或者使用python3.8引入的海象運運算元
# while len(data := wf.readframes(CHUNK)):
# stream.write(data)
# 關閉音訊流
stream.close()
# 釋放PortAudio系統資源
p.terminate()
1.2.2 音訊錄製
以下程式碼展示了基於PyAudio呼叫麥克風錄音,並將錄音結果儲存為本地檔案。
import wave
import pyaudio
# 設定音訊流的資料塊大小
CHUNK = 1024
# 設定音訊流的格式為16位元整型,也就是2位元組
FORMAT = pyaudio.paInt16
# 設定音訊流的通道數為1
CHANNELS = 1
# 設定音訊流的取樣率為16KHz
RATE = 16000
# 設定錄製時長為5秒
RECORD_SECONDS = 5
outfilepath = 'output.wav'
with wave.open(outfilepath, 'wb') as wf:
p = pyaudio.PyAudio()
# 設定wave檔案的通道數
wf.setnchannels(CHANNELS)
# 設定wave檔案的取樣位數
wf.setsampwidth(p.get_sample_size(FORMAT))
# 設定wave檔案的取樣率
wf.setframerate(RATE)
# 開啟音訊流,input表示錄音
stream = p.open(format=FORMAT, channels=CHANNELS, rate=RATE, input=True)
print('Recording...')
# 迴圈寫入音訊資料
for _ in range(0, RATE // CHUNK * RECORD_SECONDS):
wf.writeframes(stream.read(CHUNK))
print('Done')
stream.close()
p.terminate()
1.2.3 全雙工音訊錄製與播放
全雙工系統(full-duplex)可以同時進行雙向資料傳輸,而半雙工系統(half-duplex)只能在同一時間內進行單向資料傳輸。在半雙工系統中,一臺裝置傳輸資料時,另一臺裝置必須等待傳輸完成後才能進行資料處理。以下程式碼展示了全雙工(full-duplex)音訊錄製與播放,即同時進行音訊錄製和播放,而不需要等待一個操作完成後再進行另一個操作。
import pyaudio
RECORD_SECONDS = 5
CHUNK = 1024
RATE = 16000
p = pyaudio.PyAudio()
# frames_per_buffer設定音訊每個緩衝區的大小
stream = p.open(format=p.get_format_from_width(2),
channels=1,
rate=RATE,
input=True,
output=True,
frames_per_buffer=CHUNK)
print('recording')
for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)):
# read讀取音訊然後writer播放音訊
stream.write(stream.read(CHUNK))
print('done')
stream.close()
p.terminate()
1.3 回撥函數的使用
在前面的程式碼中,PyAudio執行音訊播放或錄製是以阻塞主執行緒的方式進行的,這意味著程式碼無法同時處理其他任務。為了解決這一問題,PyAudio提供了回撥函數,使得程式在進行音訊輸入和輸出時,能夠以非阻塞的方式進行操作,即處理音訊流的同時處理其他任務。PyAudio回撥函數是在單獨的執行緒中執行的,當音訊流資料可用時,回撥函數會被自動呼叫並以立即對音訊資料進行處理。PyAudio回撥函數具有固定的引數介面,函數介紹如下:
def callback(in_data, # 錄製的音訊資料的位元組流,如果沒有錄音則為None
frame_count, # 每個緩衝區中的幀數,本次讀取的資料量
time_info, # 有關音訊流時間資訊的字典
status_flags) # 音訊流狀態的標誌位
以下程式碼展示了以回撥函數的形式播放音訊。
import wave
import time
import pyaudio
filepath = "demo.wav"
with wave.open(filepath, 'rb') as wf:
# 當音訊流資料可用時,回撥函數會被自動呼叫
def callback(in_data, frame_count, time_info, status):
# 讀取了指定數量的音訊幀資料
data = wf.readframes(frame_count)
# pyaudio.paContinue為常數,表示繼續進行音訊流的處理
# 根據需要更改為pyaudio.paAbort或pyaudio.paComplete等常數來控制處理流程的中斷和結束
return (data, pyaudio.paContinue)
p = pyaudio.PyAudio()
# stream_callback設定回撥函數
stream = p.open(format=p.get_format_from_width(wf.getsampwidth()),
channels=wf.getnchannels(),
rate=wf.getframerate(),
output=True,
stream_callback=callback)
# 判斷音訊流是否處於活動狀態
while stream.is_active():
time.sleep(0.1)
stream.close()
p.terminate()
以下程式碼展示瞭如何運用回撥函數實現音訊錄製與播放的全雙工模式。在超時情況下,通過呼叫stream.close()來關閉音訊流並釋放相關資源。一旦音訊流被關閉,將無法再傳輸音訊資料。若想實現錄音過程中暫停一段時間後再繼續錄音,可使用stream.stop_stream()來暫停音訊流的資料傳輸,即暫時停止音訊的讀取和寫入,但仍保持流物件處於開啟狀態。隨後,可通過呼叫stream.start_stream()來重新啟動音訊流的資料傳輸。
import time
import pyaudio
# 錄音時長
DURATION = 5
def callback(in_data, frame_count, time_info, status):
# in_data為麥克風輸入的音訊流
return (in_data, pyaudio.paContinue)
p = pyaudio.PyAudio()
stream = p.open(format=p.get_format_from_width(2),
channels=1,
rate=16000,
input=True,
output=True,
stream_callback=callback)
start = time.time()
# 當音訊流處於活動狀態且錄音時間未達到設定時長時
while stream.is_active() and (time.time() - start) < DURATION:
time.sleep(0.1)
# 超過時長關閉音訊流
stream.close()
p.terminate()
1.4 裝置管理
PyAudio提供了host Api和device Api來獲取音訊裝置,但host Api和device Api代表了不同的層級和功能。具體如下:
- host Api:是對底層音訊系統的抽象,表示系統上可用的音訊介面,提供了與底層音訊裝置互動的功能。每個host Api都有自己的特點和支援的功能集,如使用的資料格式、取樣率等。常見的host Api包括ALSA、PulseAudio、CoreAudio等。
- device Api:是指具體的音訊輸入或輸出裝置,如麥克風、揚聲器或耳機等。每個音訊裝置都屬於一個特定的音訊host Api,並具有不同的引數設定,例如取樣率、緩衝區大小等。
本文主要對更為常用的device Api進行介紹,PyAudio中關於device Api的函數有如下:
-
get_device_info_by_index(index):
通過整數型索引獲取指定裝置的詳細資訊。該函數返回一個包含裝置資訊的字典,包括裝置名稱、輸入/輸出通道數、支援的取樣率範圍等。 -
get_default_input_device_info():
獲取預設輸入裝置的詳細資訊。該函數返回一個包含裝置資訊的字典。 -
get_default_output_device_info():
獲取預設輸出裝置的詳細資訊。該函數返回一個包含裝置資訊的字典。 -
get_device_count():
獲取計算機上可用音訊裝置的數量,這些裝置可以是麥克風、揚聲器、音訊介面等。
其中預設裝置為當前作業系統的音訊預設裝置,可以通過作業系統音訊控制頁面更改預設音訊輸入輸出裝置。下面程式碼展示了這些函數的使用:
import pyaudio
# 獲取指定裝置的詳細資訊
def get_device_info_by_index(index):
p = pyaudio.PyAudio()
device_info = p.get_device_info_by_index(index)
p.terminate()
return device_info
# 獲取預設輸入裝置的詳細資訊
def get_default_input_device_info():
p = pyaudio.PyAudio()
default_input_info = p.get_default_input_device_info()
p.terminate()
return default_input_info
# 獲取預設輸出裝置的詳細資訊
def get_default_output_device_info():
p = pyaudio.PyAudio()
default_output_info = p.get_default_output_device_info()
p.terminate()
return default_output_info
# 獲取計算機上可用音訊裝置的數量
def get_device_count():
p = pyaudio.PyAudio()
device_count = p.get_device_count()
p.terminate()
return device_count
# 範例用法
index = 0
print("可用音訊裝置數量:", get_device_count())
print("裝置{}的資訊:{}".format(index, get_device_info_by_index(index)))
print("預設錄音裝置的資訊:", get_default_input_device_info())
print("預設播放裝置的資訊:", get_default_output_device_info())
對於以上程式碼,如返回的預設播放裝置資訊字典如下:
預設播放裝置的資訊:
{'index': 3,
'structVersion': 2,
'name': '揚聲器 (Realtek High Definition Au',
'hostApi': 0,
'maxInputChannels': 0,
'maxOutputChannels': 2,
'defaultLowInputLatency': 0.09,
'defaultLowOutputLatency': 0.09,
'defaultHighInputLatency': 0.18,
'defaultHighOutputLatency': 0.18,
'defaultSampleRate': 44100.0}
該裝置也是系統當前預設的音訊裝置,其中各個引數的含義如下:
'index': 3:裝置的索引號,用於在裝置列表中唯一標識該裝置。'structVersion': 2:裝置資訊結構的版本號,用於指示該裝置資訊的資料結構版本。'name': '揚聲器 (Realtek High Definition Au':裝置的名稱,表示該裝置是一個 Realtek High Definition 型號的揚聲器。'hostApi': 0:裝置音效卡驅動模式,來自於PortAudio,如果想詳細瞭解見:pyaudio音效卡資訊中hostApi。'maxInputChannels': 0:裝置支援的最大輸入通道數,這裡為0表示該裝置沒有輸入功能,不支援錄音。'maxOutputChannels': 2:裝置支援的最大輸出通道數,這裡為2表示該裝置支援2個輸出通道,即可以播放立體聲音訊。'defaultLowInputLatency': 0.09:預設低輸入延遲,以秒為單位,表示從音訊輸入訊號進入裝置所需的最小時間。'defaultLowOutputLatency': 0.09:預設低輸出延遲,以秒為單位,表示從裝置輸出訊號到達音訊輸出所需的最小時間。'defaultHighInputLatency': 0.18:預設高輸入延遲,以秒為單位,表示從音訊輸入訊號進入裝置所需的最大時間。'defaultHighOutputLatency': 0.18:預設高輸出延遲,以秒為單位,表示從裝置輸出訊號到達音訊輸出所需的最大時間。'defaultSampleRate': 44100.0:預設取樣率,表示裝置支援的預設音訊取樣率為44100赫茲(Hz)。這是音訊裝置在單位時間內取樣的樣本數,影響聲音的質量和頻率範圍。
如果想指定裝置進行音訊錄製或錄製,則在open函數中指定裝置的索引,程式碼如下:
import pyaudio
p = pyaudio.PyAudio()
# 獲取可用的裝置數量
device_count = p.get_device_count()
# 遍歷裝置,列印裝置資訊和索引
for i in range(device_count):
device_info = p.get_device_info_by_index(i)
print(f"Device {i}: {device_info['name']}")
# 選擇所需的錄音裝置的索引
input_device_index = 1
# 選擇所需的播放裝置的索引
output_device_index = 2
# 開啟音訊流,並指定裝置
stream = p.open(format=p.get_format_from_width(2),
channels=1,
rate=16000,
input=True,
output=True,
input_device_index = input_device_index,
output_device_index = output_device_index)
# 操作輸出裝置和錄音裝置
# ...
2 SpeechRecognition
2.1 SpeechRecognition介紹與安裝
SpeechRecognition是一個用於語音識別的Python庫,支援多個語音識別引擎以將音訊轉換為文字。SpeechRecognition開源倉庫地址為:speech_recognition。基於PyAudio庫,SpeechRecognition封裝了更加方面和全面的音訊錄製函數。本文主要介紹利用SpeechRecognition錄製音訊。使用SpeechRecognition進行音訊錄製,需要Python3.8及以上環境,以及最低PyAudio 0.2.11版本。在安裝PyAudio後,SpeechRecognition安裝命令如下:
pip install SpeechRecognition
SpeechRecognition主要的類有:
AudioData
AudioData類是用於表示語音資料,主要引數和函數如下:
引數
frame_data:音訊位元組流資料sample_rate:音訊取樣率sample_width: 音訊的取樣位數
函數
get_segment:返回指定時間段內的音訊資料的AudioData物件get_raw_data:返回音訊資料的原始位元組流get_wav_data:返回音訊資料的wav格式位元組流get_aiff_data:返回音訊資料的aiff格式位元組流get_flac_data:返回音訊資料的flac格式位元組流
Microphone
Microphone類是封裝PyAudio,用於驅動麥克風裝置功能的類,因此構造引數與PyAudio主要引數和函數如下:
引數
device_index:麥克風裝置的索引號,不指定將採用PyAudio的預設音訊輸入設定format:取樣格式為16位元整數,不指定將採用PyAudio的預設音訊輸入設定SAMPLE_WIDTH:音訊的取樣位數 ,不指定將採用PyAudio的預設音訊輸入設定SAMPLE_RATE:取樣率,不指定將採用PyAudio的預設音訊輸入設定CHUNK:每個緩衝區中儲存的幀數,預設為1024audio: PyAudio物件stream:呼叫PyAudio的open函數開啟的音訊流
函數
get_pyaudio:用來獲取PyAudio的版本號,並呼叫PyAudio庫list_microphone_names:返回當前系統中所有可用的麥克風裝置的名稱列表list_working_microphones:返回當前系統中所有正在工作的麥克風裝置的名稱列表。麥克風裝置是否執行的評定方式為:對於某裝置,嘗試錄製一段短暫的音訊,然後檢查是否成功錄製到了具有一定音訊能量的音訊資料。
Recognizer類
Recognizer類是用於語音識別的主要類,它提供了一系列引數和函數來處理音訊輸入,主要引數和函數如下:
引數
energy_threshold = 300: 用於錄製最低音訊能量,基於音訊均方根RMS計算能量dynamic_energy_threshold = True: 是否使用動態能量閾值dynamic_energy_adjustment_damping = 0.15: 能量閾值調整的阻尼係數dynamic_energy_ratio = 1.5: 動態能量比率pause_threshold = 0.8: 在一段完整短語被認為結束之前,非語音音訊的持續時間(以秒為單位)operation_timeout = None: 內部操作(例如API請求)開始後超時的時間(以秒為單位),如果不設定超時時間,則為Nonephrase_threshold = 0.3: 認為一段語音至少需要的持續時間(以秒為單位),低於該值的語音將被忽略(用於過濾噪聲)non_speaking_duration = 0.5: 非語音音訊的持續時間(以秒為單位)
函數
record:從一個音訊源中讀取資料adjust_for_ambient_noise:用於在錄製音訊之前自動根據麥克風的環境噪聲水平調整energy_threshold引數listen:音訊錄製,結果返回AudioData類listen_in_background:用於在後臺錄製音訊並呼叫回撥函數
Recognizer類的listen函數每次錄音分為三個階段:
-
錄音起始
這一階段意味著開始錄音但是沒有聲音輸入。如果當前獲得的聲音片段能量值低於energy_threshold,則認為沒有聲音輸入。一旦當前獲得的聲音片段能量值高於energy_threshold,則進入下一階段。該階段將最多儲存non_speaking_duration長度的音訊片段。如果dynamic_energy_threshold為True,則會根據環境動態調整energy_threshold。
listen函數提供輸入引數timeout以控制該階段時長,如果錄音處於該階段timeout秒則停止錄音返回錯誤提示,timeout預設為None。 -
錄音中
這一階段意味著已有聲音輸入。如果聲音片段能量值低於energy_threshold連續超過pause_threshold秒,則結束錄音。在這一階段energy_threshold一直是固定值,並不會進行動態調整。
listen函數提供輸入引數phrase_time_limit以控制該階段最大時長,如果錄音處於該階段phrase_time_limit秒則結束錄音。 -
錄音結束
在這一階段中,如果錄音中階段獲得的聲音片段時間不超過phrase_threshold秒,則不返回錄音結果且進入下一次錄音起始階段。如果超過phrase_threshold秒,則將音訊片段轉為音訊流,以AudioData物件返回。
2.2 範例程式碼
音訊錄製
import speech_recognition as sr
# 建立一個Recognizer物件,用於語音識別
r = sr.Recognizer()
# 設定相關閾值
r.non_speaking_duration = 0.3
r.pause_threshold = 0.5
# 建立一個Microphone物件,設定取樣率為16000
# 建構函式所需引數device_index=None, sample_rate=None, chunk_size=1024
msr = sr.Microphone(sample_rate=16000)
# 開啟麥克風
with msr as source:
# 如果想連續錄音,該段程式碼使用for迴圈
# 進行環境噪音適應,duration為適應時間,不能小於0.5
# 如果無噪聲適應要求,該段程式碼可以註釋
r.adjust_for_ambient_noise(source, duration=0.5)
print("開始錄音")
# 使用Recognizer監聽麥克風錄音
# phrase_time_limit=None表示不設定時間限制
audio = r.listen(source, phrase_time_limit=None)
print("錄音結束")
# 將錄音資料寫入.wav格式檔案
with open("microphone-results.wav", "wb") as f:
# audio.get_wav_data()獲得wav格式的音訊二進位制資料
f.write(audio.get_wav_data())
# 將錄音資料寫入.raw格式檔案
with open("microphone-results.raw", "wb") as f:
f.write(audio.get_raw_data())
# 將錄音資料寫入.aiff格式檔案
with open("microphone-results.aiff", "wb") as f:
f.write(audio.get_aiff_data())
# 將錄音資料寫入.flac格式檔案
with open("microphone-results.flac", "wb") as f:
f.write(audio.get_flac_data())
音訊檔讀取
# 匯入speech_recognition庫,別名為sr
import speech_recognition as sr
# 建立一個Recognizer物件r,用於語音識別
r = sr.Recognizer()
# 設定音訊檔路徑
filepath = "demo.wav"
# 使用AudioFile開啟音訊檔作為音訊源
with sr.AudioFile(filepath) as source:
# 使用record方法記錄從音訊源中提取的2秒音訊,從第1秒開始
audio = r.record(source, offset=1, duration=2)
# 建立一個檔案用於儲存提取的音訊資料
with open("microphone-results.wav", "wb") as f:
# 將提取的音訊資料寫入檔案
f.write(audio.get_wav_data())
回撥函數的使用
import time
import speech_recognition as sr
# 這是從後臺執行緒呼叫的回撥函數
def callback(recognizer, audio):
# recognizer是Recognizer物件的範例。audio是從麥克風捕獲到的音訊資料
print(type(audio))
r = sr.Recognizer()
m = sr.Microphone()
with m as source:
# 我們只需要在開始監聽之前校準一次
r.adjust_for_ambient_noise(source)
# 在後臺開始監聽
stop_listening = r.listen_in_background(m, callback)
# 進行一些無關的計算,持續5秒鐘
for _ in range(50):
# 即使主執行緒正在做其他事情,我們仍然在監聽
time.sleep(0.1)
# 呼叫此函數請求停止後臺監聽
stop_listening(wait_for_stop=False)
麥克風裝置檢視
import speech_recognition as sr
# 獲取麥克風裝置名稱列表
def list_microphone_names():
mic_list = sr.Microphone.list_microphone_names()
for index, mic_name in enumerate(mic_list):
print("Microphone {}: {}".format(index, mic_name))
print("\n")
# 獲取可用的工作麥克風列表
def list_working_microphones():
mic_list = sr.Microphone.list_working_microphones()
for index, mic_name in mic_list.items():
print("Microphone {}: {}".format(index, mic_name))
print("\n")
# 獲得pyaudio物件
def get_pyaudio():
audio = sr.Microphone.get_pyaudio().PyAudio()
# 獲取預設音訊輸入裝置資訊
print(audio.get_default_input_device_info())
print("\n")
return audio
print("所有麥克風列表")
list_microphone_names()
print("可執行麥克風列表")
list_working_microphones()
print("預設音訊輸入裝置資訊")
get_pyaudio()
3 語音識別範例應用
本範例給出一個基於SpeechRecognition庫和Whisper語音識別庫的非流式語音識別範例應用。一般來說語音識別分為流式語音識別和非流式語音識別:
- 流式語音識別是指在語音輸入過程中實時進行語音識別,即邊接收語音資料邊輸出識別結果,實現實時性較高的語音識別。在流式語音識別中,語音被分割成一小段一小段的流,可以通過連續傳送這些流來實時地獲取識別結果。隨著語音輸入的增加,流式語音識別也可以優化輸出部分結果。流式語音識別準確率相對較低,但是實時性強,適用於需要快速響應的場景,例如實時語音助手、電話客服、會議記錄等。技術上,流式語音識別需要實時處理音訊流,要求演演算法具有低延遲和高吞吐量的特點,通常使用各種優化策略來提高實時效能。
- 非流式語音識別是指等待語音輸入結束後將完整的語音輸入一次性進行分析和識別。非流式語音識別精度高,適用於一些不需要實時響應的場景或一次性識別整段語音的場景,如指令識別、語音轉寫、語音搜尋、語音翻譯等。技術上,非流式語音識別注重語音的整體準確性和語意理解,通常採用複雜的模型和演演算法來提高識別準確率。
Whisper是OpenAI開源的通用多語言語音識別模型庫。Whisper使用了一個序列到序列的Transformer模型,支援多國語言語音識別,其英語的識別水平與人類接近。關於Whisper的安裝和使用可參考Whisper開源倉庫或參考文章:Whisper語音轉文字手把手教學。所提供的語音識別範例實現了簡單的語音起始和結束檢測,並進行相應的語音識別和結果展示,程式程式碼結構如下:
.
├── asr.py 語音識別類
├── record.py 錄音類
└── run.py 介面類
安裝SpeechRecognition庫和Whisper庫後執行run.py檔案即可開啟範例應用。
介面類
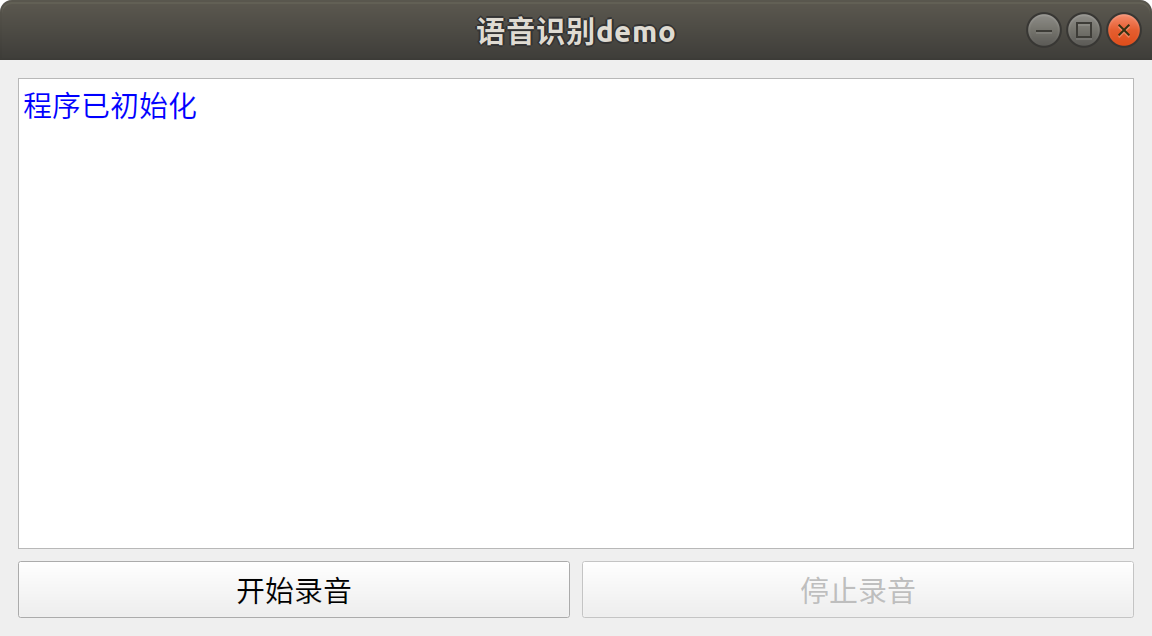
介面類提供了一個基於PyQt5編寫的簡單應用介面,如下所示。當介面初始化時,會同時初始化錄音類和語音識別類。點選開始錄音按鈕後,程式將實現自動迴圈監聽說話音訊的開始和結束。每次說話結束後,程式會自動進行語音識別,並將識別結果顯示在介面中。點選停止按鈕則會等待錄音結束並停止語音監聽。
# run.py
from PyQt5 import QtGui
from PyQt5.QtWidgets import *
from PyQt5.QtCore import QSize, Qt
import sys
from record import AudioHandle
class Window(QMainWindow):
"""
介面類
"""
def __init__(self):
super().__init__()
# --- 設定標題
self.setWindowTitle('語音識別demo')
# --- 設定視窗尺寸
# 獲取系統桌面尺寸
desktop = app.desktop()
# 設定介面初始尺寸
self.width = int(desktop.screenGeometry().width() * 0.3)
self.height = int(0.5 * self.width)
self.resize(self.width, self.height)
# 設定視窗最小值
self.minWidth = 300
self.setMinimumSize(QSize(self.minWidth, int(0.5 * self.minWidth)))
# --- 建立元件
self.showBox = QTextEdit()
self.showBox.setReadOnly(True)
self.startBtn = QPushButton("開始錄音")
self.stopBtn = QPushButton("停止錄音")
self.stopBtn.setEnabled(False)
# --- 元件初始化
self.initUI()
# --- 初始化音訊類
self.ahl = AudioHandle()
# 連線用於傳遞資訊的訊號
self.ahl.infoSignal.connect(self.showInfo)
self.showInfo("<font color='blue'>{}</font>".format("程式已初始化"))
def initUI(self) -> None:
"""
介面初始化
"""
# 設定整體佈局
mainLayout = QVBoxLayout()
mainLayout.addWidget(self.showBox)
# 設定底部水平佈局
blayout = QHBoxLayout()
blayout.addWidget(self.startBtn)
blayout.addWidget(self.stopBtn)
mainLayout.addLayout(blayout)
mainWidget = QWidget()
mainWidget.setLayout(mainLayout)
self.setCentralWidget(mainWidget)
# 設定事件
self.startBtn.clicked.connect(self.record)
self.stopBtn.clicked.connect(self.record)
def record(self) -> None:
"""
錄音控制
"""
sender = self.sender()
if sender.text() == "開始錄音":
self.stopBtn.setEnabled(True)
self.startBtn.setEnabled(False)
# 開啟錄音執行緒
self.ahl.start()
elif sender.text() == "停止錄音":
self.stopBtn.setEnabled(False)
# waitDialog用於等待錄音停止
waitDialog = QProgressDialog("正在停止錄音...", None, 0, 0)
waitDialog.setWindowTitle("請等待")
waitDialog.setWindowModality(Qt.ApplicationModal)
waitDialog.setCancelButton(None)
waitDialog.setRange(0, 0)
# 設定 Marquee 模式
waitDialog.setWindowFlag(Qt.WindowContextHelpButtonHint, False)
waitDialog.setWindowFlag(Qt.WindowCloseButtonHint, False)
waitDialog.setWindowFlag(Qt.WindowMaximizeButtonHint, False)
waitDialog.setWindowFlag(Qt.WindowMinimizeButtonHint, False)
waitDialog.setWindowFlag(Qt.WindowTitleHint, False)
# 關閉對話方塊邊框
waitDialog.setWindowFlags(self.windowFlags() | Qt.FramelessWindowHint)
# 連線關閉訊號,即ahl執行緒結束則waitDialog關閉
self.ahl.finished.connect(waitDialog.accept)
# 結束錄音執行緒
self.ahl.stop()
if self.ahl.isRunning():
# 顯示對話方塊
waitDialog.exec_()
# 關閉對話方塊
self.ahl.finished.disconnect(waitDialog.accept)
waitDialog.close()
self.startBtn.setEnabled(True)
def showInfo(self, text: str) -> None:
"""
資訊展示函數
:param text: 輸入文字,可支援html
"""
self.showBox.append(text)
if not self.ahl.running:
self.stopBtn.click()
def closeEvent(self, event: QtGui.QCloseEvent):
"""
重寫退出事件
:param event: 事件物件
"""
# 點選停止按鈕
if self.ahl.running:
self.stopBtn.click()
del self.ahl
event.accept()
if __name__ == '__main__':
app = QApplication(sys.argv)
ex = Window()
# 獲取預設圖示
default_icon = app.style().standardIcon(QStyle.SP_MediaVolume)
# 設定視窗圖示為預設圖示
ex.setWindowIcon(default_icon)
ex.show()
sys.exit(app.exec_())
錄音類
錄音類可以用於監聽麥克風輸入的音訊並呼叫語音識別類進行識別。通過設定取樣率、適應環境時長、錄音最長時長等引數,實現自動判斷說話開始和結束的功能。同時,通過PyQt5的訊號機制,在介面上展示不同型別的資訊,包括警告資訊和識別結果。
# record.py
import speech_recognition as sr
from PyQt5.QtCore import QThread, pyqtSignal
import time, os
import numpy as np
from asr import ASR
class AudioHandle(QThread):
"""
錄音控制類
"""
# 用於展示資訊的pyqt訊號
infoSignal = pyqtSignal(str)
def __init__(self, sampleRate: int = 16000, adjustTime: int = 1, phraseLimitTime: int = 5,
saveAudio: bool = False, hotWord: str = ""):
"""
:param sampleRate: 取樣率
:param adjustTime: 適應環境時長/s
:param phraseLimitTime: 錄音最長時長/s
:param saveAudio: 是否儲存音訊
:param hotWord: 熱詞資料
"""
super(AudioHandle, self).__init__()
self.sampleRate = sampleRate
self.duration = adjustTime
self.phraseTime = phraseLimitTime
# 用於設定執行狀態
self.running = False
self.rec = sr.Recognizer()
# 麥克風物件
self.mic = sr.Microphone(sample_rate=self.sampleRate)
# 語音識別模型物件
# hotWord為需要優先識別的熱詞
# 輸入"秦劍 無憾"表示優先匹配該字串中的字元
self.asr = ASR(prompt=hotWord)
self.saveAudio = saveAudio
self.savePath = "output"
def run(self) -> None:
self.listen()
def stop(self) -> None:
self.running = False
def setInfo(self, text: str, type: str = "info") -> None:
"""
展示資訊
:param text: 文字
:param type: 文字型別
"""
nowTime = time.strftime("%H:%M:%S", time.localtime())
if type == "info":
self.infoSignal.emit("<font color='blue'>{} {}</font>".format(nowTime, text))
elif type == "text":
self.infoSignal.emit("<font color='green'>{} {}</font>".format(nowTime, text))
else:
self.infoSignal.emit("<font color='red'>{} {}</font>".format(nowTime, text))
def listen(self) -> None:
"""
語音監聽函數
"""
try:
with self.mic as source:
self.setInfo("錄音開始")
self.running = True
while self.running:
# 裝置監控
audioIndex = self.mic.audio.get_default_input_device_info()['index']
workAudio = self.mic.list_working_microphones()
if len(workAudio) == 0 or audioIndex not in workAudio:
self.setInfo("未檢測到有效音訊輸入裝置!!!", type='warning')
break
self.rec.adjust_for_ambient_noise(source, duration=self.duration)
self.setInfo("正在錄音")
# self.running為否無法立即退出該函數,如果想立即退出則需要重寫該函數
audio = self.rec.listen(source, phrase_time_limit=self.phraseTime)
# 將音訊二進位制資料轉換為numpy型別
audionp = self.bytes2np(audio.frame_data)
if self.saveAudio:
self.saveWav(audio)
# 判斷音訊rms值是否超過經驗閾值,如果沒超過表明為環境噪聲
if np.sqrt(np.mean(audionp ** 2)) < 0.02:
continue
self.setInfo("音訊正在識別")
# 識別語音
result = self.asr.predict(audionp)
self.setInfo(f"識別結果為:{result}", "text")
except Exception as e:
self.setInfo(e, "warning")
finally:
self.setInfo("錄音停止")
self.running = False
def bytes2np(self, inp: bytes, sampleWidth: int = 2) -> np.ndarray:
"""
將音訊二進位制資料轉換為numpy型別
:param inp: 輸入音訊二進位制流
:param sampleWidth: 音訊取樣寬度
:return: 音訊numpy陣列
"""
# 使用np.frombuffer函數將位元組序列轉換為numpy陣列
tmp = np.frombuffer(inp, dtype=np.int16 if sampleWidth == 2 else np.int8)
# 確保tmp為numpy陣列
tmp = np.asarray(tmp)
# 獲取tmp陣列元素的資料型別資訊
i = np.iinfo(tmp.dtype)
# 計算tmp元素的絕對最大值
absmax = 2 ** (i.bits - 1)
# 計算tmp元素的偏移量
offset = i.min + absmax
# 將tmp陣列元素轉換為浮點型,並進行歸一化
array = np.frombuffer((tmp.astype(np.float32) - offset) / absmax, dtype=np.float32)
# 返回轉換後的numpy陣列
return array
def saveWav(self, audio: sr.AudioData) -> None:
"""
儲存語音結果
:param audio: AudioData音訊物件
"""
nowTime = time.strftime("%H_%M_%S", time.localtime())
os.makedirs(self.savePath, exist_ok=True)
with open("{}/{}.wav".format(self.savePath, nowTime), 'wb') as f:
f.write(audio.get_wav_data())
語音識別類
語音識別類利用Whisper進行語音識別。在使用Whisper進行語音識別時,可以通過設定initial_prompt引數來指定初始提示。initial_prompt引數是一個字串,用於在模型生成文字之前提供一些初始的上下文資訊。將這些資訊傳遞給Whisper模型可以幫助它更好地理解任務的背景和上下文。通過設定適當的initial_prompt,可以引導模型產生與特定主題相關的響應或者在對話中提供一些先驗知識。例如,熱點詞彙識別,結果為簡體字還是繁體字。initial_prompt並不是必需的引數,如果沒有適當的初始提示,可以選擇不使用它,讓模型完全自由生成響應。但是要注意的是如果輸入的語音為環境噪聲或者使用的是小型Whisper模型,initial_prompt的設定可能會導致語音識別輸出結果為initial_prompt。
Whisper提供了5種型號的模型,其中4種支援純英文版本,以平衡速度和準確性。Whisper模型越大精度越高,速度越慢,本文預設使用small型號的模型。以下是這些可用模型的型號名稱、大致的視訊記憶體要求和相對速度:
| 型號 | 引數量 | 僅英文模型 | 多語言模型 | 所需視訊記憶體 | 相對速度 |
|---|---|---|---|---|---|
| tiny | 39M | tiny.en |
tiny |
~1GB | ~32x |
| base | 74M | base.en |
base |
~1GB | ~16x |
| small | 244M | small.en |
small |
~2GB | ~6x |
| medium | 769M | medium.en |
medium |
~5GB | ~2x |
| large | 1550M | N/A | large |
~10GB | 1x |
# asr.py
import whisper
import numpy as np
class ASR:
"""
語音識別模型類
"""
def __init__(self, modelType: str = "small", prompt: str = ""):
"""
:param modelType: whisper模型型別
:param prompt: 提示詞
"""
# 模型預設使用cuda執行,沒gpu跑模型很慢。
# 使用device="cpu"即可改為cpu執行
self.model = whisper.load_model(modelType, device="cuda")
# prompt作用就是提示模型輸出指定型別的文字
# 這裡使用簡體中文就是告訴模型儘可能輸出簡體中文的識別結果
self.prompt = "簡體中文" + prompt
def predict(self, audio: np.ndarray) -> str:
"""
語音識別
:param audio: 輸入的numpy音訊陣列
:return: 輸出識別的字串結果
"""
# prompt在whisper中用法是作為transformer模型交叉注意力模組的初始值。transformer為自迴歸模型,會逐個生成識別文字,
# 如果輸入的語音為空,initial_prompt的設定可能會導致語音識別輸出結果為initial_prompt
result = self.model.transcribe(audio.astype(np.float32), initial_prompt=self.prompt)
return result["text"]
