DevOps|服務治理與服務保障實踐指南
朱晉君@君哥聊技術
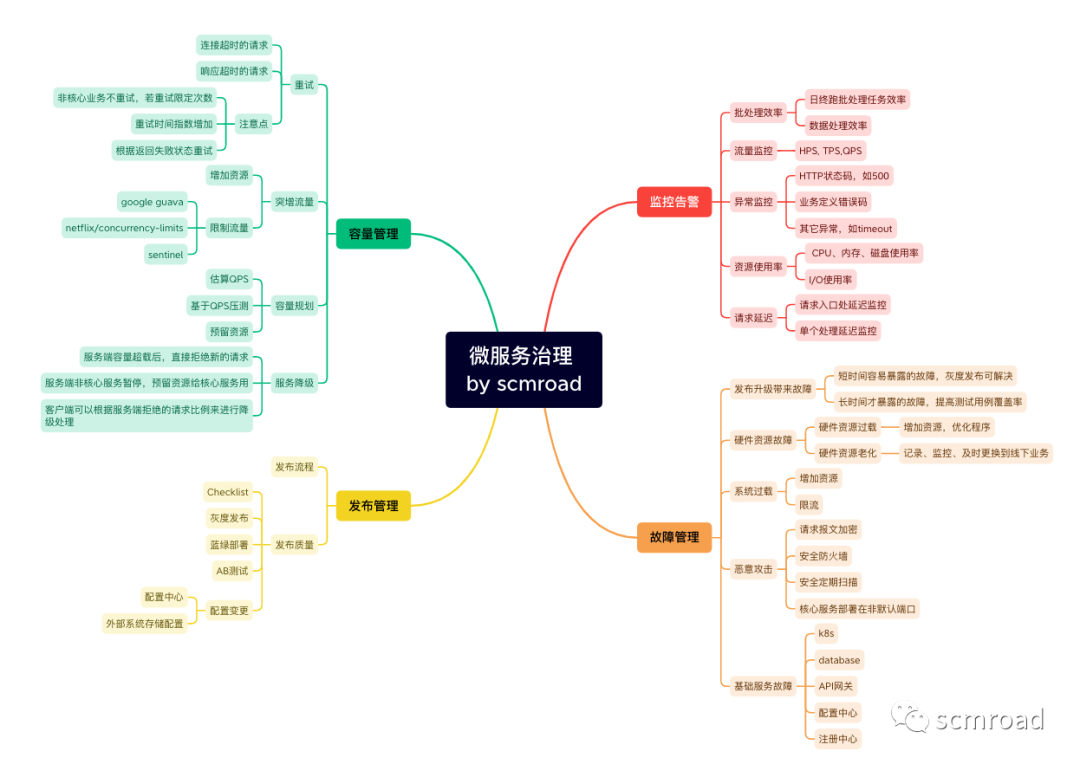
我自己為了消化裡邊的內容,整理了一個腦圖,希望對你有幫助。
凌晨四點被公司的監控告警叫醒了,告警的原因是生產環境跑批任務發生故障。即刻起床處理故障,但還是花了不少時間才解決。
這次故障是一次資料校驗的跑批任務,校驗前面跑批任務的資料是否正確。幸運的是,之前的核心任務已經完成,並沒有影響到生產上的交易系統工作。
為什麼我這裡提到了交易工作呢?因為交易系統是整個系統業務流量的入口,如果交易系統發生故障,那會給公司帶來直接的收入損失。
今天我們聊的話題是服務治理,服務治理最終達到的結果就是系統 「7 * 24」 小時不間斷服務。
1 監控告警
公司的這次生產告警很準確,找到系統的直接維護人,並且通知到是哪個跑批任務出了故障。這次告警是通過監控跑批任務中介軟體的任務執行結果來觸發的。
一般情況下,告警有哪些型別呢?我們看下圖:
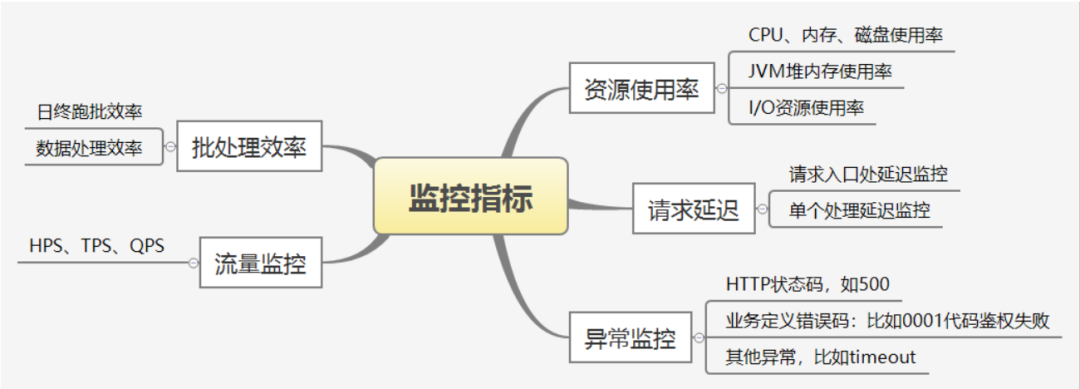
1.1 批次處理效率
❝
多數情況下批次處理任務是不阻礙業務入口的,所以不需要監控。
❞
在阻礙業務入口的情況下,批次處理任務必須要監控。我舉兩個業務場景:
- 域名系統要通過dns資訊和資料庫記錄來找出髒資料進行交易補償,這期間客戶查詢域名資訊可能是髒資料
- 銀行日終跑批期間是不允許實時交易的,這個「7 * 24」小時不間斷服務相違背
這些場景下批次處理效率是非常重要的一個監控指標,必須設定超時閾值並進行監控。
1.2 流量監控
常用的限流的指標如下圖:

流量監控我們需要注意幾點:
- 不同的系統,使用的監控指標是不同的,比如redis,可以用QPS指標,對於交易系統,可以用TPS
- 通過測試和業務量的預估來設定合適的監控閾值
- 監控閾值需要考慮突發情況,比如秒殺、搶券等場景
1.3 異常監控
異常監控對於系統來說非常重要。在生產環境中很難保證程式不發生異常,設定合理的異常報警對快速定位和解決問題至關重要。比如開篇提到的跑批告警,告警資訊中帶著異常,讓我很快就定位到了問題。
異常監控需要注意下面幾個方面:
- 使用者端read timeout,這時要儘快從伺服器端找出原因
- 對使用者端收到響應的時間設定一個閾值,比如1秒,超出後觸發告警
- 對業務異常一定要監控,比如失敗響應碼
1.4 資源使用率
生產環境設定系統資源時,一般要對系統資源的使用率有一個預測。比如redis在當前的記憶體增長速率下,多久會耗盡記憶體,資料庫在當前的增長速率下多久會用光磁碟。
系統資源需要設定一個閾值,比如70%,超過這個限制就要觸發告警。因為資源使用快要飽和時,處理效率也會嚴重下降。
設定資源使用率的閾值時,一定要考慮突增流量和突發業務的情況,提前預留額外的資源來應對。
對核心服務要做好限流措施,防止突增流量把系統壓垮。
1.5 請求延遲
請求延遲並不是一個很容易統計的指標,下圖是一個電商購物系統:
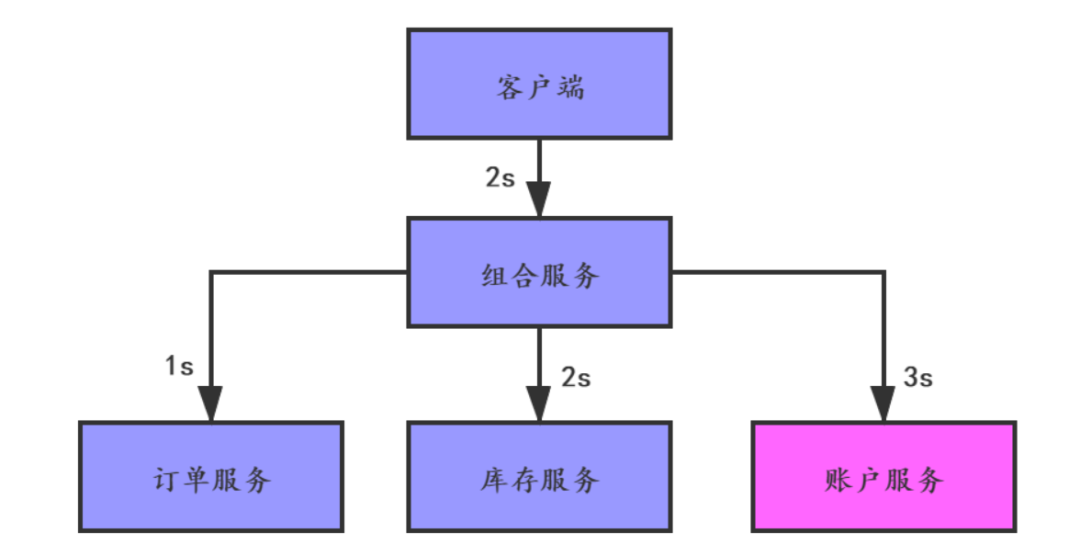
這個圖中,我們假設組合服務會並行地呼叫下面的訂單、庫存和賬戶服務。使用者端發出請求後,組合服務處理請求需要花費2秒的處理時間,賬戶服務需要花費3秒的處理時間,那使用者端設定的read timeout最小是5秒。
監控系統需要設定一個閾值來監控,比如1秒內如果有100個請求延遲都大於了5秒就觸發報警,讓系統維護人員去查詢問題。
❝
使用者端設定的read timeout不能太大,如果因為伺服器端故障導致延遲,要保證fail-fast,防止因為資源不能釋放造成系統效能大幅度降低。
❞
1.6 監控注意事項
監控是為了能讓系統維護人員快速發現生產問題並定位到原因,不過監控系統也有幾個指標需要考慮:
- 根據監控目標來制定監控指標取樣頻率,頻率太高會增加監控成本。
- 監控覆蓋率,最好能夠覆蓋到所有核心的系統指標。
- 監控有效性,監控指標不是越多越好,太多會給分辨報警有效性帶來額外工作量,也會讓開發人員習以為常。
- 告警時效,對於跑批任務這種非實時交易類系統,可以不用實時告警,記錄事件後定一個時間,比如早晨8點觸發告警,責任人到公司後處理。
- 為避免長尾效應,最好不要使用平均值。如下圖:10個請求,有9個延遲都是1秒,但有1個延遲是10秒,所以平均值參考意義並不大。
❝
可以採用按照區間分組的方式,比如延遲1秒以內的請求數量,1-2秒的請求數量,2-3秒的請求數量分組進行統計,按照指數級增長的方式來設定監控閾值。
❞
2 故障管理
2.1 常見故障原因
故障發生的原因五花八門,但常見的無非下面幾種:
- 釋出升級帶來的故障
- 硬體資源故障
- 系統過載
- 惡意攻擊
- 基礎服務故障
2.2 應對策略
應對故障,我們分兩步走:
- 立即解決故障,比如因為資料問題引起的故障,修改問題資料即可。
- 找出故障原因,可以通過查詢紀錄檔或者呼叫鏈追蹤系統來定位問題並解決
2.2.1 軟體升級故障
升級帶來的故障,有的是上線後能很快暴露的。有的是上線很長時間才會暴露,比如有的業務程式碼可能之前一直執行不到。
對於第一種情況,可以採用灰度釋出的方式進行驗證解決。
對於第二種情況,完全避免是很難的,我們只能最大限度地提高測試用例覆蓋率。
2.2.2 硬體資源故障
這類故障主要分為兩類:
- 硬體資源超載,比如記憶體不夠
- 硬體資源老化
對於第一種故障一般用監控告警的方式來通知責任人處理,處理的方式主要是增加資源,找出消耗資源嚴重的程式進行優化。
對於第二種故障需要運維人員對硬體資源進行記錄和監控,對於老化的資源及時進行更換。
2.3 系統過載
系統過載可能是遇到秒殺之類的突增流量,也可能是隨著業務發展慢慢地超過系統承受能力,可以使用增加資源或者限流的方式來應對。
2.4 惡意攻擊
惡意攻擊的型別非常多,比如DDOS攻擊、惡意軟體、瀏覽器攻擊等。
針對惡意攻擊,防止手段也很多,比如對請求報文進行加密、引入專業的網路安全防火牆、定期安全掃描、核心服務部署在非預設埠等。
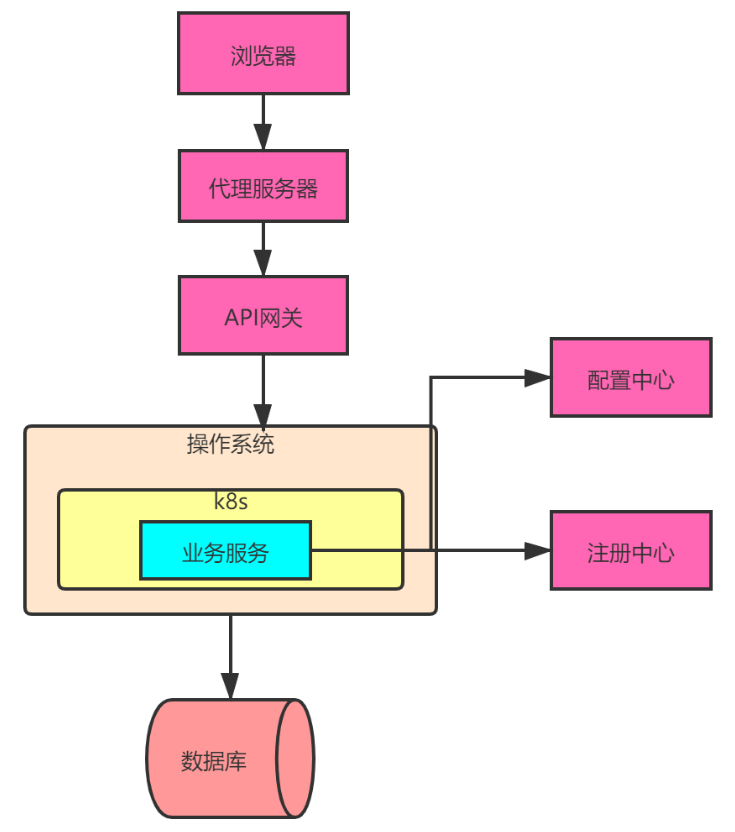
2.5 基礎軟體故障
如下圖所示,除了業務服務外每個元件都是基礎軟體,都需要考慮高可用。
3 釋出管理
釋出通常指軟硬體的升級,包括業務系統版本升級、基礎軟體升級、硬體環境升級等。作為程式設計師,本文講的升級是針對業務系統的升級。
3.1 釋出流程
一般情況下,業務系統升級流程如下:
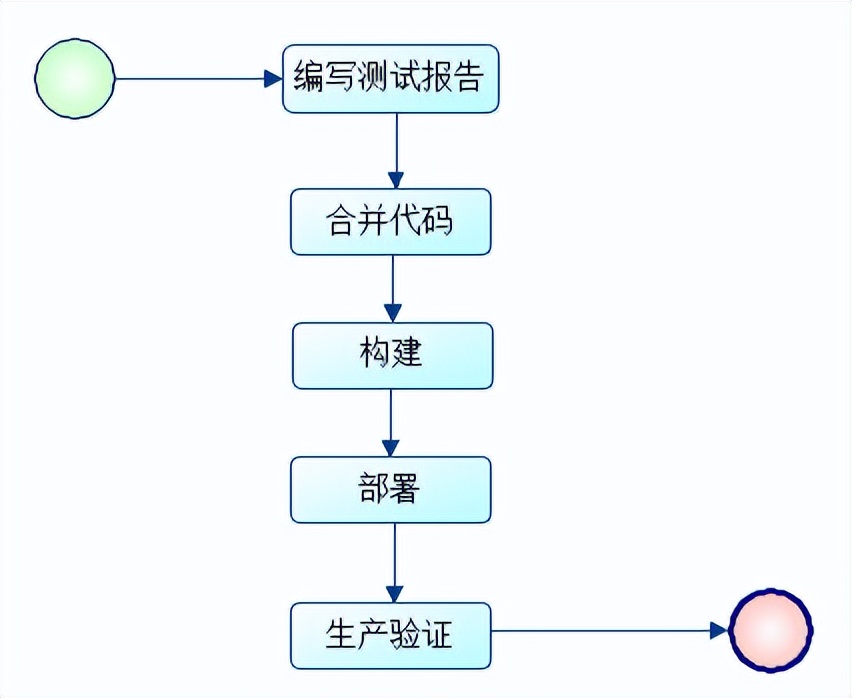
釋出到生產環境,驗證沒有問題表示釋出成功。
3.2 釋出質量
在升級軟體的時候,釋出質量非常重要,為保證釋出質量需要注意下面這些問題。
3.2.1 CheckList
為了保證釋出質量,釋出前維護一份CheckList,並且開發團隊對所有的問題進行確認。等這份清單都確認完成後進行構建釋出。下面是一些比較典型的問題:
- 上線sql是否正確
- 生產組態檔設定項是否完備
- 外部依賴的服務是否已經發布並驗證完成
- 新機器路由許可權是否已經開通
- 多個服務的釋出順序是否已經明確
- 如果上線後發生故障怎麼應對
3.2.2 灰度釋出
灰度釋出是指在黑與白之間,能夠平滑過渡的一種釋出方式。如下圖:
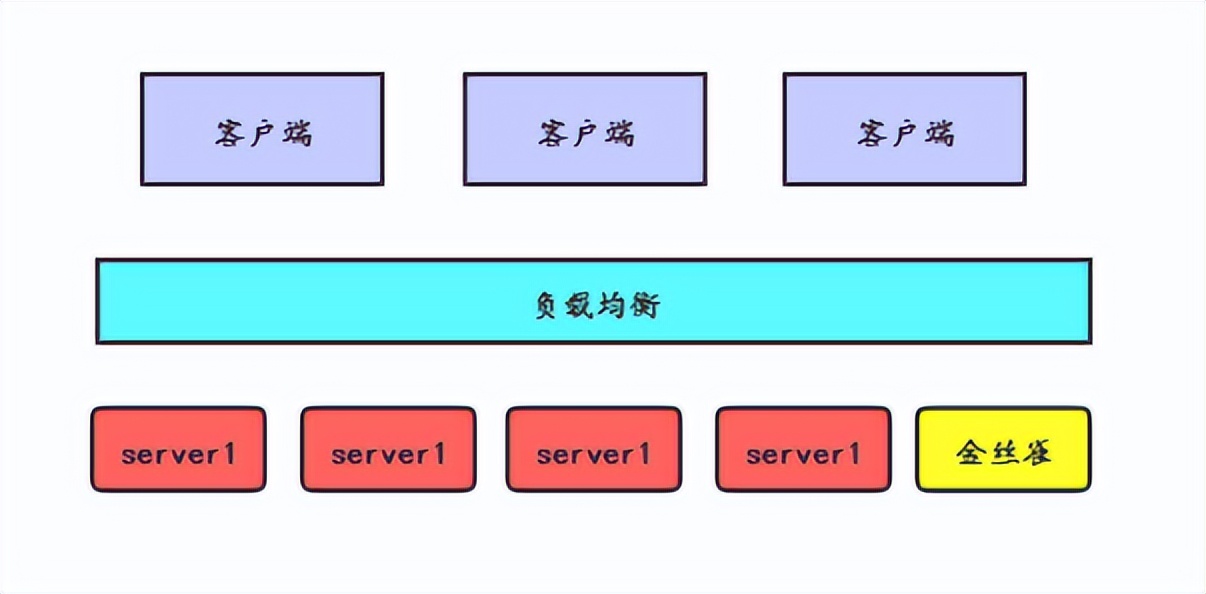
升級時採用金絲雀部署的方式,先把其中一個server作為金絲雀進行釋出升級,這個server在生產環境執行後沒有問題,再升級其他的server。有問題則進行回滾。
3.2.2 藍綠部署
藍綠部署的方式如下圖:
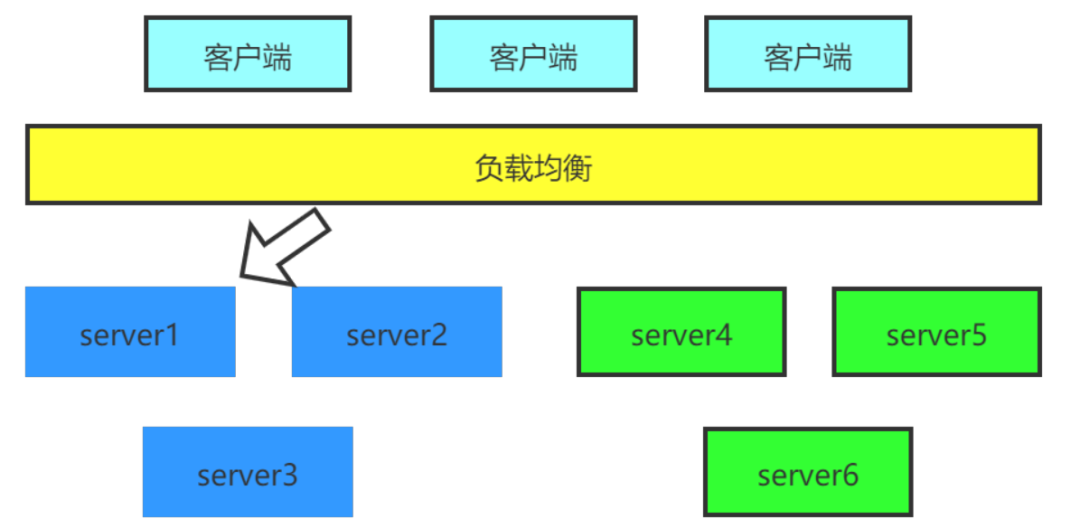
升級之前使用者端的請求傳送到綠色服務上,升級釋出之後,通過負載均衡把請求轉到藍色系統,綠色系統暫時不下線,如果生產測試沒有問題,則下線綠色系統,否則切回綠色系統。
❝
藍綠部署跟金絲雀部署的區別是,金絲雀部署不用增加新的機器,而藍綠部署相當於是增加了一套新機器,需要額外的資源成本。
❞
3.2.4 ab測試
ab測試是指在生產環境釋出多個版本,主要目的是測試不同版本的不同效果。比如頁面樣式不一樣,操作流程不一樣,這樣可以讓使用者選擇一個最喜歡的版本作為最終版本。如下圖:
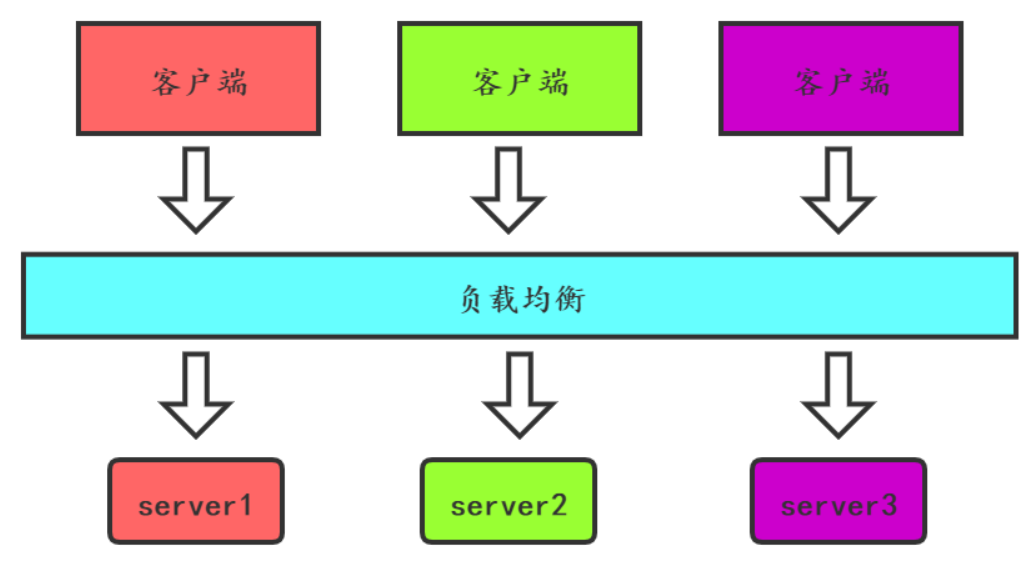
三個顏色的服務部署了,使用者端的請求分別傳送到跟自己顏色一樣的服務上。
❝
ab測試的版本都是已經是驗證沒有問題的,這點不同於灰度釋出。
❞
3.2.4 設定變更
好多時候我們把設定寫在程式碼裡,比如yaml檔案。這樣我們修改設定後就需要重新發布新版本。如果設定修改頻繁,可以考慮下面兩種方法:
- 引入設定中心
- 使用外部系統儲存設定
4 容量管理
在2.3節中講到系統過載導致的系統故障。容量管理是保證系統上線後穩定執行的一個重要環節,主要是保證系統流量不超過系統能承受的閾值,防止系統崩潰。一般情況下,系統容量超載的原因如下:
- 業務持續增加給系統帶來的流量不斷增加
- 系統資源收縮,比如一臺機器上新部署了一個應用,佔用了一些資源
- 系統處理請求變慢,比如因為資料量變大,資料庫響應變慢,導致單個請求處理時間變長,資源不能釋放
- 重試導致的請求增加
- 突增流量,比如微博系統遇到明星離婚案之類的新聞。
4.1 重試
對於一些失敗的請求進行重試,能夠很好地增加系統的使用者體驗。重試一般分為兩類,一類是對連線超時的請求,一類是對響應超時的請求。
對於連線超時的請求,可能是網路瞬時故障造成的,這種情況下重試並不會對伺服器端造成壓力,因為失敗的請求壓根就沒有到達伺服器端。
但是對於響應超時的請求,如果進行重試,可能會給伺服器端帶來額外的壓力。如下圖:
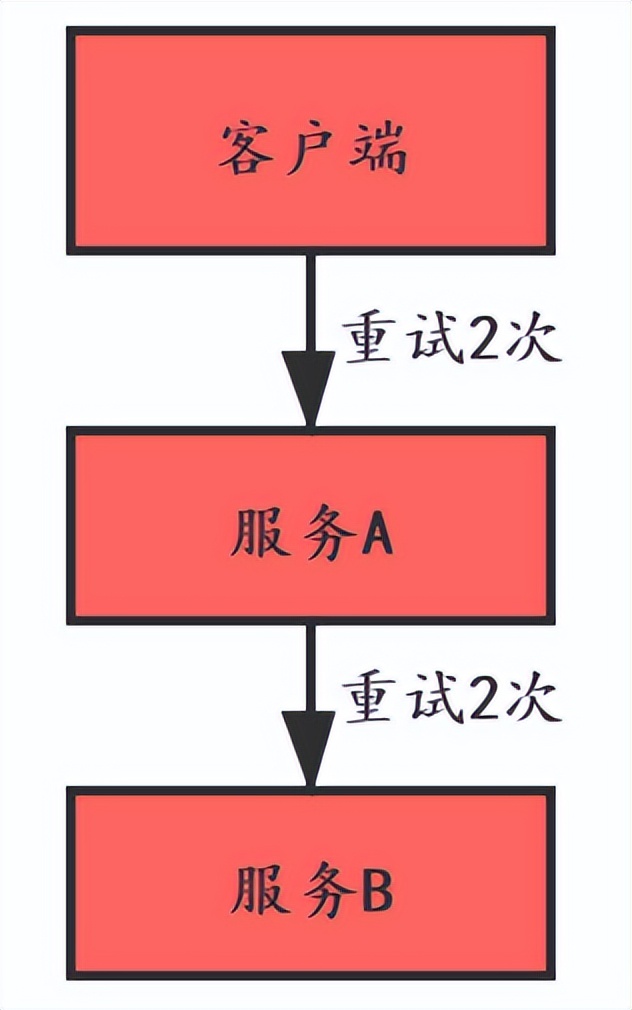
正常情況下,使用者端先呼叫服務A,服務A再呼叫服務B,服務B只被呼叫了一次。
如果服務B響應慢導致超時,使用者端設定了失敗重試2次,服務A也設定了失敗重試2次,在服務B最終不能響應的情況下,服務B最終被調了9次。
在大型分散式系統中,如果呼叫鏈很長,每個服務都設定了重試,那重試會給呼叫鏈下游服務造成巨大的壓力甚至讓系統崩潰。可見重試不是越多越好,合理的設定重試對系統有保護作用。
對於重試,有如下3個建議:
- 非核心業務不重試,如果重試,必須限定次數
- 重試時間間隔需要指數增加
- 根據返回失敗的狀態進行重試,比如伺服器端定義一個拒絕碼,使用者端就不重試了
4.2 突增流量
對於突增流量,是很難提前規劃到的。
遇到突增的流量時,我們可以先考慮增加資源。以K8S為例,如果原來有2個pod,使用deploy編排擴容到4個pod。命令如下:
kubectl scale deployment springboot-deployment --replicas=4
如果資源已經用完了,那就得考慮限流了。推薦幾個限流框架:
- google guava
- netflix/concurrency-limits
- sentinel
4.3 容量規劃
系統建設初期做好容量規劃是非常重要的。
可以根據業務量來估算系統的QPS,基於QPS進行壓力測試。針對壓力測試的結果估算的容量,並不一定能應對生產環境的真實場景和突發情況,可以根據預估容量給出預留資源,比如2倍容量。
4.4 服務降級
服務降級對於伺服器端來說,可以有三種方式:
- 伺服器端容量超載後,直接拒絕新的請求
- 非核心服務暫停,預留資源給核心服務用
- 使用者端可以根據伺服器端拒絕的請求比例來進行降級處理,比如觀察1分鐘,如果伺服器端對1000個請求,拒絕了100個,使用者端可以作為參考,以後每分鐘超過90個,就直接拒絕。
5 總結
微服務化的架構給系統帶來了很多好處,但同時也帶來了一些技術上的挑戰。這些挑戰包括服務註冊與發現、負載均衡、監控管理、釋出升級、存取控制等。而服務治理就是對這些問題進行管理和預防,保證系統持續平穩地執行。
本文所講的服務治理方案,也算是傳統意義上的方案,有時會有一些程式碼的侵入,而框架的選擇也會對程式語言有限制。
在雲原生時代,Service Mesh的出現又把服務治理的話題帶入一個新的階段。後續再做分享。
相關文章