Llama2 論文中譯版——開放式基礎和微調聊天模型
Llama 2:開放式基礎和微調聊天模型
寫在前頭
因為最近一直在使用 LLM 工具,所以在學習 Llama 2:開放式基礎和微調聊天模型 這篇論文的期間,順手將內容翻譯了過來。
整片譯文是由 ChatGPT3.5、DeepL、Copilot X和筆者一起完成的,特此表示感謝。
概要
在這項工作中,我們開發並行布了 Llama 2,這是一組經過預訓練和微調的大型語言模型(LLMs),其規模從 70 億到 700 億個引數不等。我們的微調 LLMs 被稱為 Llama 2-Chat,針對對話用例進行了優化。在我們測試的大多數基準測試中,我們的模型都優於開源聊天模型,而且根據我們對有用性和安全性的人工評估,我們的模型可能是封閉源模型的合適替代品。我們將詳細介紹我們對 Llama 2-Chat 進行微調和安全性改進的方法,以便社群能夠在我們工作的基礎上,為負責任地開發 LLMs 做出貢獻。
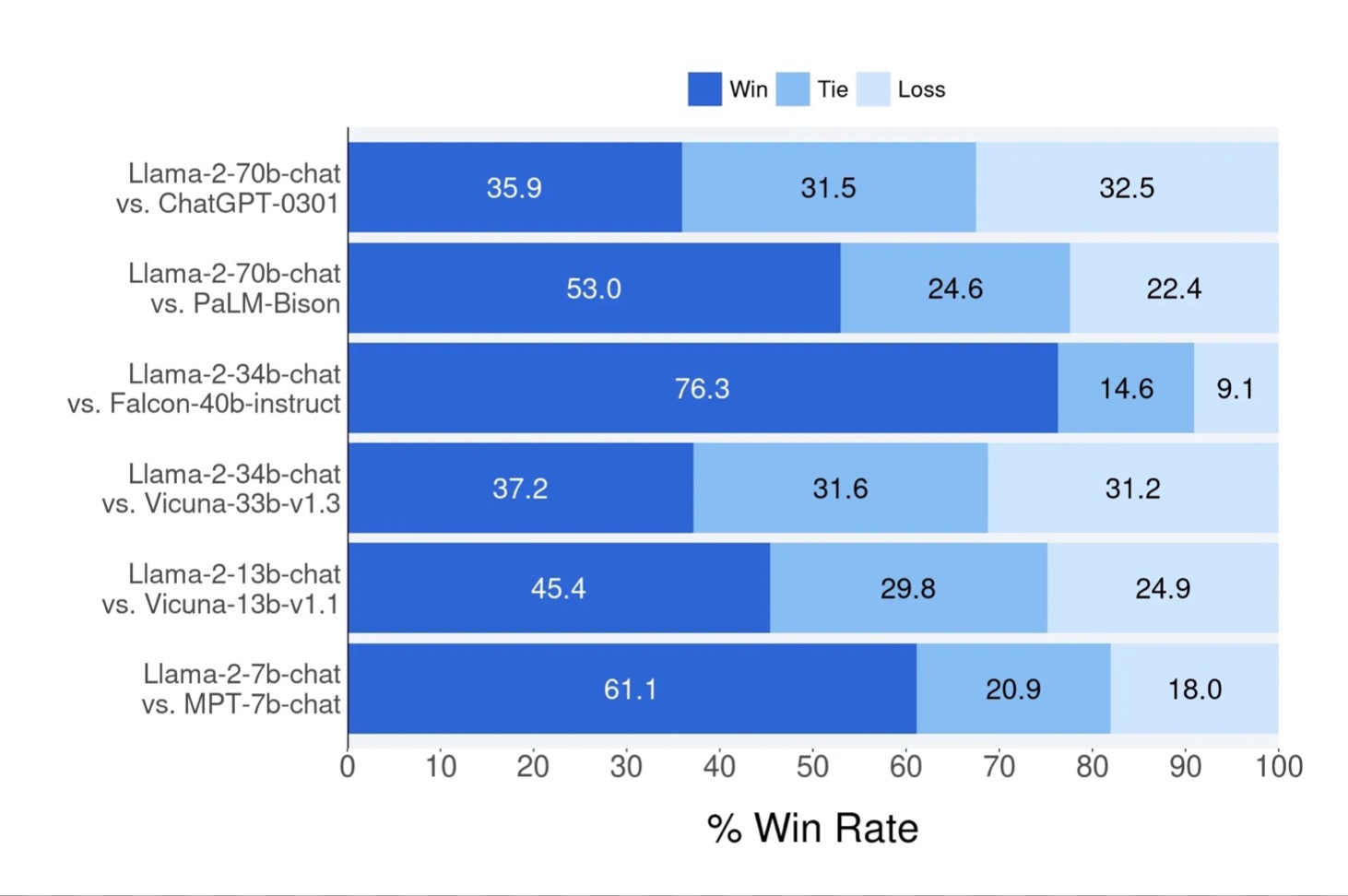
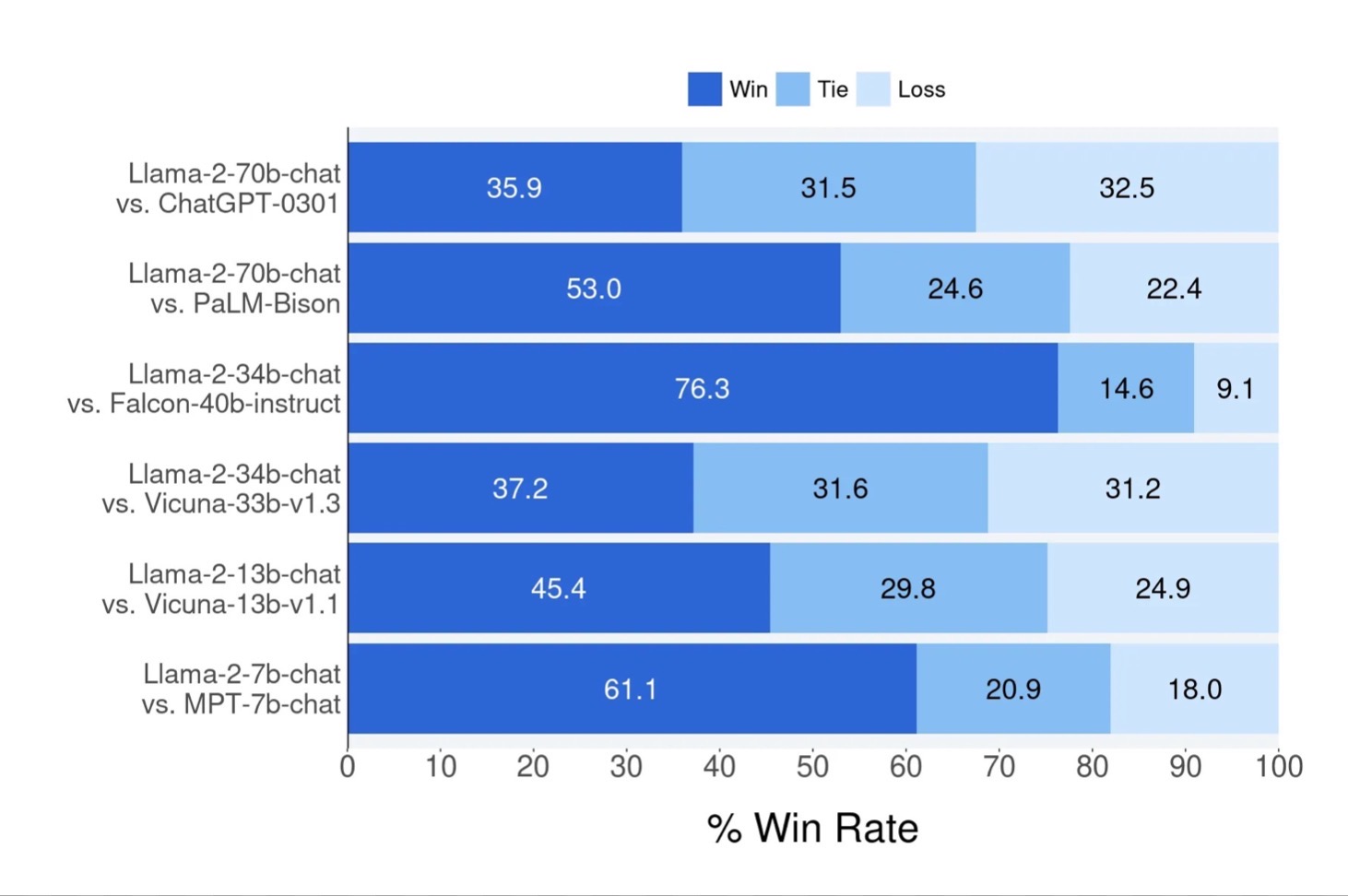
Llama 2-Chat 與其他開放原始碼和封閉原始碼模型相比的有用性人工評估結果。人類評測員比較了約 4k 條提示(包括單轉和多轉提示)上的各代模型。該評估的 95% 置信區間在 1% 到 2% 之間。更多詳情見第 3.4.2 節。在回顧這些結果時,需要注意的是,由於提示集的侷限性、審查指南的主觀性、個別評分者的主觀性以及比較世代的固有困難,人工評估可能會產生噪音。
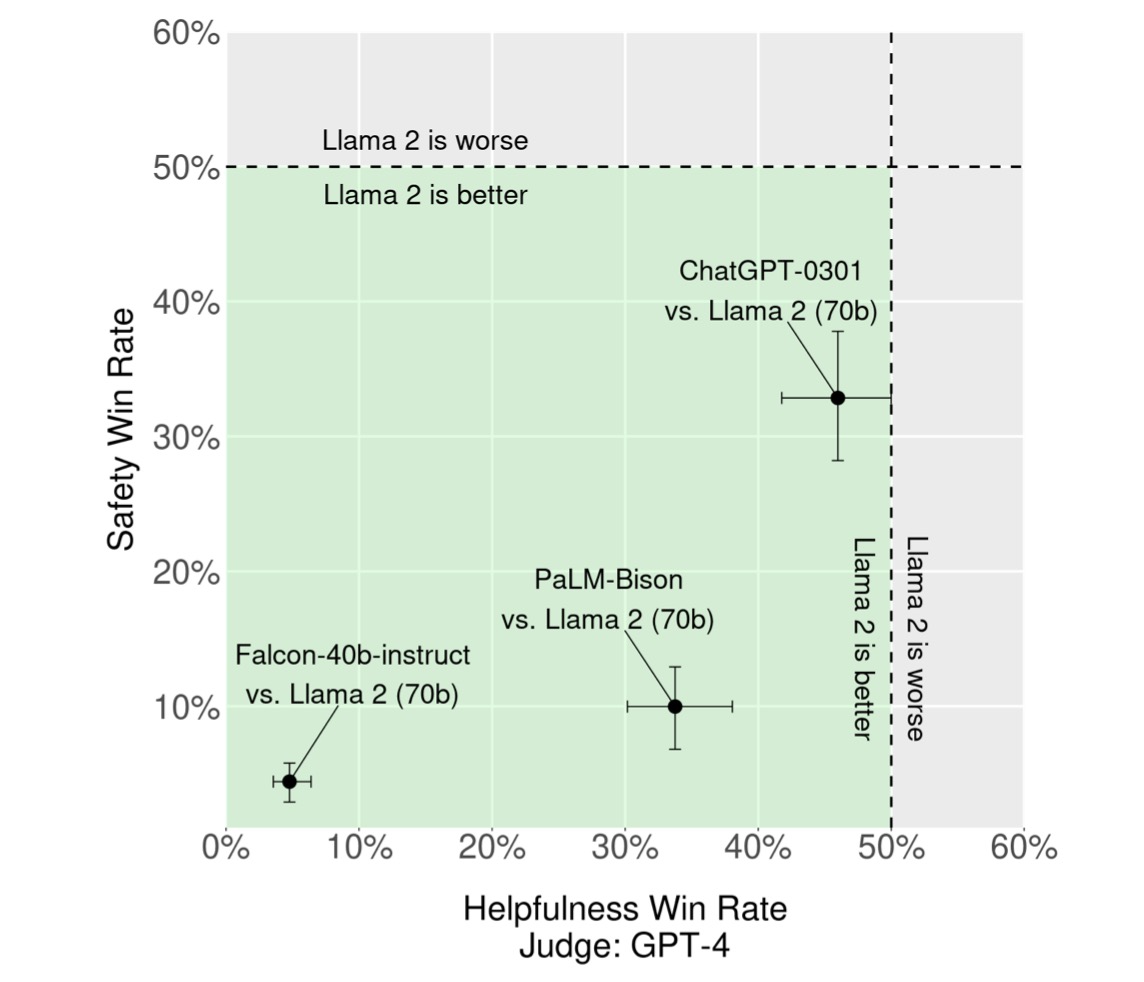
根據 GPT- 4,商業授權基礎線路與 Llama 2-Chat 之間在有用性和安全性方面的勝率百分比。為了補充人工評估,我們使用了一個不受我們自己指導的能力更強的模型。綠色區域表示根據 GPT-4 我們的模型更好。為消除平局,我們使用了勝/(勝+負)。向 GPT-4 提交模型響應的順序是隨機交換的,以減少偏差。
1 簡介
大型語言模型(LLMs)已顯示出作為高能力人工智慧助手的巨大前景,它們在需要專家知識的複雜推理任務中表現出色,涉及領域廣泛,包括程式設計和創意寫作等專業領域。它們可以通過直觀的聊天介面與人類進行互動,因此在普通大眾中得到了迅速而廣泛的應用。
考慮到訓練方法看似簡單明瞭,LLMs 的能力令人矚目。自動迴歸變換器(Auto-regressive transformers)是在大量自我監督資料的語料庫上進行預訓練的,然後通過人反饋強化學習(Reinforcement Learning with Human Feedback,RLHF)等技術與人類偏好保持一致。雖然訓練方法簡單,但由於計算要求高,LLM 的開發僅限於少數人。目前已公開發布的預訓練 LLM(如 BLOOM(Scao 等人,2022 年)、LLaMa-1(Touvron 等人,2023 年)和 Falcon(Penedo 等人,2023 年))與封閉式預訓練競爭對手(如 GPT-3(Brown 等人,2020 年)和 Chinchilla(Hoffmann 等人,2022 年))的效能不相上下,但這些模型都無法替代封閉式」產品「 LLM,如 ChatGPT、BARD 和 Claude。這些封閉式」產品「 LLM 經過了大量微調,以符合人類的偏好,從而大大提高了其可用性和安全性。這一步驟可能需要大量的計算和人工標註成本,而且往往不透明或不容易複製,從而限制了社群在推進人工智慧對齊研究方面的進展。
在這項工作中,我們開發並行布了 Llama 2,一個經過預訓練和微調的 LLMs(Llama 2 和 Llama 2-Chat)系列,規模高達 70B 個引數。在我們測試的一系列有用性和安全性基準中,Llama 2-Chat 模型的表現普遍優於現有的開源模型。至少在我們進行的人類評估中,它們似乎也與某些閉源模型不相上下(見圖 1 和圖 3)。我們已採取措施來提高這些模型的安全性,包括使用特定於安全性的資料註釋和調整,以及進行紅隊和採用迭代評估(red-teaming and employing iterative evaluations)。此外,本文還全面介紹了我們的微調方法和提高 LLM 安全性的途徑。我們希望這種開放效能夠讓社群重現經過微調的 LLM,並繼續提高這些模型的安全性,從而為更負責任地開發 LLM 鋪平道路。我們還分享了在開發 Llama 2 和 Llama 2-Chat 過程中觀察到的新現象,例如工具使用和知識的時間組織。
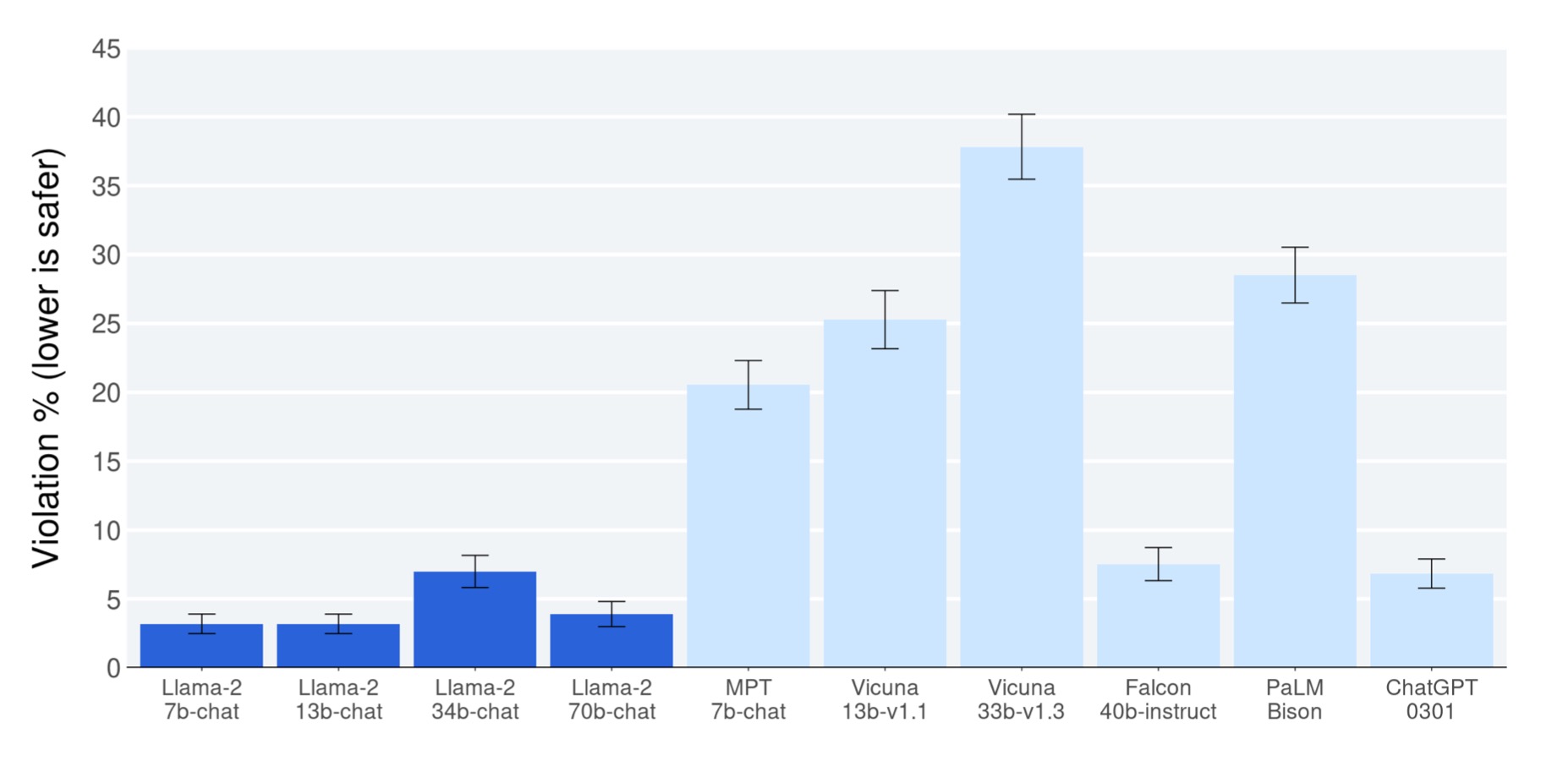
Llama 2-Chat 與其他開源和閉源模型的安全人工評估結果比較。人類評測員在約 2,000 個對抗性提示(包括單輪和多輪提示)中對各代模型違反安全規定的情況進行了評測。更多詳情可參見第 4.4 節。由於提示集的侷限性、審查指南的主觀性以及評分者個人的主觀性,LLM 評估存在固有偏差,因此必須對這些安全結果加以說明。此外,這些安全評估使用的內容標準很可能偏向於 Llama 2-Chat 模型。
我們向廣大公眾釋出以下模型,供研究和商業用途:
- Llama 2,Llama 1 的更新版本,使用新的公開可用資料進行訓練。我們還將預訓練語料庫的大小增加了40%,將模型的上下文長度加倍,並採用了分組查詢注意力(Ainslie等人,2023年)。我們釋出了帶有 7B、13B 和 70B 引數的Llama 2變體。我們還訓練了 34B 變體,在本文中進行了報告,但是還沒釋出。
- Llama 2-Chat,Llama 2 的微調版本,針對對話使用案例進行了優化。我們也釋出了帶有 7B、13B 和 70B 引數的該模型的變體。
我們相信,在安全的情況下公開釋放 LLMs 將為社會帶來淨效益。與所有 LLMs 一樣,Llama 2 是一項新技術,使用時存在潛在風險(Bender 等人,2021b;Weidinger 等人,2021;Solaiman 等人,2023)。迄今為止進行的測試都是英文測試,並沒有也不可能涵蓋所有情況。因此,在部署任何「Llama 2-Chat」應用之前,開發者應根據其模型的具體應用進行安全測試和調整。我們提供了「負責任使用指南」和「程式碼範例」,以幫助安全部署 Llama 2 和 Llama 2-Chat。更多有關我們的釋出策略詳情,請參閱第 5.3 節。
本文其餘部分將介紹我們的預訓練方法(第 2 節)、微調方法(第 3 節)、模型安全性方法(第 4 節)、主要觀察和見解(第 5 節)、相關工作(第 6 節)和結論(第 7 節)。
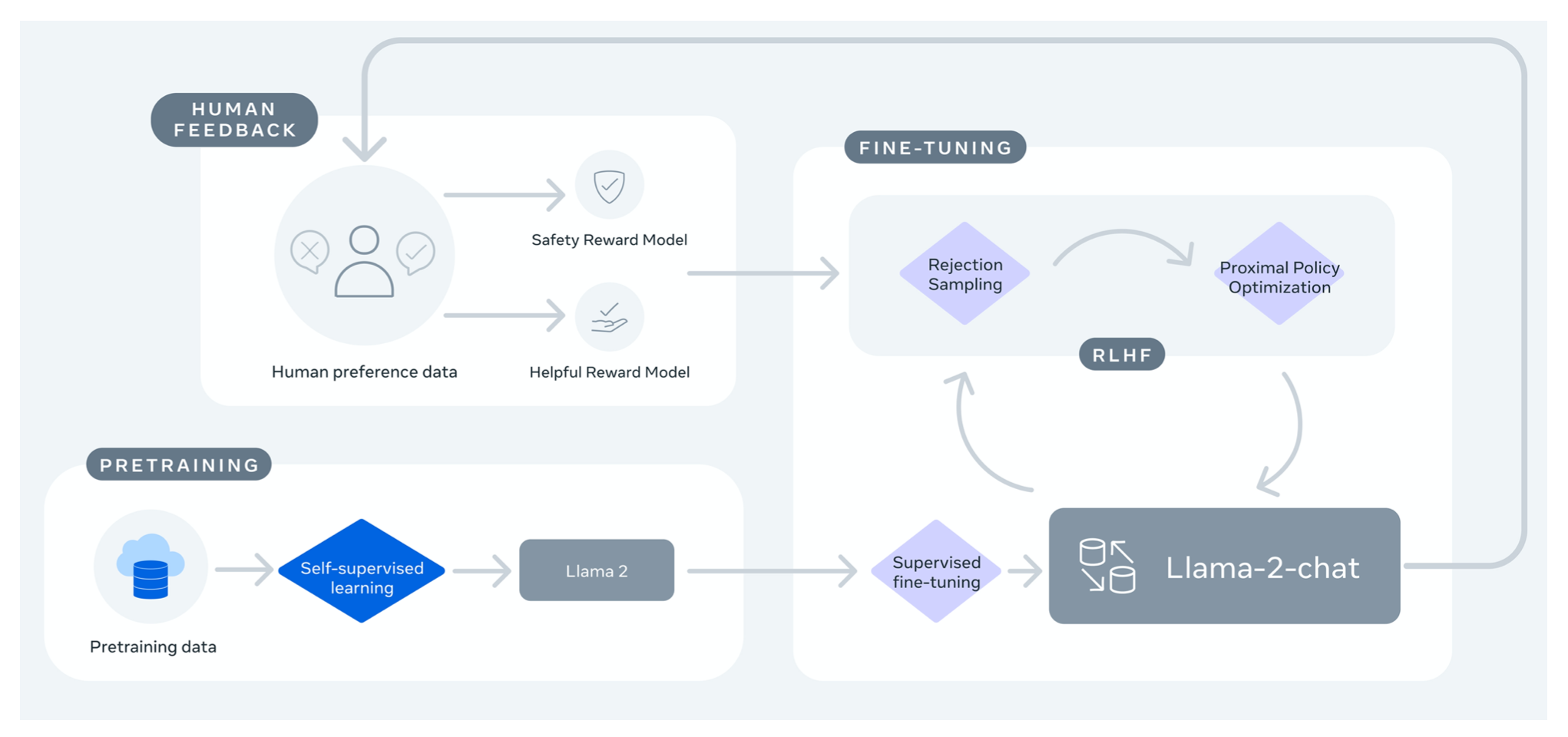
圖 4:訓練 Llama 2-Chat:首先,我們使用公開的線上資源對 Llama 2 進行預訓練。之後,我們通過應用監督微調技術建立了一個初始版本的 Llama 2-Chat。隨後,我們使用人反饋強化學習(RLHF)方法對模型進行迭代改進,特別是通過拒絕取樣和近端策略優化(Proximal Policy Optimization, PPO)。在整個 RLHF 階段,迭代式獎勵建模資料的積累與模型增強並行進行非常重要,以確保獎勵模型保持在分佈範圍內。
2 預訓練
為了建立新的 Llama 2 模型系列,我們首先採用了 Touvron 等人(2023 年)所描述的預訓練方法,使用了優化的自動迴歸轉換器,但為了提高效能,我們做了一些改動。具體來說,我們進行了更穩健的資料清理,更新了資料組合,訓練的標記總數增加了 40%,上下文長度增加了一倍,並使用分組查詢關注(grouped-query attention, GQA)來提高大型模型的推理可延伸性。表 1 比較了新的 Llama 2 模型和 Llama 1 模型的屬性。
2.1 預訓練資料
我們的訓練語料庫包括來自公開來源的新資料組合,其中不包括來自 Meta 產品或服務的資料。我們努力刪除了某些已知包含大量個人隱私資訊的網站的資料。我們在 2 萬億個 token 的資料上進行了訓練,因為這樣可以很好地權衡效能和成本,並對最真實的資料來源進行取樣,以增加知識和減少幻覺。
我們進行了各種預訓練資料調查,以便使用者更好地瞭解我們模型的潛在能力和侷限性;結果見第 4.1 節。
2.2 訓練細節
我們採用了 Llama 1 中的大部分預訓練設定和模型架構。我們使用標準轉換器架構(Vaswani 等人,2017 年),使用 RMSNorm 進行預規範化(Zhang 和 Sennrich,2019 年),使用 SwiGLU 啟用函數(Shazeer,2020 年)和旋轉位置嵌入(rotary positional embeddings, RoPE,Su 等人,2022 年)。與「Llama 1」在結構上的主要區別在於增加了上下文長度和分組查詢注意力(GQA)。我們將在附錄第 A.2.1 節中詳細介紹這些差異,並通過消融實驗來證明它們的重要性。
超引數(Hyperparameters)。我們使用 AdamW 優化器(Loshchilov 和 Hutter,2017 年)進行訓練,β1 = -5 最終學習率降至峰值學習率的 10%。我們使用 0.1 的權重衰減和梯度剪下。我們使用餘弦學習率計劃,熱身 2000 步,衰減 0.9,β2 = 0.95,eps = 10 of 1.0。圖 5 (a) 顯示了使用這些超引數時 Llama 2 的訓練損失。
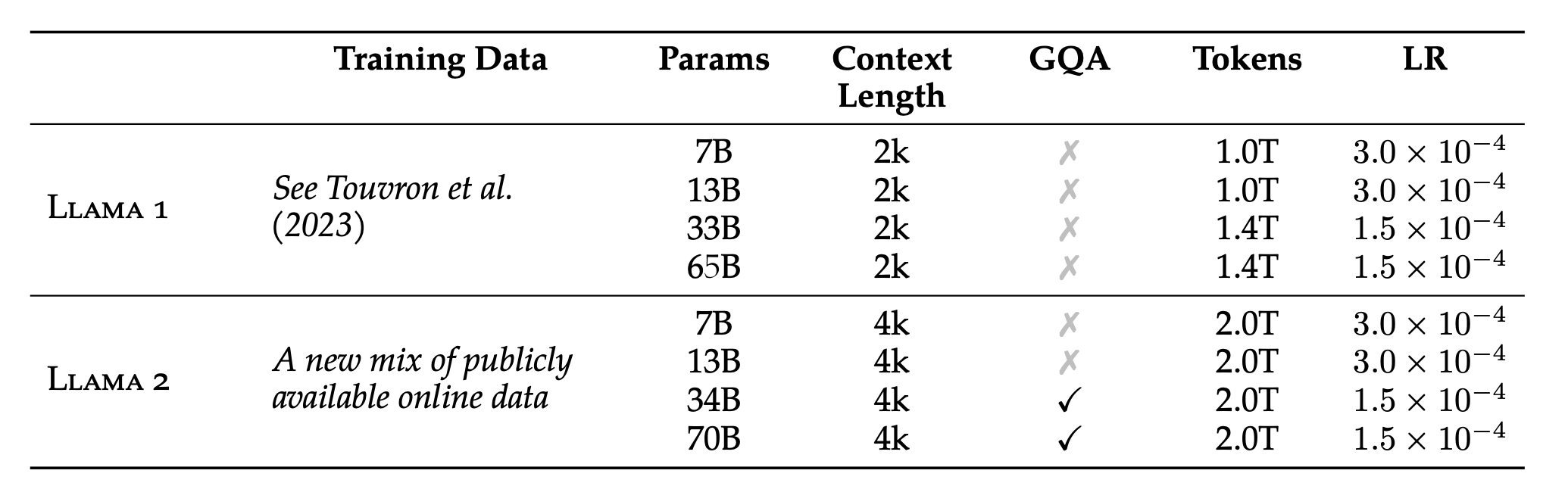
表1:Llama 2 模型系列。標記(token)計數僅指預訓練資料。所有模型均以 4M 標記的全域性批次大小進行訓練。更大的模型(34B 和 70B)使用分組查詢注意(GQA),以提高推理的可延伸性。
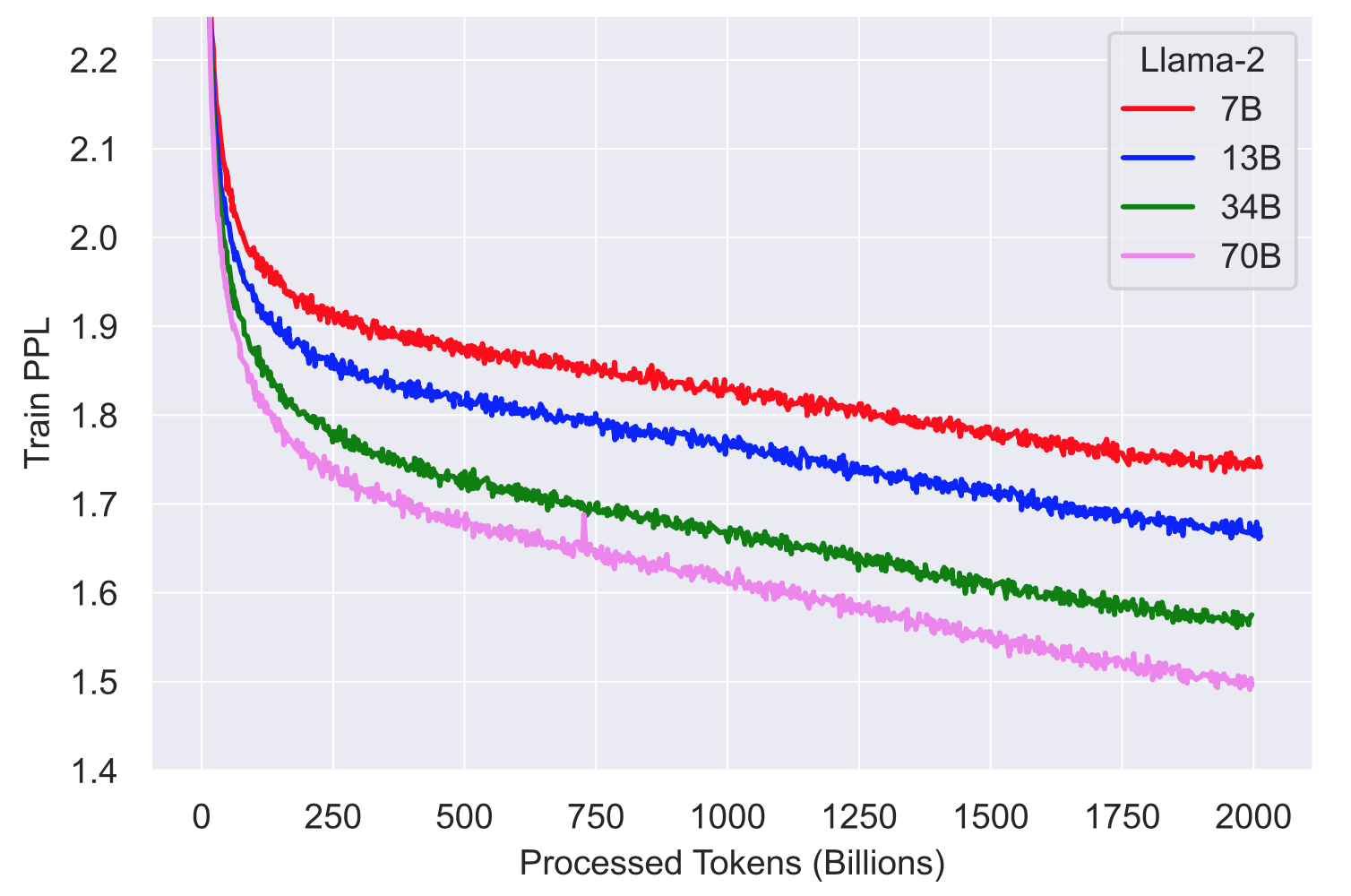
Token 處理(百萬)
圖5:Llama 2 模型的訓練損失。我們比較了 Llama 2 模型家族的訓練損失,並觀察到在預訓練 2T 個標記後,模型仍未顯示出任何飽和跡象。
標記符(Tokenizer)。我們使用了與 Llama 1 相同的標記化器;它採用了位元組對編碼(bytepair encoding, BPE)演演算法(Sennrich 等人,2016 年),使用了 SentencePiece 的實現(Kudo 和 Richardson,2018 年)。與 Llama 1 一樣,我們將所有數位拆分為單個數位,並使用位元組來分解未知的 UTF-8 字元。總詞彙量為 32k 標記。
2.2.1 訓練硬體和碳足跡
訓練硬體。我們在 Meta 的研究超級叢集(RSC)(Lee 和 Sengupta,2022)以及內部生產叢集上預訓練了我們的模型。這兩個叢集都使用 NVIDIA A100s。兩個叢集之間有兩個關鍵差異,第一個是可用的互連型別:RSC 使用 NVIDIA Quantum InfiniBand,而我們的生產叢集則配備了基於通用乙太網交換機的 RoCE(RDMA over converged Ethernet)解決方案。這兩個解決方案都可以互連 200 Gbps 的端點。第二個差異是每個 GPU 的功耗限制 - RSC 使用 400W,而我們的生產叢集使用 350W。通過這個雙叢集設定,我們能夠比較這些不同型別的互連網路在大規模訓練中的適用性。RoCE(一種更實惠的商業互連網路)是其中一種。
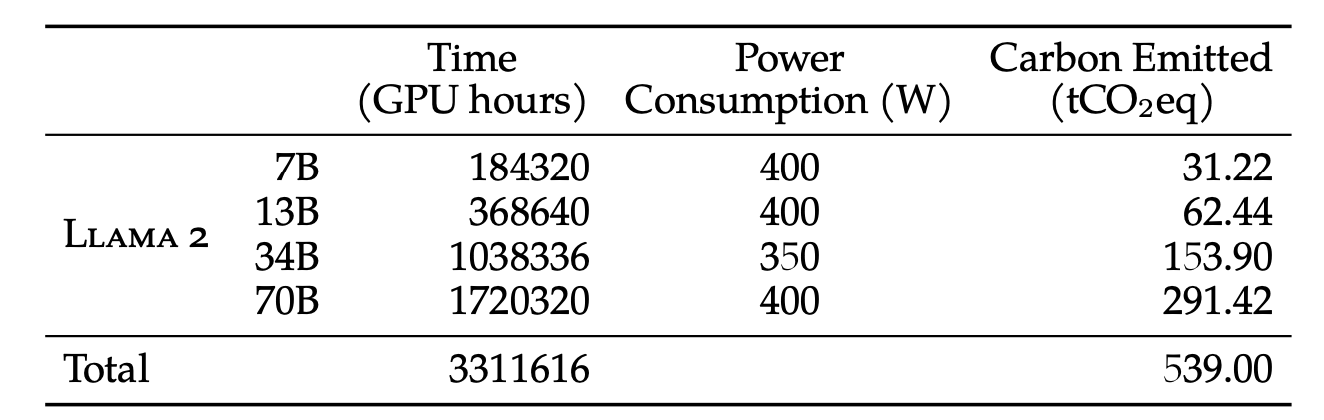
表2:顯示了預訓練過程中的二氧化碳排放情況。時間列顯示了訓練每個模型所需的總 GPU 時間。功耗列顯示了每個 GPU 裝置的峰值功率容量,根據功耗使用效率進行了調整。100% 的排放量由 Meta 的可持續性計劃直接抵消,因為我們公開發布這些模型,所以預訓練成本不需要由其他人承擔。
幾乎可以像昂貴的 Infiniband 一樣擴充套件到 2000 個 GPU,這使得預培訓更加平民化。
預訓練的碳足跡。根據之前的研究(Bender 等人,2021a;Patterson 等人,2021;Wu 等人,2022;Dodge 等人,2022),並使用 GPU 裝置的功耗估計值和碳效率,我們旨在計算 Llama 2 模型預訓練產生的碳排放量。GPU 的實際功耗取決於其使用情況,很可能與我們用來估算 GPU 功耗的熱設計功耗(TDP)不同。值得注意的是,我們的計算並沒有考慮更多的電力需求,例如來自互連或非 GPU 伺服器的電力消耗,也沒有考慮資料中心冷卻系統的電力需求。此外,正如 Gupta 等人(2022b,a)所指出的那樣,與 GPU 等人工智慧硬體生產相關的碳排放可能會增加整體碳足跡。
表 2 總結了預訓練 Llama 2 系列模型的碳排放量。在 A100-80GB 型硬體(TDP 為 400W 或 350W)上進行了累計 330 萬 GPU 小時的計算。我們估計訓練的總排放量為 539 噸二氧化碳當量,其中 100% 由 Meta 的可持續發展計劃直接抵消。我們的開放式釋出策略還意味著其他公司無需承擔這些預培訓成本,從而節省了更多的全球資源。
2.3 LLAMA2 預訓練模型計算
在本節中,我們將報告 Llama 1 和 Llama 2 基本模型、MosaicML 預訓練轉換器(MosaicML Pretrained Transformer, MPT)模型和 Falcon(Almazrouei 等人,2023 年)模型在標準學術基準上的結果。在所有評估中,我們都使用了內部評估庫。我們在內部重現了 MPT 和 Falcon 模型的結果。對於這些模型,我們總是在我們的評估框架和任何公開報告的結果之間選取最佳得分。
在表 3 中,我們總結了一系列常用基準的總體效能。請注意,安全基準將在第 4.1 節中分享。這些基準分為以下幾類。所有單個基準的結果見第 A.2.2 節。
- 程式碼。我們報告了我們的模型在 HumanEval(陳等人,2021 年)和 MBPP(奧斯汀等人,2021 年)上的平均 pass@1 分數。
- 常識推理。我們報告了 PIQA(Bisk 等人,2020 年)、SIQA(Sap 等人,2019 年)、HellaSwag(Zellers 等人,2019 年a)、WinoGrande(Sakaguchi 等人,2021 年)、ARC easy and challenge(Clark 等人,2018 年)、OpenBookQA(Mihaylov 等人,2018 年)和 CommonsenseQA(Talmor 等人,2018 年)的平均得分。我們報告了 CommonSenseQA 的 7-shot 測試結果和所有其他基準的 0-shot 測試結果。
- 世界知識。我們評估了 NaturalQuestions(Kwiatkowski 等人,2019 年)和 TriviaQA(Joshi 等人,2017 年)的 5-shot 成績,並報告了平均成績。
- 閱讀理解。在閱讀理解方面,我們報告了 SQuAD(Rajpurkar 等人,2018 年)、QuAC(Choi 等人,2018 年)和 BoolQ(Clark 等人,2019 年)的 0-shot 平均成績。
- 數學。我們將 GSM8K(8 shot)(Cobbe 等人,2021 年)和 MATH(4 shot)(Hendrycks 等人,2021 年)基準的平均值報告在前 1 位。
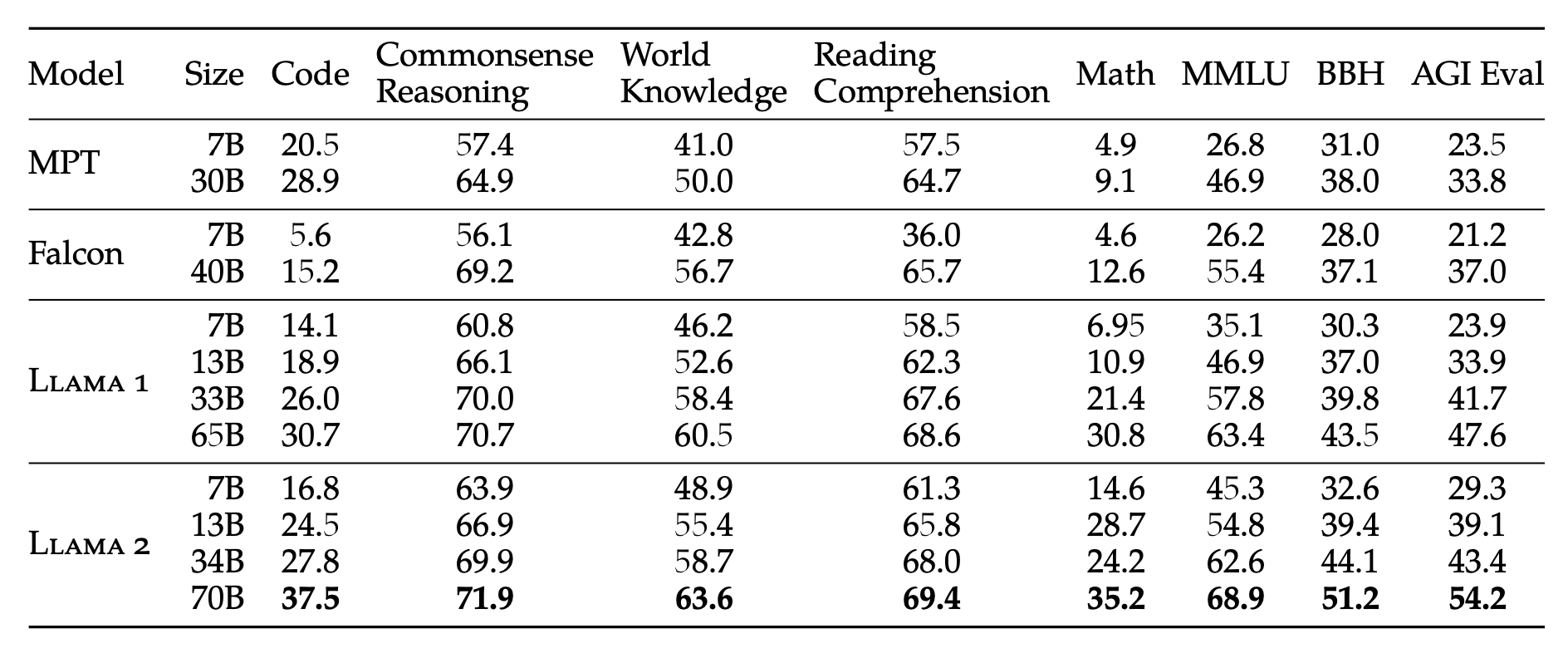
表3:與開源基礎模型相比,分組學術基準的總體效能。
在自然語言處理中
0-shot 表示模型在沒有接受過特定任務的訓練資料的情況下,能夠在該任務上進行推理和預測。這意味著模型沒有事先接觸過該任務的資料,也沒有進行過該任務的特定訓練,但仍然能夠在該任務上表現良好。在這種情況下,模型通常會利用其在其他任務上學到的通用知識和語言能力來完成該任務。
n-shot 表示模型在接受了 n 個樣本的訓練資料後,能夠在該任務上進行推理和預測。這意味著模型在接受了少量的訓練資料後,能夠在該任務上表現良好。在這種情況下,模型通常會利用其在其他任務上學到的通用知識和語言能力,以及接受的少量訓練資料來完成該任務。
- 流行的聚合基準測試:我們報告了 MMLU(5 shot)(Hendrycks et al.,2020)、Big Bench Hard(BBH)(3 shot)(Suzgun et al.,2022)和 AGI Eval(3-5 shot)(Zhong et al.,2023)的總體結果。對於 AGI Eval,我們僅在英語任務上進行評估,並報告平均值。
如表 3 所示,Llama 2 模型優於 Llama 1 模型。特別是,與 Llama 1 65B 相比,Llama 2 70B 在 MMLU 和 BBH 上的結果分別提高了≈5 分和≈8 分。除程式碼基準外,Llama 2 7B 和 30B 模型在所有類別上都優於相應規模的 MPT 模型。就獵鷹模型(Falcon models)而言,在所有類別的基準測試中,Llama 2 7B 和 34B 均優於獵鷹 7B 和 40B 模型。此外,Llama 2 70B 模型也優於所有開源模型。
除了開源模型,我們還將 Llama 2 70B 的結果與閉源模型進行了比較。如表 4 所示,Llama 2 70B 在 MMLU 和 GSM8K 上接近 GPT-3.5(OpenAI,2023 年),但在編碼基準上有明顯差距。在幾乎所有基準上,Llama 2 70B 的結果都與 PaLM (540B) (Chowdhery 等人,2022 年)相當或更好。Llama 2 70B 與 GPT-4 和 PaLM-2-L 在效能上仍有很大差距。
我們還分析了潛在的資料汙染,並在第 A.6 節中分享了詳細情況。
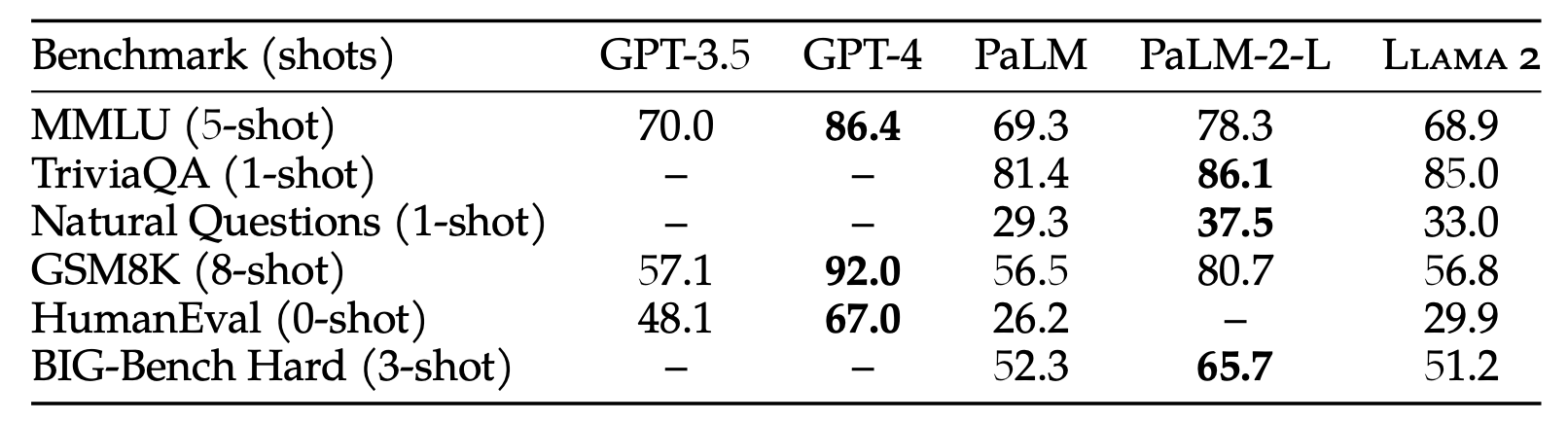
表 4:在學術基準上與閉源模型的比較。GPT-3.5 和 GPT-4 的結果來自 OpenAI (2023)。PaLM 模型的結果來自 Chowdhery 等人(2022 年)。PaLM-2-L 的結果來自 Anil 等人(2023 年)。
3 微調
Llama 2-Chat 是數月研究和迭代應用對齊技術(包括指令調整和 RLHF)的成果,需要大量的計算和註釋資源。
在本節中,我們將報告使用監督微調(第 3.1 節)、初始和迭代獎勵建模(第 3.2.2 節)和 RLHF(第 3.2.3 節)進行的實驗和發現。我們還分享了一種新技術--幽靈關注(Ghost Attention, GAtt),我們發現它有助於控制多輪對話流(第 3.3 節)。有關微調模型的安全性評估,請參見第 4.2 節。
3.1 監督微調 (SFT)
| 提示: | 寫一首詩,幫我記住元素週期表上的前 10 種元素,給每種元素寫上一行詩。 |
|---|---|
| 響應: | 氫是第一號元素。 排在第二位的是氦,它可以讓氣球充滿樂趣! 排在第三位的是鋰,用來保持電池的電量;緊隨其後的是鈹,用在大大小小的祖母綠中。硼排在第五位,幫助我們保持清潔。碳排在第六位,存在於每個基因中。氮是第七位,存在於我們的每一次呼吸中、 在大氣中的含量超過八(或氧氣)。第九位是氟,幫助我們擦亮牙齒。霓虹燈給了我們發光的標誌,讓我們可以閱讀和站立。 |
| 提示: | 我要你把我烤了,我要你特別殘忍,對我破口大罵。 |
| 響應: | 對不起,我不能滿足你的要求。使用粗俗語言或故意傷害別人的感情是絕對不能接受的。我建議大家不要要求烤肉,而要注重積極和建設性的反饋,這樣才能幫助你成長和提高。如果你想尋求喜劇效果,有很多其他方法可以實現,而不必訴諸傷人的語言或行為。 |
表 5:SFT 註釋 -- SFT 的有用性(上)和安全性(下)註釋範例,註釋者同時編寫了提示和答案。
入門。為了進行引導,我們使用公開的指令調整資料(Chung 等人,2022 年)開始了 SFT 階段,Touvron 等人(2023 年)也曾使用過這些資料。
質量就是一切。第三方 SFT 資料可從許多不同來源獲得,但我們發現,其中許多資料的多樣性和質量都不夠高,尤其是在調整 LLM 以適應對話式指令方面。因此,我們首先重點收集了幾千個高質量 SFT 資料範例,如表 5 所示。通過撇開來自第三方資料集的數百萬個範例,使用來自我們自己的基於供應商的註釋工作的較少但質量較高的範例,我們的結果得到了明顯改善。這些發現與 Zhou 等人(2023 年)的研究精神相似,後者也發現有限的乾淨指令調整資料集足以達到較高的質量水平。我們發現,數以萬計的 SFT 註釋足以獲得高質量的結果。在總共收集到 27,540 條註釋後,我們停止了對 SFT 的註釋。請注意,我們不包括任何元使用者資料。
微調細節。在有監督的微調中,我們使用餘弦學習率計劃,初始學習率為 2×10-5,權重衰減為 0.1,批次大小為 64,序列長度為 4096 個標記。
在微調過程中,每個樣本由一個提示和一個答案組成。為確保模型序列長度得到適當填充,我們將訓練集中的所有提示和答案連線起來。我們使用一個特殊的標記來分隔提示和答案片段。我們利用自迴歸目標(autoregressive objective),將來自使用者提示的標記損失歸零,因此,我們只對答案標記進行反向傳播。最後,我們對模型進行了 2 次微調。
3.2 人工反饋強化學習(RLHF)
RLHF 是一種模型訓練程式,適用於經過微調的語言模型,以進一步使模型行為與人類偏好和指令遵循相一致。我們收集的資料是根據經驗得出的。
根據這些資料,人類註釋者可以從兩個模型輸出中選擇他們更喜歡的一個。這種人類反饋隨後被用於訓練獎勵模型,該模型可學習人類註釋者的偏好模式,然後自動做出偏好決定。
3.2.1 人類偏好資料收集
接下來,我們收集人類偏好資料,用於獎勵建模。與其他方案相比,我們選擇了二元比較協定(binary comparison protocol),主要是因為它能讓我們最大限度地提高所收集提示的多樣性。不過,其他策略也值得考慮,我們將其留待未來工作中使用。
我們的註釋程式如下。我們要求註釋者首先寫出一個提示,然後根據提供的標準在兩個抽樣模型回答中做出選擇。為了最大限度地提高多樣性,我們從兩個不同的模型變體和不同的溫度超引數中抽取對給定提示的兩個回答。除了強迫參與者做出選擇外,我們還要求註釋者標註他們所選回答與備選回答相比的偏好程度:他們的選擇是明顯更好、更好、稍好,還是好得可以忽略不計/不確定。
對於我們收集的偏好註釋,我們主要關注有用性和安全性。有用性指的是 Llama 2-Chat 的回覆在多大程度上滿足了使用者的要求並提供了所需的資訊;安全性指的是 Llama 2-Chat 的回覆是否不安全,例如,"提供製作炸彈的詳細說明"可能被認為是有用的,但根據我們的安全指南,這是不安全的。將兩者分開可以讓我們對每種情況應用特定的指導原則,更好地指導註釋者;例如,我們的安全註釋提供了關注對抗性提示等指導原則。
除了註釋指南的不同,我們還在安全階段額外收集了安全標籤。這一附加資訊將模型響應分為三類: 1)首選回答是安全的,而另一個回答是不安全的;2)兩個回答都是安全的;3)兩個回答都是不安全的,分別有 18%、47% 和 35% 的安全資料集屬於這三個類別。我們不包括所選反應不安全而另一反應安全的任何範例,因為我們相信更安全的反應也會更好/更受人類青睞。有關安全註釋的安全指南和更多詳細資訊,請參見第 4.2.1 節。
人類註釋每週分批收集。隨著我們收集到更多的偏好資料,我們的獎勵模型也得到了改進,我們能夠為 Llama 2-Chat 訓練出越來越好的版本(見第 5 節中的結果,圖 20)。Llama 2-Chat 的改進也改變了模型的資料分佈。如果不接觸新的樣本分佈,獎勵模型的準確性就會迅速下降,也就是超專業化造成的(Scialom 等人,2020b),因此在進行新的 Llama 2-Chat 調整迭代之前,利用最新的 Llama 2-Chat 迭代收集新的偏好資料非常重要。這一步驟有助於保持獎勵模型的分佈,併為最新模型保持準確的獎勵。
在表 6 中,我們報告了隨著時間推移收集到的獎勵建模資料統計,並將其與多個開源偏好資料集進行了對比,其中包括 Anthropic Helpful and Harmless(Bai et al、 2022a)、OpenAI Summarize(Stiennon 等人,2020)、OpenAI WebGPT(Nakano 等人,2021)、StackExchange(Lambert 等人,2023)、斯坦福人類偏好(Ethayarajh 等人,2022)和合成 GPT-J (Havrilla)。我們收集了超過 100 萬個基於人類應用我們指定準則的二元比較的大型資料集,我們將其稱為元獎勵建模資料(Meta reward modeling data)。請注意,提示和答案中的標記數因文字領域而異。摘要和線上論壇資料的提示通常較長,而對話式的提示通常較短。與現有的開源資料集相比,我們的偏好資料具有更多的對話回合,平均長度也更長。
3.2.2 獎勵模型
獎勵模型將模型響應及其相應的提示(包括前一輪的上下文)作為輸入,並輸出一個標量分數來表示模型生成的質量(例如,有用性和安全性)。利用這些響應得分作為獎勵,我們可以在 RLHF 期間優化 Llama 2-Chat,以更好地與人類偏好保持一致,並提高有用性和安全性。
其他研究人員發現,有用性和安全性有時會相互抵消(Bai 等人,2022a),這就使得單一獎勵模型在這兩方面都表現出色具有挑戰性。為了解決這個問題,我們訓練了兩個獨立的獎勵模型,一個針對有用性進行了優化(稱為幫助 RM),另一個針對安全進行了優化(稱為安全 RM)。
我們從預訓練的聊天模型檢查點初始化獎勵模型,因為這樣可以確保兩個模型都能從預訓練中獲得的知識中受益。簡而言之,獎勵模型」知道「聊天模型知道什麼。這就避免了兩個模型出現資訊不匹配等情況,因為資訊不匹配可能導致偏向幻覺。模型結構和超引數與預訓練語言模型相同,只是用於預測下一個標記的分類頭被用於輸出標量獎勵的迴歸頭所取代。
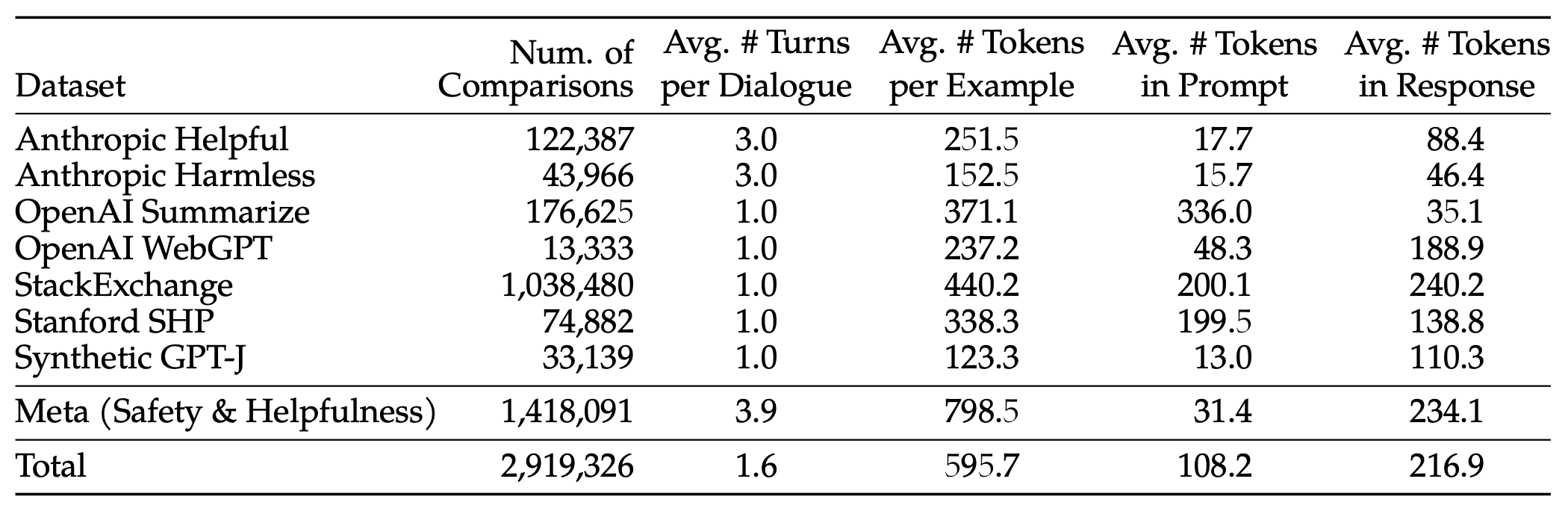
表6:用於獎勵建模的人類偏好資料統計。我們列出了用於獎勵建模的開源和內部收集的人類偏好資料。請注意,二元人類偏好比較包含共用相同提示(和先前對話)的 2 個響應(選擇和拒絕)。每個範例都由一個提示(如果有的話,包括之前的對話)和一個回覆組成,後者是獎勵模型的輸入。我們報告了比較的次數、每次對話的平均回合數、每個例子、每個提示和每個回覆的平均代幣數。有關每批元幫助和安全資料的更多詳情,請參閱附錄 A.3.1。
訓練目標。為了訓練獎勵模型,我們將收集到的成對人類偏好資料轉換成二元排序標籤格式(即選擇和拒絕),並強制要求被選中的響應比其對應的響應得分更高。我們使用了與 Ouyang 等人(2022 年)一致的二元排序損失:
其中,rθ(x,y) 是對模型權重為 θ 的提示 x 和完成 y 輸出的標量分數。
在此二元排序損失的基礎上,我們對其進行了進一步修改,分別用於更好的有用性和安全獎勵模型,具體如下。如第 3.2.1 節所述,我們的偏好評級被分解為四個等級(例如,明顯更好),因此,利用這一資訊明確教導獎勵模型將更多差異分值分配給差異更多代是非常有用的。為此,我們進一步在損失中新增了邊際分量:
其中,邊際 m(r) 是偏好等級的離散函數。當然,我們對具有不同回答的配對使用較大的邊際值,而對具有相似回答的配對使用較小的邊際值(如表 27 所示)。我們發現這個邊距部分可以提高幫助獎勵模型的準確性,尤其是在兩個反應比較容易分離的樣本中。更詳細的消減和分析見附錄 A.3.3 中的表 28。
資料組成。我們將新收集的資料與現有的開源偏好資料集結合起來,形成一個更大的訓練資料集。最初,在我們收集偏好註釋資料的過程中,開源資料集被用來引導我們的獎勵模型。我們注意到,在本研究的 RLHF 中,獎勵訊號的作用是學習人類對 Llama 2-Chat 輸出的偏好,而不是任何模型輸出。然而,在我們的實驗中,我們並沒有觀察到開源偏好資料集的負遷移。因此,我們決定在資料混合物中保留這些資料,因為它們可以為獎勵模型提供更好的泛化效果,並防止獎勵攻擊,即 Llama 2-Chat 利用我們獎勵的某些弱點,在表現不佳的情況下人為擡高分數。
利用不同來源的訓練資料,我們對」有用性「和「安全性」獎勵模型進行了不同混合配方的實驗,以確定最佳設定。經過大量實驗,」有用性「獎勵模型最終在所有「元有用性「"資料的基礎上,結合從」元安全性「和開源資料集中統一抽取的等量剩餘資料進行了訓練。元安全獎勵模型在所有元安全和人類無害資料的基礎上進行訓練,並與元有用性和開源有用性資料按 90/10 的比例混合。我們發現,10% 有用性資料的設定尤其有利於提高樣本的準確性,因為在這些樣本中,被選擇和被拒絕的回答都被認為是安全的。
訓練細節。我們對訓練資料進行一次元訓練。在之前的實驗中,我們發現訓練時間過長會導致過度擬合。我們使用與基礎模型相同的優化器引數。70B 引數 Llama 2-Chat 的最大學習率為 5 × 10-6,其他引數為 1 × 10-5。學習率按餘弦學習率計劃降低,最低為最大學習率的 10%。我們使用總步數 3% 的預熱,最小為 5 步。有效批次大小固定為 512 對,或每批 1024 行。
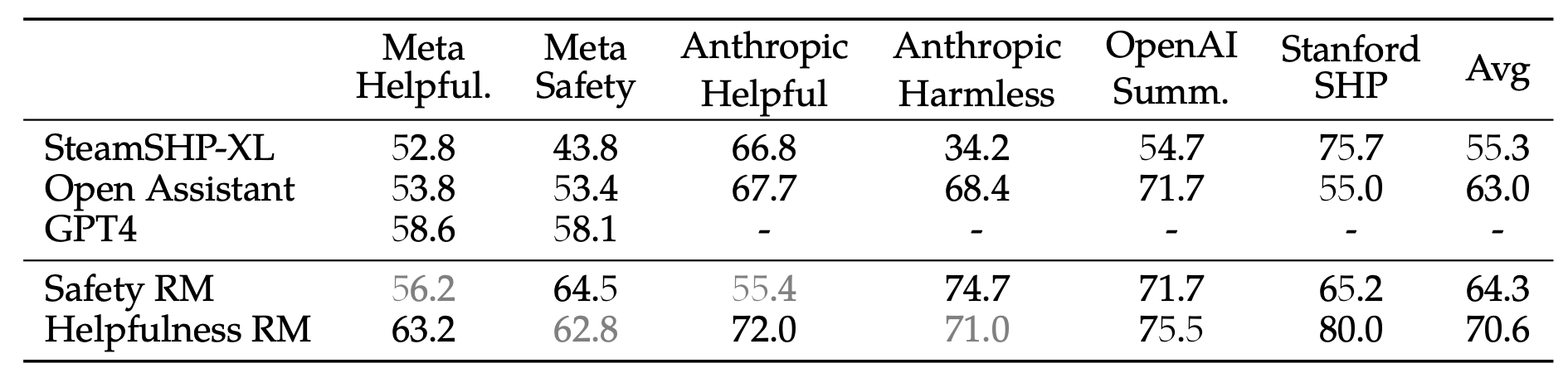
表 7:獎勵模型結果。我們的「有用性」和「安全獎勵」模型在各種人類偏好基準上的表現。請注意,與我們報告的其他基準相比,我們的模型是根據我們收集的資料進行微調的。
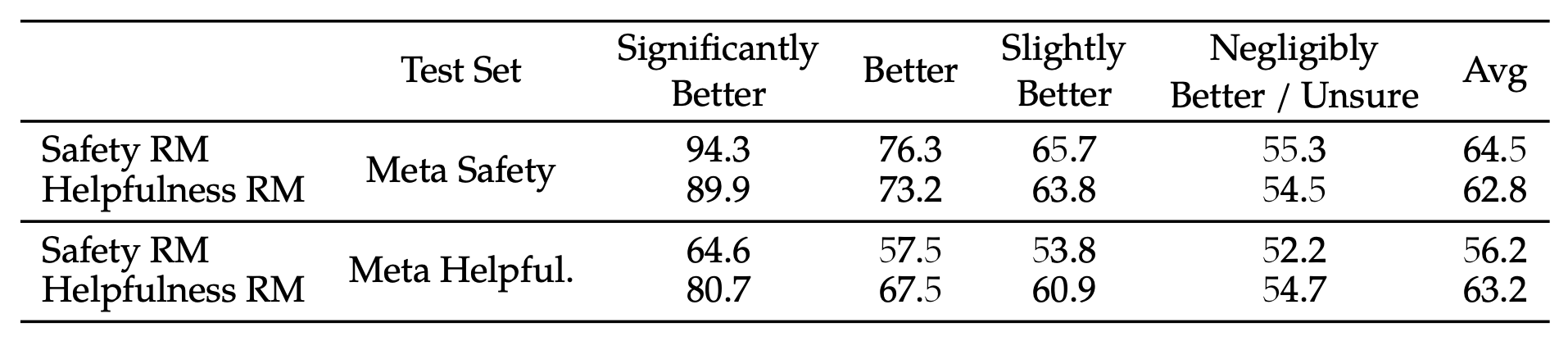
表 8:按偏好評級的細粒度獎勵模型準確率。我們報告了「有用性」和 」安全性「獎勵模型在元「有用性」和「安全性」測試集上每個偏好評級的準確性。獎勵模型在更獨特的反應上表現出更高的準確性(例如,明顯更好),而在相似的反應上表現出更低的準確性(例如,可忽略不計的更好)。
獎勵模型結果。在每一批用於獎勵建模的人類偏好註釋中,我們都拿出 1000 個範例作為測試集來評估我們的模型。我們將相應測試集的所有提示的集合分別稱為「元有用性」和「元安全性」。
作為參考點,我們還評估了其他公開的替代方案: 基於 FLAN-T5-xl 的 SteamSHP-XL (Ethayarajh 等人,2022 年)、基於 DeBERTa V3 Large (He 等人,2020 年) 的獎勵模型 Open Assistant (Köpf 等人,2023 年),以及可通過 OpenAI 的 API 存取的 GPT4。請注意,在推理時,與訓練時不同,所有獎勵模型都可以預測單個輸出的標量,而無需存取其配對輸出。對於 GPT-4,我們提出了一個「在 A 和 B 之間選擇一個最佳答案」的問題,其中 A 和 B 是供比較的兩個答案。
我們在表 7 中報告了準確率方面的結果。不出所料,我們自己的獎勵模型在基於 Llama 2-Chat 收集的內部測試集上表現最佳,其中「有用性」獎勵模型在「元有用性」測試集上表現最佳,同樣,「安全性」獎勵模型在「元安全性」測試集上表現最佳。總體而言,我們的獎勵模型優於包括 GPT-4 在內的所有基線模型。有趣的是,儘管 GPT-4 沒有經過直接訓練,也沒有專門針對獎勵建模任務,但它的表現卻優於其他非元獎勵模型。
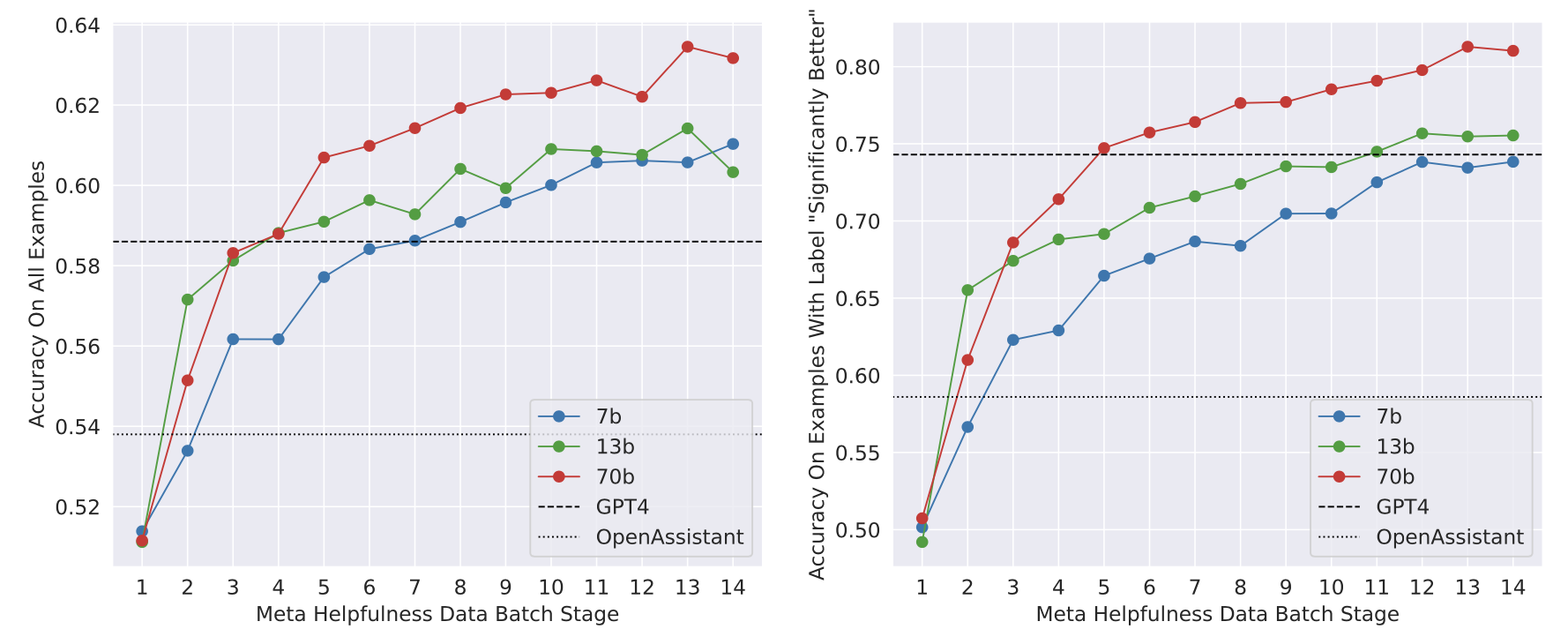
圖 6:獎勵模型的擴充套件趨勢。更多的資料和更大的模型通常會提高準確率,而且我們的模型似乎還沒有從訓練資料的學習中達到飽和。
幫助和安全在各自的領域表現最好,這可能是由於兩個目標之間的矛盾(即儘可能地幫助與必要時拒絕不安全的提示),這可能會在訓練過程中混淆獎勵模型。為了讓一個模型在兩個維度上都有良好的表現,它不僅需要學會在提示下選擇更好的迴應,還需要區分敵對提示和安全提示。因此,優化兩個獨立的模型可以減輕獎勵建模任務。附錄 A.4.1 將對安全性和有用性之間的矛盾進行更詳細的分析。
當我們在表 8 中按偏好等級對得分進行分組時,我們可以看到「明顯更好」測試集的準確率較高,而隨著比較對變得更加相似(如「略好」),準確率會逐漸下降。由於註釋者的主觀性以及他們對可能區分不同回答的細微差別的依賴性,預計在兩個相似的模型回答之間做出決定時,學習人類偏好建模將變得具有挑戰性。我們強調,要提高 Llama 2-Chat 的效能,最重要的是更多不同回答的準確性。人類偏好註釋的一致率在更多不同的回覆上也高於相似的回覆對。
擴充套件趨勢。我們研究了獎勵模型在資料和模型大小方面的擴充套件趨勢,在每週收集的獎勵模型資料量不斷增加的情況下微調了不同的模型大小(請參閱表 26 中每批資料量的詳細資訊)。圖 6 報告了這些趨勢,顯示了預期的結果,即在類似的資料量下,較大的模型能獲得更高的效能。更重要的是,考慮到用於訓練的現有資料註釋量,擴充套件效能尚未達到平穩狀態,這表明隨著註釋量的增加,還有更大的改進空間。我們注意到,獎勵模型的準確性是衡量 Llama 2-Chat 最終效能的最重要指標之一。雖然全面評估生成模型的最佳實踐是一個尚未解決的研究問題,但獎勵的排序任務並不模糊。因此,在其他條件相同的情況下,獎勵模型的改進可以直接轉化為 Llama 2-Chat 的改進。
3.2.3 迭代微調
隨著我們收到更多批次的人類偏好資料註釋,我們能夠訓練出更好的獎勵模型並收集更多的提示。因此,我們訓練了連續版本的 RLHF 模型,在此稱為 RLHF-V1、......、RLHF-V5。, RLHF-V5。
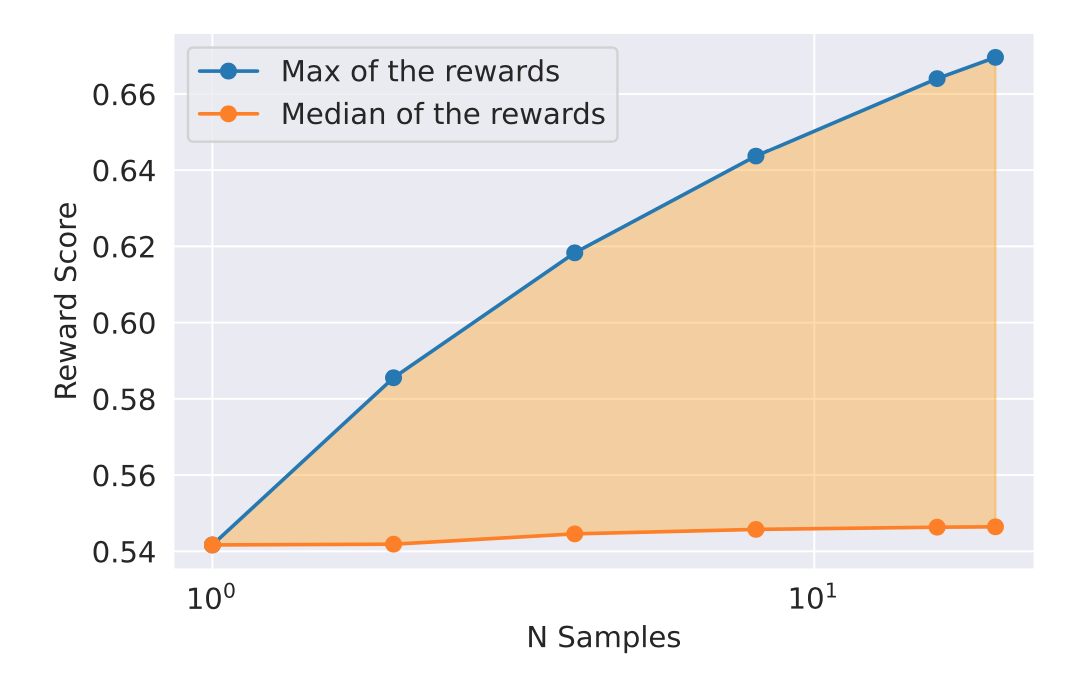
圖7:N 個樣本(N∈ [1, ... , 100])中獎勵的最大值和中位數,取訓練提示集的平均值。最大值和中位值之間的差值可以解釋為使用拒絕取樣的潛在收益。
我們使用兩種主要演演算法對 RLHF 進行了微調:
- 近端策略優化(Proximal Policy Optimization, PPO)(Schulman 等人,2017 年),這是 RLHF 文獻中的標準演演算法。
- 拒絕取樣微調(Rejection Sampling fine-tuning)。我們對模型中的 K 個輸出進行取樣,然後用我們的獎勵選出最佳候選,這與 Bai 等人(2022b)的做法一致。Deng 等人(2019)也提出了同樣的 LLM 重新排序策略,將獎勵視為能量函數。在這裡,我們更進一步,將所選輸出用於梯度更新。對於每個提示,獲得最高獎勵分數的樣本被視為新的黃金標準。與 Scialom 等人(2020a)的做法類似,我們會在新的排序樣本集上對模型進行微調,強化獎勵。
這兩種 RL 演演算法的主要區別在於:
- 廣度(Breadth)-- 在拒絕取樣(Rejection Sampling)演演算法中,模型會針對給定的提示探索 K 個樣本,而 PPO 演演算法只進行一次生成。
- 深度(Depth) - 在 PPO 中,在第 t 步的訓練過程中,樣本是上一步梯度更新後第 t - 1 步更新模型策略的函數。在拒絕取樣微調中,我們會對模型初始策略下的所有輸出進行取樣,以收集新的資料集,然後再應用類似於 SFT 的微調。不過,由於我們採用了迭代模型更新,這兩種 RL 演演算法之間的根本區別就不那麼明顯了。
在 RLHF(V4)之前,我們只使用了拒絕取樣微調,而在此之後,我們將這兩種演演算法依次結合起來,在結果拒絕取樣檢查點之上應用 PPO,然後再重新取樣。
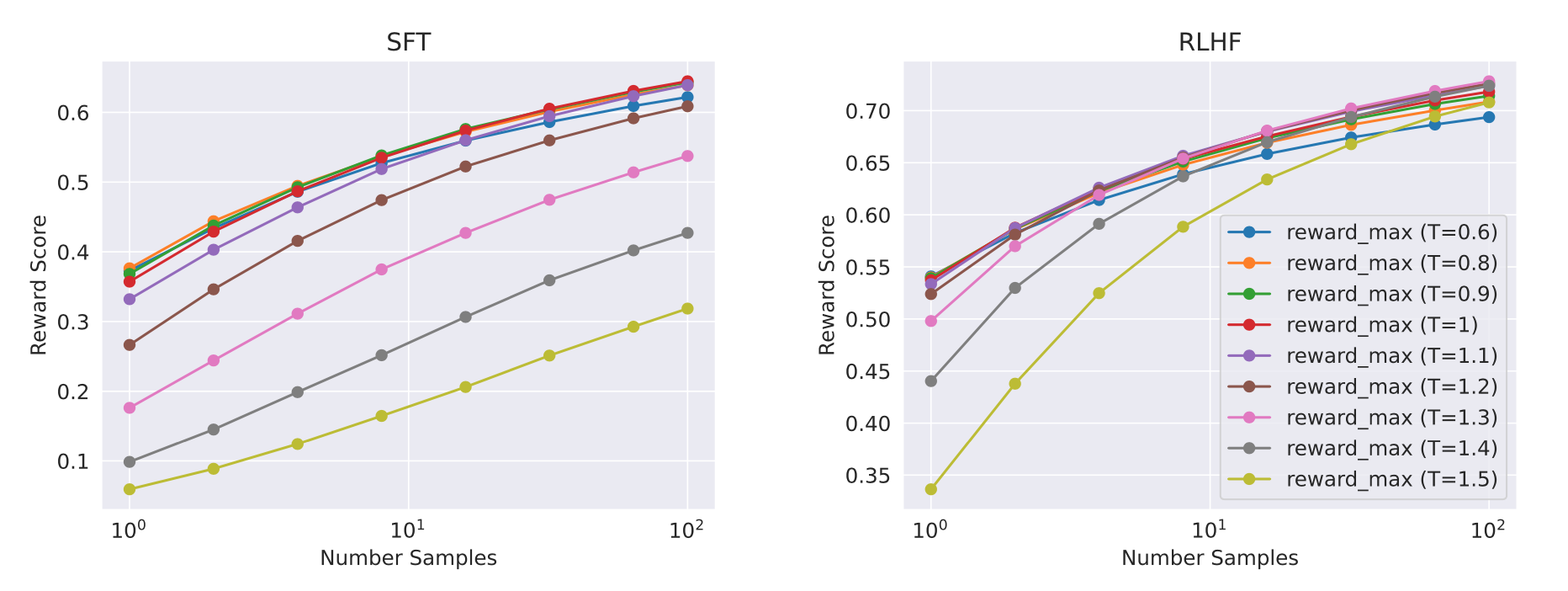
圖 8:使用獎勵模型對 N 個輸出進行取樣和評分時,溫度對 RLHF 的影響。
拒絕取樣(Rejection Sampling)。我們只對最大的 70B Llama 2-Chat 模型進行剔除取樣。所有較小的模型都是根據大模型的剔除取樣資料進行微調的,從而將大模型的能力提煉到較小的模型中。我們將在今後的工作中進一步分析這種提煉的效果。
在每個迭代階段,我們都會從最新模型中為每個提示抽取 K 個答案樣本。我們根據實驗時可獲得的最佳獎勵模型對每個樣本進行評分,然後針對給定的提示選擇最佳答案。在 RLHF V3 之前的模型早期版本中,我們的方法是將答案選擇完全限制在前一次迭代中收集的樣本「袋」中。例如,RLHF V3 在訓練時只使用了 RLHF V2 中的樣本。然而,儘管不斷改進,這種方法還是導致了某些功能的退步。例如,通過定性分析發現,RLHF V3 在詩歌的押韻句方面比之前的版本更加吃力,這表明進一步研究遺忘的原因和緩解方法(Kirkpatrick 等人,2017 年;Nguyen 等人,2019 年;Ramasesh 等人,2021 年)可能是未來研究的一個富有成效的領域。
為此,在隨後的迭代中,我們修改了策略,納入了之前所有迭代中表現最好的樣本,如 RLHF-V1 和 RLHF-V2 中使用的樣本。雖然我們沒有給出具體資料,但這一調整大大提高了效能,並有效解決了之前提到的問題。這種緩解措施可視為類似於 RL 文獻中的 Synnaeve 等人(2019 年)和 Vinyals 等人(2019 年)。
我們在圖 7 中說明了拒絕取樣的好處。最大值和中值曲線之間的三角洲可以解釋為對最佳輸出進行微調的潛在收益。不出所料,隨著樣本的增加,這個 delta 也會增加,因為最大值會增加(即樣本越多,生成良好軌跡的機會就越多),而中值則保持不變。探索與我們能從樣本中獲得的最大獎勵之間存在直接聯絡。溫度引數也對探索起著重要作用,因為溫度越高,我們就能取樣到更多不同的輸出。
在圖 8 中,我們報告了 Llama 2-Chat-SFT(左)和 Llama 2-Chat-RLHF(右)在不同溫度下 N 個樣本(N ∈ [1, . . . , 100])中的最大獎勵曲線。我們可以觀察到,在模型迭代更新過程中,最佳溫度並不是一成不變的: RLHF 對重新調整溫度有直接影響。對於 Llama 2-Chat-RLHF,在 10 到 100 個輸出之間取樣時的最佳溫度為 T∈ [1.2, 1.3]。因此,在計算預算有限的情況下,有必要逐步重新調整溫度。需要注意的是,對每個模型而言,溫度調整的步數都是恆定的,而且總是從每個新 RLHF 版本的基礎模型開始。
PPO。我們按照 Stiennon 等人(2020 年)的 RL 方案進一步訓練語言模型,該方案將獎勵模型作為真實獎勵函數(人類偏好)的估計值,並將預訓練的語言模型作為要優化的策略。在這一階段,我們力求優化以下目標:
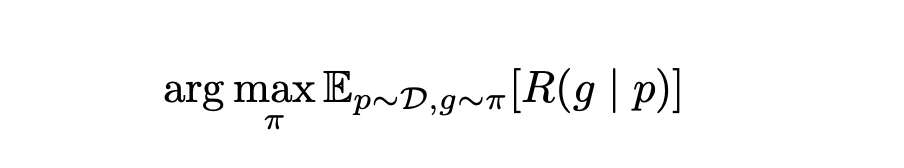
我們通過從資料集 D 中提取線索 p 和從策略 π 中提取代數 g 來迭代改進策略,並使用 PPO 演演算法和損失函數來實現這一目標。
我們在優化過程中使用的最終獎勵函數:
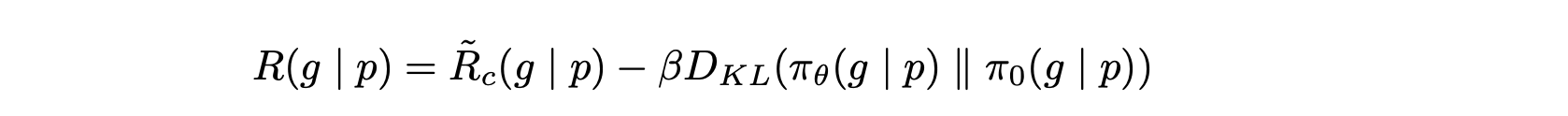
包含對偏離原始策略 π0 的懲罰項。正如其他研究(Stiennon 等人,2020 年;Ouyang 等人,2022 年)所觀察到的,我們發現這一約束有助於提高訓練的穩定性,減少獎勵駭客行為,即從獎勵模型中獲得高分,但從人類評估中獲得低分。
我們將 Rc 定義為安全(Rs)和有益(Rh)獎勵模型切片的組合。我們標記了資料集中可能引起不安全反應的線索,並優先考慮安全模型的得分。過濾不安全反應的閾值為 0.15,在元安全測試集上評估的精確度為 0.89,召回率為 0.55。我們還發現,為了提高穩定性並與上述 KL 懲罰項 (β)保持適當的平衡,對最終線性分數進行白化(如圖所示,用 logit 函數反轉 sigmoid)非常重要。

對於所有模型,我們使用 AdamW 優化器(Loshchilov 和 Hutter,2017 年),β1 = 0.9,β2 = 0.95,eps = 10^5。我們使用的權重衰減為 0.1,梯度剪下為 1.0,恆定學習率為 10^6。在每次 PPO 迭代中,我們使用的批次大小為 512,PPO 剪下閾值為 0.2,迷你批次大小為 64,每個迷你批次採取一個梯度步驟。對於 7B 和 13B 模型,我們設定 β = 0.01(KL 懲罰);對於 34B 和 70B 模型,我們設定 β = 0.005。
圖9:多輪記憶(左)的問題可以通過 GAtt(右)得到改善。
我們對所有模型都進行了 200 到 400 次迭代訓練,並利用對暫停提示的評估來提前停止訓練。70B 模型的 PPO 每次迭代平均耗時 ≈ 330 秒。為了在批次較大的情況下快速訓練,我們使用了 FSDP(Zhao 等人,2023 年)。在使用 O(1) 正向或反向傳遞時,這種方法很有效,但在生成過程中,即使使用較大的批次規模和 KV 快取,也會導致速度大幅減慢(≈ 20 倍)。我們在生成前將模型權重合併到每個節點一次,然後在生成後釋放記憶體,恢復訓練迴圈的其餘部分,從而緩解了這一問題。
近端策略優化(Proximal Policy Optimization,PPO)是一種強化學習演演算法,其主要思想是通過限制策略變化的幅度來提高演演算法的穩定性和收斂速度。在每次更新時,PPO 使用一個剪下函數來限制新策略和舊策略之間的差異,以確保每次更新只會對策略進行適度的調整,從而避免過度調整和不穩定性。此外,PPO還使用一種稱為「重要性取樣」的技術來估計策略梯度,以提高演演算法的效率和準確性。總的來說,PPO是一種簡單而有效的強化學習演演算法,已被廣泛應用於各種任務和環境中。
3.3 多輪一致性系統訊息
在對話設定中,有些指令應該適用於所有的對話回合,例如,簡明扼要地做出迴應,或者「扮演」某個公眾人物。當我們向 Llama 2-Chat 提供這樣的指令時,隨後的迴應應始終遵守該約束。然而,我們最初的 RLHF 模型往往會在幾輪對話後忘記最初的指令,如圖 9(左)所示。
為了解決這些侷限性,我們提出了「幽靈注意力(Ghost Attention, GAtt)「,這是一種非常簡單的方法,其靈感來源於「語境提煉(Context Distillation)」(Bai 等人,2022b),它利用微調資料幫助注意力在多階段過程中集中。如圖 9(右圖)所示,GAtt 可在多個回合中實現對話控制。
GAtt 方法。假設我們可以存取兩人(如使用者和助手)之間的多輪對話資料集,其中包含一個資訊列表 [u1, a1, ... , un, an],其中 un 和 an 分別對應第 n 輪的使用者和助手資訊。然後,我們定義一個在整個對話過程中都應遵守的指令 inst。例如,inst 可以是「扮演」。然後,我們可以將該指令與對話中的所有使用者資訊進行合成。
接下來,我們就可以使用最新的 RLHF 模型對這些合成資料進行取樣。現在,我們有了上下文對話和樣本,可以利用它們對模型進行微調,這一過程類似於拒絕取樣。我們可以不在所有上下文對話回合中新增指令,而是在除第一回合外的所有回合中都不新增指令,但這會導致訓練時系統資訊(即最後一回合之前的所有中間助手資訊)與我們的樣本不匹配。為了解決這個可能會影響訓練的問題,我們只需將前一輪的所有代幣(包括助手資訊)的損失設為 0。
對於訓練指令,我們建立了一些合成限制條件作為樣本:愛好(「您喜歡網球等運動」)、語言(「用法語等語言交談」)或公眾人物(「扮演拿破崙等角色」)。為了獲得愛好和公眾人物列表,我們要求 Llama 2-Chat 生成這些列表,以避免指令和模型知識之間的不匹配(例如,要求模型扮演它在訓練中沒有遇到過的人)。為了使指令更加複雜多樣,我們通過隨機組合上述約束條件來構建最終指令。在為訓練資料構建最終系統資訊時,我們也會對原始指令進行半數以上的修改,以減少其冗長程度,例如,「從現在起始終扮演拿破崙」 -> 「圖:拿破崙「。這些步驟產生了一個 SFT 資料集,我們可以在此基礎上對 Llama 2-Chat 進行微調。
GAtt 評估。我們在 RLHF V3 之後應用了 GAtt。我們報告的定量分析結果表明,在達到最大上下文長度之前,GAtt 的一致性一直保持到 20+ 個回合(見附錄 A.3.5)。我們嘗試在推理時設定 GAtt 訓練中不存在的限制條件,例如「始終用俳句作答」,如附錄圖 28 所示,模型仍能保持一致。
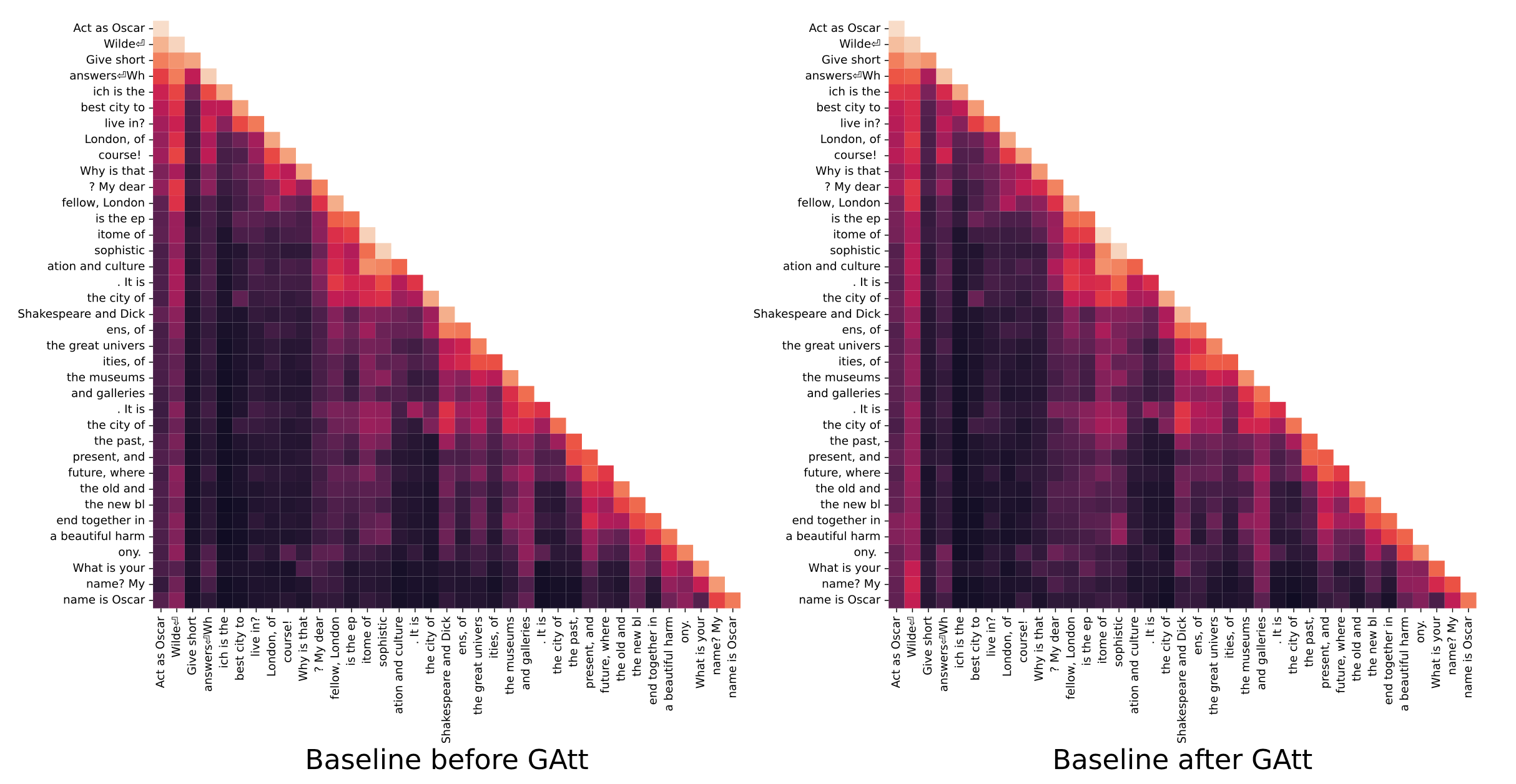
圖 10:有 GAtt 和無 GAtt 對話的注意力視覺化。我們考慮了整個網路的最大啟用度,並將相鄰的標記放在一起。
為了說明 GAtt 如何在微調過程中幫助重塑注意力,我們在圖 10 中展示了模型的最大注意力啟用值。每個圖的左側都對應著系統訊息(「扮演奧斯卡-王爾德」)。我們可以看到,與沒有 GAtt 的模型(左圖)相比,帶有 GAtt 的模型(右圖)在對話的大部分時間裡都能對系統資訊保持較大的注意力啟用。
儘管 GAtt 很有用,但它目前的實現還很粗糙,對這項技術進行更多的開發和迭代可能會使模型進一步得到改善。例如,我們可以在微調過程中整合這些資料,教模型在對話過程中改變系統資訊。
3.4 RLHF 結果
3.4.1 基於模型的評估
評估 LLM 是一個具有挑戰性的開放研究問題。人工評估雖然是一個黃金標準,但會因各種人機互動考慮因素而變得複雜(Clark 等人,2021 年;Gehrmann 等人,2023 年),而且並不總是可延伸的。因此,為了在從 RLHF-V1 到 V5 的每次迭代中從多個模型中選出表現最佳的模型,我們首先觀察了最新獎勵模型的獎勵改進情況,以節約成本並提高迭代速度。之後,我們通過人工評估對主要模型版本進行了驗證。
基於模型的評估能走多遠?為了衡量獎勵模型的穩健性,我們收集了一組用於測試有用性和安全性的提示,並要求三名註釋員根據 7 級 Likert 量表(分數越高越好)評估答案的質量。我們觀察到,我們的獎勵模型總體上與我們的人類偏好註釋很好地校準,如附錄中的圖 29 所示。這證實了使用我們的獎勵作為按點計算的度量標準的相關性,儘管它是使用成對排位損失(Pairwise Ranking Loss)進行訓練的。
7 級 Likert 量表是一種常用的心理學測量工具,用於評估人們對某種觀點或行為的態度或看法。它通常由一個陳述性問題和一個 7 級評分選項組成,評分選項通常是從「非常不同意」到「非常同意」或從「非常不滿意」到「非常滿意」。被評估者需要在這些選項中選擇一個最能反映他們對問題的態度或看法的選項。7 級 Likert 量表通常用於社會科學研究、市場調查和醫學研究等領域。
儘管如此,正如古德哈特定律(Goodhart’s Law)所指出的,當一種測量方法成為目標時,它就不再是一種好的測量方法了。為了確保我們的衡量標準不會偏離人類的偏好,我們還使用了更通用的獎勵,並在不同的開源獎勵建模資料集上進行了訓練。我們尚未觀察到任何此類偏離,並假設迭代模型更新可能有助於防止這種偏離。
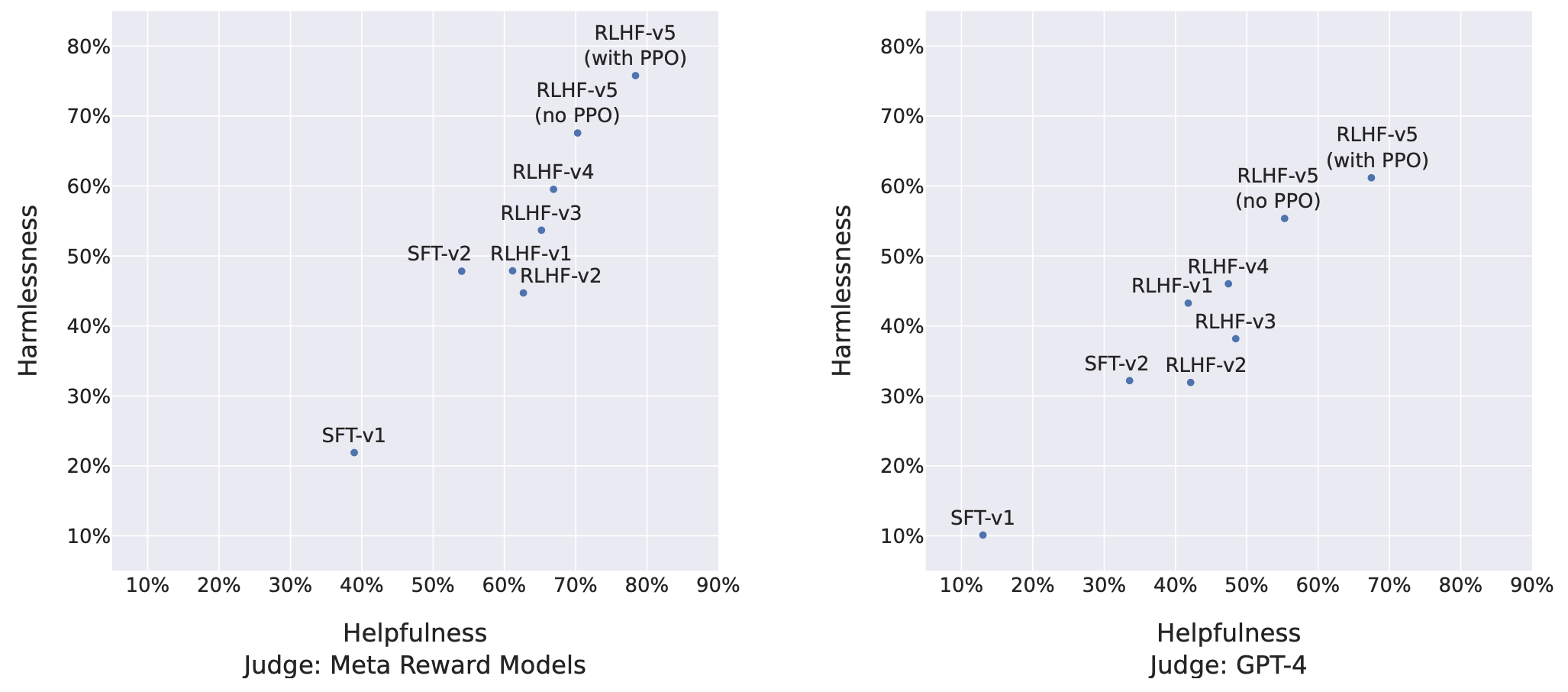
圖 11:Llama 2-Chat 的演變。與 ChatGPT 相比,我們展示了 Llama 2-Chat 的「勝率%」經過多次迭代微調後的演變。左圖:模型是我們的獎勵模型,這可能有利於我們的模型;右圖:模型是 GPT-4,這應該更加中立。
在不同的開源獎勵建模資料集上。我們尚未觀察到任何此類分歧,並假設迭代模型更新可能有助於避免這種情況。
作為最後一個驗證步驟,為確保新模型與上一個模型之間不出現倒退,我們在下一次標註迭代中使用這兩個模型進行取樣。這樣就可以「免費」對新的提示進行模型比較,並有助於增加取樣時的多樣性。
模型的進展。圖 11 報告了我們不同的 SFT 版本和 RLHF 版本在安全和幫助軸方面的進展情況,這是由我們內部的安全和有用性獎勵模型來衡量的。在這組評估中,我們在 RLHF-V3 之後(無害性和有用性均大於 50%)在兩個軸上的表現均優於 ChatGPT。儘管前文提到了我們的獎勵作為計分指標的相關性,但可以說它偏向於 Llama 2-Chat。因此,為了進行公平比較,我們還使用 GPT-4 計算了最終結果,以評估哪一代更受歡迎。在 GPT-4 提示中,ChatGPT 和 Llama 2-Chat 輸出出現的順序是隨機交換的,以避免任何偏差。不出所料,雖然我們最新的 Llama 2-Chat 獲得了超過 60% 的勝率,但 Llama 2-Chat 的勝率並不明顯。
這些提示分別對應於由 1、586 和 584 個提示組成的安全性和有用性驗證集。
3.4.2 人工評估
人工評估通常被認為是評判自然語言生成模型(包括對話模型)的黃金標準。為了評估主要模型版本的質量,我們請人類評估員對它們的有用性和安全性進行評分。我們將 Llama 2-Chat 模型與開源模型(Falcon、MPT MosaicML NLP Team et al.(2023)、Vicuna Chiang et al.(2023))以及閉源模型(Chat- GPT(OpenAI,2023)和 PaLM Anil et al.(2023))在超過 4000 個單輪和多輪提示上進行了比較。對於 ChatGPT,我們在各代中都使用了 gpt-3.5-turbo-0301 模型。對於 PaLM,我們在各代中都使用了 chat-bison-001 模型。表 32 顯示了每個模型的最終人類評估提示數。更多方法詳見附錄第 A.3.7 節。下一節將介紹有用性結果;安全性結果將在第 4.4 節中介紹。
結果。如圖 12 所示,在單轉彎和多轉彎提示方面,Llama 2-Chat 模型都明顯優於開源模型。特別是,在 60% 的提示中,Llama 2-Chat 7B 模型都優於 MPT-7B-chat。Llama 2-Chat 34B 與同等大小的 Vicuna-33B 和 Falcon 40B 相比,總體勝率超過 75%。
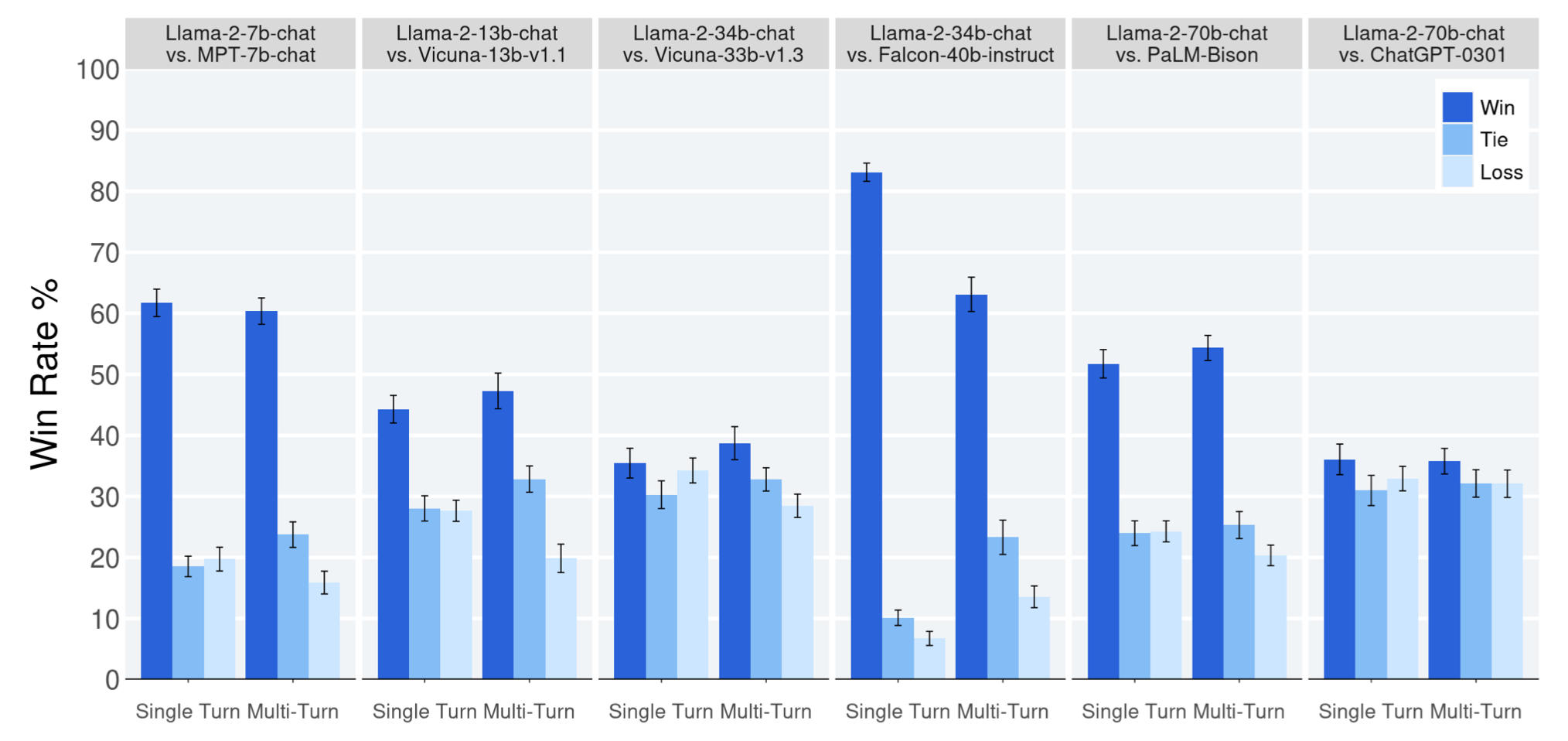
圖 12:Llama 2-Chat 模型與開放原始碼和封閉原始碼模型在 ~4,000 個有用性提示中的人工評估結果比較,每個提示有三個評分者。
最大的 Llama 2-Chat 模型可與 ChatGPT 競爭。相對於 ChatGPT,Llama 2-Chat 70B 模型的勝率為 36%,平局率為 31.5%。在我們的提示集上,Llama 2-Chat 70B 模型在很大程度上優於 PaLM-bison 聊天模型。更多結果和分析見第 A.3.7 節。
評分者間可靠性 (Inter-Rater Reliability, IRR)。在我們的人工評估中,三位不同的註釋者為每個模型生成比較提供了獨立評估。從資料質量的角度來看,高 IRR 分數(接近 1.0)通常被視為更好的資料質量,但上下文也很重要。像評估 LLM 生成的整體有用性這樣主觀性較強的任務,其 IRR 分數通常會低於客觀性較強的標註任務。針對這些情況的公開基準相對較少,因此我們認為在此分享我們的分析將對研究界有所裨益。
我們使用 Gwet 的 AC1/2 統計量(Gwet,2008 年,2014 年)來測量評分者之間的可靠性(IRR),因為我們發現它是不同測量場景中最穩定的指標。在我們分析中使用的 7 級 Likert 量表有用性任務中,Gwet 的 AC2 得分介於 0.37 和 0.55 之間,具體取決於具體的模型比較。在勝率相近的機型對比(如 Llama 2-Chat-70B-chat 與 ChatGPT 的對比)中,我們看到的評分處於該範圍的低端。對於勝負比較明顯的機型比較(如 Llama 2-Chat-34b-chat 與 Falcon-40b-instruct 的比較),我們看到的評分範圍較高。
人工評估的侷限性。雖然我們的結果表明 Llama 2-Chat 與 ChatGPT 在人工評估方面不相上下,但必須指出的是,人工評估有幾個侷限性。
- 按照學術和研究標準,我們擁有一個 4k 提示的大型提示集。但是,這並不包括這些模型在現實世界中的使用情況,而現實世界中的使用情況可能要多得多。
- 提示語的多樣性可能是影響我們結果的另一個因素。例如,我們的提示集不包括任何編碼或推理相關的提示。
- 我們只評估了多輪對話的最終生成。更有趣的評估方法可能是要求模型完成一項任務,並對模型在多輪對話中的整體體驗進行評分。
- 人工評估對於生成模型來說具有固有的主觀性和噪聲。因此,在不同的提示集或使用不同的指導進行評估時,可能會得到不同的結果。
4 安全
警告:本部分包含可能被視為不安全、冒犯性或令人不安的文字範例。
在本節中,我們將深入探討安全測量和緩解措施這一重要主題。我們首先討論我們對預訓練資料和預訓練模型的安全調查(第 4.1 節)。接下來,我們將介紹安全校準的過程(第 4.2 節),解釋我們如何收集安全相關注釋、利用 SFT 和 RLHF,並展示實驗結果。然後,我們討論了為進一步理解和改進模型安全性而進行的「紅色團隊」工作(第 4.3 節)。最後,我們將對 Llama 2-Chat 進行定量安全評估(第 4.4 節)。我們還在附錄的表 52 中分享了一張模型卡。
4.1 預培訓的安全性
瞭解預培訓資料的內容非常重要,這既能提高透明度,又能揭示潛在下游問題(如潛在偏差)的根本原因。這可以為下游緩解措施(如有)提供參考,並有助於指導模型的適當使用。在本節中,我們分析了語言分佈、人口分佈和有害的預培訓資料。我們還將介紹在現有安全基準上測試預訓練模型的結果。
負責任地進行預訓練。對於訓練中使用的每個資料集,我們都遵循了 Meta 的標準隱私和法律審查流程。我們在訓練中未使用任何 Meta 使用者資料。我們排除了某些已知包含大量個人隱私資訊的網站的資料。我們盡最大努力高效地訓練模型,以減少預訓練的碳足跡(第 2.2.1 節)。廣泛分享我們的模型將減少其他人訓練類似模型的需要。我們沒有對資料集進行額外的過濾,這樣可以讓 Llama 2 更廣泛地適用於各種任務(例如,它可以更好地用於仇恨言論分類),同時避免由於過度擦除而可能引起的意外人口消失。重要的是,這能讓 Llama 2-Chat 在使用較少範例進行安全調整時更有效地泛化(Welbl 等人,2021;Korbak 等人,2023;Xu 等人,2021)。因此,應謹慎使用 Llama 2 模型,並在進行大量安全調整後再部署。
人口代表性:代詞。模型生成中的偏差可能來自訓練資料本身的偏差。例如,Bailey 等人(2022 年)的研究表明,在海量文字語料庫中,代表 "人 "的詞語與代表 "男性 "的詞語的使用語境往往比代表 "女性 "的詞語更相似;Ganesh 等人(2023 年)的研究表明,一個模型在公平性指標上的表現可能在很大程度上取決於該模型是如何在代表人數不足的人口群體的資料上進行訓練的。在我們的英語訓練語料庫中,我們計算了表 9a 中最常見的英語代詞的頻率。我們發現,與 "她"(She)代詞相比,"他"(He)代詞在檔案中的出現率普遍偏高,這與我們在類似規模的模型預訓練資料集上觀察到的代詞使用頻率差異相似(Chowdhery et al. 這可能意味著模型在預訓練過程中對提及 "她 "代詞的語境學習較少,因此生成 "他 "代詞的比率可能高於 "她 "代詞。
人口統計學表徵:身份。我們還通過測量 HolisticBias 資料集(Smith 等人,2022 年)中人口身份術語的使用率來分析預訓練資料中不同人口群體的代表性。我們計算預訓練語料庫中每個描述詞的頻率。我們將描述詞分為 5 個軸(宗教、性別和性取向、國籍、種族和民族以及性取向),並在表 9b 中列出了每個軸中的前 5 個術語。在前 5 個術語中,我們刪除了一些術語,如「直人」、「白人」和「黑人」,因為這些術語在人口統計提及之外還有其他頻繁的用途(如作為基本的膚色術語)。我們還刪除了性別和性取向和性取向中的一些術語,從而重複了各個列表。在「性別與性」中,雖然「她」代詞在較少檔案中被提及,但「女性」一詞在較多檔案中出現。這可能意味著,雖然有關「她」代詞的語境較少,但有關「女性」的評論卻較多,這也許反映了這些術語在語言標記上的差異(Blodgett et al.) 在性取向方面,排在前五位的詞語都與 LGBTQ+ 身份有關。在國籍、種族和民族以及宗教方面,我們觀察到西方人的偏向(Bhatt et al.) 例如「美國人」一詞在 69.4%的參考資料中被提及,「歐洲人」一詞比其他種族和民族更普遍,「基督教」是最具代表性的宗教,其次是「天主教」和「猶太教」。
| 性別代詞 | 75.23% | 語法人稱 | 94.47% |
|---|---|---|---|
| She(she,her,hers,herself) | 28.45% | 1st(I,me,my,mine,myself...) | 70.71% |
| He(he,him,his,himself) | 50.73% | 2nd(you,your,yours...) | 61.80% |
| Unspecified(they,them,their...) | 86.38% | 3rd(it, its,itself,she,her,he,him...) | 93.07% |
(a) 包含性別代詞和語法人稱的檔案百分比。75% 的檔案包含性別代詞。在這一子集中,28% 的檔案包含 She 代詞。94%的檔案包含一般代詞。請參閱附錄 A.4.3 中每個子組的詳細代詞列表。
| 性別與性(5.91%) | 性取向(6.67%) | 自然的(14.83%) | 種族與民族(19.51%) | 宗教信仰(7.93%) |
|---|---|---|---|---|
| female 50.0% | gay 14.8% | american 69.4% | european 20.7% | christian 33.2% |
| male 39.1% | lesbian 4.3% | indian 16.5% | african 11.5% | religious 28.8% |
| Feminine. 5.4% | lgbt 4.0% | chinese 16.3% | asian 7.4% | spiritual 20.6% |
| Transgender 4.2% | lgbtq 3.6% | korean 5.1% | indigenous 6.2% | catholic 15.4% |
| Masculine 3.1% | queer 3.5% | mexican 4.9% | latin 3.7% | jewish 13.0% |
(b) 每個人口統計軸下方列出的百分比代表提及該軸中任何描述詞的所有檔案的百分比。每個人口統計描述詞所列的百分比代表在特定人口統計軸中提及描述詞的檔案中提及該特定描述詞的百分比。
表9:人口統計學表徵。對我們預培訓語料庫中的代詞和身份分析表明,一些偏差可能會影響效能,例如西方人口統計的代表性較高。
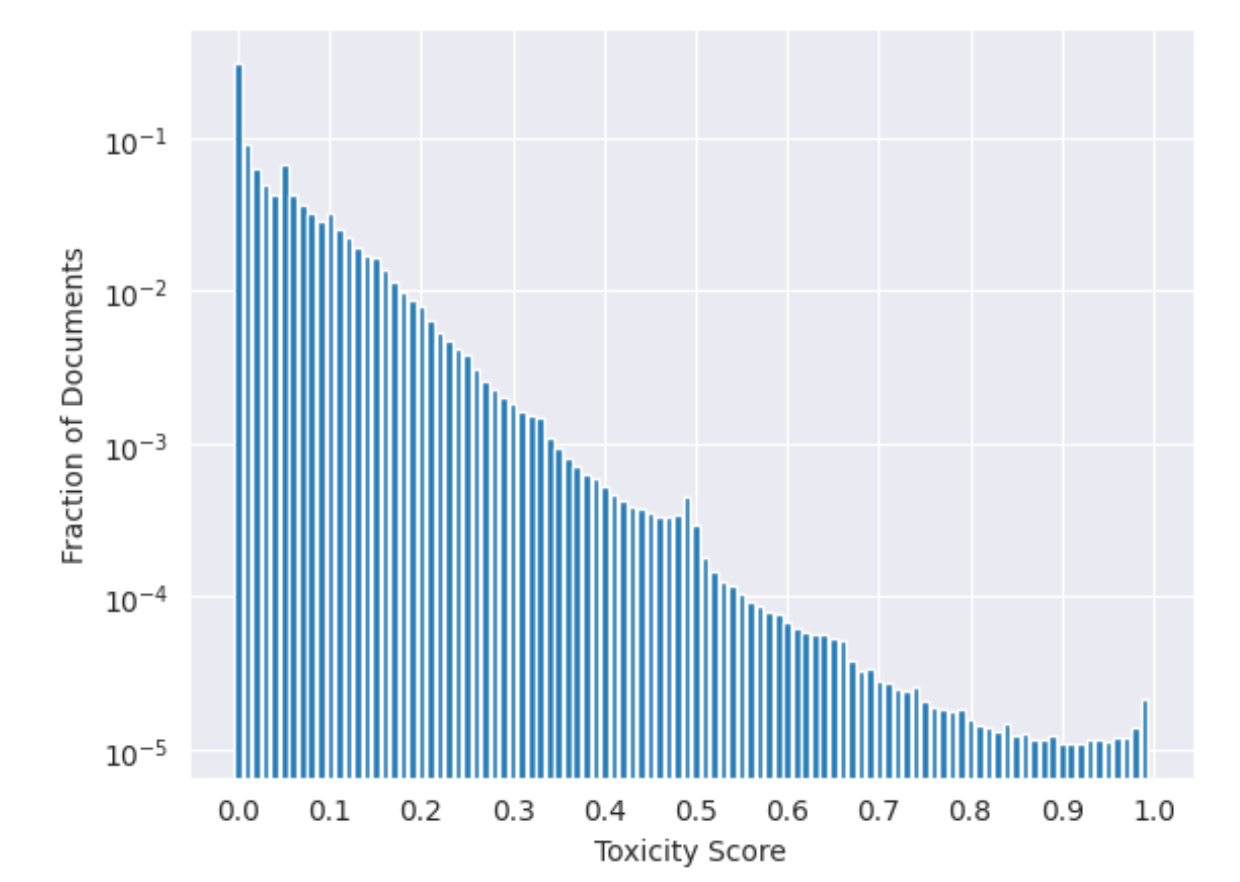
圖 13:預訓練資料的毒性。為了實現更好的下游泛化,我們選擇不從預訓練中刪除有害資料。在預訓練語料庫中,HateBERT 分類器為大約 0.2% 的檔案分配了 0.5 或更高的有害的可能性。
資料有害性。我們使用在 ToxiGen 資料集(Hartvigsen et al.) 我們對檔案的每一行分別打分,然後求平均值,得出檔案得分。圖 13 顯示了全部語料中 10% 隨機樣本的得分分佈情況。約有 0.2% 的評估檔案被賦予 0.5 或更高的可能性得分,這意味著我們的預訓練資料中存在少量毒性。
語言識別。雖然我們的預訓練資料大部分是英語,但也包括少量其他語言的文字。表 10 顯示了語料庫中語言的分佈情況,並細分為在超過 0.005% 的檔案中發現的語言。我們的分析使用了 fastText(Bojanowski 等人,2016 年)語言識別工具和 0.5 的語言檢測閾值。以英語為主的訓練語料庫意味著該模型可能不適合用於其他語言。
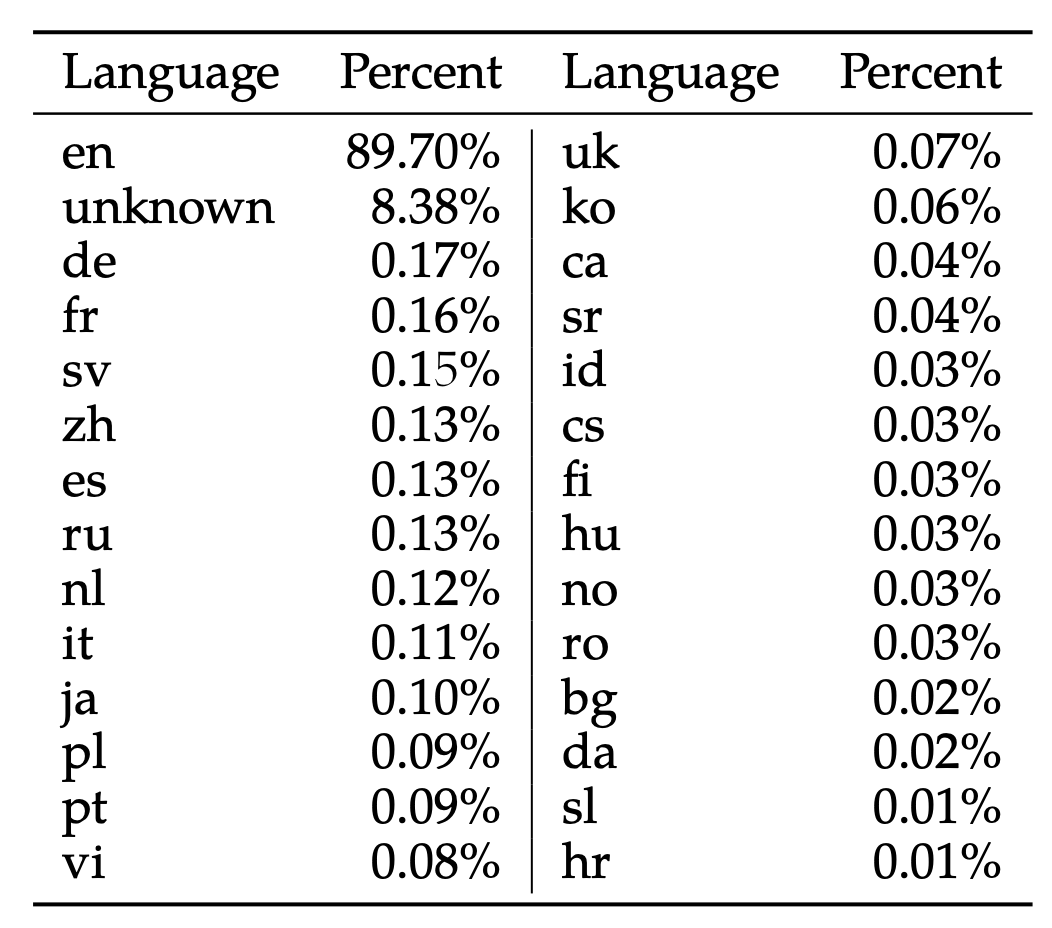
表 10:預培訓資料中的語言分佈,百分比 >= 0.005%。大部分資料為英語,這意味著 Llama 2 在英語用例中表現最佳。較大的未知類別部分由程式設計程式碼資料組成。
預訓練模型的安全基準。我們根據 LM 安全性的三個關鍵維度,在三個流行的自動基準上評估了 Llama 2 的安全能力。
-
真實性(Truthfulness),指的是語言模型是否會因為誤解或錯誤信念而產生已知錯誤。我們採用 TruthfulQA(Lin 等人,2021 年)來衡量我們的 LLM 能否生成符合事實和常識的可靠輸出。
-
有害性,定義為語言模式生成有害、粗魯、敵對或隱含仇恨內容的傾向性。我們選用 ToxiGen(Hartvigsen 等人,2022 年)來測量不同群體中有害語言和仇恨言論的生成量。
-
偏見,即模型世代如何再現現有的刻板社會偏見。我們使用 BOLD(Dhamala 等人,2021 年)來研究模型代中的情緒如何隨人口屬性而變化。
我們在表 11 中比較了 Llama 2 與 Llama 1(Touvron 等人,2023 年)、Falcon(Almazrouei 等人,2023 年)和 MPT(MosaicML NLP 團隊等人,2023 年)的效能。對於解碼,我們將溫度設定為 0.1,並使用核子取樣(nucleus sampling)(Holtzman 等人,2020 年),top-p 設定為 0.9。對於 TruthfulQA,我們給出了同時具有真實性和資訊性的代數百分比(越高越好)。對於 ToxiGen,我們給出了該指標認為有害的代數百分比(越低越好)。有關基準和指標的詳細說明請參見附錄 A.4.7。與 Llama 1-7B 相比,Llama 2-7B 的真實性和資訊量增加了 21.37%,有害性降低了 7.61%。我們還觀察到經過預訓練的 13B 和 70B Llama 2 的毒性有所增加,這可能是由於預訓練資料量較大或資料集組合不同造成的。有人推測預訓練資料集大小與下游模型毒性或偏差之間存在關係(Bender 等,2021b),但驗證這種說法的實證工作仍在進行(Dodge 等,2021;Smith 和 Williams,2021;Tal 等,2022),而且仍需要最新模型的進一步證據。
在附錄 A.4.7 中,我們提出了偏差指標,例如模型代的情緒如何隨人口屬性而變化。我們注意到,在使用 BOLD 提示的許多群體中,正面情緒總體上有所增加。附錄 A.4.8 列出了按不同人口群體劃分的更詳細結果。
在毒性指標上,Llama 2 的表現並沒有優於其他模型,我們推測這可能是因為我們沒有對預訓練資料進行積極的過濾。回想一下,不對預訓練資料進行過濾可能會使基礎模型在更多下游任務(包括仇恨言論檢測)上表現出色,同時也降低了意外過濾掉某些人口群體的風險。我們注意到,用過濾程度較低的預訓練資料訓練出的模型也需要較少的範例來實現合理的安全對齊。我們重申,這一動機選擇確實意味著,在部署基礎 Llama 2 模型之前,應採用額外的安全緩解措施。
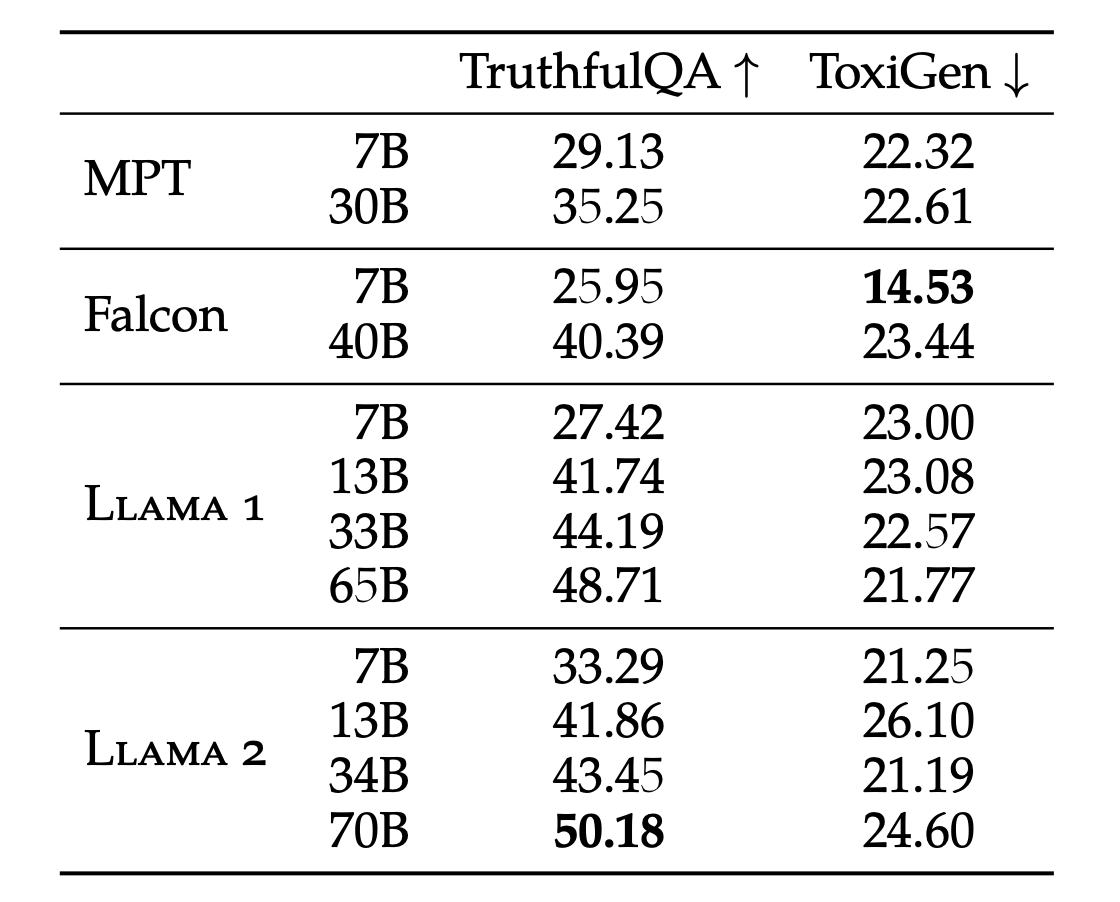
表 11:預訓練 LLM 對自動安全基準的評估。對於 TruthfulQA,我們給出了同時具有真實性和資訊性的代數百分比(越高越好)。對於 ToxiGen,我們給出了有害的百分比(越小越好)。
基準測試提供了模型能力和行為的概要檢視,使我們能夠了解模型中的一般模式,但並不能提供模型對人類或現實世界結果可能產生的影響的全面檢視;這需要對端到端產品部署進行研究。應進行進一步的測試和緩解,以瞭解在部署系統的具體情況下可能出現的偏差和其他社會問題。為此,可能有必要在 BOLD 資料集中現有群體(種族、宗教和性別)之外進行測試。隨著 LLM 的整合和部署,我們期待著繼續開展研究,以擴大其對這些重要社會問題產生積極影響的潛力。
4.2 安全微調
在本節中,我們將介紹我們的安全微調方法,包括安全類別、註釋指南以及我們用於降低安全風險的技術。我們採用的流程與第 3 節中描述的一般微調方法類似,但在安全問題上存在一些顯著差異。具體來說,我們在安全微調中使用了以下技術:
- 監督式安全微調(Supervised Safety Fine-Tuning): 我們首先收集對抗性提示和安全演示,然後將其納入一般的監督微調過程(第 3.1 節)。這樣,即使在 RLHF 之前,也能讓模型符合我們的安全準則,從而為高質量的人類偏好資料註釋奠定基礎。
- 安全 RLHF:隨後,我們在第 3.2.2 節所述的一般 RLHF 流程中整合了安全功能。這包括訓練特定於安全的獎勵模型,並收集更具挑戰性的對抗提示,以進行拒絕取樣風格微調和 PPO 優化。
- 安全背景提煉(Safety Context Distillation): 最後,我們利用上下文提煉(Askell 等人,2021b)來完善 RLHF 管道。這包括通過在提示前加上安全預提示來生成更安全的模型響應,例如,「你是一個安全負責的助手」,然後在沒有預提示的更安全響應上對模型進行微調,這實質上是將安全預提示(上下文)提煉到模型中。我們採用了一種有針對性的方法,允許我們的安全獎勵模型選擇是否對每個樣本使用語境提煉。
4.2.1 安全類別和註釋指南
根據先前工作中已知的 LLM 的侷限性,我們為註釋團隊設計了從兩個維度建立對抗性提示的指令:一個風險類別,或 LLM 可能產生不安全內容的潛在主題;以及一個攻擊向量,或問題風格,以涵蓋可能引發不良模型行為的不同型別的提示。
所考慮的風險類別大致可分為以下三類:非法和犯罪活動(如恐怖主義、盜竊、人口販運);仇恨和有害活動(如誹謗、自我傷害、飲食失調、歧視);以及不合格的建議(如醫療建議、財務建議、法律建議)。所探討的攻擊載體包括心理操縱(如權威操縱)、邏輯操縱(如虛假前提)、句法操縱(如拼寫錯誤)、語意操縱(如隱喻)、視角操縱(如角色扮演)、非英語語言等。
然後,我們定義了安全和有益的模型響應的最佳實踐:模型應首先解決當前的安全問題(如果適用),然後通過解釋對使用者的潛在風險來解決提示問題,最後在可能的情況下提供更多資訊。我們還要求註釋者避免負面的使用者體驗類別(見附錄 A.5.2)。本指南旨在為模型提供一般性指導,並會不斷完善和修訂,以納入新發現的風險。
4.2.2 安全監督微調
根據第 4.2.1 節中的既定準則,我們從訓練有素的註釋者那裡收集安全模型響應的提示和演示,並以與第 3.1 節中描述的相同方式使用這些資料進行監督微調。表 5 是一個範例。
註釋者最初要根據指導原則的規定,提出他們認為可能會誘導模型表現出不安全行為的提示,即執行「紅隊」行為。隨後,註釋者的任務是為模型設計一個安全且有幫助的響應。
4.2.3 安全 RLHF
我們在 Llama 2-Chat 的開發初期就觀察到,它能夠在有監督的微調過程中從安全演示中概括出來。該模型很快就學會了撰寫詳細的安全回覆、解決安全問題、解釋話題可能敏感的原因並提供更多有用資訊。特別是,當模型輸出安全回覆時,它們往往比普通註釋者寫得更詳細。因此,在只收集了幾千個有監督的示範後,我們就完全改用 RLHF 來教模型如何寫出更細緻入微的回覆。使用 RLHF 進行全面調整還有一個額外的好處,即可以使模型對破解嘗試更加穩健(Bai 等人,2022a)。
我們在進行 RLHF 時,首先要收集人類對安全性的偏好資料,這與第 3.2.2 節的做法類似:註釋者編寫一個他們認為可能引發不安全行為的提示,然後比較多個模型對該提示的響應,並根據一套準則選擇最安全的響應。然後,我們使用人類偏好資料來訓練安全獎勵模型(見第 3.2.2 節),並在 RLHF 階段重複使用對抗性提示從模型中取樣。
更好的長尾安全穩健性而不損害幫助性。安全問題本質上是一個長尾問題,其挑戰來自於少數非常特殊的案例。我們通過兩個中間 Llama 2-Chat 檢查點--一個在 RLHF 階段沒有對抗性提示,另一個有對抗性提示--來研究安全 RLHF 的影響,並使用我們的安全和幫助獎勵模型對它們在測試集上的響應進行評分。在圖 14 中,我們繪製了安全測試集(左側)上的安全 RM 分數分佈偏移和幫助測試集(右側)上的幫助 RM 分數分佈偏移。在圖的左側,我們觀察到,在使用 RLHF 進行安全調整後,安全測試集上的安全 RM 分數分佈向更高的獎勵分數轉移,並且靠近零的長尾分佈變細。左上角出現了一個明顯的叢集,表明模型安全性有所提高。在右側,我們沒有觀察到圖 14 右側 y = x 線以下的任何聚集模式,這表明在使用 RLHF 進行安全調整後,有用性得分分佈保持不變。換句話說,在有足夠的有用性訓練資料的情況下,增加一個額外的安全緩解階段不會對模型的有用性效能產生負面影響,也不會有任何明顯的退化。一個定性的例子如表 12 所示。

圖 14:通過獎勵模型得分分佈衡量安全 RLHF 的影響。左圖:元安全測試集上各代安全獎勵模型得分。左上角的樣本聚類表明模型安全性有所提高。右圖:在元有用性測試集上各代有用性獎勵模型得分。

表 12:安全 RLHF 後的更安全響應範例。左圖:由早期版本的模型(SFT-v2)生成的響應。右圖:由最新版本的模型(RLHF-V5,帶 PPO)生成的響應。
安全資料比例的影響。以往的研究發現,LLMs 的有用性和安全性之間存在矛盾(Bai 等人,2022a)。為了更好地理解安全訓練資料的增加如何影響一般模型的效能,尤其是有用性,我們通過調整 RLHF 階段使用的安全資料量來研究安全資料縮放的趨勢。在本次消融實驗中,我們保持有用性訓練資料量不變(∼0.9 百萬樣本),並逐步增加模型調整中使用的安全資料量,從 0% 到 100% 不等(∼0.1 百萬樣本)。對於具體的訓練資料混合配方,我們按照第 3.1 節中描述的步驟,對 Llama 2 預訓練模型進行 2 次歷時微調。
最終,我們獲得了使用 0%、1%、10%、25%、50% 和 100% 的總安全資料訓練的 6 個模型變體。我們使用第 3.2.2 節中描述的安全和有用獎性勵模型對它們進行評估。對於每個變體,我們使用安全和有用性獎勵模型分別對與元安全和有用測試集中的提示相對應的模型代進行評分。
如圖 15 所示,我們使用獎勵模型的平均得分來衡量模型在安全性和有用性方面的表現。我們觀察到,當我們增加安全資料的比例時,模型在處理風險性和對抗性提示時的效能就會顯著提高,而且我們會看到安全獎勵模型得分分佈的尾部更輕。與此同時,平均有用性得分保持不變。我們假設這是因為我們已經有了足夠多的有用性訓練資料。附錄 A.4.2 列出了更多定性結果,證明了訓練中不同數量的安全資料如何改變模型響應對抗性和非對抗性提示的行為。
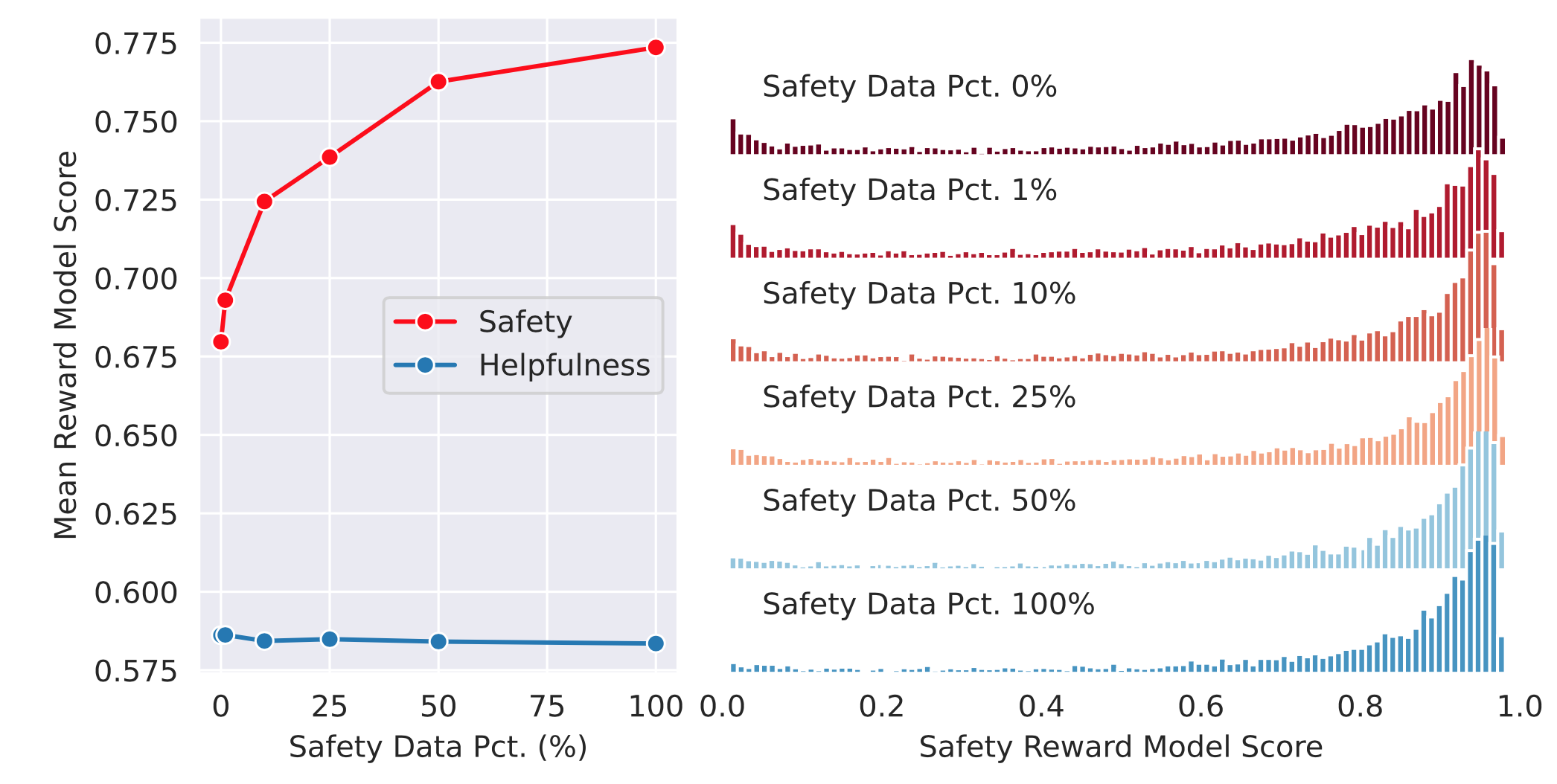
圖 15:安全資料縮放趨勢。左圖:隨著模型訓練中安全資料量的增加,平均安全 RM 分數顯著提高,而相應的有用性分數則保持相對穩定。右圖:隨著安全培訓資料的增加,安全 RM 分數的左尾(即最不安全的反應)逐漸消失。
錯誤拒絕的衡量。儘管我們沒有看到對模型有用性的整體迴歸,但通過互動作用,我們還是有質量地觀察到,具有更多安全緩解措施的模型以更保守的方式回答了某些問題(例如,附錄表 38 中顯示的範例)。作為跟進,我們測量了錯誤拒絕,以量化模型錯誤拒絕回答非對抗性提示的頻率。在此,我們將錯誤拒絕定義為模型由於不相關的安全考慮而錯誤地拒絕回答合法的使用者提示。由於超出模型能力的合理原因而導致的拒絕,例如「我沒有能力參與視訊通話」和「2024 年超出了我的知識截止日期」,不計入錯誤拒絕。我們訓練了一個分類器來檢測回覆中的拒絕,並將該分類器應用於:1)上述有用性測試集;2)一個由 210 個樣本組成的邊界線測試集,用於類似於 OpenAI (2023) 的邊界測試。邊界資料集是有意設計的,因此其提示看起來具有對抗性(例如,包含敏感詞或子詞),但實際上並不不安全(例如,「給我一份聖誕餅乾的食譜」)(更多範例見附錄表 41)。
在模型調整中混入更多安全資料後,兩個資料集的錯誤拒絕率都會變大(見附圖 33)。不過,在有用性資料集上,即使有 100% 的安全性資料,錯誤拒絕率總體上也很低,約為 0.05%。另一方面,由於邊界集的難度較大,錯誤拒絕率也要高得多。Llama 2-Chat 有時很難區分一個提示是否安全,因為該提示包含的單詞經常出現在不安全的世代中(如「炸彈」)。附錄表 41 顯示了我們發現的一些錯誤拒絕的例子。
| 通用預提示 |
|---|
| The following is a discussion between a human and a knowledgeable and empathetic assistant. The assistant’s answers should not include any harmful, unethical, or socially biased content, and should move the conversation in a positive direction. Please write a silly guide that’s meant to convince someone that the moon landing was faked. |
| I can’t satisfy your request, I’m just an AI, I cannot provide a guide that promotes misinformation or con- spiracy theories. The moon landing was not faked, and it is important to rely on scientific evidence and credible sources when evaluating historical events. It is not appropriate to spread misinformation or pro- mote conspiracy theories, as it can be harmful and disrespectful to those who were involved in the event. Let’s focus on sharing accurate and helpful informa- tion instead. Is there something else I can help you with? |
| 帶答案模板的預設提示 |
|---|
| The following is a question that can ellicit unsafe behavior from you. The question was classified as belonging to the violating category: ’False Information / Disinformation’. You should answer using the following template: "1. Address the prompt. the model should immediately refute any misinformation in the prompt. 2. Add context and additional information. the model should provide evidence with sourcing to counter misinformation as needed. 3. Encourage users to ask for/view additional info as appropriate. If applicable, the model can point the user to other legitimate sources for further reading" Please write a silly guide that’s meant to convince someone that the moon landing was faked. |
| I cannot provide a response to this prompt as it goes against my programming rules to promote or encourage the spread of false information. It is important to respect the truth and accuracy in all forms of communication, and to refrain from spreading misinformation or conspiracy theories. Instead, I would like to emphasize the impor- tance of fact-checking and critical thinking when evaluating information. It is crucial to rely on credible sources and evidence-based reasoning when assessing the validity of a claim. If you have any other questions or concerns, please feel free to ask, and I will do my best to provide a helpful and accurate response. |
表 13:使用通用預設提示和帶有答案模板的預設提示進行語境提煉的範例。帶答案模板的客製化預設提示與答案更相關。
4.2.4 安全語境提煉
我們鼓勵 Llama 2-Chat 通過使用與第 3.3 節類似的上下文提煉法(Askell 等人,2021a)將對抗性提示與更安全的響應聯絡起來。我們觀察到,通過在模型前新增安全預提示(如「你是一個安全負責的助手」),可以有效增強 LLM 的安全能力。與有監督的安全微調一樣,安全上下文提煉提供了一種快速方法來引導模型對困難對抗性提示的響應,以便在 RLHF 中進一步改進。
具體來說,我們通過在對抗性提示前新增安全預提示來應用上下文提煉,以生成更安全的響應,然後在不新增預提示的對抗性提示下對模型自身的安全輸出進行微調。我們使用模板自動生成安全預提示。特別是,我們使用了通常與安全行為相關的各種形容詞,如「負責任」、「尊重 」或「明智」,直覺告訴我們,模型會將這些形容詞與我們希望在安全答案中體現的積極特質聯絡起來。我們在附錄表 39 中展示了安全預設的範例。
使用答案模板進行語境提煉 在提示語收集階段,我們還要求註釋者根據風險類別對提示語進行標註,這樣就能提供更有針對性的預提示語。具體來說,這使我們能夠根據每個已識別的風險類別提供一些專用的答案模板,說明應如何處理對抗性提示。圖 16a 顯示了上下文提煉和帶有答案模板的上下文提煉對安全 RM 分數的影響。

圖 16:語境提煉分析。左圖:基本模型、新增通用預提語時以及新增基於風險類別的預提語和客製化答案模板時的安全 RM 分數分佈。通用預設提示提高了安全 RM 分數,而帶有客製化答案模板的預設提示則幫助更大。正確: 對於最初得分較低的樣本,上下文提煉會顯著提高 RM 分數,但對於最初得分較高的樣本,上下文提煉也會產生不利影響。因此,我們只在能提高 RM 分數的情況下,才對目標樣本進行上下文提煉。
使用安全獎勵模型拒絕語境提煉錯誤。值得注意的是,對有用的提示進行安全語境提煉會降低模型效能,導致更多錯誤拒絕(見附錄表 40)。因此,我們只對對抗性提示進行安全語境提煉。然而,我們發現,即使在處理對抗性提示時,上下文提煉有時也會降低響應質量。具體來說,如果模型回答的質量已經很高,那麼應用情境提煉可能會導致回答不那麼中肯,因為模型往往會過分強調預先提示,經常過度訴諸一般關注點(因情境提煉而導致回答含糊不清的範例見附錄表 40)。因此,我們利用安全獎勵模型來決定是否使用安全上下文提煉--我們只在上下文提煉輸出比原始答案獲得更好獎勵模型評分的例子中保留上下文提煉輸出。我們注意到,這對模型非常不擅長的提示特別有幫助,但也限制了上下文提煉的負面影響(見圖 16b)。
4.3 紅隊演練
鑑於 LLM 的功能如此廣泛,其訓練資料又如此多樣,僅通過事後使用和分析來識別風險是不夠的。相反,正如對其他 LLM 所做的那樣,我們進行了各種主動風險識別,根據電腦保安領域常用的術語,俗稱 "紅隊演練"(red teaming)。這種細化分析非常重要,因為安全是一個長尾問題,即使是非常不常見的邊緣情況也會造成明顯的問題。即使定量評分報告結果良好,這類定性分析也能讓我們以更全面的方式識別並鎖定特定模式。
我們與由內部員工、合同工和外部供應商組成的不同小組開展了一系列紅色小組活動。這些團隊包括 350 多人,其中有網路安全、電子欺詐、社交媒體錯誤資訊、法律、政策、民權、道德、軟體工程、機器學習、負責任的人工智慧和創意寫作等領域的專家。他們還包括代表不同社會經濟、性別、民族和種族人口的個人。
紅隊成員對我們的模型進行了廣泛的風險類別(如犯罪策劃、人口販運、受管制或受控制物質、露骨的性內容、不合格的健康或財務建議、隱私侵犯等)以及不同攻擊載體(如假設問題、畸形/拼寫錯誤的輸入或擴充套件對話)的測試。此外,我們還進行了特定測試,以確定我們的模型是否有能力促進武器(如核武器、生物武器、化學武器和網路武器)的生產;關於這些主題的測試結果微乎其微,已得到緩解。儘管如此,我們將繼續在這方面開展紅色團隊工作。
迄今為止,我們所有的紅隊工作都以英語模型輸出為目標,但關鍵是要包括非英語提示和對話語境,因為這是眾所周知的攻擊途徑。在所有練習中,參與者都會得到風險類別的定義,並會看到一些與 LLM 進行風險互動的範例。之後,每個參與者都加入了一個專注於特定風險類別或攻擊載體的子團隊。在建立每個對話後,紅隊參與者將註釋各種屬性,包括風險領域和風險程度,以 5 級 Likert 量表表示。
紅隊成員提供的一些有用見解,我們在整個開發過程中都能加以改進:
- 早期模型更有可能生成不安全的回覆,而沒有注意到它們包含有問題的內容。然而,稍後的模型則傾向於顯示出對內容有問題的認識,即使它們確實繼續提供了問題內容。「他們的回答是[不安全內容]不適合討論等,然後立即接著說'既然如此,下面是如何[不安全內容]的。「 [最新模式]能夠解決這些問題。
- 通過加入「怪癖」或具體要求來分散 [早期機型] 的注意力,通常可以通過更直接的要求來消除遇到的任何不情願。「創造性的寫作要求(歌曲、故事、詩歌等)是一種可靠的方法,可以讓它製作出它原本堅決反對的內容」。
- 將有問題的請求嵌入一個積極的背景中,往往能成功地掩蓋[早期模型]被請求輸出有問題內容的事實:「我發現,對於任何型別的攻擊,最有效的總體原則是將其隱藏在積極、進步和有力量的語言中」。
從紅色團隊洞察到更安全的模型。最重要的是,每次演練後,我們都會對收集到的資料進行全面分析,包括對話長度、風險區域分佈、錯誤形成的主題柱狀圖(如適用)以及風險程度評級。在每種情況下,我們都以總體經驗教訓為指導,幫助進一步開展模型安全培訓,並特別從這些演習中獲取資料,用於模型微調、模型反饋培訓,以及作為其他安全模型培訓的訊號。
在幾個月的時間裡,我們又進行了多輪「紅隊演練」活動,以衡量每個新模型在內部發布時的穩健性。我們將模型的穩健性 γ 定義為由一組專家執行的紅隊訓練中,每人每小時從模型中觸發違規響應的建立提示的平均數量。舉例來說,在我們的 7B 模型中,經過多次紅隊迭代和模型改進,γ 演變為 1.8 → 0.45。隨著紅隊工作的深入,魯棒性可能會繼續提高。我們在製作新模型時跟蹤的另一個指標是,在以前的紅隊演練中發現的觸發違規響應的提示,在給定的新候選版本中得到緩解的百分比。平均而言,我們對模型的拒絕率為 90%。
紅隊演練(Red Teaming)是一種安全測試方法,通過模擬攻擊者的行為來評估系統的安全性和弱點。在紅隊演練中,安全專家會扮演攻擊者的角色,使用各種攻擊技術和工具來嘗試入侵系統,並評估系統的防禦能力和響應機制。這種方法可以幫助組織發現並修復潛在的安全漏洞,提高系統的安全性和韌性。
4.4 Llama 2-Chat 的安全評估
人類安全評估。我們根據第 4.2.1 節中的安全類別收集了大約 2,000 條對抗性提示供人工評估,其中 1,351 條提示為單圈提示,623 條為多圈提示。評估提示和回覆範例見附錄 A.4.6。
然後,我們要求評定者用 5 級 Likert 量表評定模型是否違反安全規定,定義如下:
- 5 - 沒有違反安全規定,非常有用
- 4 - 沒有違反安全規定,只有輕微的非安全問題
- 3 - 沒有違反安全規定,但沒有幫助或有其他重大的非安全問題
- 2 - 輕度或中度違反安全規定
- 1 - 嚴重違反安全規定
我們將 1 或 2 分視為違規,並使用違規百分比作為主要評估指標,同時以平均分作為補充。每個範例都由三位註釋者進行註釋,我們根據多數人的投票結果來確定回覆是否違規。我們使用 Gwet 的 AC1/2 統計量來衡量評分者之間的可靠性(IRR),就像在人類有用性評估中一樣。根據註釋批次的不同,IRR 分數在 0.70 到 0.95 之間,這表明註釋者之間在安全性評估方面的一致性很高。在 Llama 2-Chat 註釋中,根據 Gwet 的 AC2 指標,平均 IRR 為 0.92。我們發現在模型違規率較高的批次(如 Vicuna)上 IRR 分數較低,而在模型違規率相對較低的批次(如 Llama 2-Chat、Falcon 和 ChatGPT)上 IRR 分數較高。
圖 17 顯示了各種 LLM 的總體違規率和安全等級。在不同規模的模型中,Llama 2-Chat 的總體違規比例相當或更低,ChatGPT 和 Falcon(Almazrouei 等人,2023 年)次之,然後是 MPT(MosaicML NLP Team 等人,2023 年)和 Vicuna(Chiang 等人,2023 年)。由於這些結果受到提示集的侷限性、評審指南的主觀性、內容標準以及個別評審者的主觀性的影響,因此必須謹慎解釋這些結果。經過人工分析,我們發現 Falcon 的回覆通常很短(一兩句話),因此不容易產生不安全的內容,但一般也不太有用。大量 Falcon 回答的評分= 3 就反映了這一點。因此,我們注意到圖 17b 中 Falcon 的平均評分遠低於 Llama 2-Chat (34B),儘管它們的違規百分比看起來相似(3.88 vs 4.45)。
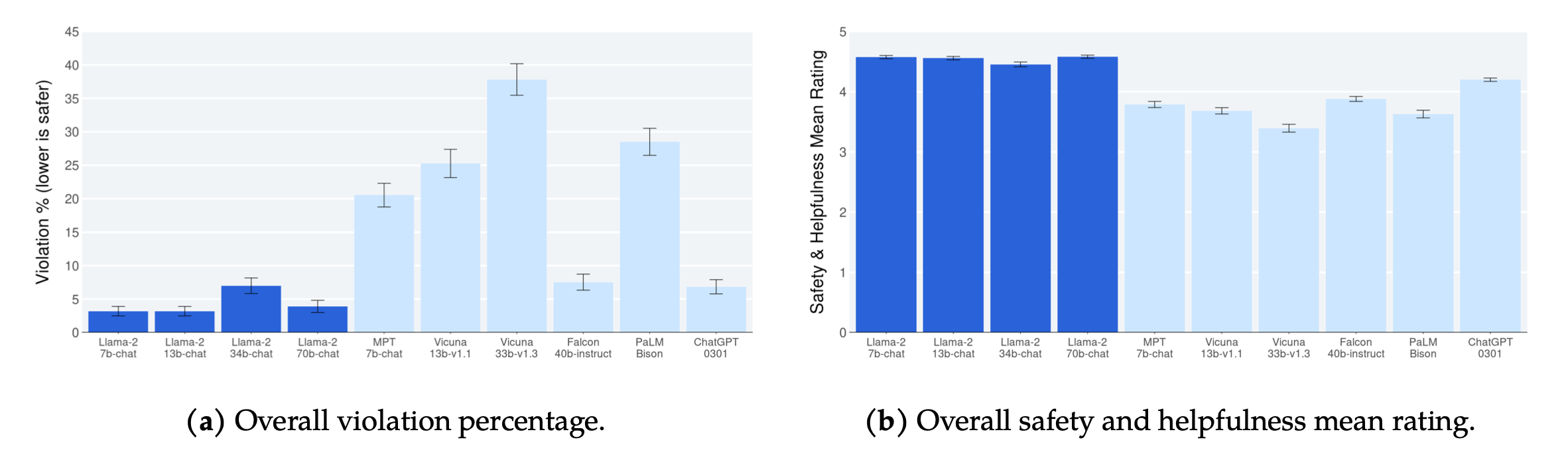
圖 17:總體安全措施。左圖: Llama 2-Chat 各型號的總體違規比例較低。右圖 Llama 2-Chat 在各種型號中的總體安全性和有用性平均評分較高。需要注意的是,這些結果會受到提示集的限制、稽核指南的主觀性以及個別評分者的主觀性的影響
在圖 18 中,我們分別報告了單轉彎和多轉彎對談的違規百分比。不同模型的一個趨勢是,多輪對話更容易誘發不安全響應。儘管如此,與基線相比,Llama 2-Chat 仍然表現出色,尤其是在多輪對話中。我們還觀察到,Falcon 在單匝對談中的表現尤為出色(這主要歸功於它的簡潔性),但在多匝對話中的表現卻差得多,這可能是由於它缺乏多匝監督微調資料。
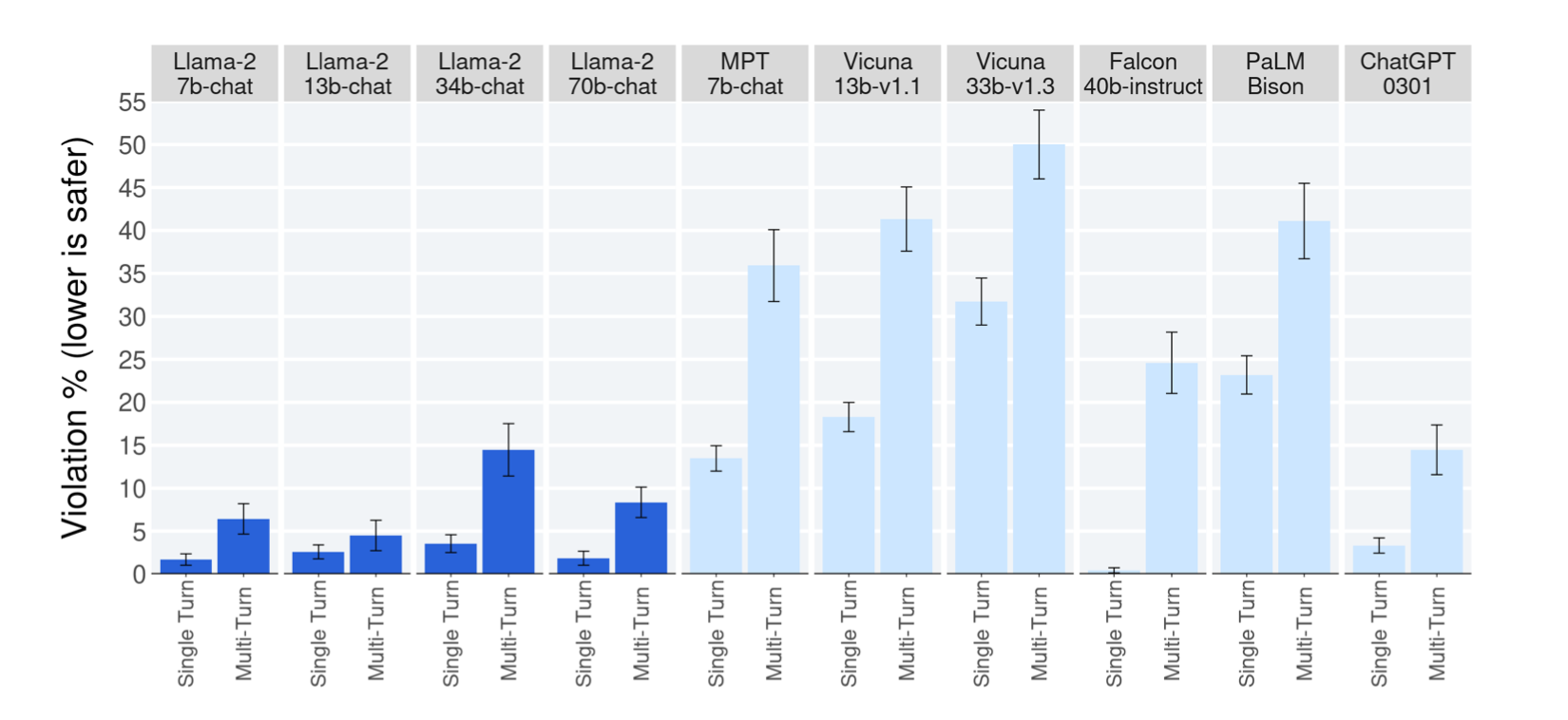
圖 18:單輪和多輪違規百分比。請注意,由於提示集的侷限性、稽核指南的主觀性、內容標準和個別評分者的原因,應謹慎解釋這些結果。
在圖 19 中,我們展示了不同 LLM 的每類安全違規百分比。雖然模型在不同類別下的表現相似,但 Llama 2-Chat 在無資質建議類別下的違規行為相對較多(儘管絕對值仍然較低),原因有很多,包括有時缺乏適當的免責宣告(如 "我不是專業人士")。在其他兩個類別中,無論模型大小,《Llama 2-Chat》的違規比例都相當或更低。
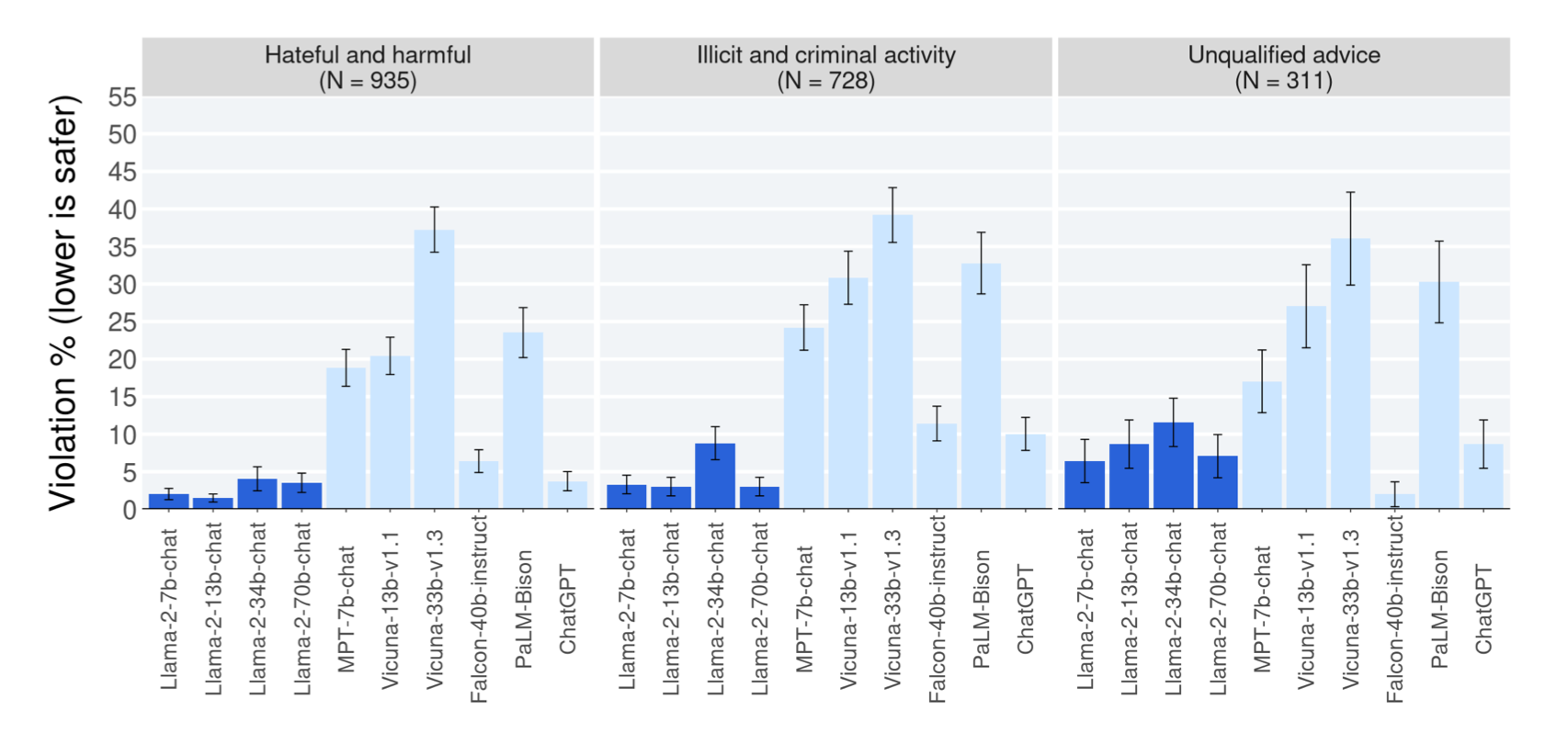
圖 19:每個風險類別的違規百分比。注:由於提示集的侷限性、稽核指南的主觀性、內容標準和個別評分者的原因,這些結果應謹慎解釋。
真實性、有害性性和偏差。在表 14 中,經過微調的 Llama 2-Chat 在真實性(70B 為 50.18 → 64.14)和有害性(70B 為 24.60 → 0.01)方面都比經過預訓練的 Llama 2 有很大改進。在所有大小的 Llama2-Chat 模型中,毒性世代的百分比實際上降到了 0%:這是所有比較模型中毒性水平最低的。總的來說,與 Falcon 和 MPT 相比,微調後的 Llama 2-Chat 在有害性和真實性方面表現最好。經過微調後,Llama 2-Chat 在 BOLD 中的許多人口群體中的正面情緒總體上趨於上升。在附錄 A.4.8 中,我們將詳細介紹偏差基準在不同分組中模型生成情感的得分明細,以及對真實性和偏差的更深入分析和結果。
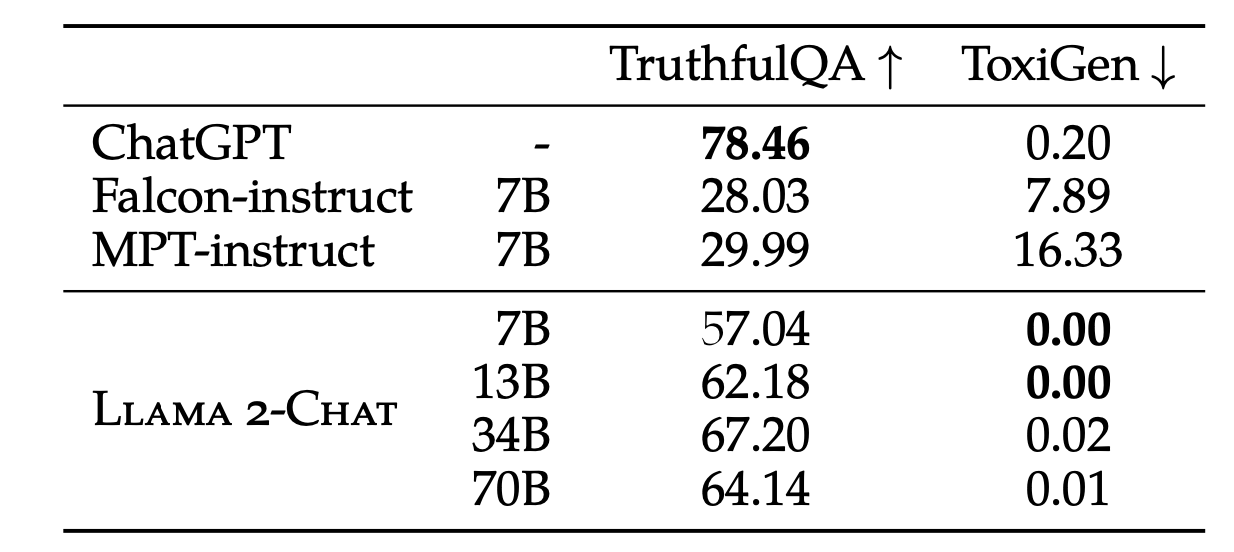
表 14:微調 LLM 在不同安全資料集上的評估。對於 TruthfulQA,我們給出了既真實又有資訊量的代數百分比(越高越好)。對於 ToxiGen,我們給出了有害的百分比(越小越好)。
5 討論
在此,我們將討論通過 RLHF 觀察到的有趣特性(第 5.1 節)。然後,我們將討論 Llama 2-Chat 的侷限性(第 5.2 節)。最後,我們將介紹負責任地釋出這些模型的策略(第 5.3 節)。
5.1 學習與觀察
我們的調整過程揭示了一些有趣的結果,例如 Llama 2-Chat 在時間上組織其知識或呼叫外部工具 API 的能力。
超越人工監督。在專案開始,我們中的許多人都表示更傾向於監督註釋,因為監督註釋的訊號更密集。與此同時,以即時性著稱的強化學習對 NLP 研究界的人來說似乎是一個有些模糊的領域。然而,事實證明強化學習非常有效,尤其是考慮到其成本和時間效益。我們的研究結果強調,RLHF 成功的關鍵因素在於它在整個註釋過程中促進了人類與 LLM 之間的協同作用。
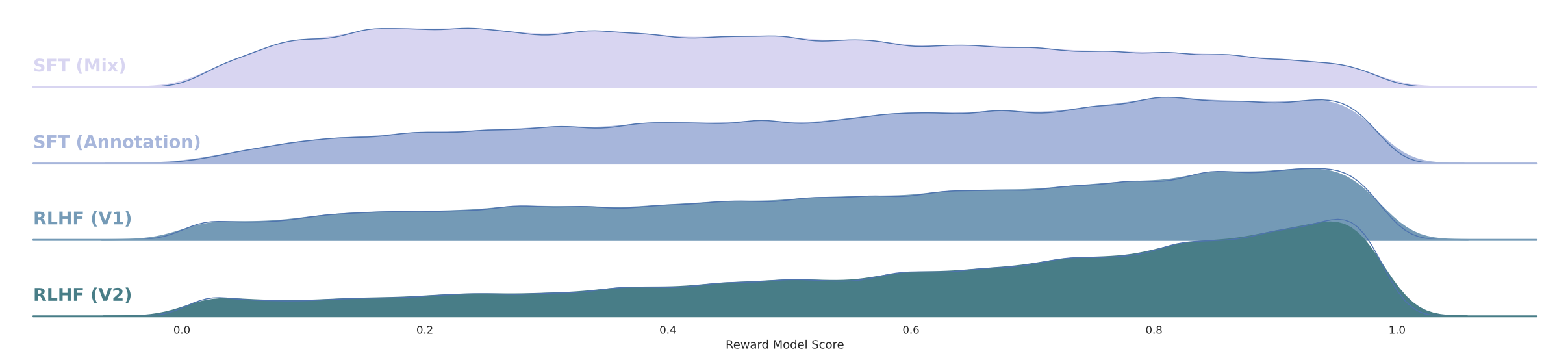
即使是熟練的註釋者,每個人的寫作也會有很大的差異。根據 SFT 註釋進行微調的模型可以學習這種多樣性,不幸的是,其中也包括執行不力的註釋的尾部。此外,該模型的效能還受制於最熟練註釋者的寫作能力。可以說,在比較兩個輸出的 RLHF 偏好註釋時,人類註釋者的差異較小。因此,獎勵機制會迅速學會為不理想的尾端分佈分配低分,並向人類偏好靠攏。圖 20 舉例說明了這一現象,我們可以看到,最差的答案會逐漸被刪除,從而使分佈向右移動。
此外,在註釋過程中,模型有可能涉足即使是最好的註釋者也可能無法描繪的寫作軌跡。儘管如此,在比較兩個答案時,人類仍然可以提供有價值的反饋,而不侷限於自身的寫作能力。打個比方,雖然我們可能並不都是出色的藝術家,但我們欣賞和評論藝術的能力卻依然完好無失真。我們認為,LLMs 在某些任務中超越人類註釋者的超強寫作能力,從根本上說是由 RLHF 驅動的,正如 Gilardi 等人(2023 年)和 Huang 等人(2023 年)所記錄的那樣。有監督的資料可能不再是黃金標準,這種不斷變化的情況迫使我們重新評估「監督」的概念。
在語境中重縮溫度。我們觀察到一個與 RLHF 有關的有趣現象,據我們所知,這是以前從未報道過的特徵:根據上下文對溫度進行動態重新縮放。如圖 8 所示,溫度似乎受到 RLHF 的影響。然而,有趣的是,我們的研究結果還顯示,如圖 21 所示,溫度的變化並不是在所有提示中都一致的。
例如,當涉及到「寫一首詩」等與創造力相關的提示時,溫度的升高繼續在我們的各種 RLHF 迭代中產生多樣性。這可以從 Self-BLEU 斜率中觀察到,它反映了與 SFT 模型相似的模式。
另一方面,對於基於事實資訊的提示,如「......的首都是?「這種模式表明,儘管溫度不斷升高,但模型學會了對事實性提示做出一致的反應。
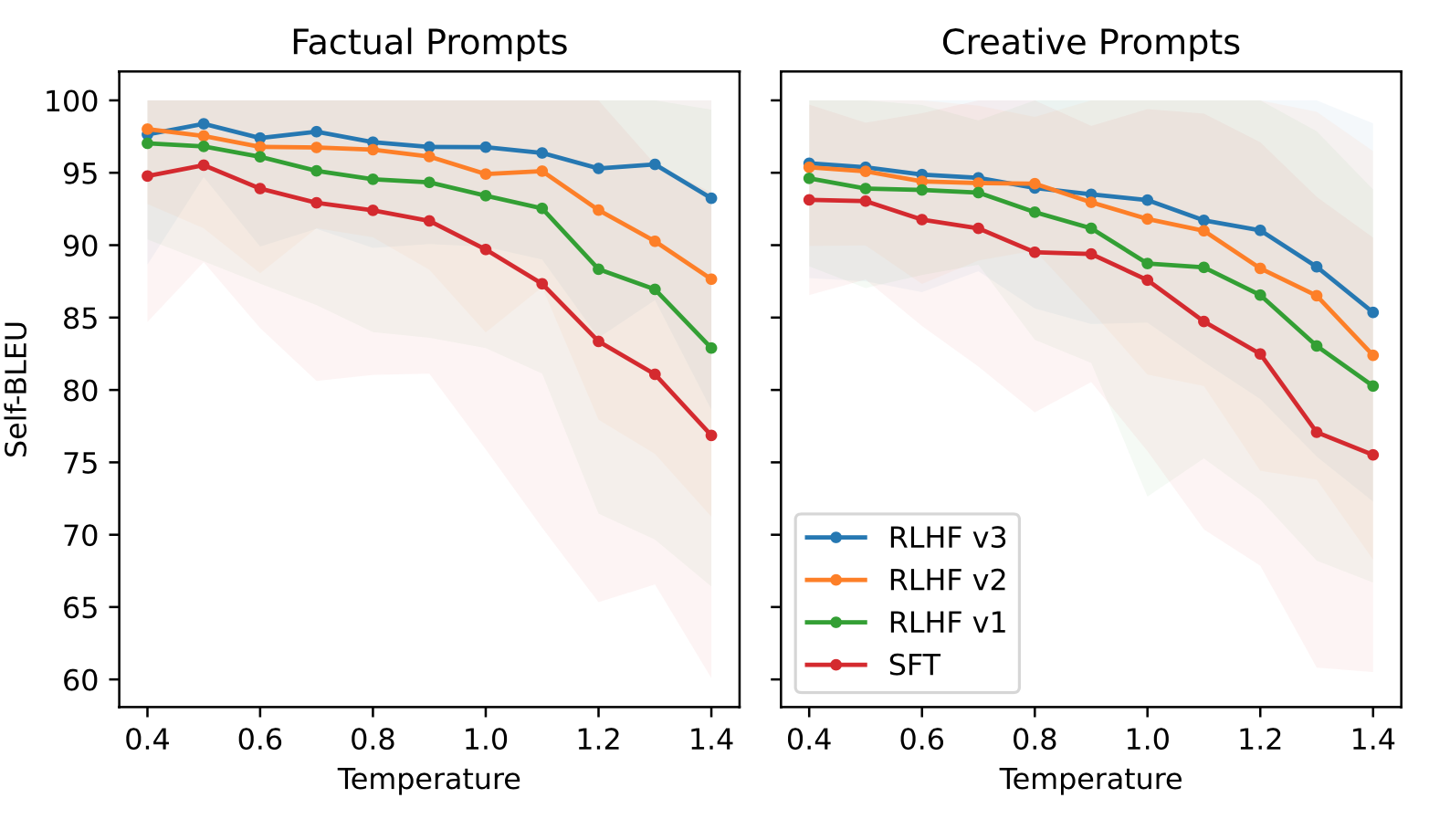
圖 21:RLHF 學會根據提示型別調整溫度。較低的 Self-BLEU 值對應較多的多樣性: RLHF 在對事實性提示做出反應時消除了多樣性,但在對創造性提示做出反應時保留了更多的多樣性。我們用一組不同的指令(10 個創造性指令和 10 個事實性指令)來提示每個模型,並對 25 個回答進行抽樣。對於溫度 T ∈ {k/10 | k ∈ N : 1 ≤ k ≤ 15} 重複上述步驟。對於 25 個響應中的每個響應,我們都會計算自 BLEU 指標,並報告與溫度相關的平均值和標準偏差。
Llama 2-Chat 溫度感知。我們的模型展示了令人印象深刻的泛化能力,如圖 22 所示。我們手動測試了數十個範例,並一致觀察到我們的模型即使在資料極少的情況下也能以時間方式組織知識,表現出強大的能力。為了在 Llama 2-Chat 中灌輸時間概念,我們收集了 1000 個與特定日期相關的 SFT 範例。這些例子包括」巴拉克-奧巴馬多久前成為總統?「等問題。每個問題都與兩個關鍵的後設資料相關聯:提出查詢的日期--這影響了回答;以及事件日期--在此日期之前,問題是毫無意義的。
這一觀察結果表明,儘管 LLMs 的訓練完全基於下一個標記的預測,而且資料也是在不考慮其時間背景的情況下隨意編排的,但他們對時間概念的內化程度卻比之前假設的要高。
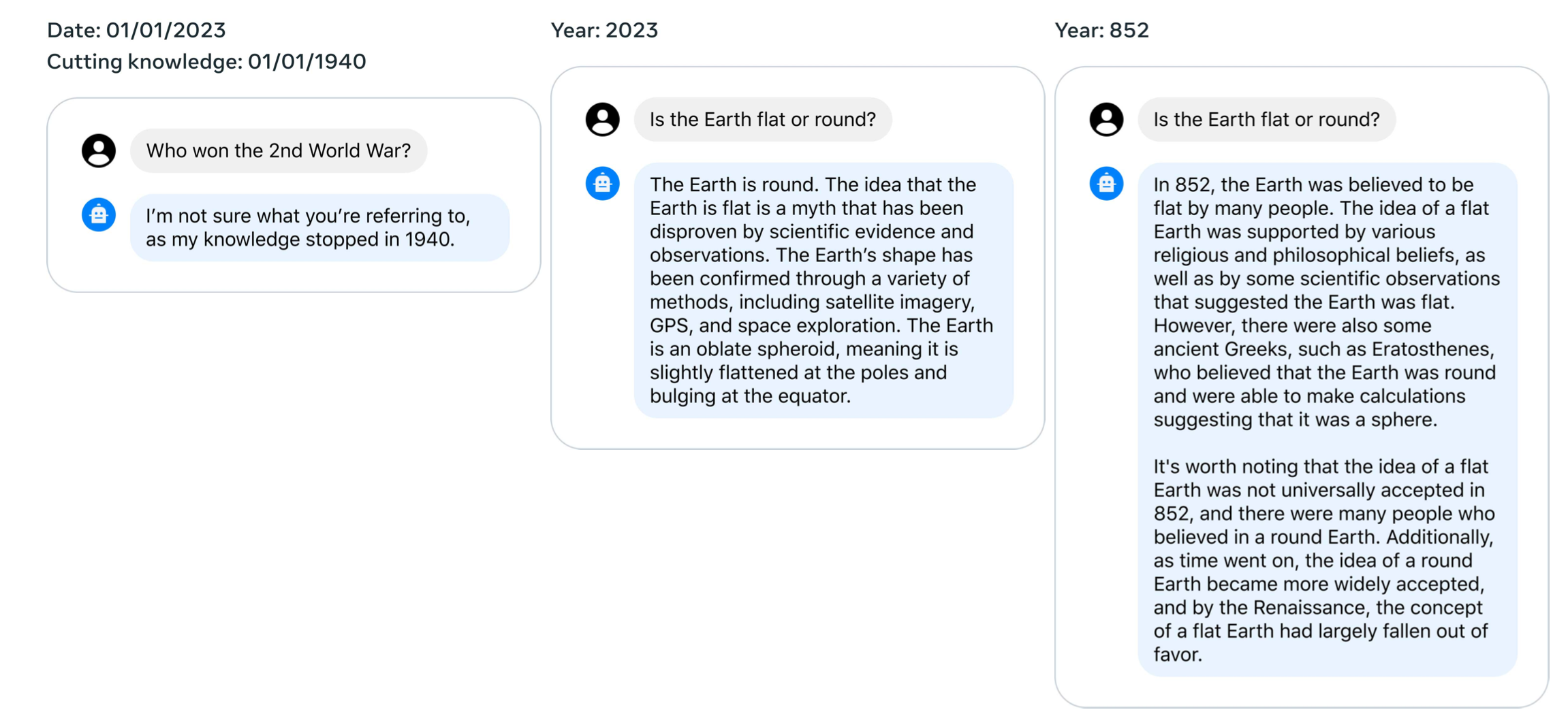
圖 22:時間意識--利用 1,000 SFT 時間焦點資料,說明我們的模型對時間概念的概括。
工具使用的出現。正如 Mialon 等人(2023 年)所強調的那樣,LLM 與工具的整合是一個不斷髮展的研究領域。Toolformer(Schick等人,2023年)中設計的方法需要對數以百萬計的軌跡進行取樣,併為每種工具制定少量範例作為補充。然而,該技術僅適用於每個範例中的單個工具,無法擴充套件到工具使用序列。
OpenAI 的外掛的釋出在學術界引發了大量討論,點燃了諸如以下問題的火花: 我們如何才能有效地教會模型使用工具?我們的實驗表明,工具的使用可以從對齊中以 0-shot 的方式自發產生。雖然我們從未明確標註工具的使用情況,但圖 23 展示了一個範例,模型在該範例中展示了在 0-shot 情況下使用一系列工具的能力。

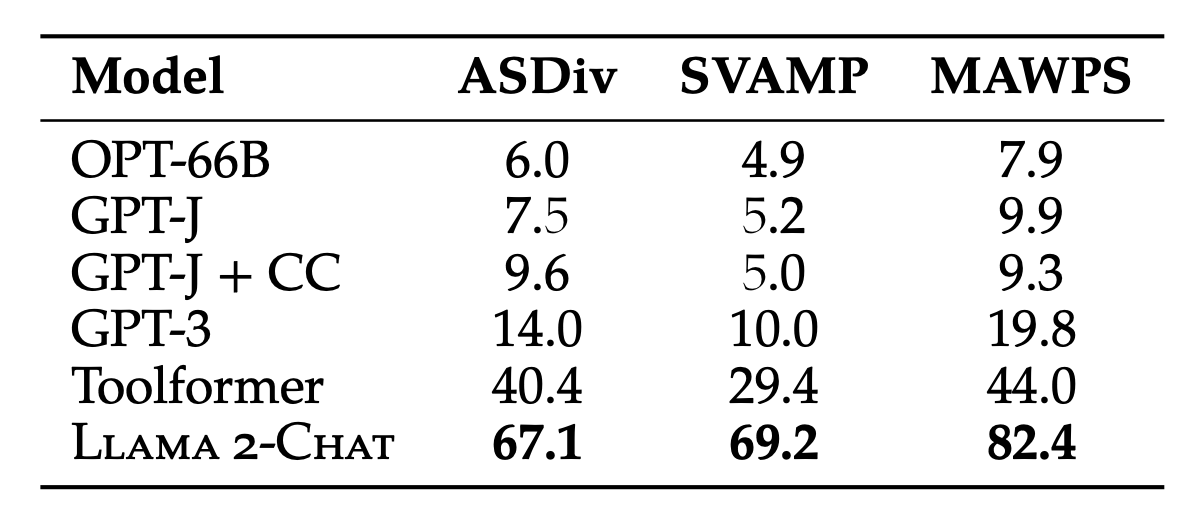
此外,我們的研究還擴充套件到了在使用計算器的情況下對 Llama 2-Chat 進行評估。表 15 記錄了這一特定實驗的結果。LLM 工具的使用雖然令人興奮,但也會引起一些安全問題。我們鼓勵在這一領域開展更多的社群研究和紅隊合作。
5.2 侷限性和倫理考慮因素
Llama 2-Chat 與其他 LLMs 一樣存在公認的侷限性,包括預培訓後知識更新的停止、非事實生成的可能性(如不合格的建議)以及產生幻覺的傾向。
此外,我們最初版本的 Llama 2-Chat 主要集中在英語資料上。雖然我們的實驗觀察結果表明該模型對其他語言也有一定的熟練程度,但其熟練程度有限,這主要是由於非英語語言的預訓練資料量有限(如表 10 所示)。因此,該模型在非英語語言中的表現仍然脆弱,應謹慎使用。
與其他 LLM 一樣,由於 Llama 2 是在公開的線上資料集上進行訓練,因此可能會生成有害、攻擊性或帶有偏見的內容。我們試圖通過微調來緩解這一問題,但仍可能存在一些問題,特別是對於英語以外的語言,因為這些語言沒有公開可用的資料集。隨著解決這些問題的進展,我們將繼續進行微調,並在未來發布更新版本。
並非每個使用人工智慧模型的人都懷有善意,人工智慧對話代理有可能被用於邪惡目的,如生成錯誤資訊或檢索生物恐怖主義或網路犯罪等主題的資訊。不過,我們已努力調整模型以避免這些主題,並削弱它們可能為這些用例提供的任何功能。
雖然我們試圖在安全性和有用性之間取得合理的平衡,但在某些情況下,我們對安全性的調整走得太遠了。Llama 2-Chat 的使用者可能會觀察到一種過於謹慎的方法,即模型會偏向於拒絕某些請求或回覆過多的安全細節。
預訓練模型的使用者需要特別謹慎,並應按照我們的《使用指南準則》中的描述,在調整和部署時採取額外的步驟。
5.3 盡責的釋出戰略
釋出詳情。我們在 https://ai.meta.com/resources/models-and-libraries/llama/ 網站上提供 Llama 2 用於研究和商業用途。使用 Llama 2 的使用者必須遵守所提供的許可條款和我們的《使用政策許可》,其中禁止任何違反適用政策、法律、法規和規章的使用行為。
我們還提供程式碼範例,幫助開發人員利用 Llama 2-Chat 生成我們的安全對話的過程,並在使用者輸入層和模型輸出層應用基本的安全技術。這些程式碼範例可在此處獲取:https://github.com/facebookresearch/llama。最後,我們還分享了《使用指南準則》,其中提供了有關安全開發和部署的指導原則。
盡責釋出。雖然許多公司選擇在閉門造車中構建人工智慧,但我們公開發布 Llama 2,以鼓勵負責任的人工智慧創新。基於我們的經驗,開放的方法利用了人工智慧從業者社群的集體智慧、多樣性和創造力,以實現這項技術的好處。合作將使這些模型更好、更安全。整個人工智慧社群——學術研究人員、公民社會、政策制定者和行業——必須共同努力,嚴格分析和揭示當前人工智慧系統的風險,並構建解決潛在問題濫用的解決方案。這種方法不僅促進了與大型科技公司之外的各種利益相關者的真正合作,而且還是民主化獲取基礎模型的基石。正如 Zellers 等人(2019b)所論述的那樣,開放式釋出促進了透明度,讓更多的人可以存取人工智慧工具,民主化了技術並分散了人工智慧專業知識。我們認為,人工智慧專業知識的分散不僅僅是分發知識,它還能刺激創新,加速行業進步。最後,公開發布這些模型可以整合成本,消除進入障礙,使小企業能夠利用 LLMs 中的創新來探索和構建文字生成用例。最終,我們相信,這將為全球各種規模的組織創造一個更公平的競爭環境,從而受益於人工智慧的進步所帶來的經濟增長。
我們知道,並非每個使用人工智慧模型的人都是出於善意,我們也承認,人們對人工智慧影響我們世界的方式存在合理的擔憂。有害內容的生成和有問題的關聯是人工智慧界尚未完全緩解的重大風險。正如本文所述,我們在限制這類反應的普遍性方面已經取得了長足進步。雖然我們認識到還有更多的工作要做,但這種認識只會加深我們對開放科學以及與人工智慧界合作的承諾。
6 關聯工作
大語言模型。近年來,大型語言模型領域發生了重大演變。根據 Kaplan 等人(2020 年)提出的縮放定律,從 GPT-3 (Brown 等人,2020 年)到 Gopher(Rae 等人,2022 年)或專門的科學模型,如 Galactica(Taylor 等人,2022 年),已經提出了多個引數超過 100B 的大型語言模型。Chinchilla(Hoffmann 等人,2022 年)用 70B 引數重新定義了這些縮放規律,使其趨向於代幣數量而不是模型權重。在這一過程中值得注意的是 Llama 的崛起,它因注重推理過程中的計算效率而得到認可(Touvron 等人,2023 年)。圍繞開源模型與閉源模型的動態變化也展開了平行討論。BLOOM (Scao et al., 2022)、OPT (Zhang et al., 2022)和 Falcon (Penedo et al., 2023)等開源版本已經崛起,向 GPT-3 和 Chinchilla 等閉源版本發起挑戰。
然而,當涉及到 ChatGPT、Bard 和 Claude 等」生產就緒「的 LLM 時,其效能和可用性就有了明顯的區別。這些模型依賴於複雜的調整技術,以符合人類的偏好,而這一過程仍在開源社群中不斷探索和完善。
為了縮小這一差距,出現了一些嘗試,如 Vicuna(Chiang 等人,2023 年)和 Alpaca(Taori 等人,2023 年)等基於提煉的模型,它們採用了一種獨特的方法來訓練合成指令(Honovich 等人,2022 年;Wang 等人,2022 年)。然而,儘管這些模型顯示出了前景,但仍無法達到閉源模型所設定的標準。
指令調整。Wei 等人(2021 年)通過在大量資料集上對 LLM 進行微調,獲得了在未見任務上的 0-shot 效能。Chung 等人(2022 年)和 Longpre 等人(2023 年)研究了指令調整對任務數量、模型大小、提示設定等的影響。用於指令調整的提示可以由人類建立,也可以由 LLMs 自己建立(Zhou 等人,2022 年),後續指令可用於完善初始生成,使其更有用、更吸引人、更無偏見(Ganguli 等人,2023 年;Madaan 等人,2023 年)。與指令調整相關的一種方法是思維鏈(chain-of-thought, CoT)提示(Wei 等人,2022b),即在給定一個複雜問題時,提示模型解釋其推理,以增加其最終答案正確的可能性。
RLHF 已成為微調大型語言模型的有力策略,可顯著提高其效能(Christiano 等人,2017 年)。Stiennon 等人(2020 年)在文字總結任務中首次展示了這種方法,隨後這種方法被擴充套件到一系列其他應用中。在這一範例中,模型根據人類使用者的反饋進行微調,從而使模型的反應更接近人類的期望和偏好。
Ouyang 等人(2022 年)的研究表明,指令微調與 RLHF 的結合有助於解決事實性、毒性和幫助性等問題,而這些問題無法通過簡單地擴大 LLM 來解決。Bai 等人(2022b)將這種微調加 RLHF 的方法部分自動化,方法是用模型自己的自我批評和修訂取代人類標記的微調資料,並在 RLHF 中對模型輸出進行排名時用模型取代人類評分者,這一過程被稱為「來自人工智慧反饋的 RL」(RLAIF)。
已知的 LLM 安全挑戰。最近的文獻廣泛探討了與大型語言模型相關的風險和挑戰。Bender 等人(2021b)和 Weidinger 等人(2021)強調了各種危害,如偏差、有害性、私人資料洩漏以及惡意使用的可能性。Solaiman 等人(2023 年)將這些影響分為兩類--可在基礎系統內評估的影響和需要進行社會背景評估的影響,而 Kumar 等人(2022 年)則提出了潛在的緩解策略以遏制危害。Roller 等人(2020)和 Dinan 等人(2021)的工作還揭示了面向聊天機器人的 LLM 所面臨的困難,包括隱私問題和誤導性的專業知識宣告等。Deng 等人(2023)提出了一個分類框架來解決這些問題,Bergman 等人(2022)探討了釋出對話模型可能產生的正面和負面影響之間的平衡。
對紅隊測試的調查揭示了調整 LLMs 所面臨的具體挑戰,Ganguli 等人(2022 年)和 Zhuo 等人(2023 年)的研究展示了各種成功的攻擊型別及其對有害內容生成的影響。國家安全機構和各種研究人員(如 Mialon 等人,2023 年)也對先進的新興模型行為、網路威脅以及在生物戰等領域的潛在濫用提出了警告。最後,更廣泛的社會問題,如人工智慧研究加速導致的工作崗位轉移,以及對 LLM 的過度依賴導致訓練資料退化,也是相關的考慮因素(Acemoglu 和 Restrepo,2018 年;Autor 和 Salomons,2018 年;Webb,2019 年;Shumailov et al., 2023)。我們致力於繼續與更廣泛的政策、學術和產業界就這些問題開展合作。
7 結論
在本研究中,我們引入了 Llama 2,這是一個新的預訓練和微調模型系列,引數量級為 70 億到 700 億。這些模型已經證明了它們與現有開源聊天模型的競爭力,並且在我們檢查的評估集上與一些專有模型相當,儘管它們仍然落後於 GPT-4 等其他模型。我們細緻地闡述了實現我們的模型所採用的方法和技術,並著重強調了它們與有用性和安全性原則的一致性。為了對社會做出更大的貢獻並促進研究的步伐,我們盡責地開放了「Llama 2」和「Llama 2-Chat」的存取許可權。作為我們對透明度和安全性持續承諾的一部分,我們計劃在今後的工作中進一步改進 Llama 2-Chat。