Redis 主從同步原理
一、什麼是主從同步?
主從同步,就是將資料冗餘備份,主庫(Master)將自己庫中的資料,同步給從庫(Slave)。
從庫可以一個,也可以多個,如圖所示:
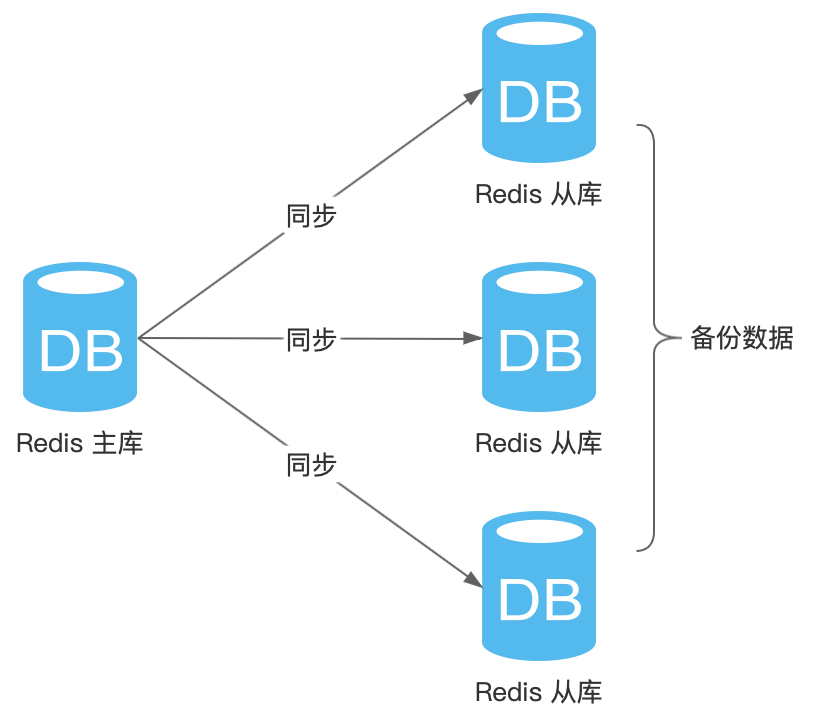
二、為什麼需要主從同步?
Redis 雖然有 RDB 和 AOF 持久化技術,可以在伺服器重啟的情況下保證記憶體中的資料不會丟失(但不意味著資料不丟,重啟的時候還是會有不可用的情況)。
但是如果伺服器關閉後,再也起不來了(比如硬體故障),那意味著資料是完全丟失的!會對業務產生重大影響。
所以,主從同步的必要性,在於資料的高可用。它可以保證機器故障時,還有其他的伺服器可以進行故障轉移。
問題來了,多臺伺服器冗餘同一份資料,Redis 是如何保證資料的一致性的?
三、Redis 是如何做到主從同步的?
簡單概括,有兩點:
- 一切修改只在主庫進行:即主庫可讀可寫,從庫唯讀不可寫;
- 寫操作從主庫同步到從庫:全量同步、增量同步。
(一)全量同步
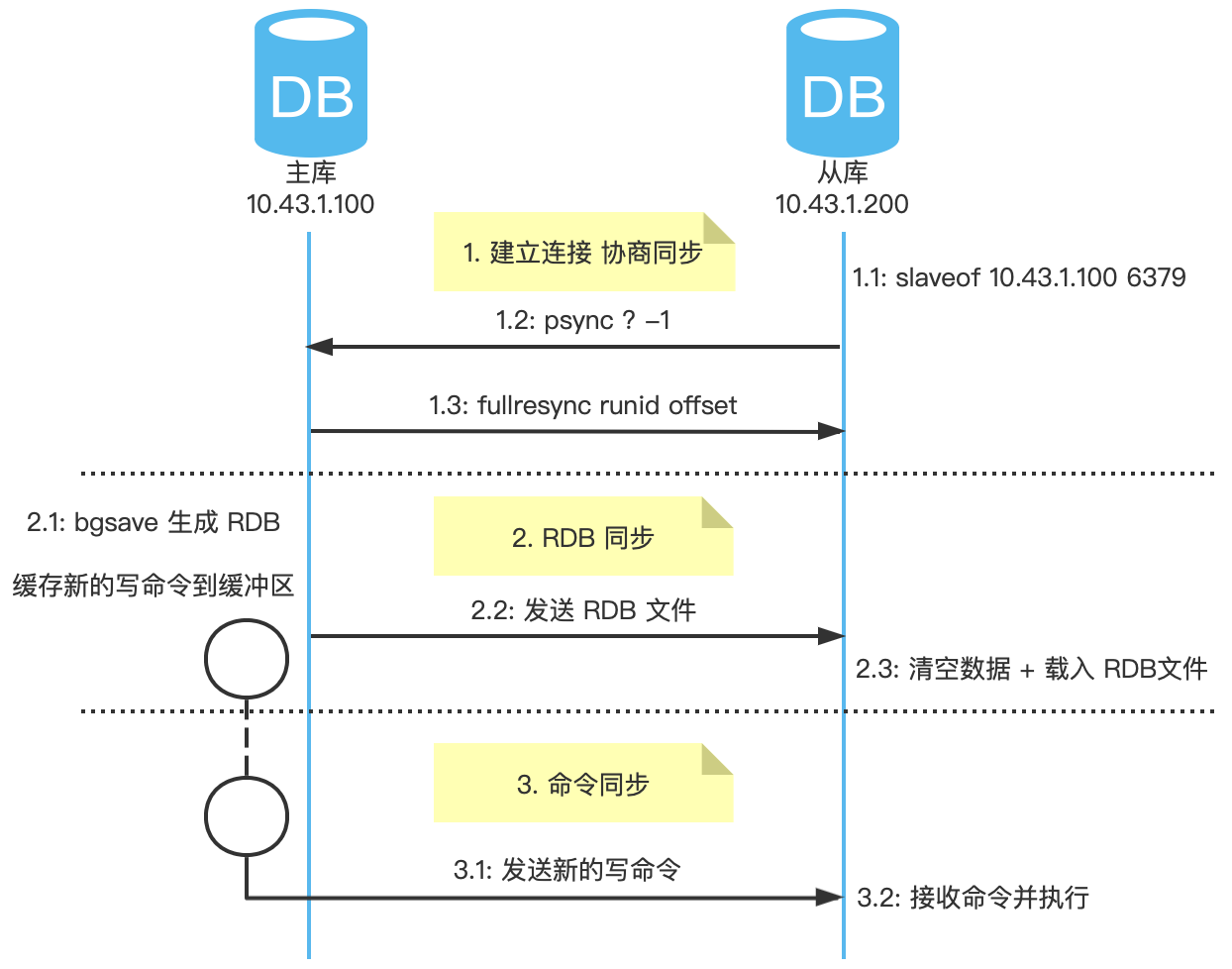
1. 建立連線 協商同步
1.1 使用使用者端 redis-cli 連線從庫,執行 replicaof 命令,指定主庫 IP 和埠;
1.2 從庫響應後,執行 psync 命令,它包含 主庫 runid 和 複製偏移量 offset 兩個引數:
- runid:啟動時自動生成隨機唯一 ID。首次同步時,主庫 runid 未知,所以為
?; - offset:表示複製的進度,第一次同步時,其值為
-1。
1.3 主庫收到 psync 命令後,使用 FULLRESYNC 命令響應從庫,同時也包含 主庫 runid 和 複製偏移量 offset 兩個引數,從庫會記錄這兩個引數。
注:replicaof 命令等同於 slaveof 命令,Redis 5.0 之前使用 slaveof 命令。
2. RDB 同步
2.1 主庫執行 bgsave 命令,此時將 fork 出子程序生成 RDB 檔案,新命令會寫入到緩衝區;
2.2 傳送 RDB 檔案到從庫;
2.3 從庫清空資料後,載入 RDB 檔案。
注一:為保證資料一致性,
bgsave執行後,主庫會持續寫入新命令到緩衝區,直到從庫載入 RDB 完成;注二:bgsave 建立了子程序,子程序獨立負責 RDB 生成的工作,生成 RDB 的過程中,不會阻塞 Redis 主庫,主庫依然可以正常處理命令。
3. 命令同步
3.1 完成 RDB 載入後,從庫會回覆確認訊息給主庫,主庫會將緩衝區的寫命令傳送給從庫;
3.2 從庫接收主庫的寫命令並執行,使得主從資料一致。
注:命令執行後,長連線會一直保持,寫操作命令也會一直同步,保證主從資料的一致性;
這個過程也稱為「基於長連線的命令傳播」。
(二)增量同步
命令傳播的過程中,如果出現 網路故障 導致連線斷開,此時新的寫命令將無法同步到從庫。
即便是抖動後斷開又恢復網路連線,但此時 TCP 連線已經斷開,資料肯定是需要重新同步了。
- 在 Redis 2.8 之前,從庫只能和主庫重新發起全量同步,對於較大的 RDB 檔案,網路恢復時間較長;
- 從 Redis 2.8 開始,從庫已支援增量同步,只會把斷開的時候沒有發生的寫命令,同步給從庫。
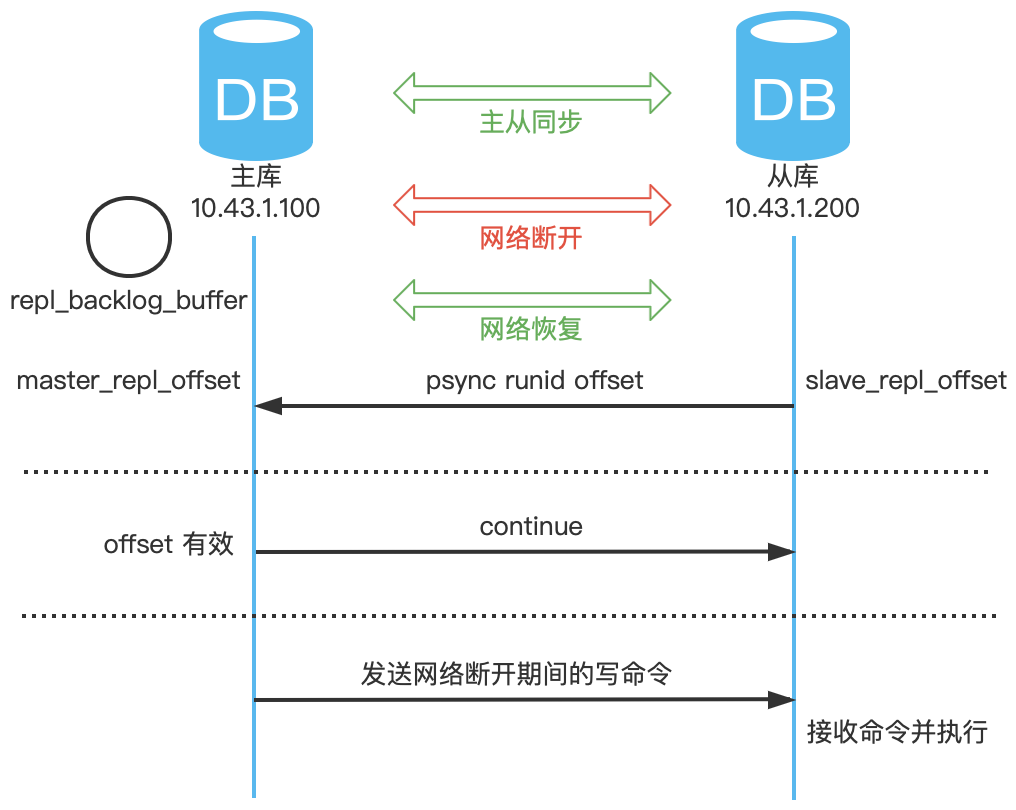
詳細過程如下:
- 網路恢復後,從庫發生 psync 命令給主庫,並攜帶之前主庫返回的 runid,還有複製的偏移量 offset;
- 主庫收到命令後,核查 runid 和 offset,確認沒問題將響應
CONTINUE命令; - 主庫傳送網路斷開期間的寫命令,從庫接收命令並執行。
實際上,主庫在進行命令傳播的過程中,做了兩個事情:
- 傳送寫命令給從庫;
- 寫命令寫入
repl_backlog_buffer複製積壓緩衝區,儲存最近傳播的寫命令。
複製積壓緩衝區,是一個環形緩衝區。主庫除了擁有 repl_backlog_buffer,還存在複製點位 master_repl_offset;
同理,從庫,也有複製點位 slave_repl_offset;
如果從庫的 psync 命令指定的 offset,資料還存在 repl_backlog_buffer 緩衝區裡,也就是:
master_repl_offset - size < slave_repl_offset,即主庫最小的偏移量,小於從庫的偏移量,說明資料還在環形緩衝區裡。
所以,只要主庫的緩衝區足夠大,足以容納最近的寫命令(Redis 協定),就可以在網路中斷後使用增量同步了。
預設 repl_backlog_buffer = 1M,如果寫入資料量較大,比如 1M/s,顯然,網路故障 1秒後,複製積壓緩衝區資料無效,所以應該增大它的值。
具體大小,需要根據實際情況確定。建議設定 10M 以上,大概就是 10s 以內的中斷,因為 Redis 伺服器啟動也需要一定時間。
文章來源於本人部落格,釋出於 2022-05-28,原文連結:https://imlht.com/archives/259/