Mysql高階3-索引的結構和分類
一、索引概述
1.1 索引的介紹
索引index:是幫助 Mysql 高效獲取資料 的 有序的資料結構,在資料之外,資料庫系統維護著的滿足特定查詢演演算法的資料結構,這些資料結構以某種方式參照(指向)資料,這樣就可以在這些資料結構上實現高階查詢演演算法,這種資料結構就是索引
1.2 索引的優缺點
-
- 優點1:提高資料檢索的效率,降低資料庫的IO成本
- 優點2:通過索引列對資料進行排序,降低資料排序的成本,降低CPU的消耗
- 缺點1:索引列也要佔磁碟空間。
- 缺點2:索引大大提高了查詢效率,同時卻也降低了更新表的速度,如對錶進行insert,update,delete時,效率降低
二、索引結構
2.1 Mysql的索引常見結構
Mysql的索引是在儲存引擎層實現的,不同的儲存引擎有不同的結構,主要包含一下幾種
-
- B+樹:最常見的索引型別,大部分引擎都支援B+樹索引
- Hash索引:底層資料結構是用雜湊表實現的,只有精確匹配索引的查詢才有效,不支援範圍查詢
2.2 Mysql常見索引對不同引擎的支援
-
- B+樹:InnoDB(支援)、MyISAM(支援)、Memory(支援)
- Hash索引:InnoDB(不支援)、MyISAM(不支援)、memory(支援)
2.3 二元樹實現索引的弊端

說明1:實際中的索引是沒有使用二元樹的,因為二元樹具有一下的弊端
說明2:當順序插入時,會形成一個連結串列,查詢效能大大降低,巨量資料量的情況下,層級較深,檢索速度慢。
說明3:特殊二元樹紅黑樹當做索引是,巨量資料量情況下,層級比較深,檢索速度慢
2.4 B樹實現索引的弊端
以一個最大度數(max-degree)為5(5階)的b樹為例(每個節點最多儲存4個key,5個指標)
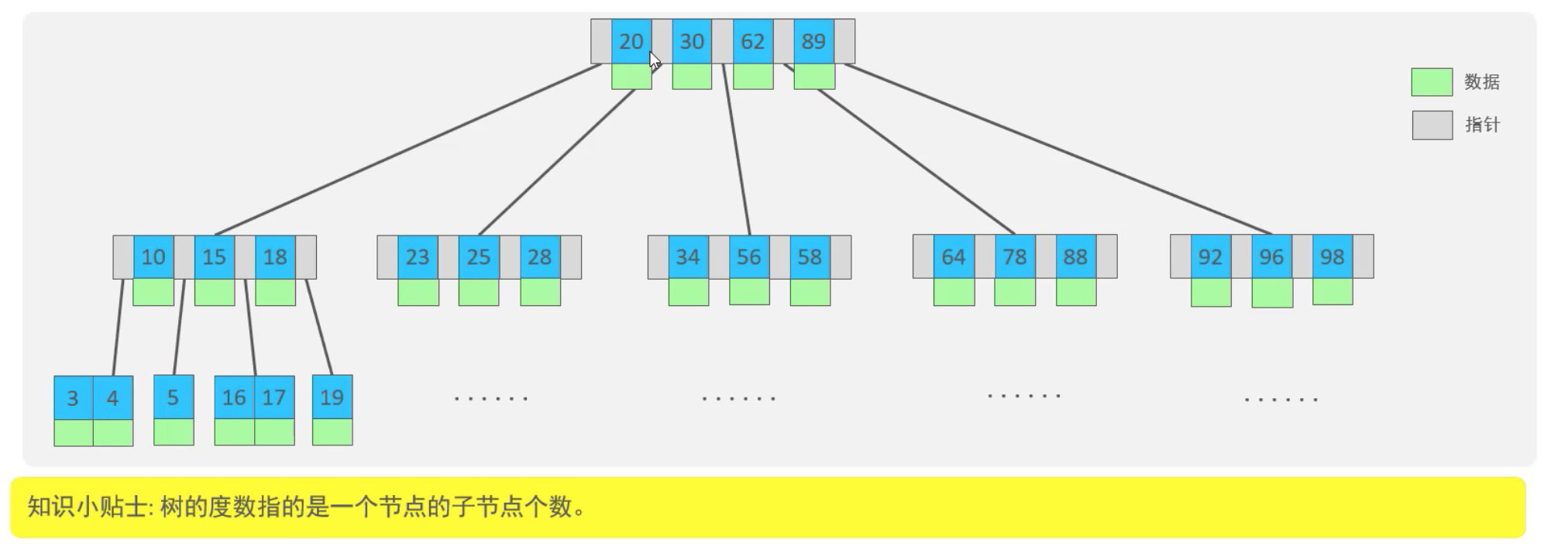
說明:B樹的資料會存在每個節點上,而節點存在頁(2.6 Mysql索引對B+樹的優化有說明)上面,每頁的大小為16K,這樣每個頁能存放的索引就比較少,導致同樣資料體積小,層級要比B+樹深。
2.5 B+樹實現索引
以一個最大度數(max-degree)為4(4階)的b+樹為例
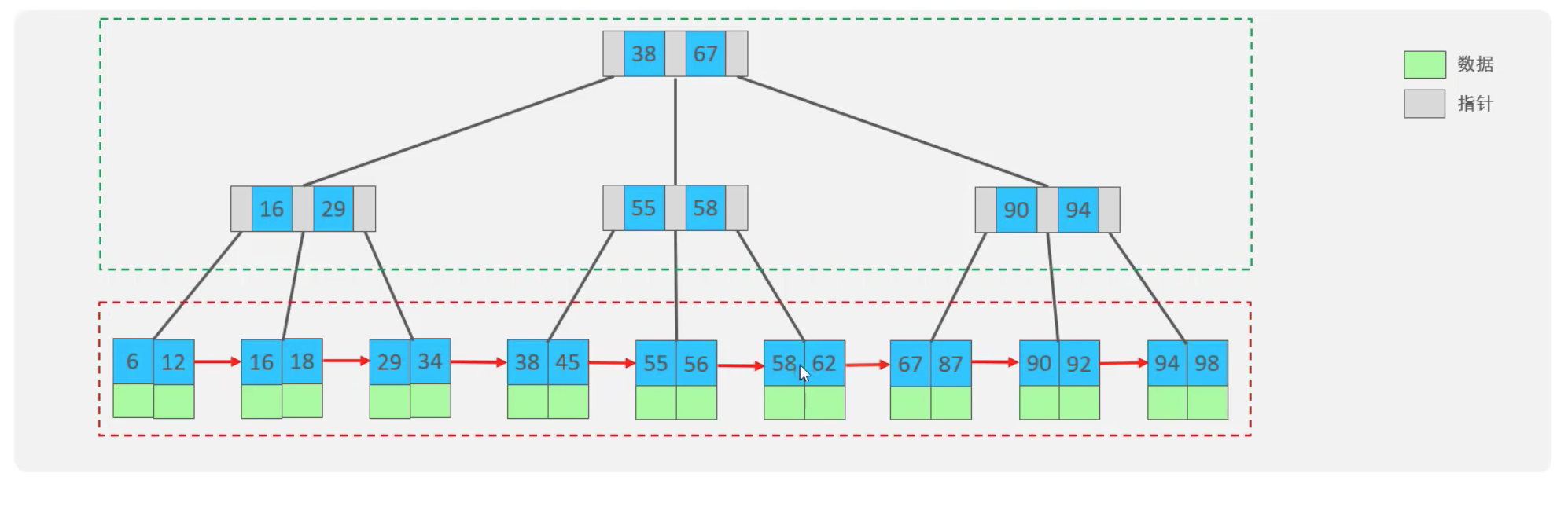
說明:對比較與B樹
1、所有的資料都會出現在葉子節點上
2、葉子節點形成一個單向連結串列
2.6 Mysql索引對B+樹的優化
Mysql索引資料結構對經典的B+樹進行了優化,在原來的B+樹基礎上,增加了一個指向相鄰葉子節點的連結串列指標,就行了帶有順序指標的B+樹,提高了區間存取的效能
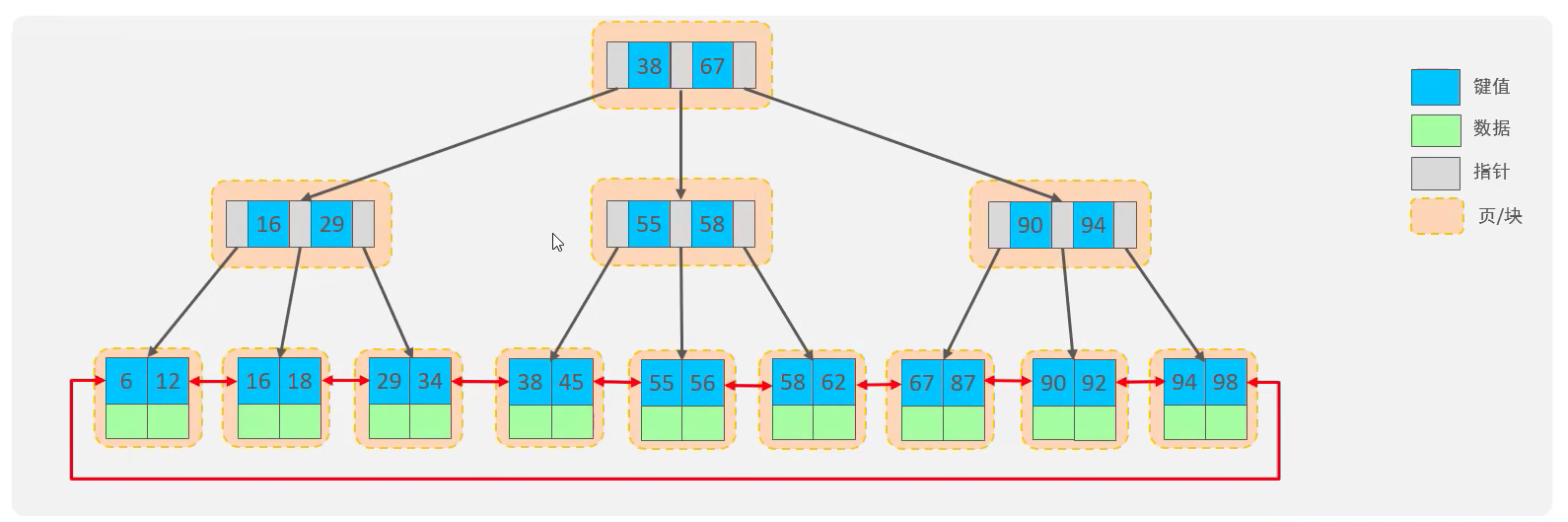
說明:每頁在InnoDB中預設16K
2.7 hash索引
雜湊索引就是採用一定的hash演演算法,將鍵值換成新的hash值,對映到對應的槽位上,然後儲存在hash表中
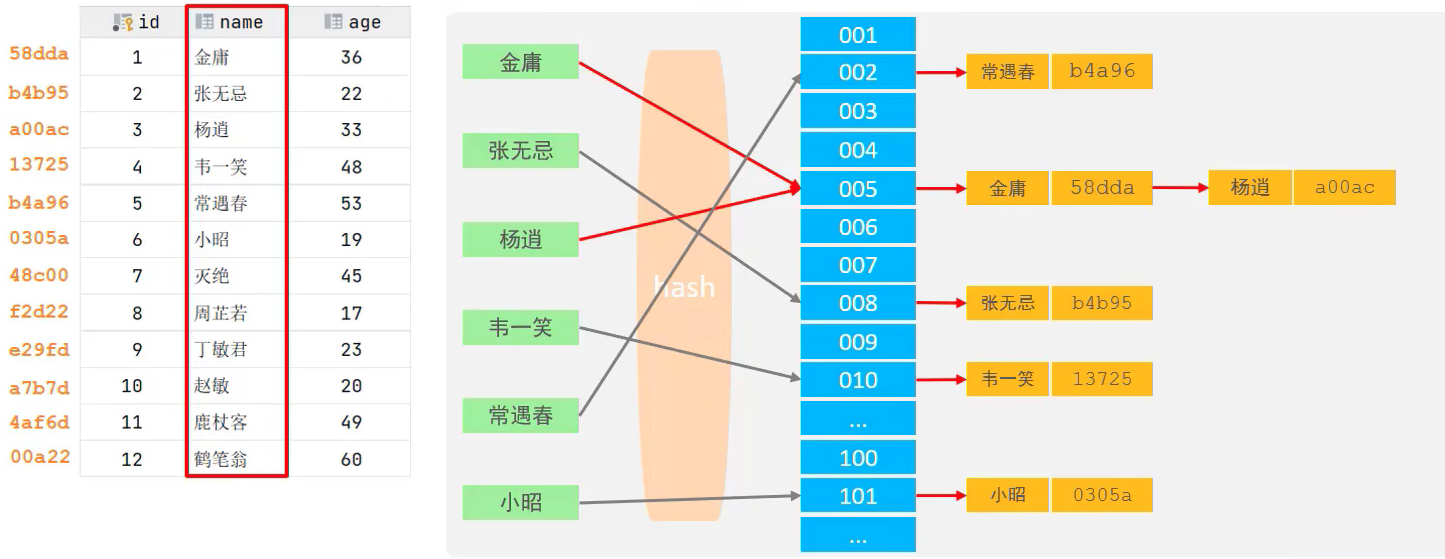
說明:如果兩個(或者多個)鍵對映到同一個槽位上,他們就產生了hash衝突,也稱hash碰撞,可以通過連結串列來解決
2.8 hash索引特點
-
- hash索引只能用於對等比較(=,in),不支援範圍查詢(between,>,<)
- 無法利用索引完成排序操作
- 查詢效率高,通常只需要一次檢索就可以了,效率通常要高於B+樹索引
- 在Mysql中,支援hash索引的事Memory引擎,而InnoDB中具有自適應hash功能,hash索引是儲存引擎根據B+樹索引在指定條件下自動構建的
2.9 InnoDB引擎選擇B+樹的優勢
-
- 相對於二元樹,層級更少,搜尋效率高
- 對於B樹,無論是葉子節點還是非葉子節點,都會儲存資料,這樣導致一頁中儲存的鍵值減少,指標跟著減少,同樣儲存大量資料,只能增加樹的高度,導致效能降低。
- 相對於hash索引,B+樹支援範圍匹配及排序操作
三、索引分類
3.1 主鍵索引
針對於表中主鍵建立的索引,預設自動建立,只能有一個, 關鍵字:primary
3.2 唯一索引
避免同一個表中某資料列中的值重複,可以有多個,關鍵字:unique
3.3 常規索引
快速定位特定資料,可以有多個,
3.4 全文索引
全文索引查詢的是文字中的關鍵字,而不是比較索引中的值,可以有多個,fulltext
3.5 聚集索引
在InnoDB中,根據索引的儲存形式劃分的,將資料儲存與索引放到一起,索引結構的葉子節點儲存了行資料,必須有,而且只有一個
-
- 如果存在主鍵,主鍵索引就是聚集索引
- 如果不存在主鍵,將使用第一個唯一(unique)索引作為聚集索引
- 如果表沒有主鍵,也沒有合適的唯一索引,則InnoDB會自動生成一個rowid作為隱藏的聚集索引
3.6 二級索引
在InnoDB中,根據索引的儲存形式劃分的,將資料與索引分開儲存,索引結構的葉子節點關聯的是對應的主鍵,可以存在多個
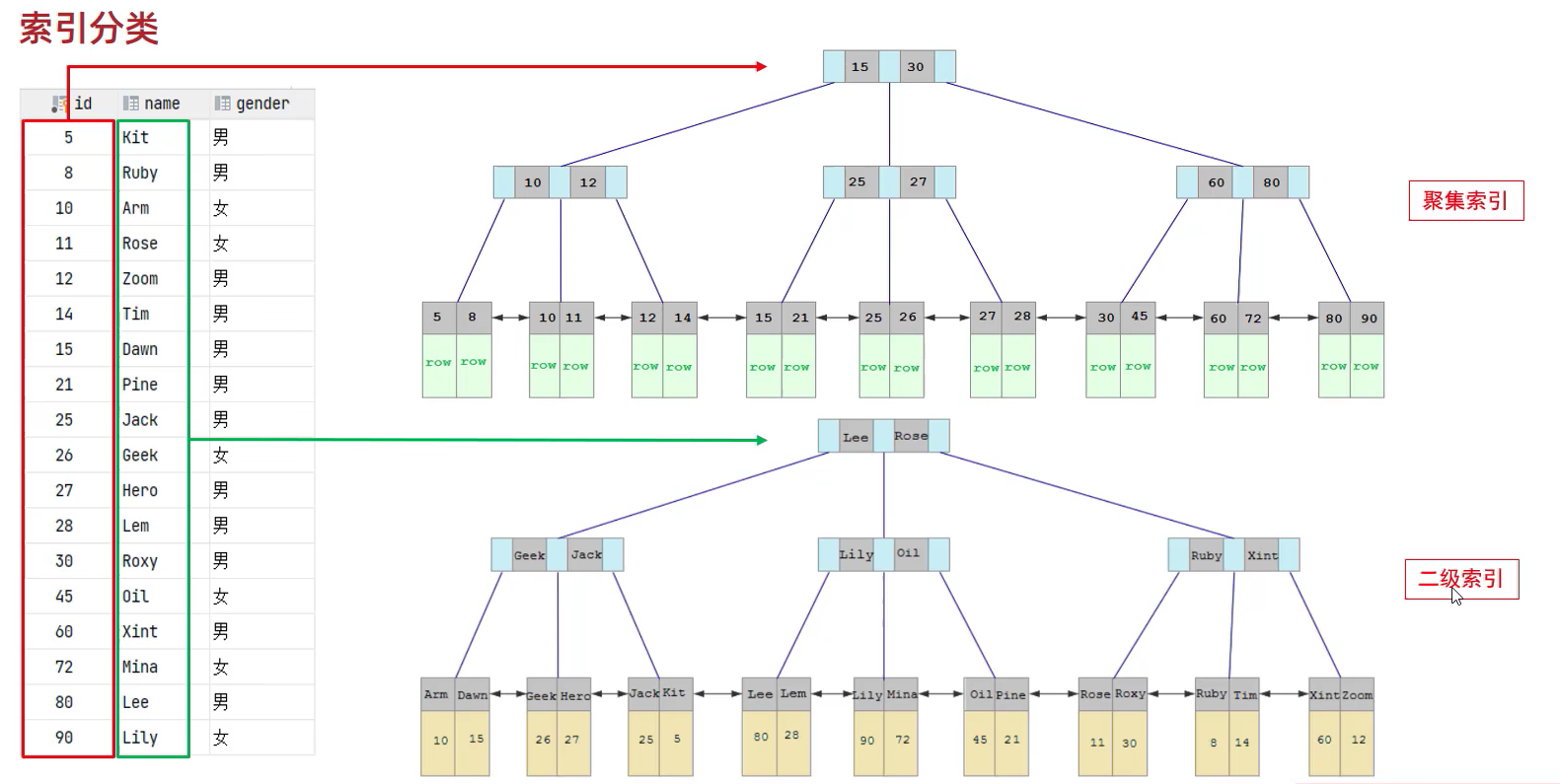
說明:聚集索引下面存放的是整行的資料,二級索引下面存放的對應的主鍵,要不然聚集索引下存放了整行資料,二級索引下也放整行資料,就會很冗餘
3.7 回表查詢
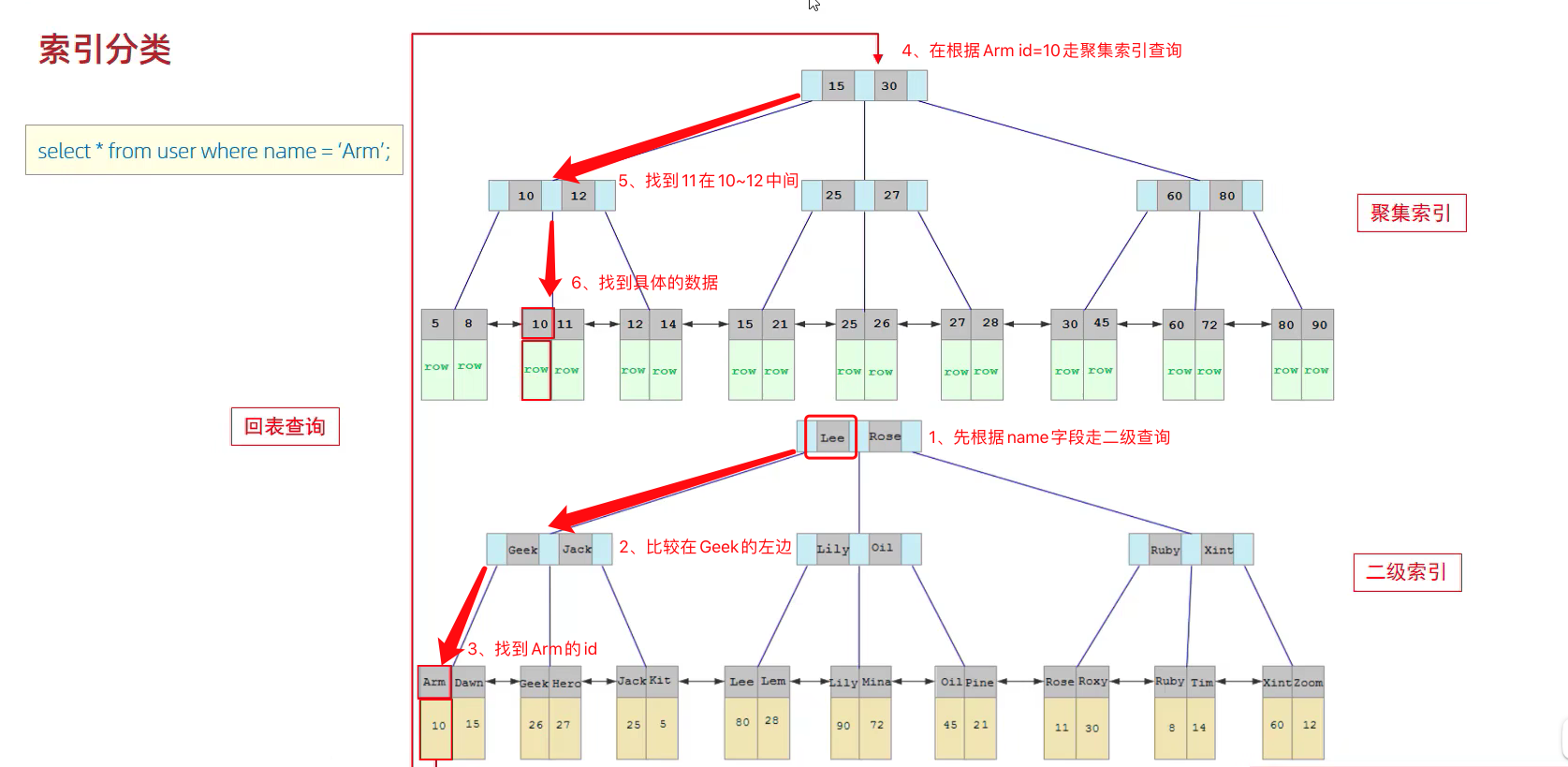
說明1:首先根據name欄位走二級索引
說明2:找到Arm對應的id=10
說明3:然後再根據id=10找到對應的資料
說明4:整個過程也叫做回表查詢
四、索引語法
4.1 檢視索引
show index from 表名
範例:
mysql> show index from account; +---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+ | Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression | +---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+ | account | 0 | PRIMARY | 1 | id | A | 4 | NULL | NULL | | BTREE | | | YES | NULL | +---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+ 1 row in set (0.00 sec)
說明:account 有一個主鍵索引
4.2 建立索引
create [unique | fulltext] index 索引名 on 表名(索引的列名, ..);
說明1:如果建立索引的欄位是唯一的,值都不重複,可以加unique約束,說明這是一個唯一欄位索引
說明2:fulltext 是全文檢索索引,主要針對大的文字欄位
mysql> create index name_idx on account(name); Query OK, 0 rows affected (0.03 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> show index from account; +---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+ | Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression | +---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+ | account | 0 | PRIMARY | 1 | id | A | 4 | NULL | NULL | | BTREE | | | YES | NULL | | account | 1 | name_idx | 1 | name | A | 4 | NULL | NULL | YES | BTREE | | | YES | NULL | +---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+ 2 rows in set (0.01 sec)
說明1:這就建立了一個名為name_idx的索引
4.3 刪除索引
drop index 索引名 on 表名
範例
mysql> drop index name_idx on account; Query OK, 0 rows affected (0.00 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> show index from account; +---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+ | Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression | +---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+ | account | 0 | PRIMARY | 1 | id | A | 4 | NULL | NULL | | BTREE | | | YES | NULL | +---------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+------------+ 1 row in set (0.00 sec)
說明:這就刪除了一個索引
五、預告
後面的文章會繼續介紹索引的使用和設計原則
侯哥語錄:我曾經是一個職業教育者,現在是一個自由開發者。我希望我的分享可以和更多人一起進步。分享一段我喜歡的話給大家:"我所理解的自由不是想幹什麼就幹什麼,而是想不幹什麼就不幹什麼。當你還沒有能力說不得時候,就努力讓自己變得強大,擁有說不得權利。"