論文解讀(BERT-DAAT)《Adversarial and Domain-Aware BERT for Cross-Domain Sentiment Analysis》
論文資訊
論文標題:Adversarial and Domain-Aware BERT for Cross-Domain Sentiment Analysis
論文作者:
論文來源:2020 ACL
論文地址:download
論文程式碼:download
視屏講解:click
1 介紹
2 問題定義
在跨域情緒分析任務中,給出了兩個域 $D_{s}$ 和 $D_{t}$,它們分別表示源域和目標域。在源域中,$D_{s}^{l}=\left\{x_{s}^{i}, y_{s}^{i}\right\}_{i=1}^{N_{s}^{l}}$ 是 $N_{s}^{l}$ 標記的源域例子,其中 $x_{s}^{i}$ 表示一個句子,$y_{s}^{i}$ 是對應的標籤。在源域中也有 $N_{s}^{u}$ 個未標記的資料 $D_{s}^{u}=\left\{x_{s}^{i}\right\}_{i=1+N_{s}^{l}}^{N_{s}^{l}+N_{s}^{u}}$。在目標域中,有一組未標記的資料 $D_{t}=\left\{x_{t}^{i}\right\}_{i=1}^{N_{t}}$,其中 $N_{t}$ 為未標記資料的數量。跨域情緒分析要求我們學習一個基於標記源域資料訓練的魯棒分類器來預測目標域中未標記句子的標籤。
2 方法
2.1 BERT Post-training
2.1.1 域區分任務
本文用域區分任務(DDT)來替換 NSP 任務:50% 的時間句子 A 和句子 B 都是從目標域評論中隨機抽取的,我們將其標記為 TargetDomain。50% 的時間句子 A 和句子 B 來自目標域和另一個域,其標籤為MixDomain。
我們在合併表示上新增一個輸出層,並使正確標籤的可能性最大化。領域區分預訓練使BERT能夠提取出不同領域的特定特徵,增強了下游的對抗性訓練,有利於跨域情緒分析。
2.1.2 目標域 MLM
為了注入目標領域的知識,本文利用掩蔽語言模型(MLM),它需要預測句子中隨機掩蔽的單詞。在跨域情緒分析中,在目標域中沒有標記資料,只有大量的未標記資料來進行 MLM 訓練 BERT。具體來說,本文用 [MASK] 隨機替換 15% 的 Token,並進行 mask token 的預測。
Note:來自其他域的句子將是帶來域偏差的噪聲。因此,當域區分任務標籤是 MixDomain 時,只掩碼目標域句子中的 Token。
2.2 對抗訓練
BERT Post-training 注入目標領域的知識,併為 BERT 帶來了對領域的意識。基於 BERT Post-training,現在可以利用對抗訓練放棄提煉的域特定特徵來匯出域不變特徵。具體來說,設計了一個情緒分類器和一個域鑑別器來處理特殊分類嵌入 [CLS] 的隱藏狀態 $h_{[CLS]}$。
2.2.1 情緒分類器
分類器:
$y_{s}=\operatorname{softmax}\left(W_{s} h_{[C L S]}+b_{s}\right)$
2.2.2 域鑑別器
標準的 DANN:
$d=\operatorname{softmax}\left(W_{d} \hat{h}_{[C L S]}+b_{d}\right)$
$L_{d o m}=-\frac{1}{N_{s}+N_{t}} \sum_{i}^{N_{s}+N_{t}} \sum_{j}^{K} \hat{d}^{i}(j) \log d^{i}(j)$
$\begin{array}{c}Q_{\lambda}(x)=x, \\\frac{\partial Q_{\lambda}(x)}{\partial x}=-\lambda I .\end{array}$
2.3 訓練目標
完整的訓練目標:
$L_{\text {total }}=L_{\text {sen }}+L_{\text {dom }}$
3 實驗結果
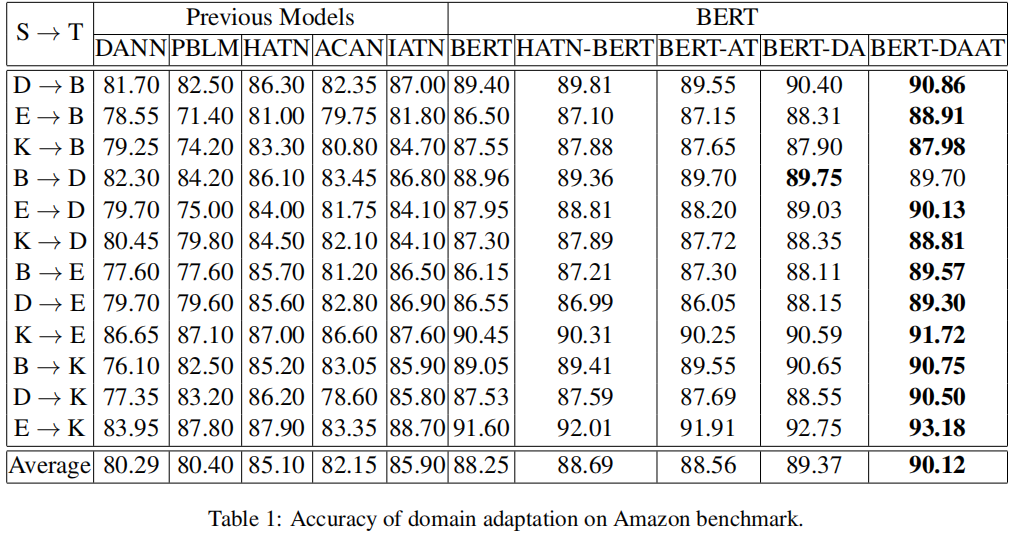
分類結果
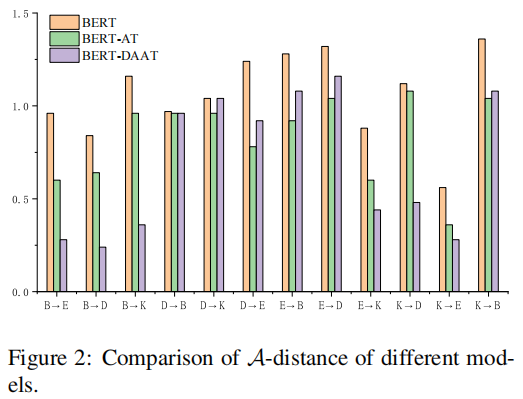
A-distance
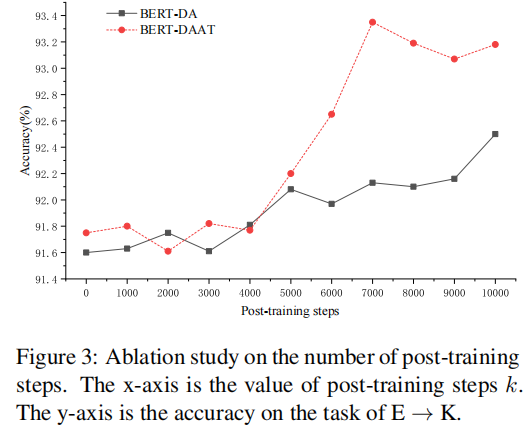
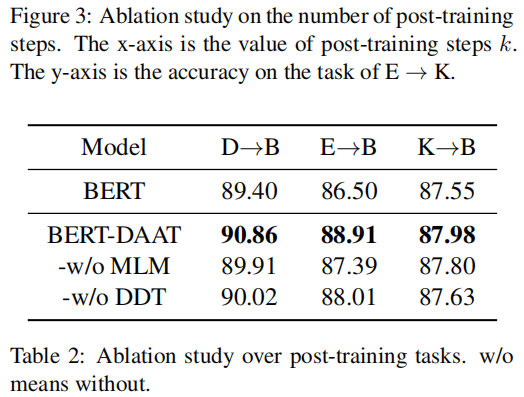
消融實驗
因上求緣,果上努力~~~~ 作者:TTTTHHHHHUUUUU,轉載請註明原文連結:https://www.cnblogs.com/BlairGrowing/p/17585186.html