深入Scikit-learn:掌握Python最強大的機器學習庫
本篇部落格詳細介紹了Python機器學習庫Scikit-learn的使用方法和主要特性。內容涵蓋了如何安裝和設定Scikit-learn,Scikit-learn的主要特性,如何進行資料預處理,如何使用監督學習和無監督學習演演算法,以及如何評估模型和進行引數調優。本文旨在幫助讀者深入理解Scikit-learn,並有效地應用在實際的機器學習任務中。

引言
在人工智慧大潮的推動下,機器學習作為一項核心技術,其重要性無需過多強調。然而,如何快速高效地開展機器學習實驗與開發,則是許多科研工作者和工程師們面臨的挑戰。Python作為一種簡潔易讀、擁有豐富科學計算庫的程式語言,已廣泛應用於機器學習領域。而在Python的眾多機器學習庫中,Scikit-learn以其全面的功能、優良的效能和易用性,贏得了眾多使用者的喜愛。在本篇文章中,我們將深入探討Scikit-learn的使用方法和內部機制,幫助讀者更好地利用這一工具進行機器學習實驗。
機器學習與Scikit-learn的重要性

機器學習作為一種能夠從資料中自動分析獲得模型,然後利用模型對未知資料進行預測的技術,正越來越廣泛地應用於生活中的各個方面,包括搜尋引擎、自動駕駛、臉部辨識、語音識別等領域。在眾多的機器學習工具中,Scikit-learn以其豐富的演演算法庫、優雅的API設計、出色的效能表現,以及活躍的社群支援,使得它在科研界和工業界都得到了廣泛的應用。
Scikit-learn的基本概述
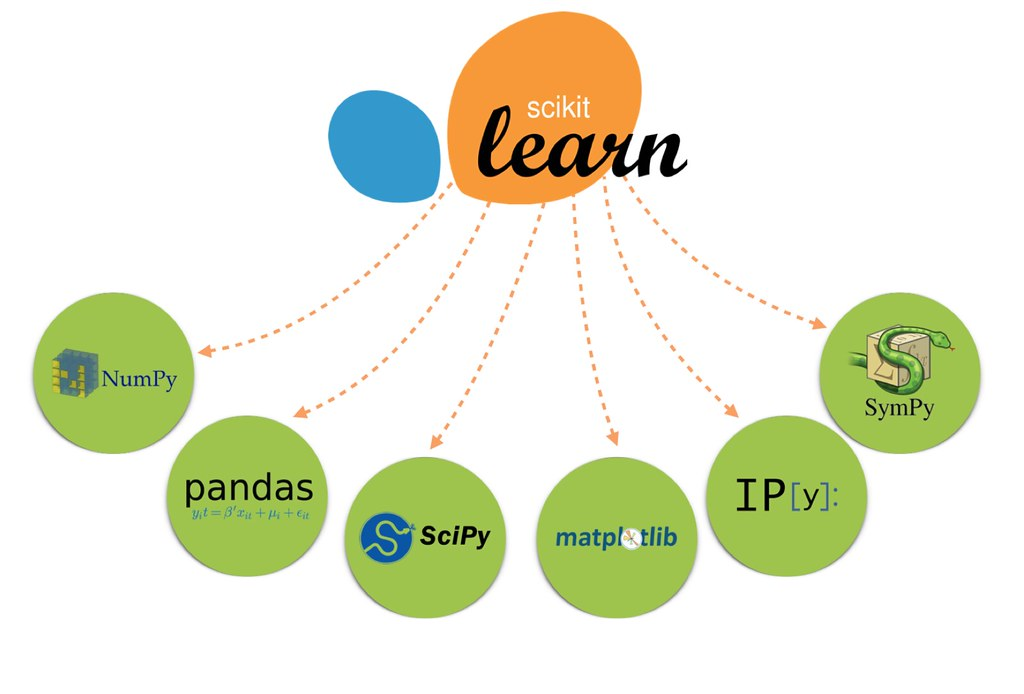
Scikit-learn是一個基於Python的開源機器學習庫,它基於NumPy、SciPy和matplotlib,支援各種機器學習模型,包括分類、迴歸、聚類和降維等。除了提供大量的機器學習演演算法外,Scikit-learn還包括了一整套模型評估和選擇的工具,以及資料預處理和資料分析的功能。簡單易用卻功能強大,是Scikit-learn受歡迎的重要原因。在接下來的文章中,我們將詳細介紹如何使用Scikit-learn進行機器學習開發。
這部分將為讀者提供機器學習和Scikit-learn的基礎概念,以及它們在現代技術領域中的應用和重要性。隨後,我們將詳細探索Scikit-learn庫的主要特性和功能,以及如何使用它進行資料處理和機器學習模型的構建,優化和評估。
安裝和設定
在開始使用Scikit-learn之前,我們需要先進行安裝和設定。在這個部分,我們將詳細介紹如何在Python環境中安裝Scikit-learn,以及如何安裝必要的依賴庫。
如何安裝Scikit-learn
Scikit-learn可以很方便地通過Python的包管理器pip進行安裝。開啟終端或命令列介面,輸入以下命令:
pip install -U scikit-learn
這條命令會安裝或者升級Scikit-learn到最新版本。如果你正在使用特定的Python環境,例如Anaconda,你也可以通過conda進行安裝:
conda install scikit-learn
安裝必要的依賴庫
Scikit-learn的執行需要依賴一些Python庫,包括NumPy和SciPy。這些庫一般來說在安裝Scikit-learn的時候會自動安裝。如果沒有自動安裝,或者需要更新到最新版本,可以使用以下命令:
pip install -U numpy scipy
此外,為了進行資料處理和視覺化,我們通常還需要安裝pandas和matplotlib。同樣,可以通過以下命令進行安裝:
pip install -U pandas matplotlib
以上的安裝過程適用於大部分情況。如果你在安裝過程中遇到任何問題,可以參考Scikit-learn的官方檔案,或者在相關的論壇和社群尋求幫助。安裝完成後,你就可以開始使用Scikit-learn進行機器學習的學習和開發了。
Scikit-learn的主要特性
Scikit-learn作為一個功能強大的Python機器學習庫,其設計理念著重於易用性和統一性。接下來,我們將逐一介紹Scikit-learn的主要特性。
強大的預處理功能
在機器學習的流程中,資料預處理是必不可少的一步。Scikit-learn提供了豐富的資料預處理功能,包括資料淨化、編碼、標準化、特徵提取和特徵選擇等。
from sklearn import preprocessing
# 以資料標準化為例,以下是使用Scikit-learn進行標準化的程式碼
X = [[ 1., -1., 2.],
[ 2., 0., 0.],
[ 0., 1., -1.]]
scaler = preprocessing.StandardScaler().fit(X)
print(scaler.transform(X))
眾多的機器學習演演算法
Scikit-learn提供了各種常用的監督學習和無監督學習演演算法,包括迴歸、分類、聚類、降維等。這些演演算法的API設計統一且一致,使得在不同的演演算法間切換變得非常簡單。
from sklearn import svm
# 以SVM為例,以下是使用Scikit-learn進行模型訓練和預測的程式碼
X = [[0, 0], [1, 1]]
y = [0, 1]
clf = svm.SVC()
clf.fit(X, y)
print(clf.predict([[2., 2.]]))
效果評估和模型選擇
Scikit-learn也提供了一套完善的模型評估和選擇工具,包括交叉驗證、網格搜尋和多種評估指標。
from sklearn import metrics
from sklearn.model_selection import cross_val_score
# 以交叉驗證為例,以下是使用Scikit-learn進行交叉驗證的程式碼
scores = cross_val_score(clf, X, y, cv=5)
print(scores)
視覺化工具
儘管Scikit-learn本身不提供繪圖功能,但是它可以很好地與matplotlib等Python繪相簿配合使用,以實現資料和模型效果的視覺化。
import matplotlib.pyplot as plt
from sklearn import datasets
# 以下是一個簡單的Scikit-learn資料視覺化範例
iris = datasets.load_iris()
X = iris.data[:, :2] # 我們只取前兩個特徵
y = iris.target
plt.scatter(X[:, 0], X[:, 1], c=y)
plt.show()
以上就是Scikit-learn的主要特性。在接下來的部分,我們將詳細介紹如何利用這些特性進行機器學習的各個階段的工作。
Scikit-learn的資料預處理
在機器學習任務中,資料預處理是一項非常重要的工作。預處理包括資料淨化、資料轉換、特徵提取等步驟,以將原始資料轉化為適合機器學習模型使用的格式。Scikit-learn提供了一套強大的資料預處理工具,以滿足這些需求。
資料淨化
資料淨化主要包括處理缺失值和異常值。Scikit-learn提供了Imputer類,用於處理缺失值。以下是使用Imputer的一個簡單範例:
from sklearn.impute import SimpleImputer
# 假設我們的資料集中有缺失值NaN
import numpy as np
X = [[1, 2], [np.nan, 3], [7, 6]]
imp = SimpleImputer(missing_values=np.nan, strategy='mean')
print(imp.fit_transform(X))
資料轉換
資料轉換主要包括標準化、歸一化、二值化等步驟。Scikit-learn提供了preprocessing模組,用於完成這些任務。
from sklearn import preprocessing
# 資料標準化範例
X = [[1., -1., 2.], [2., 0., 0.], [0., 1., -1.]]
scaler = preprocessing.StandardScaler().fit(X)
print(scaler.transform(X))
# 資料歸一化範例
X_normalized = preprocessing.normalize(X, norm='l2')
print(X_normalized)
特徵提取和特徵選擇
Scikit-learn提供了一系列的方法用於特徵提取和特徵選擇。特徵提取主要用於將原始資料轉換為特徵向量,特徵選擇則用於從原始特徵中選擇最有價值的特徵。
from sklearn.feature_extraction.text import CountVectorizer
# 特徵提取範例:文字資料轉換為詞頻向量
corpus = ['This is the first document.',
'This is the second second document.',
'And the third one.',
'Is this the first document?']
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(corpus)
print(vectorizer.get_feature_names())
print(X.toarray())
# 特徵選擇範例:使用卡方檢驗選擇最好的特徵
from sklearn.feature_selection import SelectKBest, chi2
X, y = [[1, 2], [3, 4], [5, 6], [7, 8]], [0, 0, 1, 1]
X_new = SelectKBest(chi2, k=1).fit_transform(X, y)
print(X_new)
通過上述的預處理工作,我們可以將原始資料轉換為適合機器學習模型使用的格式,這是進行機器學習的基礎。在下一部分,我們將討論如何使用Scikit-learn的API進行機器學習模型的構建和訓練。
Scikit-learn中的監督學習演演算法
監督學習是機器學習中最常見的任務之一,包括分類和迴歸兩種型別。Scikit-learn提供了一系列的監督學習演演算法,包括常見的線性模型、決策樹、支援向量機等。以下將為大家展示如何在Scikit-learn中使用這些演演算法。
線性模型
線性模型是一種常見的監督學習演演算法,用於解決迴歸和分類問題。Scikit-learn中的linear_model模組提供了一系列的線性模型,包括線性迴歸、邏輯迴歸、嶺迴歸等。
from sklearn.linear_model import LinearRegression
# 建立資料
X = [[1, 1], [1, 2], [2, 2], [2, 3]]
y = [1, 1, 2, 2]
# 建立線性迴歸模型並訓練
reg = LinearRegression().fit(X, y)
# 進行預測
print(reg.predict([[3, 5]]))
決策樹
決策樹是一種簡單而有效的分類和迴歸方法。Scikit-learn中的tree模組提供了決策樹的實現。
from sklearn import tree
# 建立資料
X = [[0, 0], [1, 1]]
Y = [0, 1]
# 建立決策樹模型並訓練
clf = tree.DecisionTreeClassifier()
clf = clf.fit(X, Y)
# 進行預測
print(clf.predict([[2., 2.]]))
支援向量機
支援向量機(SVM)是一種強大的分類方法,同時也可以用於解決迴歸問題。Scikit-learn中的svm模組提供了SVM的實現。
from sklearn import svm
# 建立資料
X = [[0, 0], [1, 1]]
y = [0, 1]
# 建立SVM模型並訓練
clf = svm.SVC()
clf.fit(X, y)
# 進行預測
print(clf.predict([[2., 2.]]))
Scikit-learn中還包括了許多其他的監督學習演演算法,如神經網路、整合方法等。這些方法的使用方式與上述類似,都遵循了Scikit-learn的統一API設計。在實際使用中,我們可以根據資料的特性和問題的需要,選擇合適的演演算法進行學習。
Scikit-learn中的無監督學習演演算法
無監督學習是指在沒有標籤的情況下對資料集進行學習,主要包括聚類和降維等任務。Scikit-learn提供了豐富的無監督學習演演算法。接下來,我們將介紹其中的一部分。
聚類
聚類是無監督學習的一種常見任務,其目標是將相似的樣本聚集在一起。Scikit-learn提供了多種聚類演演算法,如K-means,譜聚類,DBSCAN等。
from sklearn.cluster import KMeans
# 建立資料
X = [[1, 2], [1, 4], [1, 0], [4, 2], [4, 4], [4, 0]]
# 建立KMeans模型並訓練
kmeans = KMeans(n_clusters=2, random_state=0).fit(X)
# 檢視聚類結果
print(kmeans.labels_)
降維
降維是無監督學習的另一種常見任務,其目標是將高維資料對映到低維空間,以便於資料的理解和視覺化。Scikit-learn提供了多種降維演演算法,如PCA,t-SNE,等。
from sklearn.decomposition import PCA
# 建立資料
X = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
# 建立PCA模型並訓練
pca = PCA(n_components=2)
pca.fit(X)
# 檢視降維結果
print(pca.transform(X))
Scikit-learn還提供了許多其他的無監督學習演演算法,如關聯規則學習,異常檢測等。這些演演算法在處理特定問題時可以發揮巨大的作用,使得Scikit-learn在處理各種機器學習任務時具有很強的靈活性。
評估模型和引數調優
建立並訓練了機器學習模型後,我們需要對其效能進行評估,並對模型引數進行調優,以達到最佳的學習效果。Scikit-learn提供了一系列的工具用於模型評估和引數調優。
模型評估
Scikit-learn提供了多種用於模型評估的方法,包括交叉驗證、計算精度、召回率、F1分數等。
from sklearn.model_selection import cross_val_score
from sklearn.metrics import classification_report
from sklearn.ensemble import RandomForestClassifier
from sklearn import datasets
# 載入資料集
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 建立模型
clf = RandomForestClassifier(random_state=7)
# 交叉驗證
scores = cross_val_score(clf, X, y, cv=5)
print("Cross-validation scores: ", scores)
# 訓練模型
clf.fit(X, y)
# 預測結果
y_pred = clf.predict(X)
# 計算各項評價指標
print(classification_report(y, y_pred))
引數調優
Scikit-learn提供了GridSearchCV和RandomizedSearchCV等工具用於進行引數調優。
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
# 引數空間
param_grid = {'C': [0.1, 1, 10, 100], 'gamma': [1, 0.1, 0.01, 0.001], 'kernel': ['rbf']}
# 建立SVC模型
svc = SVC()
# 建立GridSearchCV物件並訓練
grid = GridSearchCV(svc, param_grid, refit=True, verbose=2)
grid.fit(X, y)
# 輸出最優引數
print(grid.best_params_)
通過上述的評估和調優,我們可以得到最優的模型和引數。在實際的機器學習任務中,模型評估和引數調優是非常重要的步驟,它們能夠顯著提高模型的效能和準確率。
結論
Scikit-learn是一個強大且易用的Python庫,它為我們提供了一整套的機器學習工具,可以用於解決從資料預處理,到模型訓練,再到模型評估和引數調優的全流程任務。Scikit-learn的廣泛應用,不僅僅因為它的功能強大,更因為它的設計理念——統一的API,使得我們可以快速地切換不同的模型和演演算法,而不需要對程式碼進行大的修改。這種靈活性和易用性,使得Scikit-learn成為了Python機器學習庫的首選。
但是,我們也需要注意,雖然Scikit-learn提供了一系列的工具,但是每個工具都有其適用的場景和條件。我們在使用Scikit-learn的過程中,需要深入理解每個工具的原理和特性,才能在不同的任務和資料上,選擇合適的工具,得到最好的效果。
希望通過這篇部落格,你對Scikit-learn有了更深入的瞭解,對如何使用Scikit-learn有了更清晰的認識。如果你對機器學習有興趣,那麼Scikit-learn將是你的必備工具。
如有幫助,請多關注
個人微信公眾號:【TechLead】分享AI與雲服務研發的全維度知識,談談我作為TechLead對技術的獨特洞察。
TeahLead KrisChang,10+年的網際網路和人工智慧從業經驗,10年+技術和業務團隊管理經驗,同濟軟體工程本科,復旦工程管理碩士,阿里雲認證雲服務資深架構師,上億營收AI產品業務負責人。