【Oracle】 instr函數與substr函數以及自制分割函數
2023-07-27 12:00:19
Oracle instr函數與substr函數以及自制分割函數
instr通常被用來作為判斷某個字串中是否含有執行字串和將返回結果作為一些資料分割的資料,即有模糊查詢like的作用,當返回的查詢結果的序號為0的時候就是沒有匹配上
substr函數就是很簡單明瞭,就是個擷取字元函數
instr函數
通常使用instr函數有三種格式
- instr(字串,要匹配的字串)
- instr(字串,要匹配的字串,起始位置)
- instr(字串,要匹配的字串,起始位置,匹配次序)
實質上都是instr(字串,要匹配的字串,起始位置,匹配次序),只不過前兩個引數一定要有資料,後兩個引數如果不填就預設為1,無論是從前查還是從後查,執行的字串順序是不變的
範例
--在ababc中查詢a,只有兩個引數的時候,起始位置和匹配次序預設為1,即從位置1開始,查詢第一次匹配的位置,即結果為1
select instr('ababc','a') from dual
;
--在ababc中查詢a,只有三個引數的時候,匹配次序預設為1,起始位置填寫2的話,即從位置2開始,查詢第一次匹配的位置,即結果為3
select instr('ababc','a',2) from dual
;
--在ababc中查詢a,有四個引數的時候,起始位置填寫1,匹配次序填寫2,即從位置1開始,查詢第二次匹配的位置,即結果為3
select instr('ababc','a',1,2) from dual
;
--在ababc中查詢a,有四個引數的時候,起始位置填寫2,匹配次序填寫2,即從位置2開始,查詢第二次匹配的位置,查詢不到結果,即結果為0
select instr('ababc','a',2,2) from dual
;
--在ababc中查詢a,有四個引數的時候,起始位置填寫-1,匹配次序填寫1,即從位置5(-1就是從後往前查詢)開始,查詢第一次匹配的位置,即結果為3
select instr('ababc','a',-1,1) from dual
;
--在ababc中查詢ab,只有兩個引數的時候,起始位置和匹配次序預設為1,即從位置1開始,查詢第一次匹配的a(ab的開頭是a)位置,即結果為1
select instr('ababc','ab') from dual
;
--在ababc中查詢ab,只有三個引數的時候,匹配次序預設為1,起始位置填寫2的話,即從位置2開始,查詢第一次匹配的a(ab的開頭是a)位置,即結果為3
select instr('ababc','ab',2) from dual
;
--在ababc中查詢ab,有四個引數的時候,起始位置填寫1,匹配次序填寫2,即從位置1開始,查詢第二次匹配的a(ab的開頭是a)位置,即結果為3
select instr('ababc','ab',1,2) from dual
;
--在ababc中查詢ab,有四個引數的時候,起始位置填寫2,匹配次序填寫2,即從位置2開始,查詢第二次匹配的a(ab的開頭是a)位置,查詢不到結果,即結果為0
select instr('ababc','ab',2,2) from dual
;
--在ababc中查詢ab,有四個引數的時候,起始位置填寫-1,匹配次序填寫1,即從位置5(-1就是從後往前查詢)開始,查詢第一次匹配的a(ab的開頭是a)位置,即結果為3
select instr('ababc','ab',-1,1) from dual
;
--在ababc中查詢ba,有四個引數的時候,起始位置填寫-1,匹配次序填寫1,即從位置5(-1就是從後往前查詢)開始,查詢第一次匹配的b(ba的開頭是b)位置,即結果為1
select instr('ababc','ba',-1,1) from dual
可以根據instr函數做很多事情
比如有時候會有一些日期髒資料,格式很混亂,則就可以直接使用instr去匹配進行處理
select substr(to_char(SYSDATE, 'YYYY-MM-DD HH24:MI:SS'),0,instr(to_char(SYSDATE, 'YYYY-MM-DD HH24:MI:SS'),':')-3) from dual
還有like的作用,下面兩個語句結果是相同的
select * from (select 'aa' as aa from dual) t where t.aa like '%a%'
;
select * from (select 'aa' as aa from dual) t where instr(t.aa,'a')>0
substr函數
通常使用substr函數有三種格式
- substr(字串,起始位置)
- substr(字串,起始位置,擷取字元數)
實質上都是substr字串,起始位置,擷取字元數),只不過前兩個引數一定要有資料,後一個引數如果不填就是預設取剩下的所有字元,無論是從前查還是從後查,執行的字串順序是不變的
範例:
--對abcde進行擷取,使用兩個引數,從第一個字元開始擷取字串剩下所有的字元,即結果為abcde
select substr('abcde',1) from dual
;
--對abcde進行擷取,使用兩個引數,從第三個字元開始擷取字串剩下所有的字元,即結果為cde
select substr('abcde',3) from dual
;
--對abcde進行擷取,使用兩個引數,從倒數第二個字元開始從前往後擷取字串剩下所有的字元,即結果為de
select substr('abcde',-2) from dual
;
--對abcde進行擷取,使用三個引數,從第一個字元開始擷取字串後三個字元,即結果為abc
select substr('abcde',1,3) from dual
;
--對abcde進行擷取,使用三個引數,從第二個字元開始擷取字串後五個字元,但是因為不夠五個,所以就會輸出剩下所有的字元,即結果為bcde
select substr('abcde',2,5) from dual
;
--對abcde進行擷取,使用三個引數,從倒數第四個字元開始從前往後擷取字串後三個字元,即結果為bcd
select substr('abcde',-4,3) from dual
基本上用到了對字串進行擷取的地方就會用到substr函數,像上面說的對日期髒資料進行處理就需要用到擷取字串,就用到了substr函數
可以通過instr函數和substr函數做一個分割函數,將分割後的資料依次輸出,而不是這種通過輸出視窗才能看到的方法
下圖為分割函數主方法,用了insrt函數,substr函數和Oracle的管道函數,管道函數具體設定見這裡
具體實現部分如下:
CREATE OR REPLACE FUNCTION test_Row_pipelined(p_insvar in varchar2,
p_delimiter in varchar2)
return test_Row_Type_TABLE
pipelined as
p_num integer := 1;
p_num1 integer;
p_length integer;
p_start integer := 1;
p_varchar varchar2(200);
ret test_Row_Type;
begin
--如果不是以分隔符結尾的,就拼接上去
select case
when (select count(1)
from dual
where p_insvar like '%' || p_delimiter) > 0 then
p_insvar
else
p_insvar || p_delimiter
end
into p_varchar
from dual;
--整個字串的長度
select length(p_varchar) into p_length from dual;
--當起始長度大於整體長度的時候
while (p_start <= p_length) loop
--找到字串與分隔符的分割後的下標
select instr(p_varchar, p_delimiter, p_start) into p_num1 from dual;
--如果沒有,則返回全部字串,說明到了結尾了
if p_num1 = 0 then
ret := test_Row_Type(p_num,
substr(p_varchar, p_start),
p_num1,
p_start,
p_length,
0,
0);
pipe row(ret);
else
--否則,擷取字元傳中,從p_start開始找到下標減去p_start的部分
ret := test_Row_Type(p_num,
substr(p_varchar, p_start, p_num1 - p_start),
p_num1,
p_start,
p_length,
0,
0);
pipe row(ret);
--新的起始點為下標加1
p_start := p_num1 + 1;
end if;
--序號加1
p_num := p_num + 1;
end loop;
return;
end;
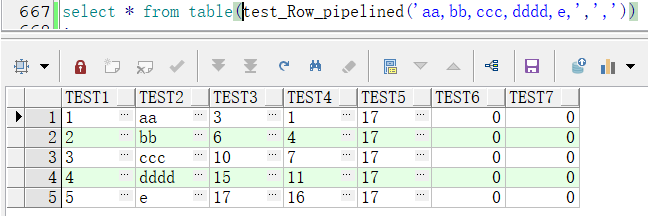
結果如下:
您能讀到這兒,我呢是發自真心的感謝您,若要轉載,還望請您帶上連結