如何快速同步第三方平臺資料?
前言
最近知識星球中有位小夥伴問了我一個問題:如何快速同步第三方平臺資料?
他們有個業務需求是:需要同步全國34個省市,多個系統的8種業務資料,到他們公司的系統當中。
他們需求同步全量的資料和增量的資料。
全量的資料主要是針對多個系統的歷史資料,大概有幾千萬資料,只需要初始化一次即可。
而增量的資料,是系統後續變更的資料。
這個需求其實不簡單,至少有以下難點:
- 不能直接存取第三方資料庫。
- 不能將歷史資料匯出到excel中,有洩露資料的風險。
- 如何快速同步歷史資料?
- 增量資料如何處理?
- 介面需要做限流嗎?
- 增量資料如何校驗資料的一致性?
帶著這些問題,開始今天的文章之旅。
1. 如何快速同步歷史資料?
想要快速同步歷史資料,第一個想到的可能是直接同步資料庫中的資料。
但多個第三方系統為了資料安全考慮,不可能直接把他們的資料庫存取地址和相關賬號密碼告訴你。
即使他們告訴你了,但有很多個系統,你一個個去連資料庫查資料,也非常麻煩。
有些小夥伴可能會說:這好辦,讓第三方系統把他們的歷史資料匯出到excel中,我們寫個程式解析去這些excel,就能將資料快速匯入到我們的資料庫中。
這是個好辦法,但忽略了一點:這些資料是敏感資料,不能對外暴露。
因此匯出excel的方案行不通。
那麼,該如何快速同步歷史資料呢?
答:使用SFTP。
不知道你有沒有跟銀行對接過,SFTP在銀行業務中經常會用到。
那麼,如何用SFTP同步資料呢?
2. 如何使用SFTP?
說起SFTP,就不得不說一說FTP。
我們都知道,FTP是用來傳送檔案的協定。使用FTP實現遠端檔案傳輸的同時,還可以保證資料傳輸的可靠性和高效性。
而SFTP是一種可以安全傳輸檔案的協定,它是一種基於SSH(Secure Shell)的檔案傳輸協定,它允許使用者將檔案以加密的形式傳輸到遠端伺服器上,以保護檔案的安全性。
FTP和SFTP有哪些區別呢?
連結方式不同:FTP使用TCP的21號埠建立連線。而SFTP是在使用者端和伺服器之間通過 SSH 協定 (即TCP22號埠) 建立的安全連線來傳輸檔案。安全性不同:SFTP使用加密傳輸認證資訊和傳輸的資料,相對於FTP更安全一些。傳輸效率不同:SFTP傳輸檔案時使用了加密解密技術,因此傳輸效率比普通的FTP要低一些。使用協定不同:FTP使用了TCP/IP協定,而SFTP使用了SSH協定。安全通道:SFTP協定提供了一個安全通道,用於在網路上的主機之間傳輸檔案。而FTP協定沒有安全通道。
因此可見,我們使用SFTP來傳輸檔案還是比較安全的。
那麼,如何使用SFTP來實現同步歷史資料的需求呢?
答:這就需要我們做好SFTP的賬號、目錄和檔案格式的規劃了。
2.1 賬號許可權控制
首先需要運維同學搭建一個SFTP伺服器,提供一個可以對外存取的域名和埠號。
然後需要在根目錄下,建立一個存放檔案的目錄,比如:/data。
然後給每個省市的第三方系統都建立一個子目錄,比如:/data/sichuan、/data/shenzhen、/data/beijing等。
接下來,我們需要給每個子目錄建立一個賬號,以及分配許可權。
比如有個賬號是:sichuan,密碼是:sisuan123。這個賬號只擁有/data/sichuan目錄讀資料和寫資料的許可權。
另外一個賬號是:shenzhen,密碼是:shenzhen123。這個賬號只擁有/data/目錄讀資料和寫資料的許可權。
以此類推。
當然大家如果不放心,可以用線上工具,將密碼設定成一個8位元的隨機字串,包含字母、數位和特殊字元,這樣的密碼安全性相對來說要高一些。
這樣相關的第三方系統都有往SFTP自己目錄下讀和寫資料的許可權。
在這裡溫馨提醒一下:上面這些賬號讀資料的許可權,主要是為了後面他們好排查問題用的,不是必須分配的,我們需要根據實際情況而定。
此外,還需要給我們自己分配一個賬號,開通對/data整個目錄的唯讀許可權。
2.2 統一資料格式
接下來,最關鍵的一步是要制定一個統一的檔案格式和資料格式。
檔名稱為:sichuan_20230724.txt。
也就是用 省市拼音_日期.txt 的格式。
這樣大家就能非常清楚的看出,是哪個省市,哪個日期產生的資料。
然後我們需要規定txt檔案的格式。
比如:id佔20個字元,name佔30個字元,金額佔10個字元等等。
如果有些列的資料不滿對應的字元長度,前面可以補0。
這樣我們的程式,只需要在解析txt檔案時,先讀取一行資料,是一個比較長的字串,然後按照固定的長度,去解析字串中每一列的資料即可。
2.3 使用job同步資料
假如第三方系統都按照我們要求,已將歷史資料寫入到指定目錄下的指定檔案中。
這時我們需要提供一個job,去讀取/data目錄下,所有子目錄的txt檔案,一個個解析裡面包含的歷史資料,然後將這些資料,做一些業務邏輯處理,然後寫入我們的資料庫當中。
如圖所示:
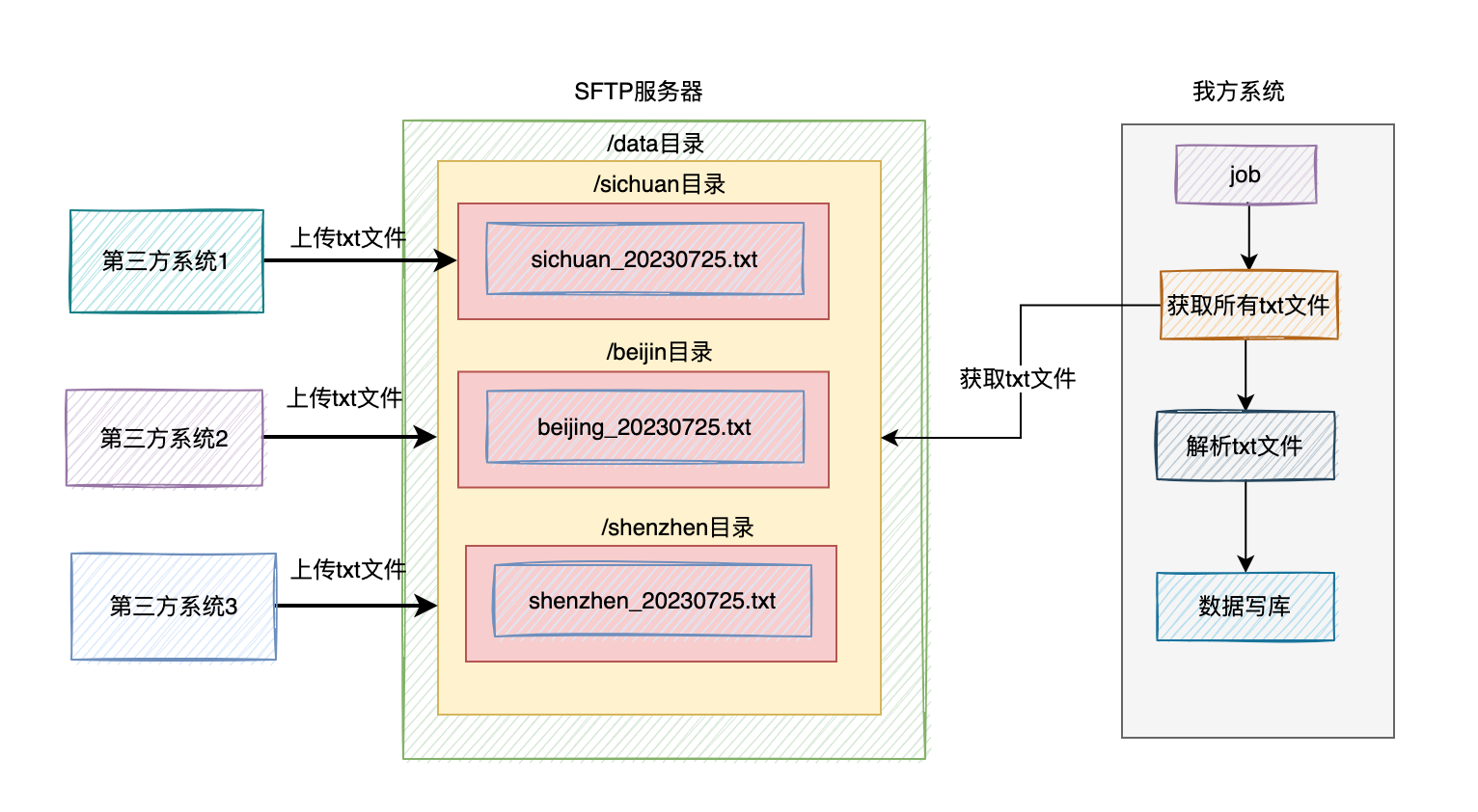
當然如果想快一點處理完,我們可以在job中使用多執行緒解析和讀取不同的txt檔案,然後寫資料。
3. 增量資料如何處理?
對於歷史資料,我們通過上面的方案,可以快速的同步資料。
但對於增量的資料如何處理呢?
增量的資料,對實時性要求比較高。
我們沒辦法跟之前一下,走SFTP同步檔案,然後使用job定時解析檔案的方案。
為了滿足資料實時性的需求,我們不得不走介面實時資料同步的方案。
那麼,是第三方系統提供介面,還是我們這邊提供介面呢?
很顯然,如果讓第三方提供介面,第三方有那麼多系統,我們需要對接很多很多介面,非常麻煩。
因此,這個介面必須由我們這邊提供。
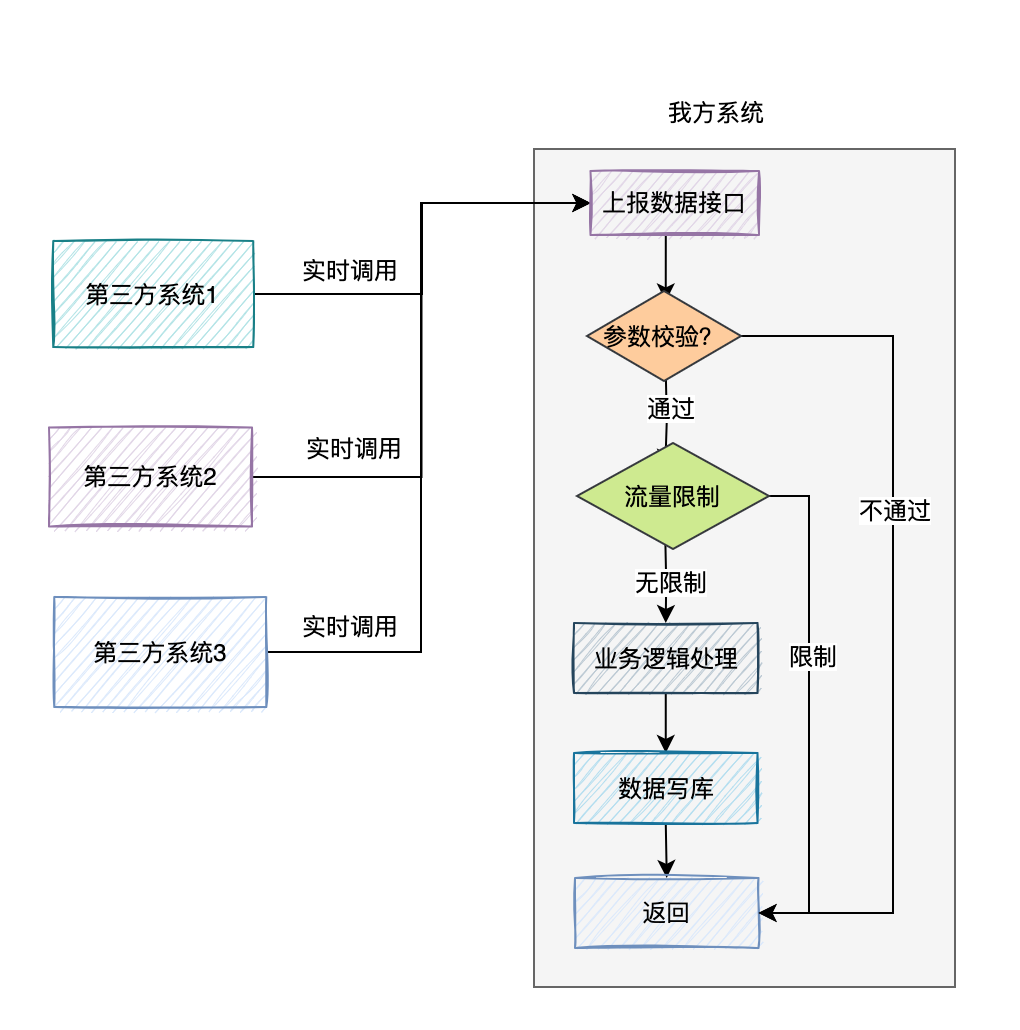
我們這邊提供一個統一的資料上報介面,支援傳入批次的資料。
為了防止第三方系統,一次性傳入過多的引數,導致該介面超時,我們需要對單次上傳的資料條數做限制,例如:一次請求,最大允許上傳500條資料。
其實,光限制請求引數還不夠。
我們的這個資料上報介面,可能會被多個系統呼叫,並行量可能也不小。
為了防止在高並行下,請求量突增把我們的介面搞掛了,我們需要對介面限流。
我們可以使用redis記錄第三方系統請求的url和請求賬號,然後在程式中查詢redis中的次數,是否超過限額。允許每一個第三方系統,在1秒之內呼叫10次。第三方系統總的請求次數,1秒不超過500次。
如果超過了限額,則資料上報介面提示:請求太頻繁,請稍後再試。
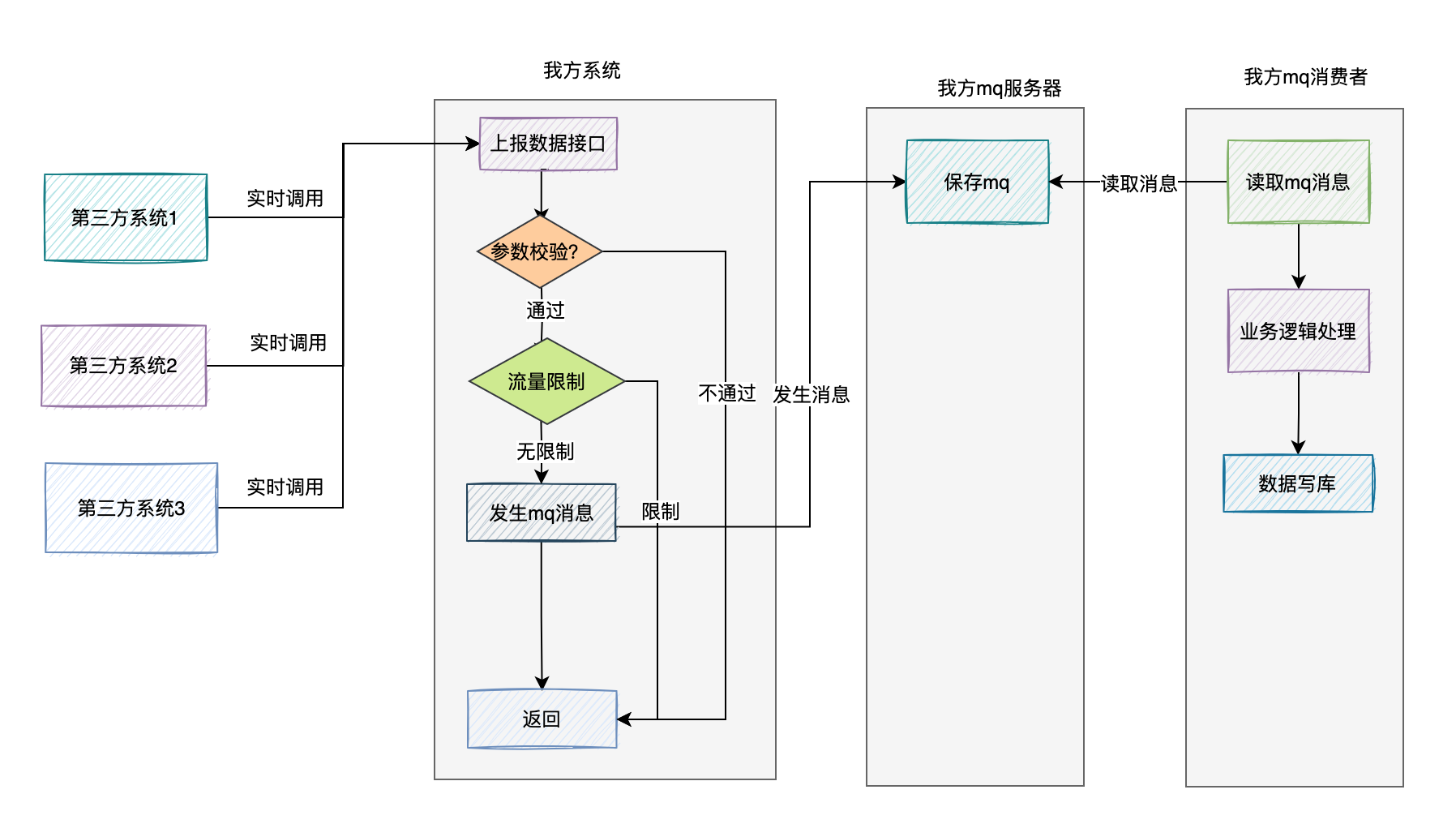
為了增加資料上報介面的效能,在接收到資料之後,不直接寫庫。
我們可以將介面中接收到的資料作為mq訊息,傳送到mq伺服器。
然後有專門的mq消費者,實時監聽mq伺服器的訊息,非同步讀取訊息寫入資料庫。
該方案比較適合,寫庫操作,包含了一些複雜的業務邏輯。
如果消費速度有點慢,我們可以及時調整mq消費者,使用多執行緒處理,或者增加mq中佇列的數量,增加mq消費者來增加訊息的處理速度。
如果mq消費者在處理mq訊息的過程中,由於網路問題,寫庫失敗了,可以增加自動重試機制。
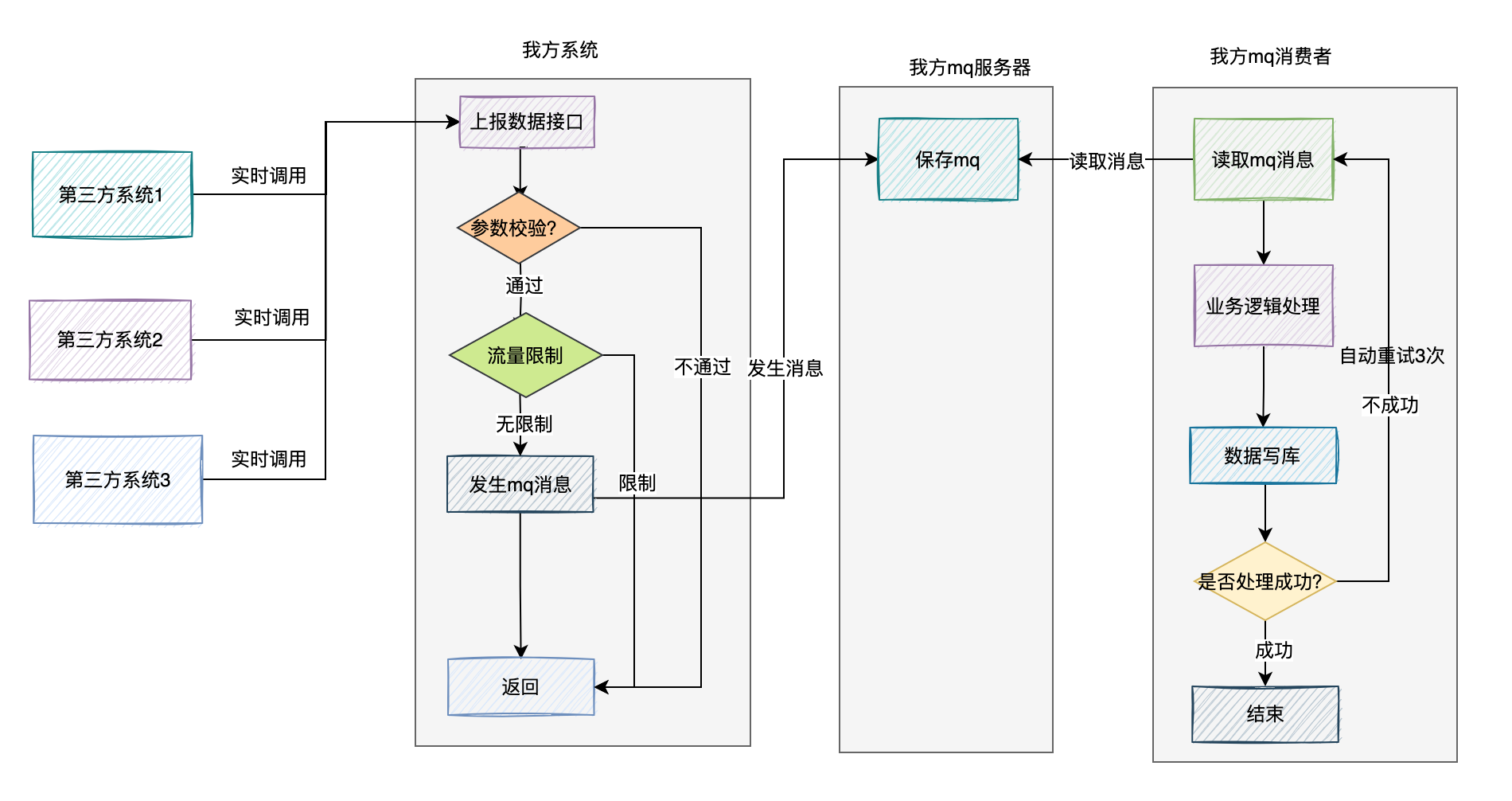
一旦mq消費者在mq消費過程中出現失敗的情況,則自動重試3次,如果還是失敗,則將訊息寫入死信佇列,目前RocketMQ自帶了失敗重試功能。
然後有個job監控死信佇列,如果一旦發現異常資料,則發報警郵件給相關開發,後面人工處理。
4. 如何校驗資料一致性?
通過上面的方案,我們把歷史資料和增量的資料都已經處理了。
但還有一個問題:如何校驗資料一致性。
對於歷史資料,其實我們好處理,第三方系統已經生成好txt檔案上傳到SFTP上了,我們可以直接對比那些檔案即可。
但對於增量的資料,是第三方系統呼叫我們的資料上報介面,去上報的資料,這部分資料如何校驗資料一致性呢?
答:我們可以要求第三方系統,在某日凌晨,生成一份昨日的增量資料到txt檔案,然後上傳到SFTP上。
我們有個job,在每天的凌晨1點會讀取第三方系統生成昨日增量資料,跟我們資料庫中昨日的增量資料做對比,校驗資料的差異性。
如果第三方後面產生的增量資料,只有新增,沒有刪除和修改,使用上面的方案是沒有問題的。
但如果增量的資料,包含了刪除和修改的資料,可能會有問題。
因為我們做比較的資料來源是昨日的增量資料,而我們的job在比較資料的過程中,萬一第三方系統上報了我們正在對比的資料,更新成了一個新值,跟昨日的值不一樣,這樣對比資料就會產生差異。
那麼,該如何解決這個問題呢?
答:我們可以只校驗昨日的資料(就修改時間是昨天),今日產生的增量資料,會在明日凌晨1點的job中會去校驗的。
在比較時,遍歷昨日增量txt檔案中的每行資料,跟資料庫中的資料做對比,如果id相同,但是修改時間是今天,則忽略這條資料。
如果id相同,修改時間是昨天,則判斷資料是否一致,如果不一致,則用txt檔案中的資料修復我們資料庫中的異常資料。
如果txt檔案中的id,在我們資料庫中不存在,則新增一條資料。
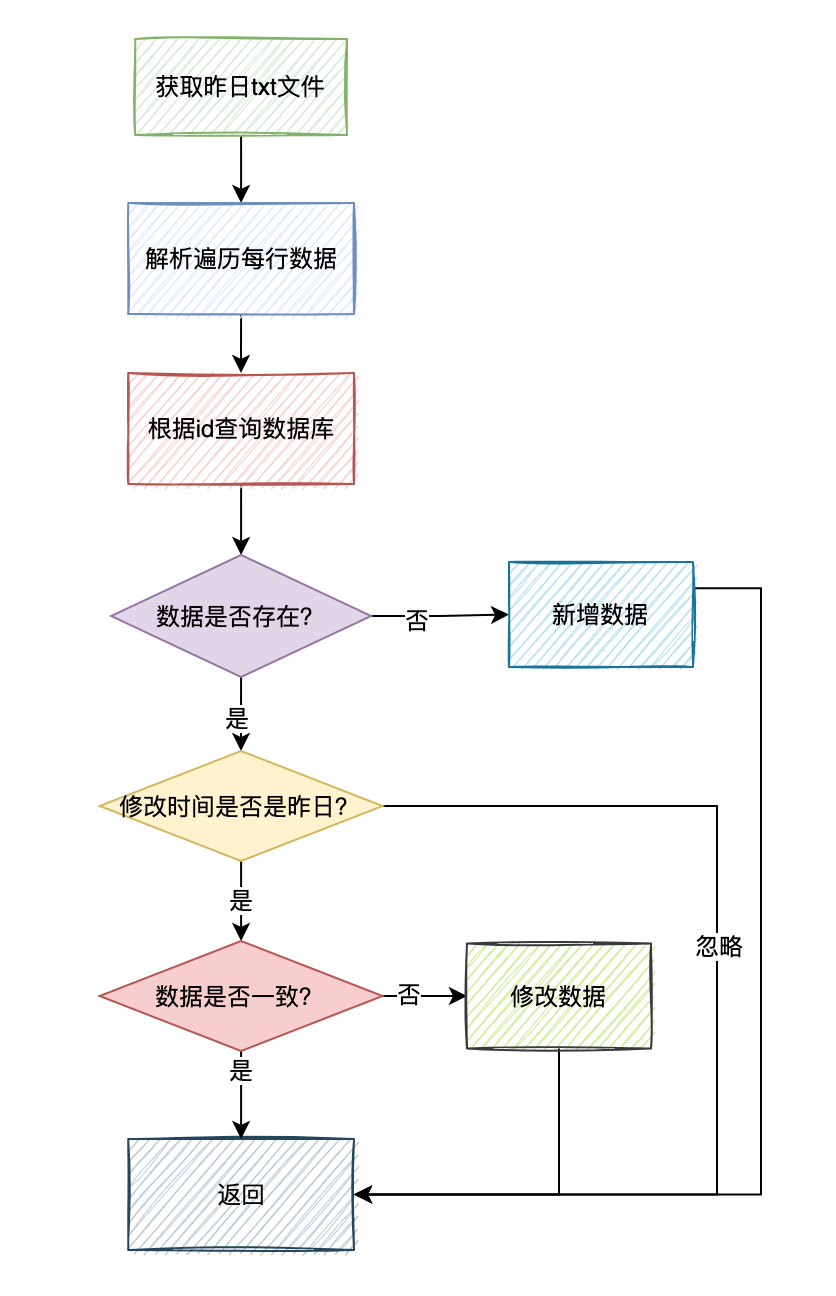
這兩種情況產生的資料變動,修改時間要設定成昨天,不然明日的job又會再重新處理一次這條資料。
這個問題是星球中眾多問題中的一個。
如果你也有類似的問題,或者有其他的問題找不到答案,戳這裡加入我們,向我們提問吧,歡迎你的到來,有問必答。
目前已經有880多名球友加入了蘇三的知識星球,一起學習,一起成長。月底即將迎來一波漲價,觀望的小夥伴要趁著了,優惠券已經不多了。

歡迎點選左下角閱讀原文瞭解蘇三的知識星球,也許這裡有很多你想要的東西。