【升職加薪祕籍】我在服務監控方面的實踐(3)-機器監控
大家好,我是藍胖子,關於效能分析的視訊和文章我也大大小小出了有一二十篇了,算是已經有了一個系列,之前的程式碼已經上傳到github.com/HobbyBear/performance-analyze,接下來這段時間我將在之前內容的基礎上,結合自己在公司生產上構建監控系統的經驗,詳細的展示如何對線上服務進行監控,內容涉及到的指標設計,軟體設定,監控方案等等你都可以拿來直接復刻到你的專案裡,這是一套非常適合中小企業的監控體系。
在前一節我們搭建好了監控元件,今天我們就來完成機器這一層次的監控。目前已經有現有的暴露系統指標的軟體node-exporter ,並且我們在上一節已經搭建完畢, 在這一節裡,我將會講解如何利用暴露出來的這些指標構建一個自定義的系統監控模板。
本節構建的自定義的監控模板檔案已經上傳到github,可直接匯入使用
github.com/HobbyBear/easymonitor/blob/main/grafanadashbord/system_dashboard.json
監控指標
如何選擇node-exporter暴露的監控指標,我們可以按照四大黃金指標給出的維度進行篩選,並且promql語句也不用我們從頭寫,已經有現有的監控模板可使用。 我們只需要搭建好prometheus ,grafana後匯入模板即可。我們用到的監控模板是node exporter full。
匯入匯出模板的步驟網上很多教學,我就不再重複造輪子了。

由於node exporter full模板裡的監控面板實在太多,我們只需要選取其中的某些面板即可。
注意下,雖然使用的是別人已經寫好的監控模板,但是我們仍然是以四大黃金指標為指導,選擇監控的維度以及監控面板。四大黃金指標分別是延遲,流量,飽和度,錯誤數。
cpu
接著我們來挨個分析下需要用到的監控指標,首先我們來看下對cpu的監控。一般硬體指標是沒有延遲這個維度,所以我們看流量,飽和度,錯誤數。**針對cpu而言,其實主要就是看飽和度和錯誤數,飽和度也就是cpu的使用率,如果cpu的使用率越高,說明cpu越趨於飽和。
cpu的使用率是通過讀取proc檔案系統獲取的。一般會將cpu的使用率按用途進行分類,用top命令也可以看到cpu使用率的分類情況
%Cpu(s): 2.4 us, 1.0 sy, 0.0 ni, 96.2 id, 0.3 wa, 0.0 hi, 0.0 si, 0.0 st
我們挨個看下各種分類的含義:
1, us 代表使用者態程序消耗的cpu。
2,sy 代表 核心態程式消耗的cpu。
3,ni 代表低優先順序的程序消耗的cpu,當我們使用renice命令調低某個使用者程序的優先順序時,該使用者程序cpu佔用率會從us裡分到ni裡。這樣當一批非常吃CPU的程序被調整nice值後,調整的人就能非常清楚的知道,這些程序現在佔用多少CPU了。
4,id 代表代表空閒cpu的佔用率。
5,wa 代表程序等待cpu執行所花的時間佔cpu週期的時長。
6, hi 代表處理硬體中斷的cpu佔用率。
7,si 代表軟中斷的cpu使用率,在linux上,會執行一個特定的程序ksoftirqd 處理軟中斷的邏輯,軟中斷你可以把它理解成也是一段程式,不過這段程式執行特點的某些軟中斷的任務,linux核心為了方便觀察這些任務的耗時,專門在cpu使用率裡分出一個類別來記錄這些軟中斷的任務執行的cpu佔用率。 軟中斷的任務有多種型別,比如定時器,網路封包的處理等。
8,st 代表從其他作業系統那裡偷取到的cpu,一般在虛擬化環境比如物理主機上部署多臺虛擬機器器或者雲主機的條件下,一臺虛擬機器器能夠從另一臺虛擬機器器那裡搶佔cpu,st就代表搶佔cpu的時長。
在node exporter full裡我們選用了一個cpu的面板,把上述cpu的使用率及其分類後的使用率表現了出來。

其中用到的prometheus的查詢語句promql有8個,分別對應8種cpu使用率的分類,其中irq就是我們說的硬體中斷cpu佔用率,其餘分類都是我們剛剛介紹的分類的完整名稱。
拿其中一個計算cpu核心態程式cpu使用率的promql舉例:
sum by(instance) (irate(node_cpu_seconds_total{instance="$node",job="$job", mode="system"}[$__rate_interval])) / on(instance) group_left sum by (instance)((irate(node_cpu_seconds_total{instance="$node",job="$job"}[$__rate_interval])))
node_cpu_seconds_total 指標是我們部署的node-exporter 服務暴露給prometheus伺服器的指標,指標型別是counter型別。__rate_interval 是grafana的內建變數,grafana會根據樣本的抓取間隔和麵板篩選的時間範圍自動算出一個合適的值作為rate函數的引數,以便我們得到合適的曲線。
整個promql語句代表的含義就是看 核心態程式在過去__rate_interval 時間內的cpu使用週期佔cpu過去__rate_interval 時間內 總的週期時長 的百分比作為核心態程式cpu的佔用率。
其餘分類的cpu使用率和這個例子的promql語句類似,就不一一分析了。
記憶體
再來看看記憶體的指標是怎麼樣的, 對於記憶體而言,沒有流量以及延遲 飽和度是記憶體使用空間大小,錯誤數我們主要看缺頁錯誤以及oom kill的次數 。
記憶體佔用空間大小
看記憶體使用空間,我們拿top命令輸出的內容舉例
KiB Mem : 24521316 total, 327428 free, 18130784 used, 6063104 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 4672160 avail Mem
第一行分別代表了total 總記憶體位元組,free 空閒記憶體位元組數,used已經使用的記憶體位元組數,buff/cache 快取的記憶體位元組數,buff/cache 一般是指讀寫磁碟或者讀寫檔案時,核心為了平衡寫入記憶體與寫入磁碟的速率差引入的緩衝區。
第二行代表的是交換空間的資訊,交換空間是指核心為了防止程序突增的記憶體超過系統記憶體引入的一片磁碟空間,它能夠在記憶體不足時 將記憶體中的資訊交換到磁碟,在記憶體空閒時,將磁碟中的資訊換回到記憶體裡。
total代表交換空間總的大小,free是交換空間可用的位元組大小,used代表使用了的交換空間位元組數,avail Mem代表可以交換到磁碟上的實體記憶體大小,當實體記憶體不足時,會將這部分記憶體交換到磁碟上。
記憶體的監控面板同樣我們也是從node exporter full 裡找一個就行。
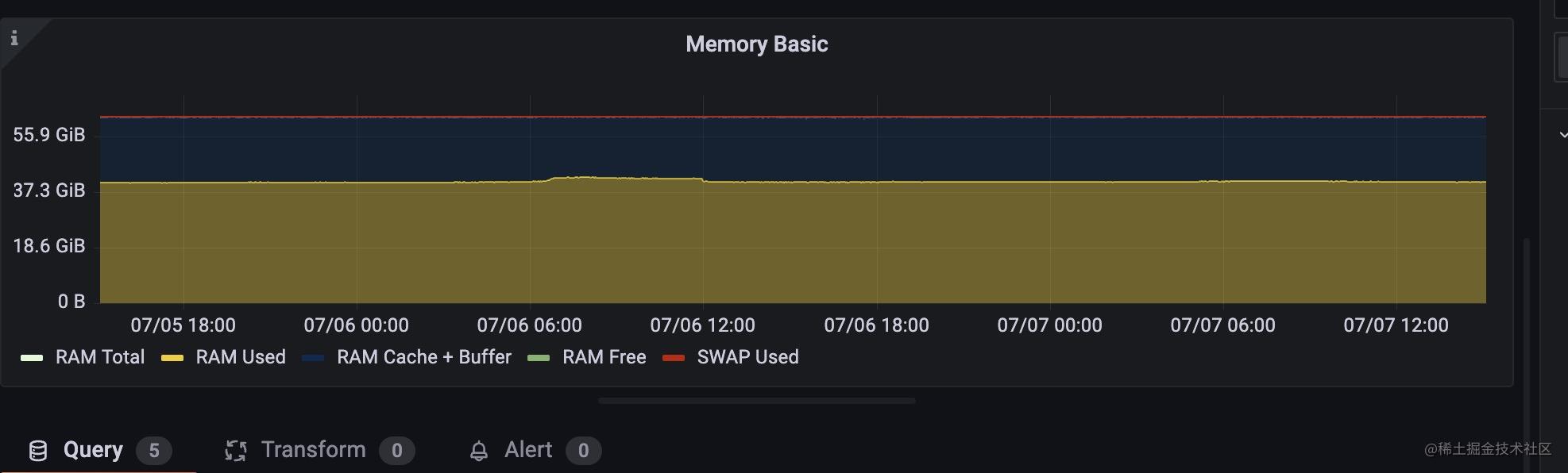
由於記憶體是可增可減的,所以是個guage型別的指標,相應的指標資訊也是從proc檔案系統獲取到的,其路徑是 /proc/meminfo ,對應的promql語句不用使用什麼函數只需要將對應的指標值加減即可,比較容易理解,我就不具體分析,下面是其中一個時間線的查詢語句:
node_memory_Cached_bytes{instance="$node",job="$job"} + node_memory_Buffers_bytes{instance="$node",job="$job"} + node_memory_SReclaimable_bytes{instance="$node",job="$job"}
page fault 和oom kill次數
其中page fault分major fault和minor fault 。
major fault是指在分配記憶體時,記憶體地址即不在虛擬地址空間也不在實體記憶體中的情況,這種情況需要將資料從磁碟讀到實體記憶體裡並建立對映關係。
minor fault 是指分配記憶體時,記憶體地址不在虛擬地址空間,但是已經在實體記憶體中了,這種情況只需要將虛擬地址和實體地址建立對映就行,比如多個程序共用記憶體的情況,可能某些程序還沒有建立起對映關係,所以存取時會出現minor page fault。
監控面板如下:
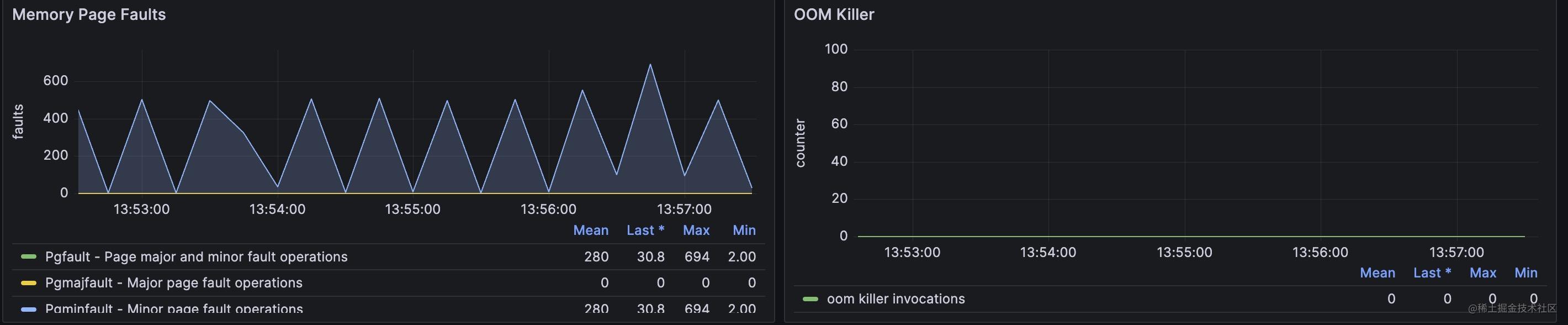
oom killer 顯示的就是程序由於記憶體溢位被系統核心kill掉的次數。
這兩個指標都是遞增的,索引是counter型別,我們可以使用irate或者rate函數就能構建其隨時間變化的速率了,具體promql語句我就不再解釋了。
磁碟
緊接著,我們來看看對磁碟的監控,磁碟可以通過磁碟的iops,吞吐量顯示流量,通過磁碟的空間反映飽和度,通過等待讀寫磁碟請求的時間來側面反應延遲情況。
涉及到幾個指標具體含義如下:
1,磁碟的使用空間 : 這個很容易理解,當磁碟要滿了,就必然存不進新的資料了。
2, iops : 這個指標是指磁碟每秒讀寫請求的次數,一般我們在雲服務商那裡都能看到對應磁碟的這個值,當達到峰值時,會影響磁碟的讀寫效能。
3, 吞吐量: 這個值代表磁碟每秒寫入寫出的流量,也就是每秒讀寫了多少位元組數,這個值也是不同磁碟有不同的極限值,當磁碟吞吐量達到最大值後,也會影響到磁碟的效能。
4, 等待時間: 磁碟的讀寫請求本質上也是排隊進行的,它們在佇列中會有一個等待時間。
同樣的,我們從node exporter full這個模板裡選擇4個面板來監控它們,
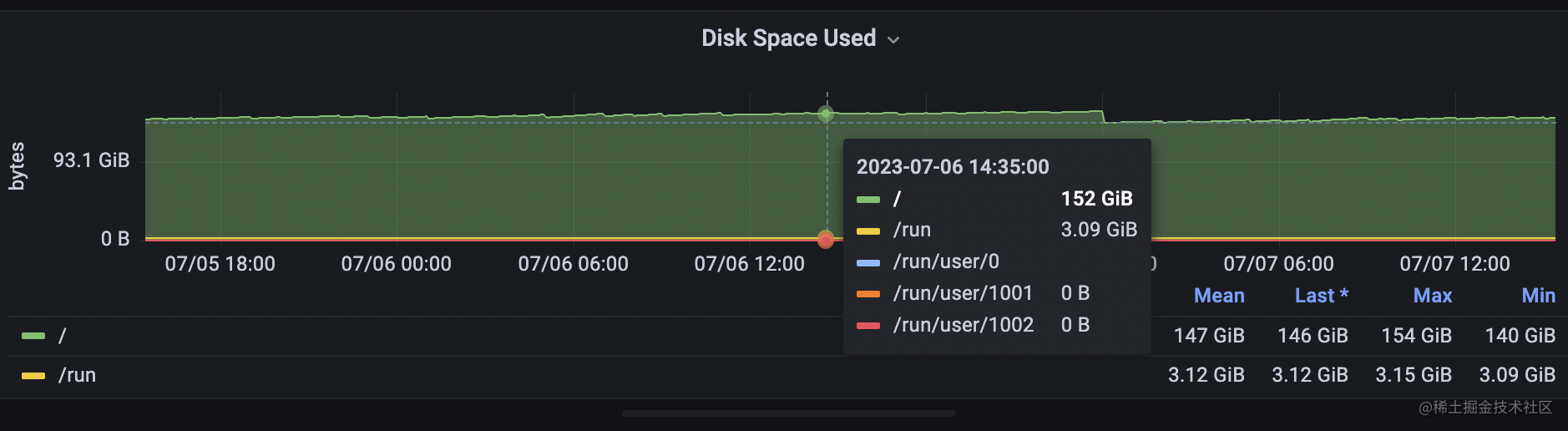
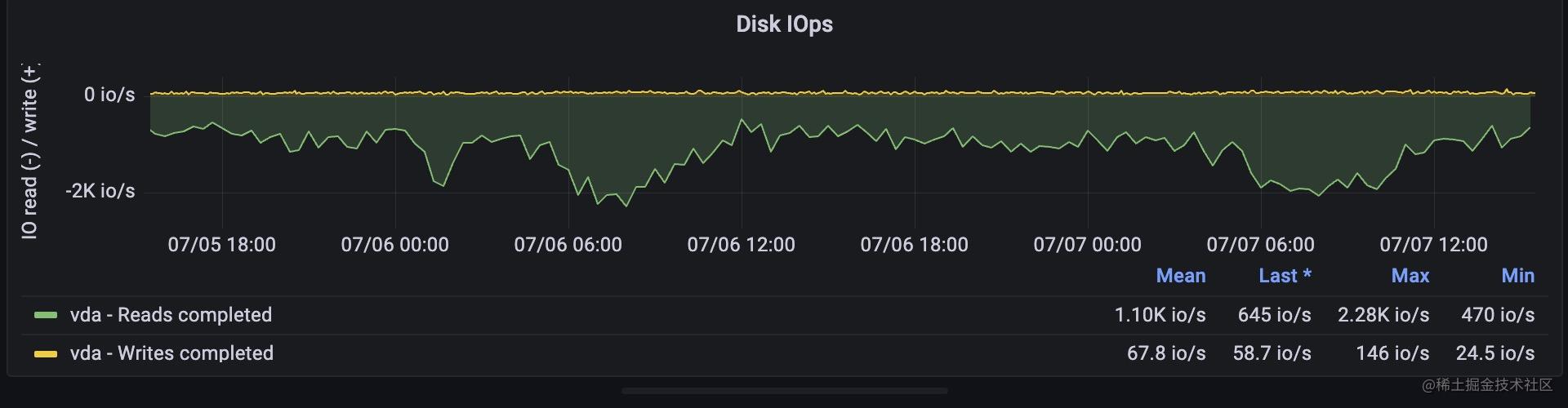
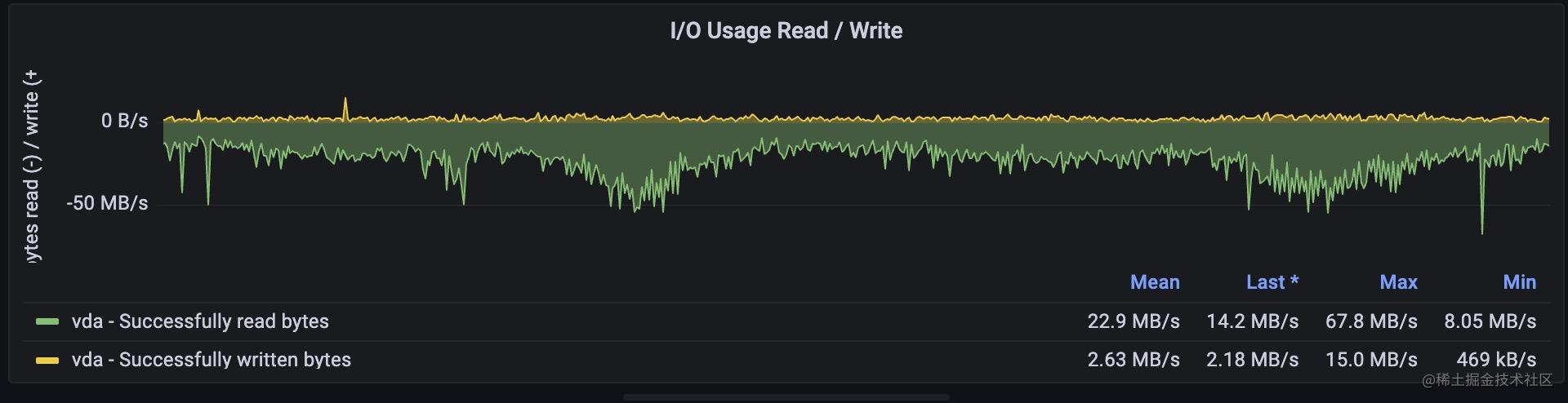
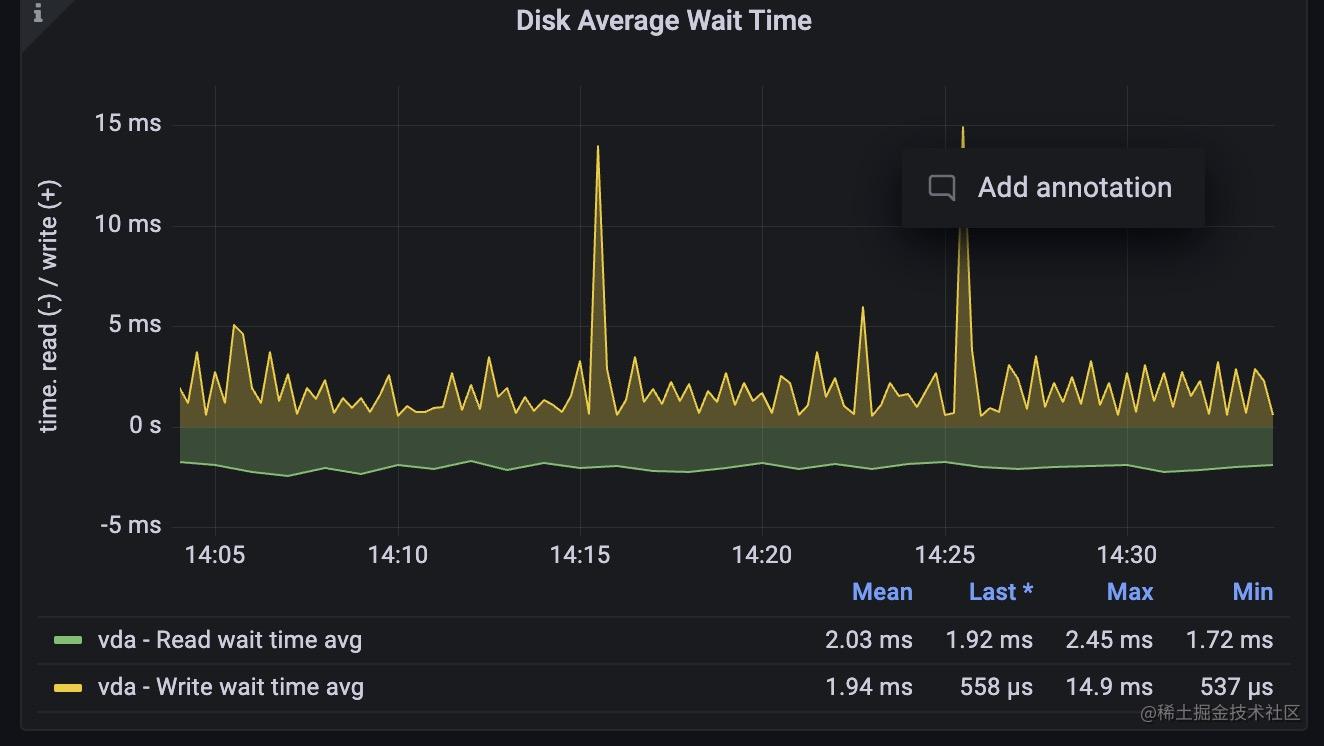
磁碟空間是一個guage型別的指標,而iops和吞吐量,等待時長都是一個counter型別用irate函數取的速率,promql語句比較簡單,這裡就不再繼續展開了。
網路
接著,我們看下在網路方面應該對哪些指標進行監控,網路封包的傳送涉及到網路卡的能力,網路卡能力也是有極限的,網路的延遲一般體現在介面上,我們不用在系統層面展示,流量可以用pps來表示,飽和度可以用頻寬來表示,錯誤數可以通過網路卡以及tcp層面暴露的錯誤資訊來表示 ,涉及到的指標含義如下:
1,頻寬 :這個和磁碟吞吐量比較類似,是單位時間內傳輸的位元組數,不過單位一般是bit/s 和位元組的換算 8 * bit/s = 1 B/s
2, pps : 每秒的收發包數量。
這兩個值也是在你購買不同規格的網路時有不同的極限值,我們需要注意監控指標是否和極限值比較接近的情況,達到極限值後會影響網路的效能。
這兩個指標同樣能夠從監控模板裡找到對應的面板,
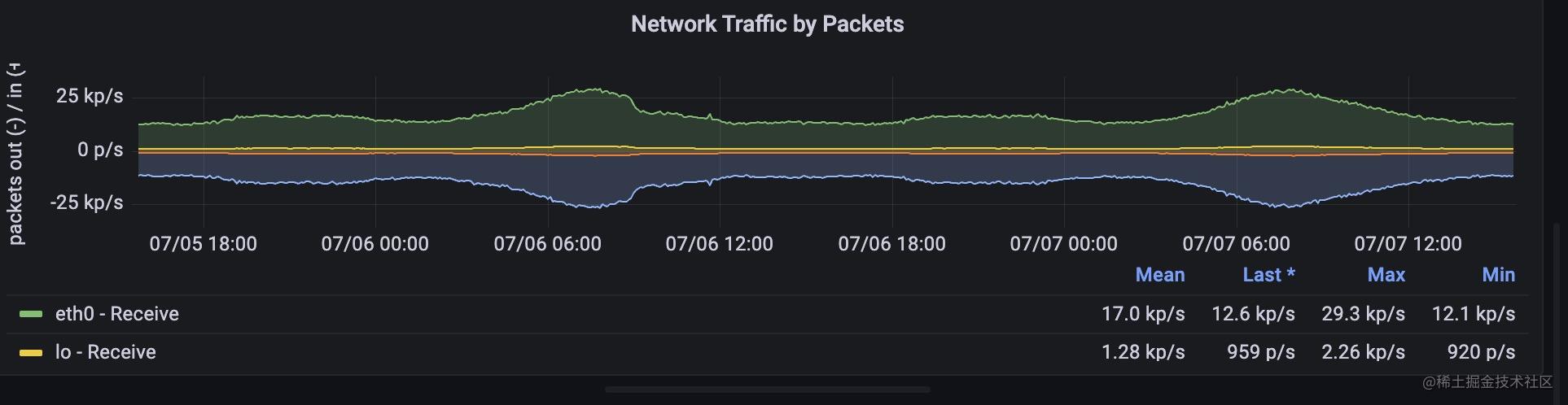
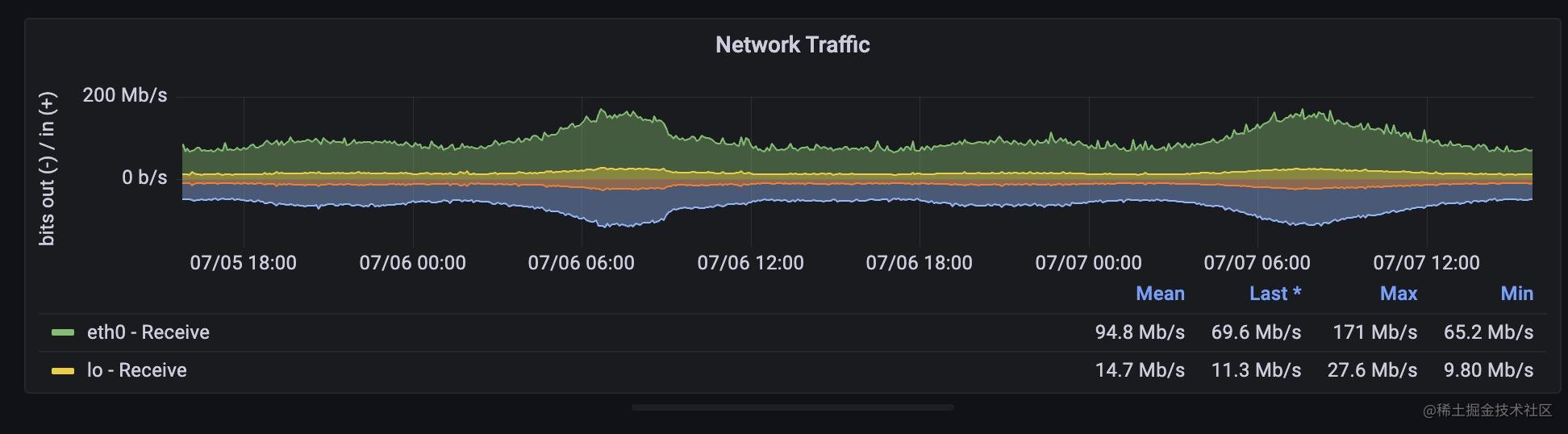
兩個指標都是counter型別,promql表示式用rate或者irate取值既可以看到pps或者流量速率了。
網路卡層面和tcp層面暴露的錯誤資訊
網路卡層面暴露的錯誤原理和ifconfig 看到網路卡的錯誤次數一致, RX errors 和 TX errors分別代表讀寫發生錯誤的次數。
// ifconfig 輸出結果
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.0.94 netmask 255.255.255.0 broadcast 192.168.0.255
ether fa:16:3e:ed:d6:94 txqueuelen 1000 (Ethernet)
RX packets 218761044009 bytes 151837637636460 (138.0 TiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 198948059963 bytes 110561548482730 (100.5 TiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
tcp 層面錯誤統計原理是從/proc/net/netstat讀取到相關資訊。
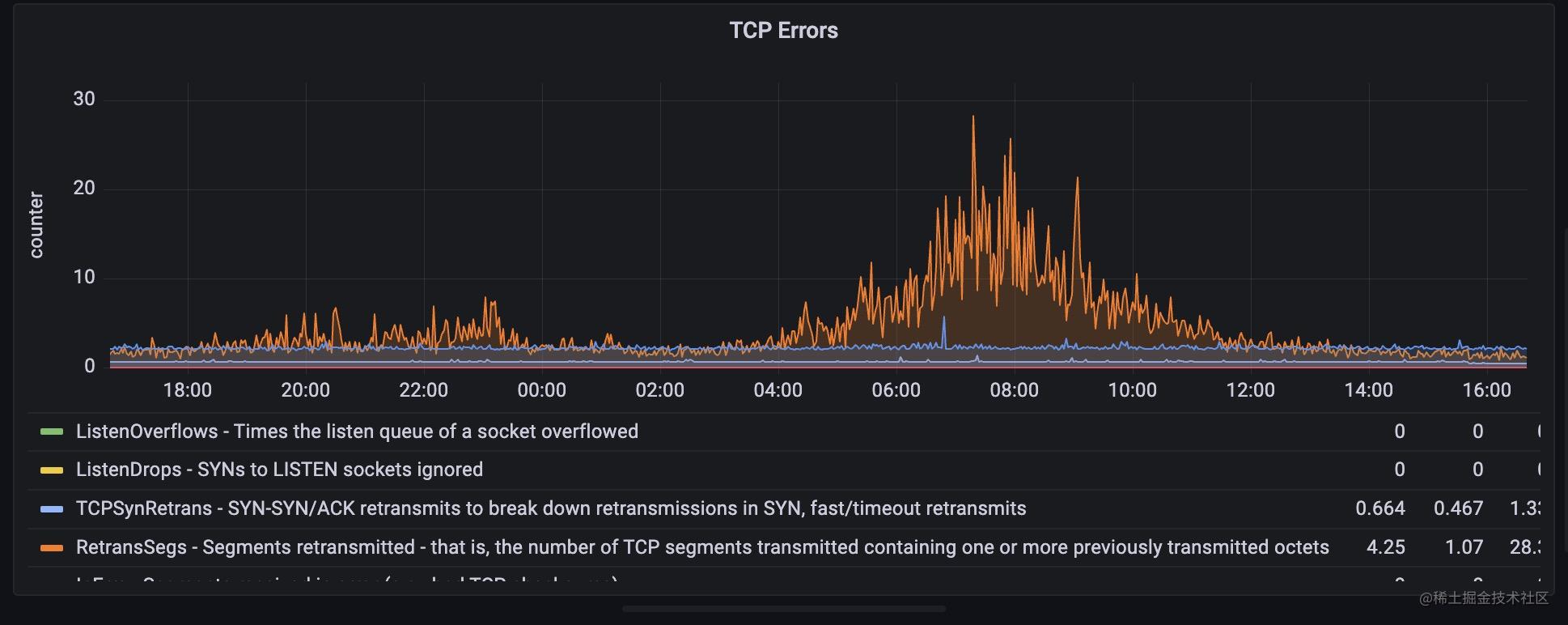
我們可以從監控面板中直接看出tcp出現錯誤最多的地方,在我這個面板裡,目前是高峰期出現重傳的情況比較多。
對連線的監控
但是僅僅用上面的監控只是從宏觀上看到網路的擁塞情況。我們有時可能更需要考慮在tcp層的飽和情況。
所以我們在此基礎上又加了連線數的監控。
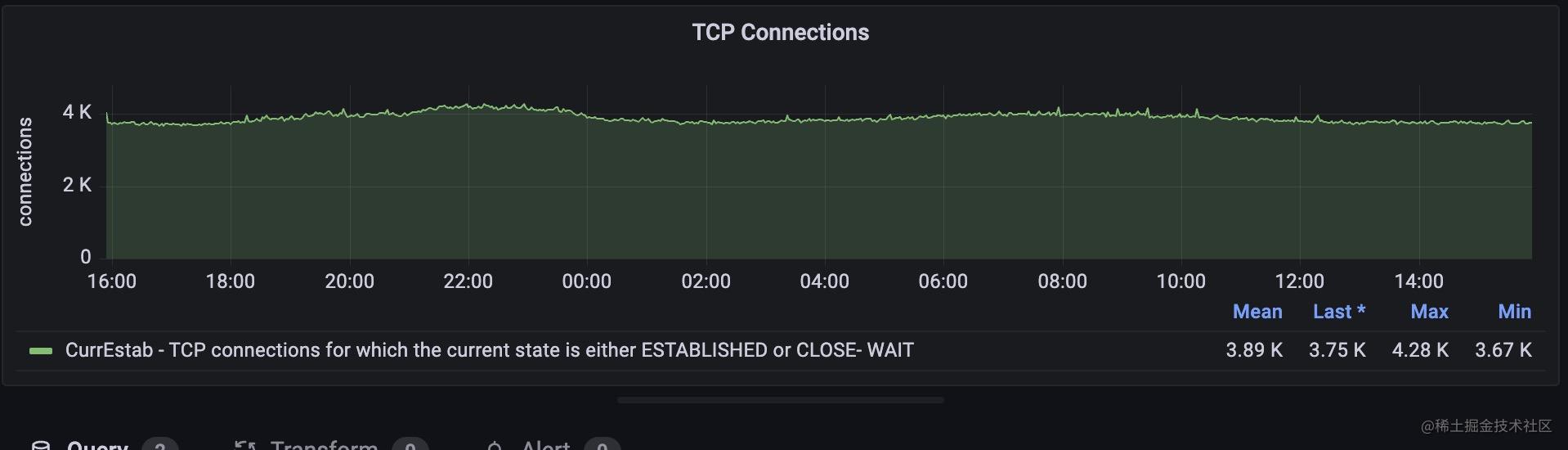
這個面板能夠展示tcp當前連結數,當前連結是處於 ESTABLISHED 和 CLOSE-WAIT 狀態的 TCP 連線數。
下面這個面板是展示了主動建立連線和被動建立連線的情況
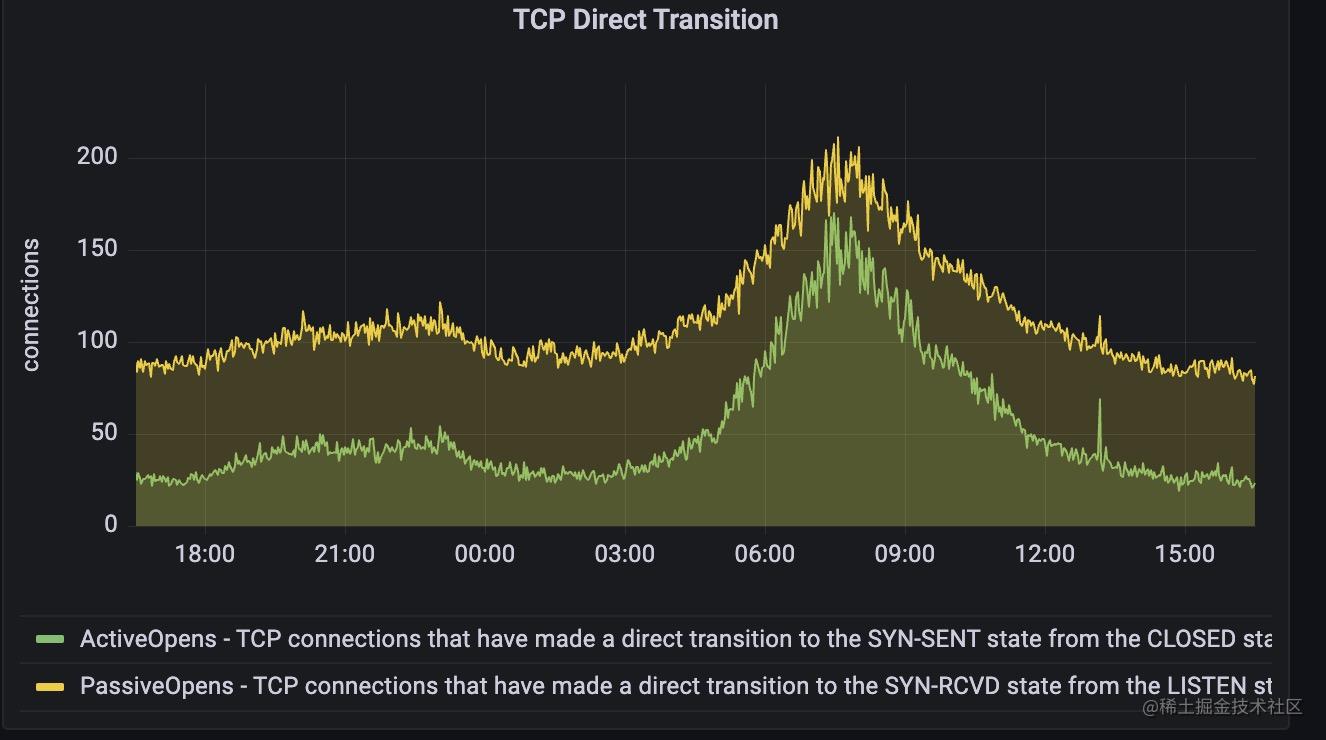
上述指標和用netstat -s 看tcp的資訊是一致的,node exporter服務也是採用用netstat工具類似的原理,從proc檔案系統的/proc/net/netstat 目錄讀取到相關資訊。
對程序狀態的監控
除了上述監控指標外,我們還加上了對整個系統內部程序狀態的監控,這是鑑於之前某些服務會產生異常子程序的情況才考慮新增的。主要對系統內各個時刻的程序狀態進行監控計數。

系統資源限制監控
除了上述監控外,系統內部還有一些資源不是無限的,也需要記錄下系統當前使用這些資源的情況,比如已經使用的檔案描述符,pid號,連線表nf_conntrack的大小(這個表滿了會產生丟包),執行緒數等等,我都統一歸納為資源限制監控了。具體面板就不在這裡貼上了。這些資源限制資源以後是我們建立報警時重點關注的指標。
總結
在這一節,我們通過node exporter 建立起了對機器層級的監控,涉及cpu,記憶體,磁碟,網路,其中涉及的監控面板來自於現有的監控模板node exporter full,不過由於node exporter full 數量實在太多,我們挑選了一些組成了最終的監控模版,模版的json檔案已經放到了文章開頭, 你完全可以將它直接匯入到你的grafana專案裡,建立起對機器層級的監控。
在萬千人海中,相遇就是緣分,為了這份緣分,給作者點個贊