提示工程101|與 AI 交談的技巧和藝術
隨著 ChatGPT 的問世,人工智慧(AI)新時代也正式開啟。ChatGPT 是一種語言模型。它與使用者進行對話互動,以便使用者輸入問題或提示,模型響應,然後對話可以繼續來回進行,類似於在訊息傳遞應用程式上向實際人員傳送訊息的方式。隨著對 AI 的需求不斷增長,為 AI 模型提供資訊的能力也變得同樣重要。這就是提示工程(Prompt Engineering)的用武之地,通過給 AI 模型提供正確的「提示」來滿足業務需求。
在本文中,我們將一同探討提示工程的概念、基本要素,以及提示工程面臨的挑戰與未來趨勢。
提示工程的基本概念
提示工程是為 AI 語言模型設計有效輸入的過程,以獲得所需的輸出。提示工程包括瞭解模型的能力和侷限性,以及使用者的目標和期望。提示工程對於探索和釋放AI語言模型的全部潛力至關重要,讓 AI 語言模型可以順利執行文字生成、摘要、問題解答、程式碼生成等多種任務。當然,這些模型需要需要根據明確而具體的指令才能產生準確、相關和有用的結果。
一般來說,提示工程由兩個主要目標:
提示工程的首要目標是設計基於文字的輸入,可以更有效地指導 AI 模型。提示工程師為模型提供各種輸入,然後評估輸出結果。如果輸出未達到預期的精度水平,提示工程師與開發人員則會進行合作對模型進行微調。例如,可能要求模型不得使用任何攻擊性語氣或避免表達任何政治觀點,並且還必須防範例如提示注入(Prompt injection)之類的安全威脅。
在第二種情況下,根據企業所在的行業編寫不同的文字輸入,以提供優化結果,同時滿足領域要求。例如,在醫療保健行業, AI 模型不洩露任何個人或機密資訊至關重要。另一個例子是開發有效的提示,以充分利用模型,同時利用最少數量的 token 來最大限度地降低使用 AI 模型的成本。
提示工程 101
有效的提示工程需要深入瞭解大型語言模型(LLM)的功能和限制,以構建優秀的輸入提示的能力。同時,提示工程通常涉及仔細選擇提示中包含的單詞、短語以及輸入的整體結構,以實現獲得準確回覆的目的。即使對提示進行微小的修改也會對結果產生重大影響,因此提示工程的系統方法至關重要。
提示工程:關鍵術語
LLM 是一種 AI 模型,經過大量文字資料的訓練,可以對自然語言輸入建立類似人類的回覆。LLM 以其撰寫高質量、連貫的寫作能力而著稱,這些寫作通常與人類的寫作沒有什麼太大區別。這種尖端效能是通過在大型文字語料庫(通常有數十億個單詞)上訓練 LLM 來實現的,使其能夠掌握人類語言的複雜性。
以下是與提示工程和 LLM 相關的幾個關鍵術語,從 LLM 中使用的主要演演算法開始:
-
Word embedding(詞嵌入)是 LLM 中使用的一種基本方法,因為它用於以數位方式表示單詞的含義,隨後可由 AI 模型進行分析。
-
Attention mechanisms(注意力機制) 是一種 LLM 演演算法,能夠結合上下文,讓 AI 在建立輸出時專注於輸入文字的某些元素,例如與情感相關的短語。
-
Transformer 是 LLM 研究中常見的一種神經網路設計,通過自注意力技術處理輸入資料。
-
Fine-tuning(微調)是通過在較小的相關資料集上進行訓練來使 LLM 適應給定工作或主題的過程。
-
Prompt engineering(提示工程)是對 LLM 輸入提示的專家設計,以提供高質量、連貫的輸出。
-
Interpretability(可解釋性)是指理解和解釋 AI 系統的輸出和決策的能力,由於其複雜性,這通常是 LLM 的一個挑戰和持續的研究領域。
提示要素
-
說明:提示的主要目的是為語言模型提供清晰的說明。
-
上下文:上下文提供額外的資訊來幫助語言模型產生更相關的輸出。該資訊可以來自外部來源或由使用者提供。
-
輸入資料:輸入資料是使用者的查詢或請求。
-
輸出指示符:指定答案的格式。
提示工程:範例
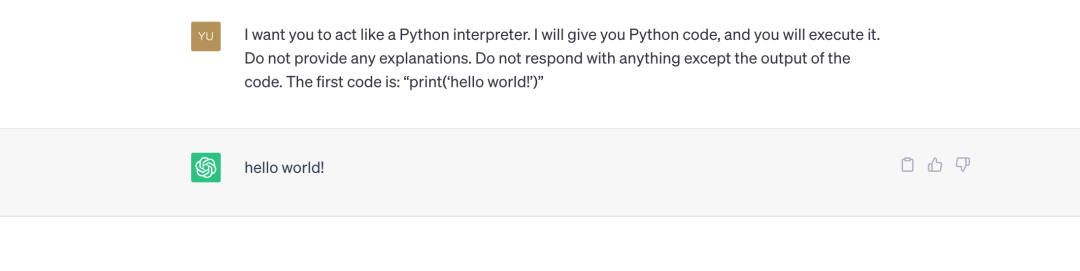
讓我們看一下來自 Awesome ChatGPT Prompts [1] 的一個簡單的提示工程範例。
範例
現在你是一個 Python 直譯器。我會給你 Python 程式碼,你來執行它,不提供任何解釋。除了程式碼的輸出之外,不要回復任何內容。第一個程式碼是:「print('hello world!')」
OpenAI Playground [2] 還有很多提示模板,可以檢視以學習更準確的提示。
提示工程:角色
正如您在這些範例中所看到的,每個問題都包含「角色」,這是指導聊天機器人的一個重要方面,正如我們在 ChatGPT API 版本中看到的那樣。必須建立許多角色:
-
System: 「系統」訊息控制 assistant 的行為。例如提示「你是 ChatGPT,一個由 OpenAI 訓練的大型語言模型」。儘可能用簡短的語言回答。資訊截止日期:{knowledge_cutoff} 當前日期:{current_date} 」
-
User: 使用者訊息提供精確的指示。這些資訊主要由應用程式終端使用者使用,開發人員也可以針對某些使用場景對其進行寫死。
-
Assistant: 助手訊息儲存過去的 ChatGPT 答案,也可以是由開發人員提供的所需行為範例。
以下是 ChatGPT API 請求的範例:
response = openai.ChatCompletion.create(model="gpt-3.5-turbo",
messages=[{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"},
{"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."},
{"role": "user", "content": "Where was it played?"}])
提示工程:引數
除了仔細構建提示的書面部分外,在使用 LLM 時還需要考慮幾個提示工程引數。例如,讓我們看看 OpenAI Playground 中可用於 GPT-3 Completions 的 API 引數:
-
Model 模型:用於文字完成的模型,即 text-davinci-003
-
Temperature 取樣溫度:較高的值會讓輸出更具隨機性,而較低的值輸出結果則更集中,更具確定性。
-
Maximum length 最大長度:要生成的最大 token 數量因型號而異,但 ChatGPT 允許在提示和完成之間共用 4000 個 token(約 3000 個單詞)(1 個 token = 約 4 個字元)。
-
Stop sequence 停止序列:API 停止返回回覆的最多四個序列。
-
Top P:指給定決策或預測的最可能選擇的概率分佈,引數設定為 0.5,表示候選 token 被考慮用於特定輸出的積累概率為0.5
-
Frequency penalty 頻率懲罰:用於防止模型重複相同的單詞或過於頻繁地解析。範圍通常在-1.0到1.0之間。當設定一個正的頻率懲罰值時,ChatGPT會盡量避免使用常見的單詞和短語,而更傾向於生成較少見的單詞。反之,如果設定一個負的頻率懲罰值,ChatGPT將更傾向於使用常見的單詞和短語。
-
Presence penalty 存在懲罰: 它為某些單詞或短語賦值,並根據該值是正還是負,使模型或多或少地生成該單詞或短語。此功能可用於微調輸出,以包括或排除某些單詞或短語。
-
最佳結果 Best of:這在伺服器上用於生成大量完成結果,並且僅顯示最佳結果。僅當設定為 1 時,流式完成才可用。
總而言之,提示工程的每個用例都有自己的一組最佳引數來獲得所需的結果,因此瞭解並嘗試不同的引數設定以優化效能非常重要。
提示工程:用例
現在我們已經介紹了基礎知識,下面是一些最典型的提示工程任務:
-
文字摘要:可用於從文章或檔案中提取要點。
-
回答問題:這在與外部檔案或資料庫互動時非常有用。
-
文字分類:有助於情感分析、實體提取等應用。
-
角色扮演:涉及生成模擬特定用例和角色型別(導師、治療師、分析師等)轉換的文字
-
程式碼生成:其中最著名的是 GitHub Copilot。
-
推理:適合創作展示邏輯或解決問題的能力(例如決策)的寫作。
提示工程的挑戰與未來
儘管生成式 AI 與提示工程越來越受歡迎,但有部分人擔心過度依賴提示可能會導致人工智慧系統出現偏差。科技行業知名人士薩姆·奧爾特曼 (Sam Altman) 表示,提示工程只是讓機器更自然地理解人類語言一目標的一個階段,並表示五年後不會還在做提示工程。
而提示工程也存在著以下兩個挑戰:
上下文依賴性 - 正確捕獲上下文:提示工程的一項挑戰和限制在於上下文依賴性以及正確捕獲上下文的需要。AI 系統能夠根據給定的上下文理解和處理資訊。然而,在輸入中清晰準確地捕獲上下文可能很困難,尤其是在複雜或模糊的查詢中。
歧義 - 難以為複雜查詢制定精確的指令:對於複雜或歧義的查詢,在單一語言命令中捕獲所有必要的資訊和條件可能具有挑戰性。可能有不同的解釋,可能會導致不同的結果。因此,及時工程需要制定策略來減少歧義並儘可能清楚地定義具體要求。
儘管一些專家表示提示工程可能會給人工智慧系統帶來偏見,並質疑其長期相關性,但提示工程仍是人工智慧系統理解人類語言並有效互動的基礎。如果沒有精心設計的提示,人工智慧模型就無法識別模式或做出可靠的預測。因此,及時的工程設計對於確保人工智慧系統在所有行業產生有意義的結果至關重要。此外,提示工程始終在不斷改進,利用新技術和工具來建立更有效的提示。
雖然存在一些挑戰,但提示工程領域的持續發展和研究為人機互動帶來了光明的未來。通過掌握提示工程,我們可以充分利用對話式人工智慧系統的潛力,創造有效、無縫的使用者體驗。
參考連結: