執行緒池shutdown引發TimeoutException
問題描述
分享一個發版過程服務報錯問題,問題出現在每次發版,服務準備下線的時候,報錯的位置是在將任務submit提交給執行緒池,使用Future.get()引發的TimeoutException,錯誤紀錄檔會列印下面的"error"。虛擬碼如下:
List<Future<Result<List<InfoVO>>>> futures = new ArrayList<>();
lists.forEach(item -> {
futures.add(enhanceExecutor.submit(() -> feignClient.getTimeList(ids)));
);
futures.forEach(
item -> {
try {
Result<List<InfoVO>> result = item.get(10, TimeUnit.SECONDS);
} catch (InterruptedException | TimeoutException | ExecutionException e) {
log.error("error", e);
}
}
);
程式碼邏輯非常簡單,就是將一個Feign介面的呼叫提交給執行緒池去並行執行,最終通過Feture.get()同步獲取結果,最多等待10s。
執行緒池的設定引數是:核心執行緒數為16,最大執行緒數為32,佇列為100,解決策略為CallerRunsPolicy,意為當執行緒無法處理任務時,任務交還給呼叫執行緒執行。
問題分析
問題分析的開始走了一些彎路,因為Timeout異常給人最直觀的感受就是介面超時了,加上這個介面也確實偶爾超時,所以我們用arthas分析了一下介面執行時間,發現介面並不慢,結合上面的執行緒池引數,基本不會出現超時。同時通過grafana上的監控,分析介面的qps和執行時間,基本可以排除是介面超時這一點。
後來開始懷疑是不是對方服務也在下線,因為我們幾個服務多數時候會一起更新,從而導致Feign出現異常,還使用了resilience4j,它裡面也有超時和執行緒池,會不會是它在這種場景下出現問題導致。
這裡又繞了一個圈,通過各種google,github,chatgpt後,沒有發現相關資料。這後來也給我一個警示就是,在懷疑相關元件之前,要先排查完自己的程式碼,沒有頭緒時不要一下子鑽進去。
後來結合紀錄檔的時間線,重新梳理。上面的執行緒池是我們自己封裝的執行緒池,支援監控、apollo動態修改執行緒池引數,紀錄檔跟蹤traceId列印,執行任務統計,服務下線執行緒退出等功能,這很像美團技術團隊提到的執行緒池,不過我們基於自己的需求進行封裝,使用起來更簡單、輕量。
在服務優雅下線這篇,我們寫到

在服務下線前該執行緒池會響應一個event bus訊息,然後執行執行緒池的shutdown方法,本意是服務下線時,執行緒池不再接收新的任務,並觸發拒絕策略。那會不會是這裡出現問題呢?
結合上面的程式碼,當執行緒池shutdown後,執行CallerRunsPolicy策略,再submit應該就會阻塞。這就是我們平時理解的,當佇列滿了,就繼續開啟執行緒至maximumPoolSize,如果執行緒數已經達到maximumPoolSize,並且佇列也滿了,此時就觸發解決策略。
如下程式碼,當第三次submit的時候就阻塞了,符合上面說的情況。
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(1, 1, 10, TimeUnit.MINUTES, new ArrayBlockingQueue<>(1), new ThreadPoolExecutor.CallerRunsPolicy());
threadPoolExecutor.submit(() -> {
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
}
});
threadPoolExecutor.submit(() -> {
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
}
});
//到這裡就阻塞了
threadPoolExecutor.submit(() -> {
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
}
});
那如何期間shutdown了呢?按照網上的很多介紹,如果執行緒池shutdown了,再提交任務,就觸發拒絕策略。這句話本身沒有錯,但也沒有完全對,坑就在這裡。 如果你執行下面的程式碼,會發現和上面是不一樣的,第三個submit不會阻塞了。
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(1, 1, 10, TimeUnit.MINUTES, new ArrayBlockingQueue<>(1), new ThreadPoolExecutor.CallerRunsPolicy());
threadPoolExecutor.submit(() -> {
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
}
});
threadPoolExecutor.submit(() -> {
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
}
});
//加了這一行
threadPoolExecutor.shutdown();
//這裡不會阻塞了...
threadPoolExecutor.submit(() -> {
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
}
});
為什麼會這樣呢,我們跟蹤下原始碼,發現它確實會走到拒絕策略,但在CallerRunsPolicy拒絕策略裡面有一個判斷,如果執行緒池不是shutdown的,就直接呼叫Runnable的run方法,這裡使用的是呼叫者執行緒,所以呼叫者執行緒會阻塞,如果執行緒池是shutdown的,就什麼也不做,相當於任務丟棄了。

按照這個說法,如果我在最後使用Future接收一下submit的返回值,然後呼叫Future.get方法,會發生什麼?
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(1, 1, 10, TimeUnit.MINUTES, new ArrayBlockingQueue<>(1), new ThreadPoolExecutor.CallerRunsPolicy());
threadPoolExecutor.submit(() -> {
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
}
});
threadPoolExecutor.submit(() -> {
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
}
});
//加了這一行
threadPoolExecutor.shutdown();
//這裡不會阻塞了...
Future future = threadPoolExecutor.submit(() -> {
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
}
});
//這裡會發生什麼?
future.get(10, TimeUnit.SECONDS);
結果是超時了,報了TimeoutException,如下圖:
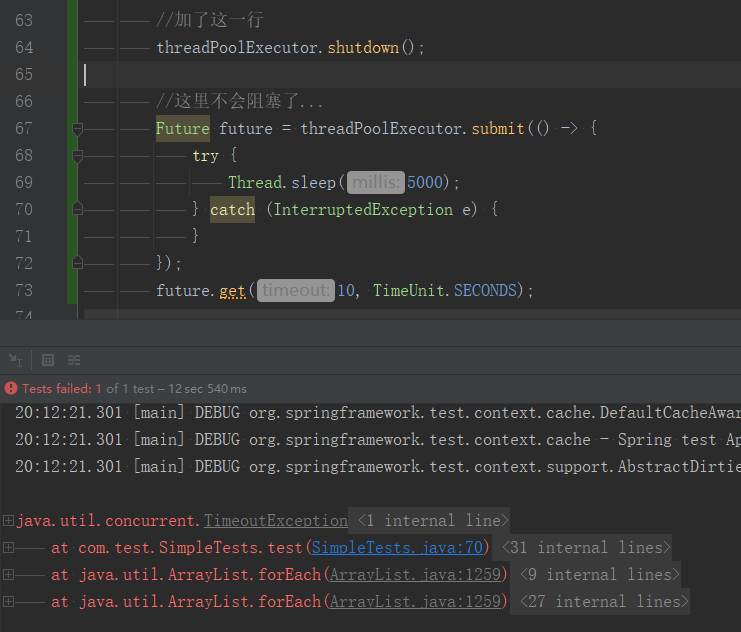
我們的問題得以復現,但future.get為什麼會超時呢?正常情況下,它是實現阻塞呼叫執行緒的,又是如何線上程拿到執行結果時返回執行的,這就需要我們對Future的原理有所理解了。
Future 原理
Future字面意思是未來的意思,很符合語意。當我們使用非同步執行任務的時候,在未來某個時刻想知道任務執行是否完成、獲取任務執行結果,甚至取消任務執行,就可以使用Future。
Future是一個介面,FutureTask是它的一個實現類,同時實現了Future和Runnable介面,也就是說FutureTask即可以作為Runnable執行,也可以通過它拿到結果。
ThreadPollExecutor.submit的原始碼如下,newTaskFor就是建立一個FutureTask。
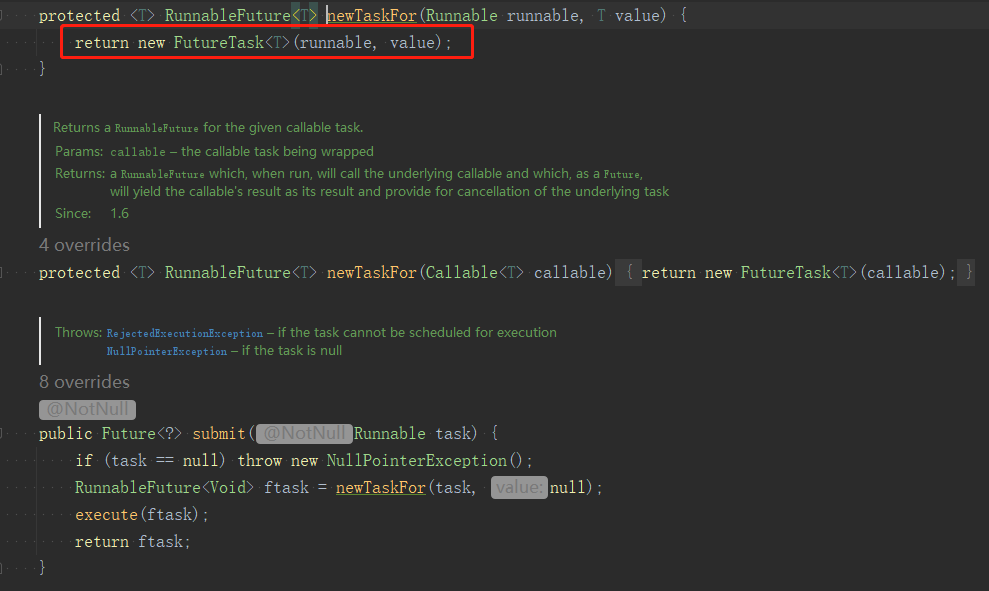
假如任務提交後還沒執行完,我們看它是如何實現阻塞的,帶超時時間的get()方法原始碼如下:
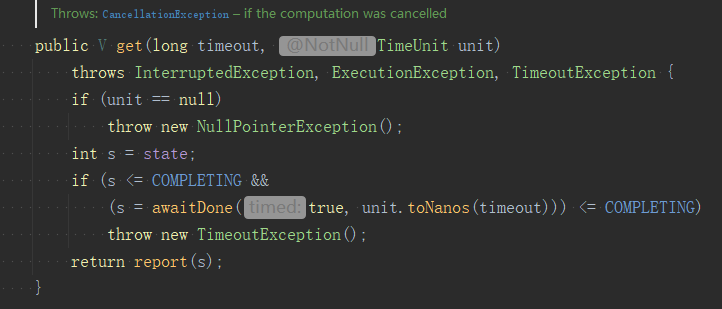
程式碼中判斷如果state > COMPLETING,就直接呼叫report,也就是直接返回。state是個私有成員遍歷,它可能有以下值,大於1表示是任務終態直接返回。
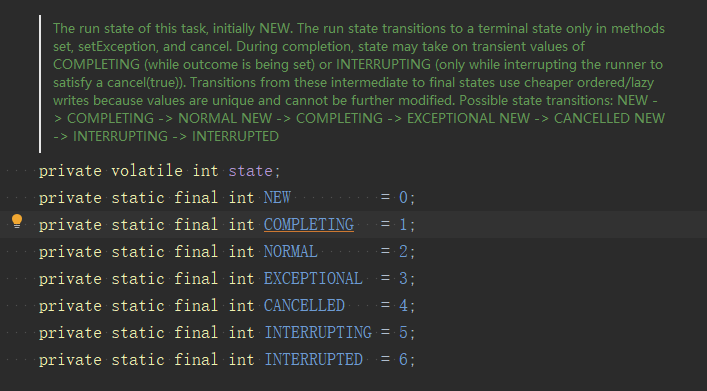
否則就進入awaitDone()方法,程式碼如下:
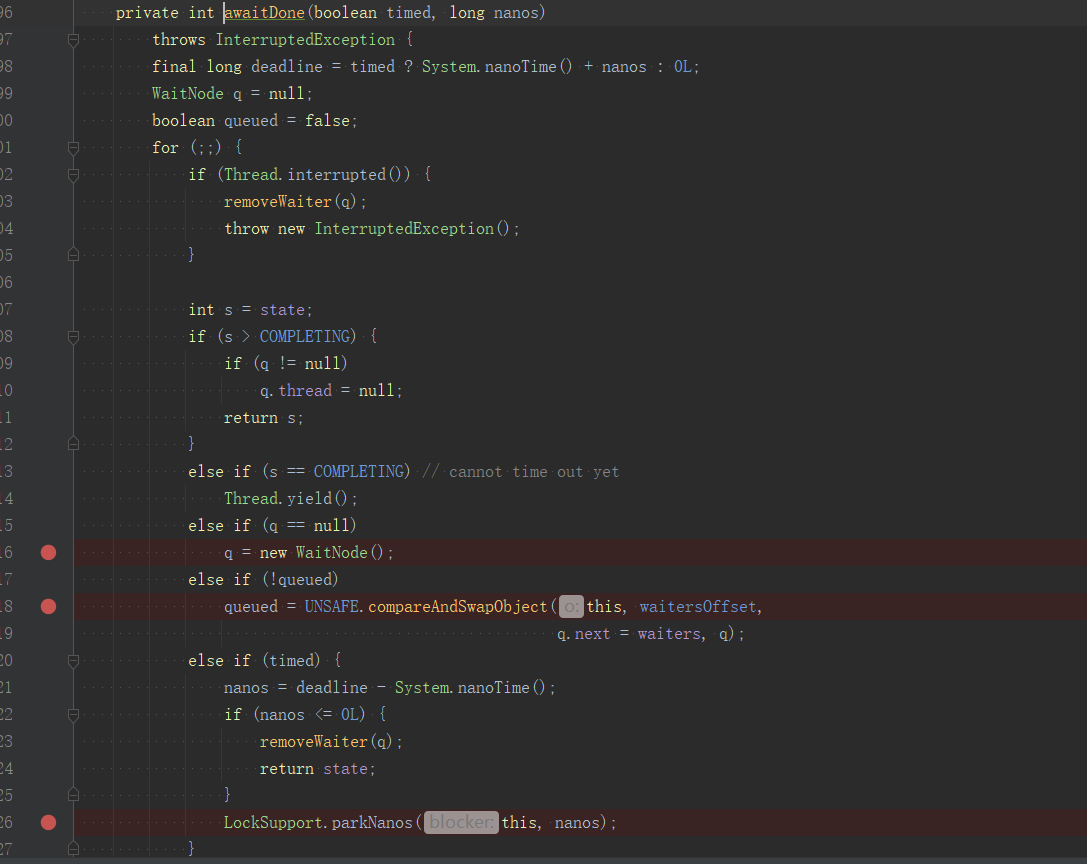
該方法是個無條件for迴圈,但它絕不是通過消耗cpu不斷檢查某個狀態來獲取結果,這樣效率太低了。
按照「正常」呼叫(我們只考慮最簡單場景,不要受一些異常或不重要的分支幹擾,以免越陷越深),這個for迴圈會進入3次,分別就是上圖打斷點的3個位置。
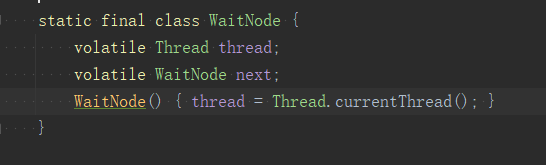
第一個位置會建立一個WaitNode節點,WaitNode保護一個Thread和一個next,很明顯它會構成一個連結串列。
第二個位置會嘗試用CAS的方式將它將這個節點新增到連結串列頭部,如果新增失敗,就會繼續for迴圈,一直到新增成功。新增成功就會進入第三個斷點位置。
第三個位置會呼叫LockSupport.parkNanos(this, nanos),阻塞當前執行緒。
這裡為什麼是一個連結串列呢? 原因很簡單,我們將任務提交後,可以在多個執行緒等這個任務的結果,也就是在多個執行緒呼叫get()方法,那麼每一次就會建立一個WaitNode,並形成一個連結串列。
ok,知道Future.get()怎麼實現阻塞的,我們看下當任務執行完,它是如何恢復並拿到結果的。
回到上面執行緒池的submit方法,FutureTask作為一個Runnable傳遞給執行緒池execute,那麼最終就會執行它的run()方法。
我們還是主要看「正常」執行的流程,執行完會走到set方法,做兩個事情:
1.將state狀態設定為NOMAL,表示任務正常執行完成。
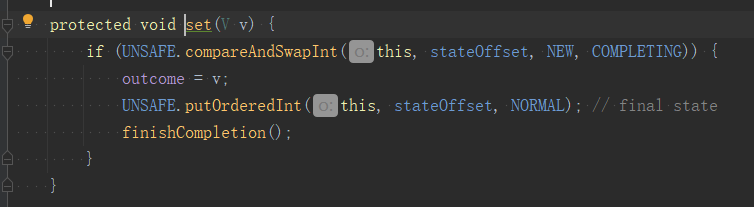
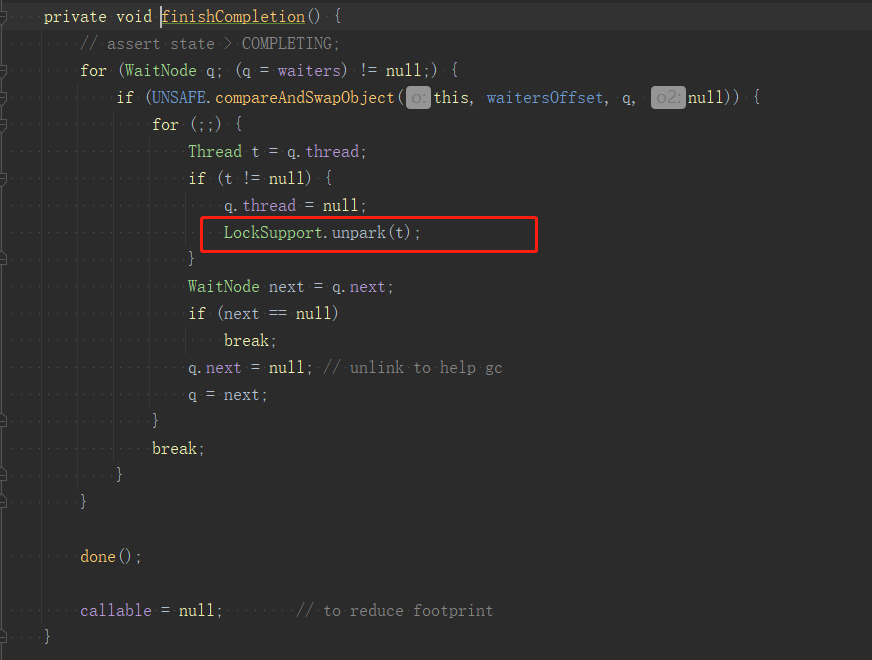
2.執行finishCompletion方法,遍歷waiters連結串列所有節點,每個節點對應一個執行緒,將執行緒取出來,執行LockSupport.unpark(t)恢復執行緒執行。
總結
通過原始碼分析我們知道,當呼叫Future.get()執行緒阻塞時,它的恢復是靠FutureTask.run()恢復的,也就是我們提交的任務被執行後恢復。
當我們執行緒shutdown後,再submit任務確實會觸發拒絕策略,但CallerRunsPolicy會判斷執行緒池狀態是否是shutdown,如果不是,就直接呼叫Runnable.run()方法,相當於在呼叫執行緒執行。如果是shutdown狀態就什麼都不做,問題就出在這裡,我們是要依靠它的執行來恢復阻塞的,現在什麼都不做,就無法恢復了。同樣的DiscardPolicy,DiscardOldestPolicy也會有這個問題,AbortPolicy是直接丟擲異常,呼叫執行緒在submit就拋異常了,走不到Future.get()方法。
但java為什麼要這麼做呢?這個拒絕策略的本意就是使用呼叫者執行緒執行,但這種情況下卻將任務丟棄了。我看了jdk17的原始碼,這個邏輯並沒有改變,也就是有一定的合理性。
執行緒池關閉當執行緒池已經shutdown,則意味著其不能再接收新任務,如果它shutdown了還使用呼叫執行緒執行,其實本質上還是在接收新任務,這違背了執行緒池規定的shutdown以後不再接收新任務的語意。
總之,在使用shutdown的時候需要注意這個問題,例如我們的場景應該是在觸發服務下線等待請求都處理完成後再shutdown,而不是一開始就shutdown,這樣有一些請求還在處理中就會出現問題。或者在保證服務下線等待事件內任務都能處理完,就乾脆不要shutdown了,讓呼叫者自己去保證這個事情,處理後報錯已經不再出現。
更多分享,歡迎關注我的github:https://github.com/jmilktea/jtea