我真的想知道,AI編譯器中的IR是什麼?
隨著深度學習的不斷髮展,AI 模型結構在快速演化,底層計算硬體技術更是層出不窮,對於廣大開發者來說不僅要考慮如何在複雜多變的場景下有效的將算力發揮出來,還要應對 AI 框架的持續迭代。
AI 編譯器就成了應對以上問題廣受關注的技術方向,讓使用者僅需專注於上層模型開發,降低手工優化效能的人力開發成本,進一步壓榨硬體效能空間。IR對於AI編譯器來說是非常重要的一種資料結構鴨!!!
IR 中間表達
什麼是IR
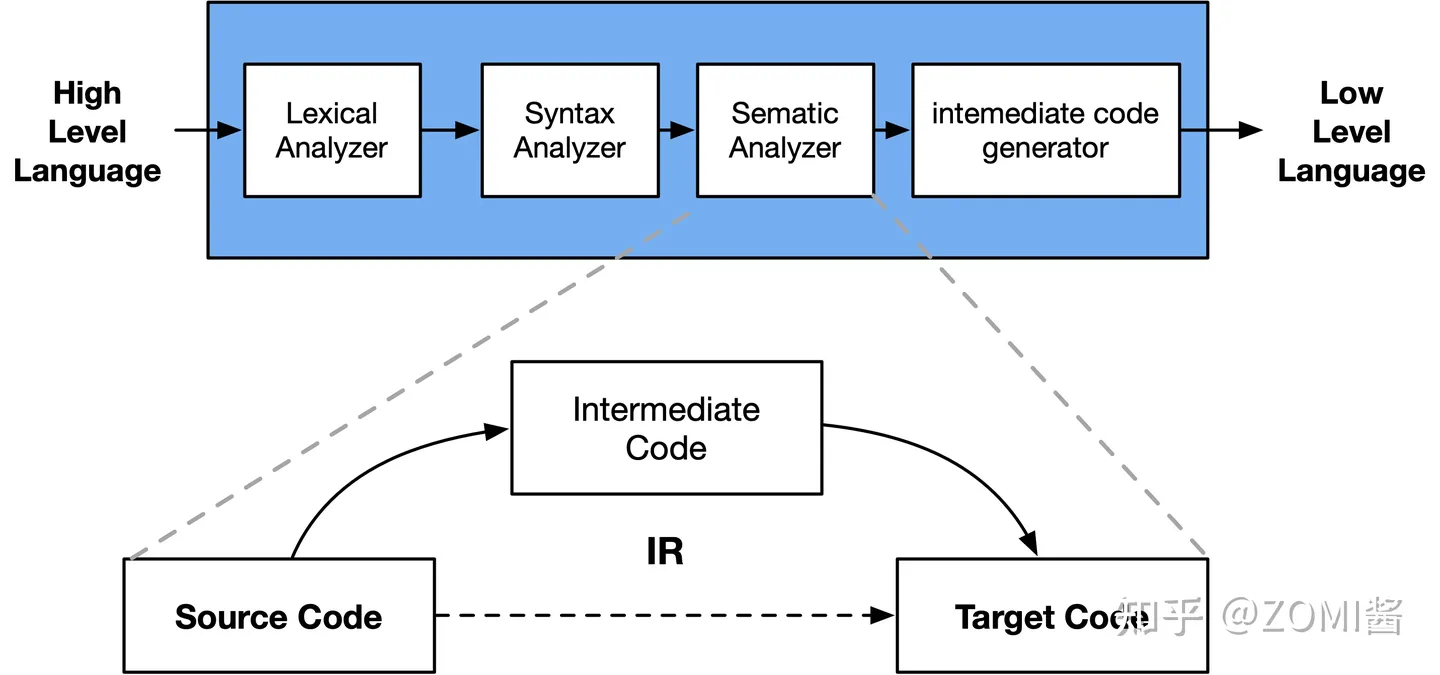
IR(Intermediate Representation)中間表示,是編譯器中很重要的一種資料結構。編譯器在完成前端工作以後,首先生成其自定義的 IR,並在此基礎上執行各種優化演演算法,最後再生成目的碼。
從廣義上看,編譯器的執行過程中,中間節點的表示,都可以統稱為 IR。從狹義上講編譯器的 IR,是指該編譯器明確定義的一種具體的資料結構,這個資料結構通常還伴隨著一種語言來表達程式,這個語言程式用來實現這個明確定義的 IR。大部分時間,不太嚴格區分這個明確定義的 IR 以及其伴隨的語言程式,將其統稱為 IR。
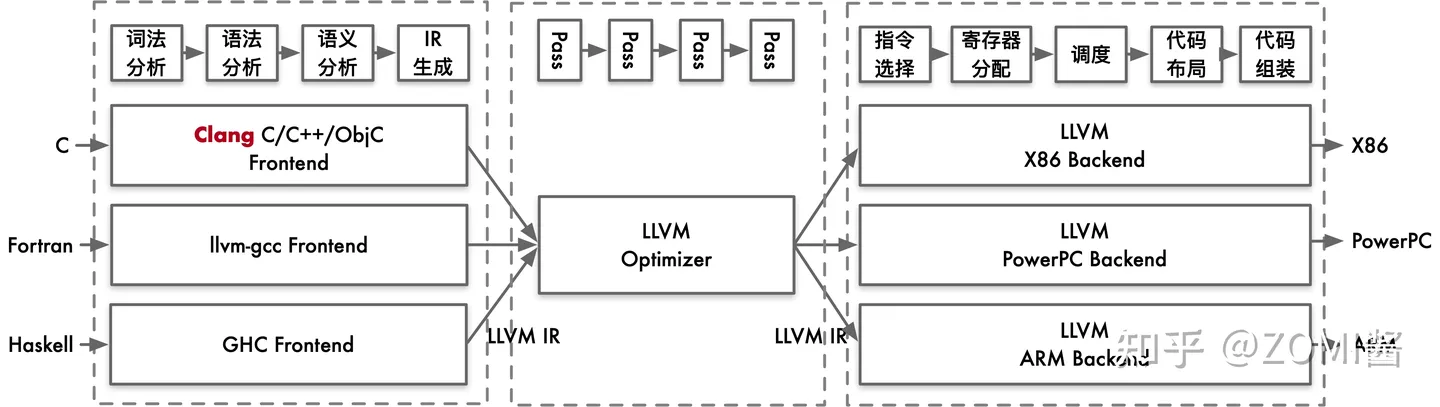
如圖所示,在編譯原理中,通常將編譯器分為前端和後端。其中,前端會對所輸入的程式進行詞法分析、語法分析、語意分析,然後生成中間表達形式 IR。後端會對 IR 進行優化,然後生成目的碼。
例如:LLVM 把前端和後端給拆分出來,在中間層明確定義一種抽象的語言,這個語言就叫做 IR。定義了 IR 以後,前端的任務就是負責最終生成 IR,優化器則是負責優化生成的IR,而後端的任務就是把 IR 給轉化成目標平臺的語言。LLVM 的 IR 使用 LLVM assembly language 或稱為 LLVM language 來實現 LLVM IR的型別系統,就指的是 LLVM assembly language 中的型別系統。
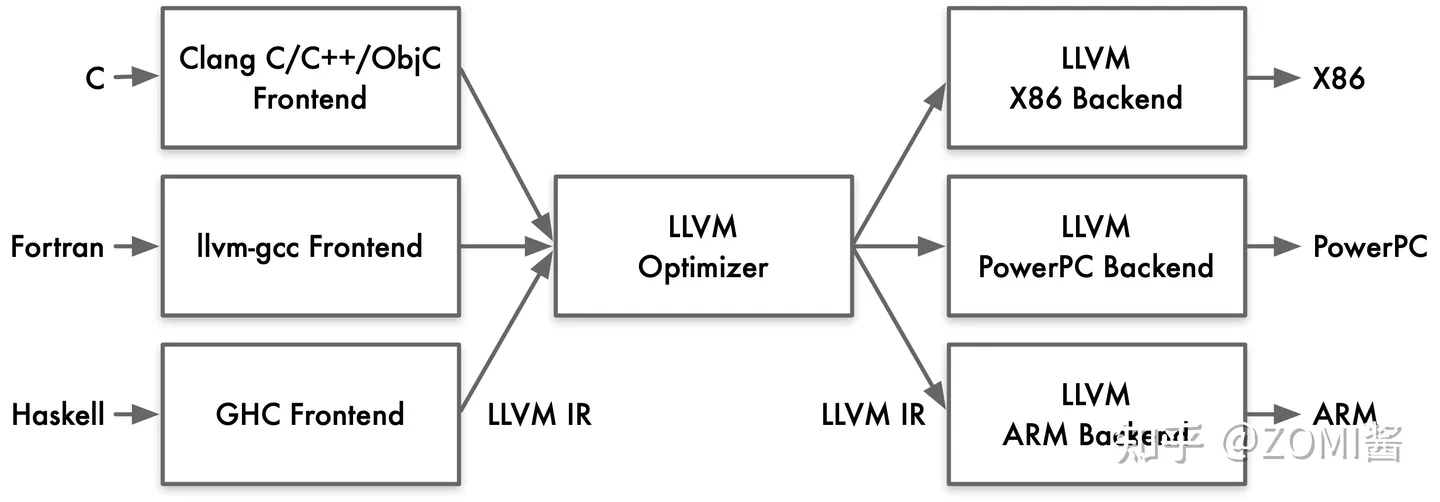
因此,編譯器的前端,優化器,後端之間,唯一交換的資料結構型別就是 IR,通過 IR 來實現不同模組的解耦。有些IR還會為其專門起一個名字,比如:Open64的IR通常叫做WHIRL IR,方舟編譯器的IR叫做MAPLE IR,LLVM則通常就稱為LLVM IR。
IR的定義
IR 在通常情況下有兩種用途,1)一種是用來做分析和變換,2)一種是直接用於解釋執行。
編譯器中,基於 IR 的分析和處理工作,前期階段可以基於一些抽象層次比較高的語意,此時所需的 IR 更接近原始碼。而在編譯器後期階段,則會使用低層次的、更加接近目的碼的語意。基於上述從高到低的層次抽象,IR 可以歸結為三層:高層 HIR、中間層 MIR 和 底層 LIR。
- HIR
HIR(High IR)高層 IR,其主要負責基於源程式語言執行程式碼的分析和變換。假設要開發一款 IDE,主要功能包括:發現語法錯誤、分析符號之間的依賴關係(以便進行跳轉、判斷方法的過載等)、根據需要自動生成或修改一些程式碼(提供重構能力)。此時對 IR 的需求是能夠準確表達源程式語言的語意即可。
其實,AST 和符號表就可以滿足上述需求。也就是說,AST 也可以算作一種特殊的 IR。如果要開發 IDE、程式碼翻譯工具(從一門語言翻譯到另一門語言)、程式碼生成工具、程式碼統計工具等,使用 AST(加上符號表)即可。基於 HIR,可以執行高層次的程式碼優化,比如常數摺疊、內聯關聯等。在 Java 和 Go 的編譯器中,有不少基於 AST 執行的優化工作。
- MIR
MIR(Middle IR),獨立於源程式語言和硬體架構執行程式碼分析和具體優化。大量的優化演演算法是通用的,沒有必要依賴源程式語言的語法和語意,也沒有必要依賴具體的硬體架構。這些優化包括部分算術優化、常數和變數傳播、死程式碼刪除等,實現分析和優化功能。
因為 MIR 跟源程式程式碼和目標程式程式碼都無關,所以在編譯優化演演算法(Pass)過程中,通常是基於 MIR,比如三地址程式碼(Three Address Code,TAC)。
三地址程式碼 TAC 的特點:最多有三個地址(也就是變數),其中賦值符號的左邊是用來寫入,右邊最多可以有兩個地址和一個操作符,用於讀取資料並計算。
- LIR
LIR(Low IR),依賴於底層具體硬體架構做優化和程式碼生成。其指令通常可以與機器指令一一對應,比較容易翻譯成機器指令或組合程式碼。因為 LIR 體現了具體硬體(如 CPU)架構的底層特徵,因此可以執行與具體 CPU 架構相關的優化。
多層 IR 和單層 IR 比較起來,具有較為明顯的優點:
- 可以提供更多的源程式語言的資訊
- IR表達上更加地靈活,更加方便優化
- 使得優化演演算法和優化Pass執行更加高效
如在 LLVM 編譯器裡,會根據抽象層次從高到低,採用了前後端分離的三段結構,這樣在為編譯器新增新的語言支援或者新的目標平臺支援的時候,就十分方便,大大減小了工程開銷。而 LLVM IR 在這種前後端分離的三段結構之中,主要分開了三層 IR,IR 在整個編譯器中則起著重要的承上啟下作用。從便於開發者編寫程式程式碼的理解到便於硬體機器的理解。