Lite-Mono(CVPR2023)論文解讀
Lite-Mono: A Lightweight CNN and Transformer Architecture for Self-Supervised Monocular Depth Estimation 是CVPR2023收錄的論文,從它的標題能很清晰瞭解到它所在的領域或解決的問題是:自監督的單目深度估計;它的網路結構是輕量化的折積和Transformer的混合結構。
解決的問題
大多數的研究都是往提高任務的準確率,這必然造成所設計的網路更注重準確率,使網路的體積或計算量大幅提高,這使在邊緣終端上使用的可能性越來越小。本文針對自監督的單目深度估計,探討在控制網路引數量的同時保持或提高準確性。
主要貢獻
1. 在自監督的單目深度估計方面,降低網路的引數量和運算量,同時提升了準確率。提高在邊緣終端上使用的可能性。
相關研究
1)監督的深度估計
[1] Depth map prediction from a single image using a multi-scale deep netwrk. (NeurIPS2014)
[2] Deeper depth prediction with fully convolutional residual networks. (3DV2016)
[3] Deep ordinal regression network for monocular depth estimation. (CVPR2018)
2)自監督的深度估計
[4] Unsupervised cnn for single view depth estimation: Geometry to the rescue. (ECCV2016)
[5] Unsupervised monocular depth estimation with left-right consistency. (CVPR2017)
[6] Unsupervised learning of depth and ego-motion from video. (CVPR2017)
[7] Digging into self-supervised monocular depth estimation. (ICCV2019)
3)這方面的網路架構
[8] Self-supervised monocular depth estimation with internal feature fusion. (2021)
[9] R-msfm: Recurrent multi-scale feature modulation for monocular depth estimating. (ICCV2021)
[10] Transformers in self-supervised monocular depth estimation with unknown camera intrinsics. (2022)
[11] Vision transformers for dense prediction. (ICCV2021)
[12] Monoformer: Towards generalization of self-supervised monocular depth estimation with transformers. (2022)
[13] Monovit: Self-supervised monocular depth estimation with a vision transformers. (3DV2022)
[14] Mpvit: Multi-path vision transformer for dense prediction. (CVPR2022)
解決方案和關鍵點
1)網路結構

作者的工作主要在DepthNet上,PoseNet是一直沿用ResNet-18的方案(從 [7] 之後沒有改變)。
DepthNet是4-Stage結構,每個Stage進行1/2解析度的下取樣(新的特徵圖是原來的1/4),這是比較常規的做法,另一種是5-Stage,考慮到是輕量化的工作,選擇5-Stage的可能性更小(引數量和計算量)。在Encoder裡另一個特別的做法是Stage-1與Decoder沒有連線,與常見的類UNet結構有些區別,估計也是為了輕量化考慮。
Encoder一共4個創新點:
1. CDC Block;
2. LGFI Block;
3. Pooled Concatenation;
4. Cross-Stage Connction.
2)Consecutive Dilated Convolutions (CDC)
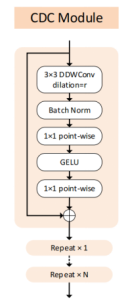
CDC主要由三部分組成:3 x 3的空洞深度可分離折積和兩層全連線。作者提到與之前的空洞折積通常在並聯使用,而這裡會串聯使用,簡單說,每個CDC Block的Dilation值可能設定不一樣,這使CDC的感受野有所區別,增加抓取特徵的多樣性。使用深度可分離折積(MobileNet v1)是輕量化手段之一,但同時也會弱化網路的表現能力。為了解決這個問題,depth-wise折積通常連線著point-wise折積,從作用上等效普通的折積層。作者在這裡沒有使用point-wise,而是在通道(channel)上使用全連線,變相達到point-wise效果並且進行channel膨脹。再由最後一層全連線投影回原通道,從結構上有點深度可分離折積接傳統MLP的味道,但引數量更少。
3)Local-Global Features Interaction (LGFI)
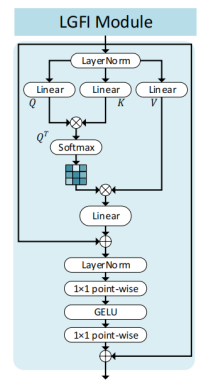
LGFI主要由兩部分組成:自注意力模組和MLP。兩部分都沒有什麼特別的地方,Transformer模組本身不會增加很多引數量,它的消耗主要在計算量上,所以作者在Stage-2 到 Stage-4,每個Stage只使用一個LGFI。把全域性關聯性作為一個補充,而不是主要。
4)Pooled Concatenation
在Stage-2 到 Stage-4的輸入端增加3個原圖下取樣的特徵,3個特徵圖分別是R,G,B,而下取樣的方式是平均池化。由於從原圖直接平均池化到目標解析度會引起大量細節丟失,所以作者使用多次1/2平均池化的做法。相比較每個Stage的輸入通道數,Pooled Concatenation所提供3個通道的影響比較有限,從消融實驗中能看出來。
5)Cross-Stage Connection
在Stage-3和Stage-4的輸入端,除了上一個Stage的輸入之外,增加上一個Stage的「生圖」。由於每個Stage的通道數是固定的,所以下一個Stage的輸入通道數成倍增加,應該是從增加特徵多樣性上考慮。但從消融實驗中能看出來,它的作用不是太大。
6)網路設定

作者提供了4種不同的網路設定,最小隻有2.0M引數量,比現在一般的網路都小得多,能為不同的邊緣終端選擇合適的設定。
總結
在實驗部分可以看到本網路結構在引數量、計算量和準確率均比之前的網路有所提高,主要還是得益於CDC和LGFI。實驗部分我沒有談到,如果需要的話,可以補充上去。
Transformer模組在視覺上的使用都得到廣泛的認可,它主要還是計算量方面的損耗比較大,但在小尺寸特徵圖上的損耗沒這麼突出,所以在Stage-4裡可以嘗試使用更多的Transformer模組。