想在golang裡用好泛型還挺難的
golang的泛型已經出來了一年多了,從提案被接受開始我就在關注泛型了,如今不管是在生產環境還是開源專案裡我都寫了不少泛型程式碼,是時候全面得回顧下golang泛型的使用體驗了。
先說說結論,好用是好用,但問題也很多,有些問題比較影響使用體驗,到了不吐不快的地步了。
這篇文章不會教你泛型的基礎語法,並且要求你對golang的泛型使用有一定經驗,如果你還是個泛型的新手,可以先閱讀下官方的教學,然後再閱讀本篇文章。
泛型的實現
實現泛型有很多種方法,常見的主流的是下面這些:
- 以c++為代表的,型別引數就是個預留位置,最後實際上會替換成實際型別,然後以此為模板生成實際的程式碼,生成多份程式碼,每份的型別都不一樣
- 以TypeScript和Java為代表的型別擦除,把型別引數泛化成一個滿足型別約束的型別(Object或者某個interface),只生成一份程式碼
- 以c#為代表,程式碼裡表現的像型別擦除,但執行的時候實際上和c++一樣採用模板範例化對每個不同的型別都生成一份程式碼
那麼golang用的哪種呢?哪種都不是,golang有自己的想法:gcshape。
什麼是gcshape?簡單得說,所有擁有相同undelyring type的型別都算同一種shape,所有的指標都算一種shape,除此之外就算兩個型別大小相同甚至欄位的型別相同也不算同一個shape。
那麼這個shape又是什麼呢?gc編譯器會根據每個shape生成一份程式碼,擁有相同shape的型別會共用同一份程式碼。
看個簡單例子:
func Output[T any]() {
var t T
fmt.Printf("%#v\n", t)
}
type A struct {
a,b,c,d,e,f,g int64
h,i,j string
k []string
l, m, n map[string]uint64
}
type B A
func main() {
Output[string]()
Output[int]()
Output[uint]()
Output[int64]()
Output[uint64]() // 上面每個都underlying type都不同,儘管int64和uint64大小一樣,所以生成5份不同的程式碼
Output[*string]()
Output[*int]()
Output[*uint]()
Output[*A]() // 所有指標都是同一個shape,所以共用一份程式碼
Output[A]()
Output[*B]()
Output[B]() // B的underlying tyoe和A一樣,所以和A共用程式碼
Output[[]int]()
Output[*[]int]()
Output[map[int]string]()
Output[*map[int]string]()
Output[chan map[int]string]()
}
驗證也很簡單,看看符號表即可:
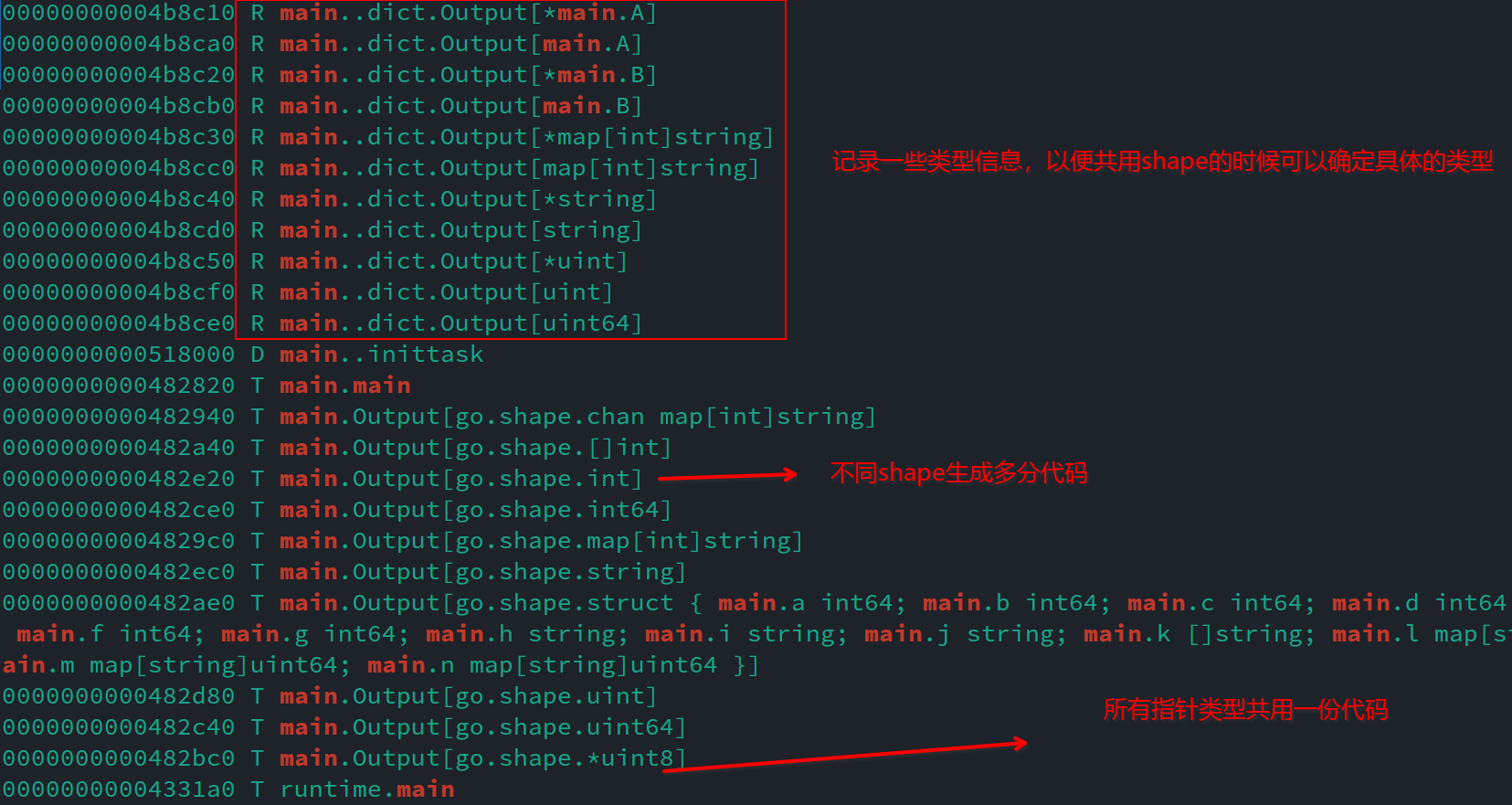
為啥要這麼做?按提案的說法,這麼做是為了避免程式碼膨脹同時減輕gc的負擔,看著是有那麼點道理,有相同shape的記憶體佈局是一樣的,gc處理起來也更簡單,生成的程式碼也確實減少了——如果我就是不用指標那生成的程式碼其實也沒少多少。
儘管官方拿不出證據證明gcshape有什麼效能優勢,我們還是姑且認可它的動機吧。但這麼實現泛型後導致了很多嚴重的問題:
- 效能不升反降
- 正常來說型別引數是可以當成普通的型別來用的,但golang裡有很多時候不能
正因為有了gcshape,想在golang裡用對泛型還挺難的。
效能問題
這一節先說說效能。看個例子:
type A struct {
num uint64
num1 int64
}
func (a *A) Add() {
a.num++
a.num1 = int64(a.num / 2)
}
type B struct {
num1 uint64
num2 int64
}
func (b *B) Add() {
b.num1++
b.num2 = int64(b.num1 / 2)
}
type Adder interface {
Add()
}
func DoAdd[T Adder](t T) {
t.Add()
}
func DoAddNoGeneric(a Adder) {
a.Add()
}
func BenchmarkNoGenericA(b *testing.B) {
obj := &A{}
for i := 0; i < b.N; i++ {
obj.Add()
}
}
func BenchmarkNoGenericB(b *testing.B) {
obj := &B{}
for i := 0; i < b.N; i++ {
obj.Add()
}
}
func BenchmarkGenericA(b *testing.B) {
obj := &A{}
for i := 0; i < b.N; i++ {
DoAdd(obj)
}
}
func BenchmarkGenericB(b *testing.B) {
obj := &B{}
for i := 0; i < b.N; i++ {
DoAdd(obj)
}
}
func BenchmarkGenericInterfaceA(b *testing.B) {
var obj Adder = &A{}
for i := 0; i < b.N; i++ {
DoAdd(obj)
}
}
func BenchmarkGenericInterfaceB(b *testing.B) {
var obj Adder = &B{}
for i := 0; i < b.N; i++ {
DoAdd(obj)
}
}
func BenchmarkDoAddNoGeneric(b *testing.B) {
var obj Adder = &A{}
for i := 0; i < b.N; i++ {
DoAddNoGeneric(obj)
}
}
猜猜結果,是不是覺得引入了泛型可以解決很多效能問題?答案揭曉:
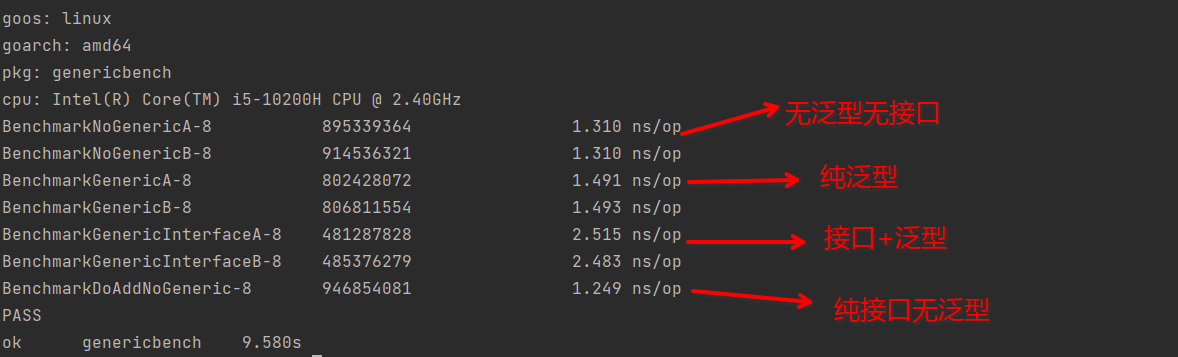
哈哈,純泛型和正常程式碼比有不到10%的差異,而介面+泛型就慢了接近100%。直接用介面是這裡最快的,不過這是因為介面被編譯器優化了,原因參加這篇。
你說誰會這麼寫程式碼啊,沒事,我再舉個更常見的例子:
func Search[T Equaler[T]](slice []T, target T) int {
index := -1
for i := range slice {
if slice[i].Equal(target) {
index = i
}
}
return index
}
type MyInt int
func (m MyInt) Equal(rhs MyInt) bool {
return int(m) == int(rhs)
}
type Equaler[T any] interface {
Equal(T) bool
}
func SearchMyInt(slice []MyInt, target MyInt) int {
index := -1
for i := range slice {
if slice[i].Equal(target) {
index = i
}
}
return index
}
func SearchInterface(slice []Equaler[MyInt], target MyInt) int {
index := -1
for i := range slice {
if slice[i].Equal(target) {
index = i
}
}
return index
}
var slice []MyInt
var interfaces []Equaler[MyInt]
func init() {
slice = make([]MyInt, 100)
interfaces = make([]Equaler[MyInt], 100)
for i := 0; i < 100; i++ {
slice[i] = MyInt(i*i + 1)
interfaces[i] = slice[i]
}
}
func BenchmarkSearch(b *testing.B) {
for i := 0; i < b.N; i++ {
Search(slice, 99*99)
}
}
func BenchmarkInterface(b *testing.B) {
for i := 0; i < b.N; i++ {
SearchInterface(interfaces, 99*99)
}
}
func BenchmarkSearchInt(b *testing.B) {
for i := 0; i < b.N; i++ {
SearchMyInt(slice, 99*99)
}
}
這是結果:
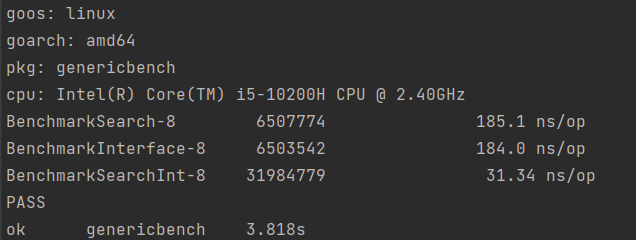
泛型程式碼和使用介面的程式碼相差無幾,比普通程式碼慢了整整六倍!
為啥?因為gcshape的實現方式導致了型別引數T並不是真正的型別,所以在呼叫上面的方法的時候得查詢一個叫type dict的東西找到當前使用的真正的型別,然後再把繫結在T上的變數轉換成那個型別。多了一次查詢+轉換,這裡的MyInt轉換後還會被複制一次,所以能不慢麼。
這也解釋了為什麼把介面傳遞給型別引數是最慢的,因為除了要查一次type dict,介面本身還得再做一次型別檢查並查詢對應的method。
所以想靠泛型大幅提升效能的人還是洗洗睡吧,只有一種情況泛型的效能不會更差:在型別引數上只使用內建的運運算元比如加減乘除,不呼叫任何方法。
但也不該因噎廢食,首先泛型struct和泛型interface受到的影響很小,其次如我所說,如果不使用型別約束上的方法,那效能損耗幾乎沒有,所以像lo、mo這樣的工具庫還是能放心用的。
這個問題1.18就有人提出來了,然而gcshape的實現在這點上太拉胯,小修小補解決不了問題,官方也沒改進的動力,所以哪怕到了1.21還是能復現同樣的問題。
不過噩夢才剛剛開始,更勁爆的還在後面呢。
如何建立物件
首先你不能這麼寫:T{},因為int之類的內建型別不支援這麼做。也不能這樣:make(T, 0),因為T不是型別預留位置,不知道具體型別是什麼,萬一是不能用make的型別編譯會報錯。
那麼對於一個型別T,想要在泛型函數裡建立一個它的範例就只能這樣了:
func F[T any]() T {
var ret T
// 如果需要指標,可以用new(T),但有注意事項,下面會說
return ret
}
So far, so good。那麼我要把T的型別約束換成一個有方法的interface呢?
type A struct {i int}
func (*A)Hello() {
fmt.Println("Hello from A!")
}
func (a *A) Set(i int) {
a.i = i
}
type B struct{i int}
func (*B)Hello(){
fmt.Println("Hello from B!")
}
func (b *B) Set(i int) {
b.i = i
}
type API interface {
Hello()
Set(int)
}
func SayHello[PT API](a PT) {
a.Hello()
var b PT
b.Hello()
b.Set(222222)
fmt.Println(a, b)
}
func main() {
a := new(A)
a.Set(111)
fmt.Println(a)
SayHello(&A{})
SayHello(&B{})
}
執行結果是啥?啥都不是,執行時會獎勵你一個大大的panic:
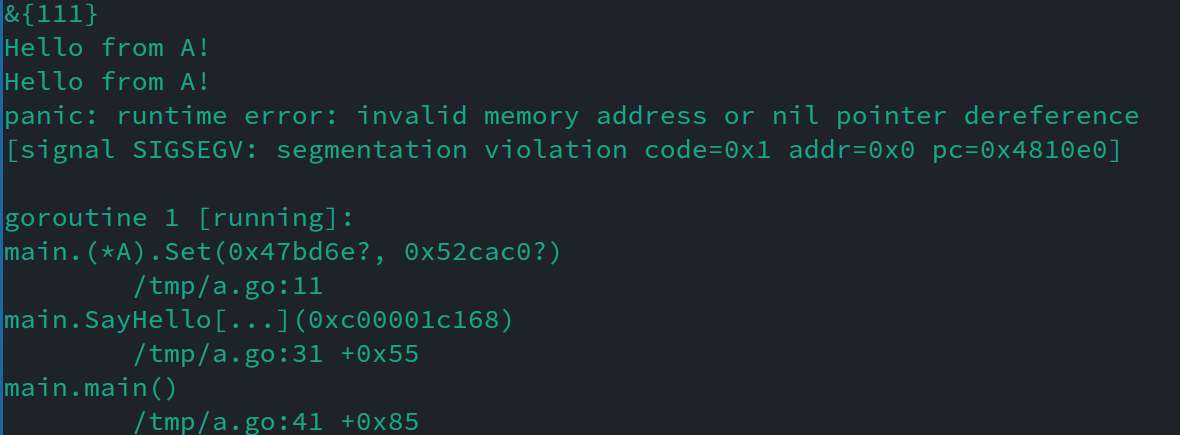
你懵了,如果T的約束是any的時候就是好的,雖然不能呼叫方法,怎麼到這調Set就空指標錯誤了呢?
這就是我要說的第二點嚴重問題了,型別引數不是你期待的那種int,MyInt那種型別,型別引數有自己獨有的型別,叫type parameter。有興趣可以去看語言規範裡的定義,沒興趣就這麼簡單粗暴的理解也夠了:這就是種會編譯期間進行檢查的interface。
理解了這點你的問題就迎刃而解了,因為它類似下面的程式碼:
var a API
a.Set(1)
a沒繫結任何東西,那麼調Set百分百空指標錯誤。同理,SayHello裡的b也沒繫結任何資料,一樣會空指標錯誤。為什麼b.Hello()調成功了,因為這個方法裡沒對接收器的指標解除參照。
同樣new(T)這個時候是建立了一個type parameter的指標,和原型別的關係就更遠了。
但對於像這樣~int、[]int的有明確的core type的約束,編譯器又是雙標的,可以正常建立範例變數。
怎麼解決?沒法解決,當然不排除是我不會用golang的泛型,如果你知道在不使用unsafe或者給T新增建立範例的新方法的前提下滿足需求的解法,歡迎告訴我。
目前為止這還不是大問題,一般不需要在泛型程式碼裡建立範例,大部分需要的情況也可以在函數外建立後傳入。而且golang本身沒有建構函式的概念,怎麼建立型別的範例並不是型別的一部分,這點上不支援還是可以理解的。
但下面這個問題就很難找到合理的藉口了。
把指標傳遞給型別引數
最佳實踐:永遠不要把指標型別作為型別引數,就像永遠不要獲取interface的指標一樣。
為啥,看看下面的例子就行:
func Set[T *int|*uint](ptr T) {
*ptr = 1
}
func main() {
i := 0
j := uint(0)
Set(&i)
Set(&j)
fmt.Println(i, j)
}
輸出是啥,是編譯錯誤:
$ go build a.go
# command-line-arguments
./a.go:6:3: invalid operation: pointers of ptr (variable of type T constrained by *int | *uint) must have identical base types
這個意思是T不是指標型別,沒法解除參照。猜都不用猜,肯定又是type parameter作怪了。
是的。T是type parameter,而type parameter不是指標,不支援解除參照操作。
不過比起前一個問題,這個是有解決辦法的,而且辦法很多,第一種,明確表明ptr是個指標:
func Set[T int|uint](ptr *T) {
*ptr = 1
}
第二種,投機取巧:
func Set[T int|uint, PT interface{*T}](ptr PT) {
*ptr = 1
}
第二種為什麼行,因為在型別約束裡如果T的約束有具體的core type(包括any),那麼在這裡就會被當成實際的型別用而不是type parameter。所以PT代表的意思是「有一個型別,它必須是T代表的實際型別的指標型別」。因為PT是指標型別了,所以第二種方法也可以達到目的。
但我永遠只推薦你用第一種方法,別給自己找麻煩。
泛型和型別的方法集
先看一段程式碼:
type A struct {i int}
func (*A)Hello() {
fmt.Println("Hello from A!")
}
type B struct{i int}
func (*B)Hello(){
fmt.Println("Hello from B!")
}
func SayHello[T ~*A|~*B](a T) {
a.Hello()
}
func main() {
SayHello(&A{})
SayHello(&B{})
}
輸出是啥?又是編譯錯誤:
$ go build a.go
# command-line-arguments
./a.go:17:4: a.Hello undefined (type T has no field or method Hello)
你猜到了,因為T是型別引數,而不是(*A),所以沒有對應的方法存在。所以你這麼改了:
func SayHello[T A|B](a *T) {
a.Hello()
}
這時候輸出又變了:
$ go build a.go
# command-line-arguments
./a.go:17:4: a.Hello undefined (type *T is pointer to type parameter, not type parameter)
這個報錯好像挺眼熟啊,這不就是取了interface的指標之後在指標上呼叫方法時報的那個錯嗎?
對,兩個錯誤都差不多,因為type parameter有自己的資料結構,而它沒有任何方法,所以通過指標指向type parameter後再呼叫方法會報一模一樣的錯。
難道我們只能建個interface裡面放上Hello這個方法了嗎?雖然我推薦你這麼做,但還有別的辦法,我們可以利用上一節的PT,但需要給它加點method:
func SayHello[T A|B, PT interface{*T; Hello()}](a PT) {
a.Hello()
}
原理是一樣的,但現在a還同時支援指標的操作。
直接用interface{Hello()}不好嗎?絕大部分時間都可以,但如果我只想限定死某些型別的話就不適用了。
如何複製一個物件
大部分情況下直接b := a即可,不過要注意這是淺拷貝。
對於指標就比較複雜了,因為type parameter的存在,我們得特殊處理:
type A struct {i int}
func (*A)Hello() {
fmt.Println("Hello from A!")
}
func (a *A) Set(i int) {
a.i = i
}
type B struct{i int/*j*/}
func (*B)Hello(){
fmt.Println("Hello from B!")
}
func (b *B) Set(i int) {
b.i = i
}
type API[T any] interface {
*T
Set(int)
}
func DoCopy[T any, PT API[T]](a PT) {
b := *a
(PT(&b)).Set(222222) // 依舊是淺拷貝
fmt.Println(a, b)
}
PT是指標型別,所以可以解除參照得到T的值,然後再賦值給b,完成了一次淺拷貝。
注意,拷貝出來的b是T型別的,得先轉成*T再轉成PT。
想深拷貝怎麼辦,那隻能定義和實現這樣的介面了:CloneAble[T any] interface{Clone() T}。這倒也沒那麼不合理,為了避免淺拷貝問題一般也需要提供一個可以複製自身的方法,算是順勢而為吧。
總結
這一年多來我遇到的令人不爽的問題就是這些,其中大部分是和指標相關的,偶爾還要外加一個效能問題。
一些最佳實踐:
- 明確使用
*T,而不是讓T代表指標型別 - 明確使用
[]T和map[T1]T2,而不是讓T代表slice或map - 少寫泛型函數,可以多用泛型struct
- 型別約束的core type直接影響被約束的型別可以執行哪些操作,要當心
如果是c++,那不會有這些問題,因為型別引數是預留位置,會被替換成真實的型別;如果是ts,java也不會有這些問題,因為它們沒有指標的概念;如果是c#,也不會有問題,至少在8.0的時候編譯器不允許構造類似T*的東西,如果你這麼寫,會有清晰明確的錯誤資訊。
而我們的golang呢?雖然不支援,但給的報錯卻是一個程式碼一個樣,對golang的型別系統和泛型實現細節沒點了解還真不知道該怎麼處理呢。
我的建議是,在golang想辦法改進這些問題之前,只用別人寫的泛型庫,只用泛型處理slice和map。其他的雜技我們就別玩了,容易摔著。