MySQL——GROUP BY詳解與優化
在 MySQL 中,GROUP BY用於將具有指定列中相同值的行分組在一起。這是在處理大量資料時非常有用的功能,允許對資料進行分類和聚合。
基本使用
語法
以下是GROUP BY子句的基本語法:
"""
SELECT col1, col2, ..., aggregate_function(col_name)
FROM table_name
WHERE condition
GROUP BY col1, col2, ...;
"""
其中,col1, col2, ...是要分組的列名,aggregate_function是用於聚合資料的函數,如SUM,
AVG, MAX, MIN等。table_name是要從中檢索資料的表的名稱,condition是可選的查詢條
件。
範例
"""
SELECT column1, column2, COUNT(*)
FROM table_name
WHERE condition
GROUP BY column1, column2
ORDER BY column1, column2;
"""
在這個範例中,選擇了column1和column2兩列,並對它們進行了分組。使用COUNT(*)函
數來計算每個組中的行數。使用ORDER BY子句按column1和column2升序排序結果集。
那怎麼查詢非分組的列名呢?
一般來講 SELECT 中的值要麼是來自於聚合函數(sum、avg、max等)的結果,要麼是來自
於 group by 後面的列。
從MySQL 5.7.5之前預設是支援的,之後的版本預設SQL模式包括ONLY_FULL_GROUP_BY,
"""
mysql> select version();
+-----------+
| version() |
+-----------+
| 8.0.18 |
+-----------+
1 row in set (0.06 sec)
mysql> select @@global.sql_mode;
+-----------------------------------------------------------------------------------------------------------------------+
| @@global.sql_mode |
+-----------------------------------------------------------------------------------------------------------------------+
| ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,
+-----------------------------------------------------------------------------------------------------------------------+
1 row in set (0.18 sec)
"""
在這種模式下執行 SQL 會報下面的錯誤
"""
mysql> select * from user group by age;
1055 - Expression #1 of SELECT list is not in GROUP BY clause
and contains nonaggregated column xxx which is not functionally
dependent on columns in GROUP BY clause;
this is incompatible with sql_mode=only_full_group_by
"""
可以通過下面兩種方式解決:
-
重新設定 sql_mode,去掉ONLY_FULL_GROUP_BY即可
-
使用 any_value() 或 group_concat()
-
any_value():將分到同一組的資料裡第一條資料的指定列值作為返回資料
-
group_concat():將分到同一組的資料預設用逗號隔開作為返回資料
"""
mysql> select age, any_value(id) from `user` GROUP BY age;
+-----+---------------+
| age | any_value(id) |
+-----+---------------+
| 3 | 0 |
| 6 | 3 |
| 7 | 5 |
| 12 | 1 |
| 14 | 2 |
| 19 | 7 |
+-----+---------------+
6 rows in set (0.15 sec)
mysql> select age, group_concat(id) from `user` GROUP BY age;
+-----+------------------+
| age | group_concat(id) |
+-----+------------------+
| 3 | 0,4 |
| 6 | 3 |
| 7 | 5 |
| 12 | 1 |
| 14 | 2 |
| 19 | 7 |
+-----+------------------+
6 rows in set (0.05 sec)
"""
不同版本的排序
我們以下面這個user表為例,看下在不同版本下有什麼區別?
"""
mysql> show create table user;
+-------+---------------------------------+
CREATE TABLE `user` (
`id` int(11) NOT NULL,
`name` varchar(255) DEFAULT NULL ,
`age` int(255) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `nameIndex` (`name`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8
+-------+---------------------------------+
mysql> select * from user;
+----+------+-----+
| id | name | age |
+----+------+-----+
| 0 | 陳 | 3 |
| 1 | 李 | 12 |
| 2 | 張 | 14 |
| 3 | 陳 | 6 |
| 4 | 李 | 3 |
| 5 | NULL | 7 |
| 7 | 張 | 19 |
+----+------+-----+
7 rows in set (0.06 sec)
"""
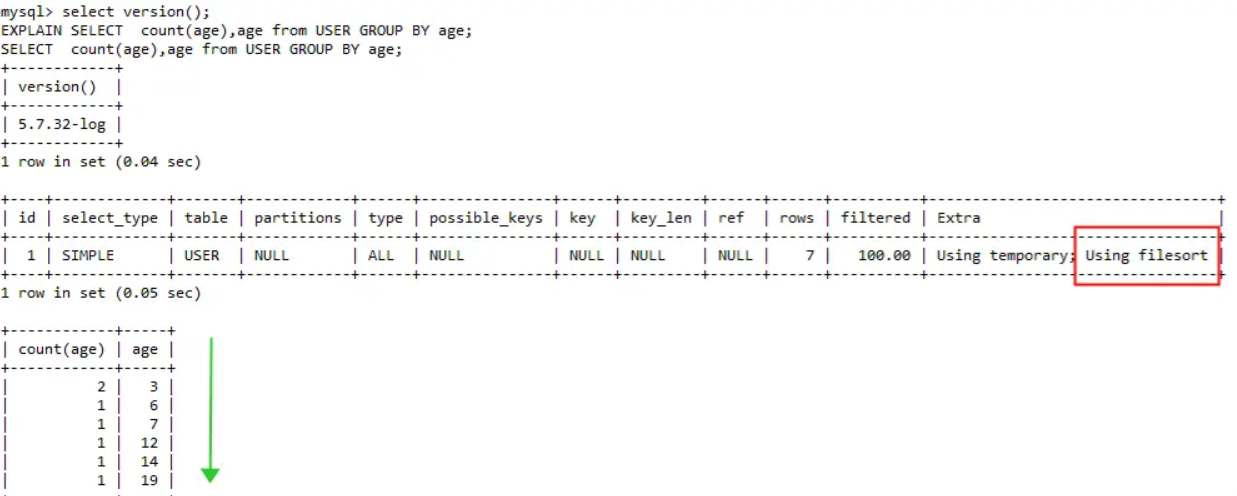
在MySQL 5.7中
在MySQL 8.0中
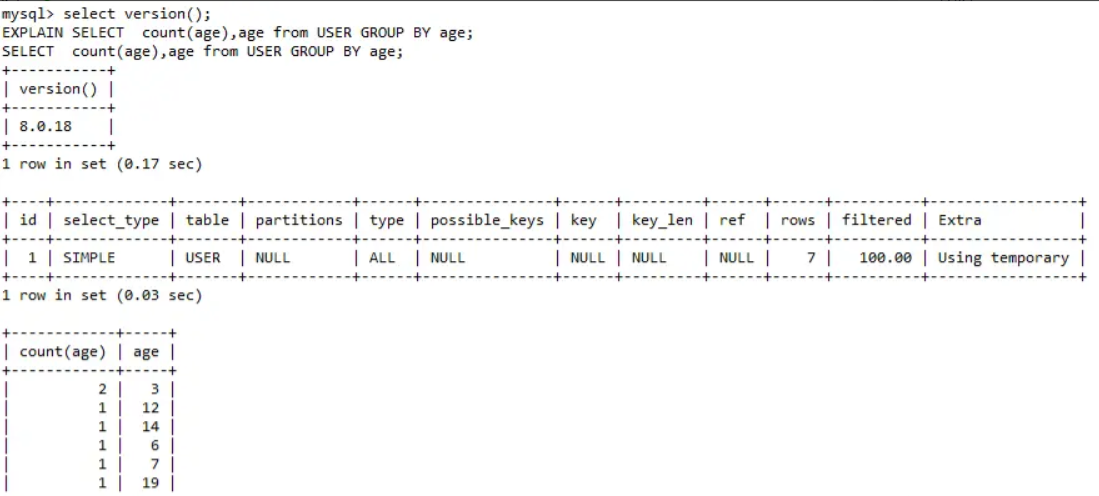
同樣的SQL在MySQL 5.7中與MySQL 8.0中執行結果是不一樣的,在MySQL 5.7中資料預設
按照分組列升序展示,在MySQL 8.0中則沒有排序,所以在MySQL 5.7中執行計劃裡面的
Extra 這個欄位的多了一個 Using filesort。
因為在MySQL 5.7中,GROUP BY 預設隱式排序,按GROUP BY列按升序排序。如果不想在
執行 GROUP BY 時執行排序的開銷,可以禁用排序:
"""
GROUP BY column_name ORDER BY NULL
"""
然而,在MySQL 8.0中,GROUP BY預設不會使用排序功能,除非使用了ORDER BY語句。
工作原理
執行流程
我們先來看下下面這條sql語句在MySQL 5.7中的執行計劃:
"""
explain select age,count(age) from user where name ='李' GROUP BY age;
"""

在Extra欄位裡面, 我們可以看到三個資訊:
- Using index condition: 表示這個語句使用了索引來過濾;
- Using temporary: 表示使用了臨時表;
- Using filesort: 表示需要排序
這個語句的執行流程是這樣的:
- 建立一個臨時表。表裡有兩個欄位 age 和 count(age)、主鍵為 age
- 掃描普通索引nameIndex ,找到 name ='李' 主鍵 ID;
- 通過主鍵ID,回表找到 age=12 欄位值
- 判斷臨時表中有沒有主鍵為 12 的行
- 沒有就插入一個記錄(12,1)
- 就將12這一行的count(age)值加1
遍歷完成後, 需要根據欄位 age 做排序
-
初始化sort_buffer, sort_buffer中有兩個欄位
-
從記憶體臨時表中一行一行地取出資料,分別存入sort_buffer中的兩個欄位裡。 這個過程要對記憶體臨時表做全表掃描。
-
在sort_buffer中根據age的值進行排序。
-
排序完成後,返回給使用者端。
記憶體臨時表排序的時候使用了rowid排序方法。
"""
"filesort_summary":{
"rows":2,
"examined_rows":2,
"number_of_tmp_files":0,
"sort_buffer_size":320,
"sort_mode":"<sort_key, rowid>"
}
"""
臨時表
記憶體臨時表
由於本例子只有幾行資料, 記憶體可以放得下,因此只使用了記憶體臨時表。 但是記憶體臨時表的
大小是有限制的, 引數 tmp_table_size 表示臨時表記憶體大小, 預設是16M。記憶體臨時表使
用的是memory引擎。
"""
mysql> show variables like '%tmp_table_size%';
+----------------+---------+
| Variable_name | Value |
+----------------+---------+
| tmp_table_size | 2097152 |
+----------------+---------+
1 row in set (0.04 sec)
"""
磁碟臨時表
如果臨時表大小超過了tmp_table_size, 那麼記憶體臨時表就會轉成磁碟臨時表。磁碟臨時表
使用的引擎預設是InnoDB, 是由引數internal_tmp_disk_storage_engine 控制
"""
mysql> show variables like '%internal_tmp_disk_storage_engine%';
+----------------------------------+--------+
| Variable_name | Value |
+----------------------------------+--------+
| internal_tmp_disk_storage_engine | InnoDB |
+----------------------------------+--------+
1 row in set (0.04 sec)
"""
為了復現生成磁碟臨時表,把 tmp_table_size設定小一點,通過查
Created_tmp_disk_tables值,檢視對應的磁碟臨時表數量
"""
mysql> set tmp_table_size=1;
select age,count(age) from user where name ='李' GROUP BY age ORDER BY age ;
show status like '%Created_tmp%';
Query OK, 0 rows affected (0.02 sec)
+-----+------------+
| age | count(age) |
+-----+------------+
| 3 | 1 |
| 12 | 1 |
+-----+------------+
2 rows in set (0.03 sec)
+-------------------------+-------+
| Variable_name | Value |
+-------------------------+-------+
| Created_tmp_disk_tables | 3 |
| Created_tmp_files | 60 |
| Created_tmp_tables | 6 |
+-------------------------+-------+
3 rows in set (0.04 sec)
"""
Created_tmp_tables:在記憶體中建立內部臨時表時或在磁碟,伺服器將遞增此值。
Created_tmp_disk_tables:在磁碟上建立內部臨時表時, 伺服器遞增此值
一般理想的設定是:
"""
Created_tmp_disk_tables / Created_tmp_tables * 100% <= 25%
"""
分組優化
不論是使用記憶體臨時表還是磁碟臨時表,group by需要構造一個帶唯一索引的表, 執行代價
都是比較高的。如果表的資料量比較大,執行起來就會很慢。
使用索引
如果可以確保輸入的資料是有序的,那麼 group by的時候, 就只需要從左到右,順序掃描,
依次累加。那就是InnoDB的索引,對索引列分組不需要臨時表,也不需要排序。

增大tmp_table_size
如果group by需要統計的資料量不大, 儘量只使用記憶體臨時表; 可以通過適當調大
tmp_table_size引數, 來避免用到磁碟臨時表。
使用SQL_BIG_RESULT
如果一個group by語句中需要放到臨時表上的資料量特別大,還是按照上面的邏輯,先放到
記憶體臨時表,插入一部分資料後,發現記憶體臨時表不夠用了再轉成磁碟臨時表,那感覺就沒必
要了,那怎麼樣可以直接使用磁碟臨時表呢?
使用SQL_BIG_RESULT, 可以與 SELECT 語句中的GROUP BY或DISTINCT關鍵字一起使用。
它的作用是告訴MySQL優化器,查詢結果集較大,直接用磁碟臨時表。MySQL會使用基於磁
盤的臨時表進行排序
例如,以下是一個使用SQL_BIG_RESULT的範例:
"""
SELECT SQL_BIG_RESULT col1, col2
FROM my_table
GROUP BY col1;
"""
需要注意的是,使用SQL_BIG_RESULT會增加伺服器的記憶體和CPU使用量,因此應該仔細評
估是否需要使用它。通常情況下,只有在處理大型資料集時才需要使用。
禁用排序
在MySQL 5.7中,如果對group by語句的結果沒有排序要求,在語句後面加 order by null,
禁用排序,減少不必要的排序開銷。
GROUP BY 和 DISTINCT 的區別
首先是使用方式不同:雖然在某些情況下 DISTINCT 和 GROUP BY 可以實現相同的結果,但
通常情況下,它們用於不同的目的,一個是去重,一個是聚合。
-
DISTINCT 關鍵字用於返回 SELECT 查詢中不同的值,即去重。它會掃描所有的行並去除重複的行。
-
GROUP BY 關鍵字用於將結果集按照指定列進行分組,並對每個分組執行聚合函數。
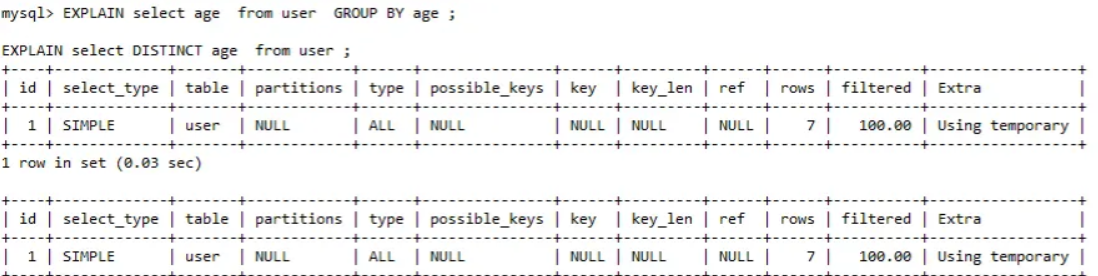
再就是在效能上:如果在不需要執行聚合函數時,DISTINCT 和GROUP BY這兩條語句的語意
和執行流程是相同的,因此執行效能也相同
使用場景
GROUP BY通常用於以下場景:
- 對資料進行分類和統計
- 按特定條件對資料進行分組
- 進行聚合操作,如計算總數、平均數、最大值、最小值等
- 生成報表或彙總資料