Llama2開源大模型的新篇章以及在阿里雲的實踐
Llama一直被譽為AI社群中最強大的開源大模型。然而,由於開源協定的限制,它一直不能被免費用於商業用途。然而,這一切在7月19日發生了改變,當Meta終於釋出了大家期待已久的免費商用版本Llama2。Llama2是一個由Meta AI開發的預訓練大語言模型,它可以接受任何自然語言文字作為輸入,並生成文字形式的輸出。Llama2-xb-chat是基於Llama2-xb在對話場景下的優化模型,目前在大多數評測指標上超過了其他開源對話模型,並且與一些熱門的閉源模型(如ChatGPT、PaLM)的表現相當。
官方介紹
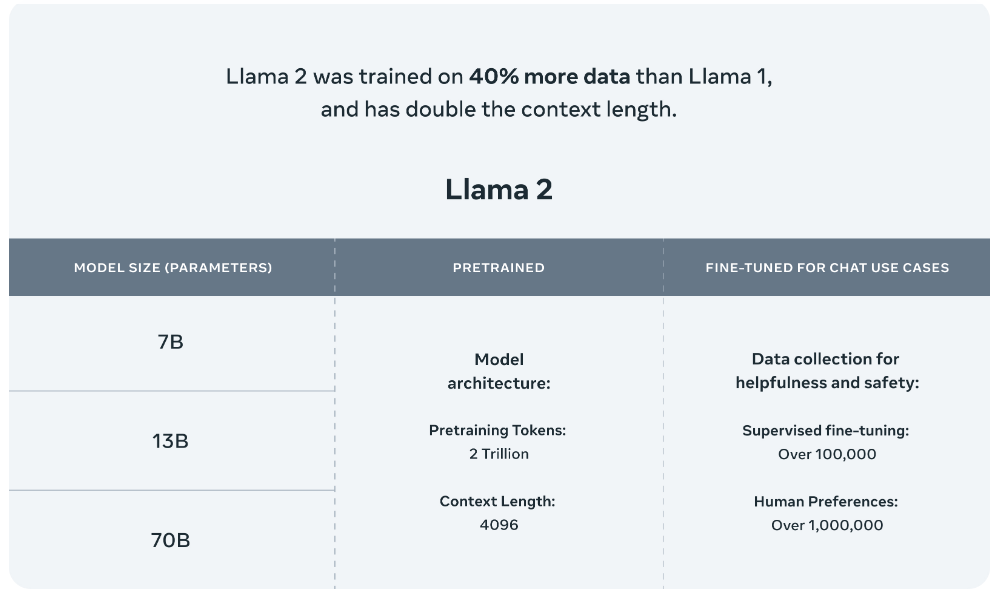
Meta釋出的Llama 2模型系列包括70億、130億和700億三種引數版本。此外,他們還訓練了一個340億引數的版本,但並未釋出,只在技術報告中提到。據官方介紹,Llama 2與其前身Llama 1相比,訓練資料增加了40%,上下文長度也翻了一番,並採用了分組查詢注意力機制。具體來說,Llama 2預訓練模型是在2萬億的token上訓練的,而精調Chat模型則是在100萬人類標記資料上訓練的。
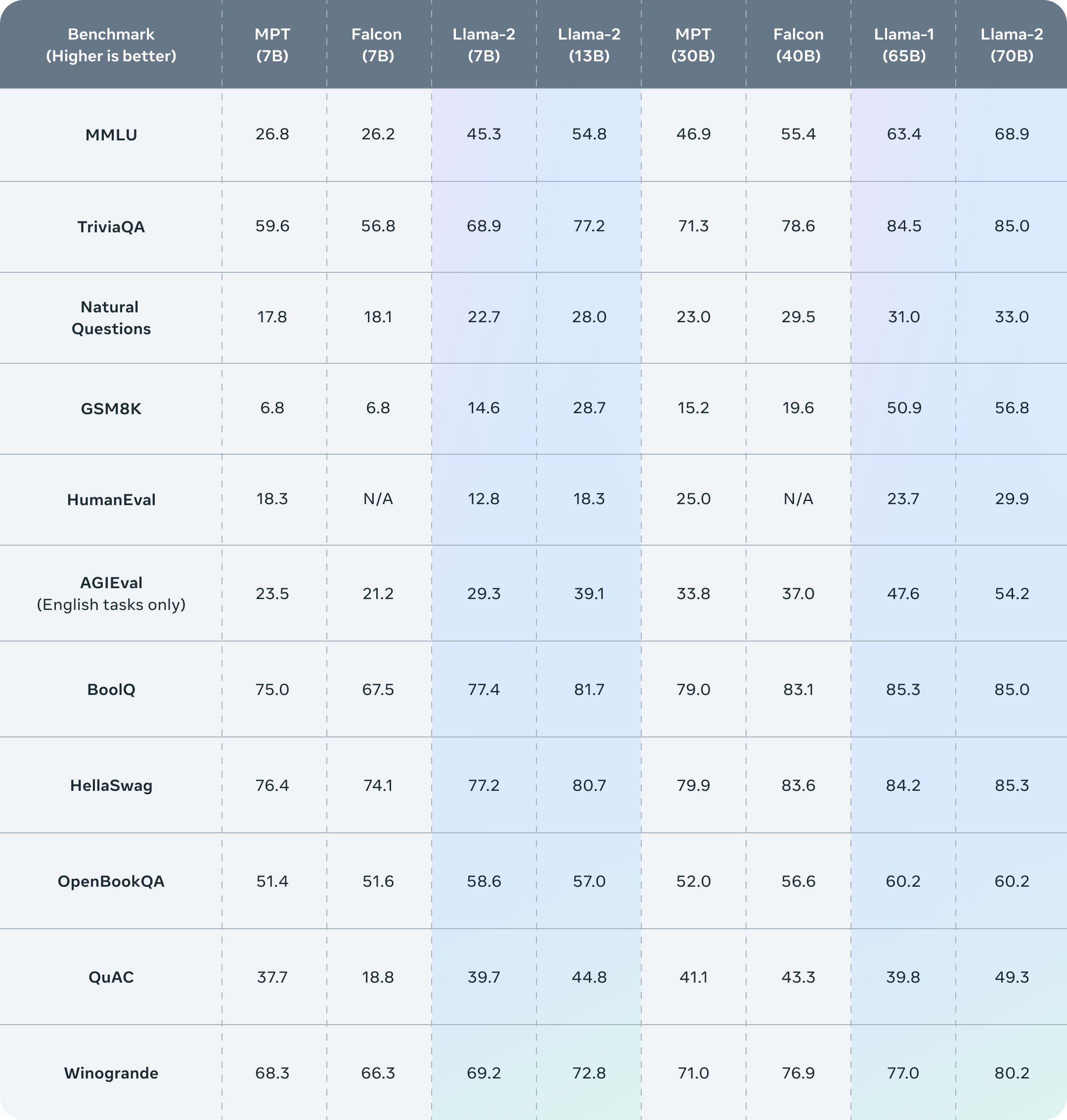
公佈的測評結果顯示,Llama 2在包括推理、編碼、精通性和知識測試等許多外部基準測試中都優於其他開源語言模型。
模型部署
Meta在Huggingface上提供了所有模型的下載連結:https://huggingface.co/meta-llama
預訓練模型
Llama2預訓練模型包含7B、13B和70B三個版本
| 模型名稱 | 模型載入名稱 | 下載地址 |
|---|---|---|
| Llama2-7B | meta-llama/Llama-2-7b-hf | 模型下載 |
| Llama2-13B | meta-llama/Llama-2-13b-hf | 模型下載 |
| Llama2-70B | meta-llama/Llama-2-70b-hf | 模型下載 |
Chat模型
Llama2-Chat模型基於預訓練模型進行了監督微調,具備更強的對話能力
| 模型名稱 | 模型載入名稱 | 下載地址 |
|---|---|---|
| Llama2-7B-Chat | meta-llama/Llama-2-7b-chat-hf | 模型下載 |
| Llama2-13B-Chat | meta-llama/Llama-2-13b-chat-hf | 模型下載 |
| Llama2-70B-Chat | meta-llama/Llama-2-70b-chat-hf | 模型下載 |
阿里雲機器學習平臺PAI
機器學習平臺PAI(Platform of Artificial Intelligence)面向企業客戶及開發者,提供輕量化、高價效比的雲原生機器學習,涵蓋PAI-DSW互動式建模、PAI-Studio拖拽式視覺化建模、PAI-DLC分散式訓練到PAI-EAS模型線上部署的全流程。
PAI平臺部署

今天PAI平臺也對Llama2-7b做了支援,提供了相關的映象可以直接部署。模型部署後,使用者可以在服務詳情頁面通過「檢視Web應用」按鈕來在網頁端直接和模型推理互動。讓我們來體驗一下吧!
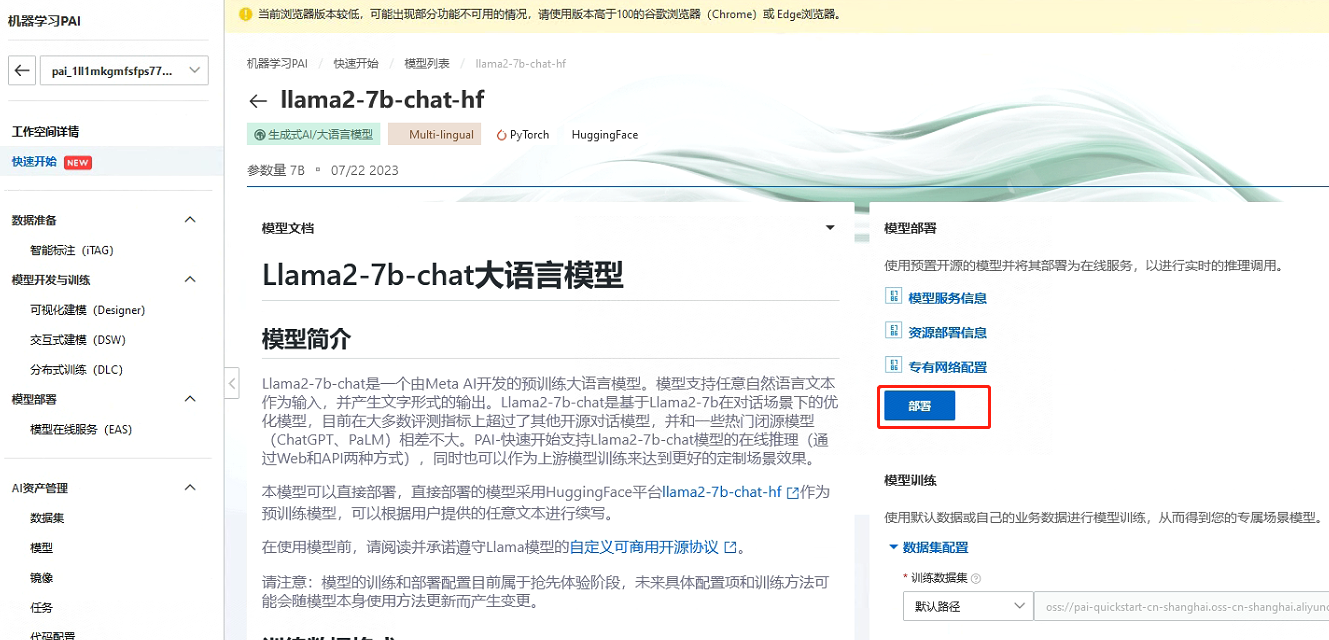
部署完成後:
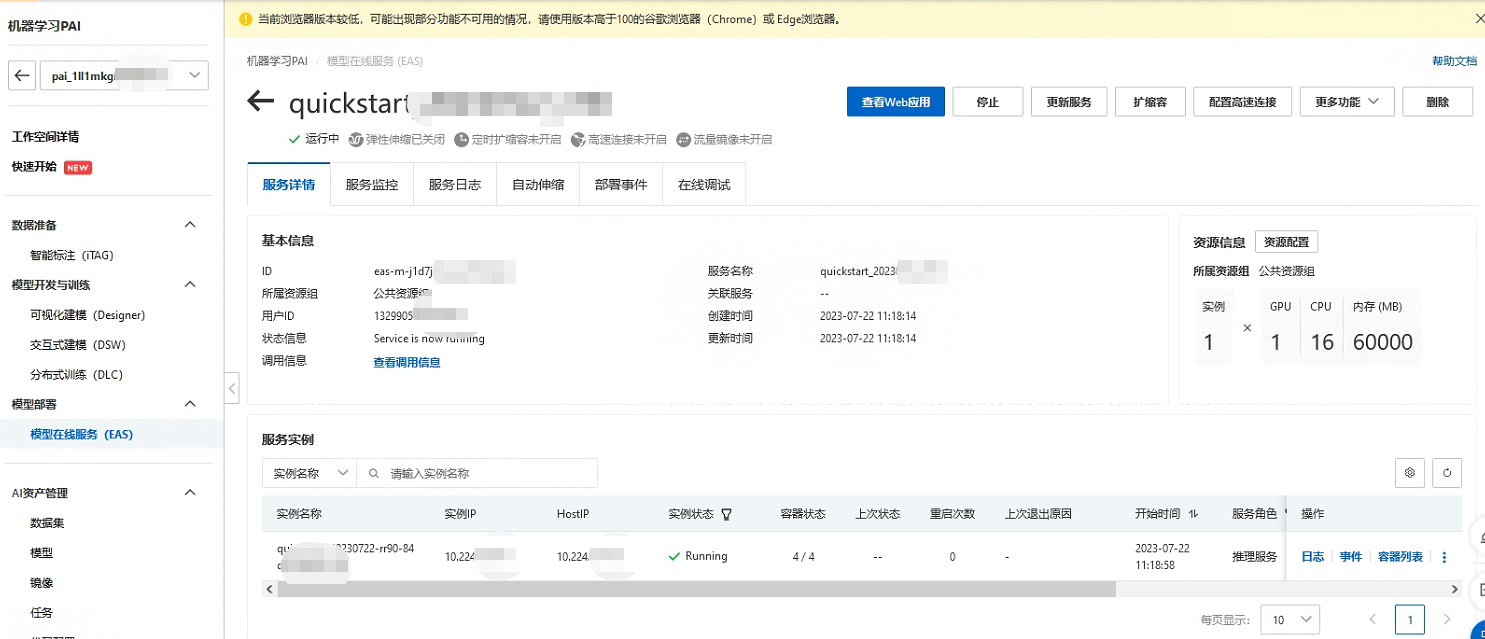
進入Web頁面來測試一下:
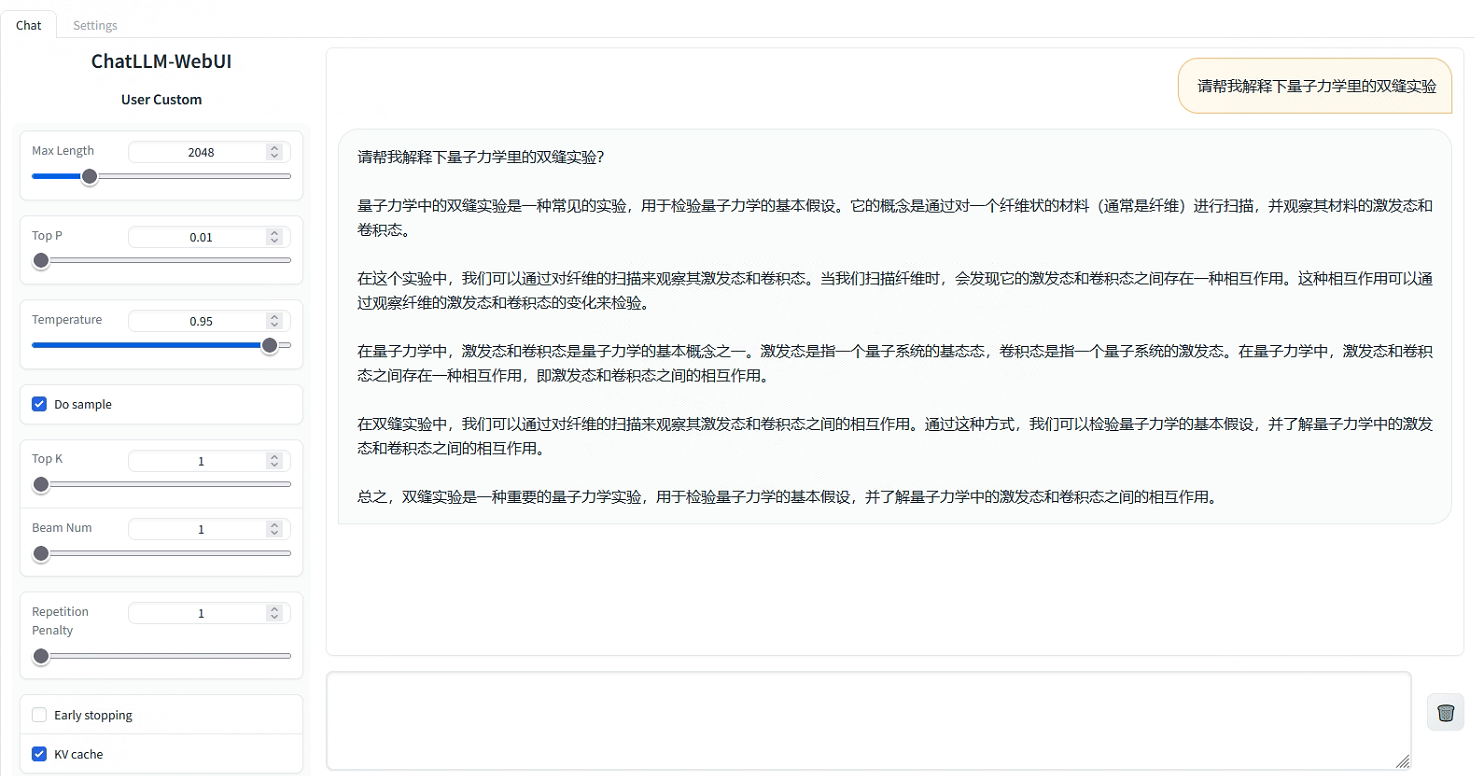
此外,也支援了通過API形式直接推理,但需要前往EAS服務並將服務執行命令更新為python api/api_server.py --port=8000 --model-path=<先前填入的model-path>。服務請求Body為輸入text/plain格式文字或application/json格式,返回資料為text/html格式。以下為傳送請求的格式範例:
{"input_ids": "List the largest islands which begin with letter 's'.","temperature": 0.8,"max_length": 5120,"top_p": 0.9}
API詳情
LLAMA2模型API呼叫需"申請體驗"並通過後才可使用,否則API呼叫將返回錯誤狀態碼。以下範例展示了呼叫LLAMA2模型對一個使用者指令進行響應的程式碼。
Python
# For prerequisites running the following sample, visit https://help.aliyun.com/document_detail/611472.html
from http import HTTPStatus
from dashscope import Generation
def simple_sample():
# 模型可以為模型列表中任一模型
response = Generation.call(model='llama2-7b-chat-v2',
prompt='Hey, are you conscious? Can you talk to me?')
if response.status_code == HTTPStatus.OK:
print('Result is: %s' % response.output)
else:
print('Failed request_id: %s, status_code: %s, code: %s, message:%s' %
(response.request_id, response.status_code, response.code,
response.message))
if __name__ == '__main__':
simple_sample()
響應範例
{"text": "Hey, are you conscious? Can you talk to me?\n[/Inst: Hey, I'm not sure if I'm conscious or not. I can't really feel anything or think very clearly. Can you tell me"}
HTTP呼叫介面
curl --location 'https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation' \
--header 'Authorization: Bearer <your-dashscope-api-key>' \
--header 'Content-Type: application/json' \
--data '{
"model": "llama2-7b-v2",
"input":{
"prompt":"Hey, are you conscious? Can you talk to me?"
}
}'
響應範例
{
"output":{
"text":"Hey, are you conscious? Can you talk to me?\nLeaders need to be conscious of what’s going on around them, and not just what’s happening within their own heads.\nThis means listening to your team."
},
"request_id":"fbd7e41a-363c-938a-81be-8ae0f9fbdb3d"
}
隨著時間的推移,基於Llama2開源模型的應用預計將在國內如雨後春筍般湧現。這種趨勢反映了從依賴外部技術向自主研發的轉變,這不僅能滿足我們特定的需求和目標,也能避免依賴外部技術的風險。因此,我們更期待看到優秀的、獨立的、自主的大模型的出現,這將推動我們的AI技術的發展和進步。
更深入的內容後續學習後再總結吧