Linux核心筆記(三)核心程式語言和環境
學習概要:
Linux核心使用的程式語言、目標檔案格式、編譯環境、內聯組合、語句表示式、暫存器變數、行內函式 c和組合函數之間的相互呼叫機制Makefile檔案的使用方法。
as86組合語言語法
組合器專門來把程式編譯成含機器碼的二進位制程式或目標檔案。組合器會把輸入的一個組合語言程式(例如srcfile)編譯成目標檔案。組合的命令列基本格式是
as[選項] -o objfile srcfile
其中objfile是as編譯輸出的目標檔名稱,srcfile.s是as的輸入組合語言程式名稱。如果沒有使用輸出檔名,那麼as會編譯輸出名稱為a.out的預設目標檔案選項用來控制編譯過程以產生指定格式和設定的目標檔案。輸入的組合語言程式srcfile是一個文字檔案。該檔案內容必須是有換行字元結尾的一系列文字行組成。雖然GNU as可使用分號在一行上包含多個語句,但通常在編制組合語言程式時每行指包含一條語句。
語句可以是隻包含空格、製表符和換行符的空行,也可以是賦值語句(或定義語句)、偽操作符語句和機器指令語句。例如BOOTSEG = 0X07C0
- 偽操作符語句都是組合器使用的指示符,它通常並不會產生任何程式碼。它有偽操作碼和0個或多個運算元組成。每個操作碼都是由一個點字元'.'開始。
點字元本身是一個特殊的符號,它表示編譯過程中的位置計數器。其值是點符號出現處機器指令第1個位元組的地址。 - 機器指令語句是可執行機器指令的助記符,它由操作碼和0個或多個運算元構成。另外任何語句之前都可以有標號。標號是由一個識別符號後跟一個冒號:組成。在編譯過程,當組合器遇到一個標號,那麼當前位置計數器的值就會賦值給這個標號。
- 一條組合語句通常由標號(可選)、指令助記符(指令名)和運算元三個欄位組成,標號位於一條指令的第一個欄位。它代表其所在位置的地址,通常指明一個跳轉指令的的目標位置。最好還可以跟隨用註釋符開始的註釋部分。
- 組合器編譯產生的目標檔案objfile通常起碼包含三個段或區
- .text:正文段(程式碼段,是一個已初始化過的段)通常其中包含程式的執行程式碼或唯讀程式碼(.bss)
- .data:資料段 :其中包含可讀/寫的資料。而未初始化資料段是一個未初始化的段。通常組合器產生的輸出目標檔案不會為該段保留空間,但在目標檔案連結成執行程式被載入時作業系統會把該段的內容全部初始化為0.
as86
.bass:未初始化資料段
as86組合語言程式
一個簡單的框架範例boot.s來說明as86組合程式的結構以及程式中語句的語法,然後給出編譯連結和執行方法,最後再分別列出as86和ld86的使用方法和編制選項。
1 !
2 !boot.s -- bootsect.s的框架程式。用程式碼0x07替換串msg1中1字元,然後在螢幕第一行上顯示。
3 !
4 .globl begtext,begdata,begbss,endtext,enddata,endbss !全域性識別符號,供ld86連結使用
5 .text !正文段:
6 begtext:
7 .data ! 資料段;
8 begdata
9 .bss !未初始化資料段
10 begbss:
11 .text !正文段
12 BOOTSEG = 0X07c0 !BIOS載入bootsect程式碼的原始段地址;
13
14 entry start !告知連結程式,程式從start標號處開始執行。
15 start:
16 jmpi go,BOOTSEG !段間跳轉。INITSET指出跳轉段地址,標號go是偏移地址。
17 go: mov ax,cs !段暫存器cs值-->ax,用於初始化資料段ds和es。
18 mov ds,ax
19 mov ex,ax
20 mov [msg1+17],ah !0x07-->替換字串中1個點符號,喇叭就會響一聲
21 mov cx,#20 !共顯示20個字元,包含回車換行符
22 mov dx,#0x1004 !共顯示在螢幕第17行、第5列處。
23 mov bx,#0x000c !字元顯示屬性(紅色)
24 mov bp,#msg1 !指向要顯示的字串(中斷呼叫請求)
25 mov ax,#0x1301 !寫字串並移動遊標到串結尾處。
26 int 0x10 !BIOS中斷呼叫0x10,功能0x13,子功能01.
27 loop1: jmp loop1 !死迴圈
28msg1:.ascii "Loading System..."!呼叫BIOS中斷顯示的資訊。共20個ASCII碼字元
29 .byte 13,10
30 .org 510 !表示以後語句從地址510(0x1FE)開始存放。
31 .word 0XAA55 !有效引導磁區標誌,供BIOS載入引導磁區使用
32 .text
33 endtext
34 .data
35 enddata
36 .bss
37 endbss:
該程式是一個簡單的引導磁區啟動程式。編譯連結產生的執行程式可以放入軟碟第1個磁區直接用來引導計算機啟動。啟動後會在螢幕第17行、第五列處顯示出紅色字串"Loading system ..",並且遊標下移一行。然後程式就在27行上死迴圈。
第4行上的'.globl'是組合指示符(或稱組合偽指令、偽操作符)。組合指示符均以一個字元'.'開始,並且不會在編譯時產生任何程式碼。組合指示符由一個偽操作碼,後跟0個或多個運算元組成。第4行上的'glogl'是一個偽操作碼,而其後面的標號'begtext,begdata,begbss'等標號就是它的運算元。標號是後面帶冒號的標誌符,例如第6行上的'begtext:'。但是在參照一標號時無須帶冒號。
第12行定義了一個賦值語句"BOOTSEG = 0x7c0"。等號'='(或符號'EQYU')用於定義識別符號BOOTSEG所代表的值,因此這個識別符號可稱為符號常數。這個值與C語言中的寫法一樣,可以使用十進位制、八進位制、十六進位制。
第14行上的識別符號'entry'是保留關鍵字,用於迫使連結器ld86
在生成的可執行檔案中包括進其後指定的標號'start'。通常在連結多個目標檔案生成一個可執行檔案時應該在其中一個組合程式中用關鍵詞指定一個入口標號,以便於偵錯。
第16行上是一個段間(Inter-segment)遠跳轉語句,就跳轉到下一條指令。由於當BIOS把程式載入到實體記憶體0x7c00處並跳轉到該處時,所有段暫存器(包括CS)預設值均為0,即此時CS:IP = 0X0000:0X7c00。因此這裡使用段間跳轉語句就是為了給CS賦段值0x7c0。該語句執行後CS:IP=0X07C0:0X0005。隨後的兩條語句分別給DS和ES段暫存器賦值,讓它們都指向0x7c0。這樣便於對程式中的資料(字串)進行定址。
第20行上的MOV指令用於把ah暫存器中0x7c0段值的高位元組(0x07)存放到記憶體中字串msg1最後一個'.'位置處。這個字元將導致BIOS中斷在顯示字串時鳴叫一聲。
! 直接暫存器定址。跳轉到bx值指定的地址處,即把bx的值拷貝到IP中。
mov bx,ax
jmp bx
! 間接暫存器定址。bx值指定記憶體位置處的內容作為跳轉的地址。
mov [bx],ax
jmp [bx]
! 把立即數1234放到ax中,把msg1地址值放到ax中。
mov ax,#1234
mov ax,#msg1
! 絕對定址。把記憶體地址1234(msg1)處的內容放入ax中。
mov ax,1234
mov ax,msg1
mov ax,[msg1]
! 索引地址。把第二個運算元所指記憶體位置處的值放入ax中。
mov ax,msg1[bx]
mov ax, msg1[bx*4+si]
第21--25行的語句分別用於把立即數放到相對應的暫存器中。**把立即數前一定要加'#',否則將作為記憶體地址使用而使語句變成絕對定址語句,**,例如,把一個標號(例如msg1)的地址值放入暫存器中時也一定要在前面加'#',否則會變成把msg1地址處的內容放到暫存器中!
第26行是BIOS螢幕顯示中斷呼叫int0x10。這裡其功能19、子功能。1.該中斷的作用是把一字串(msg1)寫到螢幕指定位置處。暫存器cx中是字串長度值,dx中是顯示位置值,bx中是顯示使用的字元屬性,es:bp指向字串。
第27行是一個跳轉語句,跳轉到當前指令處。因此這是一個死迴圈語句。這裡採用死迴圈語句是為了讓顯示的內容能夠停留在螢幕上而不被刪除。死迴圈語句是偵錯組合程式時常用的方法。
第28--29行定義了字串msg1。定義字串需要使用偽操作符'.ascii',並且需要使用雙引號括住字串。偽操作符'.asciiz'還會自動在字串後新增一個NULL(0)字元。另外,第29行上定義了回車和換行(13,10)兩個字元。定義字元需要使用偽操作符'.byte',並且需要使用單引號把字元括住。
3.1.3as組合語言程式的編譯和連結
[/root]# as86 -0 -a -o boot.o boot.s //編譯。生成與as部分相容的目標檔案。
[/root]# ld86 -0 -s -o boot boot.o //連結。去掉符號資訊。
[/root]# ls -l boot*
-rwx--x--x 1 root root
-rw------- 1 root root
-rw------- 1 root root
[/root]# dd bs=32 if=boot of=/dev/fd0 skip =1//寫入磁碟或ImagE槽檔案中。
16+0 records in
16+0 records out
其中第1條命令利用as86組合器對boot.s程式進行編譯,生成boot.o目標檔案。第二條命令使用連結器ld86對目標檔案執行連結操作,最後生成MINIX結構的可執行檔案boot。其中選項'-0'用於生成8086的16位元目標程式;'-a'用於指定生成與GNU as 和ld 部分相容的程式碼。'-s'選項用於告訴連結器要去除最後生成的可執行檔案中的符號資訊。'-o'指定生成的可執行檔名稱。
3.1.4as86和ld使用方法和選項
as86和ld86的使用方法和選項如下:
as的使用方法和選項:
as [-03agjuw] [-b [bin]] [-lm [list] [-n name] [-o objfile] [-s sym]] srcfile
預設設定(除了以下預設值以外,其他選項預設為關閉或無;若沒有明確說明a標誌,則不會有輸出):
-3 使用80386的32位元輸出;
list 在標準輸出上顯示;
name 原始檔的基本名稱(即不包括'.'後的擴充套件名);
各選項含義
-0 使用16位元程式碼段;
-3 使用32位元程式碼段;
-a 開啟與GNU as、ld的部分相容性選項;
-b 產生二進位制檔案,後面可以分檔名;
-g 在目標檔案中僅存入全域性符號;
-j 使用所有跳轉語句均為長跳轉;
-l 產生列表檔案,後面可以跟隨列表檔名;
-m 在列表中擴充套件宏定義;
-n 後面跟隨模組名稱(取代原始檔名稱放入目標檔案中);
-o 產生目標檔案,後跟目標檔名(objfile);
-s 產生符號檔案,後跟符號檔名;
-u 將未定義符號作為輸入的未指定段的符號;
-w 不顯示警告資訊;
ld聯結器的使用語法和選項:
對於生成Minix a.out格式的版本:
ld [-03Mims[-]] [-T textaddr] [-llib_extension] [-o outfile] infile...
對於生成GNU-Minix的a.out格式的版本:
ld [-03Mimrs[-]] [-T textaddr] [-llib_extension] [-o outfile] infile...
預設設定(除了以下預設值以外,其他選項預設為關閉或無):
-03 32位元輸出;
outfile a.out格式輸出;
-0 產生具有16位元魔數的頭結構,並且對-lx選項使用i86子目錄;
-3 產生具有32位元魔數的頭結構,並且對-lx選項使用i386子目錄;
-M 在標準輸出裝置上顯示已連結的符號;
-T 後面跟隨正文基地址(使用合適於strtoul的格式);
-i 分離的指令與資料段(I&D)輸出;
-lx 將庫/local/lib/subdir/libx.a加入連結的檔案列表中;
-m 在標準輸出裝置上顯示已連結的模組;
-o 指定輸出檔名,後跟輸出檔名;
-r 產生適合於進一步重定位的輸出;
-s 在目標檔案中刪除所有符號。
3.2 GNU as組合
as組合器僅用於編譯核心中的boot/bootsect.s引導磁區程式和真真實模式下的設定程式boot/setup.s。核心中其餘所有組合語言程式(包括C語言產生的組合程式)均使用gas來編譯,並與C語言程式編譯產生的模組連結。
在編譯C語言程式時,GNU gcc編譯器會首先輸出一個作為中間結果的as組合語言檔案,然後gcc會呼叫as組合器把這個臨時組合語言程式編譯成目標檔案。即實際上as組合器最初是專門用於組合gcc產生的中間組合語言程式的,而非作為一個獨立的組合器使用。
3.2.1編譯as組合語言程式
使用as組合器編譯一個as組合語言程式的基本命令列格式如下所示:
as [選項] [-o objfile] [srcfile.s...]
其中objfile是as編譯輸出的目標檔名,srcfile.s是as的輸入組合語言程式名。如果沒有使用輸出檔名,那麼as會編譯輸出名稱為a.out的預設目標檔案。在as程式名之後,命令列上可包含編譯選項和檔名。所有選項可隨意放置,但是檔名的放置次序編譯結果密切相關。
一個程式的源程式可以被放置在一個或多個檔案中,程式的原始碼是如何分割放置在幾個檔案中並不會改變程式的語意。程式的原始碼是所有這些檔案按次序的組合結果。每次執行as編譯器,它只編譯一個源程式。
3.2.2as組合語法
as組合器使用AT&T系統V的組合語法與Intel的區別:
-
AT&T語法中立即運算元前面要加一個字元'$';暫存器運算元前要加字元百分號'%';絕對跳轉/呼叫(相對於程式計算器有關的跳轉/呼叫)運算元前面要加'*'號。而Intel組合語法均沒有這些限制。
-
AT&T語法與Intel語法使用的源和目的運算元次序正好相反。AT&T的源和目的運算元是從左到右 '源,目的'。例如Intel的語句'add eax,4'對應AT&T的'addl $4,%eax'。
-
AT&T語法中記憶體運算元的長度(寬度)由操作碼最後一個字元來確定。操作碼字尾'b'、'w'、和'l'分別指示記憶體參照寬度為8位元位元組(byte)、16位元字(word)、32位元長字(long)。Intel語法則通過在記憶體運算元前使用字首'byte ptr'、'word ptr'和'dword ptr'來達到同樣目的。因此,Intel的語句'mov al,byte ptr foo'對應於AT&T的語句'movb $foo,%al'。
-
AT&T語法中立即形式的遠跳轉和遠呼叫為'ljmp/lcall $section,$offset',而Intel的是'jmp/call far section:offset'。同樣,AT&T語法中遠返指令’lret $stack-adjust'對應Intel的'ret far stack-adjust'
*AT&T組合器不提供多程式碼段程式的支援,UNIX類作業系統要求所有程式碼在一個段中。
3.2.2.1組合程式處理
as組合器具有對組合語言程式內建的簡單預處理功能。該預處理功能會調整並刪除多餘的空格字元和製表符;刪除所有註釋語句並且使用單個空格或一些換行符替換它們;把字元常數轉換成對應的數值。但是預處理功能不會對宏定義進行處理,也沒有處理包含檔案的功能。如果需要這方面的功能,那麼可以讓組合語言程式使用大寫的字尾'.S'讓as使用gcc的CPP預處理功能。
由於as組合語言程式除了使用C語言註釋語句(即'/'和'/')以外,還使用'#'作為單行註釋開始字元,因此若在組合之前不對程式執行預處理,那麼程式中包含的所有以'#'開始的指示符或命令均被當作註釋部分。
3.2.2.2符號、語句和常數
符號(Symbol)是由字元組成的識別符號,組成符號的有效字元取決於大小寫字元集、數位和三個字元'_.$'。符號不允許數位字元開始,並且大小寫含義不同。在as組合程式中符號長度沒有限制,並且符號中所有字元都是有效的。符號使用其他字元(';')作為結束。檔案最後語句必須以換行符作為結束處。
語句(Statement)以換行符或者行分割符(";")作為結束。檔案最後語句必須以換行符作為結束。若在一行的最後使用反斜槓字元''(在換行符前),那麼就可以讓一條語句使用多行。當as讀取到反斜槓加換行符時,就會忽略掉這兩個字元。
語句由零個或多個標號(Label)開始,後面可以跟隨一個確定語句型別的關鍵符號。標號由符號後面跟隨一個冒號(":")構成。關鍵符號確定了語句餘下部分的語意。如果該關鍵符號以一個'.'開始,那麼當前語句就是一個組合命令(或稱為偽指令、指示符)。如果關鍵符號以一個字母開始,那麼當前語句就是一條組合語言指令語句。因此一條語句的通用格式為:
標號: 組合指令 註釋部分 (可選)
或
標號: 指令助記符 運算元1,運算元2 註釋部分(可選)
常數是一個數位,可分為字元常數和數位常數兩類。字元常數還可分為字串和單個字元;而數位常數可分為整數、大數和浮點數。
字串必須用雙引號括住,並且其中可以使用反斜槓''來跳脫包含特殊字元。例如'\'表示一個反斜槓字元。其中第一個反斜槓是跳脫指示符,說明把第2個字元看作一個普通反斜槓字元。常用跳脫字元序列,反斜槓若是其他字元,那麼該反斜槓將不起作用並且as組合器將會發出警告資訊。
組合程式中使用單個字元常數時可以寫成在該字元前面加一個單引號,例如"'A"表示值65、"'C"表示值67.表3-1中的跳脫碼也同樣可以用於單個字元常數。例如"'\"表示是一個普通反斜槓字元常數。
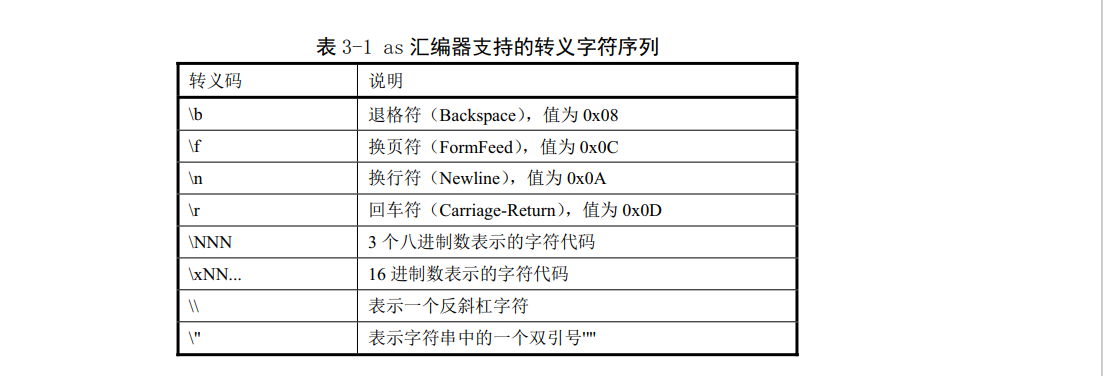
整數數位常數有4中表示方法,即使用'0b'或者'0B'開始的二進位制數('0-1'):以'0'開始的八進位制數('0-7');以非‘0’數位開始的十進位制數('0-9')和使用‘0x’或‘0X’開頭的十六進位制數('0-9a-fa-F')。若要表示負數,只需要前面新增‘-’。
大數(Bignum)是位數超過32位元二進位制位的數,其表示方法與整數的相同。組合程式中對浮點常數的表示方法與C語言中的基本一樣。由於核心程式碼中幾乎不用浮點數。
3.2.3指令語句、運算元和定址
指令(Instructions)是CPU執行的操作,通常指令也稱作操作碼(Opcode);運算元(Operand)是指令操作的物件;
而地址(Address)是指定資料在記憶體中的位置。指令語句是程式執行時刻執行的一條語句,它通常包含4個組成部分
-
標號(可選)
-
操作碼(指令助記符)
-
註釋
一條指令語句可以含有0個或最多3個用逗號分開的運算元。對於具有兩個運算元的指令語句,第1個是源運算元,第2個是目的運算元,即指令操作結果儲存在第2個運算元中。
運算元可以是立即數(即值是常數值的表示式)、暫存器(值在CPU的暫存器中)或(值在記憶體中)。一個間接運算元(Indirect operand)含有實際運算元值得地址值。AT&T語法通過在運算元前加一個'*'字元來指定一個間接運算元。只有跳轉/呼叫指令才能使用間接運算元。見下面對跳轉指令的說明。 -
立即運算元前需要加一個'$'字元字首
-
暫存器名前需要加一個'%'字元字首
-
記憶體運算元有變數名或者含有變數地址的一個暫存器指定。變數名隱含指出了變數的地址,並指示CPU參照該地址處記憶體的內容。
3.2.3.1指令操作碼的命名
AT&T語法中指令操作碼名稱(即指令助記符)最後一個字元用來指明運算元的寬度。字元‘b’、‘w’和‘l’分別指定byte、word和long型別的運算元。如果指令名稱沒有帶這樣的字元字尾,並且指令語句中不含記憶體運算元,那麼as就會根據目的暫存器運算元嘗試確定運算元寬度。例如指令語句'mov %ax,%bx'等同於'movw %ax,%bx'。同時,語句'mov $1,%bx'等同於'movw $1,%bx'。
AT&T與Intel語法中幾乎所有指令操作碼的名稱都相同,但仍有幾個例外。符號擴充套件和零擴充套件指令都需要2個寬度來指令,即需要為源和目的運算元指明寬度。AT&T語法中是通過使用兩個操作碼字尾來做到。AT&T語法中符號擴充套件和零擴充套件的基本操作碼名稱分別是'movs...'和movz...,Intel中分別是'movsx'和'movzx'。兩個字尾就附在操作碼基本名上。例如"使用符號擴充套件從%al到%edx"的AT&T語句是'movsbl %al,%edx',即從byte到long是bl、從byte到word是bw、從word到long是wl。AT&T語法與Intel語法中轉換指令的對應關係見表3-2所示

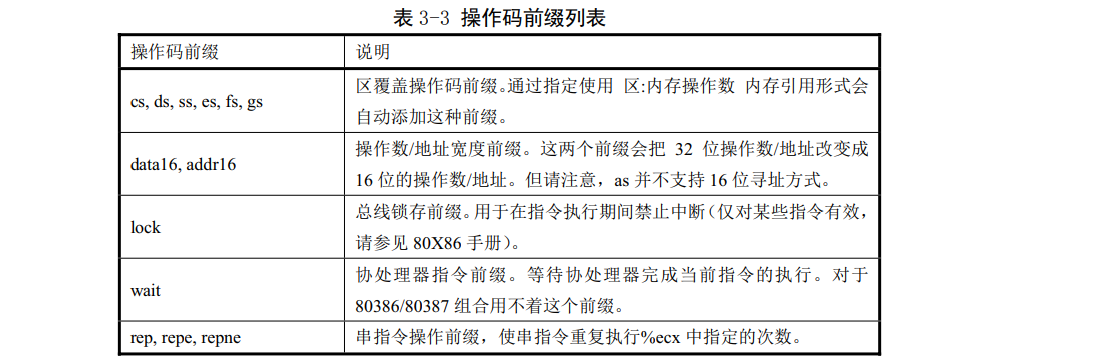
3.2.3.2指令操作碼字首
操作碼字首用於修飾隨後的操作碼。它們用於重複字串指令、提供區覆蓋、執行匯流排鎖定操作、或指定運算元和地址寬度。通常操作碼字首可作為一條沒有運算元的指令獨佔一行並且必須直接位於所影響指令之前,但是最好與它修飾的指令放在同一行上。例如,串掃描指令'scas'使用字首執行重複操作:
repne scas %es:(%edi),%al
操作碼字首有表3-3中列出的一些。
3.2.3.3記憶體參照
Intel語法的間接記憶體參照形式:
section:[base+index*scale+disp]
對應於如下AT&T語法形式:
section:disp(base,index,scale)
其中base和index是可選的32位元基暫存器和索引暫存器,disp是可選的偏移值。scale是比例因子,取值範圍是1、2、4、8。(分別是2的0次方,2的1次方,2的2次方、2的3次方)。scale其乘上索引index用來計算運算元地址。如果沒有指定scale,則scale取預設值1。section為記憶體運算元指定可選的段暫存器,並且會覆蓋運算元使用的當前預設段暫存器。請注意,如果指定的段覆蓋暫存器與預設操作的段暫存器相同,則as就不會為組合的指令再輸出相同的段字首。以下是幾個AT&T和Intel語法形式的記憶體參照例子:
movl var,%eax #把記憶體地址var處的內容放入暫存器%eax中。
movl %cs:var,%eax #把程式碼段中記憶體地址var處的內容放入%eax中。
movb $0x0a,%es:(%ebx)#把位元組值0x0a儲存到es段的%ebx指定的偏移處。
movl %var,%eax #把var的地址放入%eax中。
movl array(%esi),%eax #把array+%esi確定的記憶體地址處的內容放入%eax中。
movl (%ebx,%esi,4),%eax #把%ebx+%esi*4確定的記憶體地址處的內容放入%eax中
movl array(%ebx,%esi,4),%eax #把array+%ebx+%esi*4確定的記憶體地址處的內容放入%eax中。
movl -4(%ebp),%eax #把%ebp-4記憶體地址處的內容放入%eax中,使用預設段%ss
movl foo(,%eax,4),%eax #把記憶體地址foo+eax*4處內容放入%eax中,使用預設段%ds。
3.2.3.4跳轉指令
跳轉指令用於把執行點轉移到程式另一個位置繼續執行下去。這些跳轉的目的位置通常使用一個標號來表示。在生成目的碼檔案時,組合器會確定所有帶標號的指令的地址,並且把跳轉到的指令的地址編碼到跳轉指令中。跳轉指令可以分為無條件跳轉和條件跳轉兩大類。跳轉指令將依賴於執行指令時標誌暫存器中某個相關標誌的狀態來確定是否進行跳轉,而無條件跳轉則不依賴於這些標誌。
JMP是無跳轉指令,並可分為直接(direct)跳轉和間接(indirect)跳轉兩類,而條件跳轉指令只有直接跳轉的形式。對於直接跳轉指令,跳轉到的目標指令的地址作為跳轉指令的一部分直接編碼進跳轉指令中;對於間接跳轉指令,跳轉的目的位置取自於某個暫存器或某個記憶體位置中。直接跳轉語句的寫法是給出跳轉目標處的標號;間接跳轉語句的寫法是必須使用一個星字元'*'作為操作指示符的字首字元,並且該操作指示符使用movl指令相同的語法。下面是直接和間接跳轉的幾個例子
jmp NewLoc #直接跳轉。無條件直接跳轉到標號NewLoc處執行。
jmp *%eax #間接跳轉。暫存器%eax的值是跳轉的目標位置。
jmp *(%eax) #間接跳轉。從%eax指明的地址處讀取跳轉的目標位置。
同樣,與指令計數器PC無關的間接呼叫的運算元也必須有一個''作為字首字元。若沒有使用''字元,那麼as組合器就會選擇與指令計數PC的相關的跳轉標號。還有,其他任何具有記憶體運算元的指令都必須使用操作碼字尾('b','w'或'l')指明運算元的大小(byte、word或long)。
3.2.4區與重定位
區(Section)(也稱為段、節或部分)用於表示一個地址範圍,作業系統將會以相同的方式對待和處理在該地址範圍中的資料資訊。例如,可以有一個"唯讀"的區,我們只能從該區中讀取資料而不能寫入。區的概念主要用來表示編譯生成的目標檔案(或可執行程式)中的不同的資訊區域,例如目標檔案中的正文區或資料區。若要正確理解和編制一個as組合語言程式,我們就需要了解as產生的輸出目標檔案的格式安排。
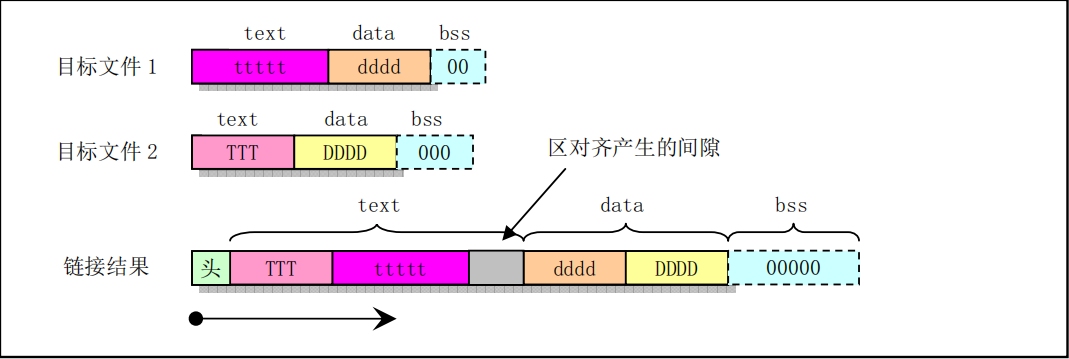
連結器ld會把輸入的目標檔案的內容按照一定規律組合成一個可執行程式。當as組合器輸出一個目標檔案時,該目標檔案中的程式碼被預設設定成從0開始。此後ld將會在連結過程中為不同目標檔案中的各個部分分配不同的最終地址位置。ld會把程式中的位元組塊移動到程式執行時的地址處。這些塊時作為固定單元進行移動的。它們的長度以及位元組次序都不會被改變。這樣的固定單元就被稱作是區(或段、部分)。而為區分配執行時刻的地址的操作就被稱為重定位(Reclocation)操作,其中包括調整目標檔案中記錄的地址,從而讓它們對應到恰當的執行時刻地址上。
as組合器輸出產生的目標檔案中至少具有3個區,分別被稱為正文(text)、資料(data)和bss區。每個區都可能是空的。如果沒有使用組合指令把輸出放置在'.text'或'.data'區中,這些區會仍然存在,但內容是空的。在一個目標檔案中,其text區從地址0開始,隨後就是data區,再後面是bss區。
當一個區被重定位時,為了讓連結器ld知道哪些資料會發生變化以及如何修改這些資料,as組合器也會往目標檔案中寫入所需要的重定位資訊。為了執行重定位元運算,在每次涉及目標檔案中的一個地址時,ld必須知道:
* 目標檔案中對一個地址的參照是從什麼地方算起的?
* 該參照的位元組長度是多少?
* 該地址參照的是哪個區?(地址)-(區的開始地址)的值等於多少?
* 對地址的參照與程式計數器PC(Program-Counter)相關嗎?
實際上,as使用的所有地址都可表示為:(區)+(區中偏移)。另外,as計算的大多數表示式都有這種與區相關的特性,在下面說明中,我們使用記號"{secname N}"來表示區secname中偏移N。
除了text、data和bss區,我們還需要了解絕對地址區(absolute區)。當連結器把各個目標檔案組合在一起,absolute區中的地址將始終不變。例如,ld會把地址{absolute 0} "重定位"到執行時刻地0處。儘管連結器在連結後絕不會把兩個目標檔案中的data區安排成重疊地址處,但是目標檔案中的absolute區必會重疊而覆蓋。
另外還有一種名為"未定義的區(Undefined section)"在組合時不能確定所在區的任何地址都被設定成{undefined U},其中U將會在以後填上。因為數值總是有定義的,所以出現未定義地址的唯一途徑僅涉及未定義的符號。對一個稱為公共塊(common block)的參照就是這樣一種符號:在組合時它的值未知,因此它在undefined區中。
類似地,區名也用於描述已連結程式中區的組。連結器ld會把程式所有目標檔案中的text區放在相鄰的地址處。我們習慣上所說的程式的text區實際上是指其所有目標檔案text區組合構成的整個地址區域。對程式中data和bss區的理解也同樣如此。
3.2.4.1連結器涉及的區
連結器ld只涉及如下4類區
- text區、data區 -- 這兩個區用於儲存程式。as和ld會分別獨立而同等地對待它們。對其中text區的描述也同樣適合data區。然而當程式在執行時,則通常text區是不會改變的。text區通常會被程序共用,其中含有指令程式碼和常數等內容。程式執行時data區的內容通常是會變化的。例如,C變數一般就存放在data區中。
- bss區 --在程式開始執行時這個區中含有0值位元組。該區用於存放未初始化的變數或作為公共變數儲存空間。雖然程式每個目標檔案bss區的長度資訊很重要,但是由於該區中存放的是0值位元組,因此無須再目標檔案中儲存bss區。設定bss區的目的就是為了從目標檔案中明確地排除0值位元組。
- absolute區 --該區的低地址0總是"重定位"到執行時刻地址0處。如果你不想讓ld在重定位元運算時改變你所參照的地址,那麼就使用這個區。從這種觀點來看,我們可以把絕對地址稱作是"不可重定位的:"在重定位元運算期間它們不會改變。
- undefined區 --對不在先前所述各個區物件的地址參照都屬於本區。
3.2.4.2子區
組合取得的位元組資料通常位於text或data區中。有時候在組合源程式某個區中可能分佈著一些不相鄰的資料組,但是你可以會想讓它們在組合後聚集在一起存放。as組合器允許你利用子區(subsection)來到達這個目的。在每個區中,可以有編號為0--8192的子區存在。編制在同一個子區中的物件會在目標檔案中與該子區中其他物件放在一起。在這種情況下,編譯器就可以在每個會輸出的程式碼區之前用'.text 0 '子區,並且在魅族會輸出的常數之前使用'.text 1 子區'。
使用子區是可選的。如果沒有使用子區,那麼所有物件都會放在子區0中。子區會以其從小到大的編號順序出現在目標檔案中,但是目標檔案中並不包含表示子區的任何資訊。處理目標檔案的ld以及其他程式並不會看到子區的蹤跡,它們只會看到由所有text子區組成的text區;由所有data子區組成的data區。為了指定隨後的的語句被組合到哪個子區中,可在'.text'表示式或'.data表示式'中使用數值引數。表示式結果應該是絕對值。如果只指定了'.text',那麼就會預設使用'.text0'。同樣地,'.data'表示使用'.data 0'。每個區都有一個位置計數器(Location Counter),它會對每個組合進該區的位元組進行計數。由於子區僅供as組合器使用方便而設定的,因此並不存在子區計數器。雖然沒有什麼直接操作一個位置計數器的方法,但是組合命令'.align'可以改變其值,並且任何標號定義都會取用位置計數器的當前值。正在執行語句組合處理的區的位置計數器被稱為當前活動計數器。
3.2.4.3bss區
bss區用於儲存區域性公共變數。你可以在bss區中分配空間,但是在程式執行之前不能再其中放置資料。因為當程式剛開始執行時,bss區中所有位元組內容都將被清零。'.lcomm'組合命令用於在bss區中定義一個符號;'.comm'可用於在bss區中宣告一個公共符號。
3.2.5符號
在程式編譯和連結過程中,符號(Sysmbol)是一個比較重要的概念。程式設計師使用符號來命名物件,連結器使用符號進行連結操作,而偵錯程式利用符號進行偵錯。
標號(Label)後面緊跟隨一個冒號的符號。此時該符號代表活動位置計數器的當前值,並且,例如,可作為指令的運算元使用。我們可以使用等號'='給一個符號賦予任意數值。
符號名一個字母或'._'字元之一開始。區域性符號用於協助編譯器和程式設計師臨時使用名稱。在一個程式中共有10個區域性符號('0'....'9')可供重複使用。為了定義一個區域性符號,只要寫出形如'N:'的標號(其中N代表任何數位)。若是參照前面最近定義的這個符號,需要寫成'Nb';若需參照下一個定義的區域性標號,則需要寫成'Nf'。其中'b'意思是向後(backwards),'f'表示向前(forwards)。區域性標號在使用方面沒有限制,到那時在任何時候我們只能向前/向後參照最遠10個區域性標號。
3.2.5.1特殊點符號
特殊符號'.'表示as組合的當前地址。因此表示式'mylab:.long.'就會把mylab定義包含它自己所處的地址值。給'.'賦值就如同組合命令'.org'的作用。因此表示式'.=.+4'與'.space4'完全相同。
3.2.5.2符號屬性
除了名字以外,每個符號都有值"值"和"型別"屬性。根據輸出的格式不同,符號也可以具有輔助屬性。如果不定義就使用一個符號,as就會假設其所有屬性均為0.這指示該符號是一個外部定義的符號。
符號的值通常是32位元的。對於標出text、data、bss或absolute區中一個位置的符號,其值是從區開始到標號處的地址值。對於text、data和bss區,一個符號的值通常會在連結過程中由於ld改變區的基地址而變化,absolute區中符號的值不會改變。這也是為何稱它們是絕對符號的原因。
ld會對未定義符號的值進行特殊處理。如果未定義符號的值是0,則表示該符號在本組合源程式中沒有定義,ld會嘗試根據其他連結的檔案來確定它的值。在程式使用了一個符號但沒有對符號進行定義,就會產生這樣的符號。若未定義符號的值不為0,那麼該符號值就表示是.comm公共宣告的需要保留的公共儲存空間位元組長度。符號指向該儲存空間的第一個地址處。
符號的型別屬性含有用於連結器或偵錯程式的重定位資訊、指示符號是外部的標誌以及一些其他可選資訊。對於a.out格式的目標檔案,符號的型別存放在一個8位元欄位中(n_type位元組)。
as組合指令
組合指令是指示組合器操作方式的偽指令。組合命令用於要求組合器為變數分配空間、確定程式開始地址、指定當前組合的區、修改位置計數器值等。所有組合指令的名稱都以'.'開始,其餘都是字元,並且大小寫無關。但是通常都使用小寫字元。
3.2.6.1 .align abs-expr1,abs-expr2,abs-expr3
.align是儲存對齊組合命令,用於在當前子區中把位置計數器設定(增加)到下一個指定儲存邊界處。第1個絕對值表示式abs-expr1(absolute expression)指定要求的邊界對齊值。對於使用a.out格式目標檔案的80x86系統,該表示式值式位置計數器值增加後其二進位制值最右面0值位的個數,即是2的次方值。例如,'.align3'表示把位置計數器值增加到8的倍數上。如果位置計數器值本身就是8的倍數,那麼就無需改變。但是對於使用ELF格式的80X86系統,該表示式值就是要求對齊的位元組數。例如'.align 8'就是把位置計數器值增加到8的倍數上。
第2個表示式給出用於對齊而填充的位元組值。該表示式與其前面的逗號可以省略。若省略,則填充位元組值是0。第3個可選表示式abs-expr3用於指示對齊操作允許填充跳過的最大位元組數。如果對齊操作要求跳過的位元組數大於這個最大值,那麼該對齊操作就被取消。若想省略第2個引數,可以在第1和第3個引數之間使用兩個逗號。
3.2.6.2 .ascii "string"
從位置計數器所值當前位置位字串分配空間並儲存字串。可使用逗號分開出多個字串。例如,'.ascii "Hello world!","My assembler"'。該組合命令會讓as把這些字串組合在連續的地址位置處,每個字串後面不會自動新增0(NULL)位元組。
3.2.6.3 .asciz "string"
該命令與‘.ascii’類似,但是每個字串後面會自動新增NULL字元。
3.2.6.4 .byte expressions
該組合命令定義0個或多個夠好分開的位元組值。每個表示式的值是一個位元組。
3.2.6.5 .common symbol,length
在bss區中宣告要給命名的公共區域。在ld連結過程中,某個目標檔案中的一個公共符號會與其他目標檔案中同名的公共符號合併。如果ld沒有找到一個符號的定義,而只是一個或多個公共符號,那麼ld就會分配指定長度length位元組的未初始化記憶體。length必須是一個絕對值表示式。如果ld找到多個長度不同但同名的公共符號,ld就會分配長度最大的空間。
3.2.6.6 .data subsection
該組合指令通知as把隨後的語句組合到編號為subsection的data子區中。如果省略編號,則預設使用編號0.編號必須是絕對值表示式。
3.2.6.7 .desc symbol,abs-expr
用絕對錶示式的值設定符號symbol的描述欄位n_desc的16位元值。僅用於a.out格式的目標檔案。
3.2.6.8 .filrepeat,size,value
該組合命令會產生數個(repeat個)大小為size位元組的重複拷貝。大小值可以為0或某個值,但是若size大於8,則限定為8.每個重複位元組內容取自一個8位元組數。高4位元組為0,低4位元組是數值value。這3個引數值都是絕對值,size和value是可選的。如果第2個逗號和value省略,value預設為0值;如果後面兩個引數都省略的話,則size預設為1。
3.2.6.9 .global symbol (或者.globl symbol)
該組合命令會使得連結器ld能看見符號symbol如果在我們的目標中定義了符號symbol,那麼它的值將能被連結過程中的其他目標檔案使用。若目標檔案中沒有定義該符號,那麼它的屬性將從連結過程中其他目標檔案的同名符號中獲得。這是通過設定符號symbol型別欄位中的外部位N_EXT來做到的。
3.2.6.10 .int expressions
該組合命令在某個區中設定0個或多個整數值(80386系統為4位元組,同.long)。每個用逗號分開的表示式的值就是執行時刻的值。例如.int 1234 ,567,0x89AB
3.2.6.11 .lcomm symbol,length
為符號symbol指定的區域性公共區域保留長度為length位元組的空間。所在的區和符號symbol的值是新的區域性公共塊的值。分配的地址在bss區中,因此在執行時刻這些位元組值被清零。由於符號symbol沒有被宣告為全域性的,因此連結器ld看不見
3.2.6.12 .long expressions
含義與.int相同
3.2.6.13 .octa bignums
這個組合指令指定0個或多個用逗號分開的16位元組大數(.byte,.work,.long,.quad,.octa)分別對應(1、2、4、8和16位元組數)
3.2.6.14 .org new_lc,fill
這個組合命令會把當前區的位置計數器設定為new_lc。new_lc是一個絕對值(表示式),或者是具有相同區作為子區的表示式,也即不能使用.org跨越各區。如果new_lc的區不對,那麼.org就不會起作用。請注意,位置計數器是基於區的,即以每個區作為計數起點。
當位置計數器值增長時,所跳躍的位元組將被填入值fill。該值必須是絕對值。如果省略了逗號和fill,則fill預設為0值。
3.2.6.15 .quad bignums
這個組合命令指定00個或多個逗號分開的8位元組大數bignum。如果大數放不進8位元組中,則取低8個位元組。
3.2.6.16 .short expressions(同.word expressions)
這個組合命令指定0個或多個用逗號分開的8位元組大數bignum。如果大數放不進8個位元組中,則取低8個位元組。
3.2.6.17 .space size,fill
該組合命令產生size個位元組,每個位元組填fill。這個引數均為絕對值。如果省略了逗號和fill,那麼fill的預設值就是0。
3.2.6.18 .string "string"
定義一個或多個用逗號分開的字串。在字串中可以使用跳脫字元。每個字串都自動附加一個NULL字元結尾。例如,.string "\n\nStarting","other strings"。
3.2.6.19 .text subsection
通知as把隨後的語句組合進編號為subsection的子區中。如果省略了編號subsection,則使用預設編號值0。
3.2.6.20 .word expressions
對應32位元機器,該組合命令含義與.short相同。
3.2.7編寫16位元程式碼
雖然as通常用來編寫純32位元的80X86程式碼,但是1995年後它對編寫執行於真真實模式或16位元保護模式的程式碼也提供有限的支援。為了讓as組合時產生16位元程式碼,需要在執行16位元模式的指令語句之前新增組合命'.code16',並且使用組合命令'.code32'讓as組合器切換回32位元程式碼組合方式。
as不區分16位元和32位元組合語句,在16位元和32位元模式下每條指令的功能完全一樣而與模式無關。as總是為組合語句產生32位元的指令程式碼而不管指令將執行在16位元還是32位元模式下。如果使用組合命令'.code16'讓as處於16位元模式下,那麼as會自動為所有指令加上一個必要的運算元寬度字首而讓指令執行在16位元模式。請注意,因為as為所有指令新增了額外的地址和運算元寬度字首,所以組合產生的程式碼長度和效能上將會受到影響。
由於在1991年開發Linux核心0.11時as組合器還不支援16位元程式碼,因此在編寫和組合0.11核心真真實模式下的引導啟動程式碼和初始化組合程式時使用前面介紹的as組合器。
3.2.8AS組合器命令列選項
- -a開啟程式列表
- -f快速操作
- -o指定輸出的目標檔名
- -R組合資料區和程式碼區
- -W取消警告資訊
3.3C語言程式
3.3.1C程式編譯和連結
使用gcc組合器編譯C語言程式時通常會經過四個處理階段,即預處理階段、編譯階段、組合階段和連結階段。
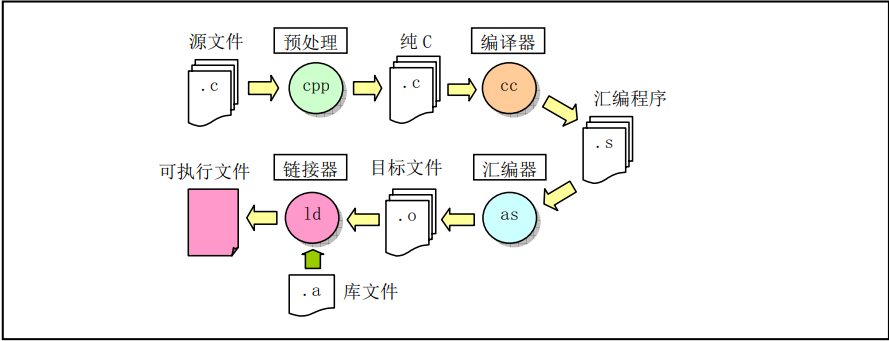
在前處理階段中,gcc會把C程式傳遞給C前處理器CPP,對C語言程式中指示符和宏進行替換處理,輸出純C語言程式碼;在編譯階段,gcc把C語言程式編譯生成對應的與機器相關的as組合語言程式碼;在組合階段,as組合器會把組合程式碼轉換成機器指令,並以特定二進位制格式輸出儲存在目標檔案中;最後GNUld連結器把程式的相關目標檔案組合連結在一起,生成程式的可執行映像檔案。呼叫gcc的命令格式與編譯組合語言的格式類似:
gcc [選項] [-o outfile] infile
其中infile是輸入的C語言檔案;outfile是編譯產生的輸出檔案。對於某次編譯過程,並非一定要全部執行這四個階段,使用命令列選項可以令gcc編譯過程在某個處理階段後就停止執行。例如,使用'-S'選項可以讓gcc在輸出了C程式對應的組合語言之後就停止執行;使用'-c'選項可以讓gcc只生成目標檔案而不執行連結處理,見如下所下。
gcc -o hello hello.c //編譯hello.c程式,生成執行檔案hello。
gcc -S hello.s hello.c //編譯hello.c程式,生成對應組合程式hello.s
gcc -c -o hello.o hello.c //編譯hello.c程式,生成對應目標檔案hello.o而不連結。
在編譯像Linux核心這樣的包含很多源程式檔案的大型程式時,通常使用make工具軟體對整個程式的編譯過程進行自動管理。
3.3.2
本節介紹核心C語言程式中接觸到的嵌入組合(內聯組合)語句。由於我們通常編制C程式過程中一般很少用到嵌入式組合程式碼,因此這裡有必要對其基本格式和使用方法進行說明。具有輸入和輸出引數的嵌入組合語句的基本格式為:
asm("組合語句"
:輸出暫存器
:輸入暫存器
:會被修改的暫存器
);
除第一行以外,後面帶冒號的行若不使用就都可以省略。其中,"asm"是內聯組合語句關鍵詞;"組合語句"是你寫組合指令的地方;"輸出暫存器"表示當這段嵌入組合執行完之後,哪些暫存器用於存放輸出資料。此地,這些暫存器分別對應一C語言表示式值或一個記憶體地址;"輸入暫存器"表示在開始執行組合程式碼時,這裡指定的一些暫存器中應存放的輸入值,它們也分別對應著一C變數或常數值。"會被修改的暫存器"表示你已對其中列出的暫存器中的值進行了改動,gcc編譯器不能再依賴於它原先對這些暫存器載入的值。如果必要的話,gcc需要重新載入這些暫存器。因為我們需要把那些沒有在輸出/輸入暫存器部分列出,但是在組合語句中明確使用到或隱含使用到的暫存器名列在這個部分中。
/kernel/traps.c檔案中第22行開始的一段程式碼作為例子來詳細解說。為了能看得更清楚一些,我們對這段程式碼進行重新排列和編號。
#define get_seg_byte(seg,addr)
({
\
register char __res;\ //定義了一個暫存器變數__res。
__asm__("push %%fs;\ //首先儲存fs暫存器原值(段選擇符)
mov %%ax,%%fs;\ //然後用seg設定fs
movb %%fs:%2,%%al;\ //seg::addr處1位元組內容到a1暫存器中。
pop %%fs"\ //恢復fs暫存器原內容
:"=a"(__res) //輸出暫存器列表
:"0"(seg),"m"(*(addr)) //輸入暫存器列表
")
__res;s})
10行程式碼定義了一個嵌入組合語言宏函數。通常使用組合語句最方便的方式把它們放在一個宏內。用圓括號括住的組合語句(花括號中的語句):"({})"可以作為表示式使用,其中最後一行上的變數__res(第10行)是該表示式的輸出值。
因為宏語句需要定義在一行上,因此這裡使用反斜槓''將這些語句連城一行。這條宏定義將被替換到程式中參照該宏名稱的地方。第一行定義了宏的名稱,也即是宏函數名稱get_seg_byte(seg,addr)。第3行定義了一個暫存器變數__res。該變數將被儲存在一個暫存器中,以便於快速存取和操作。如果想指定暫存器(例如eax),那麼我們可以把該局寫成"register char __res asm("ax");",其中"asm"也可以寫成"asm"。第4行上的"asm"表示嵌入組合語句的開始。從第4行到第7行的4條語句是AT&T格式的組合語句。另外,為了讓gcc編譯產生的組合語言程式中暫存器名稱前有一個百分號"%",在嵌入組合語句暫存器名稱之前就必須寫上兩個百分號"%%"。
第8行即是輸出暫存器,這句的含義是在這段程式碼執行結束後將eax所代表的暫存器的值放入__res變數中,作為本函數的輸出值,"=a"中的"a"稱為載入程式碼,"="表示這是輸出暫存器,並且其中的值將被輸出值替代。第9行表示在這段程式碼開始執行時將seg放到eax暫存器中,"0"表示使用與上面同個位置的輸出相同的暫存器。而((addr))表示一個記憶體偏移地址值。為了在上面組合語句中使用該地址值,嵌入組合程式規定把輸出和輸入暫存器統一按順序編號,順序是從輸出暫存器序列從左到右從上到下以"%0"開始,分別記為%0、%1、...%9。因此,輸出暫存器的編號是%0(這裡只有一個輸出暫存器),輸入暫存器前一部分("0"(seg))的編號%1,而後部分的編號是%2。上面第6行上的%2即代表((addr))這個記憶體偏移量。
現在我們來研究4-7行上的程式碼的作用。第一句將fs段暫存器的內容入棧;第二句將eax中的段值賦給fs段暫存器;第三句是把fs:(*(addr))所指定的位元組放入al暫存器中。當執行完組合語句後是,輸出暫存器eax的值將被放入__res,作為該宏函數(塊結構表示式)的返回值。
通過上面分析,我們指定,宏名稱中的seg代表一指定的記憶體值,而addr表示一記憶體偏移地址量。
asm("cld\n\t"
"rep\n\t"
"stol"
:/*沒有輸出暫存器*/
:/"c"(count-1),"a"(fill_value),"D"(dest)
:"%ecx","%edi"
);
1-3行這三句是通常的組合語句,用以清方向位,重複儲存值。 其中兩行中的字元"\n\t"是用於gcc預處理輸出程式列表時能排的整齊而設定的,字元的含義與C語言中的相同。即gcc的運作方式是先產生與C程式對應的組合程式,然後呼叫組合器對其進行編譯產生目的碼,如果在寫程式和偵錯程式時想看看C對應的組合程式,那麼就需要得到預處理程式輸出的組合程式結果(這在編寫和偵錯高效的程式碼時常用的做法)。為了預處理輸出的組合程式格式整齊,就可以使用"\n\t"這兩個格式符號。
第4行說明這段嵌入組合程式沒有用到輸出暫存器。第5行的含義是:將count-1的值載入到ecx暫存器中(載入程式碼是C),fill_value載入到eax中,dest放到edi中。為什麼要讓gcc編譯程式取做這樣的暫存器值的載入,而不讓我們自己做呢?因為gcc在它進行暫存器分配時可以進行某些優化工作。例如fill_value值可能已經在eax中。如果是在一個迴圈語句中的話,gcc就可能在整個迴圈操作中保留eax,這樣就可以在每次迴圈中少用一個movl語句。
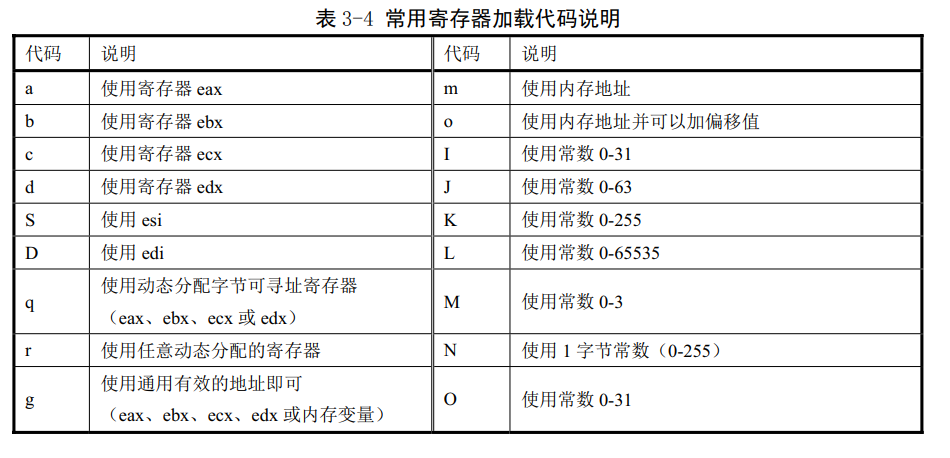
最後一行的作用是告訴gcc這些暫存器中的值已經改變了。在gcc知道你拿這些什麼後,能夠對gcc的優化操作有所幫助。表3-4中是一些可能用到的暫存器載入程式碼及其具體的含義。

下面的例子不是讓你指定哪個變數使用哪個暫存器,而是讓gcc為你選擇
asm("leal(%1,%1,4),%0"
:"=r"(y)
:"0"(x));
)
指令"leal"用於計算有效地址,但這裡用它進行一些簡單計算。第1條組合語句"leal(r1,r2,4),r3"語句表示r1+r2*4->r3。這個例子可以非常快地將x乘5。其中"%0"、"%1"是指gcc自動分配的暫存器。這裡"%1"代表輸入值x要放入的暫存器,"%0"表示輸出值暫存器。輸出暫存器程式碼前一定要加等於號。如果輸入暫存器的程式碼是0或為空時,則說明使用與相應輸出一樣的暫存器。所以,如果gcc將r指定位eax的話,那麼上面組合語句的含義即為:
"leal (eax,eax,4),eax"
注意:在執行程式碼時,如果不希望組合語句被GCC優化而作修改,就需要在asm符號後面新增關鍵詞volatile,見下面所示。這兩種宣告的區別在於程式相容性方面。建議使用後一種宣告方式。
asm volatile(........);
或這更詳細的說明為
__asm__ __volatile__(.....);
** 關鍵詞volatile也可以放在函數名前來修飾函數,用來通知gcc編譯器該函數不會返回。**這樣就可以讓gcc產生更好一些的程式碼。另外,對於不會返回的函數,這個關鍵詞也可以避免gcc產生假警告資訊。例如mm/memory.c中的如下語句說明函數do_exit()和oom()不會再返回到呼叫者程式碼中:
volatile void do_exit(long code);
static inline volatile void oom(void)
{
printk("out of memory\n\r");
do_exit(SIGSEGV);
}
這段程式碼是從include/string.h檔案中檔案中摘取的,是strcmp()字串比較函數的一種實現。同樣,其中每行中的"\n\t"是用於gcc預處理程式輸出列表好看而設定的。
////字串1與字串2的前count字元進行比較
//引數:cs - 字串1,ct -字串2,count -比較的字元數。
// %0 - eax(__res)返回值, %1 - edi(cs)串1指標,%2 - esi(ct)串2指標,%3 - ecx(count)。
// 返回:如果串1>串2,則返回1;串1 = 串2,則返回0;串1<串2,則返回-1
extern inline int strncmp(const char* cs,const char char* ct,init count)
{
register int __res; //__res是暫存器變數
__asm__("cld\n //清方向位
"1:\tdecl %3\n\t" //count--。
"js zf\n\t" // 如果count<0,則向前跳轉到標號2。
"lodsb\n\t" //取串2的字元ds:[esi]->a1,並且esi++
"scasb\n\t" //比較a1與串1的字元es:[edi],並且edi++
"jne 3f\n\t" //如果不相等,則向前跳轉到標號3。
"testb %%al,%%al\n\t" //該字元是NULL字元嗎?
"jne 1b\n" //不是,則向後跳轉到標號1,繼續比較。
"2:\txorl %%eax,%%eax\n\t"//NULL字元,則eax清零(返回值)。
"jmp 4f\n"//向前跳轉到標號4,結束。
"3:\tmovl $1,%%eax\n\t" //eax中置1
"jl 4f\n\t"//如果前面比較中串2字元<串1字元,則返回1,結束。
"neg1 %%eax\n" //否則eax = -eax,返回負值,結束。
"4:"
:"=a"(__res):"D".(cs),"S" (ct),"c"(count):"si","di","cx")
return __res; //返回比較結果。
}
3.3.3圓括號中的組合語句
花括號對"{...}"用於把變數宣告和語句組合成一個複合語句(組合語句)或一個語句塊,這樣在語意上這些語句就等同於一條語句。組合語句的右花括號後面不需要使用分號。圓括號中的組合語句,即形如"({....})"的語句,可以在GNU C中用作一個表示式使用。這樣就可以在表示式中使用loop、switch語句和區域性變數,因此這種形式的語句通常稱為語句表示式。語句表示式具有如下範例的形式:
({
int y = foo();int z;
if(y>0) z = y;
else z = -y
3+z;
})
其中組合語句中最後一條語句必須市後面跟隨一個分號的表示式。這個表示式("3+z")的值即用作整個圓括號括住語句的值。如果最後一條語句不是表示式,那麼整個語句表示式就具有void型別,因此沒有值。另外,這種表示式中語句宣告的任何區域性變數都會在整個語句結束後失效。這個範例語句可以像如下形式的賦值語句來使用:
res = x + ({略...})+b
當然,人們通常不會像上面這樣寫語句,這種語句表示式通常都用來定義宏。例如核心原始碼init/main.c程式中讀取CMOS時鐘資訊的宏定義:
#define CMOS_READ(addr)({{
\最後反斜槓起連線兩行語句的作用
outb_p(0x80|addr,0x70)\ //首先向I/O埠0x70輸出欲3讀取的位置addr。
intb_p(0x71);\ //然後從埠0x71讀入該位置處的值作為返回值。
})
再看一個include/asm/io.h標頭檔案中的讀I/O埠port的宏定義,其中最後變數_v的值就是inb()的返回值。
#define inb(port)({\
unsigned char_v;\
__asm__volatile("inb %%dx,%%al":"=a"(_v):"d"(port);\
_v;\
})
3.3.4暫存器變數
GNU對C語言的另一個擴充是允許我們把一些變數值放到CPU暫存器中,即所謂暫存器變數。這樣CPU就不用經常花費較長時間存取記憶體去取值。暫存器變數可以分為2種:全域性變數暫存器變數和區域性暫存器變數。全域性暫存器變數會在程式的整個執行過程種保留暫存器專門用於幾個全域性變數。相反,區域性暫存器不會保留指定的暫存器,而僅在內嵌asm組合語句種作為輸入或輸出運算元時使用專門的暫存器。gcc編譯器的資料流分析功能本身有能力確定指定的暫存器何時含有正在使用的值,何時可派其他用場。當gcc資料流分析功能認為儲存在某個區域性暫存器變數值無用時就可能會刪除之,並且對區域性暫存器變數的參照也可能被刪除、移動或簡化。因此,若不想讓gcc作這些優化改動,最好在asm語句種加上volatitle關鍵詞。
如果想在嵌入組合語句中把組合指令的輸出直接寫到指定的暫存器中,那麼此時使用區域性暫存器變數就很方便。由於Linux核心中通常只使用區域性暫存器變數,因此這裡我們只對區域性暫存器變數的使用方法進行討論。在GNU C程式中我們可以在函數中用如下形式定義一個區域性暫存器變數:
register int res __asm__("ax")
這裡ax是變數res所希望使用的暫存器。定義這樣一個暫存器變數並不會專門保留這個暫存器不派其他用途。在程式編譯過程中,當gcc資料流控制去欸的那個變數的值已經不用時就可能將該暫存器派作其他用途,而且對它的參照可能會被刪除、移動或被簡化。另外,gcc並不保證編譯出的程式碼會把變數一致放在指定的暫存器中。因此在嵌入組合指令的部分最好不要明確地參照該暫存器並且假設該暫存器肯定參照的是該變數值。然而把該變數用作為asm的運算元還是能夠保證指定的暫存器被用作該運算元。
3.3.5行內函式
在程式中,通過把一個函數宣告為內聯(inline)函數,就可以讓gcc把函數的程式碼整合到呼叫該函數的程式碼中去。這樣處理可以去掉函數呼叫時進入/退出時間開銷,從而肯定能夠加快執行速度。因此把一個函數宣告為行內函式的主要目的就是能夠儘量快速的執行函數體。另外,如果行內函式中有常數值,那麼在編譯期間gcc就可能用它進行一些簡化操作,因此並非所有行內函式的程式碼都會被嵌入進去。行內函式方法對程式程式碼的長度影響並不明顯。使用行內函式的程式編譯產生的目的碼可能會長一些也可能會短一些,這需要根據具體情況來定。
行內函式嵌入呼叫者程式碼中的操作是一種優化操作,因此只有進行優化編譯才會執行程式碼嵌入處理。若編譯過程中沒有使用優化選項"-O",那麼行內函式的程式編譯產生的目的碼可能會長一些也可能會短一些,這需要根據具體情況來定。
行內函式嵌入呼叫者程式碼中的操作是一個優化操作,因此只有進行優化編譯時才會執行程式碼嵌入處理。。若編譯過程中沒有使用優化選項"-O",那麼行內函式的程式碼就不會被真正地嵌入到呼叫這程式碼中,而是隻作為普通函數呼叫來處理。把一個函數宣告為行內函式的方法是在函數宣告中使用關鍵詞"inline",例如核心檔案/fs/inode.c的如下函數:
inline int inc(int *a)
{
(*a)++;
}
函數中的某些語句用法可能會使得行內函式的替換操作無法正常進行,或者不適合進行替換操作。例如使用了可變引數、記憶體分配函數mallocca()、可變長度資料型別變數、非區域性goto語句、以及遞迴函數。編譯時可以使用選項 -Winline 讓gcc對標誌成inline但不能被替換的函數給出警告資訊以及不能替換的原因。
當在一個函數定義中既使用inline關鍵詞、又使用static關鍵詞,即像下面檔案fs/inode.c中的行內函式定義一樣,那麼如果所有對該行內函式的呼叫都被替換而整合在呼叫者程式碼中,並且程式中沒有參照過該行內函式的地址,則該行內函式自身的組合程式碼就不會被參照過。在這種情況下,除非我們在編譯過程中使用選項 -fkeep-inline-functions,否則gcc就不會再為該行內函式定義之前的呼叫語句。是不會被替換整合的,並且也都不能是遞迴定義的函數。如果存在一個不能被替換整合的呼叫,那麼行內函式就會像平常一樣被編譯成組合程式碼。因為對行內函式地址的參照時不能被替換的。
static inline void wait_on_inode(struct m_inode* inode)
{
cli();
while(inode->i_lock)
sleep_on(&inode->i_wait)
sti();
}
請注意,行內函式功能已經被包括在ISO標準C99中,但是該標準定義的行內函式與gcc定義的有較大區別。ISO標準C99的行內函式語意定義等同於這裡使用組合關鍵詞inline和static的定義,即"省略"了關鍵詞static。若在程式需要使用C99標準的語意,那麼就需要使用編譯選項 -std=gnu99。不過為了相容起見,在這中情況下還是最好使用inline和static組合。以後gcc將最終預設使用C99的定義,在希望仍然使用這裡定義的語意,就需要使用選項 -std=gnu89來指定。
若一個行內函式的定義沒有使用關鍵詞static,那麼gcc就會假設其他程式檔案中也對這個函數有呼叫。因為一個全域性符號只能被定義一次,所以該函數就不能再在其他原始檔中進行定義。因此這裡對行內函式的呼叫就不能被替換整合。因此,一個非靜態的行內函式總是會被編譯出自己的組合程式碼來。在這方面,ISO標準C99對不使用static關鍵詞的行內函式定義等同於這裡使用static關鍵詞的定義。
如果在定義一個函數時同時指定了inline和extren關鍵詞,那麼該函數定義僅用於內聯整合,並且在任何情況下都不會單獨產生該函數自身的組合程式碼,即使明確了參照了該函數的地址也不會產生。這樣的一個地址會變成一個外部參照,就好像你僅僅宣告了函數而沒有定義函數一樣。
關鍵詞inLine和extern組合在一起的作用幾乎類同一個宏定義。使用這種組合方式就是把帶有組合關鍵詞的一個函數定義放在.標頭檔案中,並且不含關鍵詞的另一個相同函數定義放在一個庫檔案中。此時標頭檔案中的定義會讓絕大多數對函數的呼叫被替換嵌入。如果還沒有被替換的對該函數的呼叫,那麼就會使用(參照)程式檔案中或庫中的拷貝。
Linux 0.1x核心原始碼中檔案 include/string.h、lib/strings.c就是這種使用方式的一個例子。例如string.h定義瞭如下函數:
//將字串(src)拷貝到另一個字串(dest),直到遇到NULL字元后停止。
//引數dest - 目的字串指標,src - 源字串指標 %0 -esi(src),%1 -edi(dest)
extern inline char * strcpy(char* dest,const char *src)
{
__asm__(
"cld\n" //清方向位。
"1:\tlodsb\n\t" //載入DS:[esi]處1位元組->al,並更新esi。
"stosb\n\t" //儲存位元組al->ES:[edi],並更新edi
"testb %%al,%%al\n\t" //剛儲存的位元組是0?
"jne 1b" //不是則向後跳轉到標號1處,否則結束。
::"S"(src),"D"(dest):"si","di","ax");
return dest //返回目的字串指標。
}
而在核心函數庫目錄中,lib/string.c檔案把關鍵詞inline和extern都定義為空,見如下所示。因此實際上就在核心函數庫中又包含了string.h檔案所有這類函數的一個拷貝,即又對這些函數重新定義了一次,並且"消除"了兩個關鍵詞的作用。
#define extern //定義為空
#define inline //定義為空
#define LIBRARY
#include <string.h>
此時庫函數重新定義的上述strcpy()函數變成如下形式:
char * strcpy(char* dest,const char *src)
{
__asm__("cld\n" //清方向位置
"1:\tlodsb\n\t"//載入DS:[esi]處1位元組->a1,並更新esi
"stosb\n\t"//儲存位元組al->ES:[edi],並更新edi
"testb %%al,%%al\n\t"//剛儲存的位元組是0?
"jne 1b" //不是則向後跳轉到標號1處,否則結束
::"S"(src),"D"(dest):"si","di","ax");
return dest//返回目的字串指標
}
3.4C與組合程式的相互呼叫
為了提高程式碼執行效率,核心原始碼中有地方直接使用了組合語言編制。這就會涉及到在兩種語言編制的程式之間相互呼叫問題。本節首先說明C語言函數的呼叫機制,然後使用兩者函數之間的呼叫方法。
3.4.1C函數呼叫機制
在Linux核心程式boot/head.s執行完基本初始化操作之後,就會跳轉去執行init/main.c程式。那麼head.s程式是如何把執行控制轉交給init/main.c程式的呢?即組合程式是如何呼叫執行C語言程式的?這裡我們首先描述一下C函數的呼叫機制、控制權傳遞方式,然後說明head.d程式跳轉到C程式的方法。
函數呼叫操作包括從一塊程式碼到另一塊程式碼之間的雙向資料傳遞和執行控制轉移。資料傳遞通過函數引數和返回值來進行。另外,我們還需要在進入函數時為函數的區域性變數分配儲存空間,並且在退出函數時收回這部分空間。Intel80x86CPU為控制傳遞提供了簡單的指令,而資料的傳遞和區域性變數儲存空間的分配與回收則通過棧操作來實現。
3.4.1.1棧幀結構和控制轉移權方式
大多數CPU上的程式實現使用棧來支援函數呼叫操作。棧被用來傳遞函數引數、儲存返回資訊、臨時儲存暫存器原有值以備恢復以及儲存區域性資料。單個函數呼叫操作所使用的棧部分被稱為棧幀(Stack frame)結構,棧幀結構的兩端由兩個指標來指定。暫存器ebp通常用作影格指標(frame pointer),而esp則用作棧指標(stack pointer)。在函數執行過程中,棧指標esp會隨著資料的入棧和出棧而移動,因此函數中對大部分資料的存取都基於影格指標ebp進行。
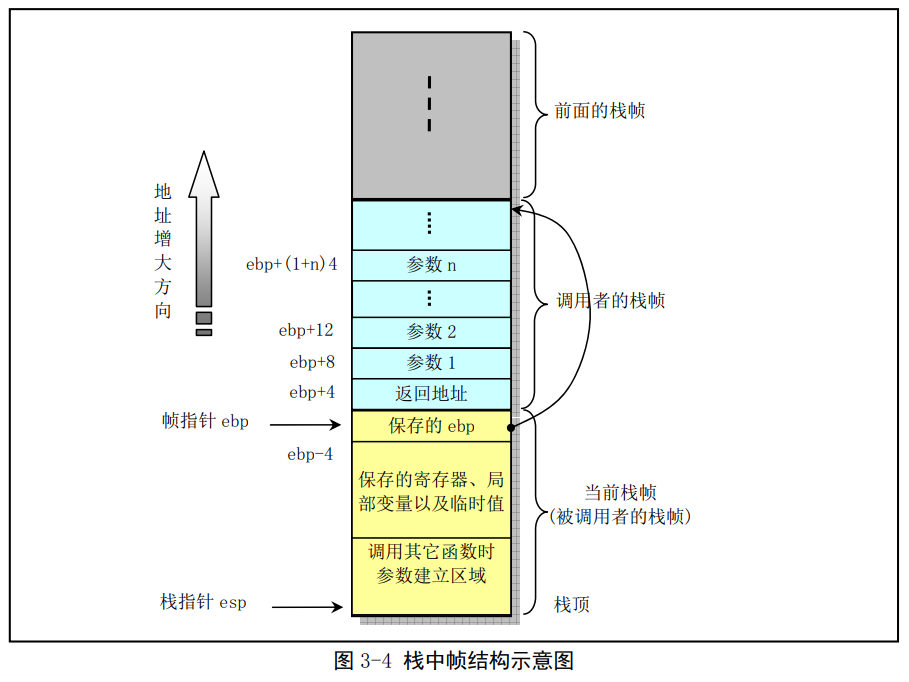
對於函數A呼叫函數B的情況,傳遞給B的引數包含在A的棧幀中。當A呼叫B時,函數A的返回地址(呼叫返回後繼續執行的指令地址)被壓入棧中,棧中該位置也明確指明瞭A棧的結束處。而B的棧幀則從隨後的棧部分開始,即圖中儲存影格指標(ebp)的地方開始。再隨後則用於存放任何儲存的暫存器值以及函數的臨時值。
B函數同樣也使用棧來儲存不能放暫存器中的區域性變數值。例如由於通常CPU的暫存器數量有限而不能夠存放函數的所有區域性資料,或者有些區域性變數是陣列或結構,因此必須使用陣列或結構參照來存取。還有就是C語言的地址操作符'&'被應用到一個區域性變數上時,我們就需要為該變數生成一個地址,即為變數的地址指標分配一空間。最後,B函數會使用棧來儲存呼叫任何其它函數的引數。
棧是往低(小)地址方向擴充套件的,而esp指向當前棧頂處的元素。通過使用push和pop指令我們可以把資料壓入棧中或從棧中彈出。對於沒有指定初始值的資料所需要的儲存空間,我們可以通過影格指標遞減適當的值來做到。類似的,通過增加棧指標值我們可以回收棧中已分配的空間。
指令CALL和Ret用於處理常式呼叫和返回操作。呼叫指令CALL的作用是把返回地址壓入棧中並且跳轉到被呼叫函數開始處執行。返回地址是程式中緊隨呼叫CALL後面一條指令的地址。因此當被呼叫函數返回時就會從該位置繼續執行。返回RET指令用於彈出棧頂處的地址並跳轉到該地址處。在使用該指令之前,應該先正確處理棧中內容,使得當前棧指標所指位置內容正是先前CALL指令儲存的返回地址。
另外,若返回值是一個整數或一個指標,那麼暫存器eax將被預設用來傳遞返回值。
儘管某一時刻只有一個函數在執行,但我們還是需要確定在一個函數(呼叫者)呼叫其他函數(被函數者)時,被呼叫者不會修改或覆蓋呼叫者今後用到的暫存器內容。因此IntelCPU採用了所有函數必須遵守的暫存器用法統一慣例。該慣例指明,暫存器eax、edx、和ecx的內容必須由呼叫者自己負責儲存。當函數B被A呼叫時,函數B可以在不用儲存這些暫存器內容的情況下任意使用它們而不會毀壞函數A所需要的任何資料。另外,暫存器ebx、esi和edi的內容則必須由被呼叫者B來保護。當被呼叫者需要使用這些暫存器中的任何一個時,必須首先在棧中儲存其內容,並在退出時恢復這些這些暫存器的內容。因為呼叫者A(或者一些更高的函數)並不負責儲存這些暫存器內容,但可能在以後的操作中還需要用到原先的值。還有暫存器ebp和esp也必須遵守第二個慣例用法。
3.4.1.2函數呼叫舉例
作為一個例子,我們來觀察下面C程式exch.c中函數呼叫的處理過程。該程式交換兩個變數中的值,並返回它們的差值。
void swap(int* a,int* b)
{
int c;
c = *a;
*a = *b;
*b = c;
}
int main()
{
int a,b;
a = 16;
b = 32;
swap(&a,&b);
return(a-b);
}
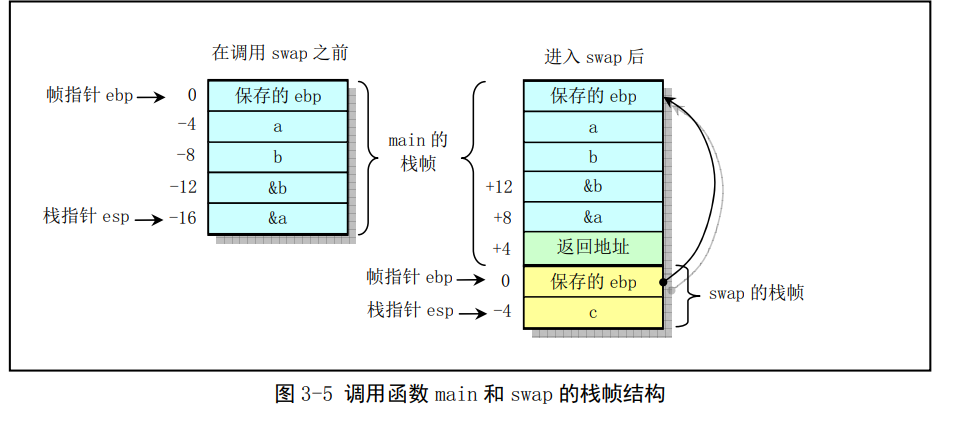
其中函數swap()用於交換兩個變數的值。C程式的主程式main()也是一個函數(將在下面說明),它在呼叫swap()之後返回交換的結果。這兩個函數的棧幀結構見圖。可以看出,函數swap()從呼叫者(main())的棧幀中獲取其引數。圖中的位置資訊相對於暫存器ebp中的影格指標。棧幀左邊的數位指出了相對於影格指標的地址偏移值。在像gdb這樣的偵錯程式中,這些數值都用2的二補數表示。例如'-4'被表示成'0xFFFFFFFC','-12'會被表示成'0xFFFFFFF4'
呼叫者main()的棧幀結構中包括區域性變數a和b的儲存空間,相對於影格指標位於-4和-8偏移處。由於我們需要為這兩個區域性變數生成地址,因此它們必須儲存在棧中而非簡單地存放在暫存器中。
.text
_swap
pushl %ebp #儲存原ebp值,設定當前函數的影格指標。
movl %esp,%ebp
subl $4,%esp #為區域性變數c在棧內分配空間
movl 8(%ebp),%eax #取函數第1個引數,該引數是一個整數型別值的指標。
movl (%eax),%ecx #取該指標所指位置的內容,並儲存到區域性變數c中。
movl (%ecx),-4(%ebp)
movl 8(%ebp),%eax #再次取第1個引數,然後取第2個引數
movl 12(%ebp),%edx
movl(%edx),%ecx
movl %ecx,(%eax)
movl 12(%ebp),%eax #再取第2個引數。
movl -4(%ebp),%ecx #然後把區域性變數c中的內容放到這個指標所指位置處。
movl %ecx,(%eax)
leave $恢復原ebp、esp值(即movl %ebp,%esp;popl %ebp)
ret
_main
pushl %ebp #儲存原ebp值,設定當前函數的影格指標
movl %esp,%ebp
subl $8,%esp #為整型區域性變數a和b在棧中分配空間
movl $16,-4(%ebp)
movl $32,-8(%ebp)
leal -8(%ebp),%eax #外呼叫swap()函數作準備,取區域性變數b的地址。
pushl %eax #作為呼叫的引數並壓入棧中。即先壓入第2個引數。
call _swap #呼叫函數swap()
movl -4(%ebp),%eax #取第1個區域性變數a的值,減去第2個變數b的值
movl -8(%ebp),%eax
leave #恢復原ebp、esp值(即movl %ebp,%esp;popl %ebp;)
ret
這兩個函數均可以劃分成三個部分:"設定",初始化棧幀結構;"主題",執行函數的實際計算操作;"結束",恢復棧狀態並從函數中返回。對於swap()函數,其設定部分程式碼是3--5行。前兩行用來設定儲存呼叫者的影格指標和設定本函數的的棧影格指標,第5行通過把棧指標esp下移4位元組為區域性變數c分配空間。第6--15行是swap函數的主題部分。第6--8用於取呼叫者的第一個引數&a,並以該引數作為地址取所有內容到ecx暫存器中,然後儲存到為區域性變數分配的空間中(-4(%ebp)。)第9--12行用於取第2個引數&b,並以該引數值作為地址取其內容放到第1個引數指定的地址處。第13--15行把儲存在臨時區域性變數c中的值存放到第2個引數指定的地址處。最後16--17行是函數結束部分。leave指令用於處理棧內容以準備返回,它的作用等價於下面兩個指令
movl %ebp,%esp #恢復原esp的值(指向棧幀開始處)
popl %ebp #恢復原ebp的值(通常是呼叫者的影格指標)。
這部分程式碼恢復了在進入swap()函數時暫存器esp和ebp的原有值,並執行返回指令ret。
第19--21行時main()函數的設定部分,在儲存和重新設定影格指標後,main()為區域性變數a和b在棧中分配了空間。第22-23行為這兩個區域性變數賦值。從24-28行可以看出main()中是如何呼叫swap()函數的。其中首先使用leal指令(取有效地址)獲得變數b和a的地址並分別壓入棧中,然後呼叫swap()函數。變數地址壓入棧中的順序正好與函數申明的引數順序相反。即函數最後一個引數首先壓入棧中,而函數的第1個引數則是最後一個在呼叫函數指令callz之前壓入棧中。第29--30兩行將兩個已經交換過的數位相減,並放在eax暫存器中作為返回值。
從以上分析可知,C語言在呼叫函數時是在堆疊上臨時存放被調函數引數的值,即C語言是傳值類語言,沒有直接的方法可用來在被呼叫函數中修改呼叫者變數的值。因此為了達到修改的目的就需要向函數傳遞變數的指標(即變數的地址)。
3.4.1.3main()也是一個函數
上面這段組合程式是gcc 1.40編譯產生的,可以看出其中有幾行多餘的程式碼。可見當時的gcc編譯器還不能產生最高效率的程式碼,這也是為什麼某些關鍵程式碼需要直接使用組合語言編制的原因。另外,上面提到c程式的主程式main()也是一個函數。這是因為在編譯連結時它將會作為ctr0.s組合程式的函數被呼叫。crt0.s是一個樁(stub)程式,名稱中的"crt"是"C run-time"的縮寫。該程式的目標檔案將被連結在每個使用者執行程式的開始部分,主要用於設定一些初始化全域性變數等。Linux0.11中crt0.s組合程式中見如下所示。其中建立並初始化全域性變數_environ供程式中其它模組使用。
.text
.global _environ #宣告全域性變數 _environ(對應C程式中的environ變數)
__entry #程式碼入口標號
movl 8(%esp),%eax#取程式的環境變數指標envp並儲存在__environ中。
movl %eax,_environ #envp是execve函數在載入執行檔案時設定的。
call _main #呼叫我們的主程式。其返回狀態值在eax暫存器中。
pushl %eax #壓入返回值為exit()函數的引數並呼叫該函數。
call _exit
jmp lb
.data
_environ #定義變數_environ,為其分配一個長字空間
.long 0
通常使用gcc編譯連結生成執行檔案時,gcc會自動把該檔案的程式碼作為第一個模組連結在可執行程式中。在編譯時使用顯示詳細資訊選項'-v'就可以明顯地看出這個連結操作過程:
[/usr/root]# gcc -v -o exch exch.s
gcc version 1.40
/usr/local/lib/gcc-as -o exch.o exch.s
/usr/local/lib/gcc-ld -o exch /usr/local/lib/crt0.o exch.o /usr/local/lib/gnulib -lc
/usr/local/lib/gnulib
[/usr/root]#
因此在通常的編譯過程中我們無需特別指定stub模組crt0.o,但是若想從上面給出的組合程式手工使用ld(gld)從exch.o模組倆連結產生可執行檔案exch,那麼我們就需要在命令列上特別指明crt0.o這個模組,並且連結的順序應該是crt0.o所有程式模組、庫檔案。"
為了使用ELF格式的目標檔案以建立共用庫模組檔案,現在的gcc編譯器(2.x)已經把這個crt0擴充套件成幾個模組:crt1.o、crti.o、crtbegin.o、cretend.o和crtn.o這些模組的連結順序為"crtl.o、crti.o、crtbegin.o(crtbeginS.o)"、所有程式模組、crtend.o(crtendS.o)、crtn.o、庫模組檔案"。gcc的組態檔specfile指定了這種連結順序。其中ctrl.o、crti.o和crtn.o由C庫提供,是C程式的"啟動"模組;crtbegin.o和crtend.o是C++語言的啟動模組,由編譯器gcc提供;而ctrl.o則與crt0.o的作用類似,主要用於呼叫main()之前做一些初始化工作,全域性符號__start就定義在這個模組中。
crtbegin.o和crtend.o主要用於C++語言在.ctors和.dtors區中執行全域性構造器(constructor)和解構器(destructor)函數。crtbeginS.o和crtendS.o的作用與前兩者類似,但用於建立共用模組中。crti.o用於在.init區中執行初始化函數init()。.init區中包含程序的初始化程式碼,即當前程式開始執行時,系統在呼叫main()之前先執行.init中的程式碼。crtn.o則用於在.fini區中執行程序終止退出處理常式fini()函數,即當程式正常退出時(main()返回之後),系統會安排執行.fini中的程式碼。
boot/head.s程式中第136--140行就是用於為跳轉到init/main.c中的main()函數作準備工作。第139行上的指令在棧中壓入了返回地址,而第140行則壓入了main()函數程式碼的地址。當head.s最後在第218行上執行ret指令時就會彈出main()的地址,並把控制權轉移到init/main.c程式中。
3.4.2在組合程式中呼叫C函數
在組合程式中呼叫一個C函數時,程式需要首先按照逆向順序把函數引數壓入棧中,即函數最後(最右邊的)一個引數先入棧,而最左邊的第1個引數在最後呼叫指令之前入棧,見圖3-6所示。然後執行CALL指令去執行被呼叫的函數。在呼叫函數返回後,程式需要再把先前壓入棧中的引數清楚掉。

在執行CALL指令時,CPU會把CALL指令下一條指令的地址壓入棧中(見圖中EIP)。如果呼叫還涉及到程式碼特權級變化,那麼CPU還會進行堆疊切換,並且把當前堆疊指標、段描述符和呼叫引數壓入新堆疊中。由於Linux核心中只使用中斷門和陷阱門方式處理特權級別變化時的呼叫情況,並沒有使用CALL指令來處理特權變化的情況,因此這裡對特權級別變化時的CALL指令使用方式不再進行說明。
組合中呼叫C函數比較"自由"。只要是在棧中適當位置的內容就可以作為引數供C函數使用。這裡仍然以圖3-6中具有3個引數的函數呼叫為例,如果我們沒有專門為呼叫函數func壓入引數就直接呼叫它的話,那麼func()函數仍然會把EIP位置以上的棧中其他內容作為自己的引數使用。如果我們為呼叫func()僅僅明確地壓入了第1、第2個引數,那麼func()函數的第3個引數p3就會直接使用p2前的棧中內容。在Linux0.1x核心程式碼中國就有幾處使用了這種方式。例如在kernel/system_call.s組合程式中第217行上呼叫copy_process()函數(kernel/fork.c中第68行)的情況。在組合程式函數__sys_fork中雖然把5個引數壓入棧中,但是copy_process()卻共帶有多達17個引數,見下面所示:
//kernel/system_call.s組合程式_sys_fork部分
212 push%gs
213 pushl %esi
214 pushl %edi
215 pushl %ebp
216 pushl %eax
217 call _copy_process #呼叫C函數copy_process()(kernel/fork.c,68)
218 addl $20,%esp #丟棄這裡所有壓棧內容。
219 ret
//kernel/fork.c程式
68 int copy_process(int nr,long ebp,long edi,long esi,long gs,long none,long ebx,long ecx,long edx,long fs, long es,long ds,long eip,long cs,long eflags,long esp,long ss)
我們知道引數越是最後入棧,它越是靠近C函數引數左側。因此實際上呼叫copy_process()函數之前入棧5個暫存器值就是copy_process()函數的最左面的5個引數。按順序它們分別對應為入棧的eax(nr)、ebp、edi、esi和暫存器gs的值。而隨後的其餘引數實際上直接對應堆疊上已有的內容。這些內容是進入系統呼叫中斷處理過程開始,直到呼叫本系統呼叫處理過程時逐步入棧的各暫存器的值。
引數none是system_call.s程式第94行上利用地址跳轉表sys_call_table呼叫_sys_fork時的下一條指令的返回地址。隨後的引數是剛進入system_call時在83-88行壓入棧的暫存器ebx、ecx、edx和段暫存器fs、es、ds。最後5個引數是CPU執行中斷指令壓入返回地址eip和cs、標誌暫存器eflags、使用者棧地址esp和ss。因為系統呼叫涉及到程式特權級別變化,所以CPU會把標誌暫存器值和使用者棧地址也壓入了堆疊。在呼叫C函數copy_process()返回後,_sys_fork也只把自己壓入5個引數丟掉,棧中其他還均儲存著。其它採用上述用法的函數還有kernel/signal.c中的do_signal()、fs/exec.c中的do_execve(),請自己分析。
另外,我們說組合程式呼叫C函數比較自由的另一個原因是我們可以根本不用CALL指令而採用JMP指令同樣到達呼叫函數的目的。方法是在引數入棧後人工把下一條要執行的指令地址壓入棧中,然後直接使用JMP指令跳轉到被呼叫函數開始地址處去執行函數。此後當函數執行完成時就會執行RET指令把我們人工壓入棧中的下一條指令地址彈出,作為函數返回的地址。Linux核心中也有多處用到了這種函數呼叫方法,例如kernel/asm.s程式第62行呼叫執行了trap.c中的do_int3()函數的情況。
3.4.3在程式中呼叫組合函數
從C程式呼叫組合程式函數的方法與組合程式中呼叫C函數的原理相同,但Linux核心程式中不常使用。呼叫方法的著重點仍然是對函數引數在棧中位置的確定上。當然,如果呼叫的組合語言程式比較短,那麼就可以直接在C程式中使用上面的介紹測內聯組合語句來實現。以下我們以一個範例來說明編制這類程式的方法。包含兩個函數的組合程式callees.s見如下所示。
/*
本組合程式利用系統呼叫sys_write()實現顯示函數 int mywrite(int fd,char* buf,int count)函數 int myadd(int a,int b,int* res)用於執行a+b=res運算。若函數返回0,則說明溢位。
注意:如果在現在的Linux系統(例如RedHat 9)下編譯,則請去掉函數名的下劃線'_'
*/
SYSWRITE = 4 #sys_write()系統呼叫號
.global _mywrite, _myadd
.text
_mywrite
pushl %ebp
movl %esp,%ebp
pushl %ebp
movl 8(%ebp),%ebx #取呼叫者第1個引數:檔案描述符fd
movl 12(%ebp),%ecx #取第2個引數:緩衝區指標
movl 16(%ebp),%edx #取第三個引數:顯示字元數。
movl $SYSWRITE,%eax #%eax中放入系統呼叫號4
int $0x80 #執行系統呼叫
popl %ebx
movl %ebp,%esp
popl %ebp
ret
_myadd
pushl %ebp
movl %esp,%ebp
movl 8(%ebp),%eax #取第1個引數a。
movl 12(%ebp),%edx #取第2個引數b。
xorl %ecx,%ecx #%ecx為0表示計算溢位。
addl %eax,%edx #執行加法運算
jo lf #若溢位則跳轉
movl 16(%ebp),%eax #取第3個引數的指標
movl %edx,(%eax) #把計算結果放入指標所指位置處
incl %ecx #沒有發生溢位,於是設定無溢位返回值
movl %ecx,%eax #%eax中是函數返回值
movl %ebp,%esp
popl %ebp
ret
該組合檔案中的第1個引數mywrite()利用系統中斷0x80系統呼叫sys_write(int fd,char* buf,int count)實現在螢幕上顯示資訊。對應的系統呼叫功能號是4(參見include/unistd.h),三個引數分別為檔案描述符、顯示緩衝區指標和顯示字元數。在執行int 0x80之前,暫存器%eax中需要放入呼叫功能號(4),暫存器%ebx、%ecx和%edx要按呼叫規定分別存放fd、buf和count。函數mywrite()的呼叫引數個數與sys_write()完全一樣。
第2個函數myadd(int a,int b,int *res)執行加法運算。其中引數res是運算的結果。函數返回值用於判斷是否發生溢位。如果返回值為0表示計算已發生溢位,結果不可用。否則計算結果將通過引數res返回給呼叫者。
注意:如果在現在Linux系統(例如RedHat 9)下編譯callee.s程式,則請去掉函數名前的下劃線'_'。呼叫這兩個函數的C程式cller.c見如下所示
/*
呼叫組合函數mywrite(fd,buf,count)顯示資訊;呼叫myadd(a,b,result)執行加法運算。如果myadd()返回0,則表示加函數發生溢位。首先顯示開始計算資訊,然後顯示運算結果。
*/
int main()
{
char buf[1024];
int a, b,res;
char* mystr="Calculating....\n"
char* emsg = "Error in adding\n"
a = 5;
b = 10;
mywrite(1,mystr,strlen(mystr));
if(myadd(a,b,&res))
{
sprintf(buf,"The result is %d \n",res)
}
else
{
mywrite(1,emsg,strlen(emsg));
}
return 0 ;
}
該函數首先利用組合函數利用mywrite()在螢幕上顯示開始計算的資訊"Calculating....",然後呼叫加法計算組合函數myadd()對a和b兩個數進行運算,並在第3個引數res中返回計算結果。最後再利用mywrite()函數把格式化過的結果資訊字串顯示在螢幕上。如果函數myadd()返回0,則表示加函數發生溢位,計算結果無效。這兩個檔案的編譯和執行結果
[/usr/root]# as -0 callee.o callee.s
[/usr/root]# gcc -o caller caller.c callee.o
[/usr/root]# ./caller
Calculating...
The result is 15
[/usr/root]#
3.5Linux0.11目標檔案格式
為了生成核心程式碼檔案,Linux0.11使用了兩種編譯器。第一種是組合編譯器as86和相對應的連結程式(或稱為連結器)ld86。它們專門用於編譯和連結執行在實地址模式下的16位元核心引導磁區程式bootsect.s和設定程式setup.s第二種是GNU的組合器as(gas)和C語言編譯器gcc以及相對應的連結程式gld。編譯器用於為源程式檔案產生對應的二進位制程式碼和資料目標檔案。連結程式用於對相關的所有目標檔案進行組合處理,形成一個可被核心載入執行的目標檔案,即可執行檔案。
本節首先簡單說明編譯器產生的目標檔案結構,然後描述連結器如何把需要連結在一起的目標檔案模組組合在一起,以生成二進位制可執行映像檔案或一個大的模組檔案。最後說明Linux0.11核心二進位制程式碼檔案Image的生成原理和過程。這裡給出了Linux0.11核心所支援的a.out目標檔案格式的資訊。as86和ld86生成的MINIX專門的目標檔案格式,我們將涉及這種格式的核心建立工具一章中給出。
為了便於描述,這裡把編譯器生成的目標檔案稱為目標模組檔案(簡稱模組檔案),而把連結程式輸出產生的可執行目標檔案稱為可執行檔案。並且它們都統稱為目標檔案。
3.5.1目標檔案格式
在Linux0.11系統中,GNU gcc或 gas編譯輸出的目標模組檔案和連結程式所生成的可執行檔案使用了UNIX傳統的a.out格式。這是一種被稱為組合或連結輸出(Assembly& linker editor output)的目標檔案格式。對於具有記憶體分頁機制的系統來說,這是一種簡單有效的目標檔案個是。a.out檔案有一個檔案頭和隨後的程式碼區(Text section ,也稱為正文段)、已初始化資料區(Data section,也稱為資料段)、重定位資訊區、符號表以及符號名字串構成,見下圖其中程式碼區和資料區通常也分別稱為正文段(程式碼段)和資料段。
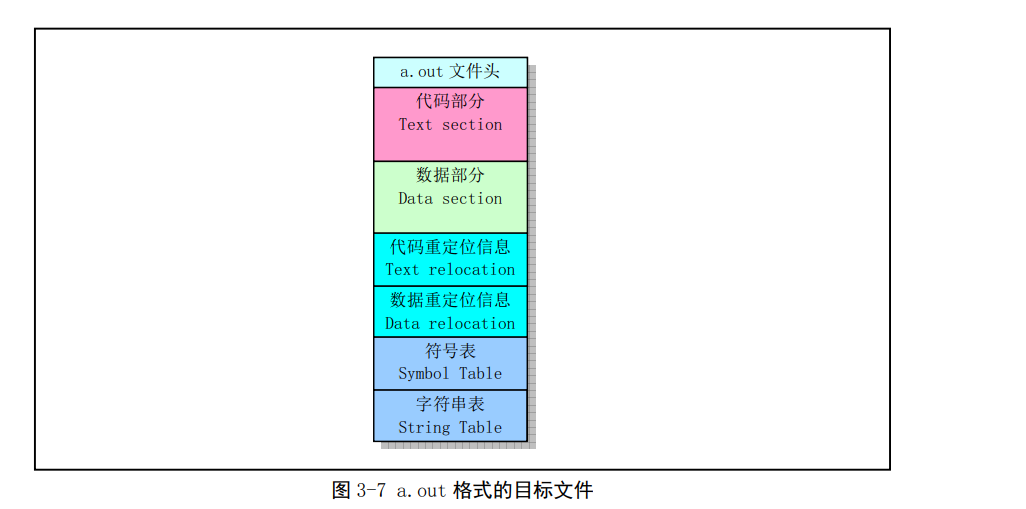
a.out格式7個區的基本定義和用途是:
- 執行標頭檔案(exec header)。執行檔案頭部分。該部分含有一些引數(exec結構),是有關目標檔案的整體結構資訊。例如程式碼和資料區的長度、未初始化資料區的長度、對應源程式檔名以及目標檔案建立時間等。核心使用這些引數把執行檔案載入到記憶體中並執行,而連結程式(ld)使用這些引數將一些模組檔案組合成一個可執行檔案。這是目標檔案唯一必要的組成部分。
- 程式碼區(text segment)。由編譯器或組合器生成的二進位制指令程式碼和資料資訊,含有程式執行時被載入到記憶體中的指令程式碼和相關資料。可以以唯讀形式被載入。
- 資料區(data segment)。由編譯器或組合器生成的二進位制指令程式碼和資料資訊,這些部分含有已經初始化過的資料,總是被載入到可讀寫的記憶體中。
- 程式碼重定位(text relocations)。這部分含有供連結程式使用的記錄資料。在組合目標模組檔案時用於定位程式碼段中的指標或地址。當連結程式需要改變目的碼的地址時就需要修正和維護這些地方。
- 資料重定位(data relocations)。類似於程式碼重定位部分的作用,但是用於資料段中指標的重定位。
- 符號表部分(sysmbol table)。這部分同樣含有供連結程式使用的記錄資料。這些資料儲存著模組檔案中定義的全域性符號以及需要從其它模組檔案中輸入的符號,或者由連結器定義的符號,用於在模組檔案之間對命名的變數和函數(符號)進行交叉參照。
- 字串表部分(string table)。該部分有與符號相對應的字串。用於偵錯程式偵錯目的碼,與連結過程無關。這些資訊可包含源程式程式碼和行號、區域性符號以及資料結構描述資訊等。
對於一個指定的目標檔案並非一定包含所有以上資訊。由於Linux0.11系統使用了IntelCPU的記憶體管理功能,因此它會為每個執行程式單獨分配一個64MB的地址空間(邏輯地址空間)使用。在這種情況下因為連結器已經把執行檔案處理成一個固定地址開始執行,所以相關的可執行檔案中就不再需要重定位資訊。
3.5.5System.map檔案
當執行GNU連結器gld(ld)時若使用了‘-M’選項,或者使用nm命令,則會在標準輸出裝置(通常是螢幕)上列印出連結映像(link map)資訊,即是指由連結程式產生的目標程式記憶體地址映像資訊。其中列出了程式段裝入到記憶體中的位置資訊。具體來講有如下資訊:
- 目標檔案及符號資訊對映到記憶體中的位置:
- 公共符號如何放置;
- 連結中包含的所有檔案成員及其參照的符號。
通常我們會把傳送到標準輸出裝置的連結映像資訊重定向到一個檔案中(例如System.map)。在編譯核心時,linux/Makefile檔案產生的System.map檔案就用於存放核心符號表資訊。符號表是所有核心符號及其對應地址的一個列表,當然包括上面說明的_etext、_edata和_end等符號的地址資訊。隨著每次核心的編譯,就會產生一個新的對應System.map檔案。當核心執行出錯時,通過System.map檔案中的符號表解析,就可以查到一個地址值對應的變數名,或反之。
利用System.map符號表檔案,在核心或相關程式出錯時,就可以獲得我們比較容易識別的資訊。符號表的樣例子如下所示:
c03441a0 B dmi_broken
c03441a4 B is_sony_vaio_laptop
c03441c0 b dmi_ident
c0344200 b pci_bios_present
c0344204 b pirq_table
3.6Make程式和Makefile檔案
Makefile(makefile)檔案是make工具程式的組態檔。Make工具程式的主要用途是能自動地決定一個含有很多源程式檔案的大型程式中哪個檔案需要被重新編譯。Makefile的使用比較複雜,這裡只是根據上面的Makefile檔案作簡單的介紹。
為了使用make程式,你就需要Makefile檔案來告訴make要做什麼工作。通常,Makefile檔案會告訴make如何編譯和連結一個檔案。當明確指出時,Makefile還可以告訴make執行各種命令(例如,作為清理操作而刪除某些檔案)。
make的執行過程分為兩個不同的階段。在第一個階段,它讀取所有的Makefile檔案以及包含的makefile檔案等,記錄所有的變數及其值、隱式的或顯示的規則,並構造出所有目標物件及其先決條件的一幅全景圖。在第二階段期間,make就使用這些內容結構來確定哪個目標物件需要被重建,並且使用相應的規則來操作。
當make重新編譯程式時,每個修改過的C程式碼檔案必須被重新編譯。如果一個標頭檔案被修改過了,那麼為了確保正確,每一個包含該標頭檔案的C程式碼程式都將被重新編譯。每次編譯操作都產生一個與源程式對應的目標檔案。最終,如果任何原始碼檔案被編譯過了,那麼所欲的目標檔案不管是剛編譯完的還是以前就編譯好的必須連線在一起以生成的可執行檔案檔案。
簡單的Makefile檔案含有一些規則,這些規則具有如下的形式:
目標(target)...:先決條件(prerequisites)...
命令(command)
....
....
其中'目標'物件通常是程式生成的一個檔案的名稱;例如是一個可執行檔案或目標檔案。目標也可以是所要採取活動的名字,比如‘清楚’‘(clean)’‘先決條件’是一個或多個檔名,是用作產生目標的輸入條件。通常一個目標依賴幾個檔案。而'命令'是make需要執行的操作。一個規則可以有多個命令,每一個命令自成一行。請注意,你需要在每個命令列之前鍵入一個製表符!這是粗心這常常忽略的地方。
如果一個先決條件通過目錄搜尋而在另外一個目錄中被找到,這並不會改變規則的命令;它們將被如期執行。因此,你必須小心地設定命令,使得命令能夠在make發現先決條件的目錄中找到需要的先決條件。這就需要通過使用自動變數來做到。自動變數是一種在命令列上根據情況能被自動替換的變數。自動變數的值是基於目標物件及其先決條件而在命令列執行前的設定。例如,’$^‘的值表示規則的所有先決條件,包含它們所處目錄的名稱;’$<‘的值表示規則中的第一個先決條件;’$@’表示目標物件;另外還有一些自動變數這裡就不提了。
有時,先決條件還常包含標頭檔案,而這些標頭檔案並不願在命令中說明。此時自動變數‘$<’正是一個先決條件。例如
foo.o:foo.c def.h hack.h
cc -c $(CFLAGS) $< -o $@
其中的'$<'就會被自動地替換成foo.c,$@則會被替換為foo.o
為了讓make能使用習慣用法來更新一個目標物件,你可以不指定命令,寫一個不帶命令的規則或者不寫規則。此時make程式將會根據源程式檔案的型別(程式的字尾)來判斷要使用哪個隱式規則。
字尾規則是為make程式定義隱式規則的老式方法(現在這種規則已經不用了,取而代之的是使用更通用更清晰的模式匹配規則)。下面規則就是一種雙字尾規則。雙字尾規則是用一對字尾定義的:源字尾和目標字尾。相應的隱式先決條件是通過使用檔名中的源字尾替換目標字尾後得到。因此,此時下面的‘$<’值是‘.c’檔名。而正條make規則的含義是將'.c'程式編譯成'*.s'程式碼。
.c.s:
$(CC)$(CFLAGS)\
-nostdinc -Iinclude -S -o $*.s $
通常命令是屬於一個具有先決條件的規則,並在任何先決條件改變時用於生成一個目標(target)檔案。然而,為目標而指定命令的也不一定要有先決條件。例如,與目標'clean'相關的含有刪除(delete)命令的規則並不需要有先決條件。此時,一個規則說明了如何以及何時來重新制作某些檔案,而這些檔案是特定規則的目標。make根據先決條件來執行命令以及建立或更新目標。一個規則也可以說明如何及何時執行一個操作。
一個Makefile檔案也可以含有除規則以外的其他文字,但是一個簡單的Makefile檔案只需要含有適當的規則。規則可能看上去要比上面示出的模板複雜得多,但基本上都是符合的。
Makefile檔案最後生成的依賴關係是用於讓make來確定是否需要重建一個目標物件。比如當某個標頭檔案被改動後,make就通過這些依賴關係,重新編譯與該標頭檔案相關的所有‘*.c’檔案。