我真的,AI框架的程式設計正規化怎麼理解?
我給領導彙報AI框架用函數語言程式設計好,沒講明白,說函數式就是寫函數那樣方便,都被領導吊飛了,啥玩意,寫啥不是寫函數,狗屁不通!
網上搜說用tensorflow那就是用宣告式程式設計,用pytorch就是指令式程式設計。有兄弟能講清楚,AI框架的程式設計正規化到底如何區分?AI框架中的不同程式設計正規化有什麼作用嗎?
框架程式設計正規化
程式設計正規化、程式設計範型、或程式設計法(Programming paradigm),是指軟體工程中的一類典型的程式設計風格。常見的程式設計範型有:函數語言程式設計、指令式程式設計、宣告式程式設計、物件導向程式設計等等,程式設計正規化提供並決定了開發者對程式執行的看法。在開發者使用 AI 框架進行程式設計的過程中,主要使用到的程式設計正規化主要有2種:1)宣告式程式設計與2)指令式程式設計。

本節將會深入展開和介紹兩種不同的程式設計正規化對AI框架整體架構設計的影響,以及目前主流的 AI 框架在程式設計正規化之間的差異。
程式開發的程式設計正規化
- 指令式程式設計(Imperative):詳細的命令機器怎麼(How)去處理一件事情以達到想要的結果
- 宣告式程式設計(Declarative):只告訴想要的結果(What),機器自己摸索執行過程(How)
程式設計與程式設計正規化
程式設計是開發者編定程式的中文簡稱,就是讓計算機程式碼解決某個問題,對某個計算體系規定一定的運算方式,使計算體系按照該計算方式執行,並最終得到相應結果的過程。
為了使計算機能夠理解人的意圖,我們就必須將需解決的問題的思路、方法和手段通過計算機能夠理解的形式告訴計算機,使得計算機能夠根據人的指令一步一步去工作,完成某種特定的任務。這種人和計算體系之間交流的過程稱為程式設計。
指令式程式設計
指令式程式設計(Imperative programming)是一種描述計算機所需作出的行為的程式設計典範,幾乎所有計算機的硬體工作都是命令式的。
其步驟可以分解為:首先,必須將帶解決問題的解決方案抽象為一系列概念化的步驟。然後通過程式設計的方法將這些步驟轉化成程式指令集(演演算法),而這些指令按照一定的順序排列,用來說明如何執行一個任務或解決一個問題。這意味著,開發者必須要知道程式要完成什麼,並且告訴計算機如何進行所需的計算工作,包括每個細節操作。簡而言之,就是把計算機看成一個善始善終服從命令的裝置。
所以在指令式程式設計中,把待解問題規範化、抽象為某種演演算法是解決問題的關鍵步驟。其次,才是編寫具體演演算法和完成相應的演演算法實現問題的正確解決。
目前開發者接觸到的指令式程式設計主要以硬體控制程式、執行指令為主。AI 框架中 PyTorch 則主要使用了指令式程式設計的方式。
下面的程式碼實現一個簡單的宣告式程式設計的過程:建立一個儲存結果的集合變數 results,並遍歷數位集合 collection,判斷每個數位大於 5 則新增到結果集合變數 results 中。上述過程需要告訴計算機每一步如何執行。
results = []
def fun(collection):
for num in collection:
if num > 5:
results.append(num)宣告式程式設計
宣告式程式設計(Declarative programming)是一種程式設計正規化,與指令式程式設計相對立。它描述目標的性質,讓計算機明白目標,而非流程。宣告式程式設計不用告訴計算機問題領域,從而避免隨之而來的副作用。而指令式程式設計則需要用演演算法來明確的指出每一步該怎麼做。
副作用:在電腦科學中,函數副作用(Side Effects)指當呼叫函數時,除了返回可能的函數值之外,還對主呼叫函數產生附加的影響。例如修改全域性變數(函數外的變數),修改引數,向主調方的終端、管道輸出字元或改變外部儲存資訊等。
宣告式程式設計透過函數、推論規則或項重寫(term-rewriting)規則,來描述變數之間的關係。它的語言執行器(編譯器或直譯器)採用了一個固定的演演算法,以從這些關係產生結果。
目前開發者接觸到的宣告式程式語言主要有:括資料庫查詢語言(SQL,XQuery),正規表示式,邏輯程式設計,函數語言程式設計等。在AI框架領域中以 TensorFlow1.X 為代表,就使用了宣告式程式設計。
以常用資料庫查詢語言 SQL 為例,其屬於較為明顯的一種宣告式程式設計的例子,其不需要建立變數用來儲存資料,告訴計算機需要查詢的目標即可:
>>> SELECT * FROM collection WHERE num > 5函數語言程式設計
函數語言程式設計(Functional Programming)函數語言程式設計本質上也是一種程式設計正規化,其在軟體開發的工程中避免使用共用狀態(Shared State)、可變狀態(Mutable Data)以及副作用。即將計算機運算視為函數運算,並且避免使用程式狀態以及易變物件,理論上函數語言程式設計是宣告式的,因為它不使用可變狀態,也不需要指定任何的執行順序關係。
其核心是隻使用純粹的數學函數程式設計,函數的結果僅取決於引數,而沒有副作用,就像 I/O 或者狀態轉換。程式通過組合函數(function composition)的方法構建。整個應用由資料驅動,應用的狀態在不同純函數之間流動。與指令式程式設計的物件導向程式設計而言,函數語言程式設計其更偏向於宣告式程式設計,程式碼更加簡潔明瞭、更可預測,並且可測試性也更好。因此實際上可以歸類為屬於宣告式程式設計的其中一種特殊範型。
函數語言程式設計最重要的特點是「函數第一位」(First Class),即函數可以出現在任何地方,比如可以把函數作為引數傳遞給另一個函數,不僅如此你還可以將函數作為返回值。以 Python 程式碼為例:
def fun_add(a, b, c):
return a + b + c
def fun_outer(fun_add, *args, **kwargs):
print(fun_add(*args, **kwargs))
def fun_innter(*args):
return args
if __name__ == '__main__':
fun_outer(fun_innter, 1, 2, 3)AI框架的程式設計正規化
主流AI框架,無論PyTorch還是Tensorflow都使用都以Python為主的高層次語言為前端,提供指令碼式的程式設計體驗,後端用更低層次的程式設計模型和程式語言開發。後端高效能可複用模組與前端深度繫結,通過前端驅動後端方式執行。AI框架為前端使用者提供宣告式(declarative programming)和命令式(imperative programming)兩種程式設計正規化。
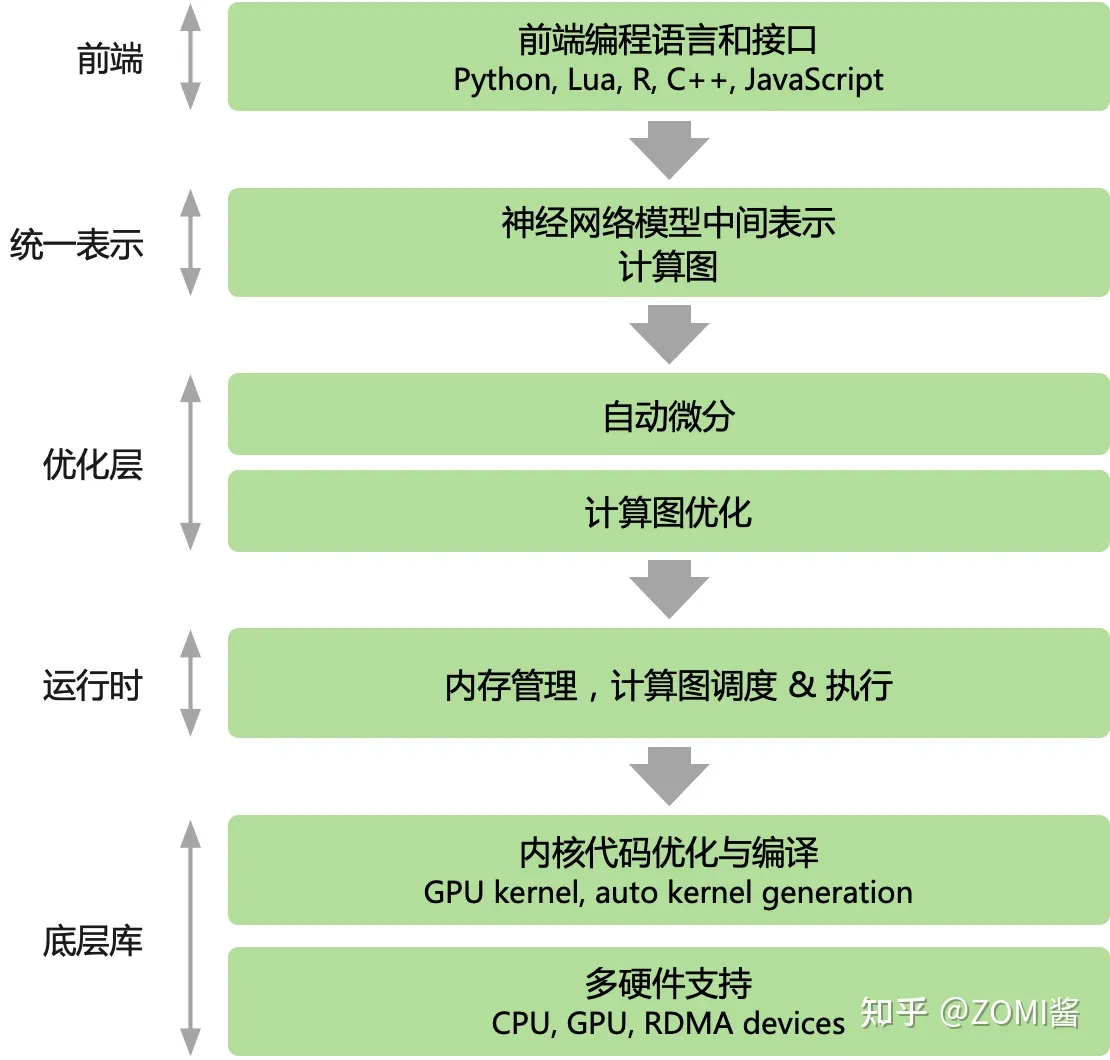
在主流的 AI 框架中,TensorFlow 提供了宣告式程式設計體驗,PyTroch 提供了命令式的程式設計體驗。但兩種程式設計模型之間並不存在絕對的邊界,multi-stage 程式設計和及時編譯(Just-in-time, JIT)技術能夠實現兩種程式設計模式的混合。隨著 AI 框架引入更多的程式設計模式和特性,例如 TensorFlow Eager模式 和 PyTorch JIT 的加入,主流 AI 框架都選擇了通過支援混合式程式設計以兼顧兩者的優點。
指令式程式設計
在指令式程式設計模型下,前端 Python 語言直接驅動後端運算元執行,使用者表示式會立即被求值,又被稱作define-by-run。開發者編寫好神經網路模型的每一層,並編寫訓練過程中的每一輪迭代需要執行的計算任務。在程式執行的時候,系統會根據 Python 語言的動態解析性,每解析一行程式碼執行一個具體的計算任務,因此稱為動態計算圖(動態圖)。
指令式程式設計的優點是方便偵錯,靈活性高,但由於在執行前缺少對演演算法的統一描述,也失去了編譯期優化的機會。
相比之下,指令式程式設計對資料和控制流的靜態性限制很弱,方便偵錯,靈活度極高。缺點在於,網路模型程式在執行之前沒有辦法獲得整個計算圖的完整描述,從而缺乏缺乏在編譯期的各種優化手段。
以 PyTorch 其程式設計特點為即時執行,它屬於一種宣告式的程式設計風格。下面使用 PyTorch 實現一個簡單的2層神經網路模型並訓練:
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
import torch
import torch.nn as nn
import torch.optim as optim
# 匯入資料
data = pd.read_csv('mnist.csv')
X = data.iloc[:, 1:].values
y = data.iloc[:, 0].values
# 分割資料集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# 將資料轉換為張量
X_train = torch.tensor(X_train, dtype=torch.float)
X_test = torch.tensor(X_test, dtype=torch.float)
y_train = torch.tensor(y_train, dtype=torch.long)
y_test = torch.tensor(y_test, dtype=torch.long)
# 定義模型
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(784, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.fc1(x)
x = self.fc2(x)
return x
model = Net()
# 定義損失函數和優化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters())
# 訓練模型
for epoch in range(5):
# 將模型設為訓練模式
model.train()
# 計算模型輸出
logits = model(X_train)
loss = criterion(logits, y_train)宣告式程式設計
在宣告式程式設計模型下,前端語言中的表示式不直接執行,而是構建起一個完整前向計算過程表示,對資料流圖經過優化然後再執行,又被稱作define-and-run。即開發者定義好整體神經網路模型的前向表示程式碼,因為整體定義好神經網路模型,因此在 AI 框架的後端會把網路模型編譯成 靜態計算圖(簡稱:靜態圖) 來執行。
執行方式比較直接:前端開發者寫的 Python 語言中的表示式不直接執行;首先會利用 AI 框架提供的 API 定義介面構建一個完整前向計算過程表示。最後對數計算圖經過優化然後再執行。
AI 框架採用宣告式程式設計的優點在於:
- 執行之前得到整個程式(整個神經網路模型)
- 在真正執行深度學習之前能夠執行編譯優化演演算法
- 能夠實現極致的效能優化
缺點也較為明顯:
- 資料型別和控制流受到 AI 框架中的 API 對神經網路有限定義而約束
- 因為神經網路的獨特性需要 AI 框架預定義對應的概念(DSL),造成不方便偵錯、靈活性低
以 Google 的 TensorFlow1.X 為代表的程式設計特點包括:計算圖(Computational Graphs)、對談(Session)、張量(Tensor),其作為一種典型宣告式程式設計風格。下面使用 TensorFlow 實現一個隱層的全連線神經網路,優化的目標函數是預測值和真實值的歐氏距離。該實現使用基本的 Tensorflow 操作來構建一個計算圖,然後多次執行這個計算圖來訓練網路。
import tensorflow as tf
import numpy as np
# 首先構建計算圖
# N是batch大小;D_in是輸入大小。
# H是隱單元個數;D_out是輸出大小。
N, D_in, H, D_out = 64, 1000, 100, 10
# 輸入和輸出是placeholder,在用session執行graph的時候
# 我們會feed進去一個batch的訓練資料。
x = tf.placeholder(tf.float32, shape=(None, D_in))
y = tf.placeholder(tf.float32, shape=(None, D_out))
# 建立變數,並且隨機初始化。
# 在Tensorflow裡,變數的生命週期是整個session,因此適合用它來儲存模型的引數。
w1 = tf.Variable(tf.random_normal((D_in, H)))
w2 = tf.Variable(tf.random_normal((H, D_out)))接著為Forward階段,計算模型的預測值y_pred。注意和PyTorch不同,這裡不會執行任何計算,而只是定義了計算,後面用session.run的時候才會真正的執行計算。
h = tf.matmul(x, w1)
h_relu = tf.maximum(h, tf.zeros(1))
y_pred = tf.matmul(h_relu, w2)
# 計算loss
loss = tf.reduce_sum((y - y_pred) ** 2.0)
# 計算梯度
grad_w1, grad_w2 = tf.gradients(loss, [w1, w2])使用梯度下降來更新引數。assign同樣也只是定義更新引數的操作,不會真正的執行。在Tensorflow裡,更新操作是計算圖的一部分,而在PyTorch裡,因為是動態的」實時「的計算,所以引數的更新只是普通的Tensor計算,不屬於計算圖的一部分。
learning_rate = 1e-6
new_w1 = w1.assign(w1 - learning_rate * grad_w1)
new_w2 = w2.assign(w2 - learning_rate * grad_w2)
# 計算圖構建好了之後,我們需要建立一個session來執行計算圖。
with tf.Session() as sess:
# 首先需要用session初始化變數
sess.run(tf.global_variables_initializer())
# 建立隨機訓練資料
x_value = np.random.randn(N, D_in)
y_value = np.random.randn(N, D_out)
for _ in range(500):
# 用session多次的執行計算圖。每次feed進去不同的資料。
# 這裡是模擬的,實際應該每次feed一個batch的資料。
# run的第一個引數是需要執行的計算圖的節點,它依賴的節點也會自動執行,
# 因此我們不需要手動執行forward的計算。
# run返回這些節點執行後的值,並且返回的是numpy array
loss_value, _, _ = sess.run([loss, new_w1, new_w2],
feed_dict={x: x_value, y: y_value})
print(loss_value)函數語言程式設計
不管是JAX 還是 MindSpore 都使用了函數語言程式設計的正規化,其在高效能運算、科學計算、分散式方面有著獨特的優勢。
其中 JAX 是作為 GPU/TPU 的高效能平行計算的框架,與普通 AI 框架相比其核心是對神經網路計算和數值計算的融合,介面上相容 NumPy、Scipy 等 Python 原生資料科學庫,在此基礎上擴充套件分散式、向量化、高階求導、硬體加速,其程式設計風格採用了函數語言程式設計,主要體現在無副作用、Lambda閉包等。而華為推出的 MindSpore 框架,其函數式可微分程式設計架構,可以讓使用者聚焦機器學習模型數學的原生表達。
本節總結
- 本節回顧了深度學習在不同AI框架的不同程式設計方式
- 瞭解了什麼是宣告式程式設計和指令式程式設計以及其具體區別
- 猜測未來以指令式程式設計提升易用性為主,結合宣告式程式設計的優化方式相融合