一步一圖帶你構建 Linux 頁表體系 —— 詳解虛擬記憶體如何與實體記憶體進行對映
筆者之前在自己的專欄《聊聊 Linux 核心》 裡通過大量的篇幅寫了一個系列關於記憶體管理相關的文章,在這個系列文章中,筆者分別通過虛擬記憶體管理和實體記憶體管理兩個角度算是把 Linux 記憶體管理子系統的全貌給大家呈現了出來。
但之前的文章都是以專題的形式給大家呈現,採用一種靜態的方式來專項闡述虛擬記憶體管理和實體記憶體管理,而且內容龐大,知識點密集。所以筆者這次想讓虛擬記憶體和實體記憶體兩者一起動態聯動起來,在這個聯動的過程中將之前的這些靜態知識點統統串聯起來,形成一條記憶體管理的主線。方便大家日後可以拎著這條主線,串聯回顧記憶體管理這些龐大且繁雜的內容。
經過《深入理解 Linux 虛擬記憶體管理》 一文的介紹我們知道,虛擬記憶體其實是 CPU 和作業系統使用的一個障眼法,聯手給程序編織了一個假象,讓程序誤以為自己獨佔了全部的記憶體空間:
- 在 32 位系統中,程序以為自己獨佔了 3G 的記憶體空間。
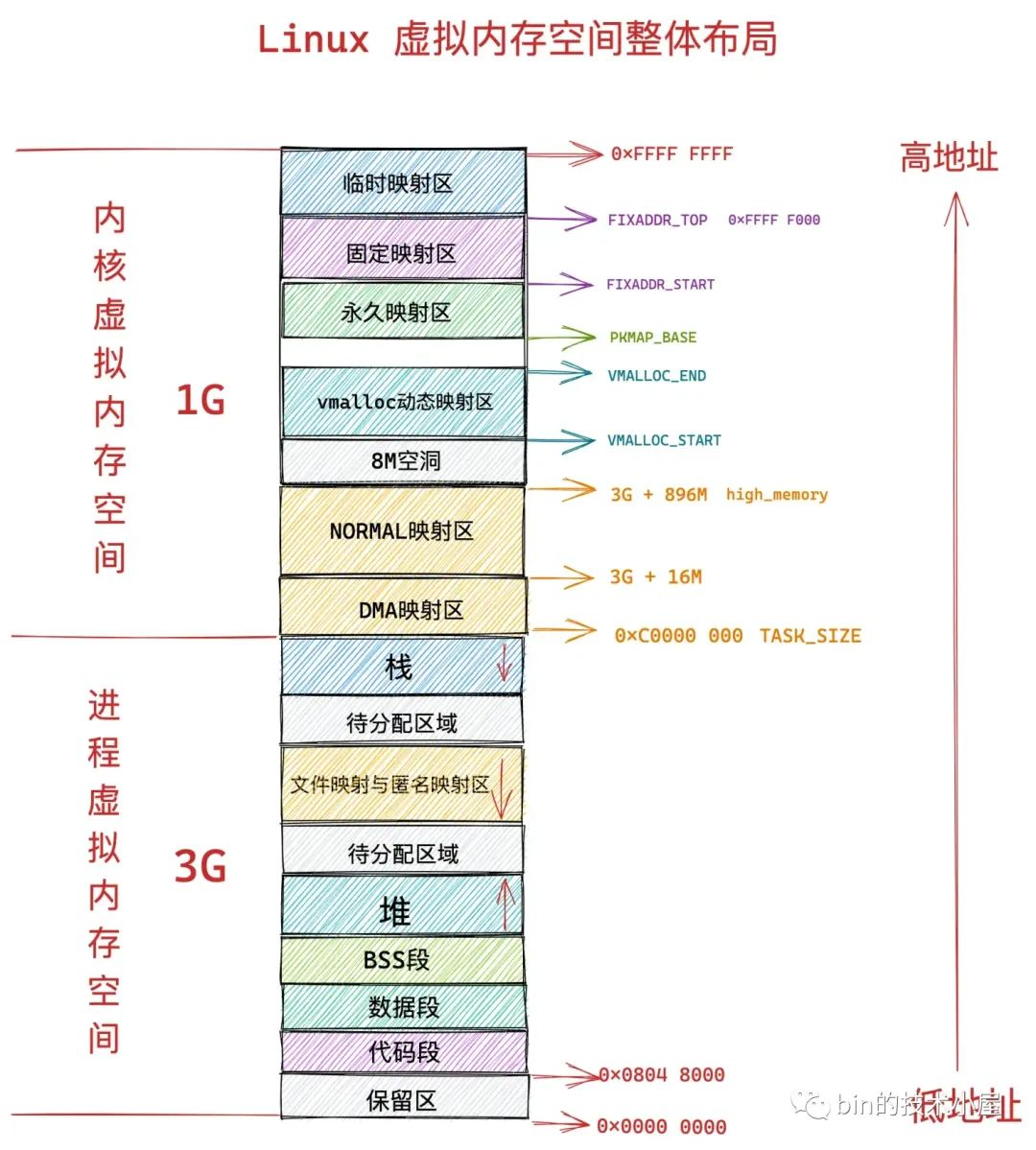
- 在 64 位系統中,程序以為自己獨佔了 128T 的記憶體空間。
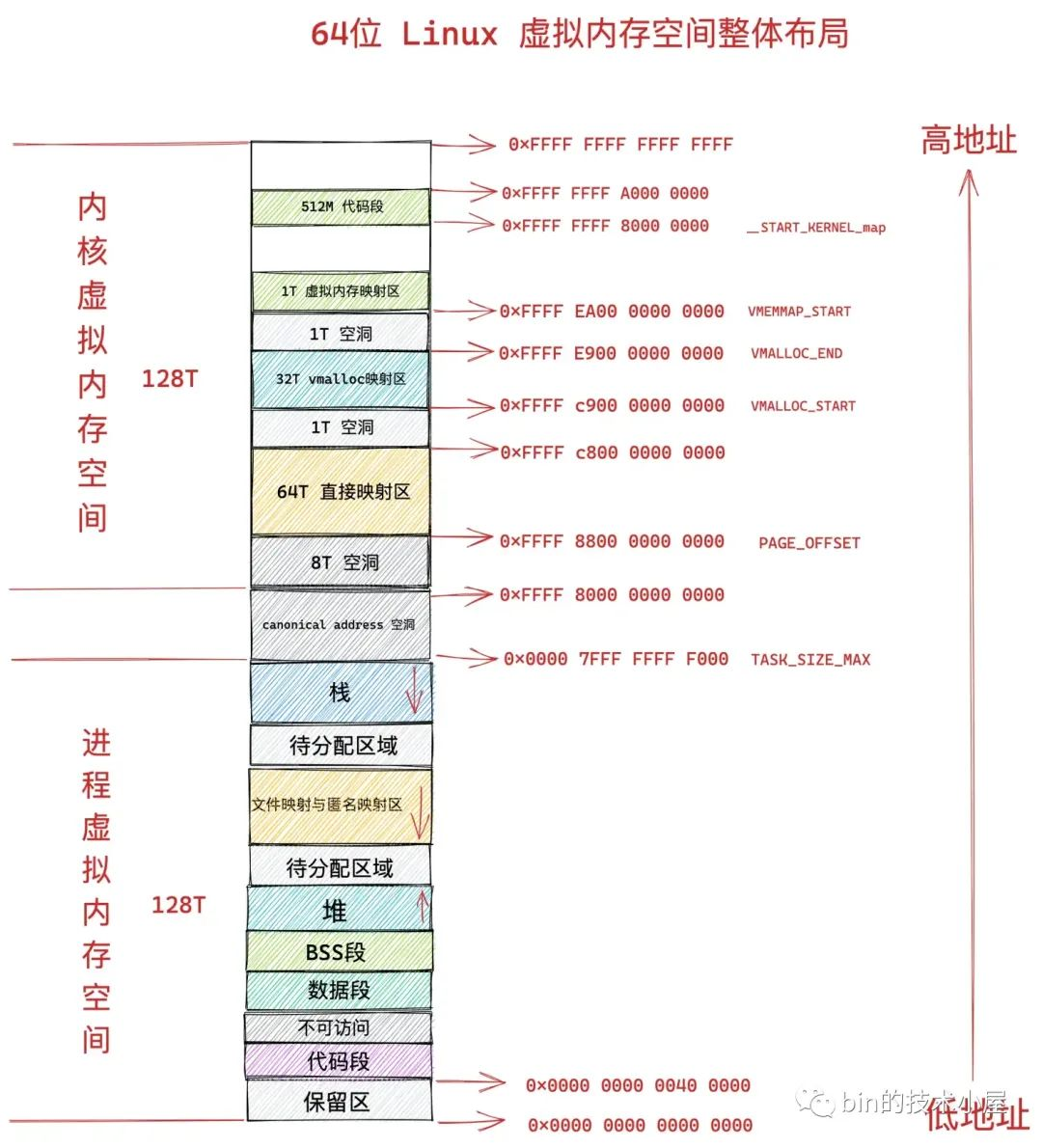
這麼做的好處是,作業系統為每個程序營造出一片獨立的虛擬地址空間,使得程序與程序之間相互隔離,互不干擾的,解決了多程序同時執行時產生的記憶體地址衝突問題。
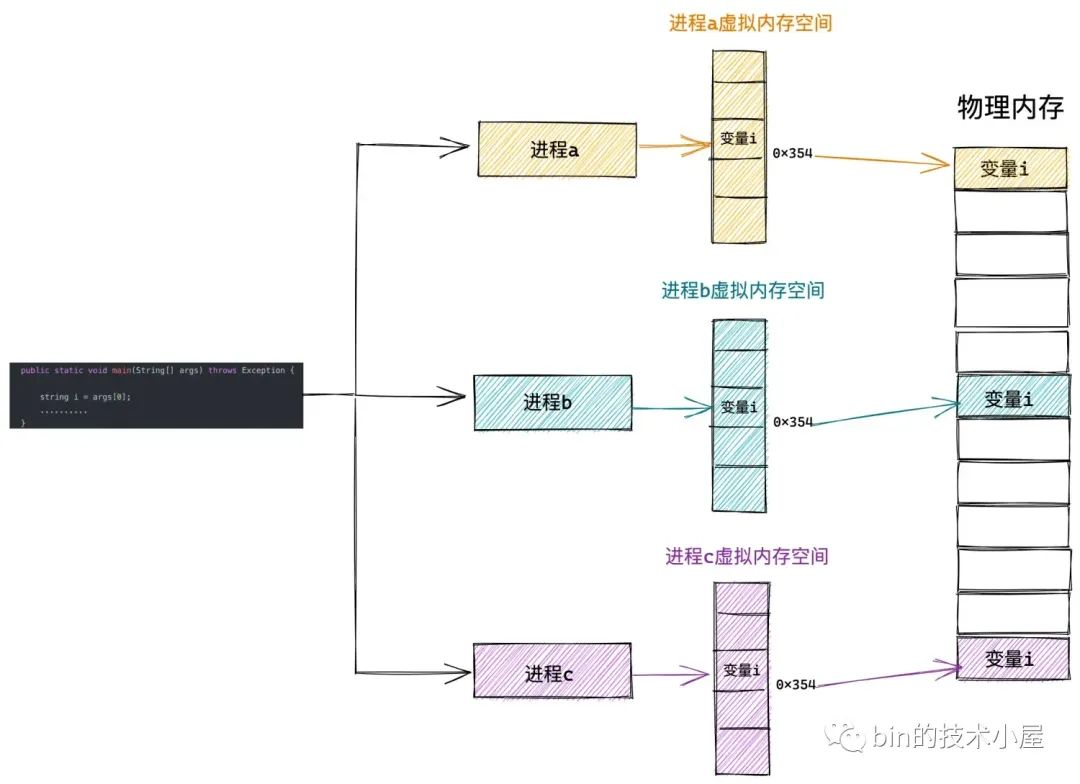
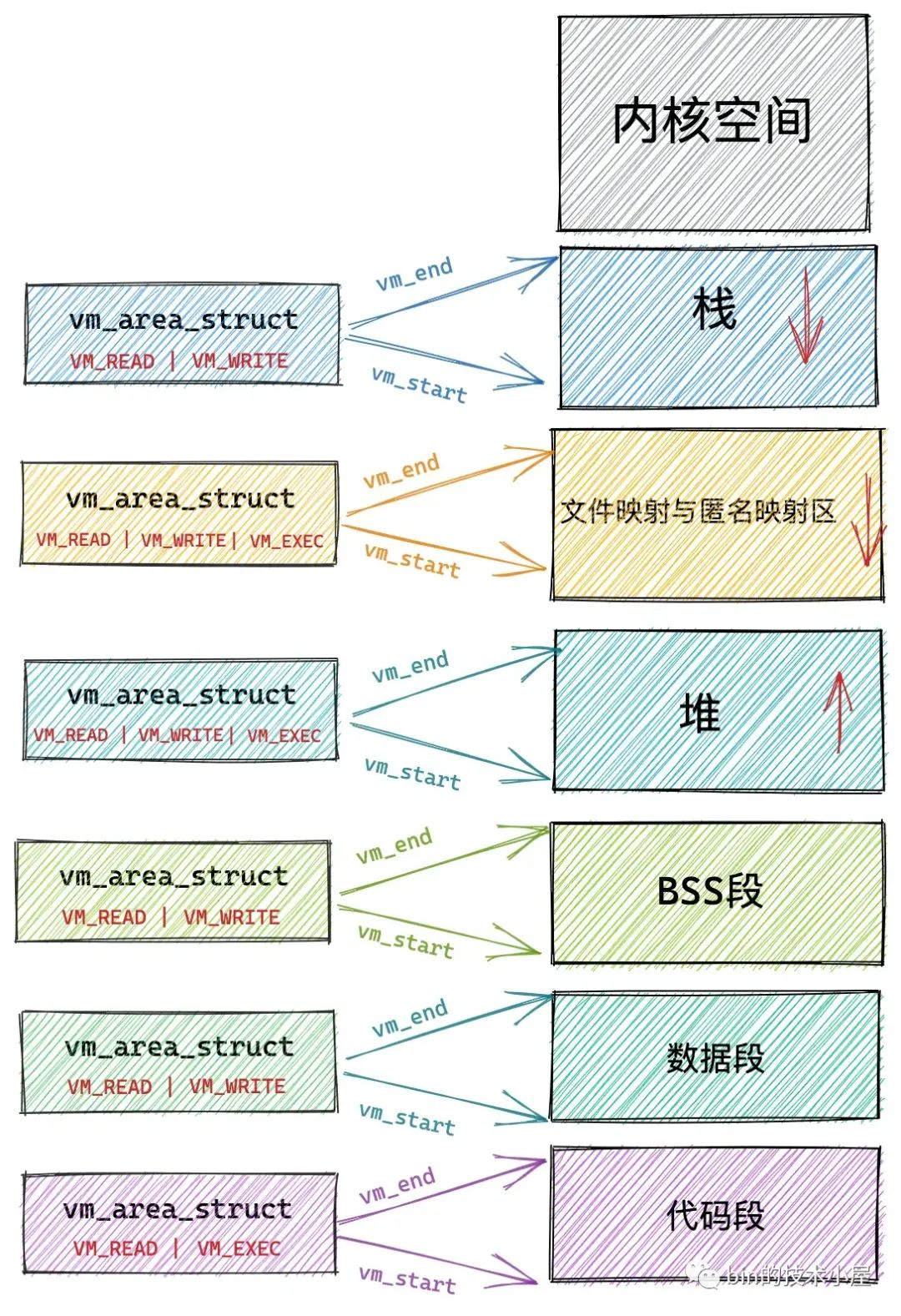
同時虛擬記憶體還提供了系統安全方面的保障,會對程序存取記憶體的行為進行相關的安全許可權檢查,保障了系統的穩定性和安全性。比如:
-
有些實體記憶體頁只允許核心來存取,程序在使用者態的時候是無法存取的。
-
虛擬記憶體中儲存了存取其對映的實體記憶體相關的許可權,程序只能執行規定許可權範圍內的訪存操作。比如,上面虛擬記憶體空間里程式碼段的許可權是可讀,可執行,但是不可寫。資料段具有可讀可寫的許可權但是不可執行。堆則具有可讀可寫,可執行的許可權(Java 中的位元組碼儲存在堆中,所以需要可執行許可權),棧一般是可讀可寫的許可權,一般很少有可執行許可權。而檔案對映與匿名對映區存放了共用連結庫,所以也需要可執行的許可權。
但是當程式執行起來之後,程式中所需要的資料本質上還是儲存在實體記憶體中的,無論作業系統對虛擬記憶體設計的多麼精彩,最終虛擬記憶體空間中每一個虛擬記憶體地址都是要對映到實體記憶體空間的中某一個特定實體記憶體地址上的。
程序虛擬記憶體空間中的每一個位元組都有與其對應的虛擬記憶體地址,同樣實體記憶體空間中每一個位元組都有與其對應的實體記憶體地址。
下面我們就來把舞臺上的桌布拿走,一起到核心中探祕一下 CPU 和作業系統聯手編織的這個障眼戲法是如何玩轉起來的~~~~
1. 虛擬記憶體如何與實體記憶體對映起來
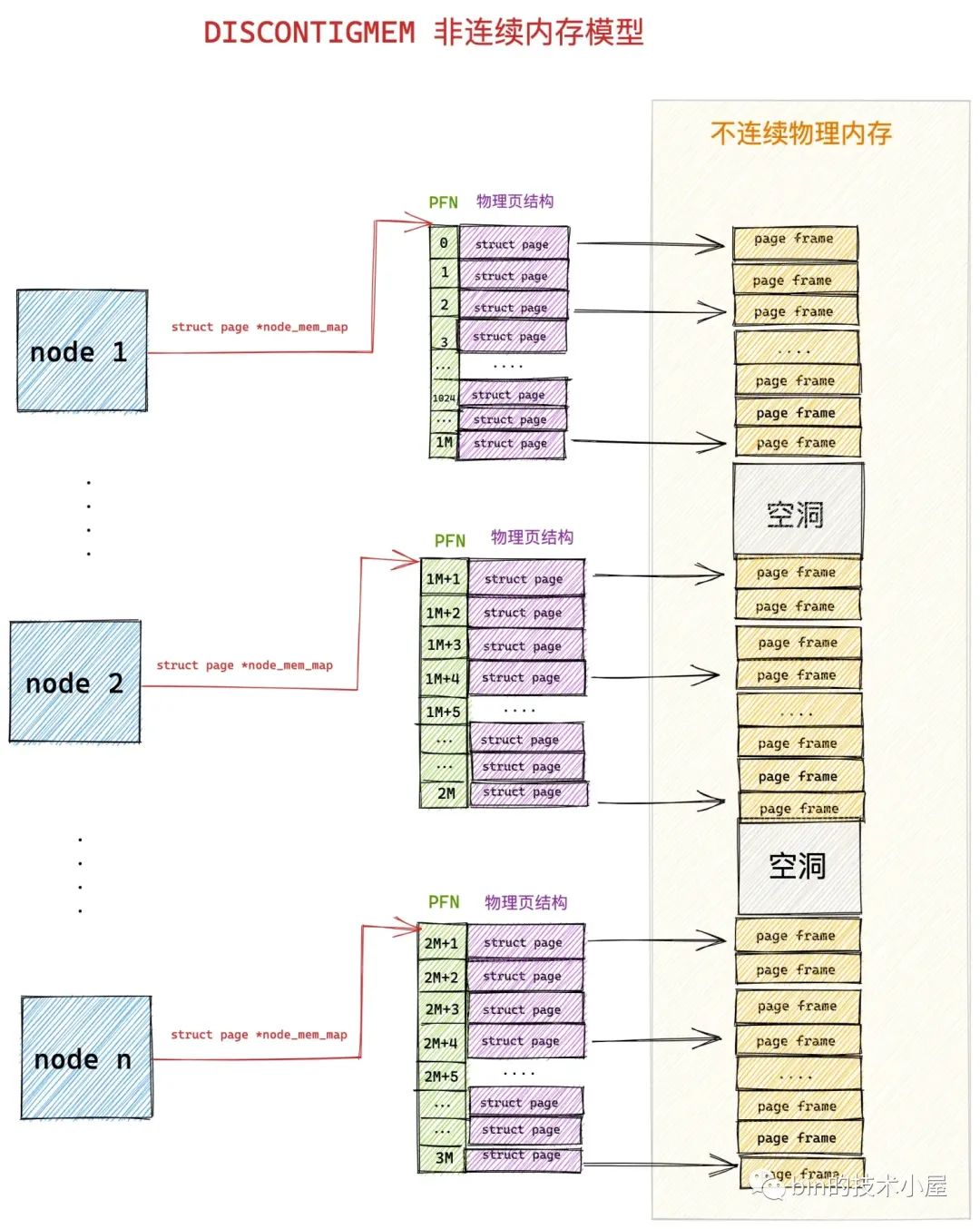
在 《深入理解 Linux 實體記憶體管理》一文中,筆者在介紹實體記憶體管理的時候曾提到,核心會將整個實體記憶體空間劃分為一頁一頁大小相同的的記憶體塊,每個記憶體塊大小為 4K,稱為一個實體記憶體頁。
一頁大小的記憶體塊在核心中用 struct page 結構體來進行管理,struct page 中封裝了每頁記憶體塊的狀態資訊,比如:組織結構,使用資訊,統計資訊,以及與其他核心結構的關聯對映資訊等。
核心會為每個實體記憶體頁 page 進行統一編號。這個編號稱之為 PFN(Page Frame Number),PFN 與 struct page 是一一對應的關係並且全域性唯一。
然後核心會將劃分出來的這些一頁一頁的記憶體塊統一組織在一個全域性陣列 mem_map 中管理。後續虛擬記憶體與實體記憶體的對映以及排程均是以頁為單位進行的。
typedef struct pglist_data {
// NUMA 節點id
int node_id;
// 指向 NUMA 節點內管理所有物理頁 page 的陣列
struct page *node_mem_map;
}
既然實體記憶體是以頁為單位進行管理,而虛擬記憶體最終是要對映到實體記憶體上的,所以在虛擬記憶體空間中也有與之相對應的虛擬頁這個概念,記憶體的對映是以頁為單位進行的。
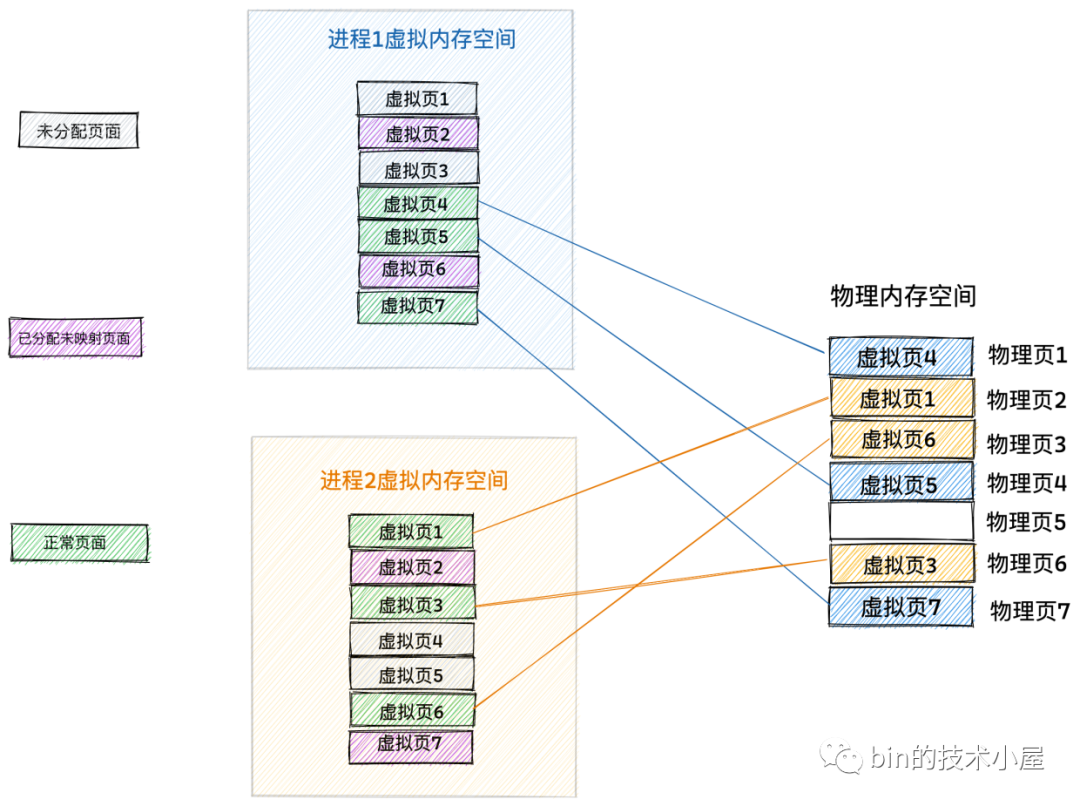
如上圖所示,在記憶體對映的場景中,虛擬記憶體頁的型別總共分為以下三種:
-
第一種就是圖中灰色方框裡標註的未分配頁面,程序的虛擬記憶體空間是非常龐大的,遠遠的超過實體記憶體空間,但這並不意味著程序可以直接隨意使用虛擬記憶體,事實上程序對虛擬記憶體的使用也是需要向核心申請的。程序虛擬記憶體空間中的虛擬記憶體頁在未被程序申請之前的狀態就是未分配頁面。
-
第二種就是圖中紫色方框裡標註的已分配未對映頁面,我們在程序中可以通過動態連結庫 glic 中的 malloc 介面或者直接通過系統呼叫 mmap 向核心申請虛擬記憶體,申請到的虛擬記憶體頁此時就變為了已分配的頁面。但此時的虛擬記憶體頁只是虛擬記憶體,其背後並沒有與實體記憶體對映起來,所以稱為已分配未對映頁面。
-
第三種是圖中綠色方框裡標註的正常頁面,當程序開始讀寫這些已分配未對映的虛擬記憶體頁時,在 CPU 中用於地址翻譯的硬體 MMU 會產生一個缺頁中斷,隨後核心會為其分配相應的實體記憶體頁面,並將虛擬記憶體頁與實體記憶體頁對映起來。此時這些已分配未對映的虛擬記憶體頁就變為了正常頁面。從此以後,程序就可以正常讀寫這些虛擬記憶體頁了。
MMU 負責將虛擬記憶體地址翻譯為實體記憶體地址,筆者後面會詳細介紹這個地址翻譯過程。
明白了這些之後,我們再來看上面這副記憶體對映圖,從圖中我們可以讀出以下幾種資訊:
-
每個程序獨佔全部的虛擬記憶體空間,比如上圖中,程序 1 的虛擬記憶體空間(藍色部分)和程序 2 的虛擬記憶體空間(黃色部分)它們都擁有屬於各自的虛擬記憶體頁1 到虛擬記憶體頁 7 這段範圍的虛擬記憶體。也就是說程序1 和程序 2 看到的虛擬記憶體空間地址範圍都是一樣的。
-
每個程序的虛擬記憶體空間都是相互隔離,互不干擾的,程序可以在屬於自己的虛擬記憶體空間裡隨意折騰。比如上圖中,程序 1 裡的虛擬記憶體頁 1 是一個未分配頁面,而程序 2 裡的虛擬記憶體頁 1 卻是一個正常頁面,被核心對映到實體記憶體頁 2 中。也就是說雖然每個程序擁有的虛擬記憶體地址空間範圍是一樣的,但是各自虛擬記憶體空間中的虛擬頁可能對映的物理頁不一樣,使用的方式和用途也不一樣。
-
程序所看到的連續虛擬記憶體,在實體記憶體中有可能是不連續的,比如上圖中,程序 1 裡的虛擬頁 4 和 虛擬頁 5,它們在程序 1 的虛擬記憶體空間中是連續的,但是它們背後對映的實體記憶體頁卻是不連續的。虛擬記憶體頁 4 被對映到了實體記憶體頁 1 中,虛擬記憶體頁 5 被對映到了實體記憶體頁 4 中。
-
實體記憶體空間中藍色部分是程序 1 正在使用的記憶體(物理頁 1,物理頁 4,物理頁 7),黃色部分是程序 2 正在使用的記憶體(物理頁 2,物理頁 3,物理頁 6)。這些複雜且瑣碎的記憶體對映細節統統由記憶體管理子系統進行管理,從而極大的解放了程式設計師的心智負擔。
現在讓我們把視角從程序的虛擬記憶體空間切換到核心中的記憶體管理系統中,來看一下核心是如何管理這些記憶體對映關係的。
談到對映,我們自然會想到 Map 這個資料結構,那麼虛擬記憶體與實體記憶體之間的對映關係如果用 Map 來表達的話,就是如下形式:
Map<虛擬記憶體,實體記憶體>
如果我們給上面那副圖加上 Map 對映關係的話,就演變成了這樣:
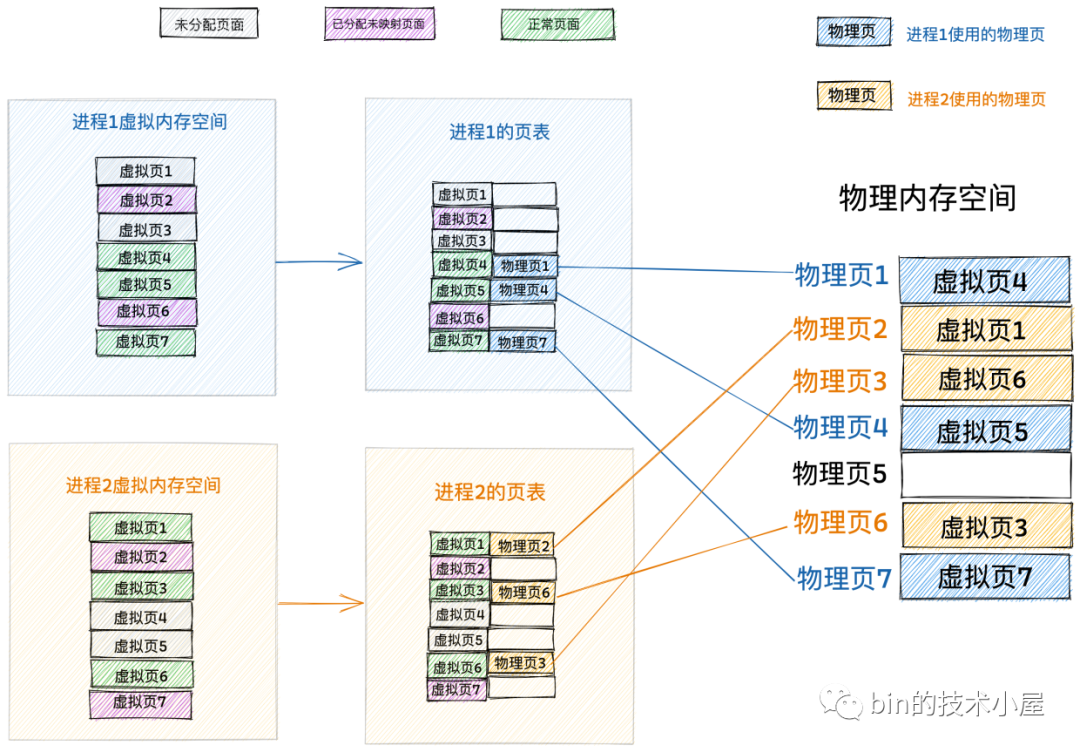
Map<虛擬記憶體,實體記憶體> 的對映關係在核心中是被一個叫做頁表的東西來管理的,頁表除了管理虛擬記憶體與實體記憶體之間的對映關係之外,還會有一些存取許可權的管理,來控制程序對實體記憶體的存取許可權。
由於程序是獨佔虛擬記憶體空間的,而且不同程序之間的虛擬記憶體空間是相互隔離的,所以每個程序也都會有屬於自己的頁表,來專門管理各自虛擬記憶體空間中的對映關係以及各自存取實體記憶體的許可權。
好了,現在我們已經大概清楚了虛擬記憶體與實體記憶體對映的一個總體框架了,當我們有了一個全域性視角之後,下面我們就來深入到細節中,來看看核心究竟如何通過一張頁表來管理這些記憶體對映關係以及存取許可權的。
2. 核心如何通過頁表來管理記憶體對映關係
我們都知道核心對實體記憶體的管理是按照頁為基本單位進行的,程序執行起來所需要的資料也是儲存在一個一個的物理頁中,既然實體記憶體頁可以儲存程序的普通資料,那麼它也一定可以儲存程序虛擬記憶體與實體記憶體之間的對映關係。
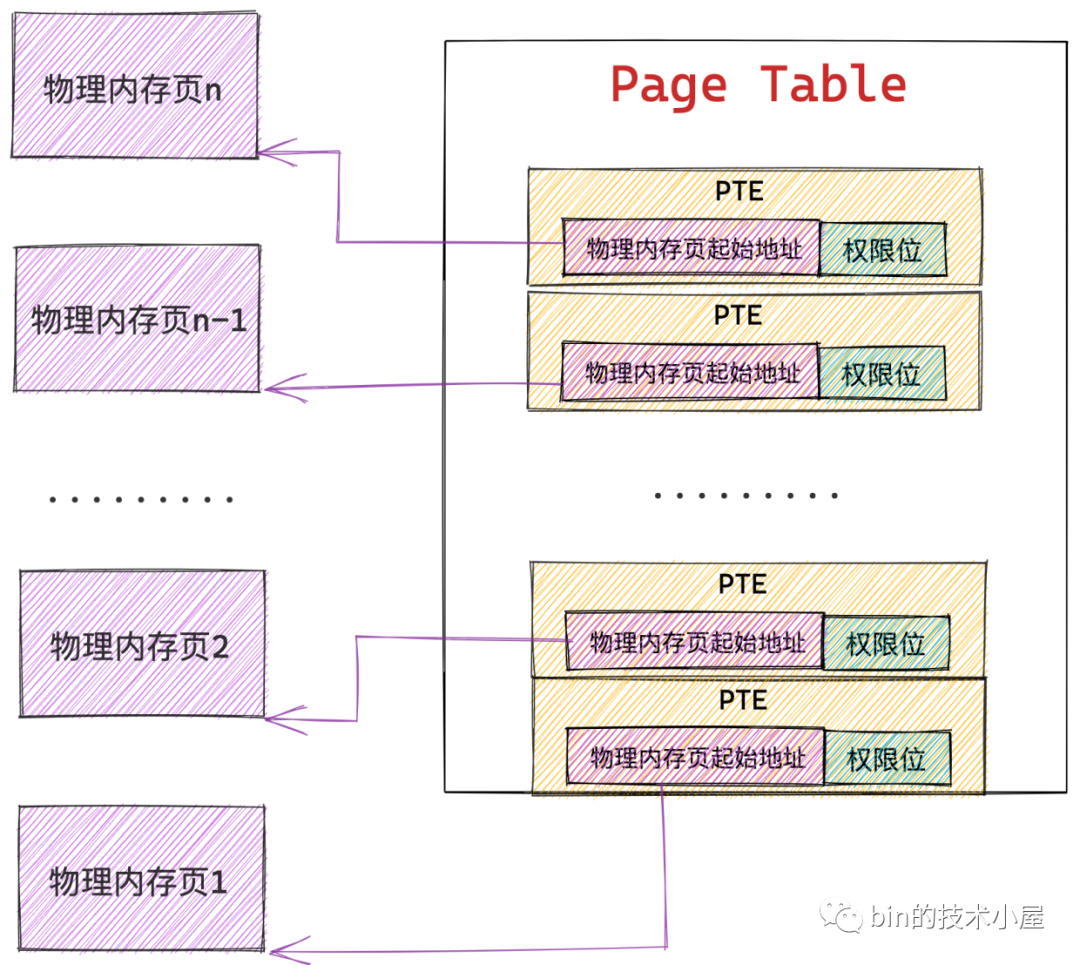
事實上,核心也是這麼幹的,核心會從實體記憶體空間中拿出一個實體記憶體頁來專門儲存程序裡的這些記憶體對映關係,而這種實體記憶體頁我們將其稱之為頁表,從這裡可以看出頁表的本質其實就是一個實體記憶體頁。
而核心會在頁表中劃分出來一個個大小相等的小記憶體塊,這些小記憶體塊我們稱之為頁表項 PTE(Page Table Entry),正是這個 PTE 儲存了程序虛擬記憶體空間中的虛擬頁與實體記憶體頁的對映關係,以及控制實體記憶體存取的相關許可權位。
在 32 位系統中頁表中的 PTE 佔用 4 個位元組,64 位系統中頁表的 PTE 佔用 8 個位元組。
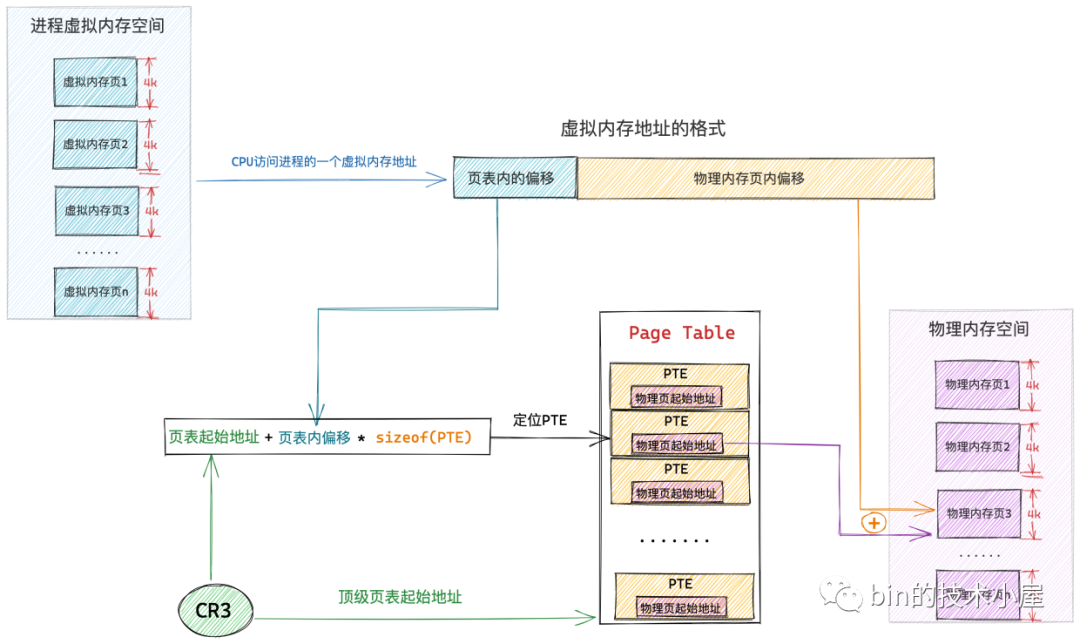
因為記憶體對映的粒度是按照頁為單位進行的,所以程序虛擬記憶體空間中的每個虛擬頁在頁表中都會有一個 PTE 與之對應,而虛擬頁背後對映的實體記憶體頁的起始地址就儲存在 PTE 中。
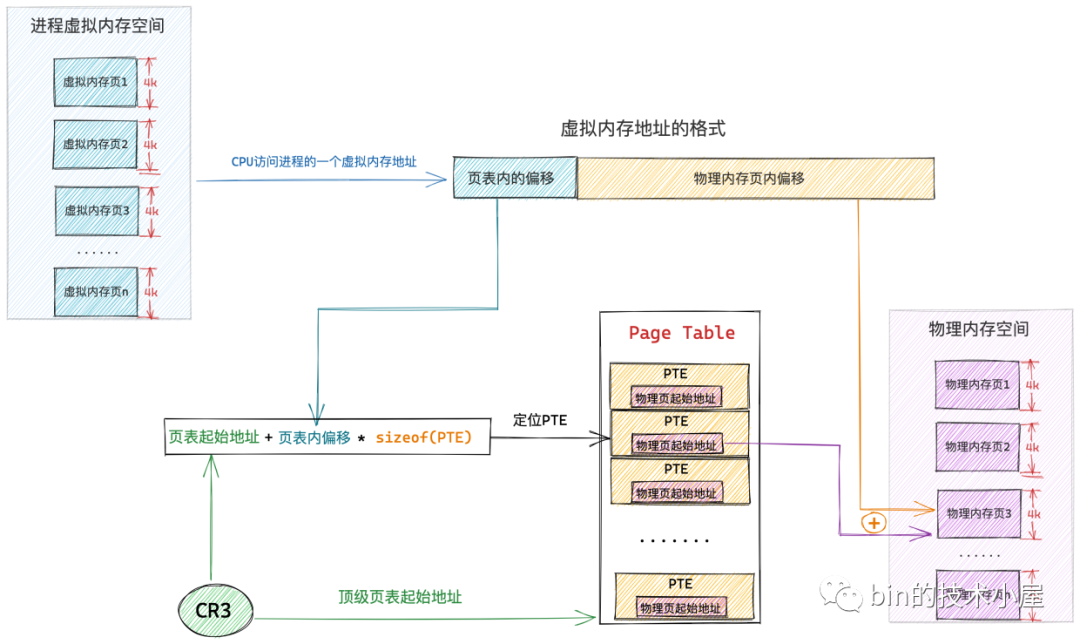
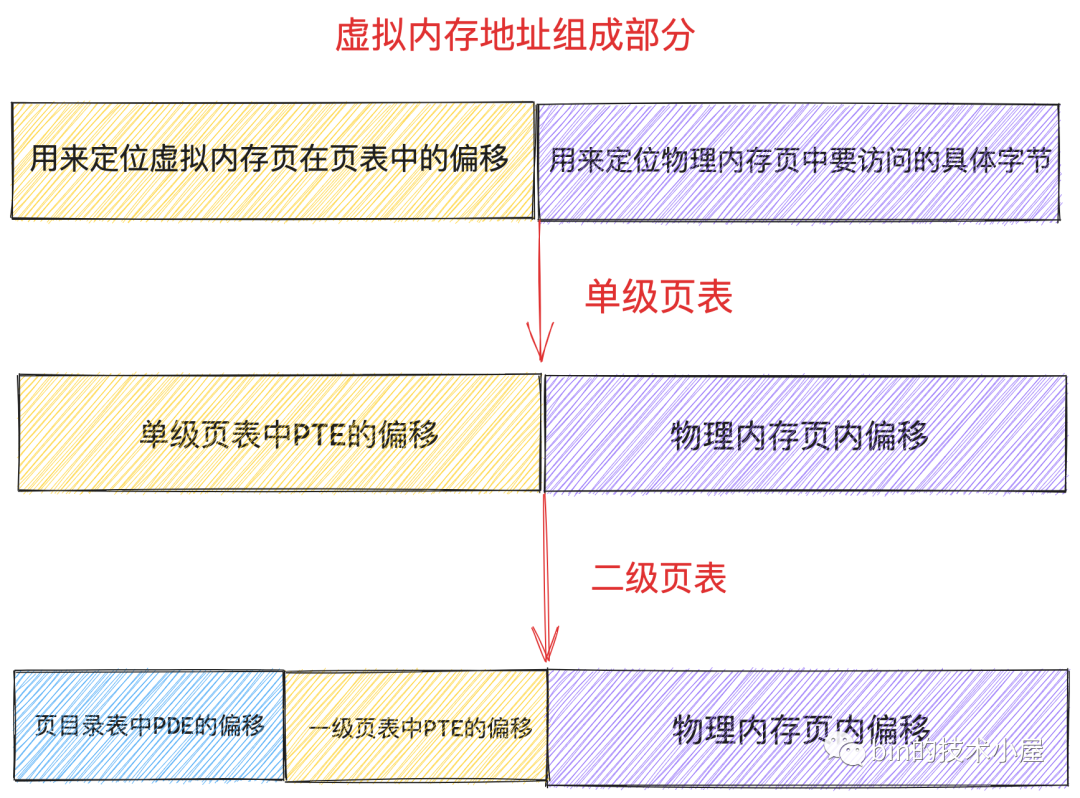
而程序虛擬記憶體空間中的每一個位元組都有一個虛擬記憶體地址來表示,格式為:頁表內偏移 + 實體記憶體頁內偏移
![]()
因為上文已經說了,程序虛擬記憶體空間中的每一個虛擬頁在頁表中都會有一個 PTE 與之對應,專門用來儲存該虛擬頁背後對映的實體記憶體頁的起始地址。
上述虛擬記憶體地址格式中的 頁表內偏移 就是專門用來定位虛擬記憶體頁在頁表中的 PTE 的,因為頁表本質其實還是一個實體記憶體頁,而一個實體記憶體頁裡邊的記憶體肯定都是連續的,每個 PTE 的尺寸又是相同的,所以我們可以把頁表看做一個陣列,PTE 看做陣列裡的元素,在一個陣列裡定位元素,我們直接通過元素的索引 index 就可以定位了。這個索引 index 就是 頁表內偏移 。
這樣一來,給定一個虛擬記憶體地址,核心會先從這個虛擬記憶體地址中提取出 頁表內偏移 ,然後根據 頁表起始地址 + 頁表內偏移 * sizeof(PTE) 就能獲取到該虛擬記憶體地址所在虛擬頁在頁表中對應的 PTE 了。
這裡大家可能會有一個疑問,頁表內偏移我們可以從虛擬記憶體地址中獲取,那這個頁表起始地址我們該從哪裡獲取呢 ?
程序的虛擬記憶體空間在核心中是用 struct mm_struct 結構來描述的,每個程序都有自己獨立的虛擬記憶體空間,而程序的虛擬記憶體到實體記憶體的對映也是獨立的,為了保證每個程序裡記憶體對映的獨立進行,所以每個程序都會有獨立的頁表,而頁表的起始地址就存放在 struct mm_struct 結構中的 pgd 屬性中。
事實上,mm_struct->pgd 存放的是程序的頂級頁表的起始地址,而為了讓大家清晰的理解整個記憶體對映的過程,所以筆者在本小節中只討論單級頁表的情形,在這裡單級頁表的語意就是頂級頁表。
struct mm_struct {
// 當前程序頂級頁表的起始地址
pgd_t * pgd;
}
而程序的頂級頁表起始地址 pgd 又是在什麼時候被核心設定進去的呢?
很顯然這個設定的時機是在程序被建立出來的時候,當我們使用 fork 系統呼叫建立程序的時候,核心在 _do_fork 函數中會通過 copy_process 將父程序的所有資源拷貝到子程序中,這其中也包括父程序的虛擬記憶體空間。
long _do_fork(unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *parent_tidptr,
int __user *child_tidptr,
unsigned long tls)
{
......... 省略 ..........
struct pid *pid;
struct task_struct *p;
......... 省略 ..........
// 拷貝父程序的所有資源
p = copy_process(clone_flags, stack_start, stack_size,
child_tidptr, NULL, trace, tls, NUMA_NO_NODE);
......... 省略 ..........
}
copy_process 函數開始拷貝父程序中的所有資源到子程序中:
static __latent_entropy struct task_struct *copy_process(
unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *child_tidptr,
struct pid *pid,
int trace,
unsigned long tls,
int node)
{
struct task_struct *p;
// 為程序建立 task_struct 結構
p = dup_task_struct(current, node);
....... 初始化子程序 ...........
....... 開始拷貝父程序資源 .......
// 拷貝父程序的虛擬記憶體空間以及頁表
retval = copy_mm(clone_flags, p);
......... 省略拷貝父程序的其他資源 .........
// 分配 CPU
retval = sched_fork(clone_flags, p);
// 分配 pid
pid = alloc_pid(p->nsproxy->pid_ns_for_children);
........... 省略 .........
}
copy_mm 函數負責處理子程序虛擬記憶體空間的初始化工作,它會呼叫 dup_mm 函數,最終在 dup_mm 函數中將父程序虛擬記憶體空間的所有內容包括父程序的相關頁表全部拷貝到子程序中,其中就包括了為子程序分配頂級頁表起始地址 pgd。
static int copy_mm(unsigned long clone_flags, struct task_struct *tsk)
{
...... 省略 ........
mm = dup_mm(tsk, current->mm);
...... 省略 ........
}
/**
* Allocates a new mm structure and duplicates the provided @oldmm structure
* content into it.
*/
static struct mm_struct *dup_mm(struct task_struct *tsk,
struct mm_struct *oldmm)
{
// 子程序虛擬記憶體空間,此時還是空的
struct mm_struct *mm;
int err;
// 為子程序申請 mm_struct 結構
mm = allocate_mm();
if (!mm)
goto fail_nomem;
// 將父程序 mm_struct 結構裡的內容全部拷貝到子程序 mm_struct 結構中
memcpy(mm, oldmm, sizeof(*mm));
// 為子程序分配頂級頁表起始地址並賦值給 mm_struct->pgd
if (!mm_init(mm, tsk, mm->user_ns))
goto fail_nomem;
// 拷貝父程序的虛擬記憶體空間中的內容以及頁表到子程序中
err = dup_mmap(mm, oldmm);
if (err)
goto free_pt;
return mm;
}
最後核心會在 mm_init 函數中呼叫 mm_alloc_pgd,並在 mm_alloc_pgd 函數中通過呼叫 pgd_alloc 為子程序分配其獨立的頂級頁表起始地址,賦值給子程序 struct mm_struct 結構中的 pgd 屬性。
static struct mm_struct *mm_init(struct mm_struct *mm, struct task_struct *p,
struct user_namespace *user_ns)
{
.... 初始化子程序的 mm_struct 結構 ......
// 為子程序分配頂級頁表起始地址 pgd
if (mm_alloc_pgd(mm))
goto fail_nopgd;
}
static inline int mm_alloc_pgd(struct mm_struct *mm)
{
// 核心為子程序分配好其頂級頁表起始地址之後
// 賦值給子程序 mm_struct 結構中的 pgd 屬性
mm->pgd = pgd_alloc(mm);
if (unlikely(!mm->pgd))
return -ENOMEM;
return 0;
}
到現在為止,一個程序就算是被完整的建立出來了,它擁有了自己獨立的頁表(頁表內容和父程序一模一樣),同時也擁有了屬於自己的頂級頁表起始地址 pgd,但是這裡大家需要特別注意一點的就是程序的 struct mm_struct 結構中的這個 pgd 現在還只是頂級頁表的虛擬記憶體地址,還無法被 CPU 直接使用。
當這個程序被排程到某個 CPU 之上時,核心就會呼叫 context_switch 來對程序上下文進行切換,切換的內容主要包括:
- 程序虛擬記憶體空間的切換。
- 暫存器以及程序棧的切換。
/*
* context_switch - switch to the new MM and the new thread's register state.
*/
static __always_inline struct rq *
context_switch(struct rq *rq, struct task_struct *prev,
struct task_struct *next, struct rq_flags *rf)
{
........ 省略 ,,,,,,,,,,
if (!next->mm) { // to kernel
........ 核心執行緒的切換 ,,,,,,,,,,
} else { // to user
........ 使用者程序的切換 ,,,,,,,,,,
membarrier_switch_mm(rq, prev->active_mm, next->mm);
// 切換程序虛擬記憶體空間
switch_mm_irqs_off(prev->active_mm, next->mm, next);
}
// 切換 CPU 上下文和程序棧
switch_to(prev, next, prev);
barrier();
return finish_task_switch(prev);
}
和本小節主題相關的是 switch_mm_irqs_off 函數,它主要負責對程序虛擬記憶體空間進行切換,其中就包括了呼叫 load_new_mm_cr3 函數將程序頂級頁表起始地址 mm_struct-> pgd 中的虛擬記憶體地址通過 __sme_pa 宏 轉換為實體記憶體地址,並將 pgd 的實體記憶體地址載入到 cr3 暫存器中。
void switch_mm_irqs_off(struct mm_struct *prev, struct mm_struct *next,
struct task_struct *tsk)
{
// 通過 __sme_pa 將 pgd 的虛擬記憶體地址轉換為實體記憶體地址
// 並載入到 cr3 暫存器中
load_new_mm_cr3(next->pgd, new_asid, true);
}
cr3 暫存器中存放的是當前程序頂級頁表 pgd 的實體記憶體地址,不能是虛擬記憶體地址。
程序的上下文在核心中完成切換之後,現在 cr3 暫存器中儲存的就是當前程序頂級頁表的起始實體記憶體地址了,當 CPU 通過下圖所示的虛擬記憶體地址存取程序的虛擬記憶體時,CPU 首先會從 cr3 暫存器中獲取到當前程序的頂級頁表起始地址,然後從虛擬記憶體地址中提取出虛擬記憶體頁對應 PTE 在頁表內的偏移,通過 頁表起始地址 + 頁表內偏移 * sizeof(PTE) 這個公式定位到虛擬記憶體頁在頁表中所對應的 PTE。
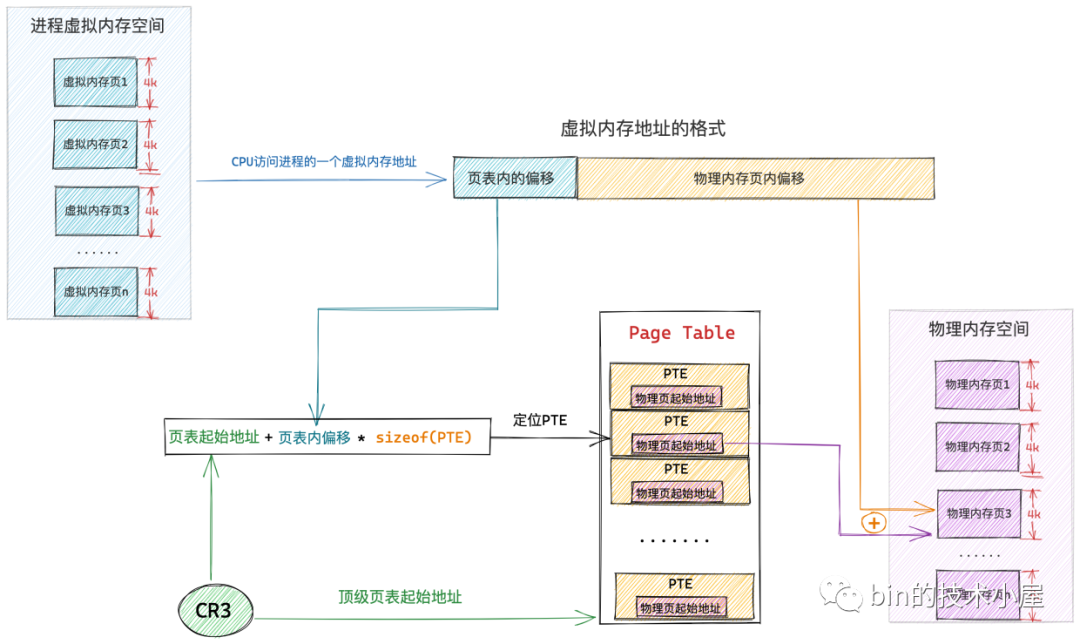
而虛擬記憶體頁背後所對映的實體記憶體頁的起始地址就儲存在該 PTE 中,隨後 CPU 繼續從上圖所示的虛擬記憶體地址中提取後半部分——實體記憶體頁內偏移,並通過 實體記憶體頁起始地址 + 實體記憶體頁內偏移 就定位到了該實體記憶體頁中一個具體的物理位元組上。
好了,現在我們已經梳理清楚了核心如何通過頁表來完成程序的虛擬記憶體與實體記憶體之間的對映關係了,並在這個基礎上,我們又近一步瞭解了 CPU 如何通過虛擬記憶體存取其背後對映的實體記憶體的整個過程。
但是這裡筆者還要和大家特別強調的一點的是:當用戶程序被 CPU 排程起來,存取程序虛擬記憶體的時候,上述的虛擬記憶體地址與實體記憶體地址轉換的過程都是在使用者態進行的,正常的記憶體存取無需進入核心態。
除非 CPU 存取的虛擬記憶體頁面型別是:
- 未分配頁面。
- 已分配未對映頁面。
- 以對映,但是由於記憶體緊張的原因,該虛擬記憶體頁對映的實體記憶體頁被置換到磁碟上了。
以上三種虛擬記憶體頁有一個共同的特徵就是它們背後的實體記憶體頁均不在記憶體中,要麼是沒有對映,要麼是被置換到磁碟上。當 CPU 存取這些虛擬記憶體頁面的時候,就會產生缺頁中斷,隨後進入核心態為其分配實體記憶體頁面,填充實體記憶體頁面中的內容,最後在頁表中建立對映關係。之後的記憶體存取均是在使用者態中進行。
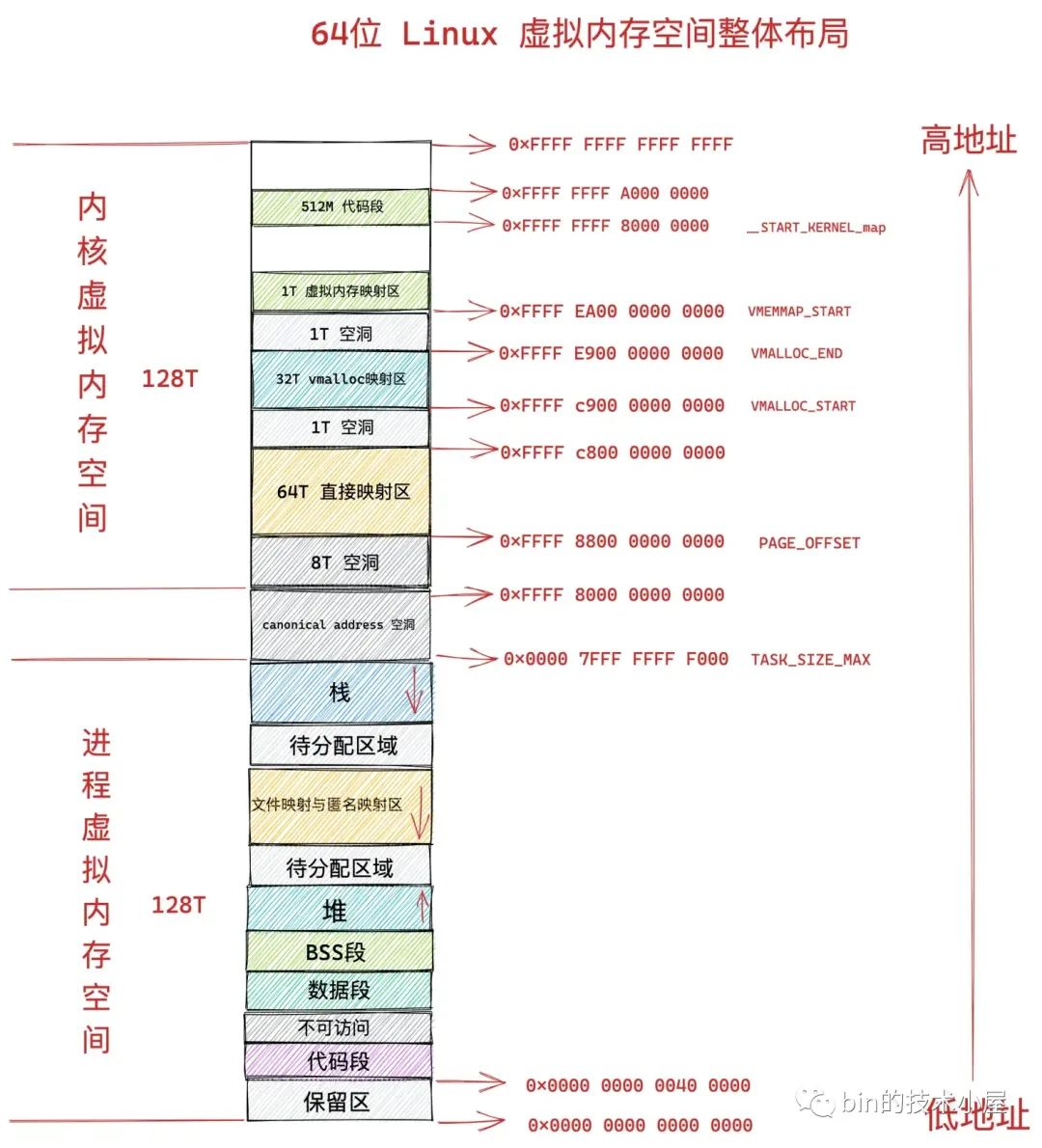
通過前邊文章 《深入理解 Linux 虛擬記憶體管理》 的介紹,我們知道,程序的整個虛擬記憶體空間分為兩個部分,一個是使用者態虛擬記憶體空間,一個是核心態虛擬記憶體空間。
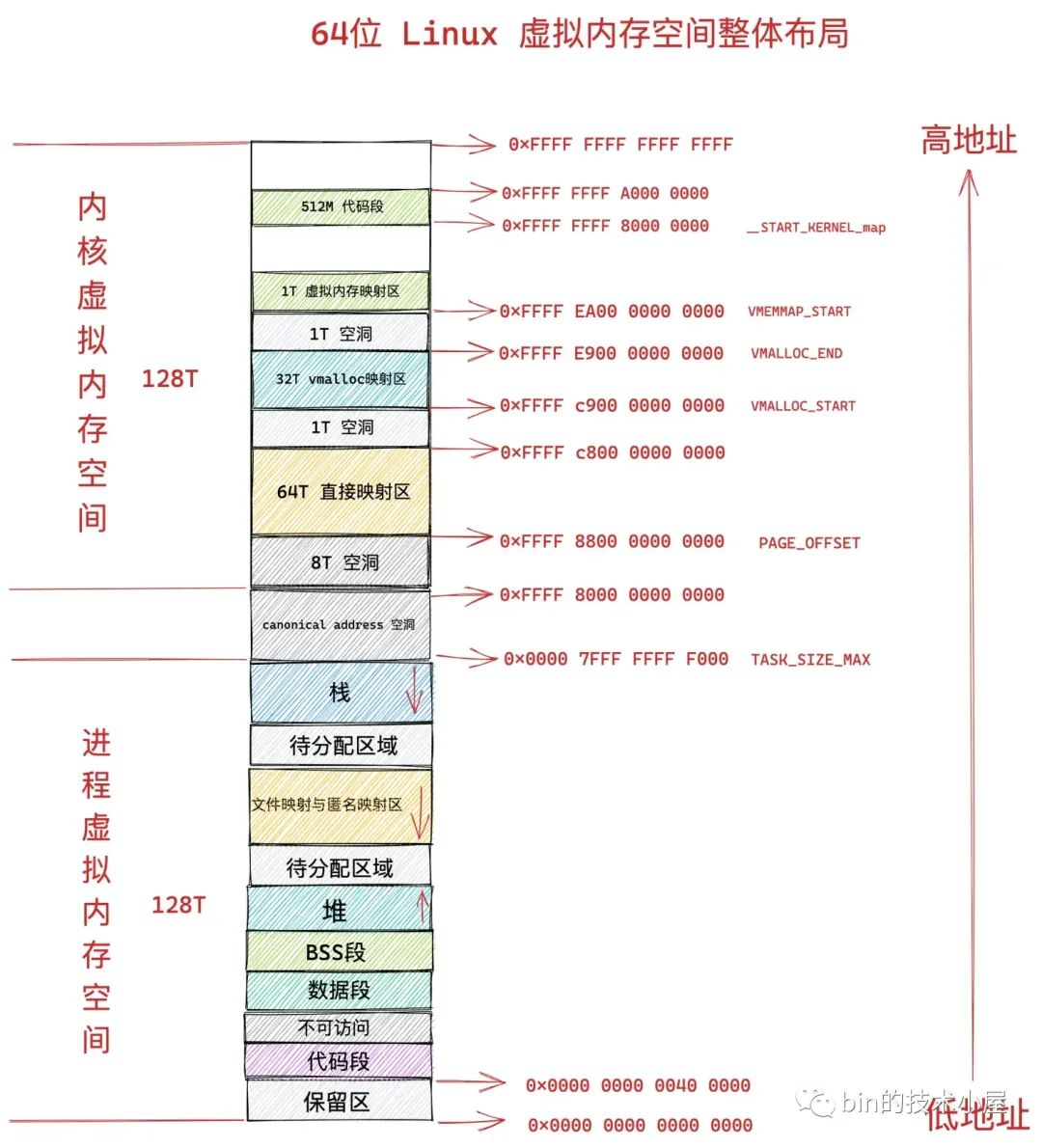
而 CPU 無論是在使用者態還是在核心態,存取的均是虛擬記憶體地址,不管是使用者空間的虛擬記憶體地址還是核心空間的虛擬記憶體地址最終都是要與實體記憶體進行對映的,而通過前邊的介紹我們也知道了,虛擬記憶體與實體記憶體的對映關係是通過頁表來管理的。
所以頁表也就分為了兩個部分:
-
程序使用者態頁表:主要負責管理程序使用者態虛擬記憶體空間到實體記憶體的對映關係。
-
核心態頁表:主要負責管理核心態虛擬記憶體空間到實體記憶體的對映關係,這一部分主要供核心使用。
和程序使用者態虛擬記憶體空間一樣,核心態虛擬記憶體空間也有一個 struct mm_struct 結構來描述:
struct mm_struct init_mm = {
.mm_rb = RB_ROOT,
.pgd = swapper_pg_dir,
.mm_users = ATOMIC_INIT(2),
.mm_count = ATOMIC_INIT(1),
.mmap_sem = __RWSEM_INITIALIZER(init_mm.mmap_sem),
.page_table_lock = __SPIN_LOCK_UNLOCKED(init_mm.page_table_lock),
.mmlist = LIST_HEAD_INIT(init_mm.mmlist),
.user_ns = &init_user_ns,
INIT_MM_CONTEXT(init_mm)
};
從這裡我們可以看到核心空間的頂級頁表起始地址 pgd 叫做 swapper_pg_dir,定義在檔案 arch/x86/include/asm/pgtable_64.h 中:
#define swapper_pg_dir init_top_pgt
核心的頁表在系統初始化的時候被一段組合程式碼 arch\x86\kernel\head_64.S所建立。後續核心虛擬記憶體空間的建立以及核心頁表的初始化工作是在系統啟動函數 start_kernel 中呼叫 setup_arch 完成。
asmlinkage __visible void __init start_kernel(void)
{
........ 省略 ........
// 建立核心虛擬記憶體空間,初始化核心頁表
setup_arch(&command_line);
........ 省略 ........
}
void __init setup_arch(char **cmdline_p)
{
// 初始化核心頁表
clone_pgd_range(swapper_pg_dir + KERNEL_PGD_BOUNDARY,
initial_page_table + KERNEL_PGD_BOUNDARY,
KERNEL_PGD_PTRS);
// 將核心頂級頁表起始地址轉換為實體地址,並載入到 cr3 暫存器中
load_cr3(swapper_pg_dir);
// 重新整理 TLB 頁錶快取
__flush_tlb_all();
}
這裡我們又看到了熟悉的 cr3 暫存器,無論是程序頁表也好還是核心頁表也好,再被 CPU 存取之前都必須先載入到 cr3 暫存器中。
現在核心頁表已經被建立和初始化好了,但是對於處於核心態的程序以及核心執行緒來說並不能直接存取這個核心頁表,它們只能存取核心頁表的 copy 副本,程序的頁表分為兩個部分,一個是程序使用者態頁表,另一個就是核心頁表的 copy 部分。
前邊我們介紹 fork 系統呼叫在建立子程序的時候,會拷貝父程序的所有資源,當拷貝父程序的虛擬記憶體空間的時候,核心會通過 pgd_alloc 函數為子程序建立頂級頁表 pgd,其實這裡還有一項重要的工作,筆者在前邊沒有講,那就是在 pgd_alloc 函數中還會呼叫 pgd_ctor,這個 pgd_ctor 函數的主要工作就是將核心頁表拷貝到程序頁表中。
static inline int mm_alloc_pgd(struct mm_struct *mm)
{
// 核心為子程序分配好其頂級頁表起始地址之後
// 賦值給子程序 mm_struct 結構中的 pgd 屬性
mm->pgd = pgd_alloc(mm);
if (unlikely(!mm->pgd))
return -ENOMEM;
return 0;
}
pgd_t *pgd_alloc(struct mm_struct *mm)
{
pgd_t *pgd;
// 為子程序分配頂級頁表
pgd = _pgd_alloc();
if (pgd == NULL)
goto out;
mm->pgd = pgd;
...... 根據設定,與初始化子程序頁表 .....
// 拷貝核心頁表到子程序中
pgd_ctor(mm, pgd);
....... 省略 ........
}
當程序通過系統呼叫切入到核心態之後,就會使用核心頁表的這部分 copy 副本,來存取核心空間虛擬記憶體對映的實體記憶體。當程序頁表中核心部分的拷貝副本與主核心頁表不同步時,程序在核心態就會發生缺頁中斷,隨後會同步主核心頁表到程序頁表中,這裡又是延時拷貝在核心中的一處應用。
核心執行緒有一點和普通的程序不同,核心執行緒只能執行在核心態,而在核心態中,所有程序看到的虛擬記憶體空間全部都是一樣的,所以對於核心執行緒來說並不需要為其單獨的定義 mm_struct 結構來描述核心虛擬記憶體空間,核心執行緒的 struct task_struct 結構中的 mm 屬性指向 null,核心執行緒之間排程是不涉及地址空間切換的,從而避免了無用的 TLB 快取以及 CPU 快取記憶體的重新整理。
struct task_struct {
// 對於核心執行緒來說,它並沒有自己的地址空間
// 因為它始終工作在核心空間中,所有程序看到的都是一樣的
struct mm_struct *mm;
}
但是核心執行緒依然需要存取核心空間中的虛擬記憶體,也就是說核心執行緒仍然需要核心頁表,但是它又沒有自己的地址空間,那該怎麼辦呢?
核心這裡做了一個非常巧妙的處理,當一個核心執行緒被排程時,它會發現自己的虛擬地址空間為 null,雖然它不會存取使用者態的記憶體,但是它會存取核心記憶體,聰明的核心會將排程之前的上一個使用者態程序的虛擬記憶體空間 mm_struct 直接賦值給核心執行緒 task_struct->active_mm 中 。
struct task_struct {
// 核心執行緒的 active_mm 指向前一個程序的地址空間
// 普通程序的 active_mm 指向 null
struct mm_struct *active_mm;
}
因為核心執行緒不會存取使用者空間的記憶體,它僅僅只會存取核心空間的記憶體,所以直接複用上一個使用者態程序頁表的核心部分就可以避免為核心執行緒分配 mm_struct 和相關頁表的開銷,以及避免核心執行緒之間排程時地址空間的切換開銷。
好了,在本小節中,筆者通過一張單級頁表的例子,帶著大家分別從程序使用者態和核心態的角度闡述了頁表是如何表達虛擬記憶體與實體記憶體之間的對映關係的。在我們清楚了頁表這個概念之後,下面筆者準備繼續帶大家去看一下頁表的演化過程,那麼在這這前,我們先來分析下單級頁表有哪些不足,近而導致程序的頁表體系需要向前演進。
3. 單級頁表的不足
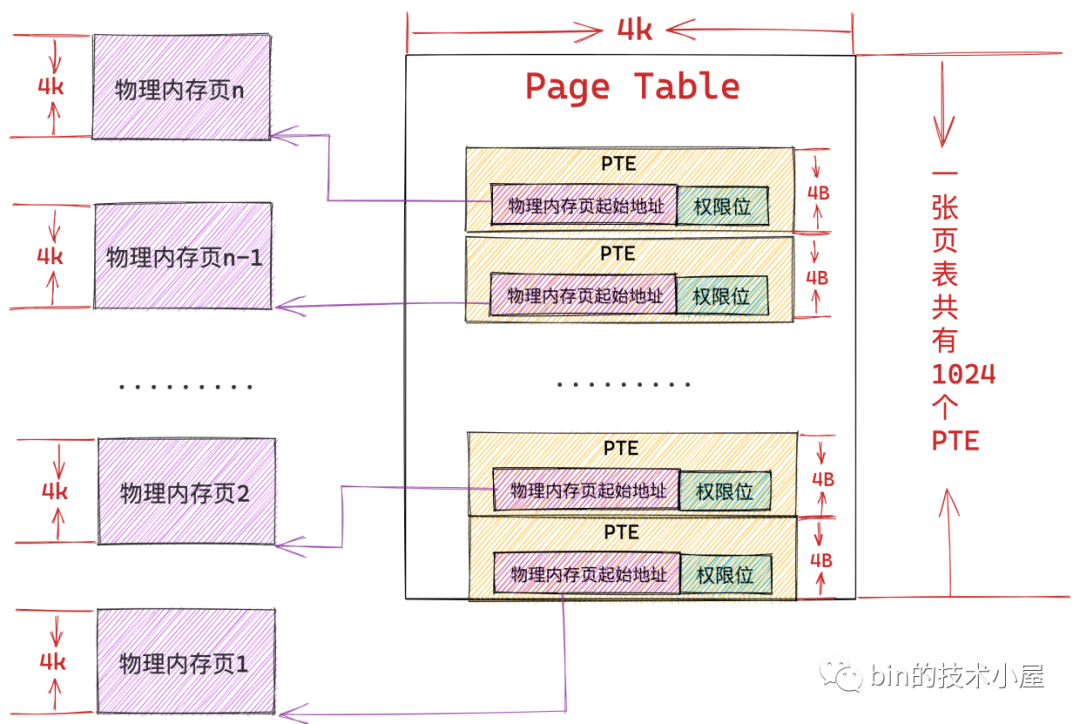
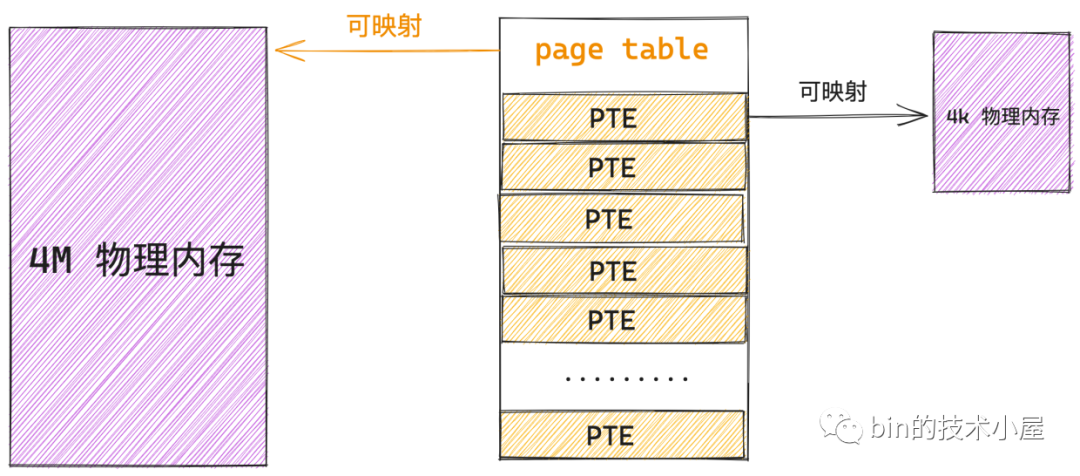
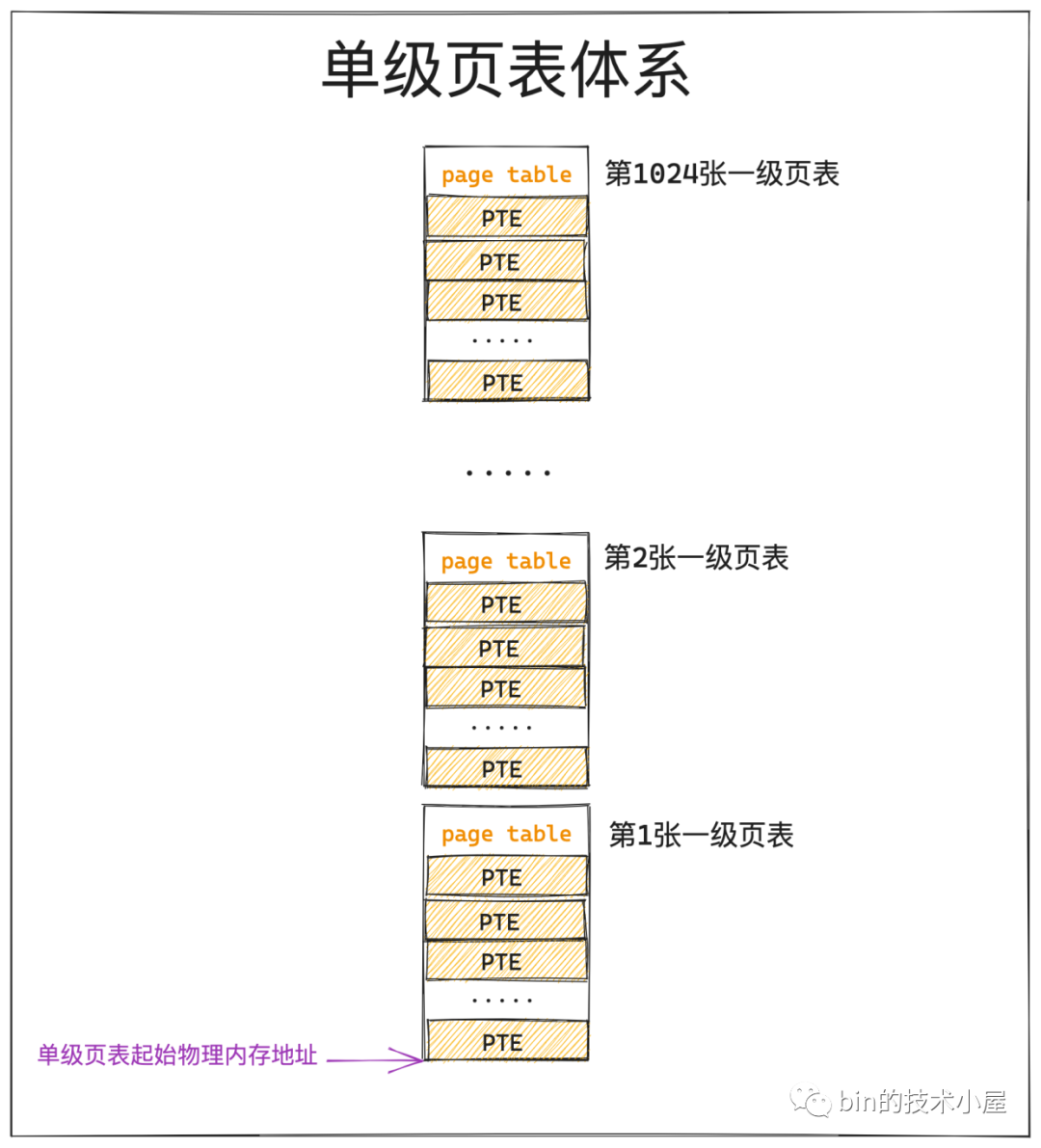
經過上小節內容的介紹我們知道,頁表的本質其實就是一個實體記憶體頁,一張頁表 4K 大小,下面我們以 32 位系統來舉例說明,在 32 位系統中,頁表中的一個 PTE 佔用 4B 大小,所以一張頁表可以容納 1024 個 PTE。
在程序中虛擬記憶體與實體記憶體的對映是以頁為單位的,程序虛擬記憶體空間中的一個虛擬記憶體頁對映實體記憶體空間的一個實體記憶體頁,這種對映關係以及訪存許可權都儲存在 PTE 中,所以程序中的一個虛擬記憶體頁對應頁表中的一個 PTE,一個 PTE 能夠對映 4K 的實體記憶體(一個實體記憶體頁)。
一張頁表裡邊可以容納 1024 個 PTE,一個 PTE 可以對映 4K 的實體記憶體,那麼一張頁表就可以對映 1024 * 4K = 4M 大小的實體記憶體 ,而頁表本質上是一個實體記憶體頁(4K大小),所以核心需要用額外的 4K 大小的實體記憶體去對映 4M 的實體記憶體。
假設我們現在系統中有 4G 的實體記憶體,一張頁表能夠對映 4M 大小的實體記憶體,而為了對映這 4G 的實體記憶體,我們需要 1024 張頁表,一張頁表佔用 4K 實體記憶體,所以為了對映 4G 的實體記憶體,我們額外需要 4M 的實體記憶體(1024張頁表)來對映。
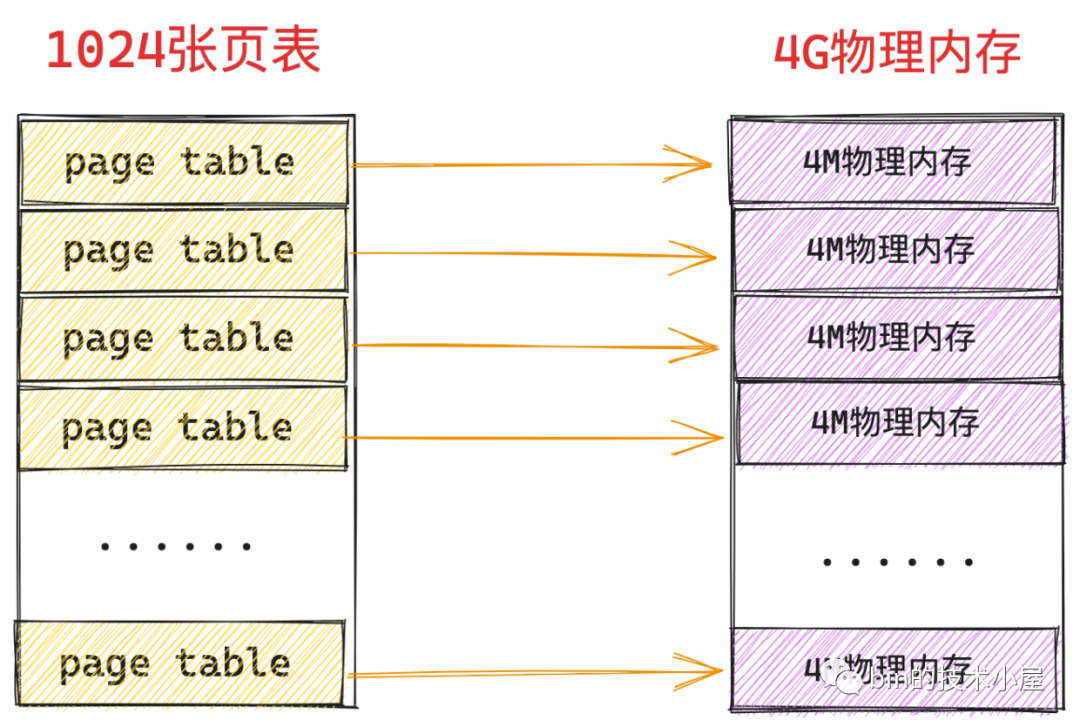
更要命的是這 4M 實體記憶體(1024張頁表)還必須是連續的,因為頁表是單級的,而頁表相當於是 PTE 的陣列,程序虛擬記憶體空間中的一個虛擬記憶體頁對應一個 PTE,而 PTE 在頁表這個陣列中的索引 index 就儲存在虛擬記憶體地址中,核心通過頁表的起始地址加上這個索引 index 才能定位到虛擬記憶體頁對應的 PTE,近而通過 PTE 定位到對映的實體記憶體頁。
如果這 4M 實體記憶體(1024張頁表)不是連續的,那麼我們就無法通過存取陣列的方式定位 PTE 了。而系統經過長時間執行之後,由於記憶體碎片的原因,是很難找到這麼大一片連續的實體記憶體的。
大家需要注意的是,這 4M 的連續實體記憶體還只是一個程序所需要的,因為程序的虛擬記憶體空間都是獨立的,頁表也是獨立的,一個程序就需要額外的 4M 連續實體記憶體(1024張頁表)來支援程序內獨立的記憶體對映關係。假如在系統中跑上 100 個程序,那總共就需要額外的 400M 連續的實體記憶體。這對於一個只有 4G 實體記憶體,單級頁表的系統來說,無疑是巨大的開銷和浪費。
在程序啟動的時候就為它分配 4M 的頁表這確實是比較大的開銷,這一點是沒錯的,但是為什麼說是一種浪費呢?
如果程序一啟動就立馬會存取全部的 4G 實體記憶體,那麼的確需要在一開始就為程序分配 4M 的連續實體記憶體來存放頁表,那這一點開銷無論多麼大都是必須的,不能省的,否則程序將無法執行。
但程式的區域性性原理告訴我們,程序在執行之後,對於記憶體的存取不會一下子就要存取全部的記憶體,相反程序對於記憶體的存取會表現出明顯的傾向性,更加傾向於存取最近存取過的資料以及熱點資料附近的資料。
程式區域性性原理表現為:時間區域性性和空間區域性性。時間區域性性是指如果程式中的某條指令一旦執行,則不久之後該指令可能再次被執行;如果某塊資料被存取,則不久之後該資料可能再次被存取。空間區域性性是指一旦程式存取了某個儲存單元,則不久之後,其附近的儲存單元也將被存取。
所以無論一個程序在實際執行過程中總共需要佔用的記憶體資源有多大,根據程式區域性性原理,在某一段時間內,程序真正需要的實體記憶體其實是很少的一部分,我們只需要為每個程序分配很少的實體記憶體就可以保證程序的正常執行運轉。
既然在某一個特定的時刻,程序只需要很少的實體記憶體就可以正常運轉,那麼程序虛擬記憶體與實體記憶體之間的對映關係相應也會很少,根本就不需要 4M 的實體記憶體來儲存對映關係。
我們完全可以在程序初始狀態下,建立一個最小集的頁表,當程序實際確實需要的時候,我們再來建立相應具體的頁表,這又是延時分配思想在核心中的另一處應用。
那麼核心是如何做到的呢?接下來我們就需要向多級頁表演進了~~~~
4. 多級頁表的演進
在開始為大家介紹多級頁表之前,筆者這裡還是要和大家不斷強化幾個核心概念,這些概念非常重要,這關係到大家是否能從本質上理解多級頁表的設計。
-
頁表本質上還是一個實體記憶體頁,只不過這個實體記憶體頁比較特殊,裡面存放的是 PTE,儲存虛擬記憶體與實體記憶體的對映關係。既然它是一個普通的實體記憶體頁,那麼也會參與核心的排程,既會被核心 swap in 以及 swap out,也會被快取在 CPU 快取記憶體中加速存取。
-
在 32 位系統中,一個 PTE 佔用 4 個位元組,可以對映 4K 的實體記憶體,一張頁表本身佔用 4K 的實體記憶體,可以對映 4M 的實體記憶體。
-
定位虛擬記憶體頁在程序頁表中對應的 PTE 是通過陣列的存取方式進行的,虛擬記憶體地址中包含了其對應的 PTE 在頁表中的偏移(頁表陣列中的 index),所以這就要求每一級頁表都必須是連續的,比如上小節中介紹的單級頁表,這 1024 張頁表必須是連續的實體記憶體(4M 大小)。
-
程序對系統記憶體的存取具有明顯的區域性性,在任意時刻,我們只需要為程序分配很少的記憶體就能保證程序的正常執行。
在強化了這些核心概念之後,我們繼續沿著上小節中介紹的單級頁表的思路往下捋,接下來我們還是以 4G 的實體記憶體為例,根據區域性性原理我們知道,程序在啟動之後的任意時刻都不可能一下子就要存取全部的 4G 實體記憶體,但是我們需要給程序提供定址 4G 實體記憶體的能力,也就是說你先別管我存取不存取,反正 4G 實體記憶體的定址能力我是需要的。
「讓社會的不良風氣吹進來,我可以不收,但你們不能不送」——範德彪

所以在單級頁表的情況下,我們必須要為程序額外分配 4M 的連續實體記憶體來存放 1024 張頁表,不管程序存取不存取,這 4M 的開銷是不能省的。
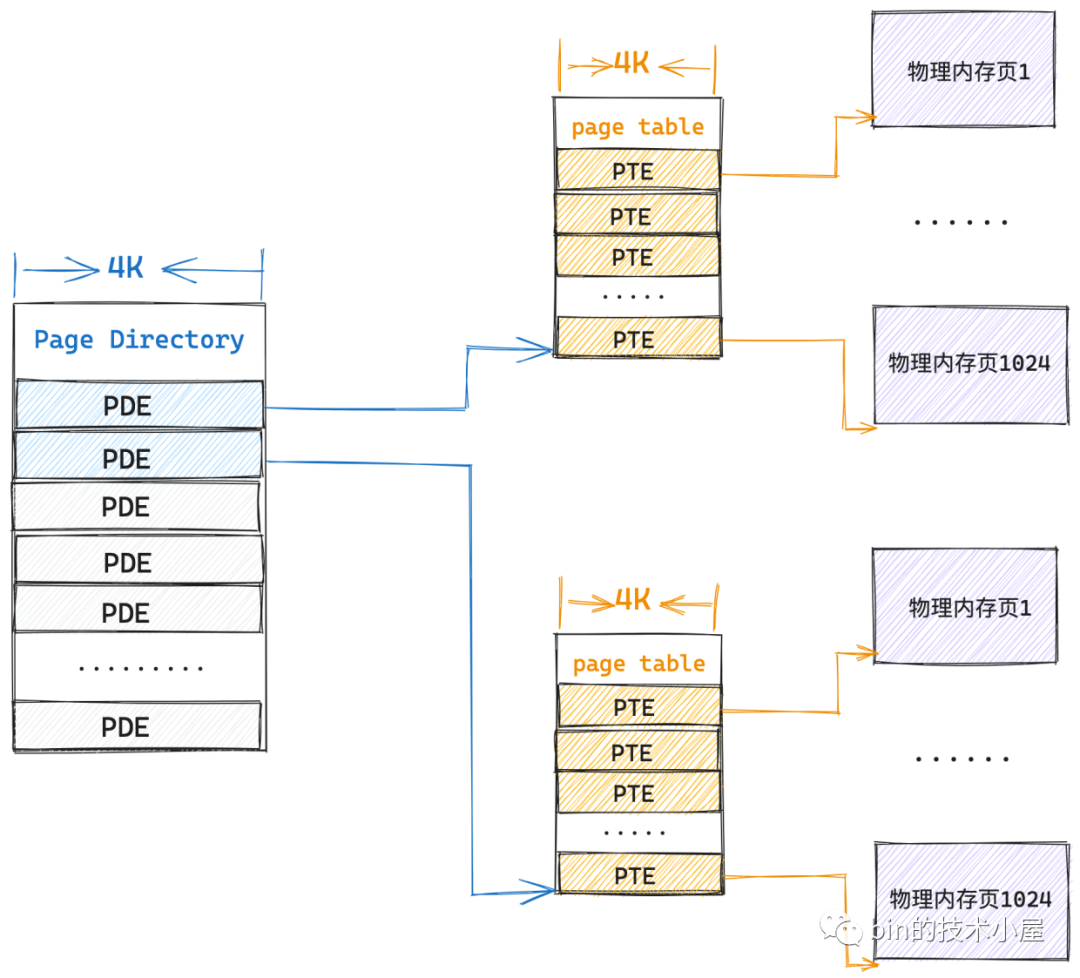
那麼現在我們在拿出一個 4K 的實體記憶體頁作為頁表,然後將這個頁表放在單級頁表的前面,組成一個二級頁表的體系,情況會變成什麼樣呢?
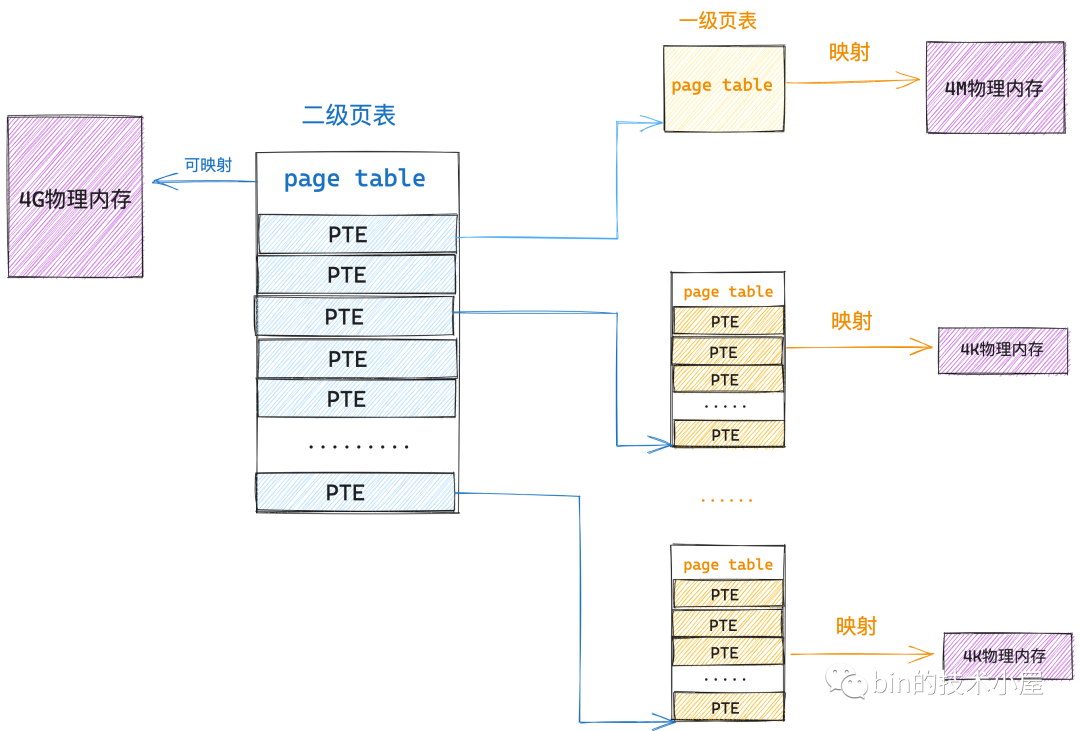
之前筆者不斷地和大家強調過,頁表的本質是一個實體記憶體頁,頁表是 PTE 的陣列,而 PTE 的本質是指向其對映的一個實體記憶體頁,既然 PTE 可以指向一個普通的實體記憶體頁,那麼它也可以指向一個頁表。
根據這個思路,二級頁表中的一個 PTE 本質上指向的還是一個實體記憶體頁,只不過這個實體記憶體頁比較特殊,它是一張頁表(一級頁表),一級頁表是用來對映真正的實體記憶體的,一張一級頁表可以對映 4M 實體記憶體。
這也就是說二級頁表中的一個 PTE 就可以對映 4M 實體記憶體,同樣的道理,二級頁表中也包含了 1024 個 PTE,所以一張二級頁表就可以對映 4G 的實體記憶體。
雖說二級頁表和一級頁表本質上都是一樣的,它們都是一個實體記憶體頁,但是我們習慣上將二級頁表叫做頁目錄表,用來做一級頁表的索引,就好像書中的目錄一樣,二級頁表中的 PTE 我們習慣上稱為做頁目錄項 (Page Directory Entry, PDE)。
因為一張頁目錄表就可以對映 4G 的實體記憶體了,所以在二級頁表的情況下,我們只需要在程序啟動的時候額外為它分配 4K 的連續實體記憶體就可以了,這相比單級頁表下,需要為每個程序額外分配 4M 的連續實體記憶體節省了非常多寶貴的記憶體資源。
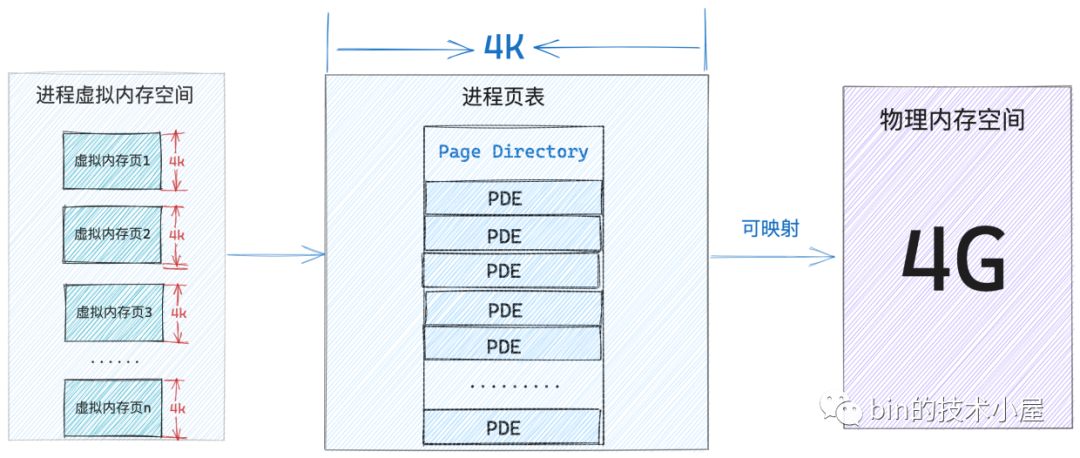
但程序執行起來肯定會存取記憶體對吧,要存取記憶體就需要有對映,在執行過程中光有一張頁目錄表肯定是不夠的,根據程式區域性性原理,程序在執行中的任意時刻,只會存取很小一塊的記憶體,比如這時程序需要存取 4K 的實體記憶體(一個實體記憶體頁),在二級頁表情況下,核心會本著你存取多少,我對映多少的原則來進行記憶體對映,下面我們來一起看看二級頁表下的對映過程並與一級頁表對比下記憶體消耗。
當前系統中,程序只有一張頁目錄表,頁目錄表裡的 PDE 沒有對映任何東西,這時程序需要存取一個實體記憶體頁,而對實體記憶體頁的對映任務主要是在一級頁表的 PTE 中,所以現在首要的任務就是建立一張一級頁表出來,並用頁目錄表索引起來。
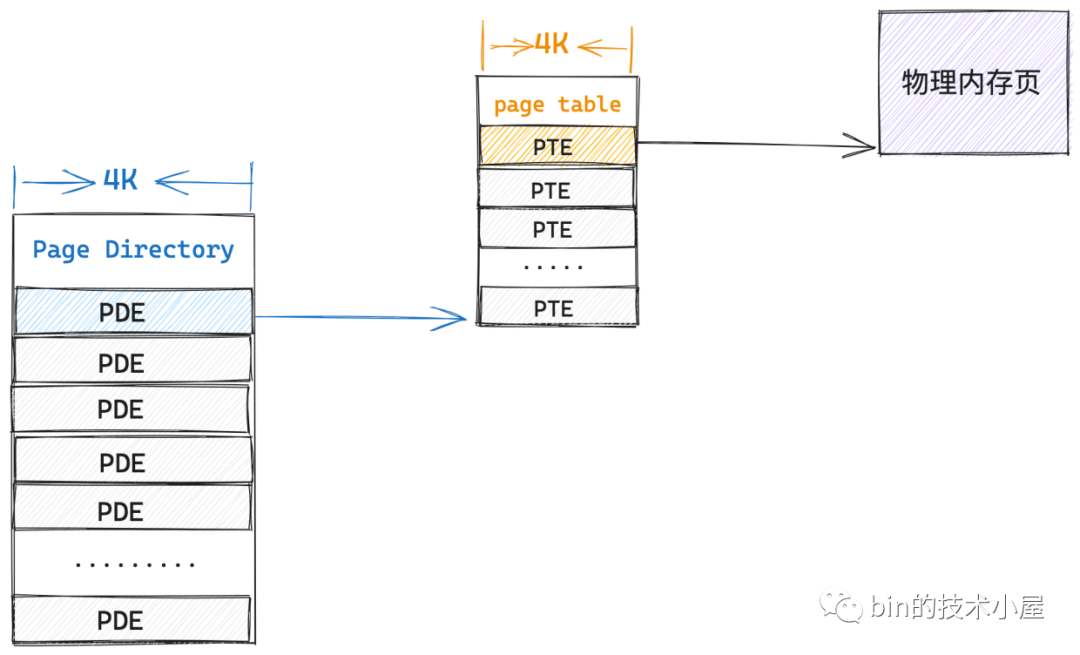
在二級頁表的情況下,核心只需要一張 4K 的頁目錄表和一張 4K 的一級頁表總共 8K 的記憶體就可以支援程序存取一個 4K 物理頁面了,而根據程式的空間區域性性原理,在不久的將來,程序只會存取與該實體記憶體頁臨近的頁面,所以事實上,即使程序存取 4M 的記憶體,依然只需要一張 4K 的頁目錄表和一張 4K 的一級頁表就可以滿足了。
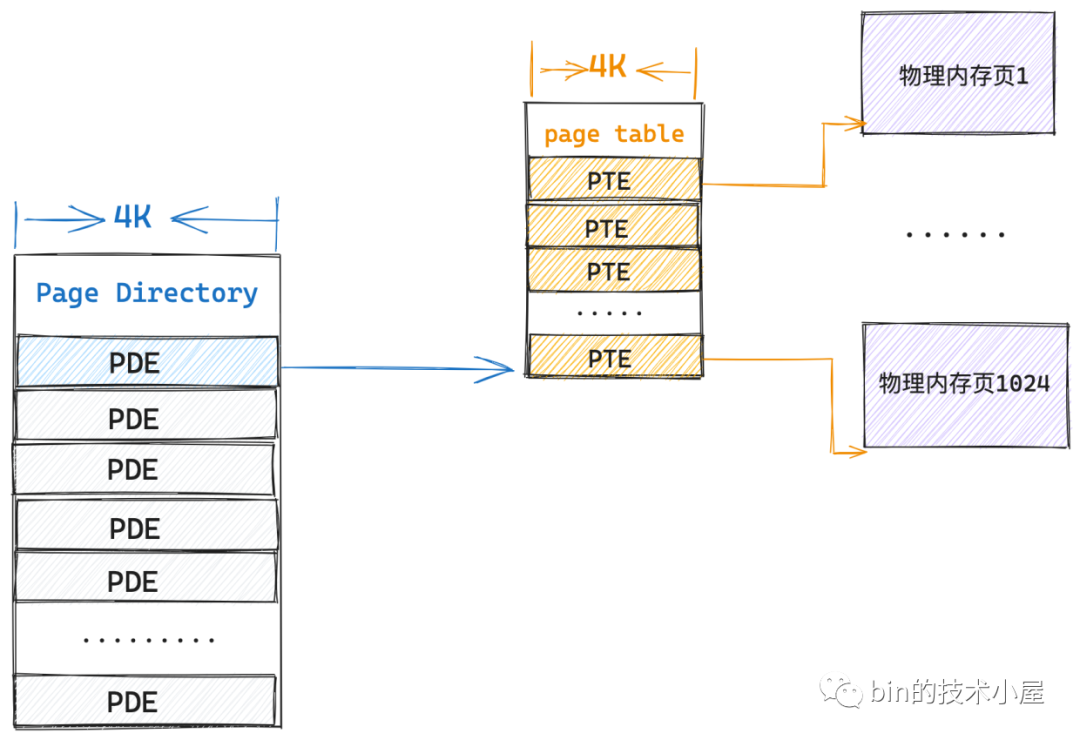
當程序需要存取下一個 4M 的實體記憶體時,這時候第一個一級頁表已經對映滿了,那就需要再建立第二張頁表用來對映下一個 4M 的實體記憶體,當然了,第二張頁表依然需要索引在頁目錄表的 PDE 中。
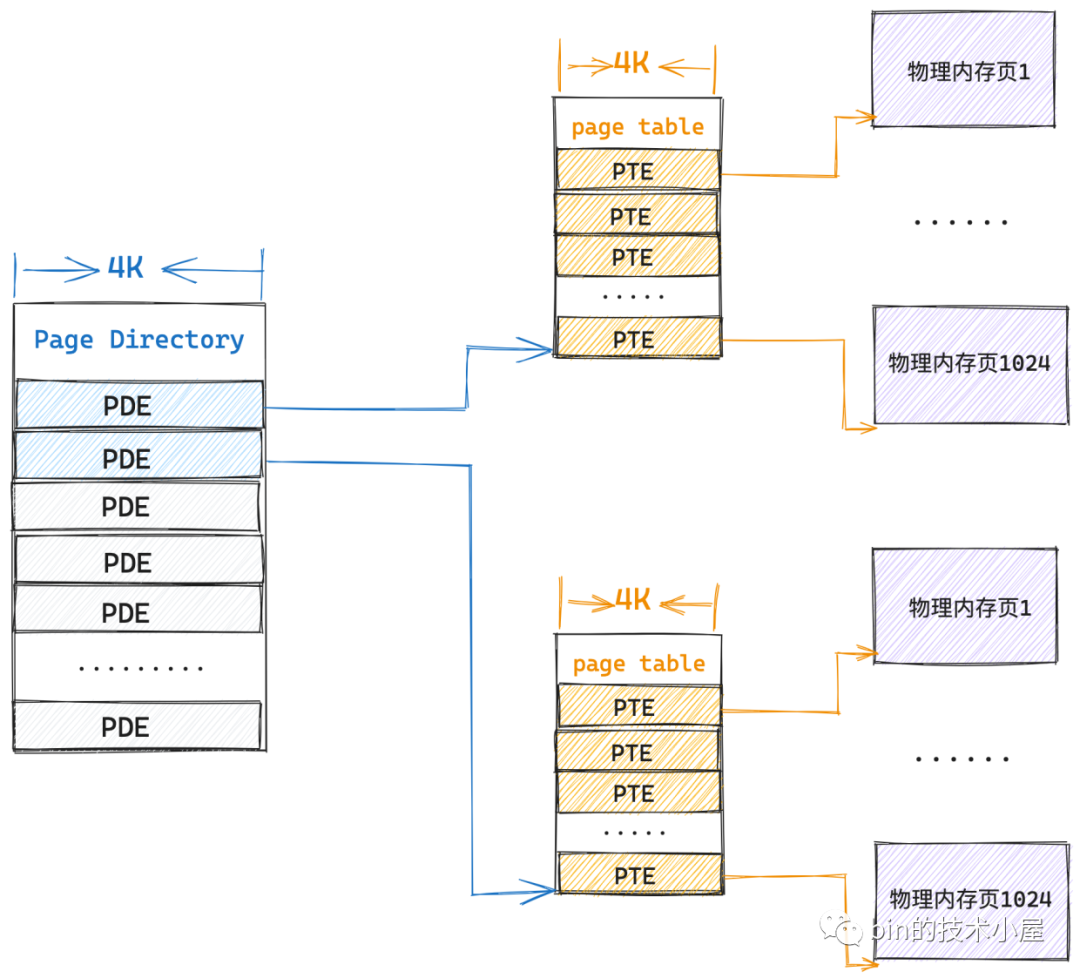
這時候核心就需要一張頁目錄表和兩張一級頁表共 12K 額外的實體記憶體來對映,這依然比單級頁表的 4M 連續實體記憶體開銷小很多。
同理,隨著程序一個 4M 接著一個 4M 實體記憶體的存取,在極端的情況下整個頁目錄表都被對映滿了,這時候核心就需要 4K(頁目錄表)+ 4M(1024張一級頁表)的額外記憶體來儲存對映關係了,這種情況下看起來會比單級頁表下的 4M 記憶體開銷大了那麼一點點,但這種屬於極端情況,非常少見,極大部分情況下還是比單級頁表開銷少很多很多的。
而且在二級頁表體系下,上面極端情況中的這 1024 張一級頁表不需要是連續的,因為我們只需要保證頂級頁表(這裡指頁目錄表)是連續的就可以了,通過頁目錄表中的 PDE 可以唯一索引到一張一級頁表的起始實體記憶體地址,而頁表內肯定是連續的 4K 實體記憶體,所以依然可以通過陣列的方式索引到一級頁表中的 PTE,近而找到其對映的實體記憶體頁面。
除此之外二級頁表體系還有一個優勢,就是當記憶體緊張的時候,那些不經常使用的一級頁表可以被 swap out 到磁碟中,當程序再次存取到該頁表對映的實體記憶體時,核心在將頁表從磁碟中 swap in 到記憶體中。當然了,頂級頁表(這裡指頁目錄表)必須是常駐記憶體的,不允許 swap 。
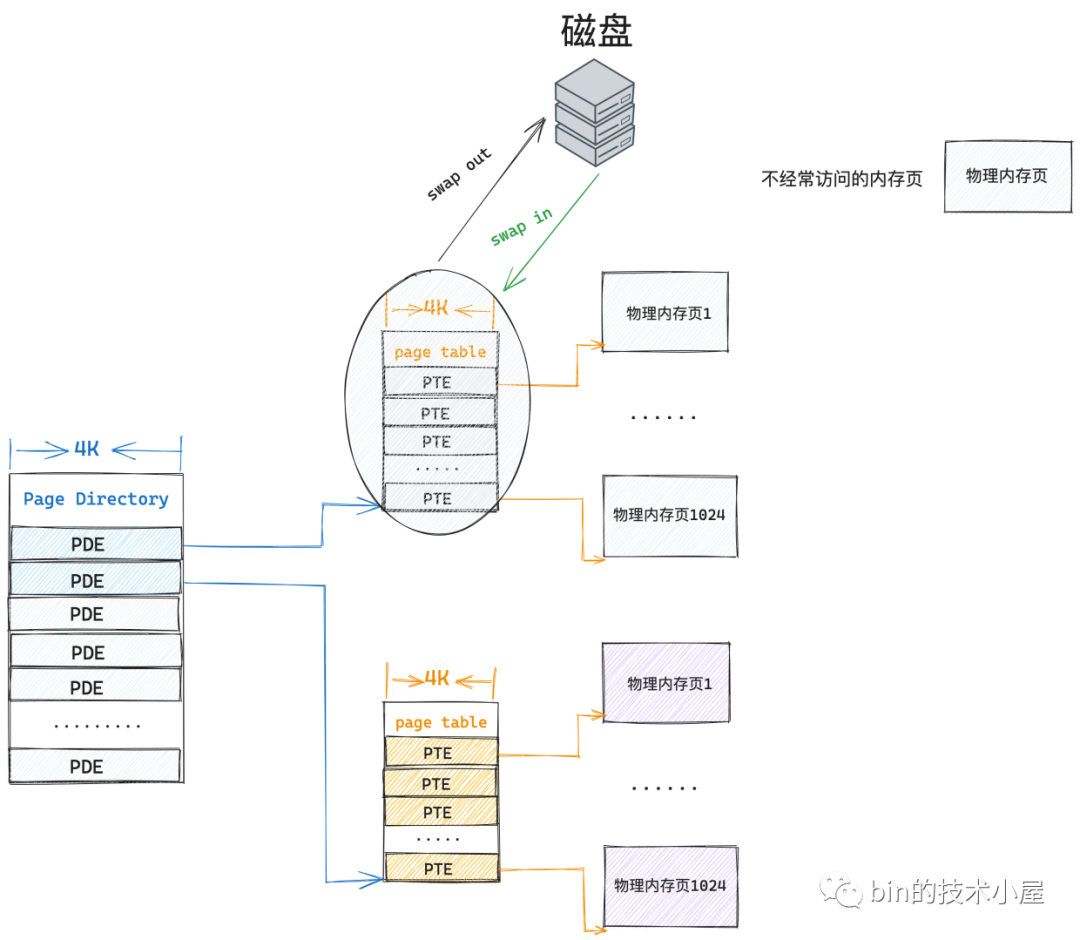
既然頁表的本質是一個實體記憶體頁,那麼同理,程序經常存取的那些頁表也會被快取到 CPU 快取記憶體中加速下一次的存取速度。
在本小節中我們主要揭露多級頁表的本質,除了二級頁表之外,根據同樣的道理,也會有三級頁表,四級頁表,Linux 核心甚至還支援五級頁表,無論頁表有多少級,但是都逃脫不了本小節中介紹的本質。本質的原理我們清楚了之後,下面我們就來看下多級頁表具體的工作過程吧~~~
4.1 二級頁表
現在我們對單級頁表體系下的虛擬記憶體的定址過程已經非常熟悉了,那麼多級頁表體系下的虛擬記憶體定址過程也是一樣的,都逃脫不了前邊為大家介紹的頁表本質。在引入二級頁表定址過程之前,我們在來回顧下單級頁表定址的本質核心邏輯:
-
首先無論是幾級頁表,它們通過虛擬記憶體定址的本質就是定位虛擬記憶體頁對應在頁表中的 PTE,然後通過 PTE 找到其對映的具體實體記憶體頁。
-
頁表的本質是一個實體記憶體頁,其中包含了 1024 個 PTE,每個 PTE 可以對映一個具體的實體記憶體頁,PTE 中儲存了實體記憶體頁的起始地址,程序地址空間中的一個虛擬記憶體頁對應頁表中的一個 PTE。因為在核心中是按照頁為單位進行記憶體對映的。
-
在單級頁表體系下,前面提到的 1024 張一級頁表背後是通過連續的 4M 實體記憶體儲存的,既然是連續的,那麼我們可以把單級頁表看做一個大的 PTE 陣列,只要我們知道了單級頁表的起始實體記憶體地址以及虛擬記憶體頁對應 PTE 在單級頁表(1024 張一級頁表)中的 index,那麼就可以定位到 PTE 了。
這裡的單級頁表起始實體記憶體地址指的就是 1024 張一級頁表中,第一張頁表的起始實體記憶體地址。
- cr3 暫存器儲存了頂級頁表的起始實體記憶體地址,頂級頁表隨著程序的建立而建立,儲存在程序 mm_struct->pgd,當程序被 CPU 排程的時候,會伴隨著程序上下文切換,其中就會將 mm_struct->pgd 轉換為實體記憶體地址並載入到 cr3 暫存器中。
這裡的頂級頁表指的就是單級頁表(1024 張一級頁表)
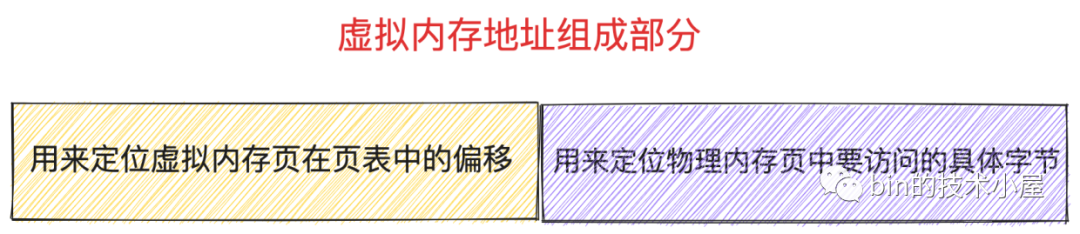
- 無論在幾級頁表體系下,程序虛擬記憶體空間中的虛擬記憶體地址格式在設計上總共分為兩大部分,一部分是用來定位虛擬記憶體頁在頁表中對應的 PTE 偏移,另一部分是用來定位實體記憶體頁中要存取的具體位元組。
- 單級頁表的起始實體記憶體地址(儲存在 cr3 暫存器中)有了,虛擬記憶體頁在單級頁表中對應 PTE 的偏移(儲存在虛擬記憶體地址中)有了,通過公式
頁表起始地址 + 頁表內偏移 * sizeof(PTE)就可以定位到虛擬記憶體頁對應的 PTE 了,而 PTE 中儲存了對映實體記憶體頁的起始地址,在加上虛擬記憶體地址中儲存的實體記憶體頁內偏移,這樣就可以定位到虛擬記憶體地址對應的物理位元組了。
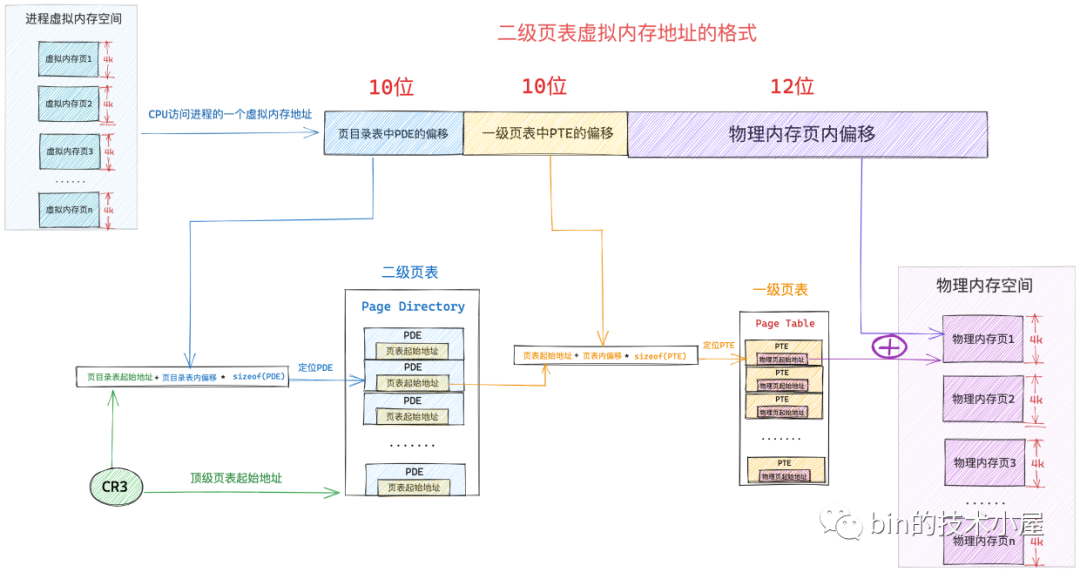
從單級頁表演進到二級頁表之後,虛擬記憶體定址的底層邏輯還是一樣的,只不過現在的頂級頁表變成了頁目錄表(Page Directory), cr3 暫存器現在存放的是頁目錄表的起始實體記憶體地址。
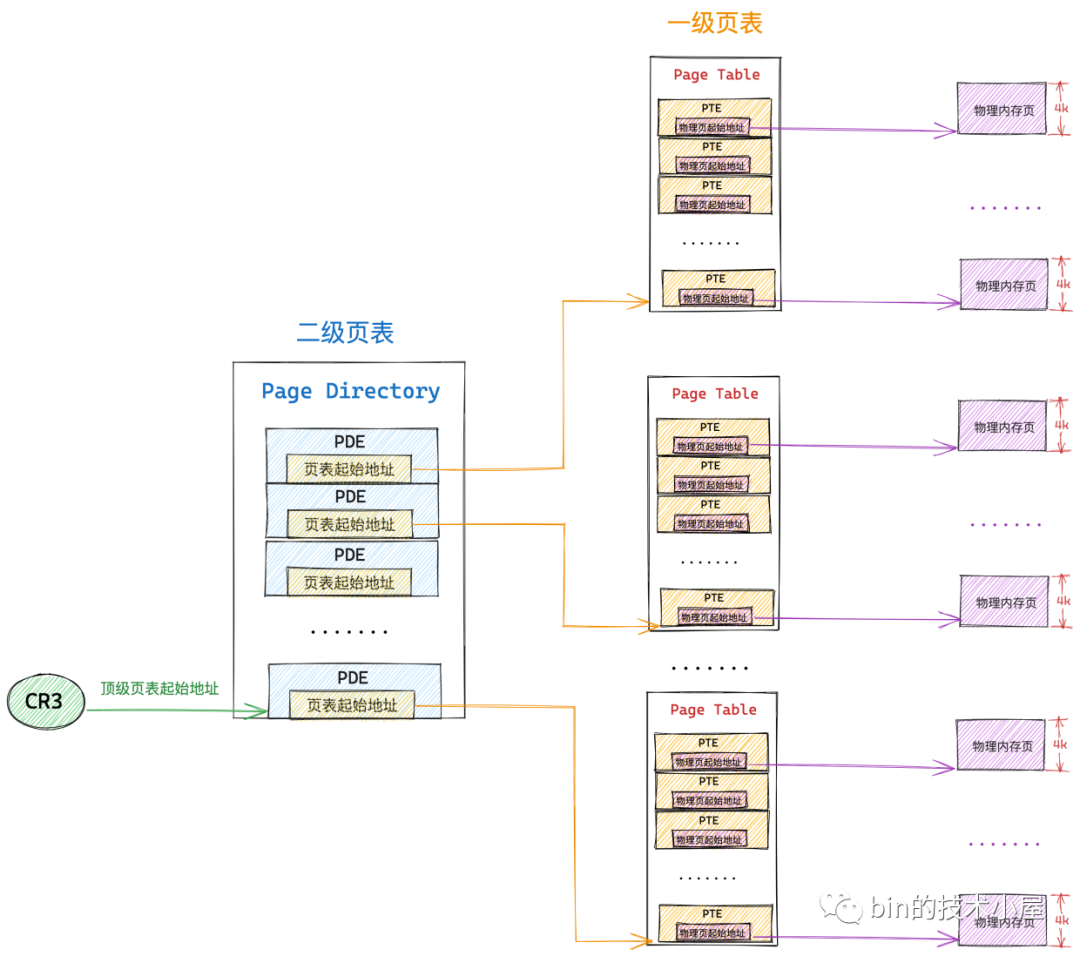
通過虛擬記憶體地址定位 PTE 的步驟由原來的一步變成了現在的兩步,因為我們多加了一級頁目錄表,所以現在需要首先定位頁目錄表中的 PDE,然後通過 PDE 定位到具體的頁表,近而找到頁表中的 PTE。
所以在二級頁表體系下的虛擬記憶體地址的格式也就發生了變化,單級頁表下虛擬記憶體地址中只需要儲存頁表中的 PTE 偏移即可,二級頁表下虛擬記憶體地址還需要多儲存一份頁目錄表中 PDE 的偏移。
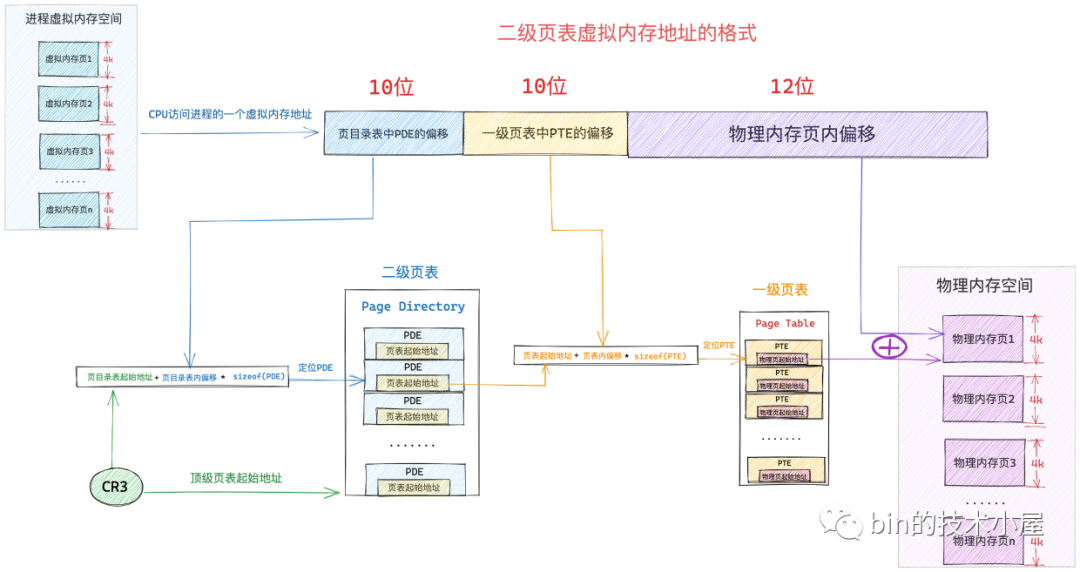
二級頁表應用在 32 位系統中,相應的虛擬記憶體地址由 32 位 bit 組成,在 32 位系統中頁目錄表中的 PDE 和頁表中的 PTE 均佔用 4 個位元組。而前邊我們也介紹過了,頁目錄表和頁表的本質其實就是一個實體記憶體頁,它們分別佔用 4K 大小。
因此一張頁目錄表中有 1024 個 PDE,要定址這 1024 個 PDE 用 10 個 bit 就可以了,所以在上圖中的虛擬記憶體地址中的 頁目錄表中 PDE 偏移 部分佔用 10 個 bit 位。
同樣的道理,一張頁表中有 1024 個 PTE, 要定址這個 1024 個 PTE 也是需要 10 個 bit,上圖中虛擬記憶體地址中的 一級頁表中 PTE 偏移 部分也需要佔用 10 個 bit 位。
這樣一來我們就可以通過虛擬記憶體地址中的前 10 個 bit 定位到頁目錄表中的 PDE ,而 PDE 指向的是一級頁表的起始實體記憶體地址,然後我們通過接下來的 10 個 bit 就可以定位到頁表中的 PTE,而 PTE 指向的是虛擬記憶體頁最終對映的實體記憶體頁的起始地址。
現在我們找到實體記憶體頁了,那麼如何在實體記憶體頁中找到我們要存取的位元組呢 ?這就需要上圖虛擬記憶體地址中的最後一部分 實體記憶體頁內偏移了,因為一個實體記憶體頁佔用 4K 大小,我們用 12 位 bit 就可以定址記憶體頁中的任意位元組了。
這樣加起來,剛好可以組成一個 32 位的虛擬記憶體地址,在我們清楚了二級頁表下的虛擬記憶體地址格式之後,接下來我們就來看下二級頁表體系下的定址過程:
-
當 CPU 存取程序虛擬記憶體空間中的一個地址時,會先從 cr3 暫存器中拿出頁目錄表的起始實體記憶體地址,然後從虛擬記憶體地址中解析出前 10 bit 的內容作為頁目錄表中 PDE 的偏移,通過公式
頁目錄表起始地址 + 頁目錄表內偏移 * sizeof(PDE)就可以定位到該虛擬記憶體頁在頁目錄表中的 PDE 了。 -
PDE 中儲存了其指向的一級頁表的起始實體記憶體地址,我們在從虛擬記憶體地址中解析出下一個 10 bit 作為頁表中 PTE 的偏移,然後通過公式
頁表起始地址 + 頁表內偏移 * sizeof(PTE)就能定位到虛擬記憶體頁在一級頁表中的 PTE 了。 -
PTE 中儲存了最終對映的實體記憶體頁的起始地址,最後我們從虛擬記憶體地址中解析出最後 12 個 bit,最終定位到虛擬記憶體地址對應的物理位元組上。
現在二級頁表下虛擬記憶體定址的完整過程筆者就為大家介紹完了,那麼我們提到了這麼次的 PDE,PTE,它們內部到底長什麼樣子呢?我們接著往下看~~~
4.1.1. 32 位頁表項 PTE
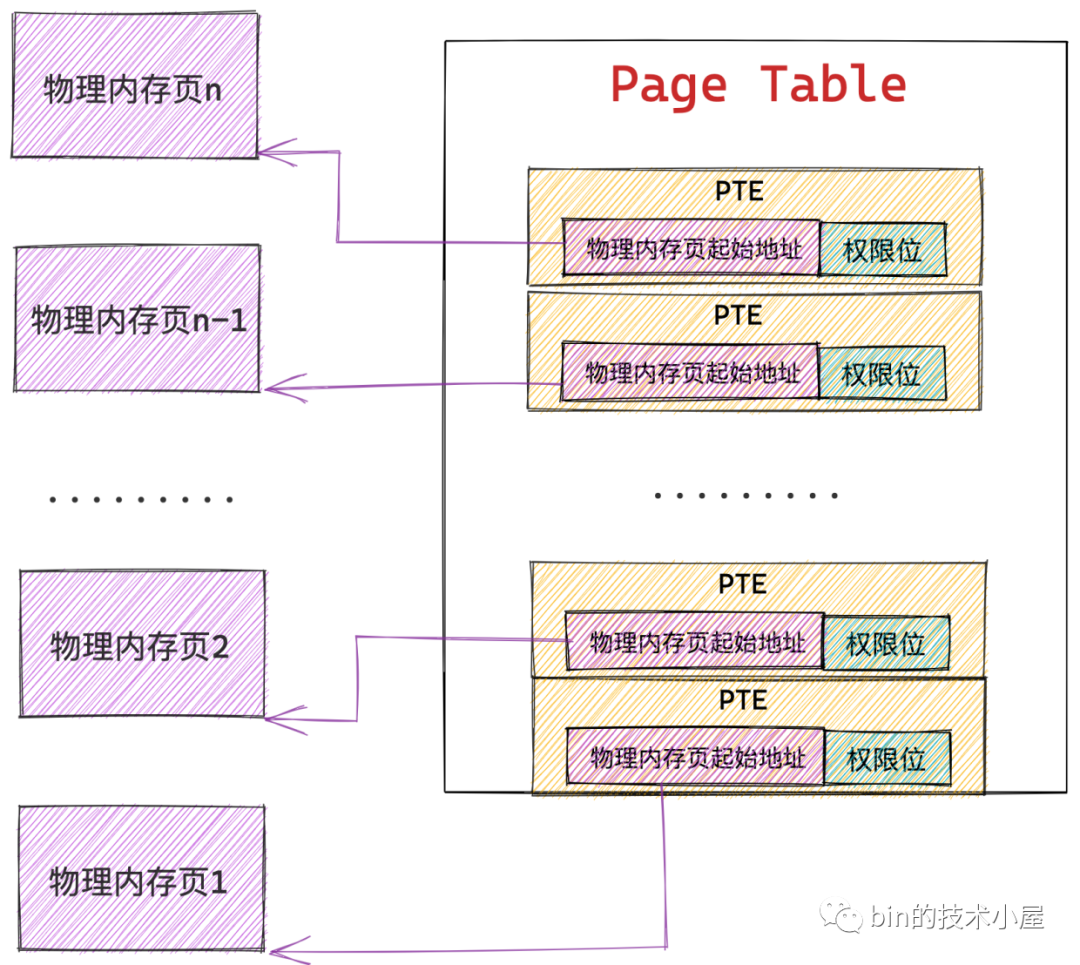
在程序的虛擬記憶體空間中,每一個虛擬記憶體頁在頁表中都有一個 PTE 與之對應,在 32 位系統中,每個 PTE 佔用 4 個位元組大小,其中儲存了虛擬記憶體頁背後對映的實體記憶體頁的起始地址,以及程序存取實體記憶體的一些許可權標識位。
PTE 在核心中是用 unsigned long 型別描述的,在 32 位系統中佔用 4 個位元組:
typedef unsigned long pteval_t;
typedef struct { pteval_t pte; } pte_t;
下面是 PTE 中 32 bit (4 位元組) 的佈局格式:

由於核心將整個實體記憶體劃分為一頁一頁的單位,每個實體記憶體頁大小為 4K,所以實體記憶體頁的起始地址都是按照 4K 對齊的,也就導致實體記憶體頁的起始地址的後 12 位全部是 0,我們只需要在 PTE 中儲存實體記憶體地址的高 20 位就可以了,剩下的低 12 位可以用來標記一些許可權位。下面是 PTE 許可權位的含義:
P(0) 表示該 PTE 對映的實體記憶體頁是否在記憶體中,值為 1 表示實體記憶體頁在記憶體中駐留,值為 0 表示實體記憶體頁不在記憶體中,可能被 swap 到磁碟上了。當 PTE 中的 P 位為 0 時,上圖中的其他許可權位將變得沒有意義,這種情況下其他 bit 位存放實體記憶體頁在磁碟中的地址。當實體記憶體頁需要被 swap in 的時候,核心會在這裡找到實體記憶體頁在磁碟中的位置。

當我們通過上述虛擬記憶體定址過程找到其對應的 PTE 之後,首先會檢查它的 P 位,如果為 0 直接觸發缺頁中斷(page fault),隨後進入核心態,由核心的缺頁例外處理程式負責將對映的物理頁面換入到記憶體中。
R/W(1) 表示程序對該實體記憶體頁擁有的讀,寫許可權,值為 1 表示程序對該物理頁擁有讀寫許可權,值為 0 表示程序對該物理頁擁有唯讀許可權,程序對唯讀頁面進行寫操作將觸發 page fault (防寫中斷異常),用於寫時複製(Copy On Write, COW)的場景。
比如,父程序通過 fork 系統呼叫建立子程序之後,父子程序的虛擬記憶體空間完全是一模一樣的,包括父子程序的頁表內容都是一樣的,父子程序頁表中的 PTE 均指向同一實體記憶體頁面,此時核心會將父子程序頁表中的 PTE 均改為唯讀的,並將父子程序共同對映的這個物理頁面參照計數 + 1。
當父程序或者子程序對該頁面發生寫操作的時候,我們現在假設子程序先對頁面發生寫操作,隨後子程序發現自己頁表中的 PTE 是唯讀的,於是產生防寫中斷,子程序進入核心態,在核心的缺頁中斷處理程式中發現,存取的這個物理頁面參照計數大於 1,說明此時該實體記憶體頁面存在多程序共用的情況,於是發生寫時複製(Copy On Write, COW),核心為子程序重新分配一個新的物理頁面,然後將原來物理頁中的內容拷貝到新的頁面中,最後子程序頁表中的 PTE 指向新的物理頁面並將 PTE 的 R/W 位設定為 1,原來物理頁面的參照計數 - 1。
後面父程序在對頁面進行寫操作的時候,同樣也會發現父程序的頁表中 PTE 是唯讀的,也會產生防寫中斷,但是在核心的缺頁中斷處理程式中,發現存取的這個物理頁面參照計數為 1 了,那麼就只需要將父程序頁表中的 PTE 的 R/W 位設定為 1 就可以了。
U/S(2) 值為 0 表示該實體記憶體頁面只有核心才可以存取,值為 1 表示使用者空間的程序也可以存取。
PCD(4) 是 Page Cache Disabled 的縮寫,表示 PTE 指向的這個實體記憶體頁中的內容是否可以被快取再 CPU CACHE 中,值為 1 表示 Disabled,值為 0 表示 Enabled。
PWT(3) 同樣也是和 CPU CACHE 相關的控制位,Page Write Through 的縮寫,值為 1 表示 CPU CACHE 中的資料發生修改之後,採用 Write Through 的方式同步回實體記憶體頁中。值為 0 表示採用 Write Back 的方式同步回實體記憶體頁。
當 CPU 修改了快取記憶體中的資料之後,這些修改後的快取內容同步回記憶體的方式有兩種:
-
Write Back:CPU 修改後的快取資料不會立馬同步回記憶體,只有當 cache line 被替換時,這些修改後的快取資料才會被同步回記憶體中,並覆蓋掉對應實體記憶體頁中舊的資料。
-
Write Through:CPU 修改快取記憶體中的資料之後,會立刻被同步回實體記憶體頁中。
A(5) 表示 PTE 指向的這個實體記憶體頁最近是否被存取過,1 表示最近被存取過(讀或者寫存取都會設定為 1),0 表示沒有。該 bit 位被硬體 MMU 設定,由作業系統重置。核心會經常檢查該位元位,以確定該實體記憶體頁的活躍程度,不經常使用的記憶體頁,很可能就會被核心 swap out 出去。
D(6) 主要針對檔案頁使用,當 PTE 指向的實體記憶體頁是一個檔案頁時,程序對這個檔案頁寫入了新的資料,這時檔案頁就變成了髒頁,對應的 PTE 中 D 位元位會被設定為 1,表示檔案頁中的內容與其背後對應磁碟中的檔案內容不同步了。關於髒頁的詳細描述,可以回看下筆者之前的這篇文章 《從 Linux 核心角度探祕 JDK NIO 檔案讀寫本質》。
PAT(7) 表示是否支援 PAT(Page Attribute Table) , PAT 的相關內容和本文主題無關,這裡就不做過多的介紹了。
G(8) 設定為 1 表示該 PTE 是全域性的,該標誌位表示 PTE 中儲存的對映關係是否是全域性的,什麼意思呢,一般來說程序都有各自獨立的虛擬記憶體空間,程序的頁表也是獨立的 ,CPU 每次存取程序虛擬記憶體地址的時候都需要進行地址翻譯(上一小節介紹的定址過程),為了加速地址翻譯的速度,避免每次遍歷頁表,CPU 會把經常被存取到的 PTE 快取在一個 TLB 的硬體快取中,由於 TLB 中快取的是當前程序相關的 PTE,所以作業系統每次在切換程序的時候,都會重新重新整理 TLB 快取。
而有一些 PTE 是所有程序共用的,比如說核心虛擬記憶體空間中的對映關係,所有程序進入核心態看到的都是一樣的。所以會將這些全域性共用的 PTE 中的 G 位元位置為 1 ,這樣在每次程序切換的時候,就不會 flush 掉 TLB 快取的那些共用的全域性 PTE(比如核心地址的空間中使用的 PTE),從而在很大程度上提升了效能。
以上介紹的這些 PTE 相關的許可權位元位定義在核心檔案/arch/x86/include/asm/pgtable_types.h 中:
#define _PAGE_BIT_PRESENT 0 /* is present */
#define _PAGE_BIT_RW 1 /* writeable */
#define _PAGE_BIT_USER 2 /* userspace addressable */
#define _PAGE_BIT_PWT 3 /* page write through */
#define _PAGE_BIT_PCD 4 /* page cache disabled */
#define _PAGE_BIT_ACCESSED 5 /* was accessed (raised by CPU) */
#define _PAGE_BIT_DIRTY 6 /* was written to (raised by CPU) */
#define _PAGE_BIT_PAT 7 /* on 4KB pages */
#define _PAGE_BIT_GLOBAL 8 /* Global TLB entry PPro+ */
// 從 PTE 中提取相應位元位的掩碼
#define _PAGE_PRESENT (_AT(pteval_t, 1) << _PAGE_BIT_PRESENT)
#define _PAGE_RW (_AT(pteval_t, 1) << _PAGE_BIT_RW)
#define _PAGE_USER (_AT(pteval_t, 1) << _PAGE_BIT_USER)
#define _PAGE_PWT (_AT(pteval_t, 1) << _PAGE_BIT_PWT)
#define _PAGE_PCD (_AT(pteval_t, 1) << _PAGE_BIT_PCD)
#define _PAGE_ACCESSED (_AT(pteval_t, 1) << _PAGE_BIT_ACCESSED)
#define _PAGE_DIRTY (_AT(pteval_t, 1) << _PAGE_BIT_DIRTY)
#define _PAGE_PSE (_AT(pteval_t, 1) << _PAGE_BIT_PSE)
#define _PAGE_GLOBAL (_AT(pteval_t, 1) << _PAGE_BIT_GLOBAL)

除此之外,核心還定義了一系列的方法,用於操作 PTE 的相關許可權位元位,這些方法三個一組,分別用於相應許可權位元位的查詢,設定,清除操作,定義在核心檔案 /arch/x86/include/asm/pgtable.h 中:
// 查詢 PTE 指向的實體記憶體頁是否在記憶體中
static inline int pte_present(pte_t a)
// 查詢記憶體頁是否可寫
static inline int pte_write(pte_t pte)
// 設定記憶體頁可寫
static inline pte_t pte_mkwrite(pte_t pte)
// 禁止讀寫
static inline pte_t pte_wrprotect(pte_t pte)
// 查詢 PTE 是否是 global
static inline int pte_global(pte_t pte)
static inline pte_t pte_mkglobal(pte_t pte)
static inline pte_t pte_clrglobal(pte_t pte)
// 查詢 PTE 指向的記憶體頁是否是髒頁
static inline int pte_dirty(pte_t pte)
static inline pte_t pte_mkclean(pte_t pte)
static inline pte_t pte_mkdirty(pte_t pte)
// 查詢 PTE 指向的記憶體頁是否最近被存取過
static inline int pte_young(pte_t pte)
static inline pte_t pte_mkold(pte_t pte)
static inline pte_t pte_mkyoung(pte_t pte)
4.1.2. 32 位頁目錄項 PDE
同 PTE 一樣,PDE 在 32 位系統中也是用 unsigned long 型別來描述的,同樣也是佔用 4 個位元組大小。
typedef unsigned long pgdval_t;
PDE 是用來指向一級頁表的起始實體記憶體地址的,而頁表的本質是一個實體記憶體頁(4K 大小),因此頁表的起始記憶體地址也是按照 4K 對齊的,後 12 位全部為 0 ,我們可以繼續用 PDE 的低 12 位來標記頁目錄項的許可權位:

這裡和頁表中 PTE 的許可權位不同的是,PDE 中的第 6 個位元位髒頁標記位沒有了,因為 PDE 指向的是一級頁表,頁表並不是一個檔案頁,所以髒頁標記在這裡就沒有意義了。
還有就是 PDE 中的第 8 位元位,Global 全域性標記位也沒有了,因為 TLB 快取的 PTE 而不是 PDE,所以不需要設定 Global 標記來防止程序切換導致 TLB flush。
最後一個不同的是 PDE 中的第 7 位元位由 PTE 中的 PAT 標記變為了 PS 標記位。那麼這個 PS 位元位在這裡是幹什麼用的呢?
當 PS 標記為 0 的時候,PDE 的對映關係確實如本小節第一張圖中所示,PDE 指向一級頁表的起始記憶體地址,這種情況下,PDE 的作用確實是我們前邊介紹的頁目錄項的作用。
但是當 PS 標記為 1 的時候,PDE 就會被核心拿來當做 PTE 使用,不過這個 」PTE「 比較特殊,其特殊之處在於該 PDE 會指向一個大頁記憶體,這個實體記憶體頁不是普通的 4K 大小,而是 4M 大小。
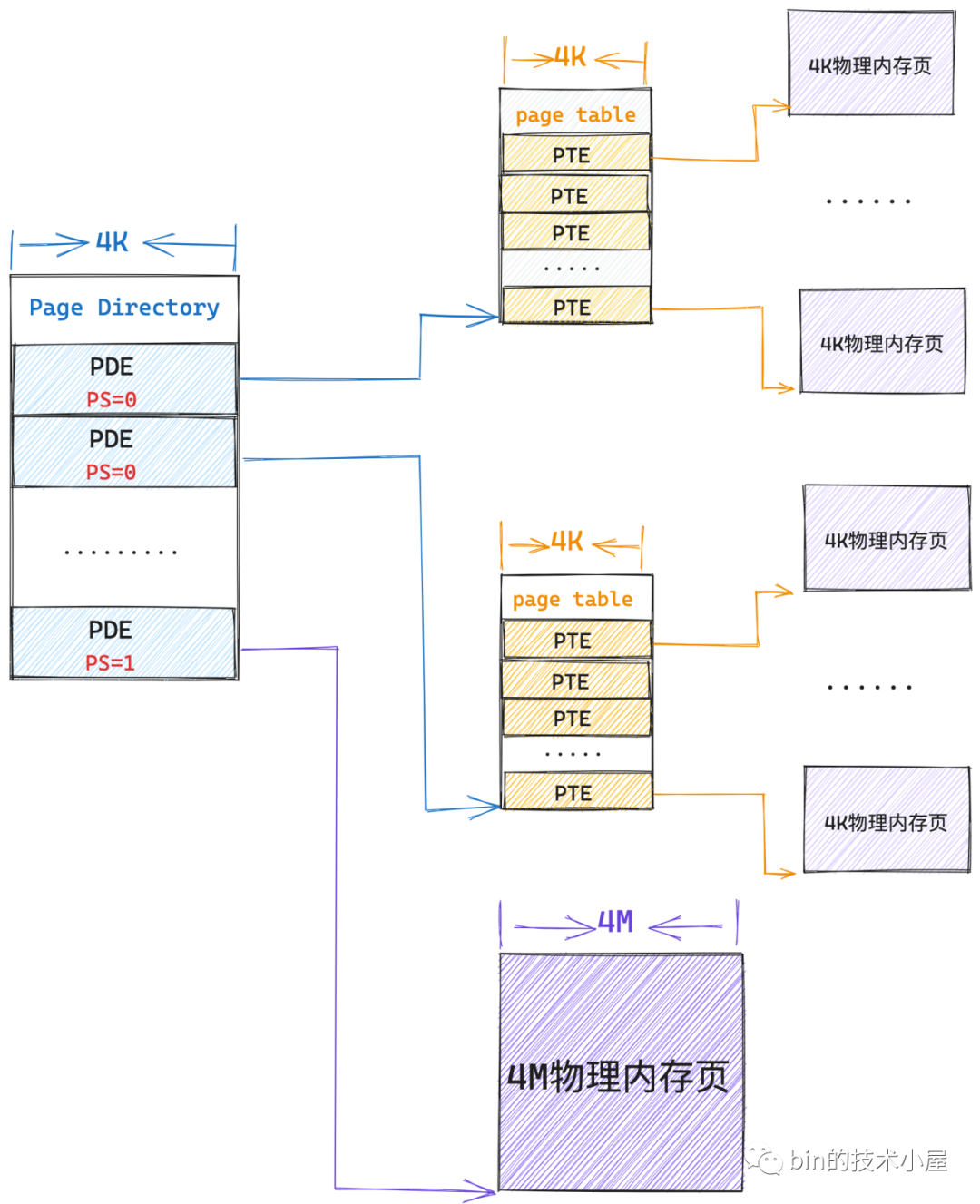
筆者在前面的小節中曾介紹過,在二級頁表體系下,頁目錄表中的一個 PDE 可以對映的實體記憶體空間是 4M ,既然這樣,PDE 也可以直接指向一張 4M 的記憶體大頁。為什麼核心還需要支援大頁記憶體呢?
我們都知道 Linux 管理記憶體的最小單位是 page,每個 page 描述 4K 大小的實體記憶體,但在一些記憶體敏感的使用場景中,使用者往往期望使用一些巨型大頁。
因為這些巨型頁要比普通的 4K 記憶體頁要大很多,所以遇到缺頁中斷的情況就會相對減少,由於減少了缺頁中斷所以效能會更高。
另外,由於巨型頁比普通頁要大,所以巨型頁需要的頁表項要比普通頁要少,頁表項裡儲存了虛擬記憶體地址與實體記憶體地址的對映關係,當 CPU 存取記憶體的時候需要頻繁通過 MMU 存取頁表項獲取實體記憶體地址,由於要頻繁存取,所以頁表項一般會快取在 TLB 中,因為巨型頁需要的頁表項較少,所以節約了 TLB 的空間同時降低了 TLB 快取 MISS 的概率,從而加速了記憶體存取。
還有一個使用巨型頁受益場景就是,當一個記憶體佔用很大的程序(比如 Redis)通過 fork 系統呼叫建立子程序的時候,會拷貝父程序的相關資源,其中就包括父程序的頁表,由於巨型頁使用的頁表項少,所以拷貝的時候效能會提升不少。
既然 PS 標記為 1 的情況下,PDE 指向的是一個 4M 的物理大頁記憶體,這種情況下核心就把 PDE 當做一個特殊的 」PTE「 使用了,所以 PDE 中的位元位佈局又發生了變化,不過大部分還是和 PTE 一樣的。

不過這裡筆者還是要向大家特殊說明一下,第 13 到 31 位元位的作用,粗略的從總體來講這個範圍的位元位確實是用來儲存 4M 大頁的起始記憶體地址的,所以筆者直接在 31:13 範圍內的位元位直接標記成 4M 大頁的起始記憶體地址。
但是進一步細分來說,其實 4M 記憶體大頁的起始地址都是按照 4M 對齊的,也就是說 4M 大頁的起始記憶體地址的後 22 位全部為 0 ,我們只需要用 10 個位元位就可以標記了,事實上,4M 大頁的起始記憶體地址在核心中就是使用 31:22 範圍內的位元標記的,剩下的位元用來做記憶體地址的擴充套件使用,不過這個和本文主旨無關,筆者就直接忽略了。
和 PTE 一樣,PDE 的相關許可權位元位也定義在核心檔案:/arch/x86/include/asm/pgtable_types.h 中:
#define _PAGE_BIT_PSE 7 /* 4 MB page */
// 從 PDE 中提取 PS 位元位掩碼
#define _PAGE_PSE (_AT(pdeval_t, 1) << _PAGE_BIT_PSE)
我們可以通過如下位運算,從 PDE 中提取 PS 位元位來確定該 PDE 指向的是一級頁表還是 4M 大頁。
native_pde_val(pde) & _PAGE_PSE
4.2 四級頁表
在 32 位系統中,核心主要採用二級頁表體系來進行虛擬記憶體定址,但是到了 64 位系統中,二級頁表明顯就不夠用了,因為二級頁表最多隻能對映 4G 的實體記憶體空間,而 64 位系統中,程序的虛擬定址空間是巨大的,程序的使用者態需要定址 128T 的虛擬記憶體空間,核心態也有 128T 的虛擬記憶體空間。
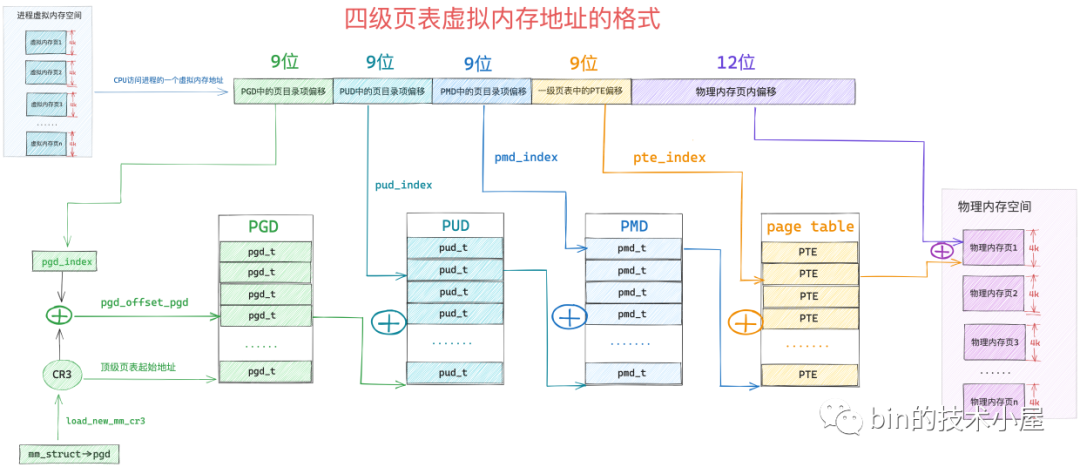
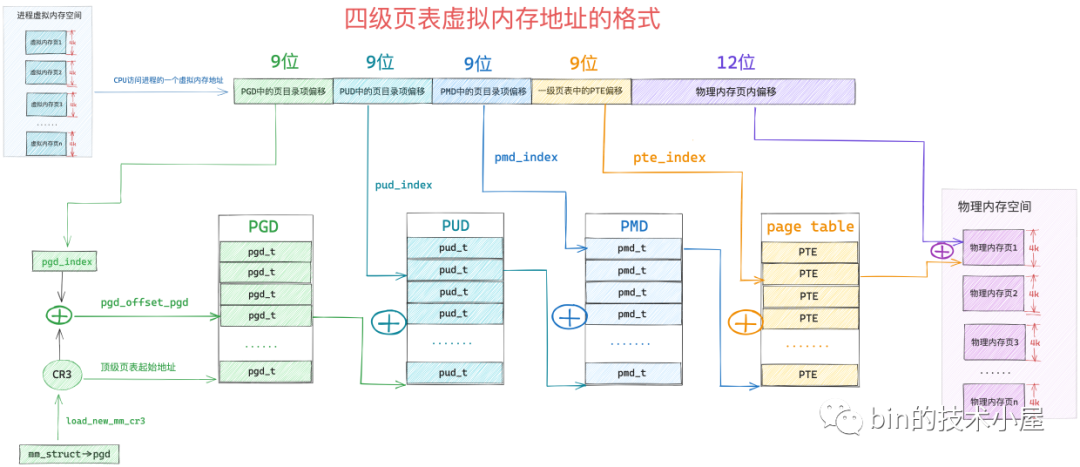
為了能夠定址這麼大的虛擬記憶體空間,核心在 64 位系統中引入了四級頁表體系,當我們清楚了二級頁表的虛擬定址過程,四級頁表就很簡單了,不就是多引入了兩級頁目錄麼,前面小節介紹的多級頁表的本質還是不變的。
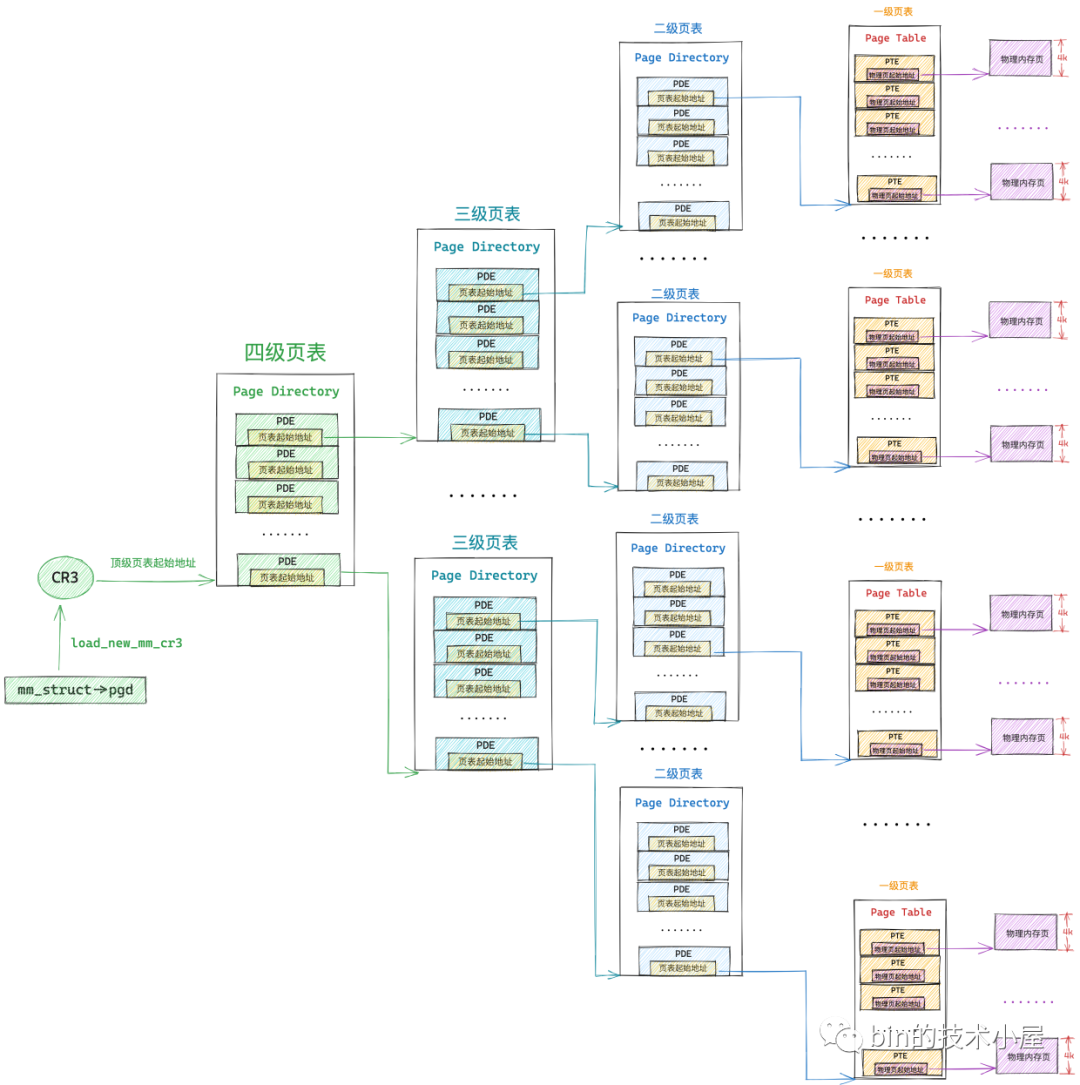
64 位系統中的四級頁表相比 32 位系統中的二級頁表來說,多引入了兩個層級的頁目錄,分別是四級頁表和三級頁表,四級頁表體系完整的對映關係如下圖所示:
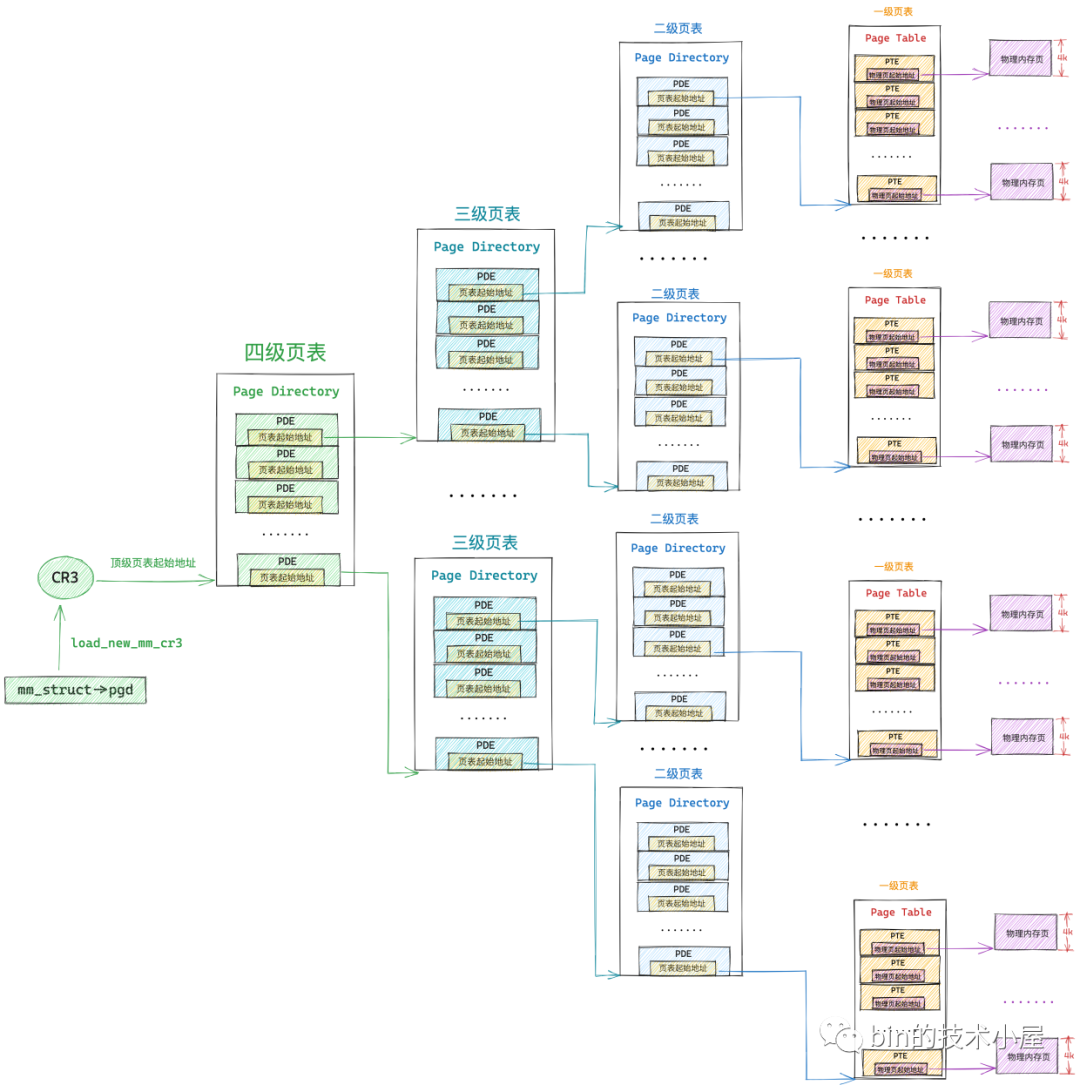
但是在核心中一般不這麼叫,核心中稱上圖中的四級頁表為全域性頁目錄 PGD(Page Global Directory),PGD 中的頁目錄項叫做 pgd_t,PGD 是四級頁表體系下的頂級頁表,儲存在程序 struct mm_struct 結構中的 pgd 屬性中,在程序排程上下文切換的時候,由核心通過 load_new_mm_cr3 方法將 pgd 中儲存的頂級頁表虛擬記憶體地址轉換實體記憶體地址,隨後載入到 cr3 暫存器中,從而完成程序虛擬記憶體空間的切換。
上圖中的三級頁表在核心中稱之為上層頁目錄 PUD(Page Upper Directory),PUD 中的頁目錄項叫做 pud_t 。
二級頁表在這裡也改了一個名字叫做中間頁目錄 PMD(Page Middle Directory),PMD 中的頁目錄項叫做 pmd_t,最底層的用來直接對映實體記憶體頁面的一級頁表,名字不變還叫做頁表(Page Table)
由於在四級頁表體系下,又多引入了兩層頁目錄(PGD,PUD),所以導致其通過虛擬記憶體地址定位 PTE 的步驟又增加了兩步,首先需要定位頂級頁表 PGD 中的頁目錄項 pgd_t,pgd_t 指向的 PUD 的起始記憶體地址,然後在定位 PUD 中的頁目錄項 pud_t,後面的流程就和二級頁表一樣了。
因此 64 位的虛擬記憶體地址格式也就隨著發生了變化:
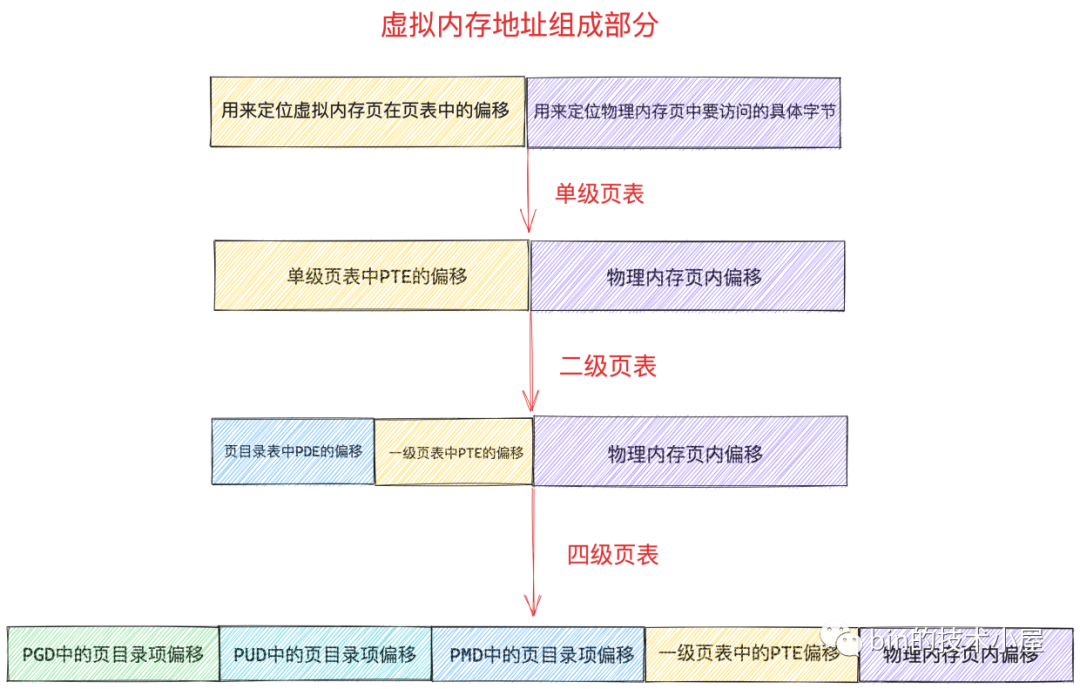
32 位系統中的頁目錄表,頁表和 64 位系統中的頁目錄表,頁表在核心中都是使用一個普通 4K 的實體記憶體頁儲存對映關係的,不同的是 64 位系統中的頁表中的 PTE 以及頁目錄表(PGD,PUD,PMD)中的 PDE 都是佔用 8 個位元組,在核心中都是使用 unsigned long 型別描述:
// 定義在核心檔案:/arch/x86/include/asm/pgtable_64_types.h
typedef unsigned long pteval_t;
typedef unsigned long pmdval_t;
typedef unsigned long pudval_t;
typedef unsigned long pgdval_t;
typedef struct { pteval_t pte; } pte_t;
// 定義在核心檔案:/arch/x86/include/asm/pgtable_types.h
typedef struct { pmdval_t pmd; } pmd_t;
typedef struct { pudval_t pud; } pud_t;
typedef struct { pgdval_t pgd; } pgd_t;
核心這裡使用 struct 結構來包裹 unsigned long 型別的目的是要確保這些頁目錄項以及頁表項只能被專門的輔助函數存取,不能直接存取。
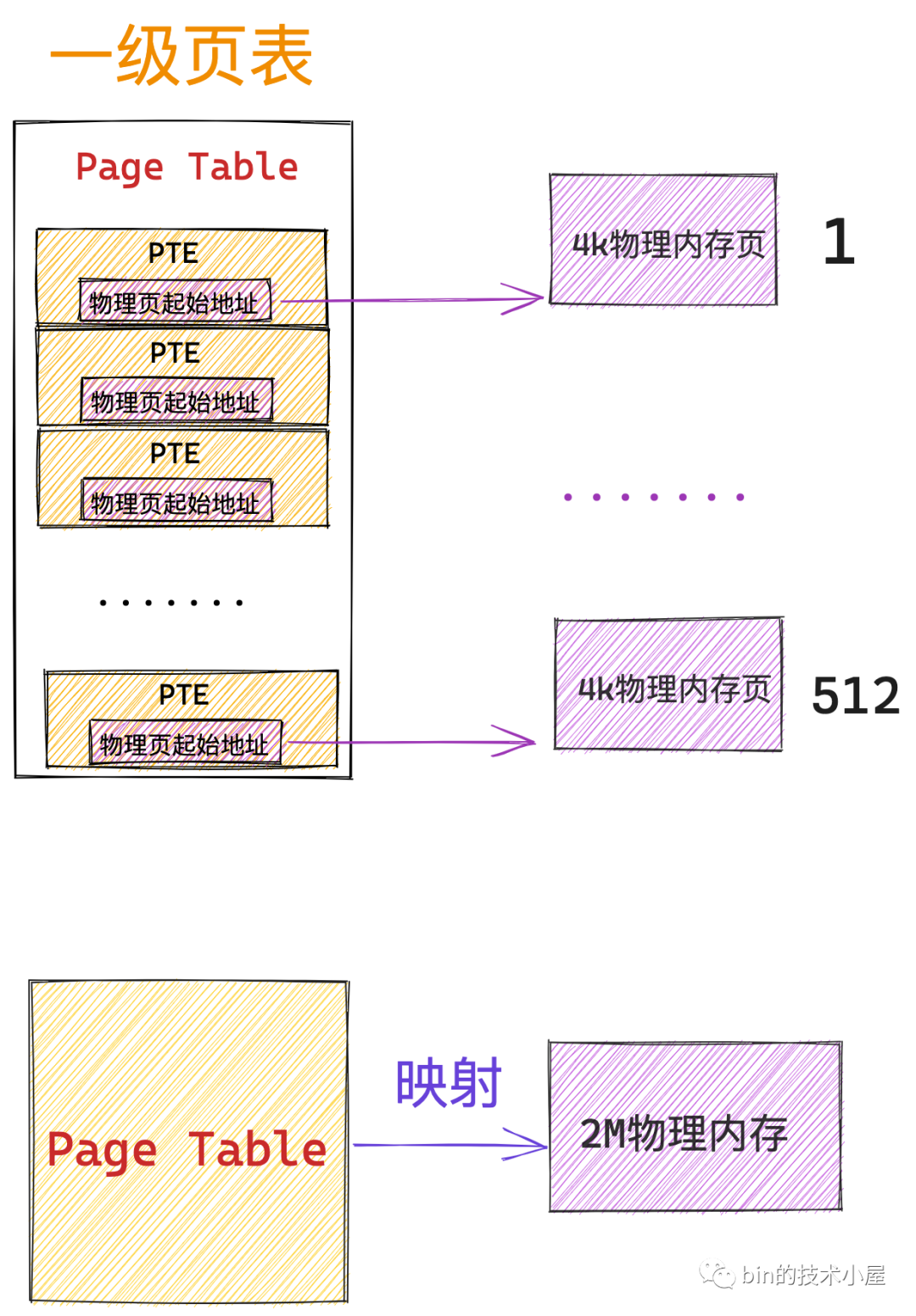
一張頁表 4K 大小,頁表中的一個 PTE 佔用 8 個位元組,所以在 64 位系統中一張頁表只能包含 512 個 PTE,在核心中使用 PTRS_PER_PTE 常數來表示一張頁表中可以容納的 PTE 個數,用 PAGE_SHIFT 常數表示一個實體記憶體頁的大小:2^PAGE_SHIFT。
/*
* entries per page directory level
*/
#define PTRS_PER_PTE 512
/* PAGE_SHIFT determines the page size */
#define PAGE_SHIFT 12
要定址頁表中這 512 個 PTE,我們用 9 個 bit 就可以了,因此上圖虛擬記憶體地址中的 一級頁表中的 PTE 偏移 佔用 9 個 bit 位。而一個 PTE 可以對映 4K 大小的實體記憶體(一個實體記憶體頁),所以在 64 位的四級頁表體系下,一張一級頁表可以對映的實體記憶體空間大小為 2M 大小。
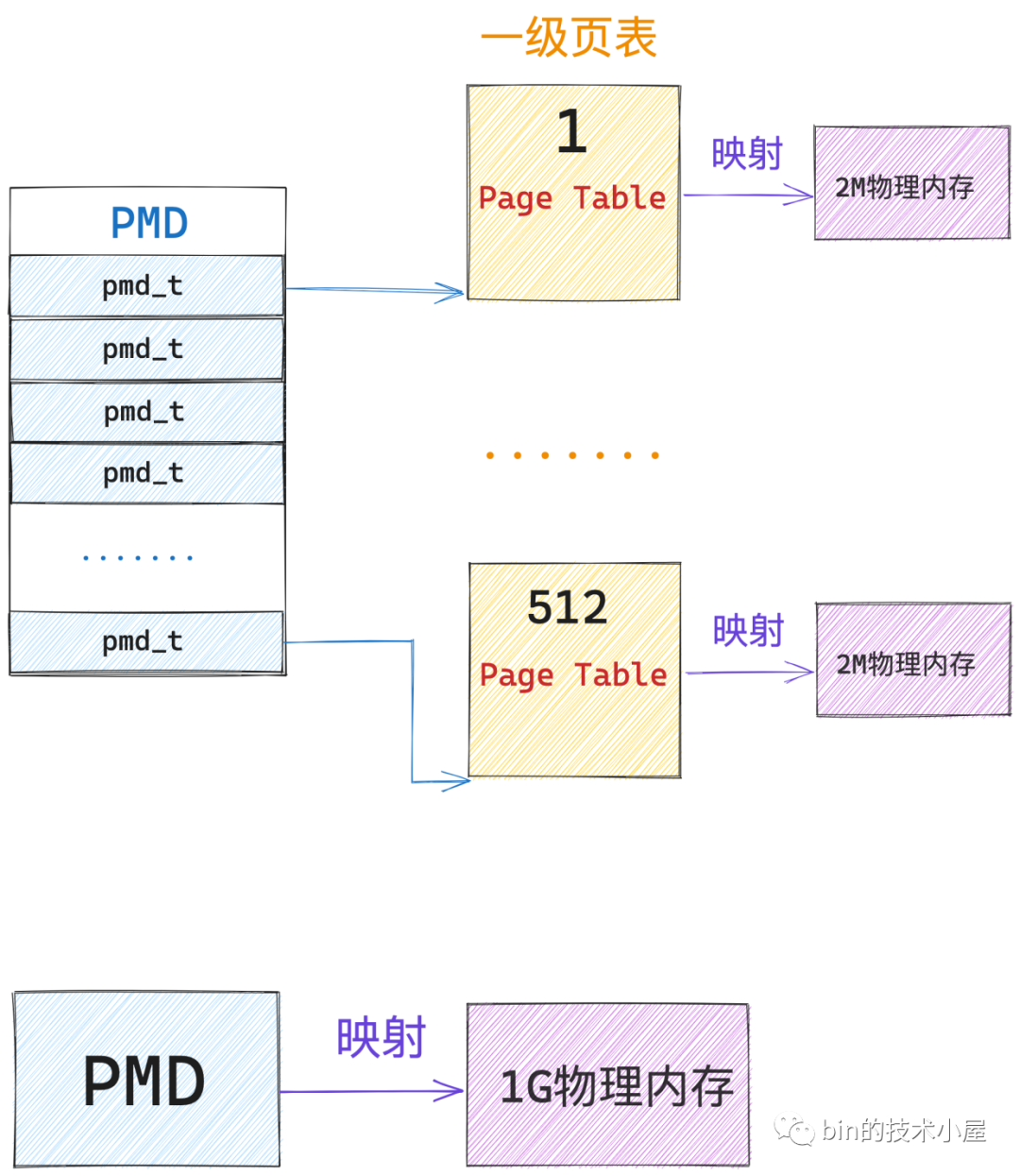
一張中間頁目錄 PMD 也是 4K 大小,PMD 中的頁目錄項 pmd_t 也是佔用 8 個位元組,所以一張 PMD 中只能容納 512 個 pmd_t,核心中使用 PTRS_PER_PMD 常數來表示 PMD 中可以容納多少個頁目錄項 pmd_t。因次 64 位虛擬記憶體地址中的 PMD中的頁目錄偏移 使用 9 個 bit 就可以表示了。
/*
* PMD_SHIFT determines the size of the area a middle-level
* page table can map
*/
#define PMD_SHIFT 21
#define PTRS_PER_PMD 512
而一個 pmd_t 指向一張一級頁表,所以一個 pmd_t 可以對映的實體記憶體為 2M,核心中使用 PMD_SHIFT 常數來表示一個 pmd_t 可以對映的實體記憶體範圍:2^PMD_SHIFT。一張 PMD 可以對映 1G 的實體記憶體。
同理我們知道,一張上層頁目錄 PUD 中可以容納 512 個頁目錄項 pud_t,核心中使用 PTRS_PER_PUD 常數來表示 PUD 中可以容納多少個頁目錄項 pud_t。 64 位虛擬記憶體地址中的 PUD中的頁目錄偏移 也是使用 9 個 bit 就可以表示了。
/*
* 3rd level page
*/
#define PUD_SHIFT 30
#define PTRS_PER_PUD 512
核心中使用 PUD_SHIFT 常數來表示一個 pud_t 可以對映的實體記憶體範圍:2^PUD_SHIFT,一個 pud_t 指向一張 PMD,因此可以對映 1G 的實體記憶體。一張 PUD 可以對映 512G 的實體記憶體。
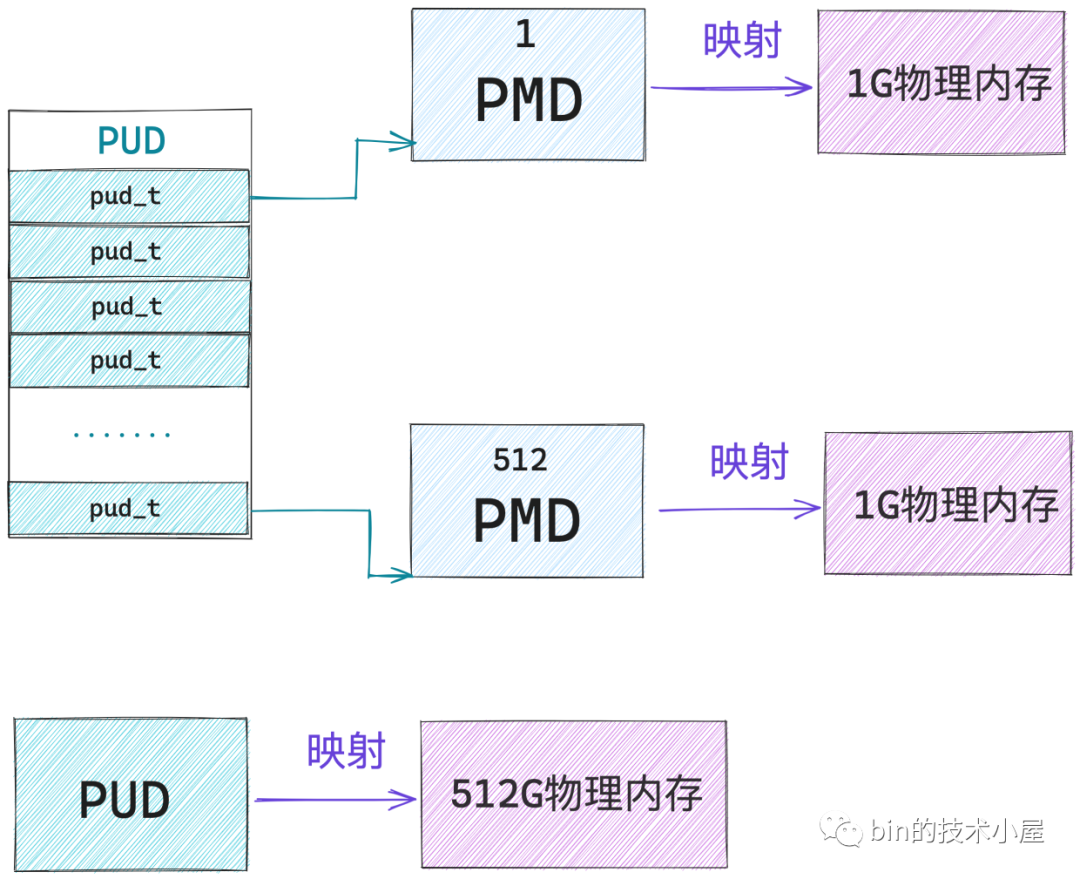
一樣的道理,頂級頁目錄 PGD 中可以容納的頁目錄 pgd_t 個數 PTRS_PER_PGD = 512, 64 位虛擬記憶體地址中的 PGD中的頁目錄偏移 也是使用 9 個 bit 就可以表示了,一個 pgd_t 可以對映的實體記憶體為 2^PGDIR_SHIFT = 512 G。一張 PGD 可以對映的實體記憶體為 256 T,可以說是非常非常巨大了。
/*
* 4th level page in 5-level paging case
*/
#define PGDIR_SHIFT 39
#define PTRS_PER_PGD 512
通過以上內容介紹,我們就得到了 64 位虛擬記憶體地址中的位元位佈局情況:
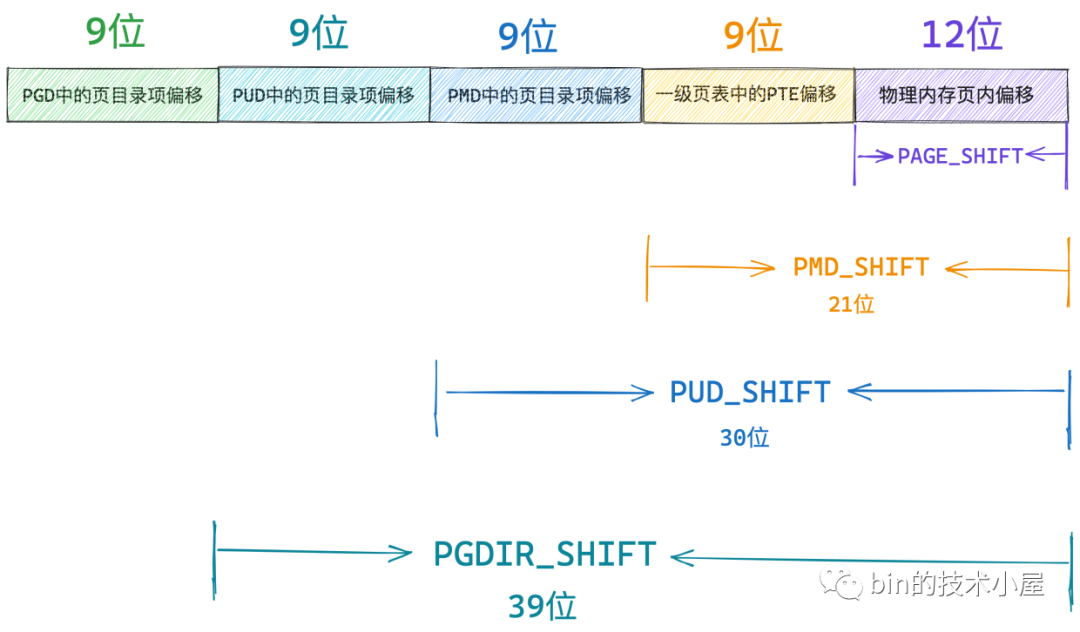
-
PAGE_SHIFT 用來表示頁表中的一個 PTE 可以對映的實體記憶體大小(4K)。
-
PMD_SHIFT 用來表示 PMD 中的一個頁目錄項 pmd_t 可以對映的實體記憶體大小(2M)。
-
PUD_SHIFT 用來表示 PUD 中的一個頁目錄項 pud_t 可以對映的實體記憶體大小(1G)。
-
PGD_SHIFT 用來表示 PGD 中的一個頁目錄項 pgd_t 可以對映的實體記憶體大小(512G)。
這些 XXX_SHIFT 常數在核心中除了可以表示對應頁目錄項對映的實體記憶體大小之外,還可以從一個 64 位虛擬記憶體地址中獲取其在對應頁目錄中的偏移。
比如我們現在需要從一個 64 位虛擬記憶體地址中獲取它在 PGD 中的偏移,可以講虛擬記憶體地址右移 PGD_SHIFT 位來得到:
#define pgd_index(address) ( address >> PGDIR_SHIFT)
然後我們可以通過 PGD 的起始記憶體地址加上 pgd_index 就可以得到虛擬記憶體地址在 PGD 中的頁目錄項 pgd_t 了。
#define pgd_offset_pgd(pgd, address) (pgd + pgd_index((address)))
同樣的道理,我們可以將虛擬記憶體地址右移 PUD_SHIFT 位,並用掩碼 PTRS_PER_PUD - 1 掩掉高 9 位 , 只保留低 9 位,就可以得到虛擬記憶體地址在 PUD 中的偏移了:
PTRS_PER_PUD - 1轉換為二進位制是 9 個 1,用來擷取最低的 9 個位元位。
static inline unsigned long pud_index(unsigned long address)
{
return (address >> PUD_SHIFT) & (PTRS_PER_PUD - 1);
}
我們通過 pgd_t 獲取 PUD 的起始記憶體地址 + pud_index 得到虛擬記憶體地址對應的 pud_t:
/* Find an entry in the third-level page table.. */
static inline pud_t *pud_offset(pgd_t *pgd, unsigned long address)
{
return (pud_t *)pgd_page_vaddr(*pgd) + pud_index(address);
}
根據相同的計算邏輯,我們可以通過 pmd_offset 函數獲取虛擬記憶體地址在 PMD 中的頁目錄項 pmd_t:
/* Find an entry in the second-level page table.. */
static inline pmd_t *pmd_offset(pud_t *pud, unsigned long address)
{
return (pmd_t *)pud_page_vaddr(*pud) + pmd_index(address);
}
static inline unsigned long pmd_index(unsigned long address)
{
return (address >> PMD_SHIFT) & (PTRS_PER_PMD - 1);
}
通過 pte_offset_kernel 函數可以獲取虛擬記憶體地址在一級頁表中的 PTE:
static inline pte_t *pte_offset_kernel(pmd_t *pmd, unsigned long address)
{
return (pte_t *)pmd_page_vaddr(*pmd) + pte_index(address);
}
static inline unsigned long pte_index(unsigned long address)
{
return (address >> PAGE_SHIFT) & (PTRS_PER_PTE - 1);
}
現在我們已經清楚了核心如何通過一系列的 XXX_offset 方法從虛擬記憶體地址中提取對應頁目錄以及頁表中的偏移了,有了這些基礎之後,接下來我們就來看一下四級頁表體系的定址過程:
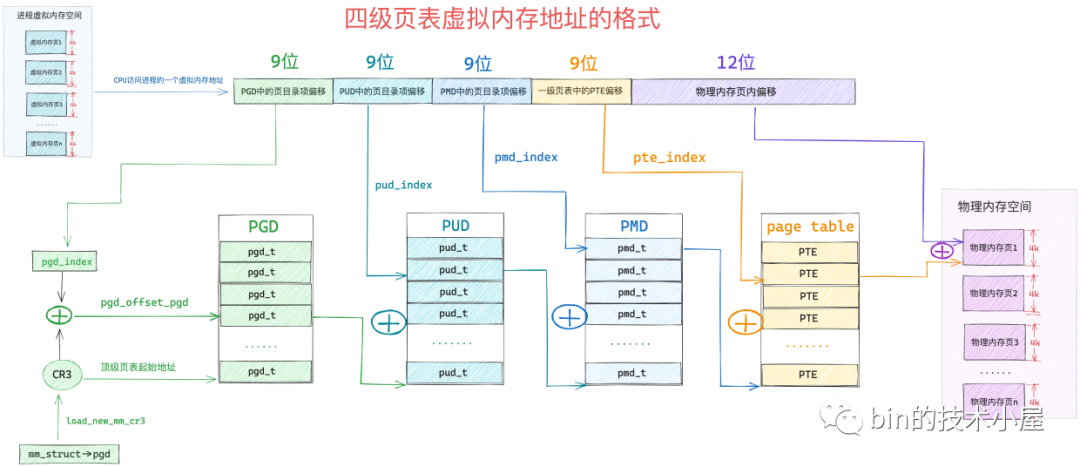
-
首先 MMU 會從 cr3 暫存器中獲取頂級頁目錄 PGD 的起始記憶體地址,然後通過 pgd_index 從虛擬記憶體地址中擷取
PGD 中的頁目錄項偏移,這樣就定位到了具體的一個 pgd_t。 -
pgd_t 中儲存的是 PMD 的起始記憶體地址,通過 pud_index 可以從虛擬記憶體地址中擷取
PUD 中的頁目錄項偏移,從而確定虛擬記憶體地址在 PUD 中的頁目錄項 pud_t。 -
同樣的道理,根據 pud_t 中儲存的 PMD 其實記憶體地址,在加上通過 pmd_index 獲取到的
PMD 中的頁目錄項偏移,定位到虛擬記憶體地址在 PMD 中的頁目錄項 pmd_t。 -
後面的定址流程就和二級頁表一樣了,pmd_t 指向具體頁表的起始記憶體地址,通過 pte_index 擷取虛擬記憶體地址在
一級頁表中的 PTE 偏移,最終定位到一個具體的 PTE 中,PTE 指向的正是虛擬記憶體地址對映的實體記憶體頁面,然後通過虛擬記憶體地址中的低 12 位(實體記憶體頁內偏移),最終確定到一個具體的物理位元組上。
4.2.1. 64 位頁表項
在 64 位系統中,頁表中 PTE 在核心中使用 unsigned long 型別描述,佔用 8 個位元組:
typedef unsigned long pteval_t;
typedef struct { pteval_t pte; } pte_t;
這 64 位的 PTE 佈局如下:

這裡我們以 36 位實體記憶體地址(最多 52 位)為例進行說明,首先實體記憶體頁的起始記憶體地址都是按照 4K 對齊的,所以 36 位實體記憶體地址的低 12 位全部為 0 ,和 32 位的 PTE 一樣,核心可以用這低 12 位來描述 PTE 的許可權位,其中 0 到 8 之間的位元位,在 32 位 PTE 和 64 位 PTE 中含義都是一樣的,這裡筆者不在贅述。
R(11) 這裡的 R 表示 restart,該位元位主要用於 HLAT paging,當遍歷到 R 位是 1 的 PTE 時,MMU 會重新從 CR3 暫存器開始遍歷頁表,這裡我們只做簡單瞭解。
本例中的實體記憶體地址是 36 位的,由於實體記憶體頁都是 4K 對齊的,低 12 位全都是 0 ,因此我們只需要在 PTE 中儲存實體記憶體地址的高 24 位即可,這部分儲存在 PTE 中的第 12 到 35 位元位。
Reserved(51:36) 這些是預留位,全部設定為 0 。Protection(62:59) 這 4 個位元位用於對實體記憶體頁的存取進行控制。
XD(63) 該位元位是 64 位 PTE 中新增的,32 位 PTE 中是沒有的,值為 1 表示該 PTE 所對映的實體記憶體頁面中的資料是可以被執行的。
4.2.2. 64 位頁目錄項
在 64 位系統中使用的四級頁表體系中一共包含了三個層級的頁目錄,它們分別為:全域性頁目錄 PGD(Page Global Directory),上層頁目錄 PUD(Page Upper Directory),PMD(Page Middle Directory)。
這三種型別的頁目錄中的頁目錄項 PDE 在核心中也是使用 unsigned long 型別來描述的,在 64 位系統中佔用 8 個位元組:
typedef unsigned long pmdval_t;
typedef unsigned long pudval_t;
typedef unsigned long pgdval_t;
typedef struct { pmdval_t pmd; } pmd_t;
typedef struct { pudval_t pud; } pud_t;
typedef struct { pgdval_t pgd; } pgd_t;
64 位 PDE 中的位元位佈局如下圖所示:

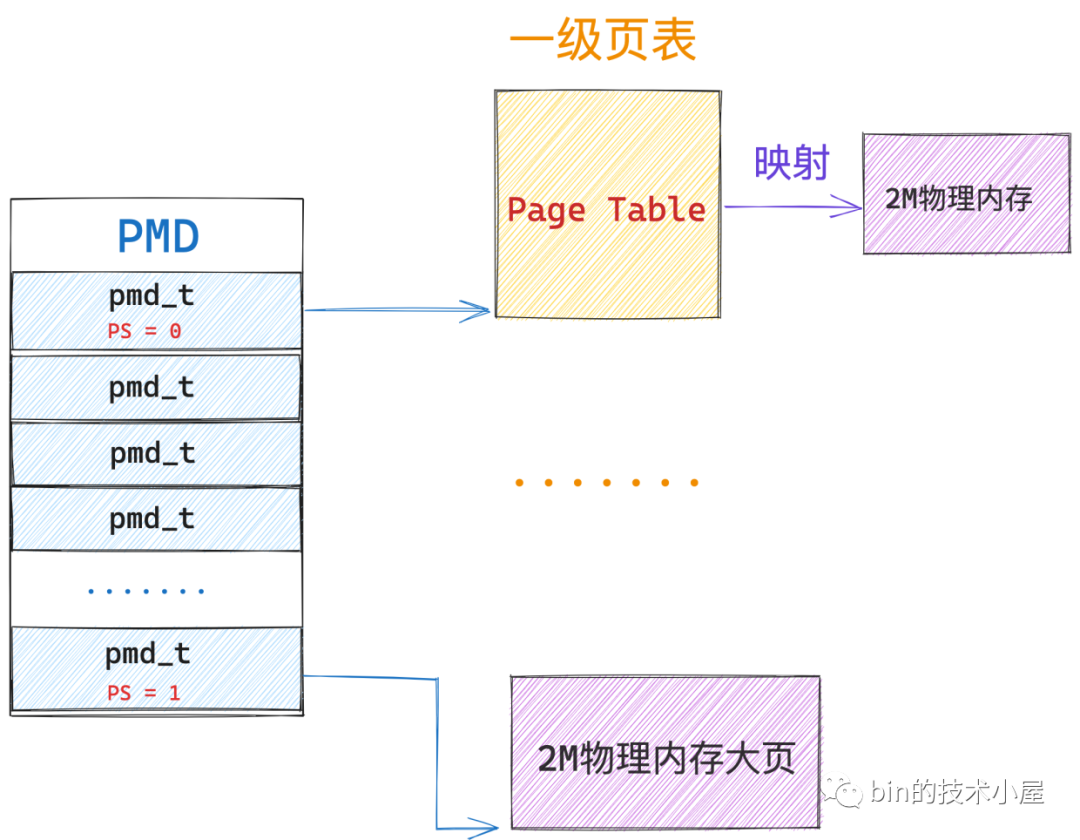
當 64 位 PDE 的 PS(7) 位元位為 0 時,該 PDE 指向的是其下一級頁目錄或者頁表的起始記憶體地址。
當 64 位 PDE 的 PS(7) 位元位為 1 時,該 PDE 指向的就是一個記憶體大頁,對於 PMD 中的頁目錄項 pmd_t 而言,它指向的是一張 2M 大小的實體記憶體大頁。
對於 PUD 中的頁目錄項 pud_t 而言,它指向的是一張 1G 大小的實體記憶體大頁。
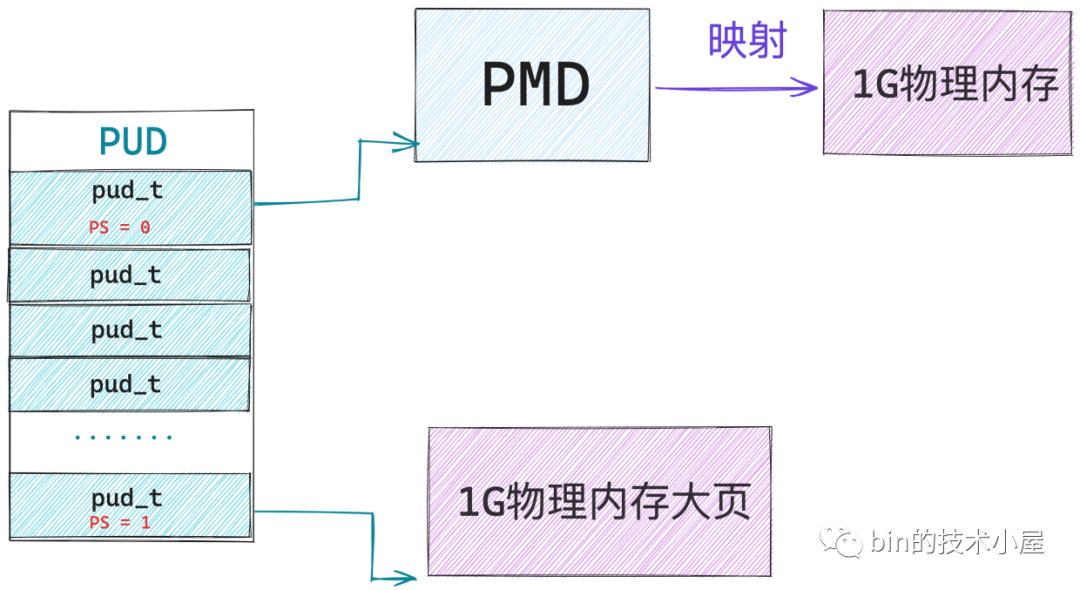
當 64 位 PDE 的 PS(7) 位元位為 1 時,這些頁目錄項 PDE 就被當做了一個特殊的 」PTE「 對待了,因此 PDE 中的位元位佈局又就變成了 64 位 PTE 中的樣子了。

為了表述嚴謹,這裡筆者需要特殊說明的一點是,方便讓大家容易理解,筆者將第 12 到 35 位元位直接標註為了儲存大頁記憶體的地址,但事實上,大頁記憶體的地址並不需要這麼多位來儲存,因為大頁中的記憶體容量比較大,所以大頁個數相對較少,它們的起始記憶體地址不會特別高,使用小於 24 位的位元就可以存放了,多出來的位元位被用作其他目的,但是這些都和本文主旨無關,筆者就直接忽略掉了。
核心當然也會提供一系列的輔助函數來對頁目錄進行操作:
-
pgd_alloc,pud_alloc,pmd_alloc 負責建立初始化對應的頁目錄。
-
mk_pgd,mk_pud,mk_pmd,mk_pte 用於建立相應頁目錄項和頁表項,並初始化上述位元位。
-
以及提供相關 pgd_xxx,pud_xxx,pmd_xxx 等形式的輔助函數,用於對相關位元位的增刪改查操作。
5. CPU 的整個定址過程
本文的重點是要為大家完整清晰地構建出核心中的頁表體系,給大家解釋清楚虛擬記憶體是如何與實體記憶體對映起來的,當我們理解了這些之後,在本小節中,筆者準備帶大家一起探祕下,當 CPU 存取一個程序虛擬記憶體空間中的某個虛擬記憶體地址之後,作業系統背後到底發生了什麼。
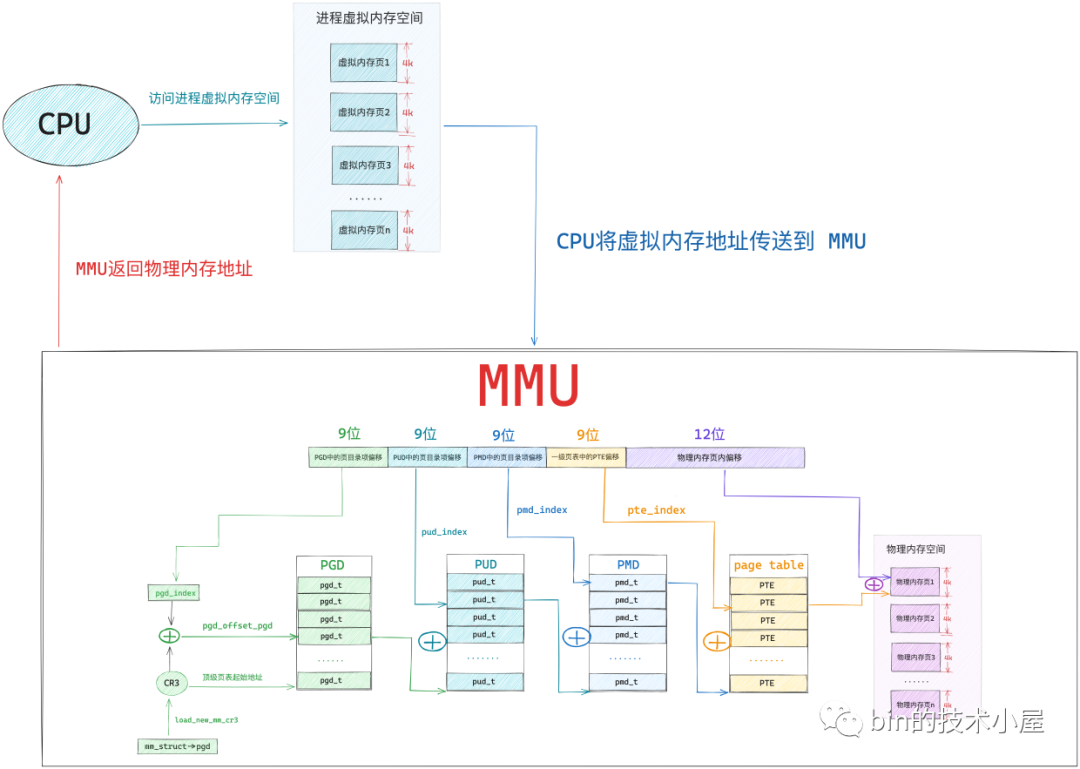
經過本文前邊內容的介紹,上圖中的這個四級頁表的遍歷過程,我們已經非常的清楚了,我們可以明顯的體會到整個地址翻譯的過程需要的步驟還是比較多的,而 CPU 存取記憶體的操作是非常非常頻繁的,如果我們採用核心這種軟體的方式對頁表進行遍歷,效率會非常的差。
而採用一種專門的硬體來對軟體進行加速,無疑是一種最簡單,最直接有效的優化手段,於是在 CPU 中引入了一個專門對頁表進行遍歷的地址翻譯硬體 MMU(Memory Management Unit),有了 MMU 硬體的加持整個地址翻譯的過程就非常的快了。
事實上,上圖中展示的四級頁表的整個遍歷操作均是在 MMU 中進行的:
經過前邊的內容我們知道,這些頁目錄,頁表的本質其實在核心看來都是一張普通的 4K 大小的實體記憶體頁,而實體記憶體頁中經常被存取到的記憶體資料都是快取在 CPU 的快取記憶體 L1 ,L2,L3 CACHE 中的,這樣可以利用區域性性原理加速 CPU 對記憶體的存取。
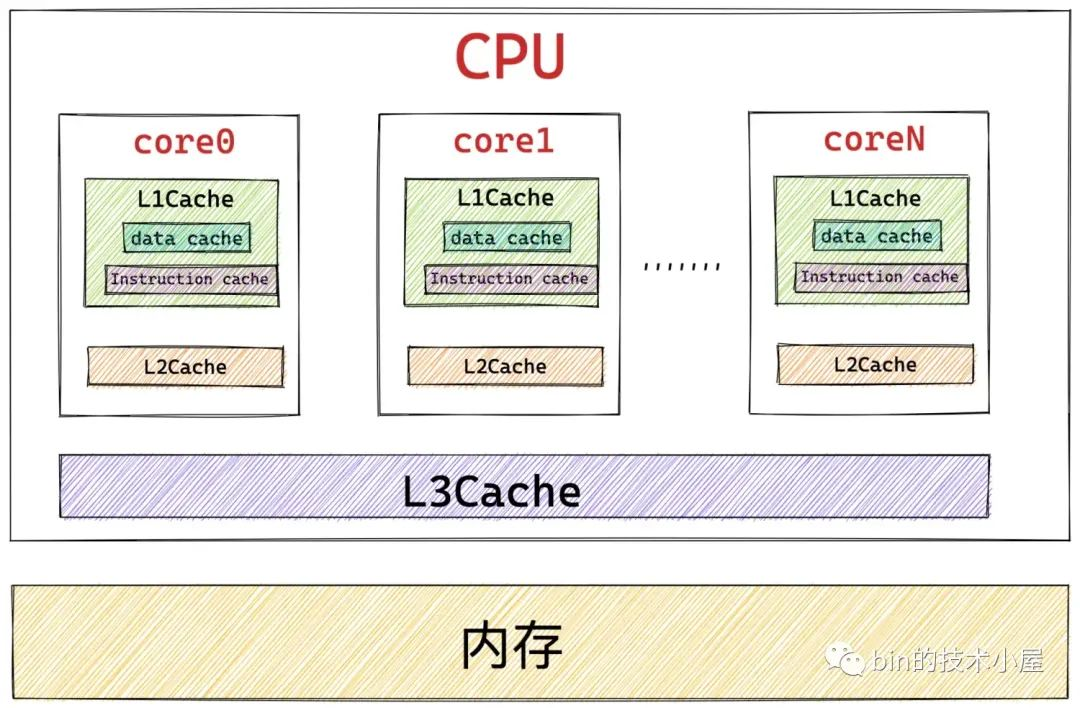
所以頁目錄表和頁表中那些經常被 MMU 遍歷到的頁目錄項 PDE,頁表項 PTE 均會快取在 CPU 的 CACHE 中,這樣 MMU 就可以直接從 CPU 快取記憶體中獲取 PDE , PTE 了,近一步加速了整個地址翻譯的過程。
當 MMU 拿到一個 CPU 正在存取的虛擬記憶體地址之後, MMU 首先會從 CR3 暫存器中獲取頂級頁目錄表 PGD 的起始記憶體地址,然後從虛擬記憶體地址中提取出 pgd_index,從而定位到 PGD 中的一個頁目錄項 pdg_t,MMU 首先會從 CPU 的快取記憶體中去獲取這個 pgd_t,如果 pgd_t 經常被存取到,那麼此時它已經存在於快取記憶體中了,MMU 直接可以進行下一級頁目錄的地址翻譯操作,避免了慢速的記憶體存取。
同樣的道理,在 MMU 經過層層的頁目錄遍歷之後,終於定位到了一級頁表中的 PTE,MMU 也是先會從 CPU 快取記憶體中去獲取 PTE,如果 PTE 不在快取記憶體中,MMU 才會去記憶體中去獲取。獲取到 PTE 之後,MMU 就得到了虛擬記憶體地址背後對映的實體記憶體地址了。
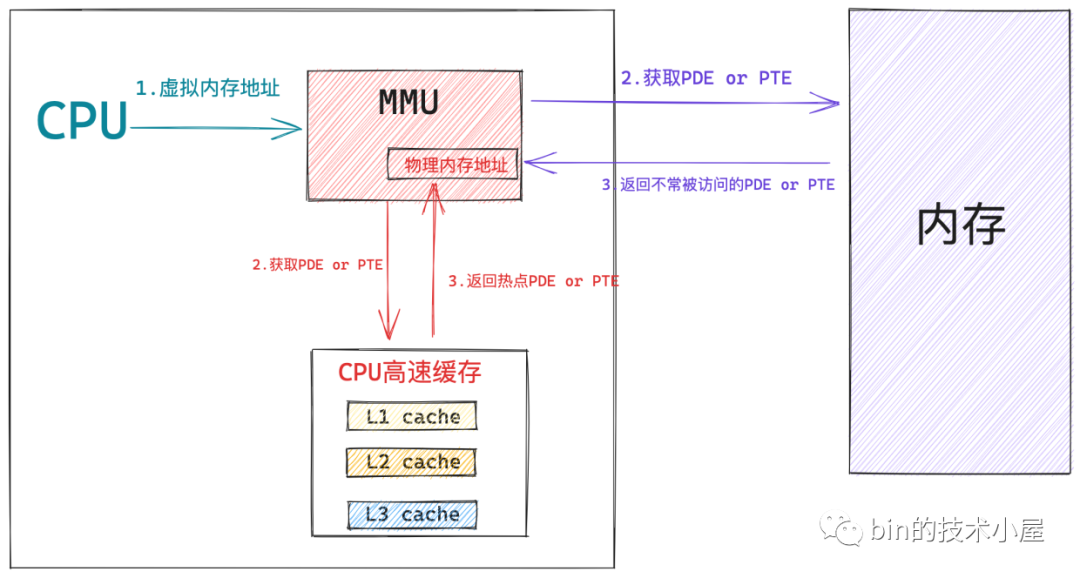
在我們引入 MMU 之後,雖然加快了整個頁表遍歷的過程,但是 CPU 每存取一個虛擬記憶體地址,MMU 還是需要查詢一次 PTE,即便是最好的情況,MMU 也還是需要到 CPU 快取記憶體中去找一下的,即便這樣開銷已經很小了,但是我們還是想近一步降低這個存取 CPU CACHE 的開銷,讓 CPU 訪存效能達到極致,那麼該怎麼辦呢?
既然 MMU 每次都需要查詢一次 PTE,那麼我們能不能在 MMU 中引入一層硬體快取,這樣 MMU 可以把查詢到的 PTE 快取在硬體中,下次再需要的時候直接到硬體快取中拿現成的 PTE 就可以了,這樣一來,CPU 的訪存效率又被近一步加快了。
這個 MMU 中的硬體快取就叫做 TLB(Translation Lookaside Buffer),TLB 是一個非常小的,虛擬定址的硬體快取,專門用來快取被 MMU 翻譯之後的熱點 PTE。當我們引入 TLB 之後,整個定址過程就又有了一些新的變化:
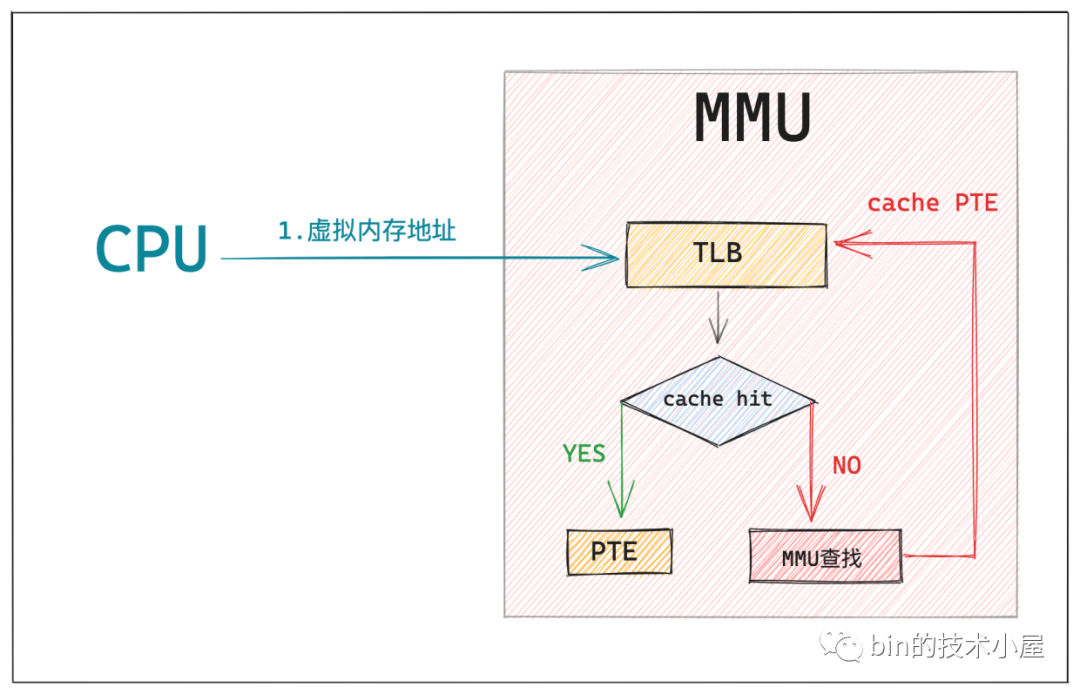
當 CPU 將要存取的虛擬記憶體地址送到 MMU 中翻譯時,MMU 首先會在 TLB 中通過虛擬記憶體定址查詢其對應的 PTE 是否快取在 TLB 中,如果 cache hit ,那麼 MMU 就可以直接獲得現成的 PTE,避免了漫長的地址翻譯過程。
如果 cache miss,那麼 MMU 就需要重新遍歷頁表,然後獲取 PTE 的記憶體地址,從 CPU 快取記憶體或者記憶體中去查詢 PTE,慢速路徑下獲取到 PTE 之後,MMU 會將 PTE 快取到 TLB 中,加快下一次獲取 PTE 的速度。
當 MMU 獲取到 PTE 之後,就可以從 PTE 中拿到實體記憶體頁的起始地址了,在加上虛擬記憶體地址的低 12 位(實體記憶體頁內偏移)這樣就獲取到了虛擬記憶體地址對映的實體記憶體地址了。
那麼當 MMU 拿到我們最終要存取的實體記憶體地址之後,又該怎麼辦呢?
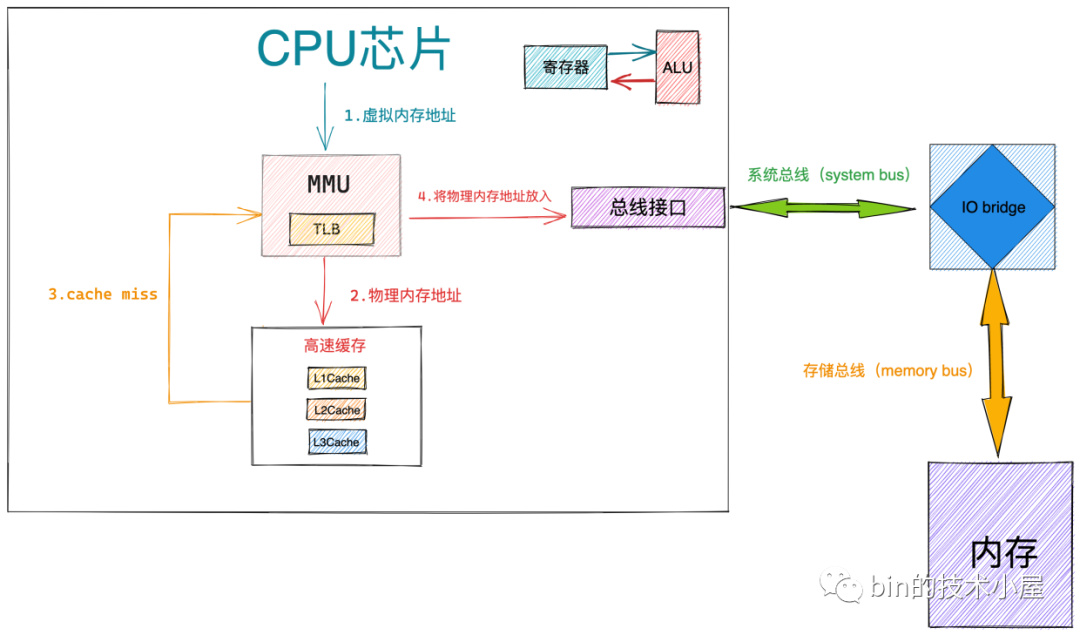
-
當 MMU 獲取到最終的實體記憶體地址,首先會根據實體記憶體地址到 CPU 快取記憶體中去查詢資料,如果 cache hit,整個訪存操作快速結束。
-
如果 cache miss,那麼 MMU 會將實體記憶體地址放到系統匯流排上傳輸,隨後 IO bridge 會將系統匯流排上傳輸的地址訊號傳遞到儲存匯流排上。
-
記憶體中的儲存控制器感受到儲存匯流排上的地址訊號之後,會將實體記憶體地址從儲存匯流排上讀取出來。並根據實體記憶體地址定位到具體的記憶體模組,隨後解析實體記憶體地址從 DRAM 晶片中取出對應實體記憶體地址裡的資料。
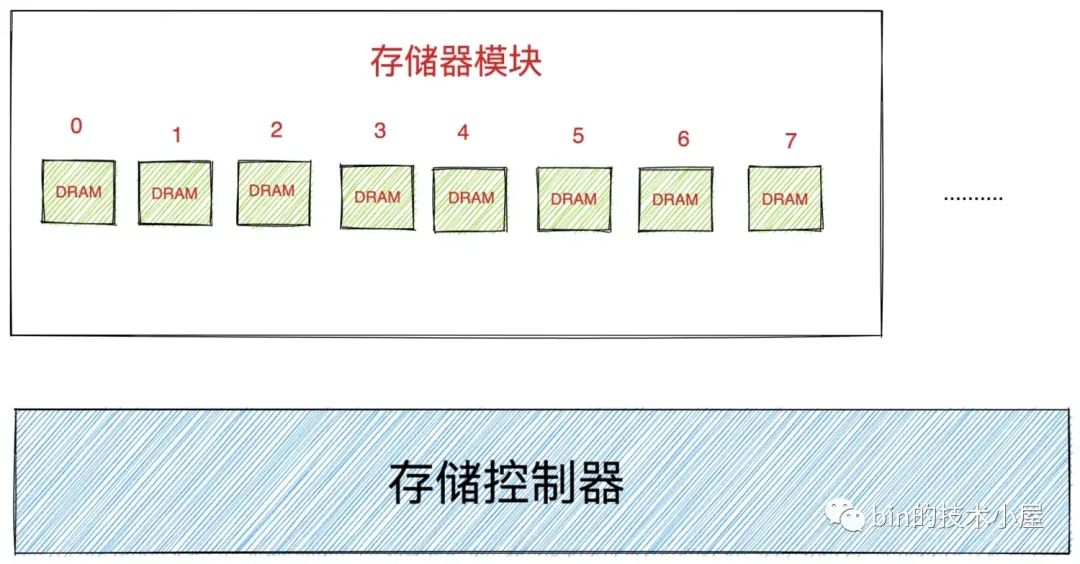
關於 DRAM 晶片的具體存取細節,感興趣的讀者朋友可以回看下筆者之前文章 《一步一圖帶你深入理解 Linux 虛擬記憶體管理》 的 」8. 到底什麼是實體記憶體地址「 小節。
-
儲存控制器將讀取到的資料放到儲存匯流排傳輸上,隨後 IO bridge 將儲存匯流排上的資料訊號轉換為系統匯流排上的資料訊號,然後繼續沿著系統匯流排傳遞。
-
CPU 晶片感受到系統匯流排上的資料訊號之後,將資料從系統匯流排上讀取出來並拷貝到暫存器中,隨後通過 ALU 完成計算。
總結
本文筆者通過頁表體系這條主線脈絡,為大家串講了一下之前介紹的虛擬記憶體管理以及實體記憶體管理的相關內容,在我們回顧完虛擬記憶體管理和實體記憶體管理之後,隨後我們引出了虛擬記憶體如何與實體記憶體進行對映這個問題,並在這個過程中為大家揭露了頁表的本質。
在我們清楚了頁表的本質之後,筆者又沿著頁表體系的演進這條主線,對單級頁表,二級頁表,四級頁表展開了介紹,其中花了一定的篇幅為大家詳細的介紹了 32 位和 64 位頁表項以及頁目錄想的位元位佈局,讓大家真真實實的看到了頁表項和頁目錄項到底長什麼樣子。
在這個基礎之上,筆者又對虛擬記憶體地址格式的組成進行了詳細的剖析,並深入到核心中,帶著大家梳理了核心是如何從虛擬記憶體地址中提取對應頁目錄以及頁表中的偏移的,在這些基礎之上詳細介紹了頁表的整個遍歷過程。
在本文的最後,筆者帶大家又梳理了一遍 CPU 定址的完整過程,對前邊的知識內容做一個串聯回顧。
到這裡頁表相關的知識內容,筆者就為大家介紹完了,感謝大家的收看,我們下篇文章見~~~~~~