飛槳paddlespeech語音喚醒推理C定點實現
前面的文章(飛槳paddlespeech語音喚醒推理C浮點實現)講了飛槳paddlespeech語音喚醒推理的C浮點實現。但是嵌入式裝置通常CPU頻率低和memory小,在嵌入式裝置上要想流暢的執行語音喚醒功能,通常用的是定點實現。於是我就在浮點實現(把折積層和相應的batchNormal層合併成一個折積層)的基礎上做了定點實現。需要說明的是目前完成的是16bit的定點實現,後面會在此基礎上做8bit的定點實現。
做定點實現主要包括兩部分工作,一是模型引數的量化和定Q格式等,二是基於Q格式的定點實現。關於模型引數的量化,我曾寫過相關的文章(深度學習中神經網路模型的量化),有興趣的可以去看看。我用的是對稱量化,這裡簡述一下這部分的工作。
1, 在python下根據paddlepaddle提供的API(named_parameters)得到模型每層的引數(weight & bias),同時看每層的weight和bias的絕對值的最大值,從而確定引數的Q格式,再以這個Q格式對weight 和bias做量化。
2, 在python下得到測試集裡非常多個檔案每層的輸入和輸出的絕對值的最大值,從而確定每層的輸入和輸出的Q格式。
至於程式碼的定點化,主要包括如下幾點:
1, 折積層的定點化
主要是做好乘累加以及輸出的移位和防飽和處理。在文章(深度學習中神經網路模型的量化)裡有詳細描述,這裡就不細講了。
2, sigmoid的定點化
調研了一下,sigmoid的定點化主要用查表法來實現。Sigmoid(x)在x<=-8時近似為0,在x>=8時近似為1,因此做表時在[-8,8)之間就可以了。 若表中有256個值,則表中x的間隔是16/256 = 0.0625。表中第一個值對應的是x=-8時sigmoid的值,第二個值對應的是x=-7.9375(-8 + 0.0635 = -7.9375)時sigmoid的值,以此類推。Sigmoid輸出的取值範圍是(0,1),因此用的Q格式是Q0.15。例如當x=0時,sigmoid(0) = 0.5,表示成Q0.15格式是0x4000。當x在[-8,8)範圍內每隔0.0625的256個sigmoid值都算出來並換算成Q0.15格式,就得到表中的256個值了。
具體實現時參考率CMSIS_5的程式碼,如下圖:
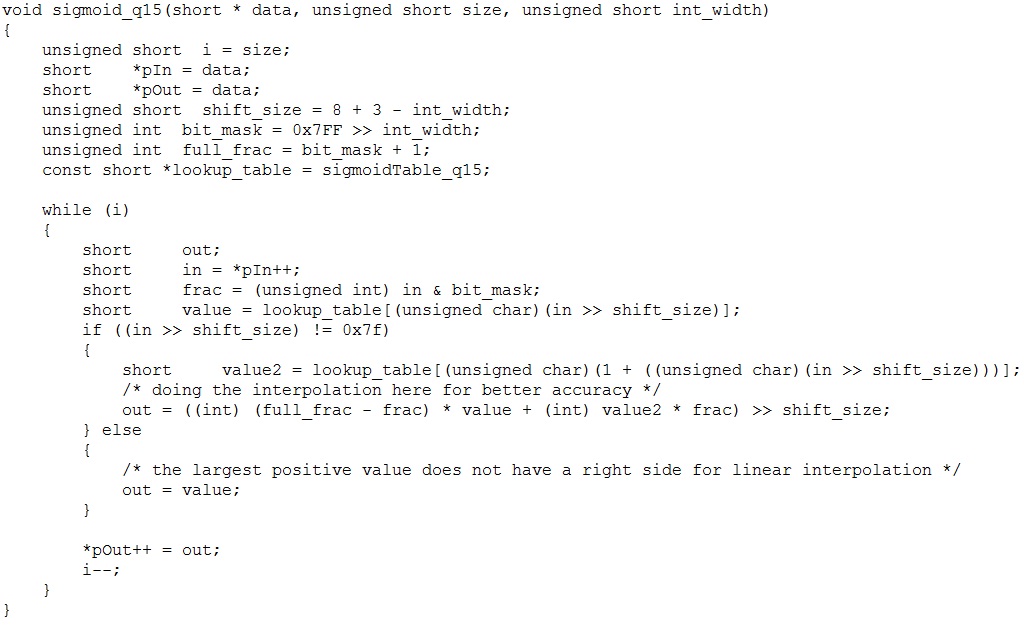
做表時把前128個值(x < 0時的)與後128個值(x>=0時的)做了位置上的互換。主要是因為處理時先對x定點化後的16位元輸入值做右移8位元處理,就變成了8位元的值,再變成unsigned char(U8)用於做表的索引。 U8(0) = 0, U8(127) = 127, 但U8(-128) = 128, U8(-127) = 129, ……, U8(-1) = 255。所以表中的位置前後部分就互換了。再看sigmoid層的輸入與sigmoid函數的輸入的關係。 假設sigmoid函數輸入的16位元定點值為0x1869,右移8位元后為0x18,即為24。表中第24個代表的是x=1.5(24 * 0.0675 = 1.5)時的sigmoid值。我的sigmoid層的輸入Q格式是Q7.8, 1.5用Q7.8表示就是0x0180, 而函數中要求的是0x18XX,所以需要把層的輸入的值做左移4位元處理。由於sigmoid函數只對[-8,8)內的值做處理,因此首先需要對層的輸入值做[-8,8)的限幅處理。上面兩步的程式碼如下圖:

調sigmoid_q15()時把int_width設成3,就表示輸入範圍是[-8,8)。 由於輸入的x值不一定正好落在表中的那些點上,如x = 0.0325就落在點0.0和點0.0625之間。 為了使sigmoid的輸出值更準確,函數中用線性插值法求那些不落在點上的sigmoid值。我在文章(基於sinc的音訊重取樣(二):實現)中講過線性插值法,有興趣的可以去看看。要想sigmoid的輸出值更準確,還可以擴大表裡值的個數,比如變成512個值,代價是多用些memory。
3, 確定好評估的指標
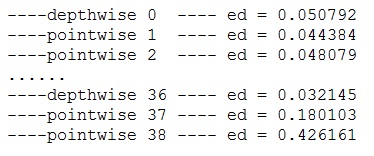
我在文章(深度學習中神經網路模型的量化)中對評估指標有所描述。這裡我選用的是歐氏距離(Euclidean Distance)。具體偵錯時浮點實現和定點實現並行執行。即算出的浮點的fbank值作為浮點實現模型的輸入,將浮點的Fbank值根據定標轉換成定點值作為定點實現模型的輸入,然後每層的浮點實現和定點實現並行執行。浮點實現得到的結果是浮點值,定點實現得到的結果是定點值,再根據輸出的Q格式轉換成浮點值。最後再用歐氏距離對輸出結果進行評估。下圖給出了某一depthwise折積層的實現程式碼。先做浮點的折積層運算,結果儲存在fbankFloat裡,然後做定點的折積層運算,結果儲存在fbankFix裡,再根據輸出的Q格式將fbankFix轉換成浮點值,最後算歐氏距離。歐氏距離越小越好。

下圖給出了偵錯好後部分層的歐氏距離的值,都是很小的(圖中0/1/2等表示折積層ID)。
4,如何偵錯
模型定點化偵錯時要從第一層到最後一層一層一層的偵錯,只有當上一層的歐氏距離達標後再去調下一層。具體到偵錯某一層時,通過log找到那些浮點值與定點轉浮點後的值差值較大的值,再到浮點實現和定點實現裡列印出輸入和運算後的具體值,分析具體原因。有可能是定點實現裡移位防飽和等沒做好,也有可能是引數量化沒作對,還有可能是輸入和輸出的Q格式沒定好導致誤差偏大等。在定輸入和輸出的Q格式時,是根據絕對值的最大值來的。如果發現精度不夠,有可能需要調整輸入或輸出的Q格式(小數位要多一位,依據是看超出定標最大值出現的次數,次數佔比較小就可以)。
偵錯時是用一個音訊檔去調。等模型偵錯完成後要在一個大的資料集上對定點實現做全面的評估,看喚醒率和誤喚醒率的變化。我做完定點實現後在一個有兩萬五千多音訊檔的資料集上做評估,跟浮點實現比,喚醒率下降了0.2%,誤喚醒率上升了0.3%。說明定點化後效能沒有出現明顯的下降。