手寫raft(一) 實現leader選舉
1. 一致性演演算法介紹
1.1 一致性同步與Paxos演演算法
- 對可靠性有很高要求的系統,通常都會額外部署1至多個機器為備用副本組成主備叢集,避免出現單點故障。
有狀態的系統需要主節點與備用副本間以某種方式進行資料複製,這樣主節點出現故障時就能快速的令備用機器接管系統以達到高可用的目的。 - 常見的主備複製方式是非同步、弱一致性的,例如DNS系統,mysql、redis(7.0之前)等資料庫的主備複製,或者通過某種訊息中介軟體來進行解耦,即在CAP中選擇了AP(高可用、分割區容錯)而捨棄了C(強一致性)。
弱一致性的AP相比強一致CP的複製有著許多優點:效率高(多個單次操作可以批次處理),耦合性低(備份節點掛了也不影響主節點工作),實現相對簡單等等。
但AP複製最大的缺點就是喪失了強一致性,主節點在操作完成響應使用者端後,但還未成功同步到備份節點前宕機,對應的變更存在著丟失的風險,因此AP的方案不適用於對一致性有苛刻要求的場合。 - 最原始的強一致性主備同步,即主節點在每一個備份節點同步完成後才能響應使用者端成功的方案效率太低,可用性太差(任意一個備份節點故障就會使得叢集不可用)。
因此基於多數派的分散式強一致演演算法被髮明瞭出來,其中最早被提出的便是Paxos演演算法。但Paxos演演算法過於複雜,在分散式環境下有大量的case需要得到正確的實現,因此時至今日也沒有多少系統真正的將Paxos落地。
1.2 raft演演算法
- 由於Paxos過於複雜的原因,Raft演演算法被髮明瞭出來。Raft演演算法在設計時大量參考了Paxos,也是一個基於紀錄檔和多數派的一致性演演算法,但在很多細節上相比Paxos做了許多簡化。
- 因為Raft比Paxos要簡單很多,更容易被開發人員理解並最終用於構建實際的系統。因此即使raft演演算法的效能相比Paxos要差一點,但目前流行的強一致分散式系統基本都是基於Raft演演算法的。
raft的論文 中將raft演演算法的功能分解為4個模組:
- leader選舉
- 紀錄檔複製
- 紀錄檔壓縮
- 叢整合員動態變更
其中前兩項「leader選舉」和「紀錄檔複製」是raft演演算法的基礎,而後兩項「紀錄檔壓縮」和「叢整合員動態變更」屬於raft演演算法在功能上的重要優化。
2. 自己動手實現一個基於Raft的簡易KV資料庫
通過raft的論文或者其它相關資料,讀者基本能大致理解raft的工作原理。
但紙上得來終覺淺,絕知此事要躬行,親手實踐才能更好的把握raft中的精巧細節,加深對raft演演算法的理解,更有效的閱讀基於raft或其它一致性協定的開源專案原始碼。
MyRaft介紹
在這個系列部落格中會帶領讀者一步步實現一個基於raft演演算法的簡易KV資料庫,即MyRaft。MyRaft的實現基於原始的raft演演算法,沒有額外的優化,目的是為了保證實現的簡單性。
MyRaft實現了raft論文中提到的三個功能,即」leader選舉「、」紀錄檔複製「和」紀錄檔壓縮「(在實踐中發現「叢整合員動態變更」對原有邏輯有較大改動而大幅增加了複雜度,限於個人水平暫不實現)。
三個功能會通過三次迭代實驗逐步完成,其中每個迭代都會以部落格的形式分享出來。
MyRaft架構圖
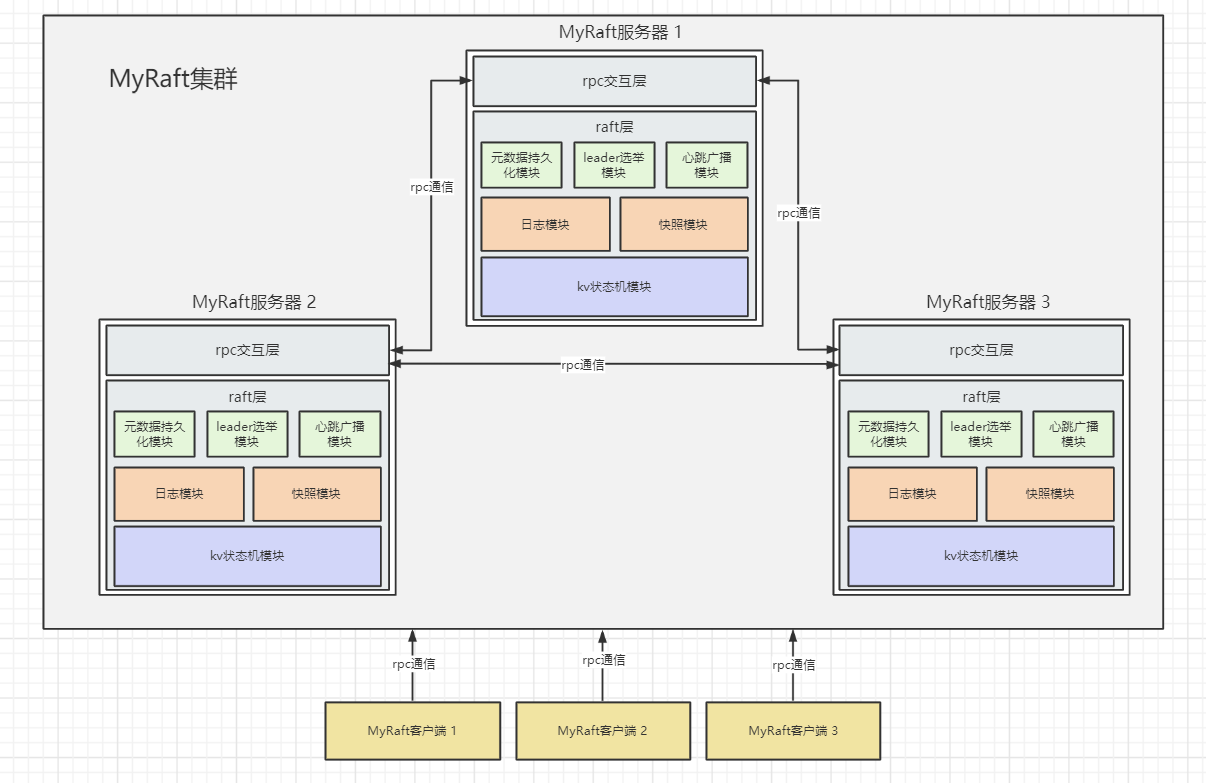
3. MyRaft基礎結構原始碼分析
- 由於是MyRaft的第一個迭代,在這個迭代中需要先搭好MyRaft的基礎骨架。
raft中的每個節點本質上是一個rpc伺服器,同時也是一個rpc的消費者,節點之間通過rpc的方式互相通訊。 - MyRaft使用的rpc框架是上一個實驗中自己實現的MyRpc框架:
部落格地址: https://www.cnblogs.com/xiaoxiongcanguan/p/17506728.html
github地址:https://github.com/1399852153/MyRpc (main分支)
Raft的rpc介面定義
- 因為lab1中只實現leader選舉,簡單起見只定義當前所需的api介面,介面引數相比最終的實現也省去了大量當前用不上的欄位,後續有需要再進行拓展。
public interface RaftService {
/**
* 請求投票 requestVote
*
* Receiver implementation:
* 1. Reply false if term < currentTerm (§5.1)
* 2. If votedFor is null or candidateId, and candidate’s log is at
* least as up-to-date as receiver’s log, grant vote (§5.2, §5.4)
*
* 接受者需要實現以下功能:
* 1. 如果引數中的任期值term小於當前自己的任期值currentTerm,則返回false不同意投票給呼叫者
* 2. 如果自己還沒有投票(FIFO)或者已經投票給了candidateId對應的節點(冪等),
* 並且候選人的紀錄檔至少與被呼叫者的紀錄檔一樣新(比較紀錄檔的任期值和索引值),則投票給呼叫者(返回值裡voteGranted為true)
* */
RequestVoteRpcResult requestVote(RequestVoteRpcParam requestVoteRpcParam);
/**
* 追加紀錄檔條目 AppendEntries
* */
AppendEntriesRpcResult appendEntries(AppendEntriesRpcParam appendEntriesRpcParam);
}
/**
* 請求投票的RPC介面引數物件
*/
public class RequestVoteRpcParam implements Serializable {
/**
* 候選人的任期編號
* */
private int term;
/**
* 候選人的Id
* */
private String candidateId;
/**
* 候選人最新紀錄檔的索引編號
* */
private long lastLogIndex;
/**
* 候選人最新紀錄檔對應的任期編號
* */
private int lastLogTerm;
}
/**
* 請求投票的RPC介面響應物件
* */
public class RequestVoteRpcResult implements Serializable {
/**
* 被呼叫者當前的任期值
* */
private int term;
/**
* 是否同意投票給呼叫者
* */
private boolean voteGranted;
}
/**
* 追加紀錄檔條目的RPC介面引數物件
* */
public class AppendEntriesRpcParam implements Serializable {
/**
* 當前leader的任期值
* */
private int term;
/**
* leader的id
* */
private String leaderId;
}
/**
* 追加紀錄檔條目的RPC介面響應物件
* */
public class AppendEntriesRpcResult implements Serializable {
/**
* 被呼叫者當前的任期值
* */
private int term;
/**
* 是否處理成功
* */
private boolean success;
}
MyRaft的Rpc使用者端與伺服器端實現
/**
* raft的rpc服務
* */
public class RaftRpcServer extends RaftServer {
private final Registry registry;
private final RaftNodeConfig currentNodeConfig;
public RaftRpcServer(RaftConfig raftConfig, Registry registry){
super(raftConfig);
this.currentNodeConfig = raftConfig.getCurrentNodeConfig();
this.registry = registry;
}
@Override
public void init(List<RaftService> otherNodeInCluster) {
// 先初始化內部模組
super.init(otherNodeInCluster);
// 初始化內部的模組後,啟動rpc
initRpcServer();
}
public List<RaftService> getRpcProxyList(List<RaftNodeConfig> otherNodeInCluster){
return initRpcConsumer(otherNodeInCluster);
}
private List<RaftService> initRpcConsumer(List<RaftNodeConfig> otherNodeInCluster){
ConsumerBootstrap consumerBootstrap = new ConsumerBootstrap()
.registry(registry)
.loadBalance(new SimpleRoundRobinBalance());
// 註冊消費者
Consumer<RaftService> consumer = consumerBootstrap.registerConsumer(RaftService.class,new FastFailInvoker());
RaftService raftServiceProxy = consumer.getProxy();
List<RaftService> raftRpcConsumerList = new ArrayList<>();
for(RaftNodeConfig raftNodeConfig : otherNodeInCluster){
// 使用rpc代理的使用者端
raftRpcConsumerList.add(new RaftRpcConsumer(raftNodeConfig,raftServiceProxy));
}
return raftRpcConsumerList;
}
private void initRpcServer(){
URLAddress providerURLAddress = new URLAddress(currentNodeConfig.getIp(),currentNodeConfig.getPort());
Provider<RaftService> provider = new Provider<>();
provider.setInterfaceClass(RaftService.class);
provider.setRef(this);
provider.setUrlAddress(providerURLAddress);
provider.setRegistry(registry);
provider.export();
NettyServer nettyServer = new NettyServer(providerURLAddress);
nettyServer.init();
}
}
public class RaftRpcConsumer implements RaftService {
private static final Logger logger = LoggerFactory.getLogger(RaftRpcConsumer.class);
private final RaftNodeConfig targetNodeConfig;
private final RaftService raftServiceProxy;
public RaftRpcConsumer(RaftNodeConfig targetNodeConfig, RaftService proxyRaftService) {
this.targetNodeConfig = targetNodeConfig;
this.raftServiceProxy = proxyRaftService;
}
@Override
public RequestVoteRpcResult requestVote(RequestVoteRpcParam requestVoteRpcParam) {
// 強制指定rpc目標的ip/port
setTargetProviderUrl();
RequestVoteRpcResult result = raftServiceProxy.requestVote(requestVoteRpcParam);
return result;
}
@Override
public AppendEntriesRpcResult appendEntries(AppendEntriesRpcParam appendEntriesRpcParam) {
// 強制指定rpc目標的ip/port
setTargetProviderUrl();
AppendEntriesRpcResult result = raftServiceProxy.appendEntries(appendEntriesRpcParam);
return result;
}
private void setTargetProviderUrl(){
ConsumerRpcContext consumerRpcContext = ConsumerRpcContextHolder.getConsumerRpcContext();
consumerRpcContext.setTargetProviderAddress(
new URLAddress(targetNodeConfig.getIp(),targetNodeConfig.getPort()));
}
}
raft服務後設資料持久化
- raft的論文中提到raft服務中需要持久化的三個要素:currentTerm(當前伺服器的任期值)、votedFor(當前伺服器在此之前投票給了誰)和logs(raft的操作紀錄檔,與本篇部落格無關在lab2中才會引入)。
- currentTerm和votedFor需要持久化的原因是為了避免raft節點在完成leader選舉的投票後宕機,重啟恢復後如果這兩個資料丟失了就很容易在同一任期內投票給多個候選人而出現叢集腦裂(即多個合法leader)。
- MyRaft用磁碟檔案進行持久化,簡單起見在currentTerm或votedFor更新時加寫鎖,通過原子性的整體刷盤來完成持久化。
public class RaftServerMetaData {
/**
* 當前伺服器的任期值
* */
private int currentTerm;
/**
* 當前伺服器在此之前投票給了誰?
* (候選者的serverId,如果還沒有投遞就是null)
* */
private String votedFor;
}
public class RaftServerMetaDataPersistentModule {
/**
* 當前伺服器的任期值
* */
private volatile int currentTerm;
/**
* 當前伺服器在此之前投票給了誰?
* (候選者的serverId,如果還沒有投遞就是null)
* */
private volatile String votedFor;
private final File persistenceFile;
private final ReentrantReadWriteLock reentrantLock = new ReentrantReadWriteLock();
private final ReentrantReadWriteLock.WriteLock writeLock = reentrantLock.writeLock();
private final ReentrantReadWriteLock.ReadLock readLock = reentrantLock.readLock();
public RaftServerMetaDataPersistentModule(String serverId) {
String userPath = System.getProperty("user.dir") + File.separator + serverId;
this.persistenceFile = new File(userPath + File.separator + "raftServerMetaData-" + serverId + ".txt");
MyRaftFileUtil.createFile(persistenceFile);
// 讀取持久化在磁碟中的資料
RaftServerMetaData raftServerMetaData = readRaftServerMetaData(persistenceFile);
this.currentTerm = raftServerMetaData.getCurrentTerm();
this.votedFor = raftServerMetaData.getVotedFor();
}
public int getCurrentTerm() {
readLock.lock();
try {
return currentTerm;
}finally {
readLock.unlock();
}
}
public void setCurrentTerm(int currentTerm) {
writeLock.lock();
try {
this.currentTerm = currentTerm;
// 更新後資料落盤
persistentRaftServerMetaData(new RaftServerMetaData(this.currentTerm,this.votedFor),persistenceFile);
}finally {
writeLock.unlock();
}
}
public String getVotedFor() {
readLock.lock();
try {
return votedFor;
}finally {
readLock.unlock();
}
}
public void setVotedFor(String votedFor) {
writeLock.lock();
try {
if(Objects.equals(this.votedFor,votedFor)){
// 相等的話就不重新整理了
return;
}
this.votedFor = votedFor;
// 更新後資料落盤
persistentRaftServerMetaData(new RaftServerMetaData(this.currentTerm,this.votedFor),persistenceFile);
}finally {
writeLock.unlock();
}
}
private static RaftServerMetaData readRaftServerMetaData(File persistenceFile){
String content = MyRaftFileUtil.getFileContent(persistenceFile);
if(StringUtils.hasText(content)){
return JsonUtil.json2Obj(content,RaftServerMetaData.class);
}else{
return RaftServerMetaData.getDefault();
}
}
private static void persistentRaftServerMetaData(RaftServerMetaData raftServerMetaData, File persistenceFile){
String content = JsonUtil.obj2Str(raftServerMetaData);
MyRaftFileUtil.writeInFile(persistenceFile,content);
}
}
3. leader選舉原理與MyRaft實現解析
leader選舉原理
raft的leader選舉在論文中有較詳細的描述,這裡說一下我認為的關鍵細節。
- Raft演演算法中leader扮演著絕對核心的角色,leader負責處理使用者端的請求、將操作紀錄檔同步給其它的follower節點以及通知follower提交紀錄檔等等。
因此Raft叢集必須基於多數原則選舉出一個存活的leader才能對外提供服務,並且一個任期內只能有一個基於多數票選出的leader。 - raft是非拜占庭容錯共識演演算法,rpc通訊時互動的雙方的請求和響應都是可信的,不會作假,節點執行的行為也符合raft演演算法的規定。
- raft中存在任期term的概念,任期值只會單向遞增,可以理解為一個虛擬的時間,是raft實現線性一致性關鍵的一環。過去的leader(term值更小的)需要服從、追隨現任的leader(term值更大的)。
- 在raft節點剛啟動時處於follower追隨者狀態。如果一段時間內raft節點沒有接受到來自leader的定時心跳rpc(logEntry為空的appendEntries)通知時就會發起一輪新的選舉。
產生這個現象的原因有很多,比如叢集剛剛啟動還沒有leader;或者之前的leader因為某種原因宕機或與follower的網路通訊出現故障等。 - 發起請求的follower會轉變為candidate候選人狀態,並首先投票給自己。同時並行的向叢集中的其它節點發起請求投票的rpc請求(requestVote),可以理解為給自己拉票。
接收到requestVote請求的節點會根據自身的狀態等資訊決定是否投票給發起投票的節點。
當candidate獲得了叢集中超過半數的投票(即包括自己在內的1票加上requestVote返回投票成功的數量超過半數(比如5節點得到3票,6節點得到4票)),則candidate成為當前任期的leader。
如果沒有任何一個candidate獲得多數選票(沒選出leader,可能是分票了,也可能是網路波動等等),則candidate會將當前任期自增1,則下一次選舉超時時會再觸發一輪新的選舉,迴圈往復直至選出leader。
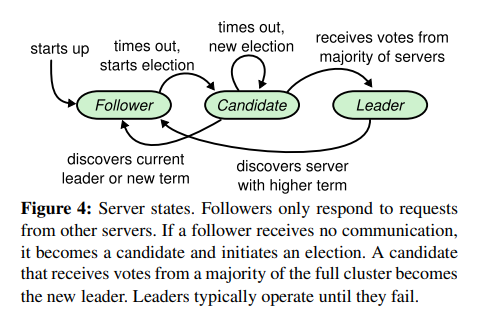
- leader當選後需要立即向其它的節點傳送心跳rpc(logEntry為空的appendEntries),昭告新leader的產生以抑制其它節點發起新的選舉。
心跳rpc必須以一定頻率的定時向所有follower傳送,傳送的時間間隔需要小於設定的選舉超時時間。 - 由於處理requestVote是先到先得的,同一任期內先發起投票請求的candidate會收到票,後傳送的會被拒絕。
假如leader宕機了,則每個follower都會在一段時間後觸發新一輪選舉,如果沒有額外的限制,則每個節點並行的發起選舉很容易導致分票,即自己投給自己,則難以達成共識(取得多數票)。
Raft的論文中提出了隨機化選舉超時時間的方案,即每個follower節點的選舉超時時間是一個固定值再加上一個隨機化的值得到的,這樣很難在同一瞬間都觸發選舉。
隨機超時時間更短的follower能夠最先發起選舉,更快的得到其它節點的投票從而避免分票的情況。
雖然無法完全避免分票,但實踐中發現效果很好,隨機超時時間下通常少數的幾次分票後就能收斂而選出leader來。 - 注意:raft論文在5.4安全性一節中提到,leader選舉對於candidate的紀錄檔狀態有一定的要求(因為只有擁有完整紀錄檔的節點才有資格成為leader,確保leader更替時紀錄檔不會丟失),
但lab1中不支援紀錄檔複製,所以MyRaft在lab1的requestVote實現中省略了相關邏輯。
MyRaft leader選舉原始碼分析
下面基於原始碼展開介紹MyRaft是如何實現raft領導者選舉的。
大致分為以下幾部分:
- raft節點設定
- raft節點定時選舉超時檢查
- candidate發起選舉
- leader定時發起心跳廣播
- raft節點處理requestVote請求
3.1 raft節點設定
- raft服務中有很多引數需要設定,比如服務的ip/port,或者raft相關的選舉超時時間、心跳間隔時間等等。
- MyRaft中統一放到一個叫RaftConfig的類裡維護,後續的功能實現時也會在這個類中進行拓展。
public class RaftConfig {
/**
* 當前服務節點的id(叢集內全域性唯一)
* */
private final String serverId;
/**
* 自己節點的設定
* */
private final RaftNodeConfig currentNodeConfig;
/**
* 整個叢集所有的服務節點的id集合
* */
private final List<RaftNodeConfig> raftNodeConfigList;
/**
* 叢集中多數的值(例如:5節點majorityNum=3,6節點majorityNum=4)
* */
private final int majorityNum;
/**
* 選舉超時時間 單位:秒
* */
private int electionTimeout;
/**
* 選舉超時時間的隨機化區間 單位:毫秒
* */
private Range<Integer> electionTimeoutRandomRange;
/**
* 心跳間隔時間 單位:秒
* */
private int HeartbeatInternal;
}
public class RaftNodeConfig {
private String serverId;
private String ip;
private int port;
}
3.2 raft節點定時選舉超時檢查
- MyRaft中將leader選舉相關的主要邏輯都集中維護在RaftLeaderElectionModule類中。
lastHeartbeatTime屬性用於儲存最後一次收到leader心跳的絕對時間,如果當前節點狀態不是leader,並且發現lastHeartbeatTime距離當前時間已經超過了指定的選舉超時時間則觸發選舉。 - 心跳檢查的超時邏輯集中在HeartbeatTimeoutCheckTask中。
由於需要引入隨機化的心跳超時時間,因此無法使用ScheduledExecutorService的scheduleAtFixedRate方法,改為在每個任務執行完成時再新增一個新任務回去的方式來實現。
/**
* Raft伺服器的leader選舉模組
* */
public class RaftLeaderElectionModule {
private static final Logger logger = LoggerFactory.getLogger(RaftLeaderElectionModule.class);
private final RaftServer currentServer;
/**
* 最近一次接受到心跳的時間
* */
private volatile Date lastHeartbeatTime;
private final ScheduledExecutorService scheduledExecutorService;
private final ExecutorService rpcThreadPool;
public RaftLeaderElectionModule(RaftServer currentServer) {
this.currentServer = currentServer;
this.lastHeartbeatTime = new Date();
this.scheduledExecutorService = Executors.newScheduledThreadPool(3);
this.rpcThreadPool = Executors.newFixedThreadPool(
Math.max(currentServer.getOtherNodeInCluster().size() * 2, 1));
registerHeartbeatTimeoutCheckTaskWithRandomTimeout();
}
/**
* 提交新的延遲任務(帶有隨機化的超時時間)
* */
public void registerHeartbeatTimeoutCheckTaskWithRandomTimeout(){
int electionTimeout = currentServer.getRaftConfig().getElectionTimeout();
if(currentServer.getCurrentTerm() > 0 && currentServer.getRaftConfig().getDebugElectionTimeout() != null){
// debug的時候多等待一些時間
electionTimeout = currentServer.getRaftConfig().getDebugElectionTimeout();
}
long randomElectionTimeout = getRandomElectionTimeout();
// 選舉超時時間的基礎上,加上一個隨機化的時間
long delayTime = randomElectionTimeout + electionTimeout * 1000L;
logger.debug("registerHeartbeatTimeoutCheckTaskWithRandomTimeout delayTime={}",delayTime);
scheduledExecutorService.schedule(
new HeartbeatTimeoutCheckTask(currentServer,this),delayTime,TimeUnit.MILLISECONDS);
}
/**
* 處理投票請求
* 注意:synchronized修飾防止不同candidate並行的投票申請處理,以FIFO的方式處理
* */
public synchronized RequestVoteRpcResult requestVoteProcess(RequestVoteRpcParam requestVoteRpcParam){
if(this.currentServer.getCurrentTerm() > requestVoteRpcParam.getTerm()){
// Reply false if term < currentTerm (§5.1)
// 發起投票的candidate任期小於當前伺服器任期,拒絕投票給它
logger.info("reject requestVoteProcess! term < currentTerm, currentServerId={}",currentServer.getServerId());
return new RequestVoteRpcResult(this.currentServer.getCurrentTerm(),false);
}
// 發起投票的節點任期高於當前節點,無條件投票給它(任期高的說了算)
if(this.currentServer.getCurrentTerm() < requestVoteRpcParam.getTerm()){
// 重新整理後設資料
this.currentServer.refreshRaftServerMetaData(
new RaftServerMetaData(requestVoteRpcParam.getTerm(),requestVoteRpcParam.getCandidateId()));
// 任期沒它高,自己轉為follower
this.currentServer.setServerStatusEnum(ServerStatusEnum.FOLLOWER);
return new RequestVoteRpcResult(this.currentServer.getCurrentTerm(),true);
}
// term任期值相同,需要避免同一任期內投票給不同的節點而腦裂
if(this.currentServer.getVotedFor() != null && !this.currentServer.getVotedFor().equals(requestVoteRpcParam.getCandidateId())){
// If votedFor is null or candidateId(取反的衛語句)
// 當前伺服器已經把票投給了別人,拒絕投票給發起投票的candidate
logger.info("reject requestVoteProcess! votedFor={},currentServerId={}",
currentServer.getVotedFor(),currentServer.getServerId());
return new RequestVoteRpcResult(this.currentServer.getCurrentTerm(),false);
}
// 投票校驗通過,重新整理後設資料
this.currentServer.refreshRaftServerMetaData(
new RaftServerMetaData(requestVoteRpcParam.getTerm(),requestVoteRpcParam.getCandidateId()));
this.currentServer.processCommunicationHigherTerm(requestVoteRpcParam.getTerm());
return new RequestVoteRpcResult(this.currentServer.getCurrentTerm(),true);
}
public void refreshLastHeartbeatTime(){
// 重新整理最新的接受到心跳的時間
this.lastHeartbeatTime = new Date();
// 接受新的心跳,說明現在leader是存活的,清理掉之前的投票資訊
this.currentServer.cleanVotedFor();
}
private long getRandomElectionTimeout(){
long min = currentServer.getRaftConfig().getElectionTimeoutRandomRange().getLeft();
long max = currentServer.getRaftConfig().getElectionTimeoutRandomRange().getRight();
// 生成[min,max]範圍內隨機整數的通用公式為:n=rand.nextInt(max-min+1)+min。
return ThreadLocalRandom.current().nextLong(max-min+1) + min;
}
}
/**
* 心跳超時檢查任務
* */
public class HeartbeatTimeoutCheckTask implements Runnable{
private static final Logger logger = LoggerFactory.getLogger(HeartbeatTimeoutCheckTask.class);
private final RaftServer currentServer;
private final RaftLeaderElectionModule raftLeaderElectionModule;
public HeartbeatTimeoutCheckTask(RaftServer currentServer, RaftLeaderElectionModule raftLeaderElectionModule) {
this.currentServer = currentServer;
this.raftLeaderElectionModule = raftLeaderElectionModule;
}
@Override
public void run() {
if(currentServer.getServerStatusEnum() == ServerStatusEnum.LEADER){
// leader是不需要處理心跳超時的
// 註冊下一個心跳檢查任務
raftLeaderElectionModule.registerHeartbeatTimeoutCheckTaskWithRandomTimeout();
}else{
try {
doTask();
}catch (Exception e){
logger.info("do HeartbeatTimeoutCheckTask error! ignore",e);
}
// 註冊下一個心跳檢查任務
raftLeaderElectionModule.registerHeartbeatTimeoutCheckTaskWithRandomTimeout();
}
}
private void doTask(){
logger.debug("do HeartbeatTimeoutCheck start {}",currentServer.getServerId());
int electionTimeout = currentServer.getRaftConfig().getElectionTimeout();
// 當前時間
Date currentDate = new Date();
Date lastHeartbeatTime = raftLeaderElectionModule.getLastHeartbeatTime();
long diffTime = currentDate.getTime() - lastHeartbeatTime.getTime();
logger.debug("currentDate={}, lastHeartbeatTime={}, diffTime={}, serverId={}",
currentDate,lastHeartbeatTime,diffTime,currentServer.getServerId());
// 心跳超時判斷
if(diffTime > (electionTimeout * 1000L)){
logger.info("HeartbeatTimeoutCheck check fail, trigger new election! serverId={}",currentServer.getServerId());
// 觸發新的一輪選舉
triggerNewElection();
}else{
// 認定為心跳正常,無事發生
logger.debug("HeartbeatTimeoutCheck check success {}",currentServer.getServerId());
}
logger.debug("do HeartbeatTimeoutCheck end {}",currentServer.getServerId());
}
private void triggerNewElection(){
logger.info("HeartbeatTimeoutCheck check fail, trigger new election! serverId={}",currentServer.getServerId());
// 距離最近一次接到心跳已經超過了選舉超時時間,觸發新一輪選舉
// 當前伺服器節點當前任期自增1
currentServer.setCurrentTerm(currentServer.getCurrentTerm()+1);
// 自己發起選舉,先投票給自己
currentServer.setVotedFor(currentServer.getServerId());
// 角色轉變為CANDIDATE候選者
currentServer.setServerStatusEnum(ServerStatusEnum.CANDIDATE);
// 並行的傳送請求投票的rpc給叢集中的其它節點
List<RaftService> otherNodeInCluster = currentServer.getOtherNodeInCluster();
List<Future<RequestVoteRpcResult>> futureList = new ArrayList<>(otherNodeInCluster.size());
// 構造請求引數
RequestVoteRpcParam requestVoteRpcParam = new RequestVoteRpcParam();
requestVoteRpcParam.setTerm(currentServer.getCurrentTerm());
requestVoteRpcParam.setCandidateId(currentServer.getServerId());
for(RaftService node : otherNodeInCluster){
Future<RequestVoteRpcResult> future = raftLeaderElectionModule.getRpcThreadPool().submit(
()-> {
RequestVoteRpcResult rpcResult = node.requestVote(requestVoteRpcParam);
// 收到更高任期的處理
currentServer.processCommunicationHigherTerm(rpcResult.getTerm());
return rpcResult;
}
);
futureList.add(future);
}
List<RequestVoteRpcResult> requestVoteRpcResultList = CommonUtil.concurrentGetRpcFutureResult(
"requestVote", futureList,
raftLeaderElectionModule.getRpcThreadPool(),1,TimeUnit.SECONDS);
// 獲得rpc響應中決定投票給自己的總票數(算上自己的1票)
int getRpcVoted = (int) requestVoteRpcResultList.stream().filter(RequestVoteRpcResult::isVoteGranted).count()+1;
logger.info("HeartbeatTimeoutCheck election, getRpcVoted={}, currentServerId={}",getRpcVoted,currentServer.getServerId());
// 是否獲得大多數的投票
boolean majorVoted = getRpcVoted >= this.currentServer.getRaftConfig().getMajorityNum();
if(majorVoted){
logger.info("HeartbeatTimeoutCheck election result: become a leader! {}, currentTerm={}",currentServer.getServerId(),currentServer.getCurrentTerm());
// 票數過半成功當選為leader
currentServer.setServerStatusEnum(ServerStatusEnum.LEADER);
currentServer.setCurrentLeader(currentServer.getServerId());
// 成為leader後立馬傳送一次心跳,抑制其它節點發起新的一輪選舉
// Upon election: send initial empty AppendEntries RPCs (heartbeat) to each server;
// repeat during idle periods to prevent election timeouts (§5.2)
HeartbeatBroadcastTask.doHeartbeatBroadcast(currentServer);
}else{
// 票數不過半,無法成為leader
logger.info("HeartbeatTimeoutCheck election result: not become a leader! {}",currentServer.getServerId());
}
this.currentServer.cleanVotedFor();
}
}
3.3 candidate發起選舉
- 在上一節介紹的HeartbeatTimeoutCheckTask中,如果發現有一段時間沒有收到心跳後當前節點便會觸發新一輪的選舉,主要邏輯在triggerNewElection方法中。
triggerNewElection中通過首先令當前term值自增1並投票給自己,然後並行的向叢集中的其它節點傳送requestVote的rpc請求。 - 並行處理邏輯通過CommonUtil中的concurrentGetRpcFutureResult方法收集所有的響應結果。
通過future.get設定超時時間,超時則認為是投票失敗。 - 在超時時間內獲得所有響應結果後,計算所得到的的票數是否大於半數(>majorityNum)。
如果超過半數則認為選舉成功,自己成為合法的leader。當前節點重新整理相關的狀態資料,同時立即發起一次心跳廣播以抑制其它節點發起新的選舉。
public class CommonUtil {
private static final Logger logger = LoggerFactory.getLogger(CommonUtil.class);
/**
* 並行的獲得future列表的結果
* */
public static <T> List<T> concurrentGetRpcFutureResult(
String info, List<Future<T>> futureList, ExecutorService threadPool, long timeout, TimeUnit timeUnit){
CountDownLatch countDownLatch = new CountDownLatch(futureList.size());
List<T> resultList = new ArrayList<>(futureList.size());
for(Future<T> futureItem : futureList){
threadPool.execute(()->{
try {
logger.debug(info + " concurrentGetRpcFutureResult start!");
T result = futureItem.get(timeout,timeUnit);
logger.debug(info + " concurrentGetRpcFutureResult end!");
resultList.add(result);
} catch (Exception e) {
// rpc異常不考慮
logger.error( "{} getFutureResult error!",info,e);
} finally {
countDownLatch.countDown();
}
});
}
try {
countDownLatch.await();
} catch (InterruptedException e) {
throw new MyRaftException("getFutureResult error!",e);
}
return resultList;
}
}
3.4 leader定時發起心跳廣播
- MyRaft中將leader心跳廣播相關的邏輯都集中在了RaftHeartbeatBroadcastModule類中,心跳廣播任務以RaftConfig中設定的頻率定期執行。
需要注意的是,心跳的時間間隔必須設定為明顯小於設定的選舉超時時間的值(考慮到rpc網路請求延遲以及follower實際處理心跳的耗時),否則leader心跳將無法抑制follower觸發選舉。 - leader心跳廣播的邏輯集中在HeartbeatBroadcastTask中。和發起投票類似,當前節點通過future並行的向叢集中的所有節點傳送logEntry為空的appendEntries(因為lab1中不涉及紀錄檔複製,所以直接去掉了logEntry這個引數欄位)。
leader原則上可以不關心follower對於心跳的響應結果,但還是需要檢查成功響應中返回的term值。如果發現有其它節點返回了更大的term值,說明叢集中可能已經選出了新的leader或者正在進行選舉,則當前節點需要退回到follower狀態。
/**
* Raft伺服器的心跳廣播模組
* */
public class RaftHeartbeatBroadcastModule {
private final RaftServer currentServer;
private final ScheduledExecutorService scheduledExecutorService;
private final ExecutorService rpcThreadPool;
public RaftHeartbeatBroadcastModule(RaftServer currentServer) {
this.currentServer = currentServer;
this.scheduledExecutorService = Executors.newScheduledThreadPool(1);
this.rpcThreadPool = Executors.newFixedThreadPool(
Math.max(currentServer.getOtherNodeInCluster().size() * 2, 1));
int HeartbeatInternal = currentServer.getRaftConfig().getHeartbeatInternal();
// 心跳廣播任務需要以固定頻率執行(scheduleAtFixedRate)
scheduledExecutorService.scheduleAtFixedRate(
new HeartbeatBroadcastTask(currentServer,this), 0, HeartbeatInternal, TimeUnit.SECONDS);
}
}
/**
* leader心跳廣播任務
* */
public class HeartbeatBroadcastTask implements Runnable{
private static final Logger logger = LoggerFactory.getLogger(HeartbeatBroadcastTask.class);
private final RaftServer currentServer;
private final RaftHeartbeatBroadcastModule raftHeartbeatBroadcastModule;
private int HeartbeatCount = 0;
public HeartbeatBroadcastTask(RaftServer currentServer, RaftHeartbeatBroadcastModule raftHeartbeatBroadcastModule) {
this.currentServer = currentServer;
this.raftHeartbeatBroadcastModule = raftHeartbeatBroadcastModule;
}
@Override
public void run() {
if(currentServer.getServerStatusEnum() != ServerStatusEnum.LEADER){
// 只有leader才需要廣播心跳
return;
}
// 心跳廣播
doHeartbeatBroadcast(currentServer);
}
/**
* 做心跳廣播
* @return 是否大多數節點依然認為自己是leader
* */
public static boolean doHeartbeatBroadcast(RaftServer currentServer){
logger.info("do HeartbeatBroadcast start {}",currentServer.getServerId());
// 先重新整理自己的心跳時間
currentServer.getRaftLeaderElectionModule().refreshLastHeartbeatTime();
// 並行的傳送心跳rpc給叢集中的其它節點
List<RaftService> otherNodeInCluster = currentServer.getOtherNodeInCluster();
List<Future<AppendEntriesRpcResult>> futureList = new ArrayList<>(otherNodeInCluster.size());
// 構造請求引數(心跳rpc,entries為空)
AppendEntriesRpcParam appendEntriesRpcParam = new AppendEntriesRpcParam();
appendEntriesRpcParam.setTerm(currentServer.getCurrentTerm());
appendEntriesRpcParam.setLeaderId(currentServer.getServerId());
for(RaftService node : otherNodeInCluster){
Future<AppendEntriesRpcResult> future = currentServer.getRaftHeartbeatBroadcastModule().getRpcThreadPool().submit(
()-> {
AppendEntriesRpcResult rpcResult = node.appendEntries(appendEntriesRpcParam);
// rpc互動時任期高於當前節點任期的處理
currentServer.processCommunicationHigherTerm(rpcResult.getTerm());
return rpcResult;
}
);
futureList.add(future);
}
List<AppendEntriesRpcResult> appendEntriesRpcResultList = CommonUtil.concurrentGetRpcFutureResult("doHeartbeatBroadcast",futureList,
currentServer.getRaftHeartbeatBroadcastModule().getRpcThreadPool(),1, TimeUnit.SECONDS);
// 通知成功的數量(+1包括自己)
int successResponseCount = (int) (appendEntriesRpcResultList.stream().filter(AppendEntriesRpcResult::isSuccess).count() + 1);
if(successResponseCount >= currentServer.getRaftConfig().getMajorityNum()
&& currentServer.getServerStatusEnum() == ServerStatusEnum.LEADER){
// 大多數節點依然認為自己是leader,並且廣播的節點中沒有人任期高於當前節點,讓當前節點主動讓位
return true;
}else{
// 大多數節點不認為自己是leader(包括廣播超時等未接到響應的場景,也認為是廣播失敗)
return false;
}
}
}
3.5 raft節點處理requestVote請求和心跳請求
處理requestVote請求
- MyRaft處理requestVote的邏輯在上面提到的RaftLeaderElectionModule的requestVoteProcess方法中。
raft需要保證每個任期都只能選出一個leader,所以對於特定的term任期需要做到只有一個節點能獲得超過半數選票。 - 因此,requestVoteProcess中會對發起投票的candidate和自己原生的term值進行比對,如果term值比自己低就直接拒絕(過去的leader不是leader,只有現在的leader才是leader)。
每個節點只有一票,如果term值相同則需要確保自己在此之前沒有投票給其它candidate。
處理心跳請求
- MyRaft的處理心跳請求的邏輯在RaftServer類的appendEntries中。由於lab1沒有紀錄檔複製的功能,所以認為收到的請求都是心跳請求。
- appendEntries中,同樣需要比對引數中term和本地term的值,儘可能的確保是真正的leader發來的心跳。
如果校驗通過了,則將原生的最後接受到的心跳時間重新整理為當前時間,來抑制選舉超時檢查任務中觸發新一輪選舉。
public class RaftServer implements RaftService {
private static final Logger logger = LoggerFactory.getLogger(RaftServer.class);
/**
* 當前服務節點的id(叢集內全域性唯一)
* */
private final String serverId;
/**
* Raft伺服器端設定
* */
private final RaftConfig raftConfig;
/**
* 當前伺服器的狀態
* */
private volatile ServerStatusEnum serverStatusEnum;
/**
* raft伺服器後設資料(當前任期值currentTerm、當前投票給了誰votedFor)
* */
private final RaftServerMetaDataPersistentModule raftServerMetaDataPersistentModule;
/**
* 當前服務認為的leader節點的Id
* */
private volatile String currentLeader;
/**
* 叢集中的其它raft節點服務
* */
protected List<RaftService> otherNodeInCluster;
private RaftLeaderElectionModule raftLeaderElectionModule;
private RaftHeartbeatBroadcastModule raftHeartbeatBroadcastModule;
public RaftServer(RaftConfig raftConfig) {
this.serverId = raftConfig.getServerId();
this.raftConfig = raftConfig;
// 初始化時都是follower
this.serverStatusEnum = ServerStatusEnum.FOLLOWER;
// 伺服器後設資料模組
this.raftServerMetaDataPersistentModule = new RaftServerMetaDataPersistentModule(raftConfig.getServerId());
}
public void init(List<RaftService> otherNodeInCluster){
// 叢集中的其它節點服務
this.otherNodeInCluster = otherNodeInCluster;
raftLeaderElectionModule = new RaftLeaderElectionModule(this);
raftHeartbeatBroadcastModule = new RaftHeartbeatBroadcastModule(this);
logger.info("raft server init end! otherNodeInCluster={}, currentServerId={}",otherNodeInCluster,serverId);
}
@Override
public RequestVoteRpcResult requestVote(RequestVoteRpcParam requestVoteRpcParam) {
RequestVoteRpcResult requestVoteRpcResult = raftLeaderElectionModule.requestVoteProcess(requestVoteRpcParam);
processCommunicationHigherTerm(requestVoteRpcParam.getTerm());
logger.info("do requestVote requestVoteRpcParam={},requestVoteRpcResult={}, currentServerId={}",
requestVoteRpcParam,requestVoteRpcResult,this.serverId);
return requestVoteRpcResult;
}
@Override
public AppendEntriesRpcResult appendEntries(AppendEntriesRpcParam appendEntriesRpcParam) {
if(appendEntriesRpcParam.getTerm() < this.raftServerMetaDataPersistentModule.getCurrentTerm()){
// Reply false if term < currentTerm (§5.1)
// 拒絕處理任期低於自己的老leader的請求
logger.info("doAppendEntries term < currentTerm");
return new AppendEntriesRpcResult(this.raftServerMetaDataPersistentModule.getCurrentTerm(),false);
}
if(appendEntriesRpcParam.getTerm() >= this.raftServerMetaDataPersistentModule.getCurrentTerm()){
// appendEntries請求中任期值如果大於自己,說明已經有一個更新的leader了,自己轉為follower,並且以對方更大的任期為準
this.serverStatusEnum = ServerStatusEnum.FOLLOWER;
this.currentLeader = appendEntriesRpcParam.getLeaderId();
this.raftServerMetaDataPersistentModule.setCurrentTerm(appendEntriesRpcParam.getTerm());
}
// 來自leader的心跳處理,清理掉之前選舉的votedFor
this.cleanVotedFor();
// entries為空,說明是心跳請求,重新整理一下最近收到心跳的時間
raftLeaderElectionModule.refreshLastHeartbeatTime();
// 心跳請求,直接返回
return new AppendEntriesRpcResult(this.raftServerMetaDataPersistentModule.getCurrentTerm(),true);
}
}
4. MyRaft leader選舉demo驗證
在工程的test目錄下,可以啟動一個5節點的MyRaft的服務叢集(用main方法啟動即可),通過修改其中的RaftClusterGlobalConfig類可以修改相關的設定。
public class RaftClusterGlobalConfig {
public static Registry registry = RegistryFactory.getRegistry(
new RegistryConfig(RegistryCenterTypeEnum.FAKE_REGISTRY.getCode(), "127.0.0.1:2181"));
/**
* raft的叢集設定
* */
public static final List<RaftNodeConfig> raftNodeConfigList = Arrays.asList(
new RaftNodeConfig("raft-1","127.0.0.1",8001)
,new RaftNodeConfig("raft-2","127.0.0.1",8002)
,new RaftNodeConfig("raft-3","127.0.0.1",8003)
,new RaftNodeConfig("raft-4","127.0.0.1",8004)
,new RaftNodeConfig("raft-5","127.0.0.1",8005)
);
public static final int electionTimeout = 3;
public static final Integer debugElectionTimeout = null;
public static final int HeartbeatInterval = 1;
/**
* N次心跳後,leader會自動模擬出現故障(退回follow,停止心跳廣播)
* N<=0代表不觸發自動模擬故障
*/
public static final int leaderAutoFailCount = 0;
/**
* 隨機化的選舉超時時間(毫秒)
* */
public static final Range<Integer> electionTimeoutRandomRange = new Range<>(150,500);
public static void initRaftRpcServer(String serverId){
RaftNodeConfig currentNodeConfig = RaftClusterGlobalConfig.raftNodeConfigList
.stream().filter(item->item.getServerId().equals(serverId)).findAny()
.orElseThrow(() -> new MyRaftException("serverId must in raftNodeConfigList"));
List<RaftNodeConfig> otherNodeList = RaftClusterGlobalConfig.raftNodeConfigList
.stream().filter(item->!item.getServerId().equals(serverId)).collect(Collectors.toList());
RaftConfig raftConfig = new RaftConfig(
currentNodeConfig,RaftClusterGlobalConfig.raftNodeConfigList);
raftConfig.setElectionTimeout(RaftClusterGlobalConfig.electionTimeout);
raftConfig.setDebugElectionTimeout(RaftClusterGlobalConfig.debugElectionTimeout);
raftConfig.setHeartbeatInternal(RaftClusterGlobalConfig.HeartbeatInterval);
raftConfig.setLeaderAutoFailCount(RaftClusterGlobalConfig.leaderAutoFailCount);
// 隨機化選舉超時時間的範圍
raftConfig.setElectionTimeoutRandomRange(RaftClusterGlobalConfig.electionTimeoutRandomRange);
RaftRpcServer raftRpcServer = new RaftRpcServer(raftConfig, RaftClusterGlobalConfig.registry);
List<RaftService> raftServiceList = raftRpcServer.getRpcProxyList(otherNodeList);
// raft服務,啟動!
raftRpcServer.init(raftServiceList);
}
}
驗證lab1中MyRaft leader選舉實現的正確性,可以通過以下幾個case簡單的驗證下:
- 啟動5個節點,看看是否能夠在短時間內選舉出一個leader,leader是否能抑制後續的選舉(leader定時心跳有紀錄檔能觀察到)。
- 將leader殺掉(5節點叢集最多能容忍2個節點故障),看是否在選舉超時後觸發新一輪選舉,並且成功選出新的leader。
- 將之前殺掉的leader再啟動,看能否成功的回到叢集中。
5. leader預選舉優化(PreVote)
在原始的raft演演算法的leader選舉中存在一個問題。具體場景舉例如下:
- 一個5節點的raft叢集,突然其中2個follower節點與另外三個節點(包含當前leader)之間出現了網路分割區,不同網路分割區的節點無法正常通訊。
- 此時3節點所在的網路分割區是多數分割區,因此可以正常工作。而2個節點所在的分割區是少數分割區,由於無法接到leader心跳而觸發新的選舉。
raft的論文中提到,發起新選舉需要先將自己的任期值term自增1,然後發起並行的requestVote。
但此時2節點所在的少數分割區是無法成功獲得大多數選票的,因此在這個分割區中的節點會不斷的發起一輪又一輪的leader選舉,term值也會在很短的時間內快速增長。 - 在一段時間後網路分割區問題恢復後,叢集中的所有節點又能互相通訊了,此時少數分割區節點的term值大概率遠大於正常工作的多數分割區中的節點。
在少數分割區節點收到來自多數分割區節點的leader的rpc請求時,其會響應一個更大的term值。此時位於多數分割區中的leader會因為響應的term值高於自己而主動退位,叢集內會發起一輪新的選舉。
從本質上來說,這個分割區恢復後進行的新選舉是無意義的。且由於進行選舉會造成叢集短暫的不可用,因此最好能避免這個問題。
業界給出的解決方法是在真正的選舉前先發起一輪預選舉(preVote)。
- 預選舉的操作和選舉一樣,也是並行的發起requestVote請求,主要的區別在於發起預選舉的節點並不事先將term值自增,而是維持不變。節點的狀態也在candidate的基礎上新增了一個preCandidate狀態。
- 發起預選舉的節點需要根據預選舉中發起的並行requestVote結果來決定是否開啟實際的leader選舉。
如果預選舉中發起的並行requestVote得到了多數票,則可以接著發起實際的選舉。而如果沒有得到多數票,則不進行實際的選舉。 - 引入了預選舉的機制後,上面所說的網路分割區發生時,少數分割區的節點由於無法在預選舉中獲得大多數票,因此只會不斷的發起一輪又一輪的預選舉。
因此,其term值不會不斷增加而是一直維持在分割區發生時的值。在分割區問題恢復後,其term值一定是小於或等於多數分割區內leader的term值,而不會進行一輪無效的選舉,從而解決上述的問題。
但需要注意的是,引入預選舉機制也會增加正常狀況下發起正常選舉的開銷。
MyRaft為了保持實現的簡單性,並沒有實現預選舉機制。但etcd、sofa-jraft等流行的開源raft系統都是實現了預選舉優化的,所以在這裡還是簡單介紹一下。
6. 總結
- 作為手寫raft系列部落格的第一篇,在部落格的第一、二節簡單介紹了raft演演算法和MyRaft,第3節則詳細分析了leader選舉的關鍵細節並基於原始碼詳細分析了MyRaft是如何實現leader選舉的。
- 單純實現Raft的leader選舉並沒有什麼難度。以我個人的實踐經驗來說,真正的困難之處在於後續功能的疊加。
由於raft的論文中介紹的幾個模組彼此之間是緊密關聯的。因此後續紀錄檔複製、紀錄檔壓縮以及成員動態變更這幾個功能的逐步實現中,每完成一個都會對上個版本的程式碼在細節上有不小的調整,大大增加了整體的複雜度。 - 部落格中展示的完整程式碼在我的github上:https://github.com/1399852153/MyRaft (release/lab1_leader_election分支),希望能幫助到對raft演演算法感興趣的小夥伴。
內容如有錯誤,還請多多指教。