論文翻譯: FREEVC:朝著高質量、無文字、單次轉換聲音的目標邁進
原文:FREEVC: TOWARDS HIGH-QUALITY TEXT-FREE ONE-SHOT VOICE CONVERSION
原文地址:https://ieeexplore.ieee.org/abstract/document/10095191
個人總結:
1.提出mel譜縮放增強方法。
2.基於VITS框架進行改進,BUT在對照實驗中缺沒有對比VITS
3.引入WavLM模型提高VC模型對說話人內容和說話人資訊的解耦能力
翻譯:
摘要: 語音轉換(VC)可以通過首先提取源內容資訊和目標說話者資訊,然後利用這些資訊重構波形來實現。然而,當前的方法通常要麼提取帶有洩露說話者資訊的不完整內容資訊,要麼需要大量的註釋資料進行訓練。此外,轉換模型與聲碼器之間的不匹配可能會降低重構波形的質量。在本文中,我們採用了VITS的端到端框架來實現高質量的波形重構,並提出了在無需文字註釋的情況下提取乾淨內容資訊的策略。我們通過對WavLM特徵施加資訊瓶頸來解耦內容資訊,並提出了基於頻譜重縮放的資料增強方法來提高提取內容資訊的純度。實驗結果表明,所提出的方法優於使用註釋資料訓練的最新VC模型,並具有更強的魯棒性。
索引詞— 語音轉換、自監督學習、資訊瓶頸、資料增強
引言
語音轉換(Voice Conversion,VC)是一種技術,可以將源說話者的聲音轉換為目標風格,比如說話者身份[1]、韻律[2]和情感[3],同時保持語言內容不變。在本文中,我們專注於單次設定下的說話者身份轉換,即僅給定目標說話者的一段話作為參考。
典型的單次語音轉換方法是從源語音和目標語音中分別解耦內容資訊和說話者資訊,然後使用它們來重構轉換後的語音[4]。因此,轉換後語音的質量依賴於(1)VC模型的解耦能力,以及(2)VC模型的重構能力。
根據語音轉換(VC)系統如何解耦內容資訊,我們可以將當前的VC方法分為基於文字的VC和無文字的VC。一種流行的基於文字的VC方法是使用自動語音識別(ASR)模型提取音素後驗圖(PPG)作為內容表示[5][6]。有些研究人員還利用文字到語音(TTS)模型中的共用語言知識來解耦內容資訊[7][8]。然而,這些方法需要大量的註釋資料來訓練ASR或TTS模型。資料註釋是昂貴的,而且註釋的準確性和細粒度,例如音素級別和字素級別,會影響模型的效能。為了避免基於文字方法的問題,人們開始研究無文字方法,即在沒有文字註釋的情況下學習提取內容資訊。典型的無文字方法包括資訊瓶頸[4]、向量量化[9]、範例歸一化[10]等。然而,它們的效能通常落後於基於文字的方法[11]。這是因為它們提取的內容資訊更容易洩露源說話者的資訊。
許多VC系統採用兩階段的重構流程[6][4]。在第一階段,轉換模型將源聲學特徵轉換為目標說話者的聲音,而在第二階段,聲碼器將轉換後的特徵轉換為波形。這兩個模型通常是分別訓練的。然而,轉換模型預測的聲學特徵與聲碼器在訓練過程中使用的真實語音特徵分佈不同。這種特徵不匹配問題,在TTS中也存在,可能會降低重構波形的質量[12]。VITS是一個一階段模型,可以同時進行TTS和VC。通過通過條件變分自編碼器(CVAE)的潛在變數將兩個階段的模型連線起來,減少了特徵不匹配問題。通過採用對抗訓練,進一步提高了重構波形的質量。然而,VITS是一個基於文字的模型,並且僅限於多對多的VC,即源說話者和目標說話者都是已知的說話者。
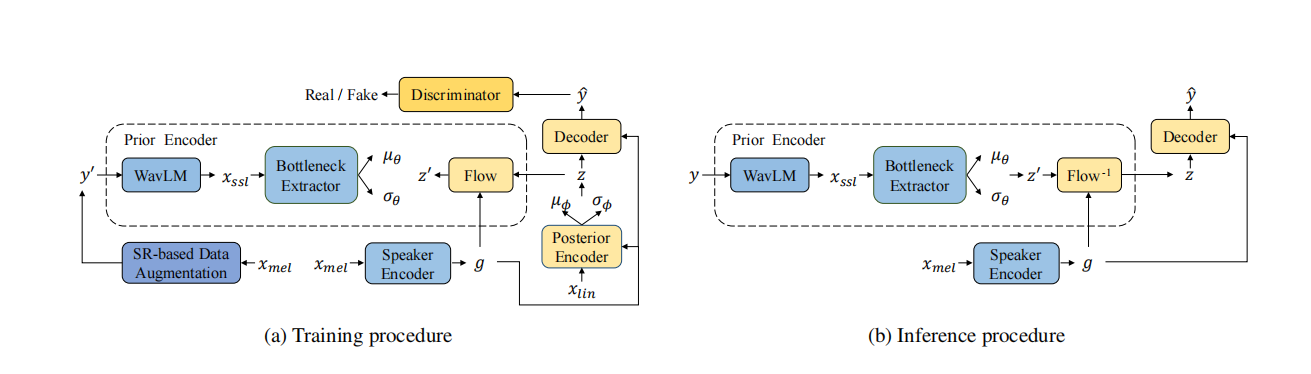
圖1:FreeVC的訓練和推理過程。其中,y表示源波形,y0表示增強後的波形,yˆ表示轉換後的波形,xmel表示梅爾頻譜圖,xlin表示線性譜圖,xssl表示SSL特徵,g表示說話者嵌入。
在本文中,我們提出了一個名為FreeVC的無文字單次語音轉換系統。該系統採用了VITS的框架,以其出色的重構能力為基礎,但是在不需要文字註釋的情況下學習解耦內容資訊。近期,語音自監督學習(Speech Self-Supervised Learning,SSL)在語音識別[14]、說話者驗證[15]和語音轉換[16]等下游任務中取得了成功,證明了SSL特徵相比傳統聲學特徵(如梅爾頻譜圖)的潛在優勢。我們使用WavLM[17]從波形中提取SSL特徵,並引入一個資訊瓶頸提取器來從SSL特徵中提取內容資訊。我們還提出了基於頻譜重縮放(SR)的資料增強方法,該方法扭曲說話者資訊而不改變內容資訊,以增強模型的解耦能力。為了實現單次語音轉換,我們使用說話者編碼器來提取說話者資訊。我們的程式碼和演示頁面是公開可用的。
方法
如圖1所示,FreeVC的主幹結構來自於VITS,它是一個使用GAN訓練增強的條件變分自編碼器(CVAE)。與VITS不同,FreeVC的先驗編碼器採用原始波形作為輸入,而不是文字註釋,並且具有不同的結構。說話者嵌入是由說話者編碼器提取的,用於進行單次語音轉換。此外,FreeVC採用不同的訓練策略和推理過程。接下來,我們將在以下小節中詳細介紹細節。
2.1. 模型架構
FreeVC包含先驗編碼器、後驗編碼器、解碼器、判別器和說話者編碼器,其中後驗編碼器、解碼器和判別器的架構遵循VITS。我們將重點描述先驗編碼器和說話者編碼器。
2.1.1. 先驗編碼器
先驗編碼器包含一個WavLM模型、一個資訊瓶頸提取器和一個正則化流(normalizing flow)。WavLM模型和資訊瓶頸提取器負責提取內容資訊,並將其建模為分佈N(z0; µθ, σθ^2)。WavLM模型以原始波形作為輸入,並生成包含內容資訊和說話者資訊的1024維SSL特徵xssl。為了去除xssl中包含的不必要的說話者資訊,將1024維xssl輸入到資訊瓶頸提取器,並轉換為d維表示,其中d遠小於1024。這種巨大的維度差會施加資訊瓶頸,強制使得結果低維表示丟棄與內容無關的資訊,例如噪聲或說話者資訊。接下來,將d維隱藏表示投影到2d維隱藏表示,然後將其分為d維µθ和d維σθ。正則化流在條件說話者嵌入g的情況下被採用,以提高先驗分佈的複雜性。遵循VITS的做法,它由多個仿射耦合層[18]組成,並被設計為體積保持,其雅可比行列式|det ∂z0/∂z|為1。
2.1.2. 說話者編碼器
我們使用兩種型別的說話者編碼器:預訓練的說話者編碼器和非預訓練的說話者編碼器。預訓練的說話者編碼器是在大量說話者資料集上訓練的說話者驗證模型。它在VC中被廣泛使用,並被認為優於非預訓練的說話者編碼器。我們採用了[6]中使用的預訓練說話者編碼器。非預訓練的說話者編碼器是與模型的其餘部分一起從頭開始進行聯合訓練。我們使用一個簡單的基於LSTM的架構,並相信如果提取的內容表示足夠乾淨,說話者編碼器將學習對缺失的說話者資訊進行建模。
2.2. 訓練策略
2.2.1. 基於頻譜重縮放的資料增強
一個過於窄的資訊瓶頸將會丟失一些內容資訊,而一個過於寬的資訊瓶頸則會包含一些說話者資訊[4]。我們不打算精細調整資訊瓶頸的大小,而是採用基於頻譜重縮放的資料增強來幫助模型學習提取乾淨的內容資訊,通過扭曲源波形中的說話者資訊。與使用各種訊號處理技術來破壞說話者資訊的工作[19][20]不同,我們的方法更容易實現,並且不需要複雜的訊號處理知識。

我們提出的基於頻譜重縮放的資料增強包括三個步驟:(1) 從波形y獲取梅爾頻譜圖xmel;(2) 對xmel進行垂直頻譜重縮放操作,得到修改後的梅爾頻譜圖x0mel;(3) 使用神經聲碼器從x0mel中重構波形y0。垂直頻譜重縮放操作如圖2所示。梅爾頻譜圖可以看作是一個具有水平時間軸和垂直頻率頻帶軸的影象。垂直頻譜重縮放操作首先使用雙線性插值將梅爾頻譜圖在垂直方向上按一定比例r進行調整,然後將調整後的梅爾頻譜圖填充或剪下為原始形狀。如果比例r小於1,我們在上方用最高頻率頻帶值和高斯噪聲填充壓縮的梅爾頻譜圖,從而產生音調較低且共振峰距較近的語音;反之,如果比例r大於1,我們剪下拉伸的梅爾頻譜圖的頂部多餘頻率頻帶,從而產生音調較高且共振峰距較遠的語音。通過使用增強的語音進行訓練,模型將更好地學習提取在每個比例r下共用的不變內容資訊。除了垂直頻譜重縮放外,我們還可以使用水平頻譜重縮放來產生時間尺度修改的波形。
2.2.2. 訓練損失
訓練損失分為CVAE相關的損失和GAN相關的損失。CVAE相關的損失包括重構損失Lrec,即目標梅爾頻譜圖與預測梅爾頻譜圖之間的L1距離,以及KL損失Lkl,即先驗分佈pθ(z|c)和後驗分佈qφ(z|xlin)之間的KL散度,其中:
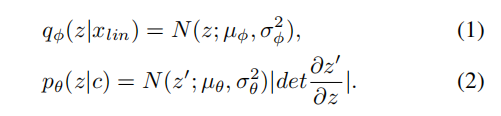
在這裡,條件c是包含在波形y/y’中的內容資訊。通過最小化Lkl,可以減少特徵不匹配問題。GAN相關的損失包括鑑別器D和生成器G的對抗損失Ladv(D)和Ladv(G),以及生成器G的特徵匹配損失Lfm(G)。最後,FreeVC的訓練損失可以表示為:
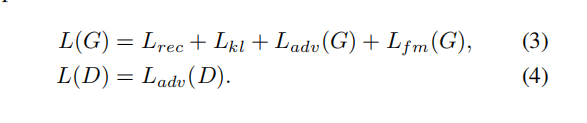
2.3. 推理過程
與VITS不同,VITS在語音轉換推理過程中通過後驗編碼器和先驗編碼器中的正則化流提取內容資訊,而FreeVC在推理過程中通過先驗編碼器中的WavLM和資訊瓶頸提取器提取內容資訊,與訓練過程中一樣。這樣,提取的內容表示不會受到源說話者嵌入質量的影響。
實驗
3.1. 實驗設定
我們在VCTK [23]和LibriTTS [24]資料集上進行實驗。只有VCTK資料集用於訓練。對於VCTK資料集,我們使用了107位說話者的資料,其中314個句子(每位說話者2個句子)隨機選取作為驗證集,10700個句子(每位說話者10個句子)用於測試,其餘用於訓練。對於LibriTTS資料集,我們使用了test-clean子集進行測試。所有音訊樣本均降取樣至16 kHz。使用短時傅立葉變換計算線性譜圖和80頻帶梅爾譜圖。FFT大小、視窗大小和幀移大小分別設定為1280、1280和320。我們將資訊瓶頸提取器的維度d設定為192。對於基於頻譜重縮放的資料增強,調整比例r的範圍從0.85到1.15。我們使用HiFi-GAN v1聲碼器[25]將修改後的梅爾頻譜圖轉換為波形。我們的模型在一塊NVIDIA 3090 GPU上進行訓練,訓練步數達到900k。批次大小設定為64,最大段長度為128幀。
我們選擇了三個基線模型與所提出的方法進行比較:(1) VQMIVC [26],一個使用非預訓練的說話者編碼器的無文字模型;(2) BNE-PPG-VC [6],一個使用預訓練的說話者編碼器的基於文字的模型;(3) YourTTS [27],一個擴充套件VITS到單次設定的基於文字模型,引入了預訓練的說話者編碼器。我們測試了三個版本的所提出的方法:(1) FreeVC-s,使用非預訓練的說話者編碼器的所提出的模型;(2) FreeVC,使用預訓練的說話者編碼器的所提出的模型;(3) FreeVC (w/o SR),使用預訓練的說話者編碼器的所提出的模型,但沒有進行基於頻譜重縮放的資料增強。
3.2. 評估指標
我們進行了主觀和客觀的評估。 對於主觀評估,我們邀請了15名參與者對語音的自然度和說話者相似度進行評估,評估採用5級均值意見分數(MOS)和相似度均值意見分數(SMOS)。我們隨機選擇了6位已知說話者(3男性,3女性)來自VCTK,6位未知說話者(3男性,3女性)來自LibriTTS,並分別在已知-已知、未知-已知和未知-未知場景中進行評估。 對於客觀評估,我們使用了三個指標:詞錯誤率(WER)、字元錯誤率(CER)和F0-PCC。源語音和轉換後語音之間的詞錯誤率和字元錯誤率是通過一個自動語音識別(ASR)模型得到的。F0-PCC是源語音和轉換後語音之間F0的皮爾遜相關係數[28]。我們隨機選擇了400個句子(200個來自VCTK,200個來自LibriTTS)作為源語音,並選擇了12個說話者(6個已知說話者,6個未知說話者)作為目標說話者。
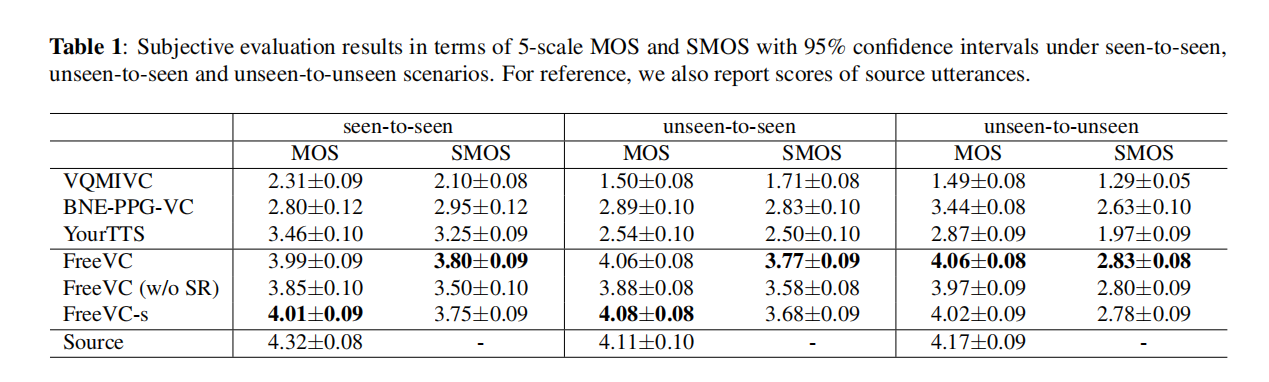
表1:在已知-已知、未知-已知和未知-未知場景下,以5級MOS和SMOS為評估指標的主觀評估結果,帶有95%置信區間。為了對比,我們還報告了源語音的評分。
3.3. 結果與分析
3.3.1. 語音自然度和說話者相似度
表1中的MOS和SMOS結果表明,所提出的模型在所有場景下的語音自然度和說話者相似度方面均優於所有基線模型。此外,我們觀察到所有基線模型在源語音質量較低的情況下,例如錄製質量低或發音不清楚時,都會出現質量降低的問題,而我們提出的模型幾乎不受影響,這表明了所提出的內容提取方法的穩健性。
在所提出的方法的三個版本中,FreeVC (w/o SR) 的語音自然度和說話者相似度低於 FreeVC。這表明,在沒有基於頻譜重縮放的資料增強的情況下訓練的模型洩漏了一些源說話者資訊,導致難以重構令人滿意的波形。FreeVC-s的表現與FreeVC相似,表明預訓練的說話者編碼器並不是我們方法效能的主要因素,一個簡單的非預訓練說話者編碼器能夠與預訓練的說話者編碼器相匹配的效能。FreeVC在未知-未知場景中表現優於FreeVC-s,這表明在大量說話者資料上預訓練的說話者編碼器可以提高對未知目標的效能。

表2:客觀評估結果。對於WER和CER,數值越小越好。F0-PCC的範圍在-1到1之間,數值越高越好。
3.3.2. 語音智慧和F0變化一致性
從表2中可以看出,我們提出的模型的WER和CER都比所有基線模型(甚至是基於文字的模型)都要低。這表明所提出的方法能夠很好地保留源語音的語言內容。F0-PCC的結果顯示,我們提出的方法與源語音具有更高的F0變化一致性,這表明所提出的方法能夠有效地保持源語音的語調。此外,我們觀察到使用基於頻譜重縮放的資料增強進行訓練略微提高了語音智慧和F0變化一致性。
結論
本文提出了FreeVC,一個無文字的單次語音轉換系統。我們採用VITS的框架進行高質量的波形重建。內容資訊是從WavLM特徵的瓶頸中提取的。我們還提出了基於頻譜重縮放的資料增強方法來改善模型的解纏能力。實驗結果證明了所提出方法的優越性。未來,我們將研究說話者自適應方法,以提高對未知目標說話者的相似性,尤其是在資料較少的情況下。
#這裡對文中使用的FLOW解釋一下:
在論文中,正則流被用於實現聲音特徵的轉換,以實現從源說話者的聲音特徵到目標說話者的聲音特徵的轉換。正則流模型通過一系列可逆變換將一個簡單的先驗分佈(通常是高斯分佈或均勻分佈)對映為複雜的後驗分佈,從而可以精確計算概率密度函數,進而實現特定的聲音轉換。
在該論文中,作者採用了端到端的框架,並在正則流模型中使用了WavLM(Waveform Language Model)作為特徵提取器,用於從原始語音波形中提取自監督學習特徵(Self-Supervised Learning Features)。然後,通過正則流模型中的多個可逆變換,將WavLM特徵對映為目標說話者的特徵。
正則流的具體用法如下:
-
特徵提取:論文中使用WavLM模型從原始語音波形中提取自監督學習特徵xssl。
-
正向傳播:通過多個可逆變換(例如Planar Transform),將輸入特徵xssl逐步對映為目標說話者的特徵z,並同時計算每個變換的對數行列式。
-
逆向傳播:為了進行反向傳播和模型優化,需要計算正向傳播中每個變換的逆操作。
-
訓練:使用逆向傳播演演算法和適當的優化器來最小化目標函數,以使轉換後的特徵z更接近於目標說話者的特徵。
-
特徵轉換:通過正則流模型,將源說話者的特徵xssl轉換為目標說話者的特徵z,從而實現一次性的聲音轉換。
正則流在這裡的作用是實現一個靈活且可逆的特徵轉換過程,它可以將源說話者的特徵對映到目標說話者的特徵,並且由於是可逆的,因此可以實現在目標說話者的特徵上進行逆向轉換,從而實現語音轉換的逆過程。