python筆記:第十二章檔案
2023-07-21 06:00:29
1.開啟檔案
位於自動匯入的模組IO中,無需手動匯入。
f = open('D:\M\test.txt')
若檔案不存在,則報錯
Traceback (most recent call last):
File "d:\M\github\Python\Demo\t14.py", line 1, in <module>
f = open('D:\M\test.txt')
^^^^^^^^^^^^^^^^^^^^^
OSError: [Errno 22] Invalid argument: 'D:\\M\test.txt'
1.1 檔案模式
只指定檔名的話,會得到一個可讀檔案物件。若想寫入檔案,必須通過新增引數來指出。
'r' 以唯讀方式開啟檔案。檔案的指標將會放在檔案的開頭,這是預設模式。
'w' 以寫入方式開啟檔案。如果檔案存在則覆蓋,如果檔案不存在則建立一個新檔案。
'a' 以追加模式開啟檔案。如果檔案存在,則在檔案末尾追加寫入,如果檔案不存在則建立一個新檔案。
'x' 以獨佔方式建立檔案,如果檔案已經存在則返回 FileExistsError 錯誤。
'b' 以二進位制模式開啟檔案。
't' 以文字模式開啟檔案(預設模式)。
'+' 可讀寫模式(可與其他模式組合使用)。
-
預設模式為
rt,將把檔案視為Unicode文字,自動執行解碼和編碼,且預設使用UTF-8編碼。 -
可以使用關鍵字引數
encoding和errors。 -
若檔案為聲音圖片視訊之類的,可以使用二進位制模式來禁用與文字相關的功能。、
2.檔案的基本方法
2.1 讀取和寫入
f.write
f = open('test.txt', 'w')
f.write('Hello')
f.close # 記得關閉
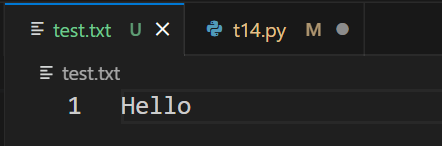
f = open('test.txt', 'r')
str1 = f.read(4) # 讀取前4個字元 指標到達第5個字元
print(str1)
str1 = f.read() # 從第五個字元開始讀取
print(str1)
>
Hell
o
若想讓指標回到起始位置,用f.seek(0)
f = open('test.txt', 'r')
str1 = f.read(4)
print(str1)
f.seek(0) # 指標回溯
str1 = f.read()
print(str1)
>
Hell
Hello
2.2 成行地讀取和寫入
2.2.1 讀取方法readline
可以不提供引數,讀取一行後返回
test.txt 檔案內容為
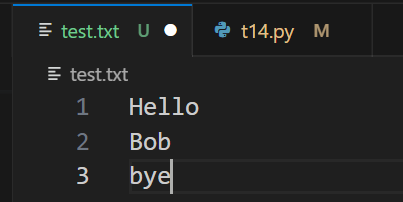
注意:檔案中每一行都有一個換行符,讀取時,換行符也會被讀取
f = open('test.txt', 'r')
str1 = f.readline()
str2 = f.readline()
print(str1)
print(str2)
執行結果
Hello
Bob
想要不讀取換行符,可用strip()
f = open('test.txt', 'r')
str1 = f.readline().strip()
str2 = f.readline().strip()
print(str1)
print(str2)
執行結果
Hello
Bob
可以指定讀取字元數量
f = open('test.txt', 'r')
str1 = f.readline(5)
print(str1)
> Hello
讀取檔案所有行,以列表返回 readlines
f = open('test.txt', 'r')
str1 = f.readlines()
print(str1)
> ['Hello\n', 'Bob\n', 'bye']
預設狀態下,VSCode不會即時儲存,需要先將test.txt儲存,再執行程式
2.2.2 寫入方法 writeline
先擦除所有內容,然後再寫入
執行前,test.txt檔案內容
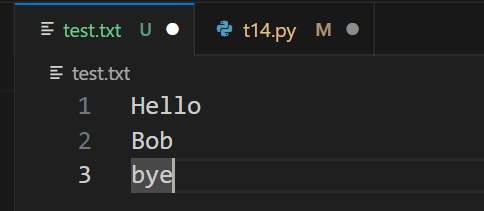
f = open('test.txt', 'w')
f.writelines('good')
f.close
執行後
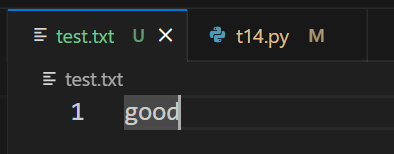
寫入時,不會自動新增換行符,需要自己新增,沒有writeline方法,可以使用write
f = open('test.txt', 'w')
f.write('middle')
f.writelines('bad\n')
f.writelines('good')
f.close
執行結果
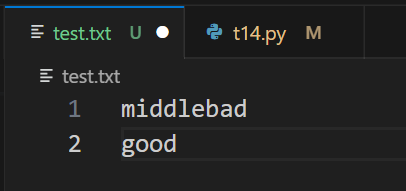
2.3 記得關閉檔案!
可以使用 try/finally 語句,再finally中呼叫close
try:
f = open('test.txt', 'w')
f.write('middle')
f.writelines('bad\n')
f.writelines('good')
finally:
f.close
還可以使用with語句關閉
# 將檔案物件賦給test
with open('test.txt', 'w') as test:
test.write('middle')
執行後檔案自動關閉
3.迭代檔案內容
3.1 每次一個字元
with open('test.txt', 'r') as f:
while True:
char = f.read(1)
if not char: break
print(char, end=' ')
檔案內容:
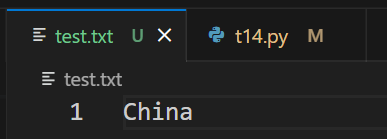
執行結果
C h i n a
3.2 每次一行
檔案內容
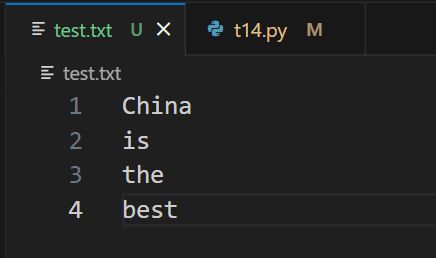
with open('test.txt', 'r') as f:
while True:
str = f.readline().strip() # 去掉換行符
if not str: break
print(str, end=' ')
> China is the best
3.3 讀取所有內容
with open('test.txt', 'r') as f:
str = f.read()
print(str, end=' ')
執行結果
China
is
the
best
3.4 延遲行迭代fileinput
fileinput 可以輕鬆地處理多個輸入流,包括檔案、標準輸入流等,同時還支援行迭代和緩衝流處理。還可以對大型檔案(幾個TB)進行處理。
常見的使用方式包括:
- 逐行讀取檔案中的資料,例如上面提到的例子。
- 處理多個檔案,例如通過 glob 模組來指定需要處理的檔案列表。
- 實現管道功能,例如通過 subprocess 模組來實現將命令的輸出作為輸入流來處理。
檔案內容
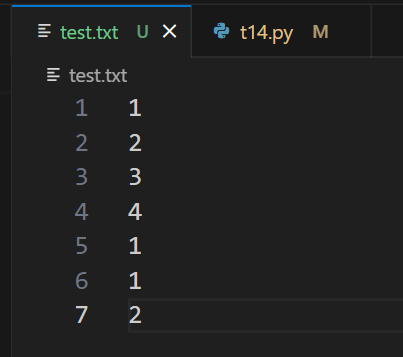
# 逐行讀取檔案並統計出現次數
for line in fileinput.input('test.txt'):
key = line.strip()
counts[key] = counts.get(key, 0) + 1
# 輸出統計結果
for key, value in counts.items():
print(key, '--', value)
執行結果
1 -- 3
2 -- 2
3 -- 1
4 -- 1