論文翻譯:跨語言語音轉換和富有表現力的語音轉換
- 跨語言語音轉換(XVC),其中源語音和參考語音使用不同的語言(例如英文——>中文)。
- 表現語音轉換(EVC),是轉換的音訊更富有說話人身份和情感風格特點。
• 提出了一種新的說話人特徵提取方法,其中應用了說話人一致性損失到聯合說話人編碼器。實驗結果表明,包含說話人一致性損失可以提高說話人相似性和情感相似性。
• 使用Whisper實現XVC:我們使用跨語言語音識別模型Whisper的中間特徵,這有助於生成沒有外國口音的高質量語音,從而實現XVC。
• 使用PPG作為輸入實現EVC:為了模擬參考語音中的情感和說話人資訊,我們使用PPG作為輸入來實現EVC,從而實現準確的情感和說話人特徵轉換。
語音轉換系統在常見的語音轉換任務中在自然度和相似性方面取得了顯著進展。然而,在跨語言語音轉換和表現語音轉換等更復雜任務中,它們的效能仍不完美。在本研究中,我們提出了一種新穎的方法,將聯合訓練的說話人編碼器和從跨語言語音識別模型Whisper中提取的內容特徵結合起來,實現高質量的跨語言語音轉換。
此外,我們引入了一個說話人一致性損失到聯合編碼器中,從而改善轉換後語音與參考語音之間的相似性。為了進一步探索聯合說話人編碼器的能力,我們使用音素後驗圖作為內容特徵,使模型能夠有效地重現參考語音的說話人特徵和情感方面。
關鍵詞:跨語言語音轉換、表現語音轉換、聯合說話人編碼器、說話人一致性損失
引言:
目前,解耦和重構語音中的資訊是實現高質量語音轉換模型的最流行方法。
具體而言,在訓練過程中,從語音中提取內容和說話人資訊,然後用於語音重構。在推理過程中,通過使用源語音中的內容資訊和參考語音中的說話人資訊,生成新的語音來實現語音轉換(簡單來說就是非平行)。
基於音素後驗概率(PPG)的語音轉換方法,如PPG-VC[9],是基於這一原理的經典語音轉換方法。然而,過去受限於自動語音識別(ASR)效能和語音合成模型能力不足,合成輸出的語音質量有限[10]。隨著非自迴歸(NAR)文字到語音(TTS)模型的出現,例如VITS[11]、FastSpeech2[12]、DiffSinger[13],以及大規模預訓練的自監督學習(SSL)模型的可用性,例如Hubert[14]和WavLM[15],高質量的語音轉換模型已經成為可能。FreeVC[16]、ACE-VC[17]和廣泛採用的開源歌聲轉換(SVC)模型SO-VITS-SVC2的基本原理是利用SSL模型從原始語音中提取內容特徵。然後,使用說話人ID或說話人分類模型從語音中提取說話人特定資訊。最後,這兩組資訊都被用於通過TTS模型重構語音。語音轉換結果的質量在很大程度上取決於語音重構模型的合成能力,特別是在準確和明確的內容資訊可用時。(說人話:就是用音素作為特徵,訓練一個聲碼器做語音的生成,這樣的好處是可以保留大量的說話人原本的情緒變換特點)
以前的語音轉換模型,如PPG-VC和Freevc,通常使用預訓練的說話人編碼器在說話人分類任務上進行訓練,以獲取說話人嵌入,然後用於引導語音合成。值得注意的是,訓練說話人編碼器的主要目標不是語音合成,而是說話人識別。因此,這種方法可能會忽略參考語音中存在的寶貴資訊,比如情感。此外,訓練說話人分類模型需要大量的資料集。Freevc-s[16]、Quickvc[18]和NVC-Net[19]使用聯合訓練的說話人編碼器,以確保說話人編碼器的輸出僅包含與說話人相關的資訊。這是通過實現瓶頸結構並仔細排除內容特徵中的說話人資訊來實現的。然而,缺乏一個更詳細的損失函數,專門設計用於捕捉與說話人相關的特徵。
說話人一致性損失的概念已經在幾項研究中使用,包括YourTTS[20]和CyclePPG-XVC[21],旨在改善模型生成的語音與真實語音之間的說話人相似性。這是通過比較同時處理生成語音和真實語音的說話人編碼器的輸出來實現的。然而,這些研究使用了專門針對說話人分類任務進行訓練的預訓練說話人編碼器。這種方法有一定的侷限性,如上述討論的情感資訊的忽略。此外,這些研究中使用的說話人一致性損失僅更新語音合成模組,對說話人編碼器本身沒有影響。因此,在應用說話人一致性損失方面仍有改進的空間,特別是在XVC和EVC任務中。
方法
2.1.動機
在最近的VC研究中,最先進的VC系統表現出令人印象深刻的效能,特別是在單語種(通常是英語)且沒有情感改變的場景中。生成的語音樣本顯示出與人類聲音的顯著自然度和相似度。我們認為現在是將VC研究的重點從傳統VC轉向更復雜應用的時候了。因此,我們選擇了XVC和EVC任務來展示我們設計的說話人資訊編碼方法的靈活性,它可以處理更多超出傳統VC範圍的任務。
所提出的ConsistencyVC靈感來自於FreeVC-s[16]、LoraSVC3、VALL-e[23]和YourTTS[20]。該模型基於FreeVC-s的基礎架構,因為它具有端到端的結構,可以實現高質量的VC。FreeVC-s的聯合說話人編碼器的瓶頸結構確保只編碼說話人特徵,而不包括內容資訊。此外,非自迴歸設計改進了推斷速度。然而,與FreeVC-s不同,我們從LoraSVC中汲取靈感,並選擇在XVC任務中表現更好的內容特徵,消除了需要進行資料增強的需求,從而節省了大量儲存空間。VALL-e是一種零樣本語音合成模型,它在訓練過程中使用目標語音的3秒片段作為參考語音輸入。該模型可以模仿說話人的特徵,甚至從任何3秒參考語音片段中合成高質量的語音,包括情感特徵。這種分段概念啟發了我們的假設,即語音的子段應該包含與整個語音相似的說話人和情感特徵。基於這一假設,並受到YourTTS的啟發,我們將說話人一致性損失應用於聯合說話人編碼器VC模型的訓練中。這種應用改善了說話人相似性和情感相似性。
2.2. 模型架構
如圖1所示,ConsistencyVC模型的主要結構遵循VITS語音合成模型。但是,文字編碼器和持續時間預測器被替換為類似於VITS中的後驗編碼器的內容編碼器。內容編碼器使用WaveNet殘差塊。內容編碼器不使用文字作為輸入,而是採用來自預訓練ASR模型的內容特徵作為輸入。說話人資訊則通過Mel頻譜圖使用聯合訓練的說話人編碼器進行編碼。在實驗部分,XVC和EVC任務使用不同的資料集和不同型別的內容特徵來訓練VC模型。然而,VC模型的結構保持不變。接下來,將詳細解釋內容特徵的選擇以及說話人編碼器的結構。
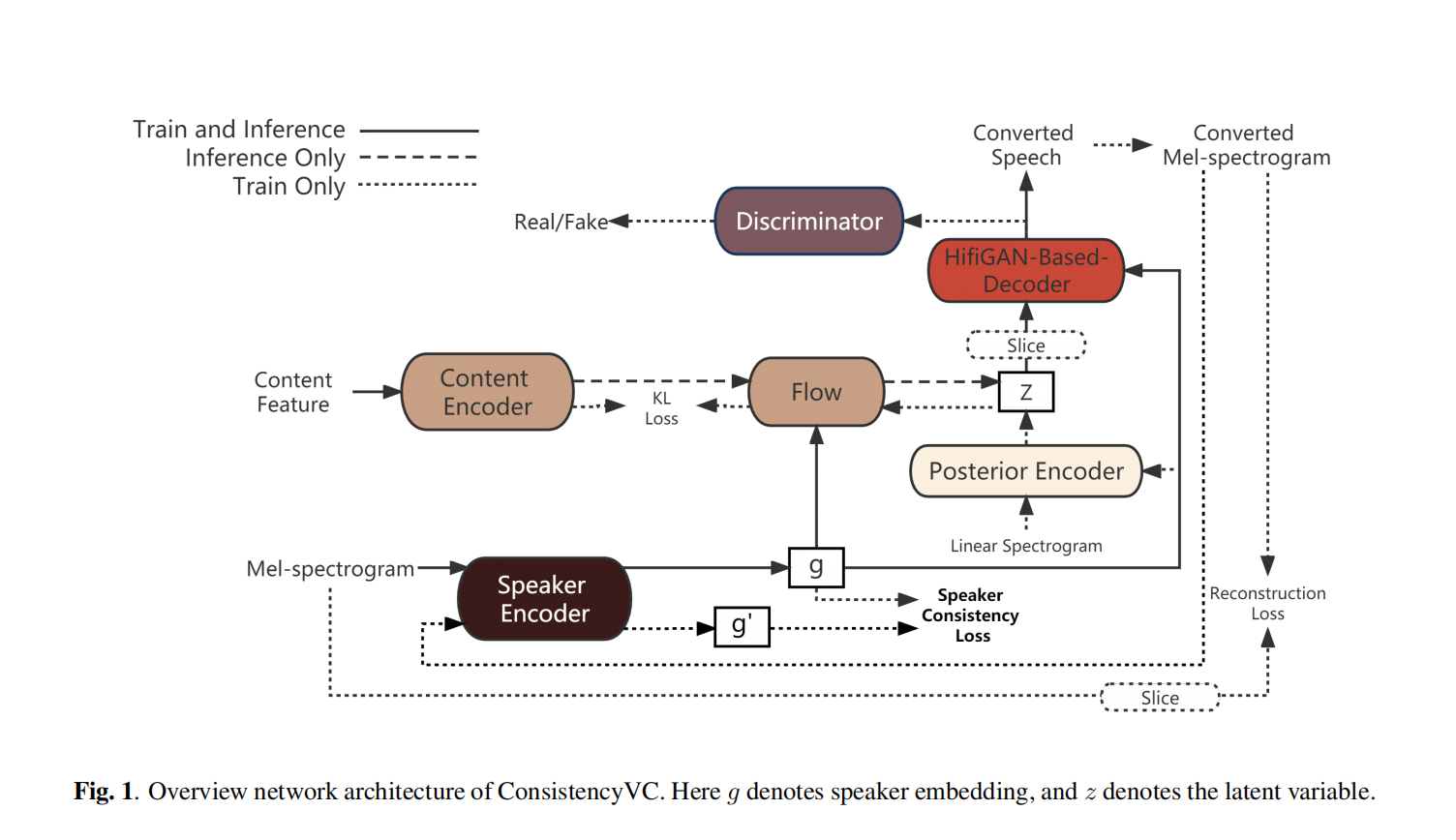
2.2.1. 內容特徵
Whisper是一種ASR模型,在跨語言語音識別任務中取得了顯著的成果。它的模型架構基於編碼器-解碼器transformer。我們選擇transformer編碼器塊的輸出,稱為Whisper編碼器的輸出(WEO),作為內容特徵。與以前XVC研究中的內容特徵相比,WEO提供了更準確和全面的資訊,包括源語音的口音(這裡小編持懷疑態度,對說話人語音使用IN會消除不同人語音分佈的均值和方差分佈的影響,只保留內容資訊,難道Whisper沒用IN?,而且在這篇文文章中是希望消除掉源說話人的口音資訊,有點矛盾了),這對於實現無外語口音的XVC至關重要。因此,我們選擇WEO作為XVC任務的內容特徵。
對於EVC任務,我們選擇使用從在音素識別任務上訓練的wav2vec模型中獲得的PPG(Phoneme Posteriorgram)。這個選擇基於以下事實:同一段話中的不同情感具有不同的韻律。PPG提供了清晰的內容資訊,且包含的韻律資訊較少,因此重建語音的韻律完全依賴於說話者編碼器的輸出,這使得PPG更適合用於EVC任務。
相反,對於XVC任務,WEO比PPG更合適。這是因為在不同的語言中,相同的發音可能有不同的韻律或口音。在XVC任務中,重建語音的韻律應該依賴於來自本地說話者的源語音。
說話者編碼器使用Mel-spectrogram作為輸入來生成編碼的說話者嵌入。說話者編碼器與模型的其餘部分一起訓練。它由一個包含3層LSTM模組和一個全連線層的塊組成,類似於FreeVC-s模型。我們將從語音中得到的Mel-spectrogram輸入到說話者編碼器的LSTM層中。 LSTM的最終隱藏狀態被傳遞給全連線層,使得可變長度的Mel-spectrogram輸入轉換為固定大小的嵌入,實現了瓶頸結構。內容編碼器的輸出被假設為與說話者無關。為了合成語音,模型使用來自說話者編碼器的輸入來替換缺失的說話者資訊。
在訓練策略上,ConsistencyVC模型遵循VITS的訓練策略,在訓練過程中加入了VAE和對抗訓練。對於生成器部分,損失可以表示為:
Lvae = Lrecon + Lkl + Ladv(G) + Lfm(G) + LSCL
其中,Lrecon是重建損失,Lkl是KL散度損失,Ladv(G)是對抗損失,Lfm(G)是特徵匹配損失。這些損失類似於VITS,所以這裡不再詳述具體細節。而是著重解釋說話者一致性損失LSCL。
在VITS的實現中,研究人員採用了視窗化生成器訓練技術[24],該技術在訓練過程中僅生成原始波形的一部分,以減少計算需求。他們隨機提取潛在表示z的片段,並將其饋送到基於HiFi-GAN的解碼器,相應的音訊片段則從真實的原始波形中提取作為訓練目標。這導致模型在訓練過程中生成的輸出語音長度只是輸入語音長度的一小部分。
在FreeVC-S中,對於VC任務,輸入的內容資訊也被分段,限制了內容特徵的最大大小。我們假設與輸入內容特徵相對應的語音段和模型輸出的語音段應該包含相同的情感和說話者特徵。基於這個假設,我們可以為共同訓練的說話者編碼器設計說話者一致性損失。
形式上,設ϕ(·)是說話者編碼器的函數,它輸出參考語音的說話者嵌入。說話者一致性損失定義為生成的語音段與真實語音段之間的說話者嵌入的L1距離:
其中,t和h分別表示真實語音段和生成的語音段。與YourTTS和其他研究類似,我們並不是在訓練的開始階段引入說話者一致性損失,而是在模型學習了基本的語音合成能力後再引入這一損失。
據我們所知,我們是第一個將一致性損失引入到共同訓練的說話者編碼器中的研究。
實驗(這篇文章實驗做的真多)
3.1. 跨語種語音轉換
3.1.1. 資料集
在跨語種語音轉換實驗中,我們使用了幾個資料集,包括Aishell-3、LibriTTS-100、JVS、ESD、VCTK、Aishell-1和JECS。其中,LibriTTS-100、ESD、Aishell3和JVC包含了英語、中文和日語的語音樣本;這些資料集被用於訓練跨語種語音轉換模型。而VCTK、Aishell-1和JECS資料集則用於提供未在訓練集中出現的英語、中文和日語說話者的樣本。這些未知說話者的樣本被用於評估模型對於模仿不在訓練集中的說話者的能力。
3.1.2. 實驗設定
在我們的實驗中,我們使用了16,000 Hz的取樣率。每位說話者的語句被隨機分為訓練集和測試集,比例為9:1。我們的模型基於FreeVC-S,但有一些引數的設計略有不同。最顯著的區別在於,對於跨語種語音轉換任務,我們選擇了WEO作為內容資訊,其跳躍大小為320。至於模型的其他輸入,我們使用短時傅立葉變換(STFT)計算了線性頻譜圖和80頻帶的Mel頻譜圖,其中FFT大小、視窗大小和跳躍大小分別設為1024、1024和320。HiFi-GAN解碼器中的四個殘差塊的上取樣比例被分解為320 = 10 × 8 × 2 × 2,這意味著四個塊的上取樣比例分別為[10,8,2,2]。為了避免「ConvTranspose1d」上取樣層引起的潛在棋盤效應[31],我們使用了[20,16,4,4]的折積核尺寸。我們使用AdamW優化器,並且設定了與FreeVC-S相同的權重衰減和學習率。
在我們的實驗中,我們比較了兩個版本的ConsistencyVC:ConsistencyXVC和ConsistencyXVC-w/o loss。這兩個模型都是在一塊NVIDIA 3090 GPU上進行訓練,使用fp16訓練技術,訓練步數最多為300k步。在前100k步中,批大小為108,訓練時使用的語句長度範圍從24,000到96,000個取樣點,對應於1.5到6秒的語音。輸入到基於HiFi-GAN的解碼器的潛變數z被分為28個片段,導致語音長度為28 × 320 = 8,960個取樣點。然而,在ConsistencyXVC中,從100k步開始,我們引入了額外的訓練階段,使用說話人一致性損失繼續訓練200k步。在這個階段,潛變數z被分為75個片段,導致語音長度為75 × 320 = 24,000個取樣點。由於潛變數z的大小較大,批大小減小為42。另一方面,ConsistencyXVC-w/o loss則繼續使用相同的引數在300k步內進行訓練,而沒有引入說話人一致性損失。(看來這個演演算法比較難訓練)
我們還選擇了BNE-PPG-VC作為基準線。BNE-PPG-VC使用F0、PPG和說話人嵌入作為輸入,通過seq2seq模型進行語音重建。由於該模型可以存取源語音的F0資訊,它也可以在進行跨語言語音轉換(XVC)時避免外語口音。我們在與ConsistencyXVC相同的三語資料集上對BNE-PPG-VC進行了訓練。
在主觀評估實驗中,我們採用了平均意見分數(Mean Opinion Score,MOS)作為主觀指標來計算轉換後語音的自然度和相似度得分。我們邀請了來自Amazon Mechanical Turk的47名英語母語者來評估這些語音。所有的源語音都是英語,但參考語音可以是英語、中文或日語。每個參與者需要評估資料集中6個原始語音的自然度,以及60個轉換後語音的自然度。此外,他們還需要評估32個轉換後語音與目標說話人語音的相似度。一些音訊樣本可以在演示頁面上找到。
表1中自然度的實驗結果顯示,參考語音不是英語並不影響英語語音的自然度。這表明模型在XVC任務中取得了成功。與此同時,說話人相似性實驗顯示,引入說話人一致性損失改善了生成語音的說話人與出現在模型訓練集中的說話人之間的相似性。然而,對於在訓練集中未見過的說話人,說話人一致性損失並沒有改善說話人相似性。
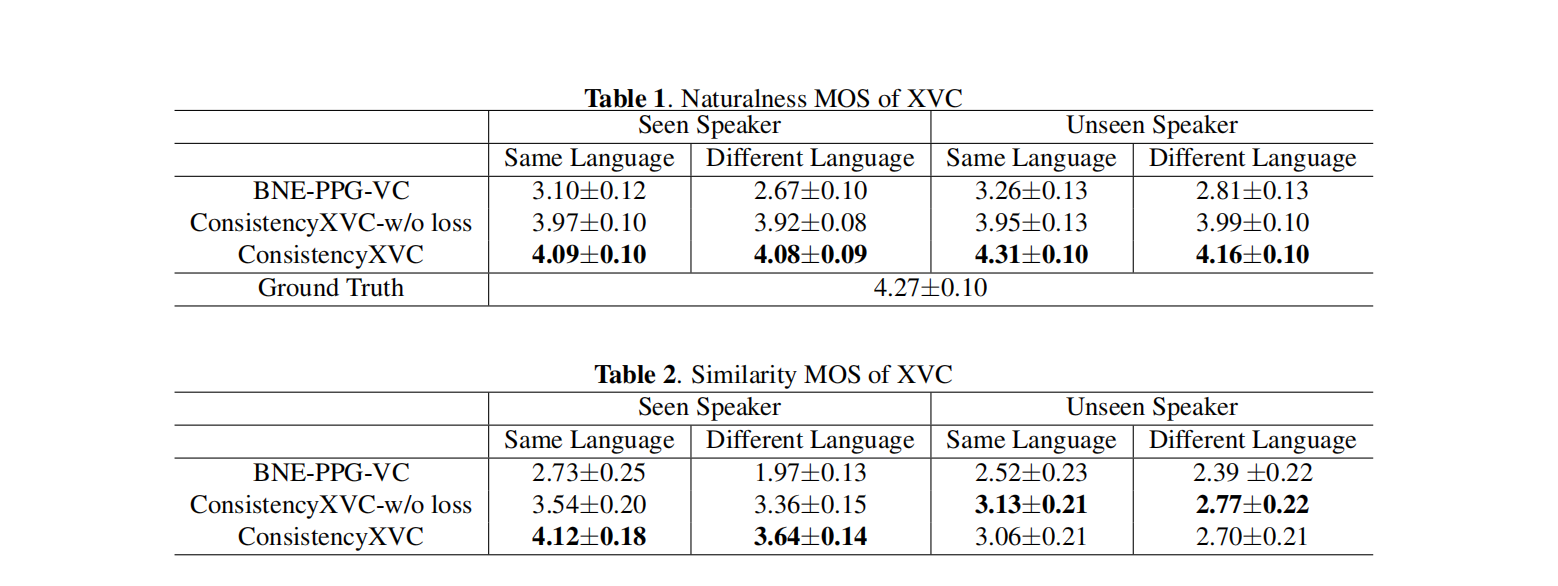
講實話,基線和文章提出的指標差距有點大,一度直逼標籤語音的質量,難道是商務評價?
EVC任務:
在EVC任務中,我們使用了英語資料集進行實驗。我們從ESD資料集[2]和VCTK資料集[28]中選擇了英語資料用於訓練模型。此外,我們還從Emov-db資料集[32]中選擇了樣本作為參考語音,以考慮模型在模擬訓練集中沒有出現的說話人的情感語音方面的能力。
在EVC任務中,我們比較了ConsistencyVC模型的不同變體,包括是否使用說話人一致性損失以及使用不同型別的內容特徵,包括PPG和WEO。
所比較的模型變體如下:
-
ConsistencyEVC:該模型使用PPG作為內容特徵輸入。在前100k步中,它以批大小為108的形式進行訓練,不使用說話人一致性損失。然後,在接下來的200k步中,通過減小批大小至42,繼續訓練並加入說話人一致性損失。
-
ConsistencyEVC-w/o loss:該模型也使用PPG作為內容特徵輸入。在整個訓練過程中,共進行300k步,批大小為108,且不使用說話人一致性損失。
-
ConsistencyEVC-whisper:該模型使用WEO作為內容特徵輸入。類似於ConsistencyEVC,在前100k步中,以批大小為108的形式進行訓練,不使用說話人一致性損失。然後,在接下來的200k步中,通過減小批大小至42,繼續訓練並加入說話人一致性損失。
除了資料集和內容特徵之外,所有其他訓練引數與XVC任務中使用的引數保持一致。
在主觀實驗中,我們採用了類似於Du等人的方法[33],使用Mean Opinion Score(MOS)來計算語音的自然度,並使用ABX偏好測試來比較不同方法在風格相似性方面的結果。我們邀請了來自亞馬遜 Mechanical Turk 的45位參與者參與實驗。每個參與者對資料集中的六個原始語音和60個轉換後的語音進行了自然度評估,並進行了36組偏好測試。在每個測試中,參與者被要求選擇哪個語音更類似於參考語音,包括說話人和情感方面。
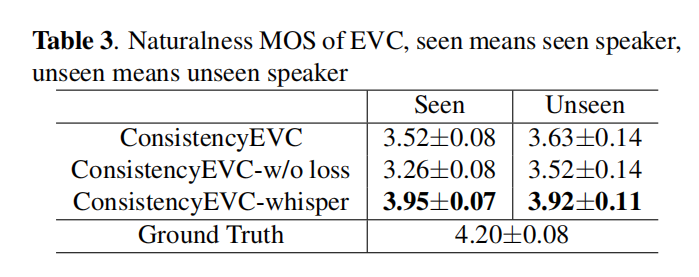
與XVC任務類似,使用說話人一致性損失提高了模型模仿已見說話人蔘考語音的能力。此外,實驗結果顯示,WEO作為內容特徵在自然度(MOS)方面表現優於PPG。WEO包含更多適合重建的資訊,從而產生更自然的合成語音。

然而,在ABX偏好測試中,ConsistencyEVC-whisper的表現比ConsistencyEVC差。這是因為WEO除了內容之外還包含其他資訊,例如語調,這對於XVC任務有助於消除外國說話者在不同語言中的口音。然而,對於EVC任務,我們希望保留源語音的內容特徵,並讓參考語音決定轉換語音的語調。因此,WEO對於XVC任務較為適用,而對於EVC任務則較為不適合。
結論、限制和未來工作
在本研究中,我們在FreeVC-s的基礎上使用了跨語言語音識別模型Whisper和基於wav2vec的音素識別模型來實現跨語言語音轉換和情感語音轉換。為了改進對參考語音的模仿能力,我們引入了共同訓練的說話人一致性損失。實驗結果表明,這種損失有助於改進說話人和情感特徵。然而,我們的研究仍然存在一些限制:
-
對未知說話人的模仿能力下降:在測試集中,當參考語音屬於未在訓練集中出現的說話人時,模型的說話人相似度下降。通過使用更多多樣的說話人資料來訓練模型,可能會提高其模仿未知說話人的能力。例如,使用LibriTTS-R資料集[34]進行訓練,該資料集包含來自2,456位說話人的585小時語音資料,可以提高零樣本和更高質量的語音轉換效果。
-
XVC和EVC任務的內容特徵不一致:選擇內容特徵是靈活的。如果重點是保持語音質量和相似的音調,可以選擇Whisper。然而,如果重點是表達情感,使用PPG作為內容特徵可以確保VC模型生成與參考語音相同風格的語音。可能這兩個任務並不是互相排斥的,因為XVC需要保留語調,而這在EVC任務中需要進行修改。未來的研究中,值得探索如何解耦語音中的情感和說話人資訊的方法。
總的來說,本研究提出了一個有前景的方法來實現跨語言和情感語音轉換,但仍有許多潛在的改進和應用可以探索。未來的研究可以繼續在此基礎上深入探索,推動語音轉換技術的進一步發展。
CycleGAN-VC:https://arxiv.org/pdf/1711.11293v2.pdf