kafka分割區分配策略
前言
現有主流訊息中介軟體都是生產者-消費者模型,主要角色都是:Producer -> Broker -> Consumer,上手起來非常簡單,但仍有需要知識點需要我們關注,才能避免一些錯誤的使用情況,或者使用起來更加高效,例如本篇要講的kafka分割區分配策略。
在開始前我們先簡單回顧一下kafka訊息儲存設計,如下圖:
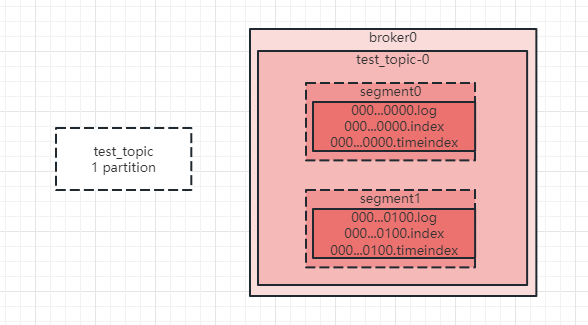
topic是一個邏輯概念,一個topic可以包含多個partition,partition才是物理概念,kafka將partition儲存在broker磁碟上。如圖,test_topic只有一個partition,那麼在broker上就會一個test_topic-0的資料夾。在partition內部,kafka為方便管理和高效處理訊息,進一步將訊息的儲存劃分為多個segment,segment也是個邏輯概念,一個segment下主要包含:.log訊息紀錄檔檔案,儲存實際訊息的地方,.index索引檔案,.timeindex時間索引檔案。segment是捲動的,當達到設定的大小或者時間,kafka就會重新建立一個新的segment,並且會在一定的時間後將過期的segment刪除。
其中每一個部分都是一個大的知識點,本次我們主要關注partition。一個partition會分配給一個consumer group中的一個consumer消費,partition是可延伸的,這為kafka訊息消費提供強大擴充套件能力,如上只有一個patition,那麼所有的訊息都會發到這裡,並且只能由一個消費者消費,這無疑會很慢。我們可以建立兩個partition,然後起兩個消費者,這樣kafka就會為每個消費者分配一個分割區,它們可以並行消費,消費速度得以提升。
那如果有3個partition呢,這個時候是怎麼分的?如果有多個topic呢,這個時候又是怎麼分的?如果有consumer上下線,又是怎麼分呢?這就是我們接下來要討論分割區分配策略。
rebalance
在開始討論分割區分配策略之前,我們先了解一下rebalance這個概念。rebalance重平衡,是指在一定情況下,kafka將分割區重新分配的過程。正常情況下我們的服務起來,分割區分配好後,就穩定執行了,但一些情況下會導致kafka進行rebalance,將分割區都重新分配一遍,這種情況主要包括:
- topic數發生了變化
- partition數發生了變化
- 消費者數發生了變化
- 消費者消費速度太慢,超過限制時間
舉個例子,我們捲動發版,必然有的應用要先下線,再重新上線,這個時候對於kafka來說消費者就發生了變化,就會發生rebalance,rebalance也是按照我們設定的分割區分配策略進行重新分配。
分割區分配策略作用是將所有topic的partition按照一定規則分配給消費者,主要有4種分割區分配策略,它們都實現了ConsumerPartitionAssignor介面,也可以實現該介面自定義分割區分配演演算法。

分割區的分配很容易會想到是有kafka server端計算和分配的,但其實不是,當觸發分割區分配時,kafka會從consumer中挑選一個作為leader,leader根據使用者端設定的分配策略計算分割區結果,然後傳送回給kafka,再由kafka同步給其它的consumer follower。
舉個例子,新增了一個消費者,rebalance過程大致如下:
該消費者傳送一個請求告訴kafka,要加入消費者組。
kafka將消費者組狀態切換到準備rebalance,關閉和消費者的所有連結,等待它們重新加入。
使用者端重新申請加入,kafka從消費者組中挑選一個作為leader,其它的作為follower。
kafka將一些元資訊同步給所有消費者。
follower不斷傳送請求給kafka,請求它們的partition。
leader根據分割區分配策略計算分割區結果,並將結果返回給kafka。
kafka將計算結果返回給follower。
所有消費者根據分割區結果開始消費訊息。

注意,rebalance的發生不是個好事情,kafka需要重新計算分割區資訊,重新分配,清理資源,當你的叢集比較大的時候,頻繁rebalance可能會影響效能。
4種分割區分配策略
RangeAssignor
範圍分配,按照每個topic的partition數計算出每個消費者應該分配的分割區數量,然後分配。
假設有2個topic,每個topic有2個分割區,如下:
T0:P00,P01
T1:P10,P11
有兩個消費者C0,C1,那麼range分配結果如下:
C0:P00,P10
C1:P01,P11
看起來很順暢,也很均衡,但如果T0新增一個P02呢,那麼分配就會如下:
C0:P00,P01,P10
C1:P02,P11
看起來也還好,畢竟兩個人分3個蘋果,會有人多一個。那如果T1也新增一個P12呢,那麼分配就會如下:
C0:P00,P01,P10,P11
C1:P02,P12
看起來好像不怎麼好了,C0又多了一個分割區,如果有更多的topic有這種情況,那麼C0的壓力無疑會比C1大很多。
這是由於range分配是按照每個topic來計算的,這可能會導致consumer的分配不均勻。
RoundRobinAssignor
迴圈分配,按照所有topic的partition迴圈分配。
假設有2個topic,每個topic有2個分割區,如下:
T0:P00,P01
T1:P10,P11
有兩個消費者C0,C1,那麼迴圈分配結果如下:
C0:P00,P10
C1:P01,P11
如果T0新增一個P02呢,那麼分配就會如下:
C0:P00,P02,P10
C1:P01,P11
如果T1也新增一個P12呢,那麼分配就會如下:
C0:P00,P02,P11
C1:P01,P10,P12
和range不同這裡每個消費者分到的分割區數還是相等的。按照迴圈分配邏輯,消費者分配到分割區數偏差不會超過1。
StickyAssignor
range和roundrobin的問題是,當發生rebalance的時候,分割區的分配結果變化會很大,理想情況是分配結果不要有很大變化,例如消費者可能根據partition做了本地快取,分配結果都變了相當於快取都失效了,可能對消費者會有影響。所有有了StickAssignor,粘性分配,從字面理解,粘性分配就是原本是你的,還是儘量分配給你,例如發生rebalance的時候。粘性分配的核心思想是優先保證分割區分配均衡,然後儘可能保留現有的分配結果。
假設有3個topic,每個topic有3個分割區,如下:
T0:P00,P01,P02
T1:P10,P11,P12
T2:P20,P21,P22
有3個消費者C0,C1,C2,那麼roundrobin分配結果如下:
C0:P00,P10,P20
C1:P01,P11,P21
C2:P02,P12,P22
假設C2下線了,觸發了rebalance,roundrobin重新分配結果如下:
C0:P00,P02,P11,P20,P22
C1:P01,P10,P12,P21
可以看到T0,T1的也重新分配了,有4個partition重新分配了。如果使用sticky分配,結果就會是:
C0:P00,P10,P20,P20,P22
C1:P01,P11,P21,P21,
可以看到,T0,T1的沒有任何變化,還是原來的消費者,這就是粘性的含義。
CooperativeStickAssignor
上面的3種分配策略使用的都是eager協定,eager協定的特點是整個rebalance會"stop the world",消費者會放棄當前的分割區,關閉連線,資源清理,然後靜靜等待分配結果。
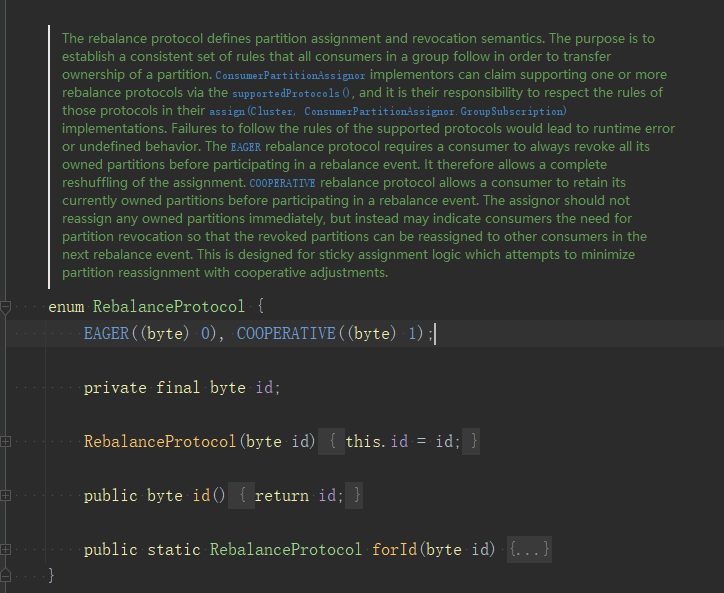
CooperativeStickAssignor是2.4版本開始提供的,使用的cooperative協定,在sticky的基礎上,優化rebalance過程,可以從RebalanceProtocol原始碼中看到這兩個協定的解釋:
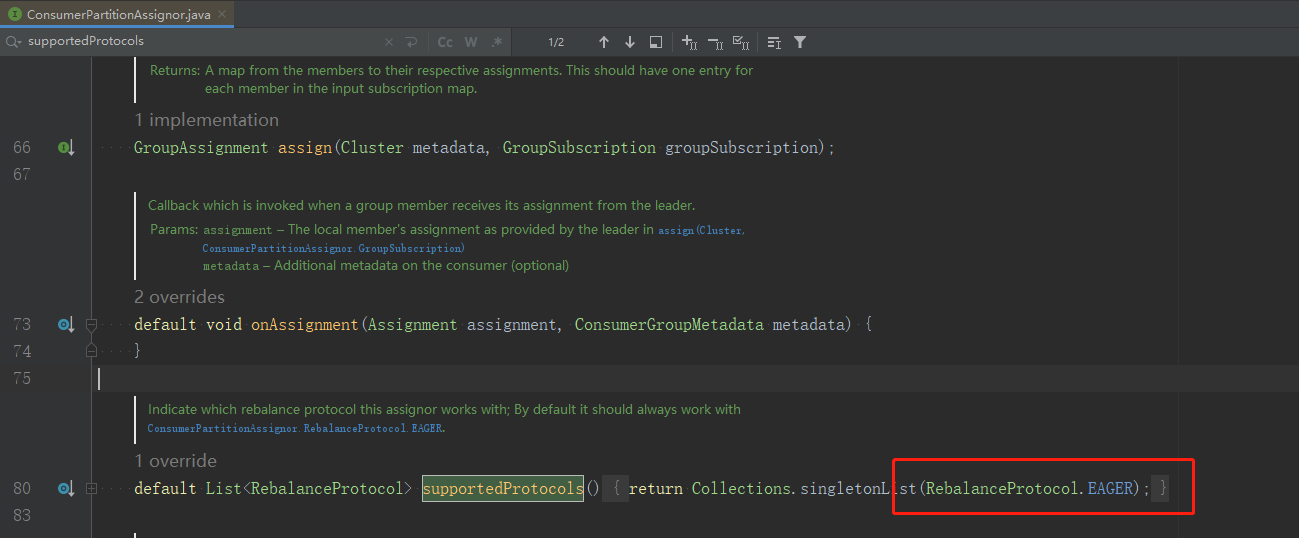
ConsumerPartitionAssignor介面預設就指定了eager協定,如圖:
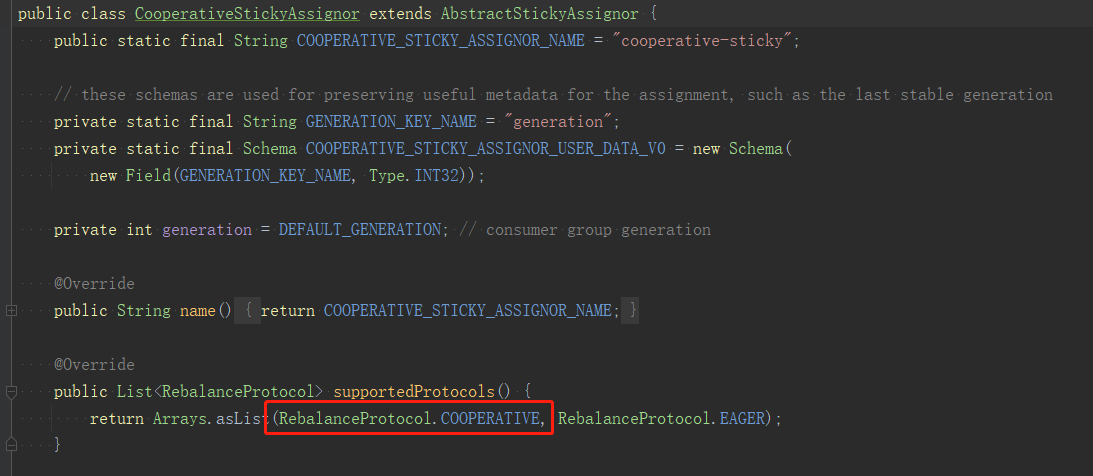
CooperativeStickAssignor重寫了這個協定,使用cooperative,如圖:
還是上面的例子,假設C2下線了,觸發了rebalance,使用sticky分配,結果就會是:
C0:P00,P10,P20,P20,P22
C1:P01,P11,P21,P21,
看起來和sticky並沒有什麼區別,畢竟它們都是sticky,但實際過程上有很大的差別,sticky會先放棄所有的分割區,清理資料,然後再重新分配,整個過程較複雜耗時,而coopertive則比較輕量,首先會將原來的分割區分配給原來的持有者,再rebalance重新分配P20,P21,P22分割區。
關於eager、cooperative協定可以參考這篇文章:https://www.cnblogs.com/listenfwind/p/14146727.html
總結
這4種分割區分配策略是可以設定的,使用者端通過partition.assignment.strategy引數進行設定,預設是RangeAssignor。
歡迎關注我的github:https://github.com/jmilktea/jtea