SAS
PROC FCMP
概述
PROC FCMP 可用於自定義函數(funcion)和子程式(subroutines)。自定義函數和子程式的名稱的最大長度為 32,長度超過 32 的名稱雖然可以定義,但無法呼叫。
建立自定義函數和子程式的優點:
- 使程式易讀、易修改
- 使函數和子程式獨立於外部環境,其內部實現不影響外部環境
- 使函數和子程式可複用,任何有許可權存取儲存函數和子程式的資料集的程式均可呼叫它們
PROC FCMP 定義函數和子程式的時遵循 DATA 步中的語法,定義後的函數和子程式被儲存在 SAS 資料集中,可以被其他 SAS 語句呼叫。
PROC FCMP 是互動式過程,必須使用 QUIT 語句進行終止。
PROC FCMP is an interactive procedure. You must terminate the procedure with a QUIT statement.
PROC FCMP 定義的函數和子程式可以被使用在:
-
DATA 步
-
WHERE 語句
-
ODS
-
部分 PROC 步,具體如下:
- PROC CALIS
- PROC FCMP
- PROC FORMAT
- PROC GA
- PROC GENMOD
- PROC GLIMMIX
- PROC MCMC
- PROC MODEL
- PROC NLIN
- PROC NLMIXED
- PROC NLP
- PROC OPTLSO
- PROC OPTMODEL
- PROC PHREG
- PROC QUANTREG
- PROC REPORT COMPUTE blocks
- SAS Risk Dimensions procedures
- PROC SEVERITY
- PROC SIMILARITY
- PROC SQL(不支援帶有陣列引數的函數)
- PROC SURVEYPHREG
- PROC TMODEL
- PROC VARMAX
程式包(Package)
通常建議將功能相關的函數和子程式儲存在同一個 SAS 資料集中的同一個包(Package)中,包名語法:
libname.dataset.package。
libname: 邏輯庫名稱dataset: 資料集名稱package: 包名
一個資料集中可包含多個包,包名不可重複,同一個包下的函數或子程式名稱不可重複,但不同包下的函數或子程式名稱可以相同。
為了避免歧義,當指定某個函數或子程式時,如果在不同包下存在相同名稱的函數或子程式時,應當額外指定包名,例如:mufunc1.inverse、myfunc2.inverse。
Function 和 Subroutine 的區別
- function 必須有返回值,subroutine 沒有返回值;
- function 內部無法存取其外部變數,subroutine 可以存取並修改其外部變數的值;
- 在 DATA 步和 PROC 步中,function 直接使用名稱進行呼叫,subroutine 使用關鍵字
CALL+ 名稱進行呼叫; - 在宏程式中,function 使用
%sysfunc()進行呼叫,subroutine 使用%syscall進行呼叫;
Fucntion 和 Subroutine 的宣告
PROC FCMP 的語法如下:
proc fcmp outlib = libname.dataset.package inlib = library;
routine-declarations
OUTLIB 選項指定儲存函數和子程式的包名,使用 INLIB 選項指定讀取函數和子程式的包名。
routine-declaration 指定函數和子程式的具體宣告內容,一個 PROC FCMP 內部可以同時宣告多個函數和子程式。
注意:建立的函數和子程式名稱不應當與內建的 SAS 函數和子程式名稱相同。
函數的宣告
函數的宣告由以下四個部分組成:
- 函數名
- 引數(一個或多個)
- 函數體
- 返回值(
RETURN語句)
fucntion name(argument-1 <, argument-2, ...>);
program-statements;
return(expression);
endsub;
- 引數包括數值引數和字串引數,宣告字串引數需要在引數名後面加一個
$符號; - 所有引數都是通過 值傳遞 (passed by value) 的,這意味著在呼叫該函數時,傳入函數的實際引數值都是從外部環境直接複製的,這樣可以保證函數內部對引數的修改不會影響到外部環境的原始變數值。
子程式的宣告
子程式的宣告與函數大致相同,不同的是,子程式沒有返回值。
subroutine name(<argument-1, argument-2, ...>);
outargs <out-argument-1, out-argument-2, ...>;
program-statements;
return;
endsub;
- 使用
OUTARGS語句宣告的引數是通過 參照傳遞 (passed by reference) 的,這意味著子程式內部任何對這些引數的修改都會導致外部環境對應變數的值的修改,因為這些引數的值並非來自外部環境的直接複製,事實上,這些變數在子程式的內部和外部共用同一個參照。當在外部環境與子程式之間存在大量資料的傳遞時,減少變數的直接複製可以提高效能。(Reducing the number of copies can improve performance when you pass parge amounts of data between a CALL routine and the calling environment.)
RETURN語句是可選的,當 RETURN 語句執行時,程式立即返回至呼叫者所處的環境,但 RETURN 語句並未返回任何值。
應用範例
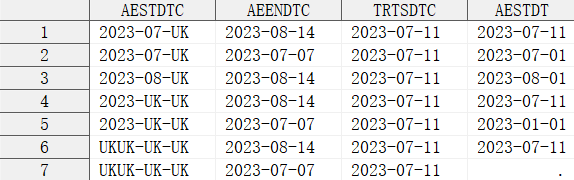
例如:ADAE 資料集衍生 AESTDT 時,需要基於不良事件結束日期 (AEENDTC) 和治療開始日期 (TRTSDTC) 對不良事件開始日期 (AESTDTC) 進行填補。
範例資料:
data ae;
input AESTDTC :$10. AEENDTC :$10. TRTSDTC :$10.;
cards;
2023-07-UK 2023-08-14 2023-07-11
2023-07-UK 2023-07-07 2023-07-11
2023-08-UK 2023-08-14 2023-07-11
2023-UK-UK 2023-08-14 2023-07-11
2023-UK-UK 2023-07-07 2023-07-11
UKUK-UK-UK 2023-08-14 2023-07-11
UKUK-UK-UK 2023-07-07 2023-07-11
run;
下面分別使用 DATA 步、函數、子程式完成資料填補:
DATA 步
data ae_data;
set ae;
/*拆分年月日*/
AESTDTC_y = upcase(scan(AESTDTC, 1, "-"));
AESTDTC_m = upcase(scan(AESTDTC, 2, "-"));
AESTDTC_d = upcase(scan(AESTDTC, 3, "-"));
TRTSDTC_y = upcase(scan(TRTSDTC, 1, "-"));
TRTSDTC_m = upcase(scan(TRTSDTC, 2, "-"));
TRTSDTC_d = upcase(scan(TRTSDTC, 3, "-"));
/*進行缺失填補*/
if AESTDTC_y ^= "UKUK" and AESTDTC_m ^= "UK" and AESTDTC_d = "UK" then do; /*日缺失*/
if AESTDTC_y = TRTSDTC_y and AESTDTC_m = TRTSDTC_m then do; /*年、月相同*/
if input(AEENDTC, yymmdd10.) > input(TRTSDTC, yymmdd10.) then do;
AESTDT = input(TRTSDTC, yymmdd10.);
end;
else do;
AESTDT = mdy(input(AESTDTC_m, 8.), 1, input(AESTDTC_y, 8.));
end;
end;
else do;
AESTDT = mdy(input(AESTDTC_m, 8.), 1, input(AESTDTC_y, 8.));
end;
end;
else if AESTDTC_y ^= "UKUK" and AESTDTC_m = "UK" and AESTDTC_d = "UK" then do; /*月、日缺失*/
if AESTDTC_y = TRTSDTC_y then do; /*年相同*/
if input(AEENDTC, yymmdd10.) > input(TRTSDTC, yymmdd10.) then do;
AESTDT = input(TRTSDTC, yymmdd10.);
end;
else do;
AESTDT = mdy(1, 1, input(AESTDTC_y, 8.));
end;
end;
else do;
AESTDT = mdy(1, 1, input(AESTDTC_y, 8.));
end;
end;
else do; /*年、月、日均缺失*/
if input(AEENDTC, yymmdd10.) > input(TRTSDTC, yymmdd10.) then do;
AESTDT = input(TRTSDTC, yymmdd10.);
end;
end;
format AESTDT yymmdd10.;
drop AESTDTC_y AESTDTC_m AESTDTC_d TRTSDTC_y TRTSDTC_m TRTSDTC_d;
run;
執行結果:
函數
/*自定義函數*/
proc fcmp outlib = sasuser.func.impute;
function impute_ae(AESTDTC $, AEENDTC $, TRTSDTC $);
/*拆分年月日*/
AESTDTC_y = upcase(scan(AESTDTC, 1, "-"));
AESTDTC_m = upcase(scan(AESTDTC, 2, "-"));
AESTDTC_d = upcase(scan(AESTDTC, 3, "-"));
TRTSDTC_y = upcase(scan(TRTSDTC, 1, "-"));
TRTSDTC_m = upcase(scan(TRTSDTC, 2, "-"));
TRTSDTC_d = upcase(scan(TRTSDTC, 3, "-"));
/*進行缺失填補*/
if AESTDTC_y ^= "UKUK" and AESTDTC_m ^= "UK" and AESTDTC_d = "UK" then do; /*日缺失*/
if AESTDTC_y = TRTSDTC_y and AESTDTC_m = TRTSDTC_m then do; /*年、月相同*/
if input(AEENDTC, yymmdd10.) > input(TRTSDTC, yymmdd10.) then do;
AESTDT = input(TRTSDTC, yymmdd10.);
end;
else do;
AESTDT = mdy(input(AESTDTC_m, 8.), 1, input(AESTDTC_y, 8.));
end;
end;
else do;
AESTDT = mdy(input(AESTDTC_m, 8.), 1, input(AESTDTC_y, 8.));
end;
end;
else if AESTDTC_y ^= "UKUK" and AESTDTC_m = "UK" and AESTDTC_d = "UK" then do; /*月、日缺失*/
if AESTDTC_y = TRTSDTC_y then do; /*年相同*/
if input(AEENDTC, yymmdd10.) > input(TRTSDTC, yymmdd10.) then do;
AESTDT = input(TRTSDTC, yymmdd10.);
end;
else do;
AESTDT = mdy(1, 1, input(AESTDTC_y, 8.));
end;
end;
else do;
AESTDT = mdy(1, 1, input(AESTDTC_y, 8.));
end;
end;
else do; /*年、月、日均缺失*/
if input(AEENDTC, yymmdd10.) > input(TRTSDTC, yymmdd10.) then do;
AESTDT = input(TRTSDTC, yymmdd10.);
end;
end;
return(AESTDT);
endsub;
quit;
自定義函數結束後,可直接在 DATA 步中呼叫。
options cmplib = sasuser.func;
data ae_fcmp;
set ae;
AESTDT = impute_ae(AESTDTC, AEENDTC, TRTSDTC);
format AESTDT yymmdd10.;
run;
子程式
這裡使用 OUTARGS 宣告了一個對外部變數 AESTDT 的參照,使得子程式內部可以直接修改外部變數 AESTDT 的值:
/*自定義子程式*/
proc fcmp outlib = sasuser.func.impute;
subroutine impute_ae_subrt(AESTDTC $, AEENDTC $, TRTSDTC $, AESTDT);
outargs AESTDT;
/*拆分年月日*/
AESTDTC_y = upcase(scan(AESTDTC, 1, "-"));
AESTDTC_m = upcase(scan(AESTDTC, 2, "-"));
AESTDTC_d = upcase(scan(AESTDTC, 3, "-"));
TRTSDTC_y = upcase(scan(TRTSDTC, 1, "-"));
TRTSDTC_m = upcase(scan(TRTSDTC, 2, "-"));
TRTSDTC_d = upcase(scan(TRTSDTC, 3, "-"));
/*進行缺失填補*/
if AESTDTC_y ^= "UKUK" and AESTDTC_m ^= "UK" and AESTDTC_d = "UK" then do; /*日缺失*/
if AESTDTC_y = TRTSDTC_y and AESTDTC_m = TRTSDTC_m then do; /*年、月相同*/
if input(AEENDTC, yymmdd10.) > input(TRTSDTC, yymmdd10.) then do;
AESTDT = input(TRTSDTC, yymmdd10.);
end;
else do;
AESTDT = mdy(input(AESTDTC_m, 8.), 1, input(AESTDTC_y, 8.));
end;
end;
else do;
AESTDT = mdy(input(AESTDTC_m, 8.), 1, input(AESTDTC_y, 8.));
end;
end;
else if AESTDTC_y ^= "UKUK" and AESTDTC_m = "UK" and AESTDTC_d = "UK" then do; /*月、日缺失*/
if AESTDTC_y = TRTSDTC_y then do; /*年相同*/
if input(AEENDTC, yymmdd10.) > input(TRTSDTC, yymmdd10.) then do;
AESTDT = input(TRTSDTC, yymmdd10.);
end;
else do;
AESTDT = mdy(1, 1, input(AESTDTC_y, 8.));
end;
end;
else do;
AESTDT = mdy(1, 1, input(AESTDTC_y, 8.));
end;
end;
else do; /*年、月、日均缺失*/
if input(AEENDTC, yymmdd10.) > input(TRTSDTC, yymmdd10.) then do;
AESTDT = input(TRTSDTC, yymmdd10.);
end;
end;
endsub;
quit;
自定義子程式結束後,可直接在 DATA 步中使用 CALL 語句呼叫。
options cmplib = sasuser.func;
data ae_fcmp_subrt;
set ae;
AESTDT = .;
format AESTDT yymmdd10.;
call impute_ae_subrt(AESTDTC, AEENDTC, TRTSDTC, AESTDT);
run;
注意,這裡應當事先初始化 AESTDT 變數,以便 CALL impute_ae_subrt 子程式將填補結果儲存到變數中。
CMPLIB 系統選項
在呼叫自定義函數和子程式之前,先當先通過 CMPLIB 系統選項指定一個或多個包含已經編譯好的函數和子程式的資料集。
例如:
options cmplib = sasuser.cmpl;
options cmplib = (sasuser.cmpl sasuser.cmplA sasuser.cmpl3);
options cmplib = (sasuser.cmpl1 - sasuser.cmpl6);
可變引數(偽)
函數和子程式均支援定義可變引數,在不知道實際傳入的引數的個數的情況下十分有用。
使用 VARARGS 選項,指定函數或子程式支援可變數量的引數,當指定了 VARARGS 使,函數或子程式的最後一個引數應當是一個陣列。
例如:定義一個求和函數,引數個數未知。
proc fcmp outlib = sasuser.func.stats;
function summation(args[*]) varargs;
total = 0;
do i = 1 to dim(args);
total = total + args[i];
end;
return(total);
endsub;
a = summation(1, 2, 3, 4, 5);
put a=;
quit;
option cmplib = sasuser.func;
data _null_;
array num[5] _TEMPORARY_ (1:5);
a = summation(num);
put a=;
run;
注意:在以上函數定義中,PROC FCMP 內部呼叫 summation 函數時,可以使用 summation(1, 2, 3, 4, 5) 這種不限引數個數的語法,然而,當需要在 DATA 步中進行呼叫時,必須事先宣告並初始化一個含有多個引數值的陣列,然後將陣列名稱作為最後一個引數傳入函數中,即 summation(num)。
遞迴
由於自定義函數也可以在 PROC FCMP 內部使用,因此,我們可以很方便地藉助 PROC FCMP 實現遞迴。
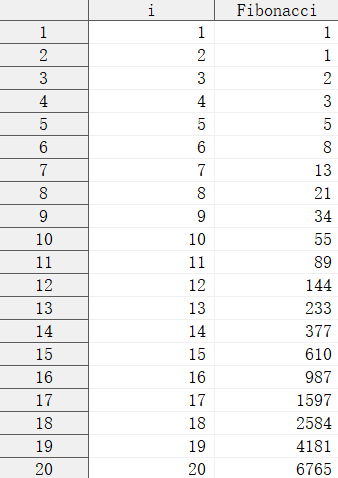
例1:斐波那切數列。
proc fcmp outlib = sasuser.func.recursive;
function Fibonacci(n);
if n = 1 then do;
return(1);
end;
else if n = 2 then do;
return(1);
end;
else do;
return(Fibonacci(n - 1) + Fibonacci(n - 2));
end;
endsub;
quit;
option cmplib = sasuser.func;
data a;
do i = 1 to 20;
Fibonacci = Fibonacci(i);
output;
end;
run;
輸出結果:
例2:經典漢諾塔遊戲
options pagesize = 50;
proc fcmp outlib = sasuser.func.recursive;
subroutine Hanoi(n, start $, mid $, end $);
if n = 1 then do;
put start " -> " end;
end;
else do;
call Hanoi(n - 1, start, end, mid);
put start " -> " end;
call Hanoi(n - 1, mid, start, end);
end;
endsub;
call Hanoi(4, "A", "B", "C");
quit;
輸出結果:

FCMP 的特殊函數和子程式
PROC FCMP 過程提供了一些特殊的函數和子程式,可以在自定義函數或子程式中呼叫它們,但不能直接在 DATA 步中進行呼叫。但是,我們可以對這些特殊的函數和子程式封裝為自定義函數和子程式,從而間接實現在 DATA 步中進行呼叫。
這些特殊的函數和子程式包括:
- 陣列相關
- CALL DYNAMIC_ARRAY
- READ_ARRAY
- WRITE_ARRAY
- C 語言相關
- CALL SETNULL
- CALL STRUCTINDEX
- ISNULL
- 執行 SAS 程式碼
- RUN_MACRO
- RUN_SASFILE
- 方程求根
- SOLVE
- 矩陣操作
- CALL ADDMATRIX
- CALL CHOL
- CALL DET
- CALL ELEMENT
- CALL EXPMATRIX
- CALL FILLMATRIX
- CALL IDENTITY
- CALL INV
- CALL MULT
- CALL POWER
- CALL SUBTRACTMATRIX
- CALL TRANSPOSE
- CALL ZEROMATRIX
- 統計相關
- INVCDF
- LIMMOMENT
RUN_MACRO
RUN_MACRO 函數用於執行預定義的 SAS 宏,相當於執行 %macro_name。這個函數可以實現在 DATA 步中執行 DATA 步。
語法:rc = RUN_MACRO('macro_name' <, variable_1, variable_2, ...>)
例如:以下定義了一個按照變數值拆分資料集的宏程式,宏程式中使用了 DATA 步和 PROC DATASETS 過程對資料集進行拆分,使用 RUN_MACRO 函數對宏程式進行封裝。
宏定義:
%macro split_dataset;
%let indata = %sysfunc(dequote(&indata));
%let var = %sysfunc(dequote(&var));
%if %sysfunc(exist(subdata_&var)) %then %do; /*資料集存在,繼續追加*/
proc datasets;
append base = subdata_&var data = &indata(firstobs = &_n_ obs = &_n_);
quit;
%end;
%else %do; /*資料集不存在,建立資料集*/
data subdata_&var;
set &indata(firstobs = &_n_ obs = &_n_);
run;
%end;
%let is_split_success = 1;
%mend;
PROC FCMP 函數定義,其中變數 is_split_success 指示拆分是否成功:
proc fcmp outlib = sasuser.func.split;
function split(indata $, var $, _n_) $;
is_split_success = 0;
rc = run_macro('split_dataset', indata, var, _n_, is_split_success);
if rc = 0 and is_split_success = 1 then do;
return("Success");
end;
else do;
return("Failed");
end;
endsub;
quit;
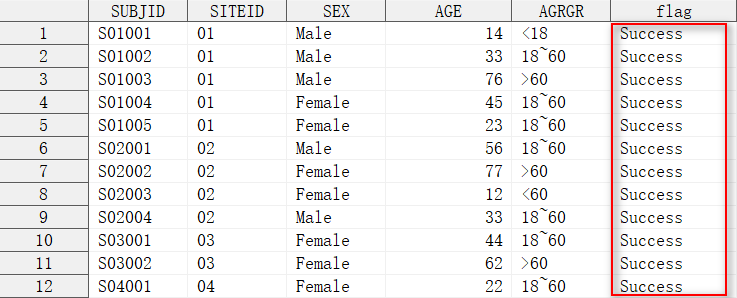
呼叫 split 函數:
data dm;
input SUBJID $ SITEID $ SEX $ AGE AGRGR $;
cards;
S01001 01 Male 14 <18
S01002 01 Male 33 18~60
S01003 01 Male 76 >60
S01004 01 Female 45 18~60
S01005 01 Female 23 18~60
S02001 02 Male 56 18~60
S02002 02 Female 77 >60
S02003 02 Female 12 <60
S02004 02 Male 33 18~60
S03001 03 Female 44 18~60
S03002 03 Female 62 >60
S04001 04 Female 22 18~60
;
run;
/*呼叫 SPLIT 函數對資料集進行拆分*/
options cmplib = sasuser.func;
data dm_test;
set dm;
length flag $10;
flag = split("dm", siteid, _n_);
run;
在這一個例子中,split 函數按照變數 siteid 的具體值,將原資料集 dm 拆分為 subdata_01, subdata_02, subdata_03, subdata04 資料集,分別包含 01~04 中心的受試者資訊,dm_test 資料集的變數 flag 指示當前觀測是否被成功拆分到相應的資料集中。
注意事項:
- 函數
RUN_MACRO的返回值僅僅代表宏程式被成功提交了,但並不意味著宏程式按照預期執行完成了,建議在宏程式內部宣告一個宏變數,用於指示宏程式是否按照預期被執行 - 引數
macro_name指定需要執行的宏程式名稱,應當使用引號包圍 variable_1, variable_2, ...指定的變數具有以下特徵:- 在執行 RUN_MACRO 指定的宏程式前,與 PROC FCMP 內變數具有相同名稱的宏變數會被定義,並且會使用 PROC FCMP 內相同名稱的變數的值進行初始化
- 在執行 RUN_MACRO 指定的宏程式後,會將宏程式內宏變數的值複製回 PROC FCMP 內具有相同名稱的變數中
Microsoft Excel 函數
SAS 預先實現了很多 Microsoft Excel 中的函數,這些函數可以在 sashelp.slkwxl 資料集中找到。使用以下語句可以列出所有 Excel 函數:
proc fcmp inlib = sashelp.slkwxl listall;
quit;
Excel 函數列表:List of Excel functions available in SAS (via SASHELP.SLKWXL)
元件物件
SAS 提供了 Component Object Interface,用於在 DATA 步和 PROC FCMP 步中操縱預定義的元件物件(Component Object)。
SAS 為 DATA 步提供了以下預定義的元件物件:
- hash and hash iterator objects(雜湊和雜湊迭代器物件)
- Java object(Java 物件)
- logger and appender objects
SAS 為 PROC FCMP 步提供了以下預定義的元件物件:
- dictionary object(字典物件)
- hash and hash iterator objects(雜湊和雜湊迭代器物件)
- Python objects(Python 物件)
元件物件由屬性、方法、運運算元組成:
- 屬性:與物件關聯的特定的資訊
- 方法:物件能進行的操作
- 運運算元:為物件提供特殊的功能
通過句點 . 來存取物件的屬性和方法,例如:hash.add()。
雜湊
PROC FCMP 提供了雜湊物件和雜湊迭代器物件,基於查詢鍵 (lookup keys) 快速儲存、搜尋、篩選和檢索資料。雜湊被認為是在大量資料中進行查詢的最快方式。
Hashing is considered the fastest way to search a large amount of information that is referenced through keys.
宣告
- 雜湊物件的宣告:
- DECLARE HASH object-reference
declare hash h;
- 雜湊迭代器 (iterator) 物件的宣告:
- DECLARE HITER object-reference("hash-reference")
declare hiter iter(h);
- 帶有構造器 (constructor) 的雜湊物件的宣告:
- DECLARE object object-reference(<argument_tag-1: value-1, argument_tag-2: value-2, ...>)
argument_tag: value 用於指定建立雜湊物件的範例時用到的資訊,取值為以下 4 種:
- dataset: 'dataset_name<(datasetoption)>' : 指定載入到雜湊物件的 SAS 資料集名稱
- duplicate: 'option' : 指定如何處理重複的鍵,取值如下:
- 'replace' | 'r' : 儲存最後一個重複的鍵
- 'error' | 'e' : 當發現重複鍵時,在紀錄檔中報告錯誤
- hashexp: n : 指定雜湊表的大小為 2n,預設值為 28 = 256。
雜湊表的大小不等於雜湊物件能夠儲存的鍵值對的數量。可以將雜湊表想象為一個桶(buckets)陣列,大小為 256 的雜湊表表示有 256 個桶,每個桶能容納無限多的鍵值對,當需要儲存大量鍵值對到一個雜湊物件時,應當適當擴大
hashexp的大小以提高效能。 - order: 'option' : 指定在雜湊物件上使用迭代器時,返回的鍵值對順序,取值如下:
- 'ascending' | 'a' : 順序排列
- 'descending' | 'd' : 逆序排列
- 'YES' | 'Y' : 順序排列
- 'NO' | 'N' : 未定義的順序
declare hash myhash(dataset: "work.table", duplicate: "r");
方法
雜湊物件的方法:
- DEFINEDATA : 定義雜湊物件的值變數
- DEFINEKEY : 定義雜湊物件的鍵變數
- DEFINEDONE : 指示雜湊物件的初始化已完成(鍵、值變數均已定義)
- NUM_ITEMS : 獲取雜湊物件的鍵值對數量
- ADD : 新增鍵值對 (key-value pair)
- REMOVE : 移除雜湊表中指定鍵的鍵值對
- REPLACE : 替換雜湊表中指定鍵的值
- CLEAR : 清除雜湊物件中的所有鍵值對
- DELETE : 刪除雜湊物件
- CHECK : 檢查雜湊物件中是否有指定的鍵
- FIND : 檢查雜湊物件中是否有指定的鍵,並返回鍵對應的值
雜湊迭代器物件的方法:
- FIRST : 獲取雜湊物件的第一個鍵值對
- LAST : 獲取雜湊物件的最後一個鍵值對
- NEXT : 獲取雜湊物件的下一個鍵值對
- PREV : 獲取雜湊物件的上一個鍵值對
字典
字典是另一種用於儲存資料的方法,它與雜湊不同的地方在於:雜湊物件僅可儲存字串和數值資料,而字典不僅可以儲存字串和數值,還可以儲存陣列、雜湊物件,甚至其他字典物件。字典能夠通過值或者參照儲存資料。
通過值儲存的資料型別有:
- 數值
- 字串
通過參照儲存的資料型別有:
- 陣列
- 雜湊物件
- 雜湊迭代器物件
- ASTORE 物件
- Python 物件
- 字典物件
宣告
字典物件使用以下語法進行宣告:
DECLARE DICTIONARY object-reference
DICTIONARY 可以使用縮寫 DNARY 進行替代。
方法
-
CLEAR : 清除字典物件的所有鍵值對
-
CLONE : 通過值儲存一個陣列
出於效能考慮,在預設情況下,陣列是通過參照進行儲存的,使用
CLONE()方法可以讓字典使用陣列的值進行儲存 -
DESCRIBE : 獲取字典指定位置處儲存的資料資訊
DESCRIBE()方法接受的第一個引數為一個變數 array-indicator,這個變數用於指示資料是否為陣列,可能的取值及其含義如下:- 1 : 指定位置儲存的資料是一個陣列
- 0 : 指定位置儲存的資料不是一個陣列
- MISSING : 指定位置沒有儲存任何資料
DESCRIBE()方法的返回值是一個數值 data-type,代表資料儲存的型別,可能的取值及其含義如下:- 1 : 雙精度浮點數
- 2 : 字元
- 0 : 缺失
- -1 : 字典
- -2 : 雜湊物件
- -3 : 雜湊迭代器
- -4 : 其他物件
- -5 : ASTORE 物件
- -6 : Python 物件
-
FIRST : 複製字典的第一個資料,並將迭代器指向第一個位置
-
HASNEXT : 指示字典是否存在下一個資料
-
HASPREV : 指示字典是否存在上一個資料
-
LAST : 複製字典的最後一個資料,並將迭代器指向最後一個位置
-
NEXT : 複製字典的下一個資料,並將迭代器指向下一個位置
-
NUM_ITEMS : 獲取字典儲存的資料個數
-
PREV : 複製字典的上一個資料,並將迭代器指向上一個位置
-
REF : 通過參照儲存一個數值或字串
-
REMOVE : 移除字典中指定的鍵值對
-
SKIPNEXT : 將迭代器指向下一個位置
-
SKIPPREV : 將迭代器指向上一個位置
Python
PROC FCMP 提供了 Python 物件,可以將 Python 函數嵌入到 SAS 程式當中,Python 程式碼並不會轉為 SAS 程式碼,而是使用 Python 直譯器進行執行,並將執行結果返回給 SAS。
環境依賴
軟體要求:
- SAS 9.4M6 或更高版本
- Python 2.7 或更高版本
環境變數設定
參考 Configuring SAS to Run the Python Language 設定環境變數。
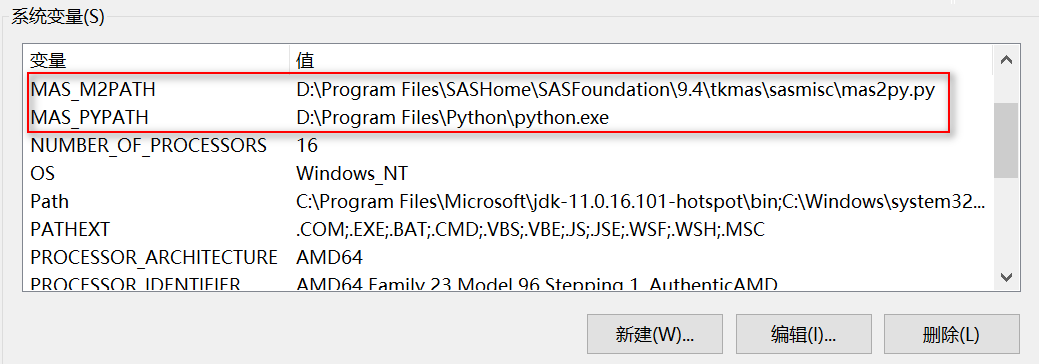
- 設定環境變數
MAS_M2PATH,路徑指向mas2py.py檔案的絕對路徑,例如:D:\Program Files\SASHome\SASFoundation\9.4\tkmas\sasmisc\mas2py.py - 設定環境變數
MAS_PYPATH,路徑指向 Python 可執行檔案的絕對路徑,例如:D:\Program Files\Python\python.exe
Python 函數工作流
在 PROC FCMP 中使用 Python 物件的典型工作流如下所述:
- 宣告一個 Python 物件
declare object py(python);
- 將 Python 原始碼插入到 SAS 程式中,例如:使用
SUBMIT INTO語句:
submit into py;
def PyProduct(var1, var2):
"Output: MyKey"
newvar = var1 * var2
return newvar,
endsubmit;
- 釋出 Python 原始碼
rc = py.publish();
- 呼叫 Python 原始碼
rc = py.call("MyPyFunc", var1, var2);
- 返回撥用結果。
MyResult = py.results["MyOutputKey"];
Python 物件的細節
元組和輸出結果
Python 函數定義的函數體中,第一行使用一個字串對返回值的形式進行定義。字串以 "Output: " 開頭,後面跟著代表函數返回值的鍵,多個返回值之間使用逗號隔開。Python 返回值被儲存在一個元組 (tuple) 中,使用鍵可以對指定的返回值進行存取。例如:下面的例子中定義了一個有兩個返回值的函數,並分別使用對應的鍵獲得返回值。
def MyFunction(foo):
"Output: Python_Return_Key1, Python_Return_Key2"
Tuple_Element1 = foo * 2
Tuple_Element2 = foo + 2
return Tuple_Element1, Tuple_Element2
My_Output1 = py.results["Python_Return_Key1"]
My_Output2 = py.results["Python_Return_Key2"]
單行長度限制
PROC FCMP 提交的 Python 原始碼的單行長度不能超過 255 個位元組。若存在超出 255 位元組長度的程式碼,應當使用字元 "",並在下一行繼續書寫程式碼
def MyPythonFunc(arg1, arg2, arg3):
"Output: MyOutputKey"
Result = arg1 + arg2 - arg3 + \
arg2 * arg1
return Result
型別轉換
SAS 會自動將 Python 程式碼的返回值轉換為合適的資料型別,需要注意的是,SAS 陣列不支援混合型別,因此這種轉換可能會造成資訊丟失。
例如:Python 程式碼執行後返回一個列表 [1, 2.3, 4.01],SAS 以列表中第一個非空元素的資料型別為基準,將剩餘所有元素的型別均轉換為這個型別,因此,SAS 將獲得陣列 [1, 2, 4]。
為了避免這種問題,可以嘗試在 Python 程式碼中返回列表 [float(1), 2.3, 4.01]。
日期時間
- 當 Python 返回日期時間結果至 SAS 時,SAS 會將日期時間轉換為合適的 SAS 日期時間;
- 當 Python 接受來自 SAS 的日期時間時,Python 無法自動將 SAS 日期時間轉換為合適的 Python 日期時間,因此,需要手動進行轉換
def get_date(indate):
"Output: outdate"
d = datetime.date(1960, 1, 1) + datetime.timedelta(days = indate)
return d.strftime('%m/%d/%Y')
註釋
在 PROC FCMP 中的 Python 程式碼中,只能使用字元 # 開頭的註釋,諸如 """This is my comment""" 之類的檔案註釋無法使用。
宣告
語法:DECLARE OBJECT object-reference(PYTHON<("module-name")>)
"module-name" 指定儲存在 Python 物件中的模組名稱,非函數名稱。
提交
語法:
- SUBMIT INTO object-reference; ...python-code... ENDSUBMIT;
- SUBMIT INTO object-reference("file-path")
方法
- APPEND : 在執行時向 Python 物件中追加 Python 程式碼
- CALL : 執行 Python 物件中的 Python 函數
- CLEAR : 清空 Python 物件中的已提交程式碼和返回結果
- INFILE : 在解析時向 Python 物件讀入外部檔案的 Python 原始碼
- PUBLISH : 向 Python 直譯器提交 Python 原始碼
- RESULTS : 獲取 Python 函數返回值構成的字典物件
- object-reference.RESULTS["output-key"]
- object-reference.RESULTS.CLEAR()
- RTINFILE : 在執行時向 Python 物件讀入外部檔案的 Python 原始碼
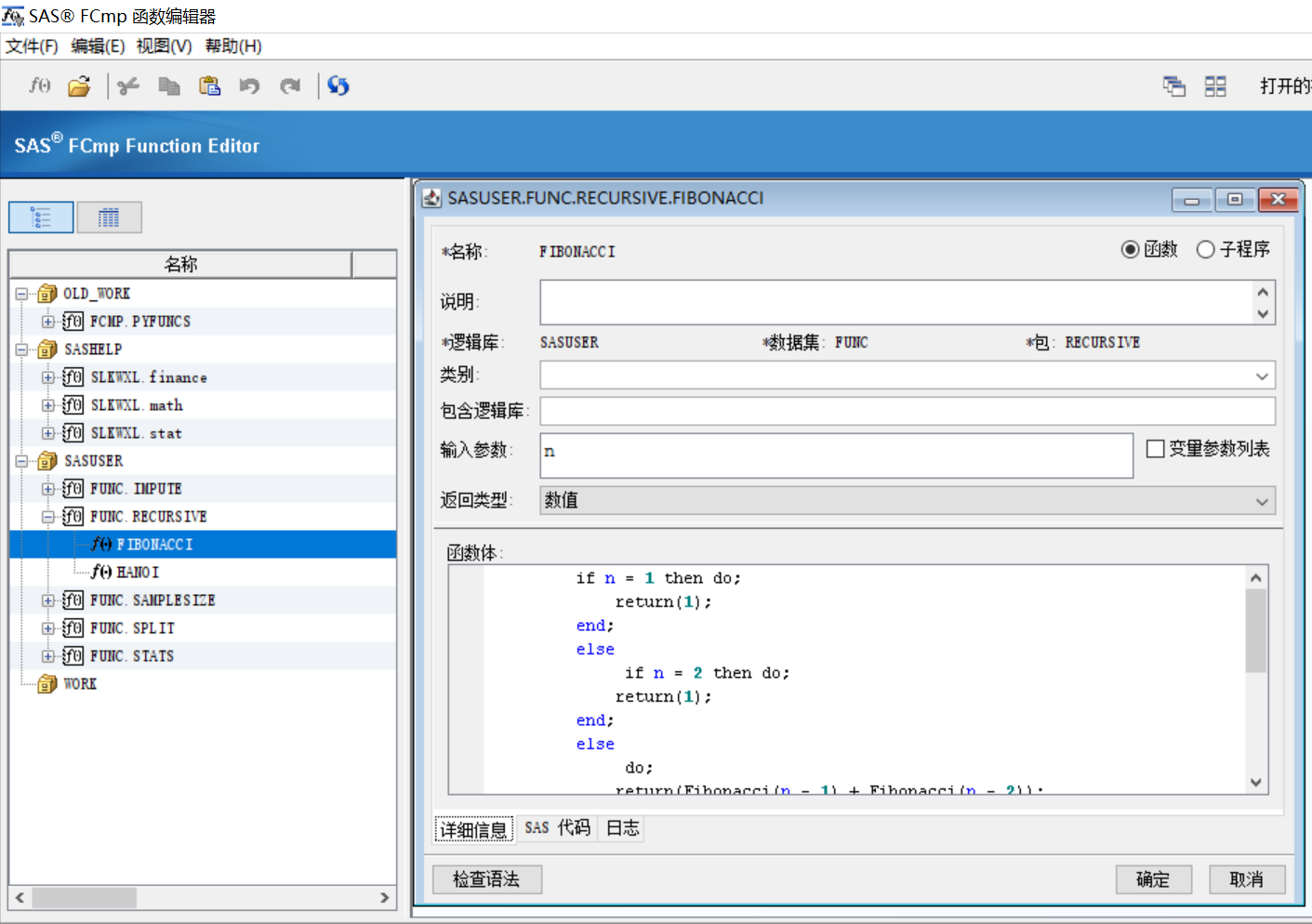
函數編輯器
SAS 系統提供了一個 FCMP 函數編輯器的圖形介面,可以在 Solution -> Analysis -> FCmp Function Editor 中找到。