PDF書籤的編輯器,基於(python、Tkinter)
2023-07-18 09:00:22
使用
指令碼
- 在github下載原始碼。
- 安裝python3
- 安裝必要的python包
pip install numpy
pip install pandas
pip install PyMuPDF
pip install opencv
pip install easyocr
easyocr模型可以不下載,在原始碼easy資料夾中有。
按照PyTorch官網的說明,下載PyTorch。
- 執行:ATMA.py
windows程式
在百度網路硬碟下載。資料夾下有兩個檔案,選擇一個下載。
- atma_64_F.zip: pyinstaller打包的單檔案,啟動慢,但是解壓後檔案相對較小。
- atma_64_D.zip: 啟動比較快,但是資料夾大。找到資料夾下ATMA.exe開啟即可使用。
基本功能
-
編輯書籤
1.1 貼上網上覆制而來的目錄文字: (1) 點選選單欄"自動修改",會自動修改縮排(如果文字中含有"章節"等字眼,或者含有"1.2.3"這樣的序數的話), 自動刪去不必要的空字元,標點…… (2) 點選選單"跳轉頁碼",修改跳轉頁碼, (3) 手動檢查修改一些瑕疵,然後選擇pdf,匯入書籤。 (4)圖中的羅馬數位不能識別為頁碼,已修復。
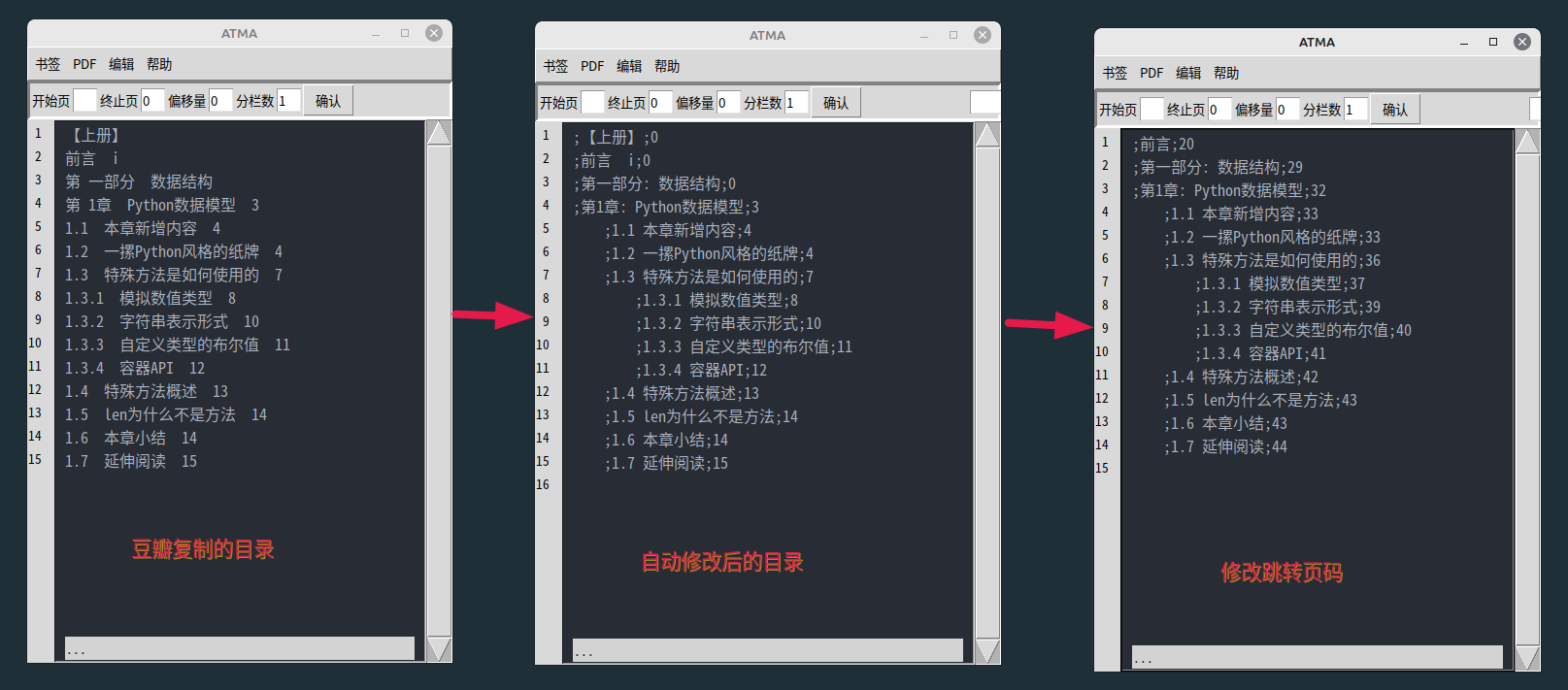
1.2 修改PDF中的書籤。匯出pdf書籤……修改……匯入
-
提取PDF目錄頁的的文字,形成書籤
速度快。 效果如下圖。 (1) 第一行的是自動插入的。 (2) 提取目錄時指令碼會嘗試自動刪除頁首頁尾等無用的文字。但這些文字跨越多行的話,不能自動刪除。 (3) 總體而言,如果PDF是文字版的,且其中的文字原本就沒有錯誤(很多PDF中的文字是OCR的), 那麼效果還可以,不需要多少人工編輯就可以匯入PDF。
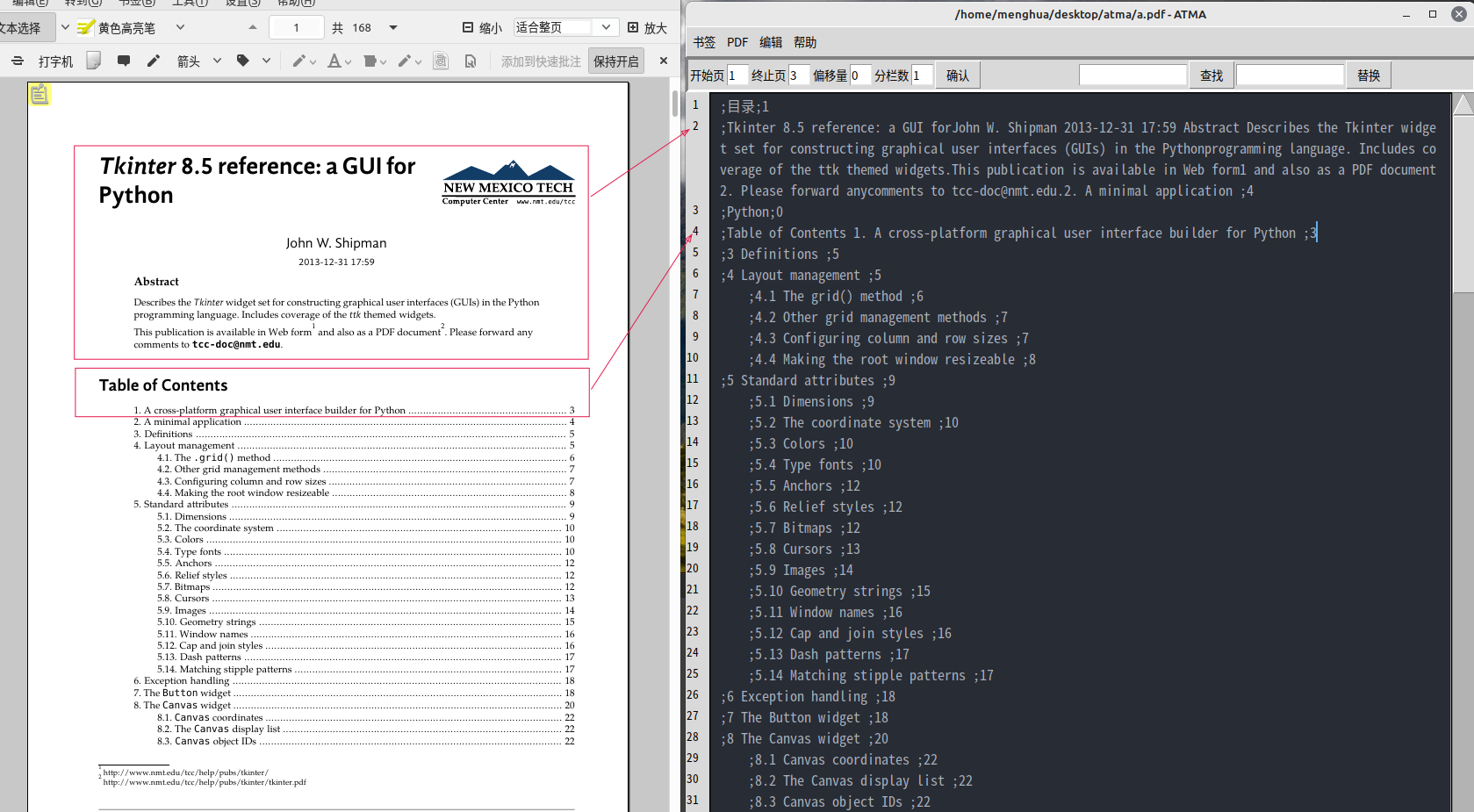
-
OCR識別PDF目錄頁面文字:
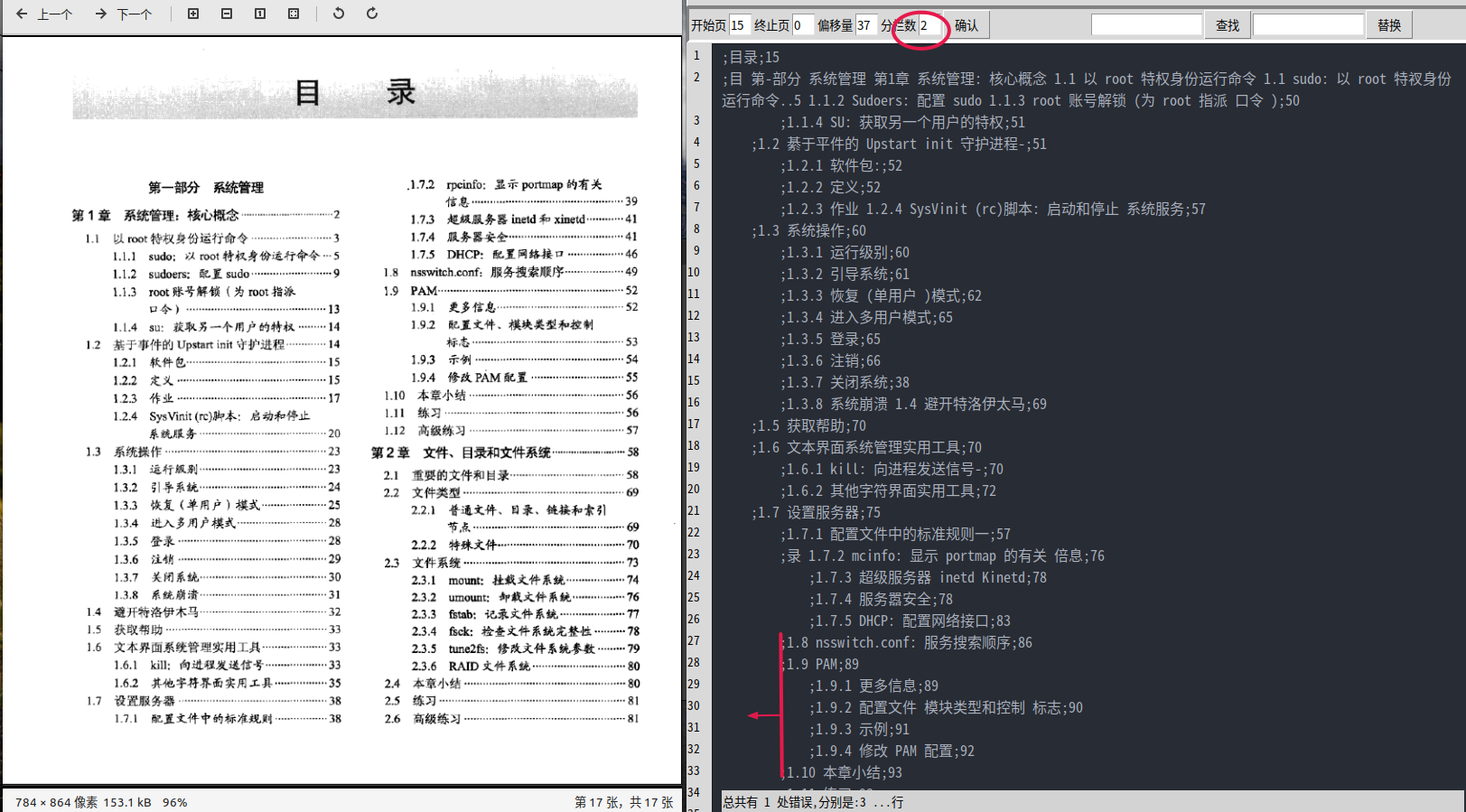
缺點是速度慢。如果PDF清晰的話,基本沒什麼錯字。 效果如下圖: (1) 識別前可以設定頁碼偏移。這樣就會將目錄頁碼根據這個偏移量而修改(一般是增加)。 (2) 一個比較普遍的問題就是,頁碼數位比較小(只有個位數)的話,因為文字框比較小, 很有可能會被OCR引擎忽略而不識別。

(3) 如果目錄分兩欄、三欄,一定要在引數裡做相應設定。這樣會在識別提前將圖片裁分。
(4) 下圖OCR輸出的結果,書籤縮排有錯誤。可以點選"自動修改",自動修改縮排。
介面
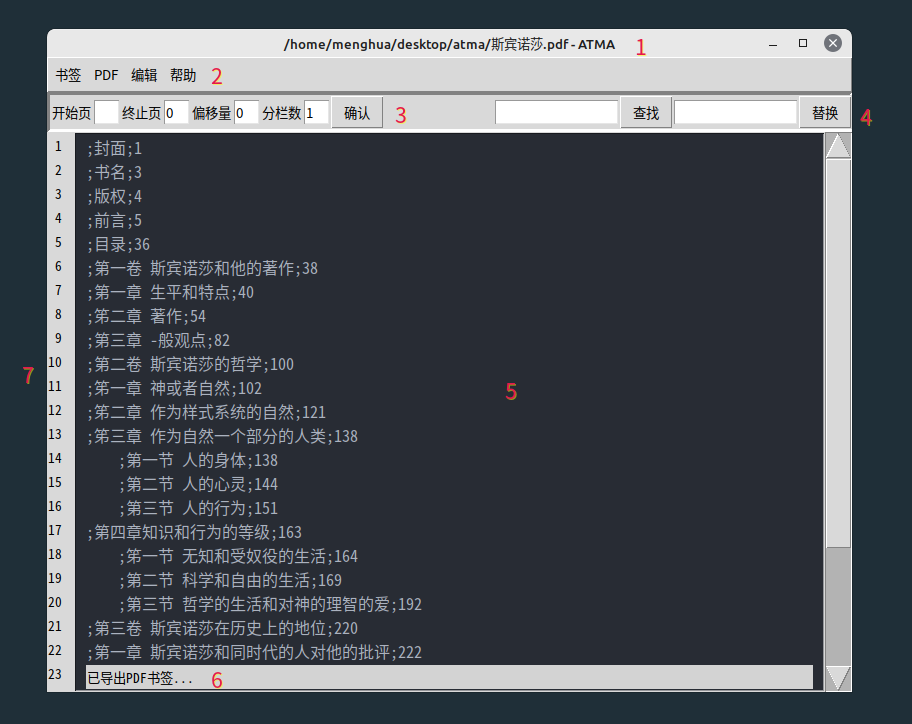
-
標題
沒有選擇pdf的情況下,顯示"ATMA"。如果選擇了PDF,顯示PDF的檔名+ATMA -
選單
2.1 書籤:開啟、儲存、檢查、自動修改文字檔案 2.1.1 新建 2.1.2 開啟 2.1.3 儲存 2.1.4 檢查 匯入書籤前可以點選"檢查",檢查書籤格式是否有錯誤。正確的(可以匯入)書籤至少滿足下面的要求: (1) 每一條書籤(每一行)的縮排不比上一條書籤的縮排大2個層級。 (2) 每一條書籤都有三個資料(兩個英文分號)。 (3) 每條書籤的跳轉頁碼不大於PDF的頁面數。 檢查過後會在軟體下方顯示有錯誤的行的行號。 2.1.5 自動修改 (1) 如果書籤文字中有"章節",序號(如」1.2「)等字眼,會自動修改資料的縮排。 (2) 提取每行最後的數位作為書籤跳轉頁碼。 (3) 格式化每一行。如果沒有跳轉頁碼,將跳轉頁碼設為0。 2.1.6 自動修改(保持縮排) 和上一個選單作用類似,但是不會修改縮排。 2.2 PDF:選擇操作的PDF,匯入匯出書籤,從PDF頁面中中獲取書籤文字 2.2.1 選擇PDF 選擇操作的PDF檔案。 2.2.2 增量儲存 將書籤直接儲存到原PDF中。(類似於一般理解的save,覆蓋儲存)但是,這需要PDF支援。 如果PDF不支援增量儲存(增量儲存不成功),就選擇下方的"另存為"。 2.2.3 另存為 將書籤匯入PDF中,然後將PDF儲存為另一個檔案。 2.3.4 匯出書籤 將PDF中的書籤匯出。 2.3.5 讀取目錄 如果PDF是文字版的PDF,可以嘗試通過讀取PDF目錄頁面中文字,形成書籤。 2.3.6 OCR目錄 如果PDF是圖片版的,選擇這個。相比上個選項,OCR速度會比較慢。 2.3 編輯 2.3.1 正則替換 選單欄下面的"替換"按鈕是不支援正則的。如果想要使用正則替換, 在下方輸入框輸入搜尋的文字和要替換的文字,然後點選該選單選項。 -
引數輸入框
輸入引數,然後點選確定。 "讀取目錄","OCR目錄"需要一些引數。這些引數在這裡輸入,輸入後點選確定。 3.1 開始頁:目錄頁面開始的頁碼 3.2 終止頁:目錄頁面終止的頁面。如果終止頁是"0",表示唯讀取"開始頁"的那一頁。預設值是0. 3.3 偏移量:目錄中頁碼數位與實際要跳轉的頁碼直接的差值。 3.4 分欄數:目錄頁面分欄的數目。OCR的時候需要設定這個引數。預設值是1,即不分欄(只有一欄)。 -
查詢、替換框。
不支援正則。查詢、替換的結果會高亮。 要使用正則替換,先在這裡輸入好文字,然後點選選單欄裡的"正則替換"。 -
文字方塊
輸入Tab會轉換成四個空格。 不穩定,不要用來編輯其他檔案。 -
狀態列
顯示一些操作相關的結果 -
行號