2023了,學習深度學習框架哪個比較好?
都2023年,才來回答這個問題,自然毫無懸念地選擇PyTorch,TensorFlow在大模型這一波浪潮中沒有起死回生,有點惋惜,現在GLM、GPT、LLaMA等各種大模型都是基於PyTorch框架構建。這個事情已經水落石出。
不過呢,我覺得可以一起去回顧下,在AI框架發展的過程中,都沉陷了哪些技術點,為什麼一開始這麼多人在糾結到底用哪個框架。
我們知道AI框架在數學上對自動微分進行表達和處理,最後表示稱為開發者和應用程式都能很好地去編寫深度學習中神經網路的工具和庫,整體流程如下所示:
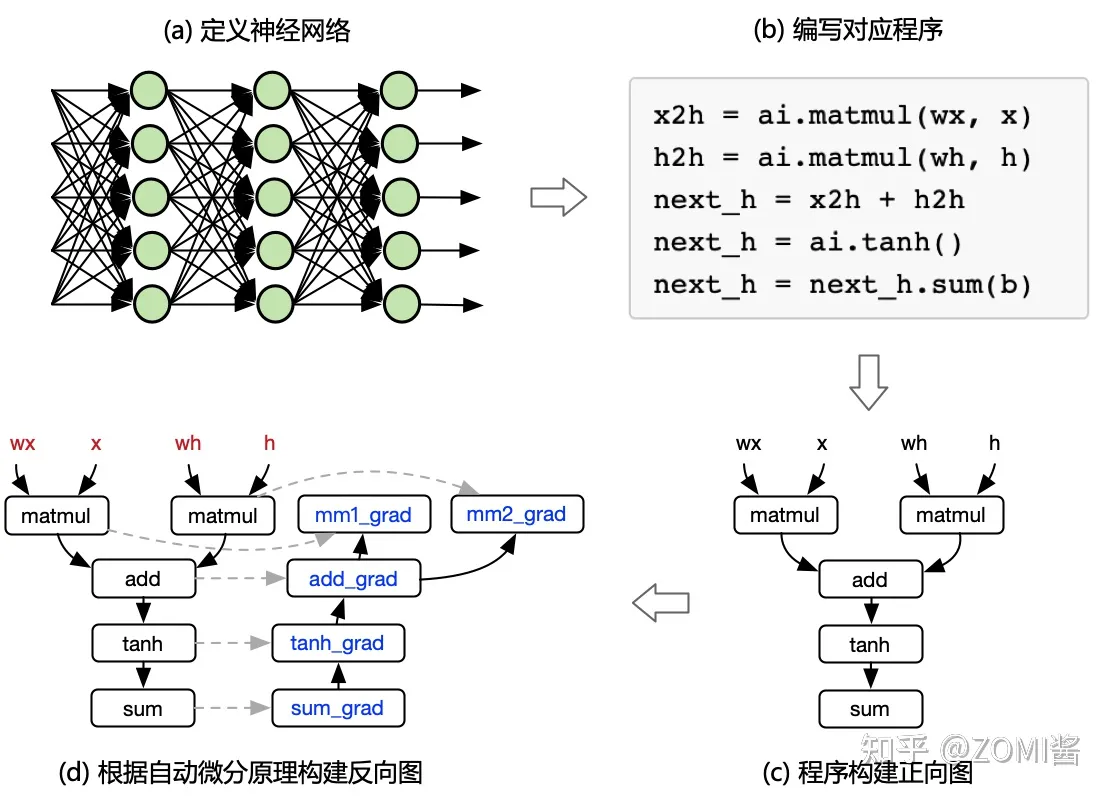
除了要回答最核心的數學表示原理意外,實際上AI框架還要思考和解決許多問題,如AI框架如何對實際的神經網路實現多執行緒運算元加速?如何讓程式執行在GPU/NPU上?如何編譯和優化開發者編寫的程式碼?因此,一個能夠商用版本的AI框架,需要系統性梳理每一層中遇到的具體問題,以便提供相關更好的開發特性:
- 前端(面向使用者):如何靈活的表達一個深度學習模型?
- 運算元(執行計算):如何保證每個運算元的執行效能和泛化性?
- 微分(更新引數):如何自動、高效地提供求導運算?
- 後端(系統相關):如何將同一個運算元跑在不同的加速裝置上?
- 執行時:如何自動地優化和排程網路模型進行計算?
下面內容將會去總結AI框架的目的,其要求解決的技術問題和數學問題;瞭解了其目的後,真正地去根據時間的維度和和技術的維度梳理AI框架的發展脈絡,並對AI框架的未來進行思考。
AI框架的目的
神經網路是機器學習技術中一類具體演演算法分枝,通過堆疊基本處理單元形成寬度和深度,構建出一個帶拓撲結構的高度複雜的非凸函數,對蘊含在各類資料分佈中的統計規律進行擬合。傳統機器學習方法在面對不同應用時,為了達到所需的學習效果往往需要重新選擇函數空間設計新的學習目標。
相比之下,神經網路方法能夠通過調節構成網路使用的處理單元,處理單元之間的堆疊方式,以及網路的學習演演算法,用一種較為統一的演演算法設計視角解決各類應用任務,很大程度上減輕了機器學習演演算法設計的選擇困難。同時,神經網路能夠擬合海量資料,深度學習方法在影象分類,語音識別以及自然語言處理任務中取得的突破性進展,揭示了構建更大規模的神經網路對大規模資料進行學習,是一種有效的學習策略。
然而,深度神經網路應用的開發需要對軟體棧的各個抽象層進行程式設計,這對新演演算法的開發效率和算力都提出了很高的要求,進而催生了 AI 框架的發展。AI框架可以讓開發者更加專注於應用程式的業務邏輯,而不需要關注底層的數學和計算細節。同時AI框架通常還提供視覺化的介面,使得開發者可以更加方便地設計、訓練和優化自己的模型。在AI框架之上,還會提供了一些預訓練的網路模型,可以直接用於一些常見的應用場景,例如影象識別、語音識別和自然語言處理等。
AI 框架的目的是為了在計算加速硬體(GPU/NPU)和AI叢集上高效訓練深度神經網路而設計的可程式化系統,需要同時兼顧以下互相制約設計目標可程式化性與效能。
1. 提供靈活的程式設計模型和程式設計介面
自動推導計算圖:根據客戶編寫的神經網路模型和對應的程式碼,構建自動微分功能,並轉換為計算機可以識別和執行的計算圖。
較好的支援與現有生態融合:AI應用層出不窮,需要提供良好的程式設計環境和程式設計體系給開發者方便接入,這裡以PyTorch框架為例對外提供超過2000+ API。
提供直觀的模型構建方式,簡潔的神經網路計算程式語言:使用易用的程式設計介面,用高層次語意描述出各類主流深度學習模型和訓練演演算法。而在程式設計正規化主要是以宣告式程式設計和指令式程式設計為主,提供豐富的程式設計方式,能夠有效提提升開發者開發效率,從而提升AI框架的易用性。
2. 提供高效和可延伸的計算能力
自動編譯優化演演算法:為可複用的處理單元提供高效實現,使得AI演演算法在真正訓練或者推理過程中,執行得更快,需要對計算圖進行進一步的優化,如子表示式消除、核心融合、記憶體優化等演演算法,支援多裝置、分散式計算等。
根據不同體系結構和硬體裝置自動並行化:體系結構的差異主要是指標對 GPU、NPU、TPU等AI加速硬體的實現不同,有必要進行深度優化,而面對大模型、大規模分散式的衝擊需要對自動分散式化、擴充套件多計算節點等進行效能提升。
降低新模型的開發成本:在新增新計算加速硬體(GPU/NPU)支援時,降低增加計算原語和進行計算優化的開發成本。
AI框架的發展
AI 框架作為智慧經濟時代的中樞,是 AI 開發環節中的基礎工具,承擔著 AI 技術生態中作業系統的角色,是 AI 學術創新與產業商業化的重要載體,助力 AI 由理論走入實踐,快速進入了場景化應用時代,也是發展 AI 所必需的基礎設施之一。隨著重要性的不斷凸顯,AI 框架已經成為了 AI 產業創新的焦點之一,引起了學術界、產業界的重視。
時間維度
結合 AI 的發展歷程,AI 框架在時間維度的發展大致可以分為四個階段,分別為1)2000 年初期的萌芽階段、2)2012~2014年的成長階段、3)2015 年~2019 年的爆發階段,和4)2020 年以後深化階段。

其在時間的發展脈絡與 AI ,特別是深度學習正規化下的神經網路技術的異峰突起有非常緊密的聯絡。
- 萌芽階段
在2020年前,早期受限於計算能力不足,萌芽階段神經網路技術影響力相對有限,因而出現了一些傳統的機器學習工具來提供基本支援,也就是 AI 框架的雛形,但這些工具或者不是專門為神經網路模型開發客製化的,或者 API 極其複雜對開發者並不友好,且並沒有對異構加速算力(如GPU/NPU等)進行支援。缺點在於萌芽階段的 AI 框架並不完善,開發者需要編寫大量基礎的工作,例如手寫反向傳播、搭建網路結構、自行設計優化器等。
其以 Matlab 的神經網路庫為代表作品。

- 成長階段
2012 年,Alex Krizhevsky 等人提出了 AlexNet 一種深度神經網路架構,在 ImageNet 資料集上達到了最佳精度,並碾壓第二名提升15%以上的準確率,引爆了深度神經網路的熱潮。
自此極大地推動了 AI 框架的發展,出現了 Caffe、Chainer 和 Theano 等具有代表性的早期 AI 框架,幫助開發者方便地建立複雜的深度神經網路模型(如 CNN、RNN、LSTM 等)。不僅如此,這些框架還支援多 GPU 訓練,讓開展更大、更深的模型訓練成為可能。在這一階段,AI 框架體系已經初步形成,宣告式程式設計和指令式程式設計為下一階段的 AI 框架發展的兩條截然不同的道路做了鋪墊。
- 爆發階段
2015 年,何愷明等人提出的 ResNet,再次突破了影象分類的邊界,在 ImageNet 資料集上的準確率再創新高,也凝聚了產業界和學界的共識,即深度學習將成為下一個重大技術趨勢。
2016年 Google 開源了 TensorFlow 框架,Facebook AI 研究團隊也釋出了基於動態圖的AI框架 PyTorch,該框架拓展自 Torch 框架,但使用了更流行的 Python 進行重構整體對外 API。Caffe 的發明者加入了 Facebook(現更名為 Meta)並行布了 Caffe2 並融入了 PyTorch 的推理生態;與此同時,微軟研究院開發了 CNTK 框架。Amazon 採用了這是華盛頓大學、CMU 和其他機構的聯合學術專案 MXNet。國內百度則率先佈局了 PaddlePaddle 飛槳AI框架並於 2016 年釋出。
在 AI 框架的爆發階段,AI系統也迎來了繁榮,而在不斷髮展的基礎上,各種框架不斷迭代,也被開發者自然選擇。經過激烈的競爭後,最終形成了兩大陣營,TensorFlow 和 PyTorch 雙頭壟斷。2019 年,Chainer 團隊將他們的開發工作轉移到 PyTorch,Microsoft 停止了 CNTK 框架的積極開發,部分團隊成員轉而支援 PyTorch;Keras 被 TensorFlow 收編,並在 TensorFlow2.X 版本中成為其高階 API 之一。
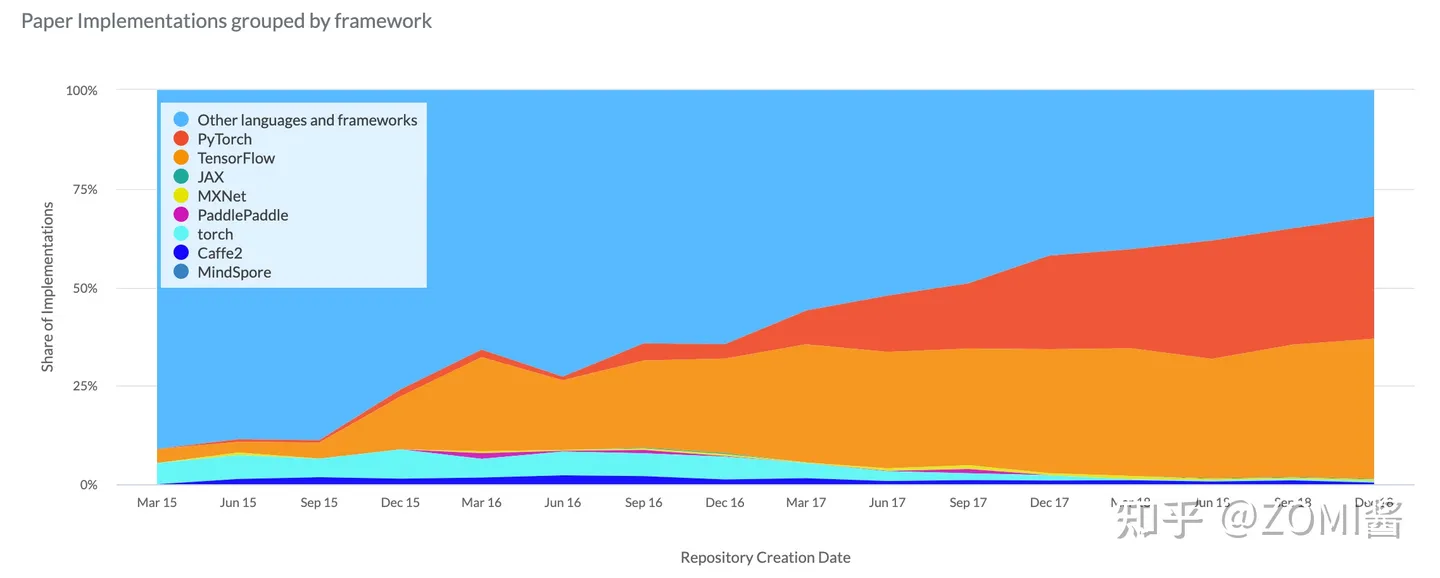
- 深化階段
隨著 AI 的進一步發展,AI 應用場景的擴充套件以及與更多領域交叉融合程序的加快,新的趨勢不斷湧現,越來越多的需求被提出。
例如超大規模模型的出現(GPT-3、ChatGPT等),新的趨勢給 AI 框架提出了更高的要求。例如超大規模模型的出現(GPT-3、ChatGPT等);如對全場景多工的支援、對異構算力支援等。這就要求 AI 框架最大化的實現編譯優化,更好地利用算力、調動算力,充分發揮叢集硬體資源的潛力。此外,AI 與社會倫理的痛點問題也促使可信賴 AI 、或則 AI 安全在 AI 框架層面的進步。
基於以上背景,現有的主流 AI 框架都在探索下一代 AI 框架的發展方向,如 2020 年華為推出昇思 MindSpore,在全場景協同、可信賴方 面有一定的突破;曠視推出天元 MegEngine,在訓練推理一體化方面深度佈局;PyTorch 捐贈給 Linux 基金會,並面向圖模式提出了新的架構和新的版本 PyTorch2.X。
在這一階段,AI 框架正向著全場景支援、大模型、分散式AI、 超大規模 AI、安全可信 AI 等技術特性深化探索,不斷實現新的突破。
技術維度
以技術維度的角度去對 AI 框架進行劃分,其主要經歷了三代架構,其與深度學習正規化下的神經網路技術發展和程式語言、及其程式設計體系的發展有著緊密的關聯。

- 第一代AI框架
第一代 AI 框架在時間上主要是在 2010 年前,面向需要解決問題有:1)機器學習 ML 中缺乏統一的演演算法庫,2)提供穩定和統一的神經網路 NN 定義。其對應的AI框架框架其實廣義上並不能稱為 AI 框架,更多的是對機器學習中的演演算法進行了統一的封裝,並在一定程度上提供了少量的神經網路模型演演算法和API的定義。具體形態有2種:
第一種的主要特點的是以庫(Library)的方式對外提供指令碼式程式設計,方便開發者通過簡單設定的形式定義神經網路,並且針對特殊的機器學習 ML、神經網路NN演演算法提供介面,其比較具有代表性意義的是 MATLAB 和 SciPy。另外還有針對矩陣計算提供特定的計算介面的 NumPy。優點是:面向 AI 領域提供了一定程度的可程式化性;支援CPU加速計算。
第二種的在程式設計方面,以CNN網路模型為主,由常用的layers組成,如:Convolution, Pooling, BatchNorm, Activation等,都是以Layer Base為驅動,可以通過簡單組態檔的形式定義神經網路。模型可由一些常用layer構成一個簡單的圖,AI 框架提供每一個layer及其梯度計算實現。這方面具有代表性的作品是 Torch、Theano 等AI框架。其優點是提供了一定程度的可程式化性,計算效能有一定的提升,部分支援 GPU/NPU 加速計算。
同時,第一代 AI 框架的缺點也比較明顯,主要集中在1)靈活性和2)面向新場景支援不足。
首先是易用性的限制難以滿足深度學習的快速發展,主要是層出不窮的新型網路結構,新的網路層需要重新實現前向和後向計算;其次是第一代 AI 框架大部分使用非高階語言實現,修改和客製化化成本較高,對開發者不友好。最後是新優化器要求對梯度和引數進行更通用複雜的運算。
隨著生成對抗網路模型 GAN、深度強化學習 DRL、Stable Diffusion 等新的結構出現,基於簡單的「前向+後向」的訓練模式難以滿足新的訓練模式。例如迴圈神經網路 LSTM 需要引入控制流、對抗神經網路 GAN 需要兩個網路交替訓練,強化學習模型 RL 需要和外部環境進行互動等眾多場景沒辦法滿足新湧現的場景。
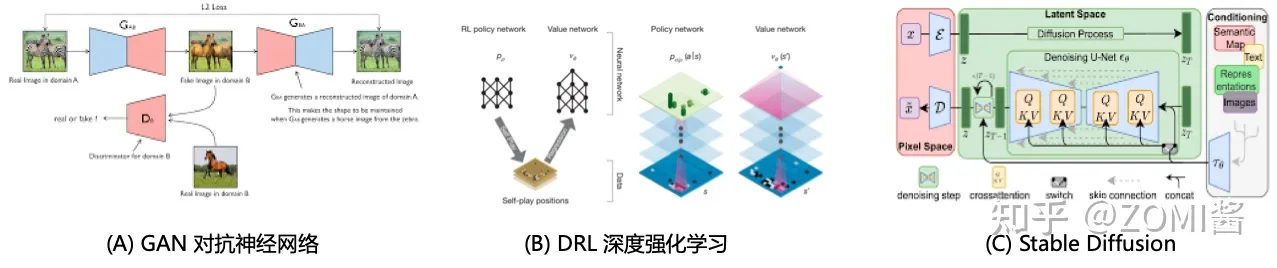
- 第二代AI框架
第二代AI框架在技術上,統一稱為基於資料流圖(DAG)的計算框架:將複雜的神經網路模型,根據資料流拆解為若干處理環節,構建資料流圖,資料流圖中的處理環節相互獨立,支援混合編排控制流與計算,以任務流為最終導向,AI 框架將資料流圖轉換為計算機可以執行或者識別的任務流圖,通過執行引擎(Runtime)解析任務流進行處理環節的分發排程、監控與結果回傳,最終實現神經網路模型的構建與執行。
以資料流圖描述深度神經網路,前期實踐最終催生出了工業級 AI 框架,如TensorFlow 和PyTorch,這一時期同時伴隨著如Chainer,DyNet等激發了 AI 框架設計靈感的諸多實驗專案。TensorFlow 和 PyTorch 代表了現今 AI 框架框架的兩種不同的設計路徑:系統效能優先改善靈活性,和靈活性易用性優先改善系統效能。
這兩種選擇,隨著神經網路演演算法研究和應用的更進一步發展,又逐步造成了 AI 框架在具體技術實現方案的分裂。
- 第三代AI框架
在第三代 AI 框架中,面向通用化場景,如 CNN、LSTM、RNN 等場景開始走向統一的設計架構,不同的AI框架在一定程度都會模仿或者參考 PyTorch 的動態圖 Eager 模式,提升自身框架的易用性,使其更好地接入 AI 生態中。
目前在技術上一定程度開始邁進第三代AI框架,其主要面向設計特定領域語言(Domain-Specific Language,DSL)。最大的特性是:1)兼顧程式設計的靈活性和計算的高效性;2)提高描述神經網路演演算法表達能力和程式設計靈活性;3)通過編譯期優化技術來改善執行時效能。
具體面向不同的業務場景會有一些差異(即特定領域),如 JAX 是 Autograd 和 XLA 的結合,作為一個高效能的數值計算庫,更是結合了可組合的函數轉換庫,除了可用於AI場景的計算,更重要的是可以用於高效能機器學習研究。例如Taichi面向圖形影象可微分程式設計,作為開源平行計算框架,可以用於雲原生的3D內容創作。

AI框架的未來
應對未來多樣化挑戰,AI 框架有以下技術趨勢:
全場景
AI 框架將支援端邊雲全場景跨平臺裝置部署
網路模型需要適配部署到端邊雲全場景裝置,對 AI 框架提出了多樣化、複雜化、碎片化的挑戰。隨著雲伺服器、邊緣裝置、終端 裝置等人工智慧硬體運算裝置的不斷湧現,以及各類人工智慧運算庫、中間表示工具以及程式設計框架的快速發展,人工智慧軟硬體生態呈現多樣化發展趨勢。
但目前主流 AI 框架仍然分為訓練部分和推理部分,兩者不完全相容。訓練出來的模型也不能通用,學術科研專案間難以合作延伸,造成了 AI 框架的碎片化。目前業界並沒有統一的中間表示層標準,導致各硬體廠商解決方案存在一定差異,以致應用模型遷移不暢,增加了應用部署難度。因此,基於AI框架訓練出來的模型進行標準化互通將是未來的挑戰。
易用性
AI 框架將注重前端便捷性與後端高效性的統一
AI 框架需要提供更全面的 API 體系以及前端語言支援轉換能力,從而提升前端開發便捷性。AI 框架需要能為開發者提供完備度 高、效能優異、易於理解和使用的 API 體系。
AI 框架需要提供更為優質的動靜態圖轉換能力,從而提升後端執行高效性。從開發者使用 AI 框架來實現模型訓練和推理部署的角度看,AI 框架需要能夠通過動態圖的程式設計正規化,來完成在模型訓練的開發階段的靈活易用的開發體驗,以提升模型的開發效率;通過靜態圖的方式來實現模型部署時的高效能執行;同時,通過動態圖轉靜態圖的方式,來實現方便的部署和效能優化。目前 PyTorch2.0 的圖編譯模式走在業界前列,不一定成為最終形態,在效能和易用性方面的兼顧仍然有待進一步探索。
大規模分散式
AI 框架將著力強化對超大規模 AI 的支援
OpenAI 於 2020 年 5 月釋出 GPT-3 模型,包含 1750 億引數,資料集(處理前)達到 45T, 在多項 NLP 任務中超越了人類水平。隨之 Google 不斷跟進分散式技術,超大規模 AI 逐漸成為新的深度學習正規化。
超大規模 AI 需要大模型、巨量資料、大算力的三重支援,對 AI 框架也提出了新的挑戰,
- 記憶體:大模型訓練過程中需要儲存引數、啟用、梯度、優化器狀態,
- 算力:2000 億引數量的大模型為例,需要 3.6EFLOPS 的算力支援,必要構建 AI 計算叢集滿足算力需求
- 通訊:大模型並行切分到叢集後,模型切片之間會產生大量通訊,從而通訊就成了主要的瓶頸
- 調優:E 級 AI 算力叢集訓練千億引數規模,節點間通訊複雜,要保證計算正確性、效能和可用性,手動偵錯難以全面兼顧,需要更自動化的偵錯調優手段
- 部署:超大規模 AI 面臨大模型、小推理部署難題,需要對大模型進行完美壓 縮以適應推理側的部署需求
科學計算
AI框架將進一步與科學計算深度融合交叉
傳統科學計算領域亟需 AI 技術加持融合。計算圖形可微程式設計,類似Taichi這樣的語言和框架,提供可微物理引擎、可微渲染引擎等新功能。因此未來是一個AI與科學計算融合的時代,傳統的科學計算將會結合AI的方法去求解既定的問題。至於AI與科學計算結合,看到業界在探索三個方向:
利用 AI 神經網路進行建模替代傳統的計算模型或者數值模型,目前已經有很大的進展了,如拿了戈登貝爾獎的分子動力學模型DeepMD。
AI求解,模型還是傳統的科學計算模型,但是使用深度學習演演算法來求解,這個方向已經有一定的探索,目前看到不少基礎的科學計算方程已經有對應的AI求解方法,比如PINNs、PINN-Net等,當然現在挑戰還很大,特別是在精度收斂方面,如果要在AI框架上使用AI求解科學計算模型,最大的挑戰主要在前端表達和高效能的高階微分。
使用AI框架來加速方程的求解,科學計算的模型和方法都不變的前提下,與深度學習使用同一個框架來求解,其實就是把AI框架看成面向張量計算的通用分散式計算框架。
本節總結
本節內容回顧了AI框架在時間維度和技術維度的發展趨勢
技術上初代AI框架解決AI程式設計問題,第二代加速科研和產業落地,第三代結合特定領域語言和任務
一起學習了AI框架隨著的軟硬體的發展升級而共同發展,展望AI框架的未來