ChatGPT在工業領域的研究與應用探索-產品化部署及應用
《ChatGPT在工業領域的研究與應用探索-資料與工況認知》
《ChatGPT在工業領域的研究與應用探索-AI助手實驗應用》
ChatGPT在工業領域的應用需要解決兩個問題:(1).私有化部署,並且保障工業企業資料資產安全;(2).要有具體領域的基礎資料,能夠訓練出來模型,因為有些工業企業沒有自己的資訊化系統,還基本靠手工紙製填報、Excel彙報的方式來處理資訊,這些資料沒有辦法有效利用和形成資料資產。
缺少可以訓練ChatGPT模型的基礎資料是最難解決的問題,這不是短週期可以解決的問題,有資料積累的過程,還有工業企業規劃專案不見效益不建設的特點,這也是生產型企業的特點,畢竟自己賺錢才能自己花,也是可以理解的。
一項新技術的出現,可能給大部分領域帶來翻天覆地的變化,可能促進部分領域發生改變,這都是價值的體現,不能排斥新技術與領域的結合應用。例如每個專案都規劃有「知識庫」的功能,一開始知識庫只是檢索檔案標題關鍵字;後來有檔案資料庫可以進行全文檢索及進行內容模糊關聯;ChatGPT至少可以在知識庫這塊完成更高層次應用,語意理解、邏輯推理、知識整合等。
有些使用者或是專家在專案建設中提出來要提煉工藝庫、模型庫、演演算法庫等,可能是眼界不夠高及接觸的比較狹窄,至今也沒有看到建設比較好的**庫。可以試著讓ChatGPT成為每個角色的助手,例如工藝的、資訊化的、裝置的、電氣的等角色,讓ChatGPT成為自己,再不斷的迭代它。基於這樣的想法,從搞資訊化角度,至少要考慮兩個方面的內容:框架和產品應用。
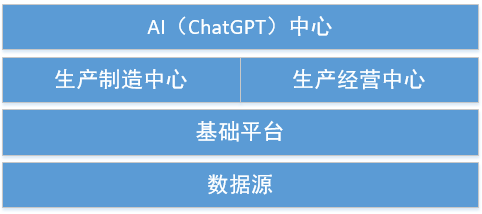
從大的框架角度來考慮,ChatGPT扮演AI助手的角色,應用越來越發揮出來應有的價值,所以工業系統化專案整體框架會發生一些改變。如下圖:
從產品應用角度考慮,肯定要有一套成熟的類ChatGPT產品化系統,支援私有化部署,支援不同角色的人上傳自己的基礎資料,並且訓練出來模型,實現具體應用場景的問答。
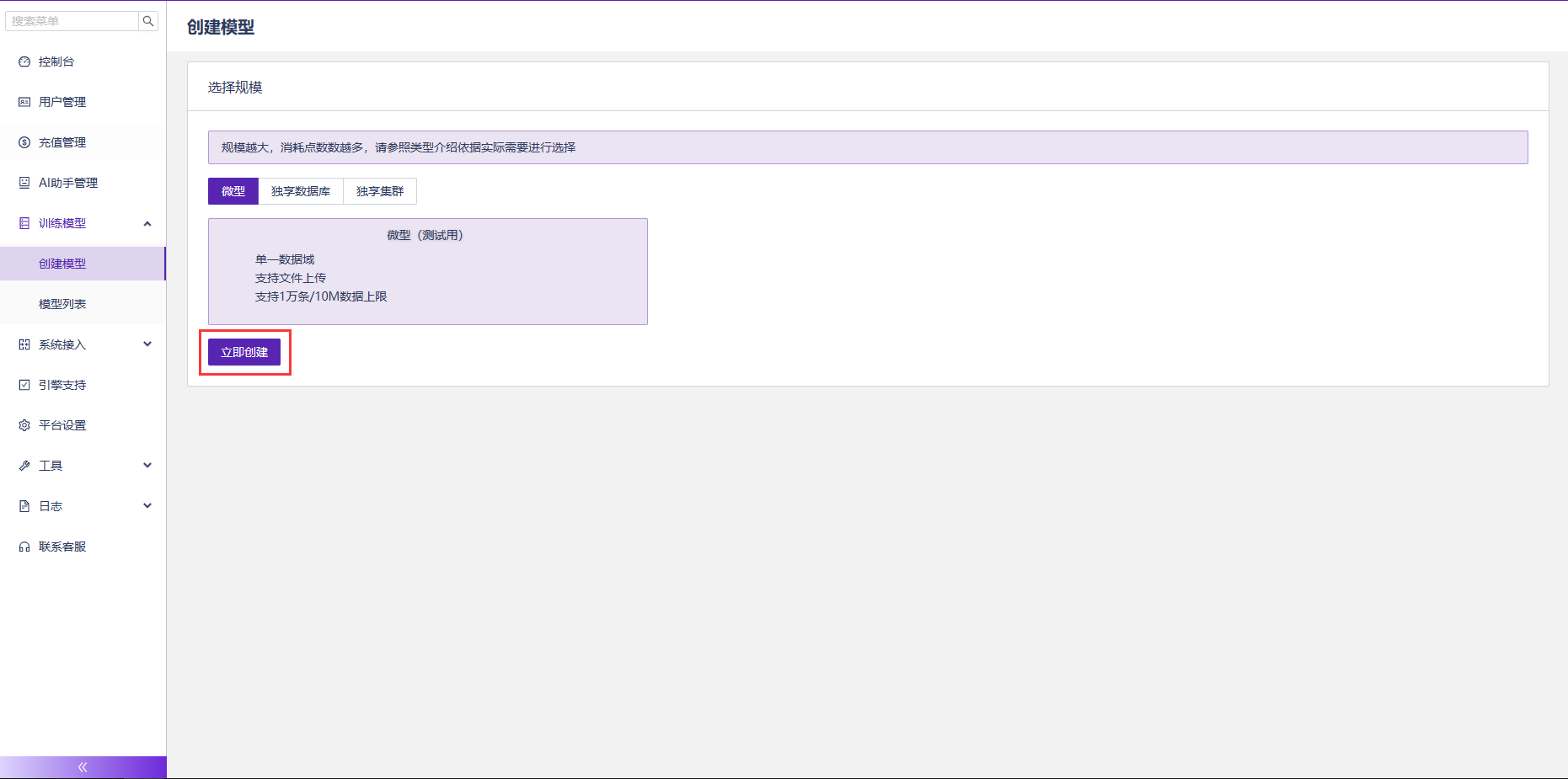
(1)建立一個模型,用於上傳基礎資料和訓練模型。如下圖:
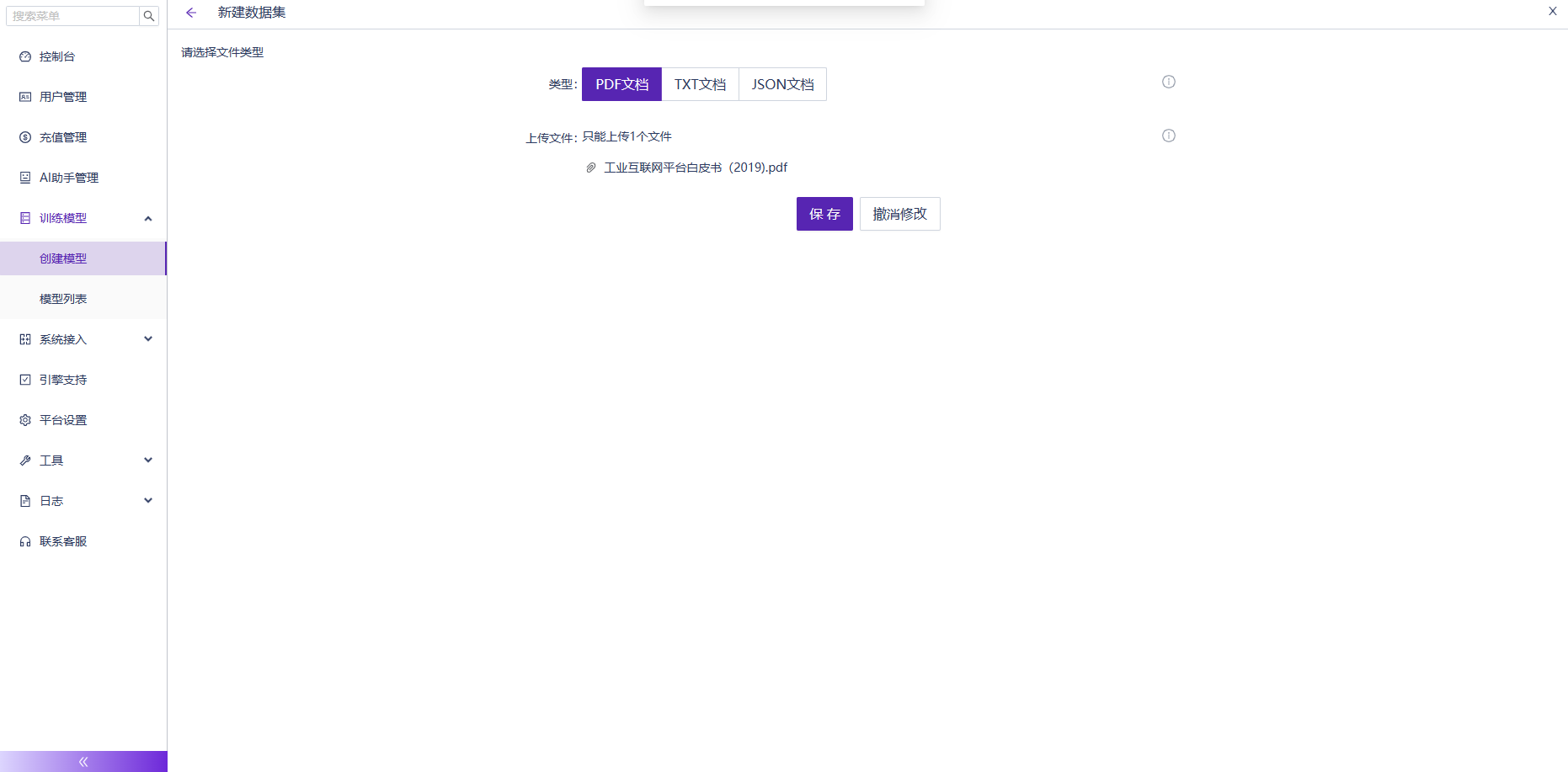
(2)我是一名資訊化工程師,我把《工業互聯平臺白皮書》上傳到該模型,現在支援PDF\TXT\JSON格式的檔案。如下圖:
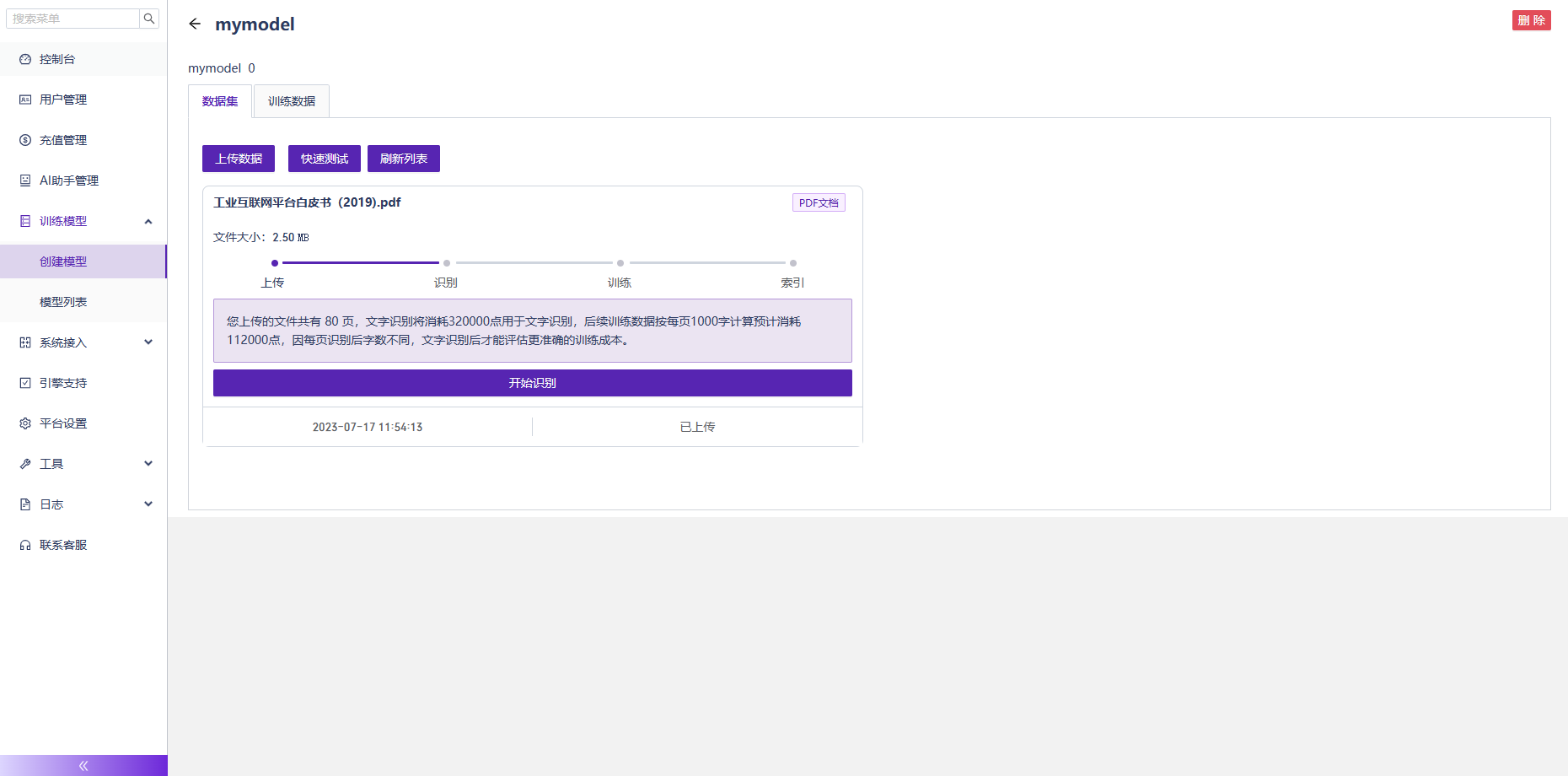
(3)開始識別檔案的資料及訓練模型,根據檔案的大小,識別和訓練模型的時間長短不一樣。如下圖:
(4)訓練結束後,可以檢視模型資料集,如下圖:

(5)建立一個AI助手,並且關聯剛才訓練好的模型,如下圖:
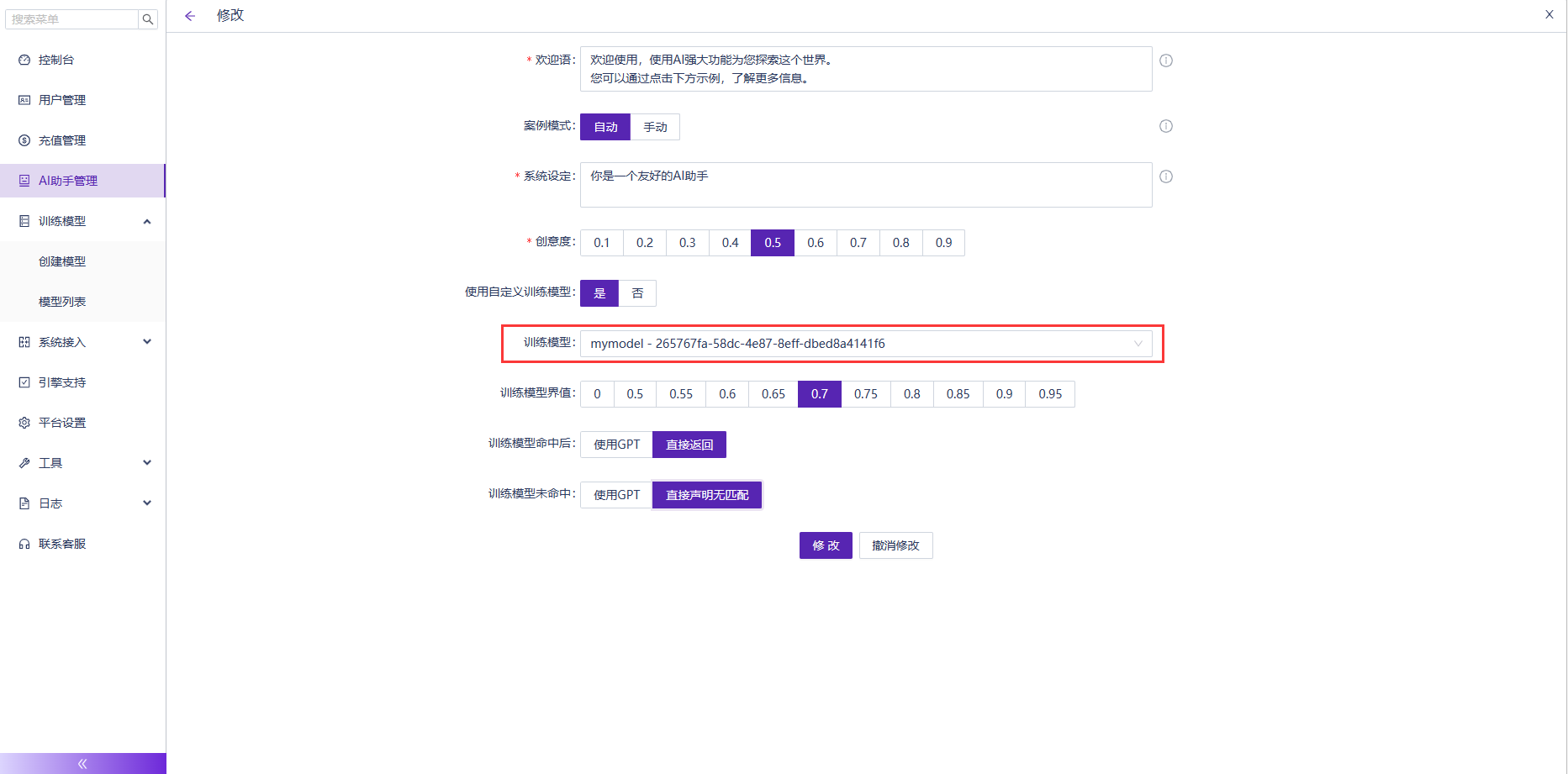
(6)AI助手建立好後,可以釋出上崗了,可以通過前端應用該AI助手,根據提問內容,按《工業互聯平臺白皮書》的內容進行回答。如下圖:

以上是ChatGPT基本應用的整體過程,隨著工藝資料、工況資料、裝置資料、生產資料、經營資料越來越多,ChatGPT回答越全面、越準確,例如企業領導問當前的生產和經營情況、員工問當前工況問題及解決方案等。
物聯網&巨量資料技術 QQ群:54256083
物聯網&巨量資料專案 QQ群:727664080
QQ:504547114
微信:wxzz0151
部落格:https://www.cnblogs.com/lsjwq
微信公眾號:iNeuOS
