【Python】從同步到非同步多核:測試樁效能優化,加速應用的開發和驗證
測試工作中常用到的測試樁mock能力
在我們的測試工作過程中,可能會遇到前端服務開發完成,依賴服務還在開發中;或者我們需要壓測某個服務,而這個服務的依賴元件(如測試環境MQ) 無法支撐並行存取的場景。這個時候我們可能就需要一個服務,來替代測試環境的這些依賴元件或服務,而這就是本文的主角--測試樁。
測試樁可以理解為一個代理,它可以用於模擬應用程式中的外部依賴項,如資料庫、網路服務或其他API,它可以幫助我們在開發和測試過程中隔離應用程式的不同部分,從而使測試更加可靠和可重複。
應用場景
測試樁使用的一般有以下幾種場景:
| 場景 | 使用測試樁的原因與目的 |
|---|---|
| 單元測試 | 隔離被測程式碼與其他元件或外部依賴的互動,便於在不考慮其他部分的情況下對被測程式碼進行測試。 |
| 整合測試 | 當某些元件未實現或不可用時,使用測試樁模擬這些元件,以便繼續進行整合測試。 |
| 效能測試 | 快速生成高負載和大量並行請求,評估系統在高負載條件下的效能表現。 |
| 故障注入和恢復測試 | 模擬故障(如網路故障、服務宕機等),驗證系統在遇到故障時的行為和恢復能力。 |
| API測試 | 使用測試樁模擬API的響應,以便在API實現完成之前就可以進行使用者端開發和測試。 |
| 第三方服務測試 | 在開發和測試階段避免與真實的第三方服務進行互動,降低額外成本和不穩定的測試結果。測試樁用於模擬這些第三方服務,使得在不影響真實服務的情況下進行測試。 |
本文將選取常用的幾個場景循序漸進地介紹測試樁的開發和優化。
簡單測試樁
如果在測試環境中不方便安裝其他的庫,我們可以使用Python標準庫中的一個模組http.server模組建立一個簡單的HTTP請求測試樁。
# simple_stub.py
# 測試樁接收GET請求並返回JSON資料。
import json
from http.server import BaseHTTPRequestHandler, HTTPServer
class SimpleHTTPRequestHandler(BaseHTTPRequestHandler):
def do_GET(self):
content = json.dumps({"message": "Hello, this is a test stub!"}).encode("utf-8")
self.send_response(200)
self.send_header("Content-Type", "application/json")
self.send_header("Content-Length", f"{len(content)}")
self.end_headers()
self.wfile.write(content)
if __name__ == "__main__":
server_address = ("", 8000)
httpd = HTTPServer(server_address, SimpleHTTPRequestHandler)
print("Test stub is running on port 8000")
httpd.serve_forever()
執行上面的程式碼,將看到測試樁正在監聽8000埠。您可以使用瀏覽器或curl命令存取 http://localhost:8000,將會收到 {'message': 'Hello, this is a test stub!'}的響應。
http.server擴充套件:一行命令實現一個靜態檔案伺服器
http.server模組可以作為一個簡單的靜態檔案伺服器,用於在本地開發和測試靜態網站。要啟動靜態檔案伺服器,請在命令列中執行以下命令:
python3 -m http.server [port]
其中[port]是可選的埠號,不傳遞時預設為8000。伺服器將在當前目錄中提供靜態檔案。
如在紀錄檔資料夾中執行python -m http.server,就能在web瀏覽器中存取這個資料夾中的檔案和子資料夾的內容:
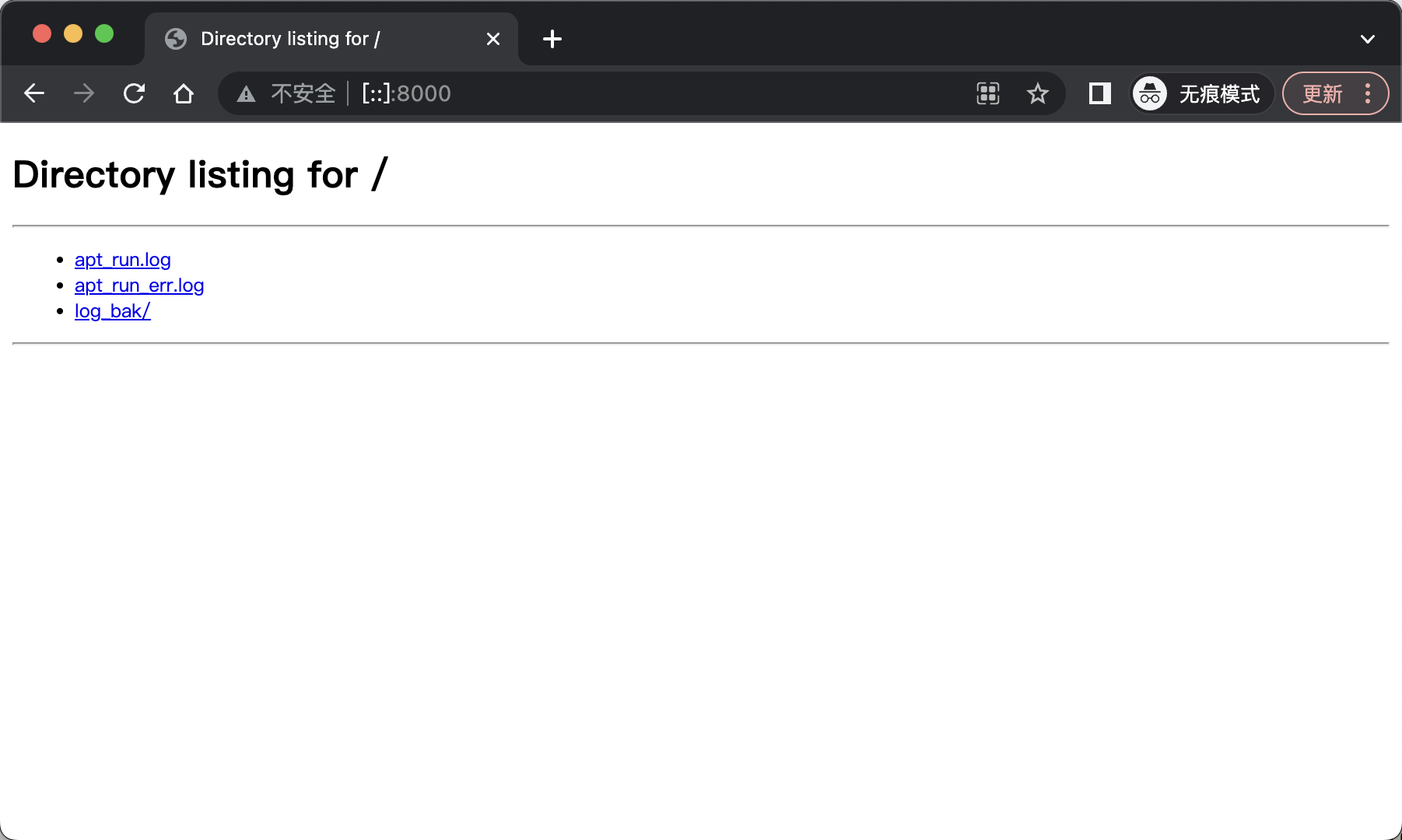
注意:
http.server主要用於開發和測試,效能和安全方面不具備在生產環境部署的條件
效能優化:使用非同步響應
我們在前面的實現了一個簡單的測試樁,但在實際應用中,我們可能需要更高的效能和更復雜的功能。
非同步響應
在只有同樣的資源的情況下,像這樣的有網路I/O的服務,使用非同步的方式無疑能更有效地利用系統資源。
說到非同步的http框架,目前最火熱的當然是FastAPI,使用FastAPI實現上面的功能只需兩步。
首先,安裝FastAPI和Uvicorn:
pip install fastapi uvicorn
接下來,建立一個名為fastapi_stub.py的檔案,其中包含以下內容:
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
async def get_request():
return {"message": "Hello, this is an optimized test stub!"}
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
執行程式碼,這個測試樁也是監聽在8000埠。我們可以像之前那樣使用瀏覽器或其他HTTP使用者端向測試樁發起請求。
點選檢視非同步程式設計優勢 介紹
| 非同步程式設計優勢 | 說明 |
|---|---|
| 非阻塞I/O | 非同步程式設計允許程式在等待I/O操作完成時執行其他任務,從而更有效地利用系統資源。 |
| 並行執行 | 非同步程式設計允許多個任務並行執行,而無需等待每個任務按順序完成,從而提高整體效能。 |
| 更少的上下文切換 | 非同步程式設計可以在單個執行緒或程序中執行多個任務,因此上下文切換的次數通常較少,降低了系統開銷。 |
| 更好的可伸縮性 | 非同步程式設計通常具有更好的可伸縮性,因為它可以在有限的資源下處理更多的任務,尤其適用於處理大量使用者端請求的場景,如Web伺服器、資料庫伺服器等。 |
需要注意的是,雖然非同步程式設計在許多場景下可以提供更好的效能,但它並不總是比同步程式設計快。在某些情況下,如CPU密集型任務,非同步程式設計可能無法帶來明顯的效能提升。此外,非同步程式設計通常需要更復雜的程式設計模型和錯誤處理機制,因此在選擇非同步程式設計時需要權衡其優缺點。
效能優化:利用多核
雖然我們前面使用到了非同步的方式來提升測試樁的效能,但是程式碼還是隻是跑在一個CPU核心上,如果我們要進行效能壓測,可能無法滿足我們的效能需求。這個時候我們可以使用 gunicorn庫 來利用上伺服器的多核優勢。
gunicorn
Gunicorn的主要特點和優勢:
| 特點與優勢 | 說明 |
|---|---|
| 簡單易用 | Gunicorn易於安裝和設定,可以與許多Python Web框架(如Flask、Django、FastAPI等)無縫整合。 |
| 多程序 | Gunicorn使用預先分叉的工作模式,建立多個子程序處理並行請求。這有助於提高應用程式的效能和響應能力。 |
| 相容性 | Gunicorn遵循WSGI規範,這意味著它可以與遵循WSGI規範的任何Python Web應用程式一起使用。 |
| 可設定性 | Gunicorn提供了許多設定選項,如工作程序數量、工作程序型別(同步、非同步)、超時設定等。這使得Gunicorn可以根據具體需求進行靈活設定。 |
| 部署友好 | Gunicorn在生產環境中非常受歡迎,因為它簡化了部署流程。Gunicorn可以與其他工具(如Nginx、Supervisor等)一起使用,以便更好地管理和擴充套件Web應用程式。 |
安裝 gunicorn
pip install gunicorn
使用 gunicorn 啟動服務
啟動服務:
gunicorn -w 4 fastapi_stub:app
可以看到,上面的命令啟動了4個worker 程序,大家也可以使用ps -ef命令查詢一下程序狀態。
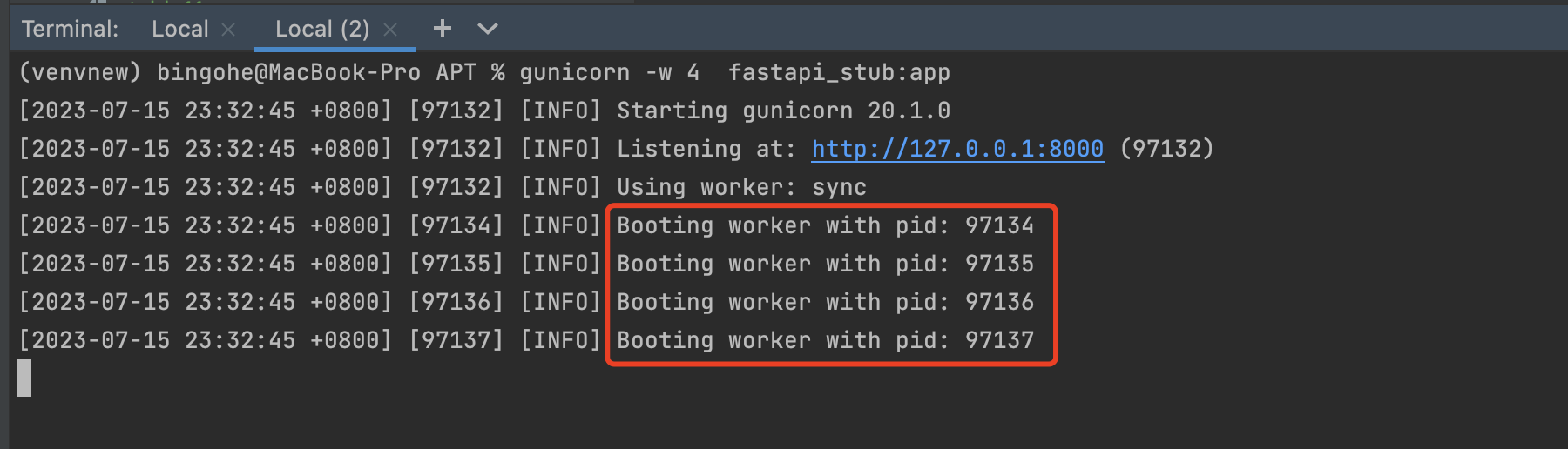
gunicorn的一些常用引數:
| 引數 | 說明 |
|---|---|
| -w, --workers | 設定工作程序的數量。根據系統的CPU核心數和應用程式的負載特徵來調整。預設值為1。 |
| -k, --worker-class | 設定工作程序的型別。可以是sync(預設)、gevent、eventlet等。如果使用非同步工作程序,需要安裝相應的庫。例如,對於FastAPI應用程式,可以使用-k uvicorn.workers.UvicornWorker。 |
| -b, --bind | 設定伺服器繫結的地址和埠。格式為address:port。例如:-b 0.0.0.0:8000。預設值為127.0.0.1:8000。 |
| --timeout | 設定工作程序的超時時間(以秒為單位)。如果工作程序在指定的時間內沒有完成任務,它將被重啟。預設值為30秒。 |
| --log-level | 設定紀錄檔級別。可以是debug、info、warning、error或critical。預設值為info。 |
| --access-logfile | 設定存取紀錄檔檔案的路徑。預設情況下,存取紀錄檔將輸出到標準錯誤流。要禁用存取紀錄檔,請使用-。例如:--access-logfile -。 |
| --error-logfile | 設定錯誤紀錄檔檔案的路徑。預設情況下,錯誤紀錄檔將輸出到標準錯誤流。要禁用錯誤紀錄檔,請使用-。例如:--error-logfile -。 |
| --reload | 在開發環境中使用此選項,當應用程式程式碼發生更改時,Gunicorn將自動重新載入。不建議在生產環境中使用。 |
| --daemon | 使用此選項以守護行程模式執行Gunicorn。在這種模式下,Gunicorn將在後臺執行,並在啟動時自動分離。 |
Gunicorn提供了許多其他設定選項,可以根據具體需求進行調整。要檢視完整的選項列表,可以檢視Gunicorn的官方檔案:https://docs.gunicorn.org/en/stable/settings.html。
效能優化:使用快取(functools.lru_cache)。
當處理重複的計算或資料檢索任務時。使用記憶體快取(如Python的functools.lru_cache)或外部快取(如Redis)來快取經常使用的資料也能極大的提升測試樁的效率。
假設我們的測試樁需要使用到計算計算斐波那契數列這樣耗時的功能,那麼快取結果,在下次遇到同樣的請求時直接返回而不是先計算再返回,將極大的提高資源的使用率、減少響應的等待時間。
如果僅僅是直接返回資料的,沒有進行復雜的計算的測試樁,使用
lru_cache並沒有實際意義。
以下是一個更合適的使用lru_cache的範例,其中我們將對斐波那契數列進行計算並快取結果:
from fastapi import FastAPI
from functools import lru_cache
app = FastAPI()
@lru_cache(maxsize=100)
def fibonacci(n: int):
if n <= 1:
return n
else:
return fibonacci(n - 1) + fibonacci(n - 2)
@app.get("/fibonacci/{n}")
async def get_fibonacci(n: int):
result = fibonacci(n)
return {"result": result}
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
在這個範例中,我們使用FastAPI建立了一個簡單的HTTP請求測試樁。我們定義了一個名為fibonacci的函數,該函數計算斐波那契數列。為了提高效能,我們使用functools.lru_cache對該函數進行了快取。
在路由/fibonacci/{n}中,我們呼叫fibonacci函數並返回結果。可以命令存取 http://localhost:8000/fibonacci/{n}進行偵錯。
需要注意的是 maxsize引數是functools.lru_cache裝飾器的一個設定選項,它表示快取的最大容量。lru_cache使用字典來儲存快取項,當一個新的結果需要被快取時,它會檢查當前快取的大小。如果快取已滿(即達到maxsize),則會根據LRU策略移除最近最少使用的快取項。如果maxsize設定為None,則快取可以無限制地增長,這可能導致記憶體問題。
單元測試中的mock
Python unittest.mock
在Python中,unittest模組提供了一個名為unittest.mock的子模組,用於建立mock物件。unittest.mock包含一個名為Mock的類以及一個名為patch的上下文管理器/裝飾器,可以用於替換被測試程式碼中的依賴項。
import requests
from unittest import TestCase
from unittest.mock import patch
# 定義一個函數 get_user_name,它使用 requests.get 發起 HTTP 請求以獲取使用者名稱稱
def get_user_name(user_id):
response = requests.get(f"https://api.example.com/users/{user_id}")
return response.json()["name"]
# 建立一個名為 TestGetUserName 的測試類,它繼承自 unittest.TestCase
class TestGetUserName(TestCase):
# 使用 unittest.mock.patch 裝飾器替換 requests.get 函數
@patch("requests.get")
# 定義一個名為 test_get_user_name 的測試方法,它接受一個名為 mock_get 的引數
def test_get_user_name(self, mock_get):
# 設定 mock_get 的返回值,使其在呼叫 json 方法時返回一個包含 "name": "Alice" 的字典
mock_get.return_value.json.return_value = {"name": "Alice"}
# 呼叫 get_user_name 函數,並傳入 user_id 引數
user_name = get_user_name(1)
# 使用 unittest.TestCase 的 assertEqual 方法檢查 get_user_name 的返回值是否等於 "Alice"
self.assertEqual(user_name, "Alice")
# 使用 unittest.mock.Mock 的 assert_called_with 方法檢查 mock_get 是否被正確呼叫
mock_get.assert_called_with("https://api.example.com/users/1")
總結
在開發測試樁時,我們需要根據實際需求和後端服務的特點來設計測試樁的行為,為的是使其更接近實際後端服務的行為,確保測試結果具有更高的可靠性和準確性。
可能還有其他的優化方案,歡迎大家提出。希望本文能對大家的工作帶來幫助。
如果覺得還不錯,就在右下角點個贊吧,感謝!
合抱之木,生於毫末;九層之臺,起於累土;千里之行,始於足下。