加速LakeHouse ACID Upsert的新寫時複製方案
概述
隨著儲存表格式 Apache Hudi、Apache Iceberg 和 Delta Lake 的發展,越來越多的公司正在這些格式的基礎上構建其 Lakehouse,以用於許多用例,例如增量攝取。 但當資料量增加時,更新插入的速度有時仍然是一個問題。
在儲存表中,使用Apache Parquet作為主要檔案格式。 在本文中我們將討論如何構建行級二級索引以及在 Apache Parquet 中引入的創新,以加快 Parquet 檔案內資料的更新插入速度。 我們還將展示基準測試結果,顯示速度比 Delta Lake 和 Hudi 中的傳統的寫入時複製快得多。
動機
高效的表 ACID 更新插入對於當今的 Lakehouse 至關重要。 資料保留和變更資料捕獲 (CDC) 等重要用例嚴重依賴它。 雖然 Apache Hudi、Apache Iceberg 和 Delta Lake 在這些用例中被廣泛採用,但當資料量擴大時,更新插入速度會變慢,特別是對於寫入時複製模式。 有時緩慢的更新插入會成為耗時和資源消耗的任務,甚至會阻礙按時完成任務。
為了提高 upsert 的速度,我們在具有行級索引的 Apache Parquet 檔案中引入了部分寫時複製,可以跳過不必要的資料頁(Apache Parquet 中的最小儲存單元),從而實現高效讀寫。 這裡的術語「部分」意味著僅對檔案內的相關資料頁執行更新插入,但跳過不相關的資料頁。 一般情況下只需要更新一小部分檔案,大部分資料頁可以跳過。 與 Delta Lake 中的寫入時複製相比,我們觀察到速度有所提高。
LakeHouse 中的寫時複製
在本文中我們使用 Apache Hudi 作為範例,但類似的想法也適用於 Delta Lake 和 Apache Iceberg。 Apache Hudi 支援兩種型別的 upsert:寫時複製和讀時合併。 通過寫時複製,在更新範圍內具有記錄的所有檔案都將被重寫為新檔案,然後建立新的快照後設資料以包含新檔案。 相比之下讀時合併只是新增用於更新的增量檔案,然後將其留給讀取器進行合併。 一些用例(例如「被遺忘權」)通常使用寫時複製模式,因為它可以減輕讀取壓力。
下圖顯示了更新分割區表的一個欄位的範例。 從邏輯檢視來看,使用者 ID1 的電子郵件欄位被替換為新電子郵件,並且其他欄位沒有更新。 從物理上講,表資料作為單獨的檔案儲存在磁碟上,並且在大多數情況下,這些檔案根據時間或其他分割區機制分組為分割區。 Apache Hudi 使用索引系統來定位每個分割區中受影響的檔案,然後完全讀取它們,更新記憶體中的電子郵件欄位,最後寫入磁碟並形成新檔案。 圖中的紅色表示被重寫的新檔案。
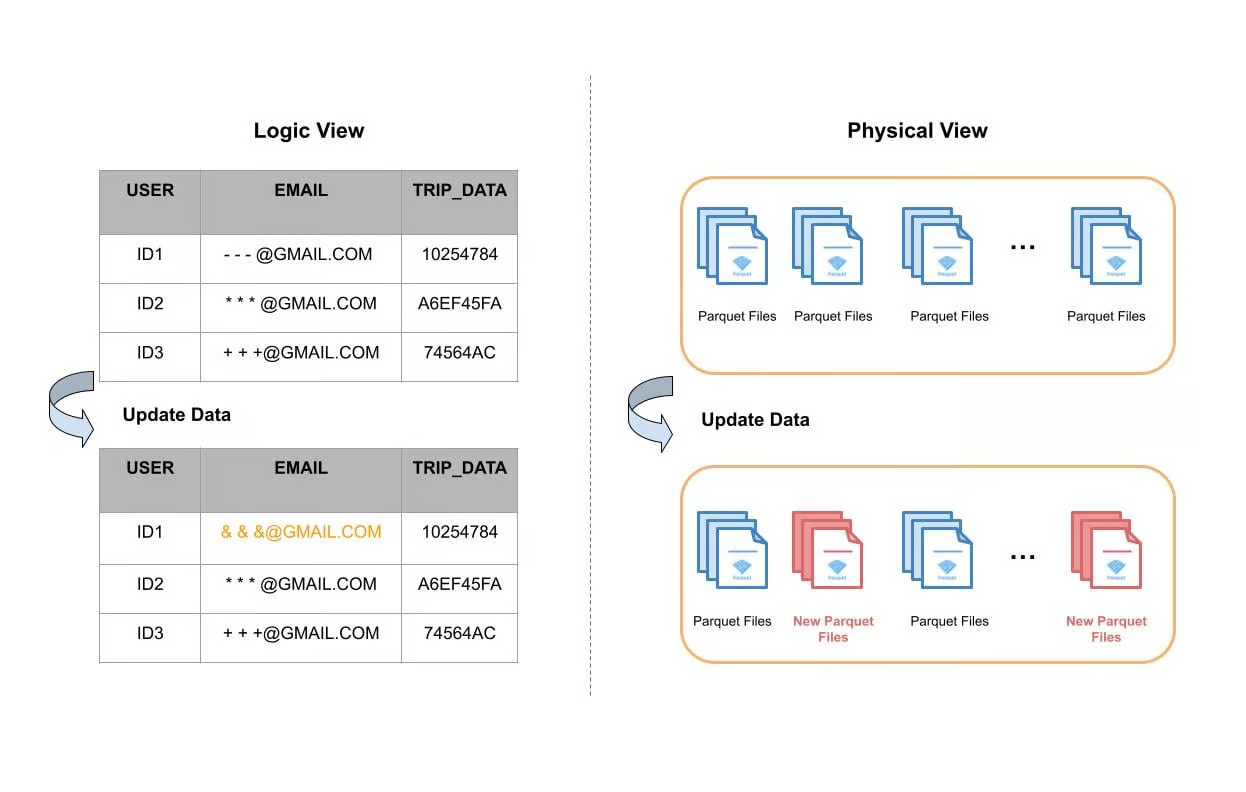
圖 1:表更新插入的邏輯和物理檔案檢視
正如部落格「使用 Apache Hudi 在 Uber 構建大規模事務資料湖」中提到的,我們的資料湖中一些表收到的更新分佈在 90% 的檔案中,導致任何給定的大型資料重寫約 100 TB。因此寫時複製的速度對於許多用例來說至關重要,緩慢的寫時複製不僅會導致作業執行時間更長,還會消耗更多的計算資源。 在某些用例中我們看到大量的 vCore 被使用,相當於花費了數百萬美元。
引入行級二級索引
在討論如何改進 Apache Parquet 中的寫時複製之前,我們想先介紹一下 Parquet 行級二級索引,我們用它來定位 Parquet 中的資料頁,以幫助加速寫時複製。
Parquet行級二級索引是在第一次寫入Parquet檔案時或通過離線讀取Parquet檔案時構建的。 它將記錄對映到 [file, row-id] 而不僅僅是 [file]。 例如,RECORD_ID可以用作索引鍵,FILE和Row_ID用於指向檔案以及每個檔案的偏移量。
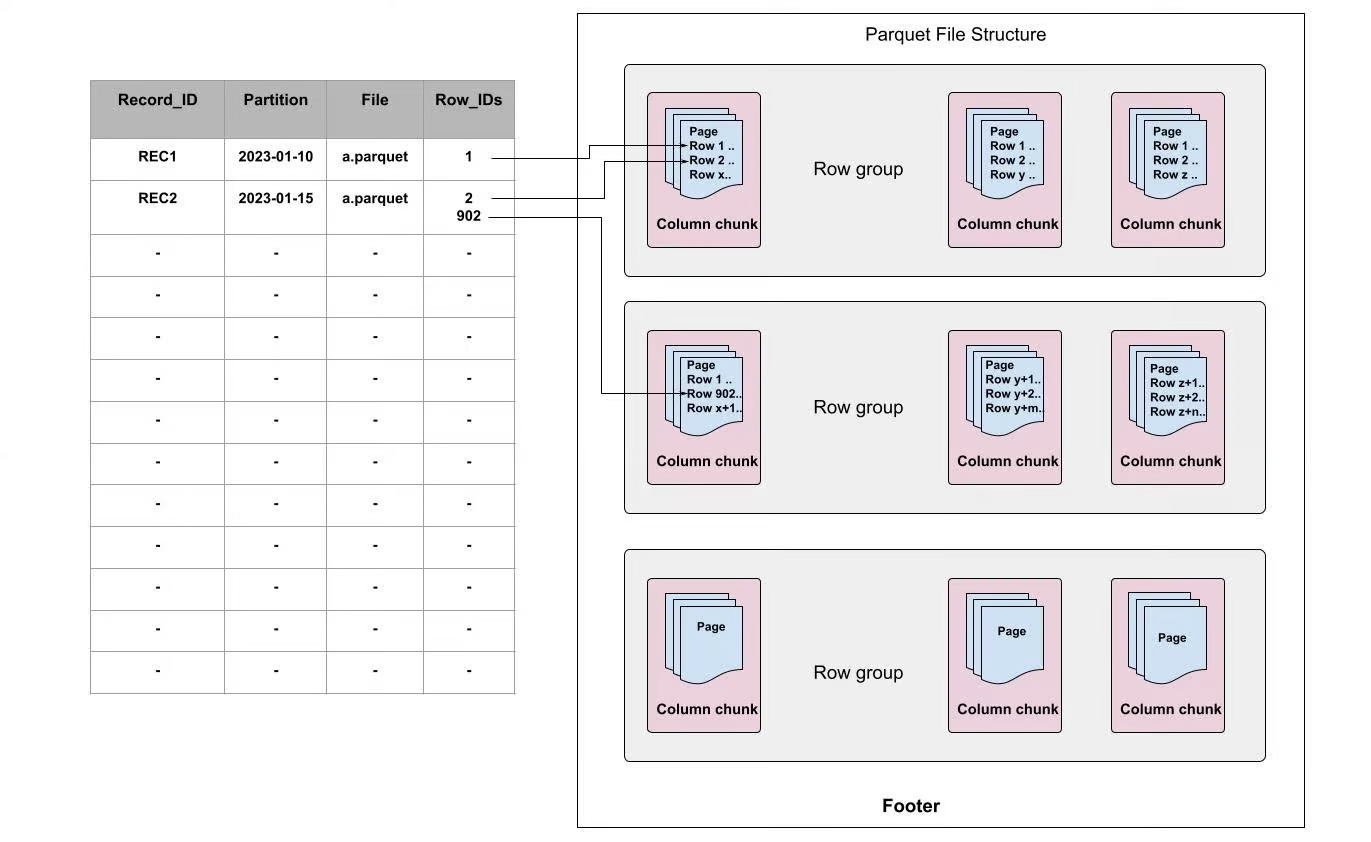
圖 2:Apache Parquet 的行級索引
在 Apache Parquet 內部,資料被劃分為多個行組。 每個行組由一個或多個列塊組成,這些列塊對應於資料集中的一列。 然後每個列塊的資料以頁的形式寫入。 塊由頁組成,頁是存取單個記錄必須完全讀取的最小單位。 在頁面內部,除了編碼的詞典頁面之外,每個欄位都附加有值、重複級別和定義級別。
如上圖所示,每個索引都指向該記錄所在頁面內的行。 通過行級索引,當收到更新時,我們不僅可以快速定位到哪個檔案,還可以定位到哪些資料頁需要更新。 這將幫助我們跳過所有其他不需要更新的頁面,並節省大量計算資源以加快寫時複製過程。
Apache Parquet 中的寫入時複製
我們引入了一種在 Apache Parquet 中執行寫時複製的新方法,以實現 Lakehouse 的快速更新插入。 我們僅對 Parquet 檔案內的相關資料頁執行寫時複製更新,但通過直接複製為位元組緩衝區而不進行任何更改來跳過不相關的資料頁。 這減少了更新插入操作期間需要更新的資料量並提高了效能。
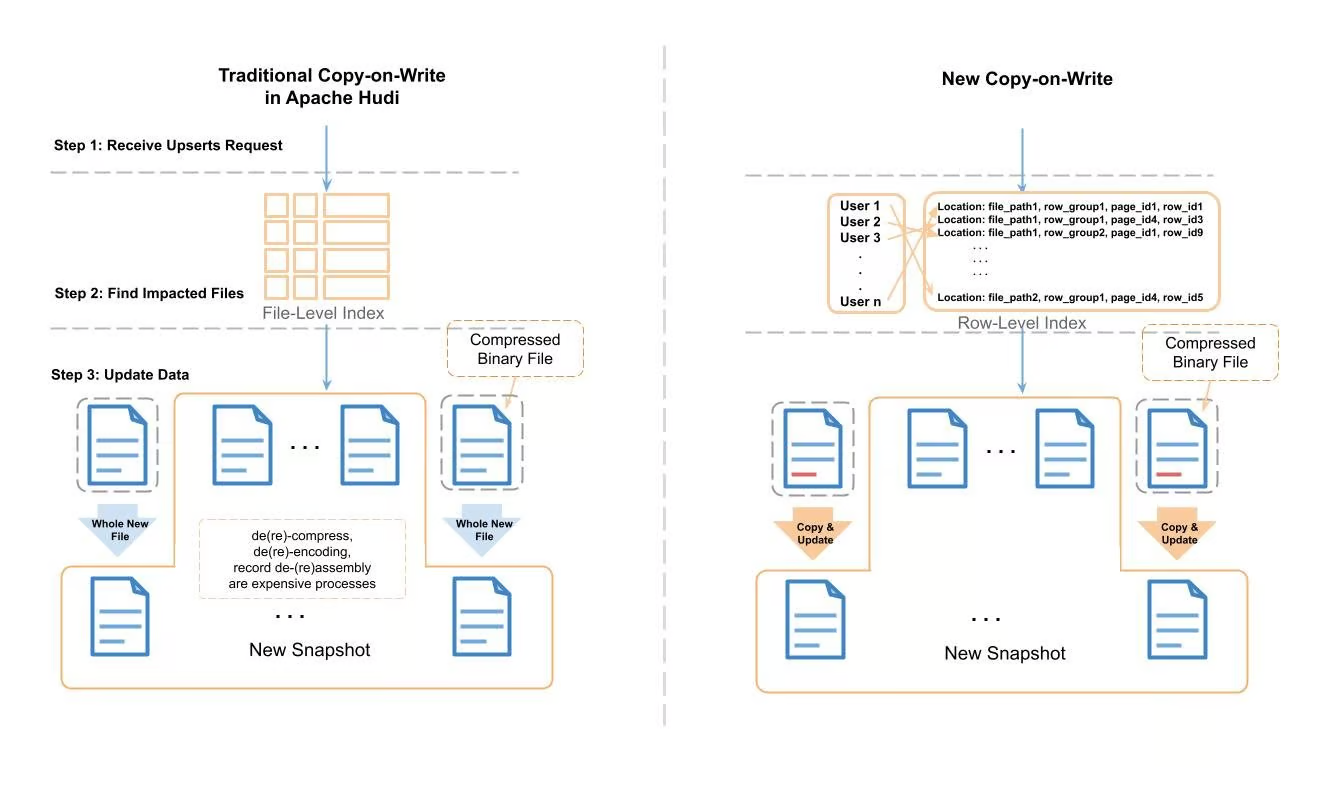
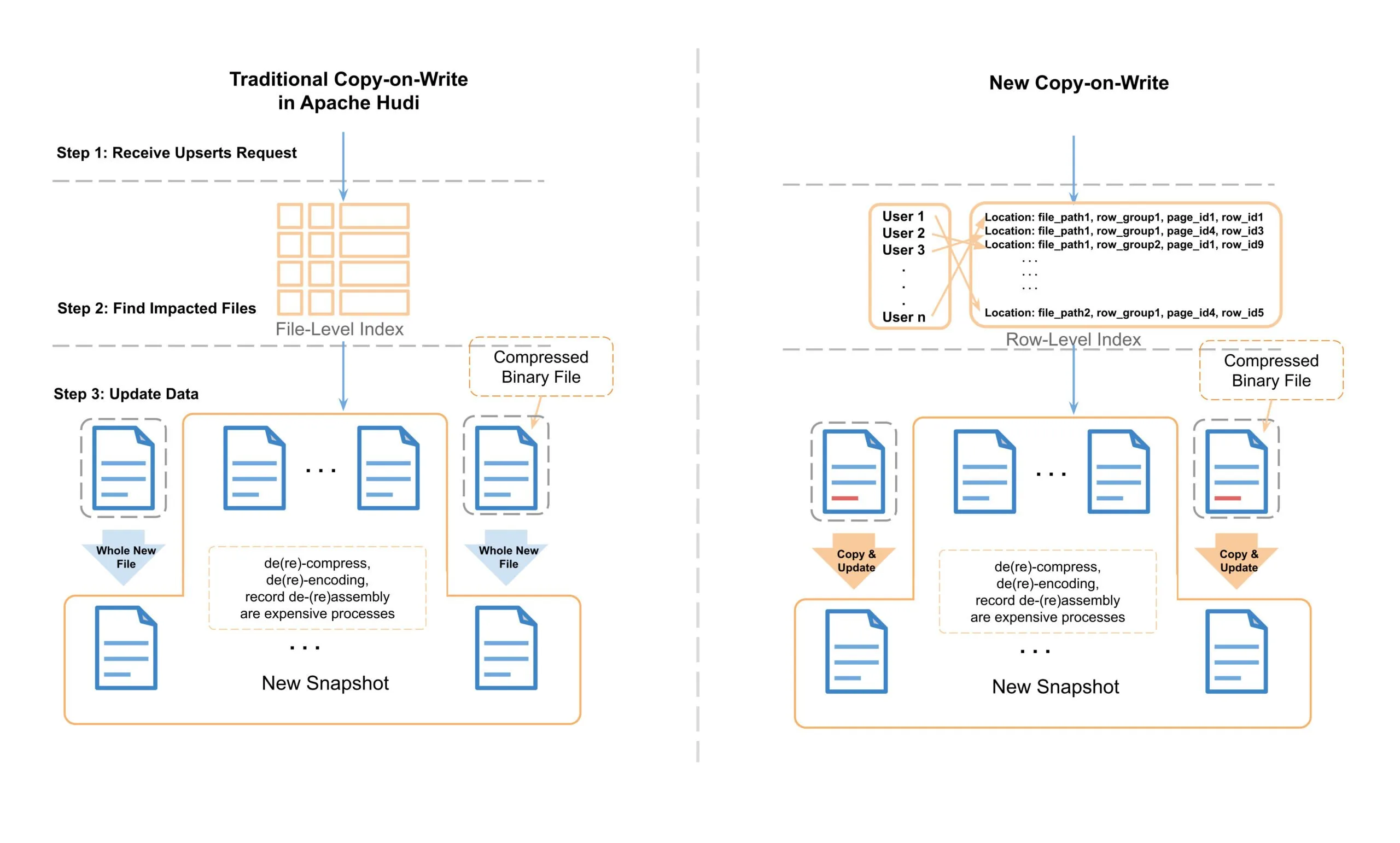
圖 3:Apache Hudi 中傳統寫時複製與新寫時複製的比較
我們演示了新的寫時複製過程,並將其與傳統過程進行比較。 在傳統的Apache Hudi upsert中,Hudi利用記錄索引來定位需要更改的檔案,然後將檔案記錄一條條讀取到記憶體中,然後搜尋要更改的記錄。 應用更改後,它將資料作為一個全新檔案寫入磁碟。 在這個讀取-更改-寫入過程中,存在一些昂貴的任務(例如,解(重新)壓縮、解(重新)編碼、具有重複級別、定義級別的記錄解(重新)組裝等),這些任務會消耗 大量的 CPU 週期和記憶體。
為了改善這個耗時和資源消耗的過程,我們使用行級索引和 Parquet 後設資料來定位需要更新的頁。 對於那些不在更新範圍內的頁,我們只是將資料作為位元組緩衝區逐字複製到新檔案,而無需解(重新)壓縮、解(重新)編碼或記錄解(重新)組裝。 我們稱之為「複製和更新」過程。 下圖對其進行了更詳細的描述。
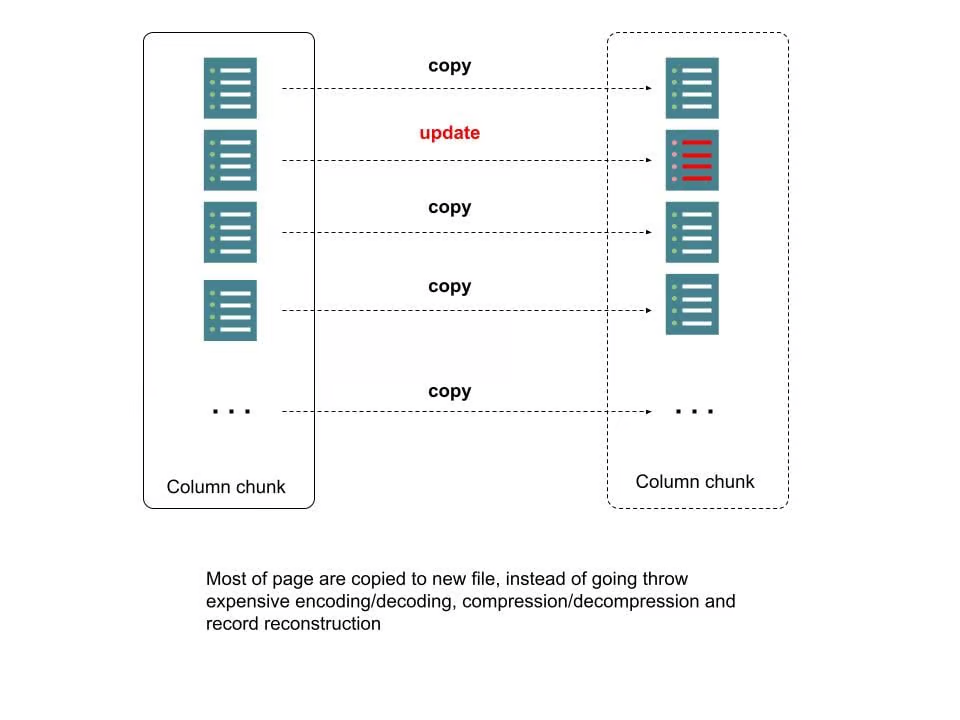
圖 4:Parquet 檔案中新的寫時複製
基準測試結果
我們進行了基準測試,以使用TPC-DS資料比較我們的快速寫時複製方法與傳統方法(例如 Delta Lake)的效能。
我們使用具有相同 vCore 數量和 Spark 作業記憶體設定的 TPC-DS 銷售資料,以開箱即用的設定進行測試。 我們選擇了 5% 到 50% 之間的一定比例的資料進行更新,然後比較 Delta Lake 和新的寫時複製所消耗的時間。 我們認為 50% 作為最大值足以滿足實際用例。
測試結果表明新方法可以實現明顯更快的速度。 當更新資料的百分比時,獲得的效能是一致的。
免責宣告:DeltaLake 上的基準測試使用預設的開箱即用設定。
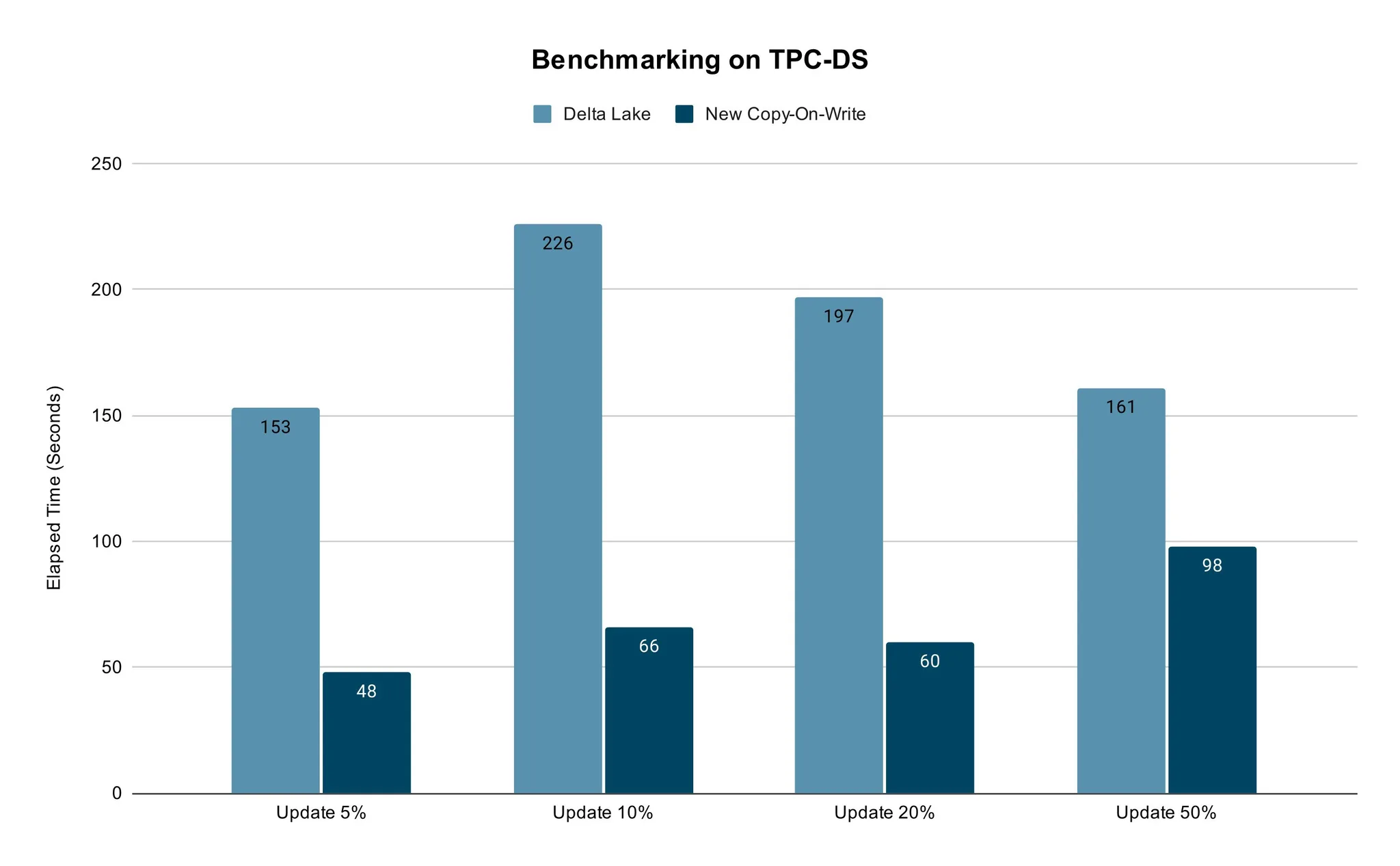
圖 5:新寫時複製與傳統 Delta Lake 的基準測試結果
結論
總之高效的 ACID 更新插入對於當今的LakeHouse至關重要。 雖然 Apache Hudi、Delta Lake 和 Apache Iceberg 被廣泛採用,但更新插入的速度緩慢仍然是一個挑戰,特別是當資料量擴大時。 為了解決這一挑戰,我們在具有行級索引的 Apache Parquet 檔案中引入了部分寫時複製,這可以有效地跳過不必要的資料頁讀寫。 我們已經證明這種方法可以顯著提高更新插入的速度。 我們的方法使公司能夠高效地執行資料刪除和 CDC,以及依賴 LakeHouse 中高效表更新插入的其他重要用例。
未來工作
我們計劃將行級索引和快速寫時複製功能整合到 Apache Hudi,Uber 的 LakeHouse 就是在 Apache Hudi 上構建。 我們將看到這種整合將如何提高 Apache Hudi 的效能並幫助我們的客戶解決增量攝取等問題。敬請關注!
PS:如果您覺得閱讀本文對您有幫助,請點一下「推薦」按鈕,您的「推薦」,將會是我不竭的動力!
作者:leesf 掌控之中,才會成功;掌控之外,註定失敗。
出處:http://www.cnblogs.com/leesf456/
本文版權歸作者和部落格園共有,歡迎轉載,但未經作者同意必須保留此段宣告,且在文章頁面明顯位置給出原文連線,否則保留追究法律責任的權利。
如果覺得本文對您有幫助,您可以請我喝杯咖啡!

