Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics
在Delta Lake官網上提到的一篇新一代湖倉架構的論文.

這篇論文由Databricks團隊2021年發表於CIDR會議. 這個會議是對sigmod和vldb會議的補充.
可以看到這篇論文和前一篇Delta Lake: High-Performance ACID Table Storage over Cloud Object Stores發表時間僅隔了一年. 論述的內容也是對Delta Lake這套架構的補充(場景拓展).
Warehouse, lake, lakehouse
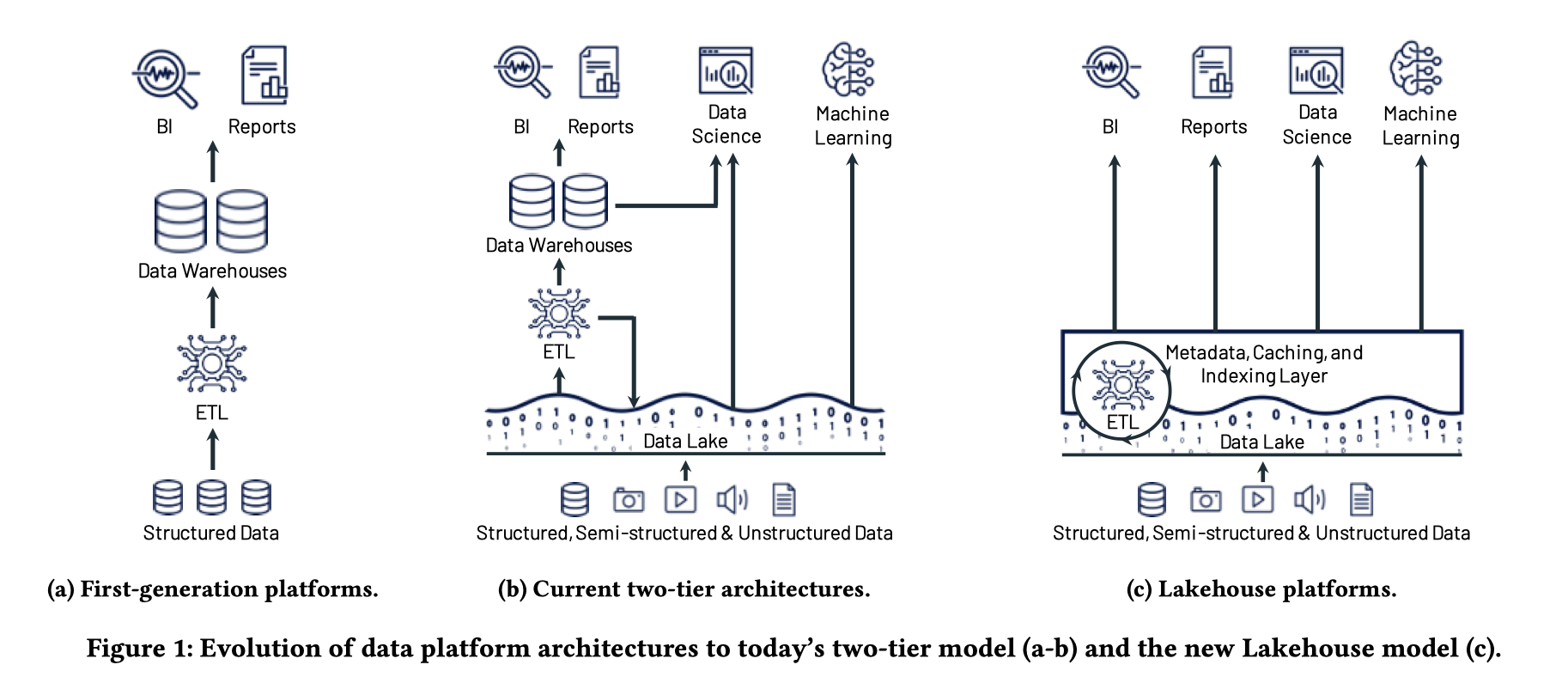
第一代數倉只將資料庫操作的結構化紀錄檔通過ETL清洗儲存到專門的資料倉儲中, 典型的如基於Hive的數倉. 這一代數倉的主要服務的目標場景是BI分析. 他的架構也是一種計算儲存緊耦合的架構, 例如hive上計算節點就和儲存的資料節點部署在一起, 通常還會有data colocate的優化.
第二代演化成了2層的結構, Data Lake 可以儲存半結構化, 和非結構化的資料, 例如視訊, 音訊

這種架構下可以支援非結構化資料, 也支援直接的資料存取, 可以更好的對接非SQL的機器學習系統. 但目前自己在業界沒有明顯的感受到這種兩層的結構, 可能是因為我對AI場景沒怎麼接觸
論文中描述這已經是絕大部分公司的架構了

那麼有沒有將傳統基於標準格式的資料湖轉化成既有數倉管理能力, 高效能的分析能力, 又有快速的開放的資料存取的架構呢?

答案是 Lakehouse = Data Lake + Data warehouse.
資料直接儲存於Object store之上, 而上層的BI系統, 機器學習, 資料科學計算都直接從Lakehouse中取數分析, 這樣就實現了儲存層的統一. 通過Data Lake 和 Data warehouse的結合實現了兩者能力的結合.
而Lakehouse 就可以基於前文所介紹的Delta lake來構建, 可以看出Lakehouse是對傳統數倉的一次升級. 但是純粹這樣的架構效能也許沒有原先數倉中計算儲存緊耦合的效能好, 畢竟多了額外的跨網路拉取資料的開銷



最大的問題就是效能問題
Lakehouse架構
- 基於可以直接存取的, 標準的檔案格式, 典型的如Parquet. 所以Lakehouse提供是一套基於檔案的介面, 可以直接存取儲存的資料, 並且提供了事務性的保障
- 基於雲上的廉價物件儲存
- 通過後設資料層實現事務機制
- 對機器學習和資料科學的支援是第一優先順序
- 提供效能保障
如何保障效能呢?
- caching 對於熱資料通過本地ssd快取加速查詢
- auxiliary data structures such as indexes and statistics, and data layout optimizations. 通過索引, 資料重排和資料排布的優化. 對於熱資料, 通過快取可以實現和傳統數倉中資料co-locate的優化, 而對於冷資料, 影響最大的是資料讀取的多少, 因此通過一系列輔助資料, 可以大大減少需要掃描的資料量
- Data layout: Zorder
- 查詢引擎自身優化, 向量化執行引擎
有待探索的優化
- 專為Lakehouse所設計的format, 雖然在一直強調standard format: Parquet/Orc, 但是看出來還是有設計一套新的format的意圖, 不知道Databricks在Parquet/Orc有碰到什麼痛點