解密Prompt系列11. 小模型也能COT-先天不足後天來補
前兩章我們分別介紹了COT的多種使用方法以及COT的影響因素。這一章更多面嚮應用,既現實場景中考慮成本和推理延時,大家還是希望能用6B的模型就不用100B的大模型。但是在思維鏈基礎和進階玩法中反覆提到不論是few-shot還是zero-shot的思維鏈能力似乎都是100B左右的大模型才有的湧現能力,而在小模型上使用COT甚至會帶來準確率的下降。
至於為啥小模型無法進行COT,論文[5]通過把小模型回答錯誤但大模型可以回答正確的問題進行歸納總結,認為小模型的COT能力受到有限的語意理解和數學計算能力的限制。不過我們在實際嘗試中發現小模型的few-shot理解能力似乎是更大的短板,表現在小模型無法很好理解抽象few-shot中的推理模板和樣本間的共性。
不過以上的觀點都是針對模型的先天能力,那我們是否可以把COT推理作為一種生成風格,或者NLP任務型別,通過微調讓模型獲得COT能力呢ψ(`∇´)ψ
想要讓小模型擁有COT能力,多數方案是通過COT樣本微調來實現的,以下Reference[1]-[4]中的4篇論文的核心差異就在COT樣本構造和微調方式。以下我們把幾篇論文合在一起來說,下圖來自[3]
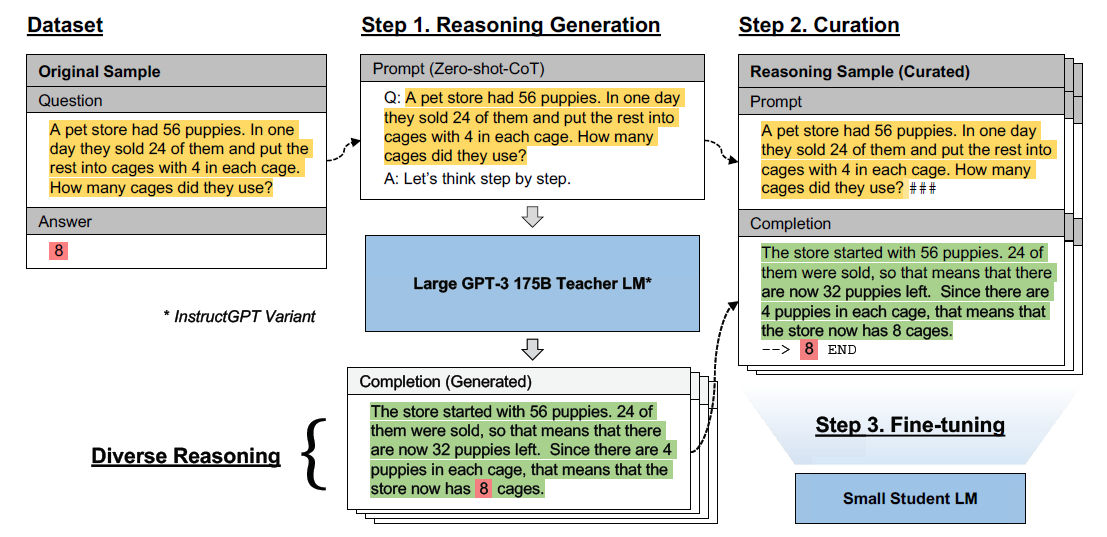
COT樣本
以下Reference中的論文都是使用大模型來生成COT樣本不過在資料集,COT樣本構建和過濾機制上存在差異。
論文[1]使用了GSM8k的資料集,用Code-Davinci-002隨機生成40個的思維鏈推理,選擇答案正確的一條作為訓練樣本。樣本生成這塊寫的相對比較模糊。
論文[2]優化了COT樣本準確率。使用Palm540B和GPT3 175B模型,用8個few-shot樣本來引導模型生成COT,這裡為了提高大模型COT的準確率,作者修改了指令,在few-shot+question之後會直接給出正確答案作為Hint,來引導模型倒推出正確的COT,同樣是只過濾答案正確的樣本
論文[3]優化了思維鏈的多樣性。考慮同一個問題其實有很多種解法,以及不同的解法間往往存在邏輯共性,與其讓模型擬合單一的推理結果,不如讓模型從多個推理路徑中去抽象重要資訊。因此論文提出了diverse reasoning,每個樣本用text-davinci-002生成多個思維鏈,保留所有答案正確且推理邏輯不同的樣本。並且在論文中驗證了一個樣本生成更多思維鏈會帶來顯著的效果提升
論文[4]優化了COT資料集的多樣性,整了個COT Collection資料集包含1.88M的COT樣本。具體的資料篩選和構建邏輯詳見論文。使用了Codex來生成思維鏈,方案融合了[2]和[3]
模型訓練
不同論文選擇了不同的student模型,指令樣本構建和指令微調方式,簡單對比如下
| 論文 | 微調模型 | 微調樣本 | 微調方式 |
|---|---|---|---|
| [1] | FlanT5 250M~11B | Few-shot-COT+Zero-shot-COT+Few-shot-Answer Only | 蒸餾:Top5 Token的KL距離 |
| [2] | T5 60M~11B | Zero-shot-COT | 指令微調SFT |
| [3] | GPT-3 0.3B~6.7B | prompt模板Zero-shot-COT | 指令微調SFT |
| [4] | FlanT5 T0 | Few-Shot-COT + Zero-shot-COT | 兩步指令微調 |
以上不同的指令樣本Looklike如下,差異包括是否有few-shot上文,是否有COT推理

在指令樣本構建上多數是直接輸入問題,輸出COT思維鏈的,但個人其實更偏好few-shot的COT方案。因為在實際應用中,其實需要分析和推理的很多場景都是非標準化的,遠遠不是解個數學題或者QA這類標準化問題可以覆蓋。這種情況下需要客製化場景所需的推理邏輯,這時zero-shot肯定就不行了,需要few-shot來給出不同場景所需的不同推理鏈路。例如問診的流程要先問當前症狀,病程,病史,用藥,再基於使用者不同的回答,選擇是化驗,拍片,還是聽診開藥等等。因此大模型和小模型的能力差異除了小模型自身的推理能力有限,還有小模型的In-Context理解能力有限,而few-shot樣本微調被證明可以提升模型In-context理解能力。
再說下微調的部分,除了常規的指令微調方案之外,[1]採用了蒸餾方案,不熟悉蒸餾的可以先看下Bert推理太慢?模型蒸餾。簡單來說就是讓Student模型擬合Teacher模型的分佈,分佈可以是對齊輸出層也可以進一步對齊模型中間層,損失函數一般是兩個分佈的KL散度或者MSE。這裡作者使用的蒸餾方案是對齊輸出層分佈,考慮OpenAI的介面每次只返回Top5 Token對應的概率,因此只對Student模型每步解碼的Top5 Token計算KL散度作為loss。蒸餾過程還有一些例如tokenizer對齊的細節,詳見論文
[4]採用了兩步微調,第一步在指令微調模型的基礎上,使用範圍更廣的COT Collection樣本集對模型進行COT微調,再在該模型的基礎上,使用單一領域/任務的COT樣本進一步微調,效果會有進一步提升。這一點其實可能說明COT推理本身除了是一種生成風格,也是一種模型能力,所以不同的推理資料集之間存在可遷移性,我們在單任務推理中混入數學COT也發現有效果提升。
Insights
效果其實不用太多說,小模型在經過以上COT訓練後,在對應資料集上都有很顯著的能力提升。考慮不同論文使用的模型checkpoint不同,Benchmark資料集的劃分也不同所以可比性不高,以及現在的很多random split的方案真的說不清楚是否有資訊洩露問題。建議大家在自己的業務使用中去尋找更合適的方案。這裡想更多說下論文中提到的一些insight
- COT能力提升以其他任務能力下降為代價
論文[1]發現在數學COT能力提升的同時,模型在BigBench(BBH)上的打分會出現顯著的下降,並且這個過程是隨微調逐漸發生的。論文指出的可能原因是小模型能承載的能力有限,因此不像大模型可以許廣泛任務上有很好的表現,小模型單一能力的提升,可能會以通用能力損失為代價。雖然這裡我有些存疑,感覺BBH的效果下降也可能是因為COT的生成風格和很多通用任務的生成風格存在差異,如果在COT微調時在中加入額外的指令,把直接生成推理轉化成基於指令推理的條件生成任務,可能會降低對其他任務的影響。
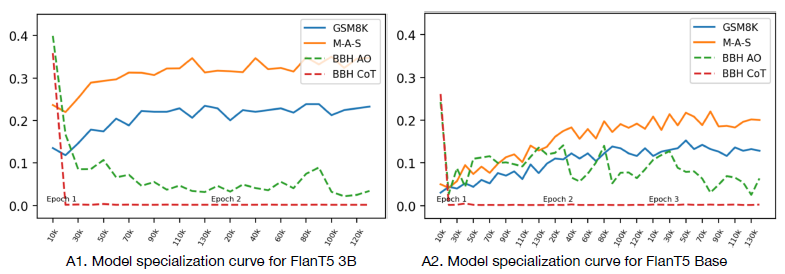
- 小模型COT也存在規模效應
論文幾乎都提到了這一點,簡單說就是越大的模型越好,所以在ROI允許的範圍內選擇最大的小模型哈哈~
- 使用Few-shot-COT微調,會同時提升zero-shot和few-shot能力,反之不成立
以上發現也是論文[1]使用混合樣本(fewshot+zeroshot+無cot)樣本進行微調的原因。其實比較好理解,因為COT推理的生成風格和其他指令任務是存在差異的(哈哈zero-shot-cot在我看來就像是無緣無故,別人問你問題,你本來可以直接給個答案,結果你突然開啟柯南模式開始叭叭的推理)。因此如果用zero-shot-cot微調,會直接影響模型的解碼分佈,而使用few-shot-cot微調,充分的上文讓模型更多擬合COT條件解碼概率,只會有部分能力遷移到無條件解碼概率,且對其他指令任務的影響也會更小。

- 多步推理任務上COT微調可能比常規指令微調效果更佳,模型規模效應更明顯
論文[3]對比了在同一個任務上使用COT樣本微調和使用只有答案的常規樣本微調,整體上在需要多步推理的任務上,COT微調有更明顯的模型規模效應,隨模型變大COT微調的效果會顯著超過常規微調。
- COT資料集的質量和數量都和重要
論文[2]論證了COT資料集存在規模效應,樣本越多,微調效果越好,這裡的規模效應可能更多來自思維鏈的多樣性覆蓋。而論文[3]論證了相同數量的COT樣本,人工篩選的正確推理樣本對比從模型預測答案正確的COT中取樣相同量級的樣本,效果會有顯著提升。畢竟1個錯誤的樣本可能需要10個正確的樣本來糾偏,因此在保證資料集多樣性和規模的同時,更有效的樣本過濾邏輯也很重要。
reference
[1] Specializing Smaller Language Models towards Multi-Step Reasoning
[2] Teaching Small Language Models to Reason
[3] Large Language Models are Reasoning Teachers
[4] The CoT Collection: Improving Zero-shot and Few-shot Learning of Language Models via Chain-of-Thought Fine-Tuning
[5] Chain-of-Thought Prompting Elicits Reasoning in Large Language Models